
中文命名实体识别的傅立叶卷积网络
2022-06-15 15:52李彪
现代信息科技 2022年2期


摘 要:针对transformer编码器架构在中文命名实体识别任务上表现不佳的问题,提出使用无参数化的傅立叶子层替换编码器中自注意力子层,使用卷积神经网络替代前馈神经网络。实验表明,采用结合傅立叶变换和卷积神经网络的transformer encoder架构的算法,可以在较小的字符嵌入和参数量下实现性能提升,且训练过程更快。
关键词:中文命名实体识别;编码器;傅立叶变换;卷积神经网络
中图分类号:TP391;TP18 文献标识码:A文章编号:2096-4706(2022)02-0104-03
Abstract: In view of the poor performance of transformer encoder architecture in the task of Chinese named entity recognition, a non-parameter Fourier sublayer is proposed to replace the self attention sublayer in the encoder, and a convolutional neural network is used to replace the feedforward neural network. Experiments show that the algorithm based on the transformer encoder architecture combining Fourier transform and convolutional neural network can improve the performance with small character embedding and parameters, and the training process is faster.
Keywords: Chinese named entity recognition; encoder; Fourier transform; convolutional neural network
0 引 言
命名实体识别是自然语言处理领域的重要基础课题,旨在将文本中命名实体分类到预定义的类别,如人名、组织和公司等。自然语言处理领域的一系列下游任务都依赖于命名实体的准确识别,如问答系统和知识图谱,甚至在推荐系统领域内NER也开始扮演着重要角色。
现有的标准NER模型将命名实体识别视作逐字符的序列标注任务,通过捕获上下文信息预测每个命名实体的预定义标签分类概率。该领域内的主要模型可以大致分为以条件随机场为代表的概率统计模型和以BiLSTM-CRF[1]为代表的深度学习模型。
Transformer[2]架构在NLP领域的其他任务中快速地占据了主导地位,通过从输入的组合中学习更高阶特征的方式灵活地捕获不同语法和语义关系。但其核心的注意力子层在方向性、相对位置、稀疏性方面不太适合NER任务。
本文引入无参数的傅立叶变换子层和卷积神经网络单元对Transformer架构中注意力子层和前馈神经网络单元进行完全替代,改进后的Transformer结构解决了中文命名实体识别中模型特征提取能不足和中文潜在特征表示不充分的问题。傅里叶子层和卷积神经网络单元的参数规模和并行性能使得该架构在小规模语料、较小字符嵌入和快速训练场景中更具实用性。模型在CLUENER2020[3]中文细粒度命名实体识别数据集上取得了较好的实验性能。
1 相关工作
近年来,基于深度学习的实体识别方法开始成为主流研究方向。Collobert[4]等提出使用卷积神经网络完成命名实体识别任务。RNN模型因为能够解决可变长度输入和長期依赖关系等问题被引入NER领域,BiLSTM-CRF模型使用双向长短期记忆网络和其他语言学特征提升模型识别效果。
傅立叶变换作为神经网络理论研究的重要方向。Chitsaz等在卷积神经网络中部署了FFT以加快计算速度,Choromanski等利用随机傅立叶特征将Transformer自注意力机制的复杂性线性化,而James等[5]提出的FNet网络更是在训练速度和模型精度上取得了成功。
本文提出了一种基于新型Transformer编码结构的命名实体识别方法,通过引入无参数化的快速傅立叶变换弥补Transformer结构的自注意力机制在中文命名实体识别任务中方向性和相对位置上的不足,并采用更适合上下文信息交互的卷积神经网络替换Transformer结构中密集的全连接层。新型Transformer编码结构结合BiLSTM-CRF模型,在不引入先验知识和预训练信息的基础上,采用更少的词嵌入长度、参数量和标注数据语料即可充分捕获文本序列的潜在特征,构建一种迁移能力更强、完全端到端的命名实体识别模型。
2 FTCN模型
FTCN模型共包含三个部分:FTCN编码模块,BiLSTM模块和CRF模块。FTCN编码模块支持随机初始化并自主训练词向量和预训练词向量微调两种词嵌入方式。BiLSTM模块通过引入门控机制充分提取文本的双向语义特征。最后,CRF模块采用动态规划算法将BiLSTM输出的特征向量解码为一个最优的标记序列。
2.1 FTCN解码模块
FTCN-Encoder是一种无须注意力机制的Transformer架构,其中每一层由一个傅里叶子层和一个卷积神经网络子层组成,模块结构如图1所示。本质上,本文是将每个Transformer架构的自注意力子层替换成一个傅里叶子层,该子层将输入序列沿着序列长度和词向量维数两个维度进行离散傅立叶变换。同时,本文使用卷积神经网络取代每个Transformer架构的前馈神经网络,卷积神经网络可以模拟实现类似n-gram模型的效果,充分挖掘上下文字符之间的语义特征,相较于前馈神经网络参数量更少且更适合命名实体识别任务。
其中,傅立叶变换将函數转换成一系列周期函数,给定一个序列,离散傅立叶变换的公式为:
其中,k∈[0,N-1],对于每个k,离散傅立叶变换将原始输入表示为之和。傅里叶子层将输入沿着序列长度和词向量维数两个维度进行离散傅立叶变换。对于结果我们仅保留实数部分。
同时,如果保留Transformer中的前馈神经网络,则FTCN-encoder模块将退化成无卷积神经网络参与的FTNN-encoder模块。FTCN-encoder模块的特征提取能力更强,且可以通过设置各子层的连接方式,选择ResNet连接或Concat连接。而FTNN-encoder模块的连接方式则更适合ResNet连接,模型参数量过大且难以收敛。
2.2 BiLSTM模块
长短期记忆网络是一种特殊的RNN网络,在动态捕获序列特征和保存记忆信息的基础上引入门控机制和记忆单元。用于缓解长序列遗忘问题的三个门控机制分别为遗忘门、输入门和输出门,这种门控机制通过对记忆单元的信息进行有效遗忘和记忆,能够学习到长期依赖并解决了不同长度输入和RNN容易产生梯度消失和爆炸的问题。BiLSTM是对长短期记忆网络的一种优化改进,使用正向和反向长短期记忆网络来提取隐藏的前向语义信息和后向语义信息,实现对上下文数据的充分利用。
2.3 CRF模块
通常,基于概率统计的机器学习和深度学习都是将命名实体识别任务视作序列标注问题,所以多采用Softmax等分类器完成多分类任务。但Softmax分类器忽略了预测标签之间的依存关系,而依存关系是命名实体识别中重要的机制。条件随机场模型可以考虑标签序列的全局关系,得到全局最优的标注序列。
3 实验与分析
本文采用控制变量的方法进行实验设计,为了验证傅立叶卷积网络FTCN的性能和各个结构对性能提升的占比,将采用统一的数据处理方法、相同的运行环境和训练参数设置。模型的差异度仅存在于不同的结构构成,共同部分确保一致。在每轮实验中都让模型得到充分训练,并采用多轮测试取平均的方式作为最终的性能指标,排除随机性和其他实验干扰。
3.1 实验数据及评价指标
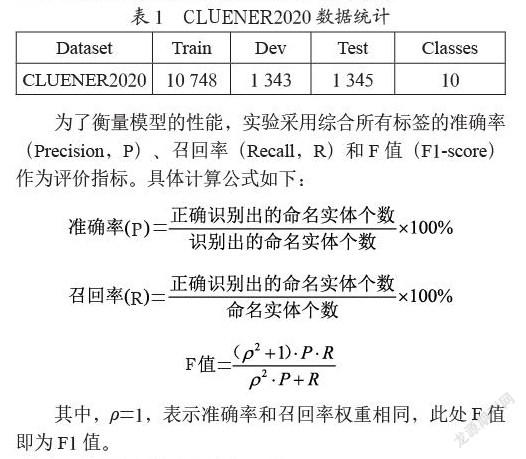
本文使用中文细粒度命名实体识别数据集CLUENER 2020,本数据是在清华大学开源的文本分类数据集THUCTC基础上,选出部分数据进行细粒度命名实体标注。CLUENER2020采用四元标记集{B,I,O,S},标注了包括组织、姓名、地址、公司、政府、书名、游戏、电影、组织机构和景点共计10个标签类型。其中B表示命名实体的第一个词,I表示命名实体的其余词,O表示非命名实体词,S则表示命名实体为单个字符。与其他可用的中文数据集相比,CLUENER2020被标注了更多的类别和细节,具有更高的挑战性和难度。CLUENER2020数据集的信息统计如表1所列。
为了衡量模型的性能,实验采用综合所有标签的准确率(Precision,P)、召回率(Recall,R)和F值(F1-score)作为评价指标。具体计算公式如下:
其中,ρ=1,表示准确率和召回率权重相同,此处F值即为F1值。
3.2 模型搭建和参数设置
实验使用PyTorch搭建模型,并保证模型的数据处理和训练、测试部分代码的一致性。PyTorch是一个基于Torch的Python开源机器学习库,用于自然语言处理等应用程序。实验所涉及模型的参数设置如下:输入维度为128,训练集和测试集的batch_size为32,训练学习率为0.01,dropout参数均为0.5,FTCN中卷积核kernel_size设置为3和5并保证输出维数与输入维数一致。
3.3 实验结果
在CLUENER2020数据集上,为了有效验证FTCN模型的性能,本文采用以下四种方法进行实验设置:CLUENER2020数据集中的基线模型BiLSTM-CRF、采用FTCN解码模块的FTCN(encoder)-CRF、将FTCN解码模块中卷积神经网络替换为transformer中前馈神经网络的FTNN(encoder)-BiLSTM-CRF和本文提出的FTCN模型。实验结果如表2所示。
从表2中可以看出,BiLSTM-CRF的F1值为69.90%相较于CLUENER2020数据集中提出的基线模型取得了相近的结果;FTCN(encoder)-CRF模型由于缺少BiLSTM模块所以取得较差的成绩;FTNN(encoder)-BiLSTM-CRF由于FNN导致编码模块的特征提取能力不足;本文提出的FTCN模型在准确率、召回率和F1值三项评价指标上均取得了最优,对比CLUENER2020提出的baseline即BiLSTM-CRF模型将F1值从70%提升至72.48%,提升幅度约为3.54%,并且模型训练速度显著提升,收敛更为迅速。
4 结 论
本文提出了一种全新的端到端神经网络FTCN,并将其应用于中文命名实体识别任务中且在CLUENER2020中文细粒度命名识别数据集上验证了模型的性能。该模型的编码模块使用类似Transformer编码的架构,使用傅立叶变换子层取代了Transformer中的自注意力子层,并选择更适合自然语言处理任务的卷积神经网络代替前馈神经网络。在降低模型参数量的基础上,提升了模型的并行程度,充分挖掘上下文字符间的语义信息,提升了命名实体识别的性能。
参考文献:
[1] HUANG Z,XU W,YU K. Bidirectional LSTM-CRF models for sequence tagging [J/OL].arXiv:1508.01991 [cs.CL].[2021-11-02].https://arxiv.org/abs/1508.01991.
[2] VASWANI A,SHAZEER N,PARMAR N,et al. Attention is all you need [J/OL] arXiv:1706.03762 [cs.CL].[2021-11-02].https://doi.org/10.48550/arXiv.1706.03762.
[3] XU L,DONG Q,LIAO Y,et al. CLUENER2020:fine-grained named entity recognition dataset and benchmark for Chinese [J/OL].arXiv:2001.04351 [cs.CL].[2021-11-05].https://doi.org/10.48550/arXiv.2001.04351.
[4] PINHEIRO P O,COLLOBERT R. Weakly Supervised Semantic Segmentation with Convolutional Networks [J].arXiv:1411.6228 [cs.CV].[2021-11-03].https://arxiv.org/abs/1411.6228.
[5] LEE-THORP J,AINSLIE J,ECKSTEIN I,et al. FNet:Mixing Tokens with Fourier Transforms [J].arXiv:2105.03824 [cs.CL].https://doi.org/10.48550/arXiv.2105.03824.
作者简介:李彪(1996—),男,汉族,安徽蚌埠人,硕士研究生在读,研究方向:人工智能、自然语言处理、数据挖掘。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
科学与财富(2018年34期)2018-01-15
科技与创新(2017年5期)2017-03-28
科技创新与应用(2016年35期)2017-02-21
计算机应用(2016年12期)2017-01-13
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
电脑知识与技术(2016年10期)2016-06-16
现代电子技术(2009年14期)2009-09-05
电子设计应用(2004年6期)2004-07-27
