
基于结合情景上下文的FHMM负荷分解方法
2022-06-24 10:01魏海浩刘爱莲李英娜
计算机应用与软件 2022年4期
魏海浩 刘爱莲 李英娜
(昆明理工大学信息工程与自动化学院 云南 昆明 650500)
0 引 言
智能用电是智能电网的重要环节之一,是实现高级量测体系和互动服务体系的核心内容。负荷监测是实现智能用电的关键技术之一。非侵入式负荷分解(Non-intrusive load disaggregation,NILD)最早由Hart[1]教授提出,利用电力入口处总负荷信息,对用户内部的用电设备进行状态监测和能耗分解。NILD有利于用户与电网公司友好互动,对于电网削峰填谷以及用户绿色用电、节约用电均具有指导意义。
目前负荷分解方法主要分为模式识别和机器学习两种。其中模式识别主要包括粒子群算法、遗传算法等。文献[2]将总谐波失真系数和功率作为负荷特征,采用惯性权重粒子群算法进行负荷分解,负荷识别率高且克服了粒子群算法后期陷入局部最优的缺点,但是前提条件为用电设备是开关型负荷。文献[3]将NILM视为0-1背包问题,测试粒子群、模拟退火、差分进化等数学优化算法对于负荷辨识的性能,同样是将用电设备抽象成开关二状态模型。文献[4]首先运用AP聚类进行设备状态提取,然后基于遗传算法进行负荷识别与分解,虽然对设备的建模更贴近实际,但是未考虑多用电器同时运行的情况。
机器学习在一定程度上能够解决上面的问题,其中隐马尔可夫(HMM)是常用的方法。文献[5]提出了一种基于粒子滤波的负荷分解方法,单个负载和负载的叠加分别用隐马尔可夫(HMM)和因子隐马尔可夫(FHMM)建模,并且模拟了三种情景下的实验:有无噪声和重置后验估计。文献[6]运用FHMM对整个家庭负载设备进行建模,使用维特比进行负载能耗的解码,对比传统的NILM,该方法识别精度有一定的提高特别是针对负荷波动性较大的负载设备。文献[7]提出了一种稀疏维特比的方法,该方法基于超状态隐马尔可夫模型和稀疏维特比算法。文献[8]考虑了设备之间的相互作用,使用FHMM对设备交互进行建模,并且通过维特比算法进行推断。
目前对于负荷分解的研究很多,但是依然面临一些问题:(1) 基于优化算法的负荷分解对负载设备的建模并不符合设备的实际运行情况[9],并且基于k-means电器状态聚类受功率波动的影响,导致聚类中心不稳定。(2) 基于HMM的NILD考虑的用电情景过于单一,导致识别不准确。(3) 随着电器数量的增多,基于HMM的NILD使用维特比进行负载能耗解码的效率低问题。
针对以上问题,提出一种结合情景上下文的FHMM负荷分解。对于单个负载和多负载叠加的情况分别运用HMM和FHMM建模。运用高斯混合模型(GMM)进行负荷状态聚类。结合情景上下文信息,对负载设备的状态转移概率进行优化消除冗余状态转移概率,对状态空间以及状态转移路径进行约束降低维特比算法的复杂度。
1 负荷模型建立
1.1 单个电力负载的负荷模型
根据负载稳态特征的不同,负荷类型可分为开/关型负荷、有限状态型负荷、连续变状态型负荷。其中,前两种设备类型没有本质区别,都具有有限的工作状态,且各状态的负荷特征相对稳定,可以用来描述大多数家用电器[6]。有限状态型负载的运行过程如图1所示。

图1 有限状态负载的运行过程
有限状态类型负载的运行过程可以通过HMM建模。假设,用电器状态集合为Q={q1,q2,…,qK},K代表用电器运行状态的个数,则其运行过程可以描述为一个离散时间序列S={s1,s2,…,st,…,sT},其中st∈Q表示时刻t时用电器所处的状态是不可观测的隐藏状态,T为运行时间。用电器输出功率作为观测值输出,观测序列为O={o1,o2,…,oT}。单个用电器的负荷模型如图2所示,该模型中K=2,st在ON和OFF之间切换。

图2 单个负荷的HMM模型
单个负荷的HMM模型可由5个参数描述:θ={Q,V,π,A,B}。
1)Q代表隐藏状态集合;V={v1,v2,…,vM}为观测值集合,ot∈V。
2) 初始状态概率π表示t=1时模型处于某个隐藏状态的概率,π={π1,π2,…,πK},πk=P(s1=qk),k=1,2…,K。
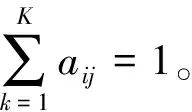
4) 观测值概率矩阵B={bj(m)}K×M,其中bj(m)表示t时刻状态j输出观测值Vm的概率。
1.2 总负荷模型


图3 总负荷的FHMM模型
基于FHMM的总负荷模型可由3个参数描述:θ{π,A,B}。
2 基于高斯混合模型的负荷状态聚类

(1)
式中:x是D维数据向量;λ=(ω1,ω2,…,ωK;μ1,μ2,…,μK;Σ1,Σ2,…,ΣK)为GMM的参数;ωk(k=1,2,…,K)代表第k个高斯分布的权重;g(x|μk,Σk)为第k个高斯分布模型。
(2)
g(x|μk,Σk)=
(3)
式中:μk为均值向量;Σk为观测向量的协方差矩阵。
2.1 基于EM算法的GMM参数估计
EM算法通过事先假定数据的类别然后根据迭代估计出GMM的权值ωk、均值μk和协方差Σk。具体步骤如下。
E-步:引入隐含变量,即xi属于k类的后验概率P(k|xi,λ(t))。对于数据X={x1,x2,…,xn},已知上次迭代的参数λ(t)=(ω(t),μ(t),Σ(t)),则隐含变量为:
(4)
M-步:求解模型参数的最大似然估计,并对参数进行更新。引入模型的对数似然函数:
(5)
分别对ωk、μk、Σk求偏导,将隐含变量代入得到t+1次迭代的GMM参数:
(6)
(7)
(8)

2.2 状态聚类
GMM模型建立后,对于输入数据,采用Bayes最大后验概率(MAP)准则[13],得到数据属于哪一类,具体实现如下。
对于一组样本数据,数据类别的划分可以描述为:
(9)
每个数据点来自第k个高斯分量的后验概率为:
(10)
式中:ωk为第k个高斯分布密度的先验概率;g(xi|μk,Σk)为xi属于第k类的概率密度。样本xi属于某类的后验概率密度最大,即xi属于该类。联立式(9)和式(10)的聚类结果为:
(11)
3 基于FHMM负荷分解
3.1 FHMM参数估计

(12)
(13)
(14)
(15)
观测值满足:ot|st(1:N)~N(μt,Σt)。

3.2 结合情景上下文维特比算法的负载状态估计
情景上下文包括:
1) 对实际环境下负载设备的功耗模式进行分析,对各负载的状态转移概率矩阵进行优化。考虑REDD数据集[14]中的washer_dryer负载设备,它包含OFF、洗衣、烘干三个状态,washer_dryer的运行过程如图4所示。

图4 washer_dryer运行过程
观察图4可知,washer_dryer的状态转移矩阵为9×9方阵。假设其状态转移矩阵如表1所示。

表1 washer_dryer状态转移概率
但是实际情况下用户行为决定了其操作模式,Q13、Q21和Q32是不存在的,即新的状态转换图和状态转移矩阵更新如图5和表2所示。

图5 修正后的washer_dryer运行过程

表2 修正后的washer_dryer状态转移概率
仿照上述结合实际环境对负载设备的功耗模式进行分析,可得到其他负载设备优化后的状态转移概率矩阵。
2) 根据t时刻的功率观测值ot对该时刻的状态空间进行约束,同时考虑后前时刻的差分功率ΔPt来减少状态转移路径的条数,降低维特比算法的计算量。

(16)

图6 基于FHMM的负荷分解

(17)

(18)

(19)
对于总负荷模型t时刻的差分功率是大于或等于N个设备的差分功率的和,可由式(20)描述。
(20)

通过式(18)对负荷设备i的状态空间进行约束,剔除状态空间中不符合实际情况的状态,通过式(20)考虑后前时刻观测值的差分功率ΔPt减少状态转移路径的条数,经过约束的FHMM负荷分解可由图7表示。

图7 基于状态约束的FHMM负荷分解
在FHMM参数θ{π,A,B}已知的条件下,结合实际情况对负荷设备的状态空间进行约束,接下来运用维特比算法通过动态规划求解概率最大路径,即求得各负荷设备的最优状态序列实现负荷分解,其目标函数为:
(21)
其中:
(22)
(23)
(24)
(25)
3.3 各负载设备的负荷分配
(26)
联立式(21)和式(26),得到负荷设备i的负荷序列Oi,得其在时段T内的能耗为:
(27)
4 算例分析
本文选用REDD数据集中6户家庭的负荷数据来验证算法,数据长度为10天,采样频率为1 Hz。前7天的数据用于训练模型参数,余下3天的数据用于验证负荷分解效果。在用聚类算法求取用电器状态之前,由于功率序列中普遍存在功率脉冲噪声,因此选用中值滤波去除序列中的噪声。图8反映了dishwaser电器的原始功率信号,以及使用了中值率波处理后的信号。对比发现当滤波窗口为7的时候信号更加平滑,信号中几乎没有比较突出的尖峰,与此同时信号也并未发生畸变,与原信号比较吻合。

(a) 中值率波处理后的信号

(b) 原始功率信号图8 中值滤波
针对滤波处理后的数据,分别使用k-means和GMM算法分别对该功率数据聚类,聚类效果如表3所示,选取House1和House2的两种电器进行横向对比,结果k-means受功率波动的影响较大,表现出较大的方差,从而导致聚类中心不稳定,而GMM是一种基于概率的聚类,受波动的影响较小,两次聚类的中心比较稳定。图9是GMM的聚类结果,可以看出其结果为四个高斯分布图。综上说明本文选取GMM状态聚类是合理的。

表3 GMM和k-means聚类结果对比

续表3

图9 基于GMM的dishwaser状态聚类
表4为利用GMM聚类得到的House1中所有电器的运行功率。

表4 House1中各电器的运行功率
为验证本文方法负荷分解的性能,引入F1-Measure、能耗分解误差εE这2个参数作为评价指标,具体计算方法如下:
(28)
(29)

表5展示了利用第一周的历史数据训练的负荷分解模型在测试环境下2个指标的结果。表5中,F1-Measure的均值为0.823,表明本文方法能够对电器设备准确辨识;其次,平均能耗误差为4.034%,表明本文方法可以准确地实现负荷的分解。

表5 负荷分解测试结果
组合优化方法(Combinatorial Optimization,CO)[15]是NILM的常用方法,前文已经探讨CO无法模拟用电器的实际运行过程,处理办法往往是将用电设备抽象成开关二状态负荷。因此,接下来本文将进行负荷分解方法的横向和纵向对比。横向对比为结合情节上下文的FHMM(C-FHMM)和CO的对比;纵向对比为FHMM和C-FHMM的对比,基于CO的负荷分解参考文献[16]。实验结果如表6所示。
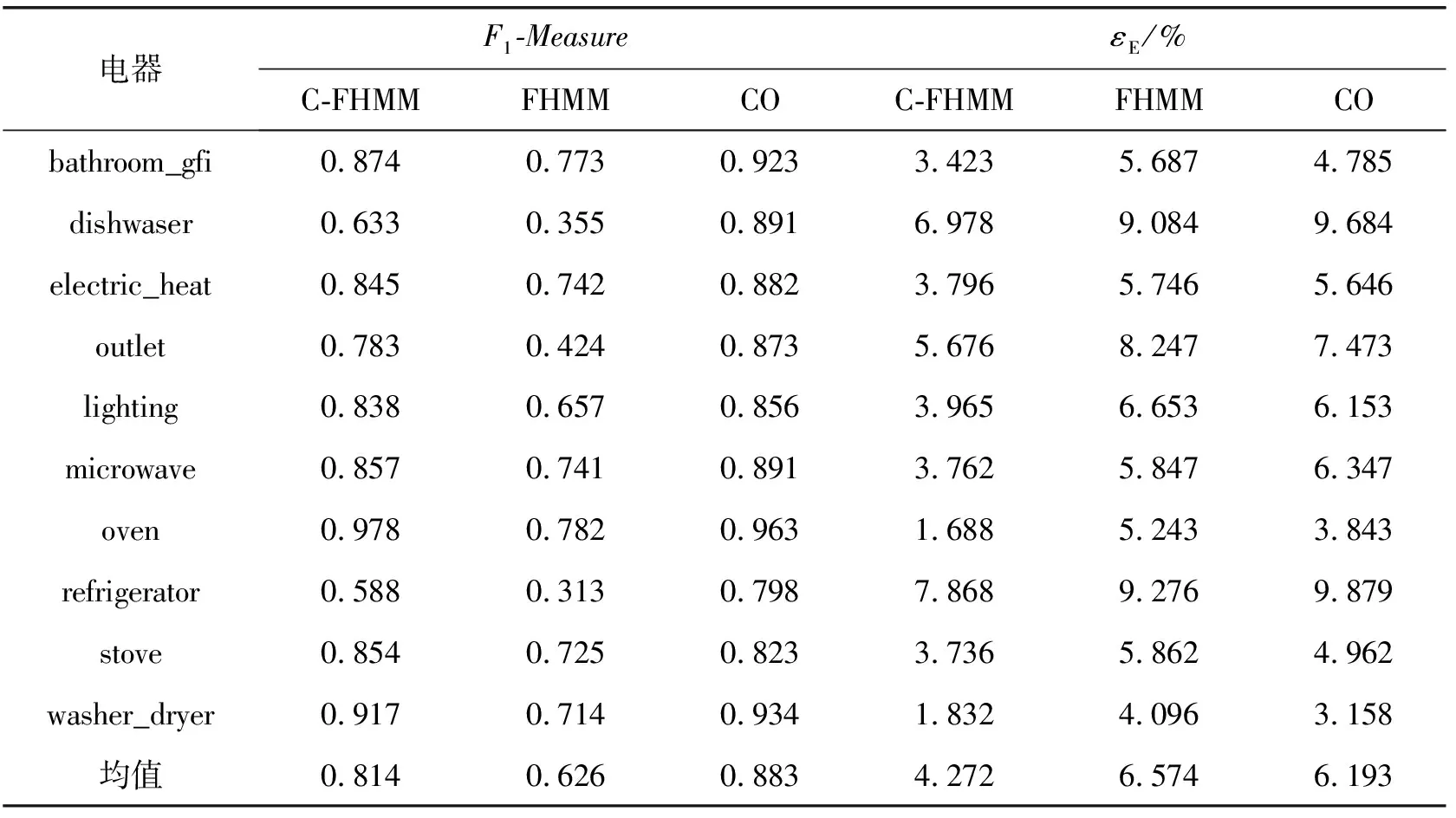
表6 负荷分解方法对比
可以看出,从F1-Measure的角度看,CO的F1-Measure最高,平均值为0.883;FHMM的F1-Measure最低;C-FHMM的F1-Measure比CO低的原因为C-FHMM将电器建模为多状态,负荷分解时出现电器状态的混淆识别导致其F1-Measure略低于CO。从能耗分解误差εE的角度看,C-FHMM的能耗误差要比CO的能耗误差小,为4.272%,这是由于当CO将电器建模为二状态(电器的各状态的平均功率代表运行时功率),出现负荷辨识错误时将提高其能耗分解误差。其次,dishwaser和refrigerator的F1-Measure最低,原因是这两个电器的运行状态功率比较接近(见表4),导致负荷辨识错误。图10为运用C-FHMM方法得到的负荷分解结果。

图10 负荷分解结果
图11展示了三种方法的负荷分解效率,观察发现,随着电器设备的增多,算法求解的复杂度越大。本文的C-FHMM在运用维特比算法进行解码时对状态空间和状态转移路径进行了约束,所以运算效率相比FHMM有了明显提高,且当电器设备数量大于8个时,负荷分解效率也优于CO。

图11 负荷分解效率
5 结 语
本文提出一种结合情景上下文的FHMM的负荷分解方法:(1) 针对组合优化(CO)的负荷分解对电器设备建模不符合电器实际运行状态的问题,运用因子隐马尔可夫(FHMM)对负荷进行建模。(2) 根据电器工作状态的功率服从高斯分布,运用GMM进行电器状态聚类,避免了k-means聚类中心不稳定问题。(3) 考虑情景上下文的信息,对负载设备状态转移概率进行优化,其次,对状态空间以及状态转移路径进行约束,降低维特比算法的复杂度。
基于REDD数据集进行方法验证,本文算法对比CO和FHMM在降低能耗分解误差的情况下,分解效率也有一定的提高。不足的地方在于,当用电设备的状态功率接近时分解效果并不理想,其次模型的训练依赖于电器已知的情况。未来将对上述存在的问题进行研究。
猜你喜欢
中外文摘(2022年8期)2022-05-17
文萃报·周五版(2022年14期)2022-04-12
汽车实用技术(2022年4期)2022-03-07
———摄影大师艾略特·厄维特拍的一组情侣照片
北广人物(2020年42期)2020-11-04
红蜻蜓(2020年9期)2020-09-26
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
电子技术与软件工程(2016年23期)2017-03-06
WTO经济导刊(2016年9期)2016-11-02
学生天地·小学低年级版(2014年1期)2014-02-12
科学启蒙(2006年1期)2006-01-11
