
基于双窗口TextRank关键句提取的文本情感分析
2022-06-24 10:12宛艳萍谷佳真
计算机应用与软件 2022年4期
宛艳萍 张 芳 谷佳真
(河北工业大学人工智能与数据科学学院 天津 300401)
0 引 言
情感分析(Sentiment Analysis,SA)又称观点识别、情感挖掘等。指通过计算机手段快速获取、整理和分析网络评论文本的过程。随着社交网络、电子商务、移动互联网等技术的大力发展,互联网中带有情感色彩的文本数据迅速膨胀,对其进行整理并分析可以更好地理解网民的观点和立场。目前情感分析已经应用于舆情管控、商业决策、信息预测、情绪管理等方面。
目前国内外对于文本情感分析的方法主要包括基于词典规则和基于机器学习两种。基于词典规则的方法过于依赖于情感词典,无法解决未登录词的问题,基于机器学习的文本情感倾向性分析多使用SVM、KNN和朴素贝叶斯等分类器,不同分类器具有不同的分类效果,各有其优劣势。
由于中文文本的复杂性,在情感分析的文本中常会包含一些具有复杂情感表达或有情感歧义的语句,会增加情感分类的难度和错误倾向,且不同的句子对于文本的情感贡献度是不同的,因此林政等[1]提出了情感关键句的概念。对情感分析的文本提取关键句可以避免非关键句对文本整体的情感倾向引起的判断偏差,有助于提高情感倾向性分析的性能。如对于某酒店的评论,评论中前半部分描述了酒店附近的景区使用了大量积极性的词语,但在评论的最后明确表示不会再入住此酒店,所以此评论的情感是负向的,但由于包含大量积极性的词语,若直接对整条评论进行情感倾向性分析很容易产生误判。
现阶段基于关键句的文本情感倾向性研究,对于关键句的提取大多只考虑如情感、关键词等文本属性,通过各属性间加权求和的方法提取关键句并没有考虑文本的上下文信息,关于分类器的选择多使用SVM、朴素贝叶斯等分类器进行情感分类并不能有效地结合不同分类器的分类优势。因此本文在已有基于关键句的文本情感分析研究的基础上,提出一种融合全局特征和自身特征的关键句提取算法,然后对提取的关键句采用集成分类器进行情感倾向性分析的方法。
1 相关研究
1.1 关键句提取方法
目前对于提取关键句的研究并不多,文献[1]中首次提出情感关键句的概念,根据情感属性、位置属性和关键词属性加权求和的方式提取关键句;文献[2]提出了SOAS算法,首先根据位置属性、关键词属性、词频句子频特征这三类属性提取关键句,然后结合词性和依存关系规则计算情感倾向性得分;文献[3]在SOAS的基础上考虑了主题特征,通过各句子间加权求和计算文本最终得分;文献[4]中将情感关键句的提取视为一个二元分类问题,提取句子特征并使用SVM进行分类;文献[5]对于关键句的提取考虑了Title和上下文信息,提出一种基于Title和加权TextRank抽取关键句的情感分析方法。
现有的方法在提取情感关键句时大多根据情感属性、位置属性和关键词属性加权求和提取关键句,只考虑了文本自身的特征并没有考虑全局信息。本文融合全局特征和自身特征提取关键句,对于全局特征不仅考虑传统的文本信息还考虑句子之间的相似性将其加权融合到TextRank中构建基于句子的图模型得到每个句子的得分,再根据句子本身特征对每个句子得分进行调整。当TextRank基于句子构建图模型时普遍认为所有的句子节点之间的边都是互相连接的,各节点之间权重共享,但当文本中包含句子比较多时,对于距离相距较远的句子其相互影响并不大,此时若认为所有的句子节点间都存在相互连接的边会使得与本句节点距离较近和较远的句子节点对本句的影响同样重要,这不仅增加了噪音且与实际情况不符。因此本文提出一种融合全局特征和自身特征双窗口的加权TextRank关键句提取算法(WTTW算法),在构建图模型时认为与本句节点所相邻的前两个句子节点和后两个句子节点相互影响并连接构成图模型的边,对于文本中句子较多的情况更贴近实际,并且减少了大量的计算工作。
1.2 分类器的选择
目前基于机器学习的情感倾向性研究主要是把情感倾向性分析的过程看成一个二分类或多分类的过程。文献[6]中首先将Tweets进行主客观分类,然后将主观文本再进行正负倾向性分析。文献[7]提出一种自适应多分类SVM模型,利用co-training算法将常用的分类器转化为自适应分类器。文献[1]在有监督分类中采用了分类器融合的方法。文献[8]对tweets使用不同的基分类器进行情感分类,将所有基分类器输出的结果进行累加,若正向得分大于负向得分,则判断为正向,反之为负向。
现有的研究关于文本情感倾向性分类器的选择大多只使用了单一的分类器或者将分类器进行简单的融合,并没有考虑将不同分类器根据后验概率进行加权集成,加权集成多种分类器可以调节不同分类器的优劣势,提高分类性能。
综上所述,本文提出一种融合全局特征和自身特征双窗口的加权TextRank关键句提取算法(WTTW算法),在WTTW算法提取关键句的基础上加权集成多种分类器进行文本情感倾向性分析的方法。
2 关键句提取算法
关键句的提取主要从全局特征和句子本身特征两方面进行考虑。全局特征主要通过关键词特征、位置特征、句子之间的相似度构建窗口为2的TextRank图模型,句子本身特征主要考虑句子情感特征和标点特征。
2.1 关键词权重
一般认为包含总结性词语、转折性词语和感知性词语(总之、总的来说、但是、觉得等)成为关键句的可能性越大。本文总结了一些较常见的这三类词语,部分如表1所示。

表1 关键性词语表
若句子中出现这些词语则成为关键句的可能性越大,关键词权重w1的计算公式如下:
(1)
(2)
2.2 位置权重
文本中通常首句和尾句更可能是总结句,包含关键性的信息,则越靠近首句或尾句的句子成为关键句的可能性越大,则位置权重w2的计算公式如下:
(3)
式中:i为句子的位置;n为句子总数。
2.3 相似度权重
经典的TextRank通过词的共现次数计算两个句子的相似性。文献[9]在TextRank中计算句子相似度时,认为BM25算法取得的效果最好。BM25算法是一种经典的检索算法,基于句子间相似度计算。两个句子相似度计算式为:
(4)
式中:前半部分因数IDF(wit)表示句子si中词wit的重要性;后半部分因数为词wit的相关性得分,f为词在sj中出现的频率,|sj|为句子sj的长度,avgSL为所有句子的平均长度,参数k1调节词频的影响力,b调节句子长度的影响力。IDF(wit)计算如下:
(5)
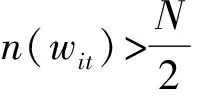
(6)
式中:N为句子总数,n(wit)为包含词wit的句子数,即认为包含词wit的句子越少,词wit越具有区分能力,越重要。
综上所述,相似度权重w3的计算式为:
(7)
2.4 基于全局特征构建窗口为2的图模型
TextRank算法是文本基于图排序的算法,作用于句子时多用于提取文本摘要[10-12],其思想源于谷歌的PageRank。PageRank是网页的排序算法,一个网页的重要性通过其所链接的网页的数量和影响力决定。借鉴于PageRank,TextRank通过将文本切分为不同的文本单元(词或句子)使其作为节点。对给定的文本D,首先进行句子切分D={s1,s2,s3,…,sn},si为文本中的第i个句子,n为文本中包含的句子总数,对于每个句子si={wi1,wi2,wi3,…,wim},由m个词组成。基于全局特征构建窗口为2的有权图G=(V,E),若文本中有5个句子其有权图模型如图1所示,各节点的得分为:
式中:d为阻尼系数,代表从任一节点跳转到另一节点的概率,一般取值0.85;In(vi)表示指向点vi的点的集合;Out(vj)表示点vj指向的点的集合;wji表示节点vj与节点vi之间边的权重。
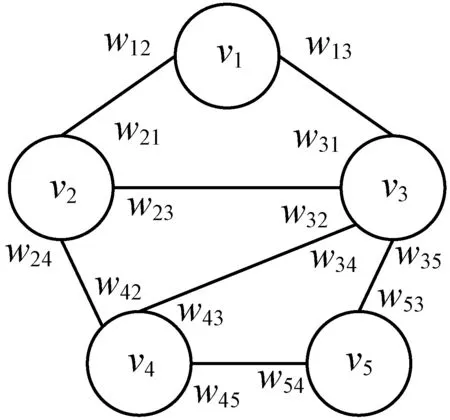
图1 窗口为2的有权图模型
可以看出,本文将整个文本作为一个单元,设置长度为2的滑动窗口,从第一句至最后一句顺序进行滑动窗口建立图模型。图中V={v1,v2,…,v5}为句子的节点集,依次代表文本中的5个句子,各节点得分如式(8)所示,由于窗口长度为2,因此v1节点只能与v2和v3两个节点连接构成边,而节点v3处于中间位置,则最多可与v1、v2、v4和v5四个节点连接构成边,其中各边上的wij表示节点vi共享给节点vj的边权重值。
由式(8)知,每个节点的得分主要取决于与其相连的节点所传递过来的权重wij。本文中对于各句子之间的权重wij主要考虑了关键词权重w1、位置w2、相似度权重w3,各句子之间的最终权重值可以写成3个权重加权求和的形式如式(9)所示,其中λ1+λ2+λ3=1,经实验确定λ1=0.45、λ2=0.25、λ3=0.3,将式(9)代入式(8)迭代直至收敛计算出句子的全局特征得分scoregl(si)。
wij=λ1w1+λ2w2+λ3w3
(9)
2.5 句子本身特征
句子本身的特征主要考虑了句子的情感特征和标点特征。本文认为关键句应该是情感强烈且单一的句子,所以对于句子si情感特征的得分scoreem(si)计算如下:
(10)
(11)
通常情况下叹号代表着更强的语气,而省略号多数情况下代表着无奈或失望,所以若一个句子中包含着叹号或者省略号可能蕴含的情感更强烈,则对于句子si标点特征的得分scorepun(si)计算如下:
(12)
对于给定的文本先通过图模型得到全局特征得分,然后根据标点特征和情感特征对各句子得分进行调整,得到句子的总得分,计算式如下:
T_score(si)=scoregf(si)+scorepun(si)+scoreem(si)
(13)
通过式(13)计算各个句子的最终得分,提取得分靠前的K个句子作为关键句,具体的关键句提取算法如算法1所示。
算法1基于全局特征和自身特征的WTTW关键句提取算法
输入:文本D,全局特征调节参数λ1、λ2、λ3。
输出:文本的关键句。
对文本D,根据标点进行预处理并切分句子D={s1,s2,s3,…,sn}
ForeachsiinDdo
根据式(1)计算si相似度权重w1
根据式(3)计算si关键词权重w2
根据式(7)计算si位置权重w3
根据式(10)计算si情感特征的得分scoreem(si)
根据式(12)计算si标点特征的得分scorepun(si)
End
根据式(9)对各项权重加权求和代入式(8),构建基于全局特征窗口为2的图模型,迭代直至收敛计算scoregf(si)
根据式(13)计算句子的总得分,提取得分高的前K个句子作为文本的关键句
3 基于关键句的soft_voting算法
对于传统的文本情感倾向性研究中,大多使用单一的分类器,如k近邻、朴素贝叶斯、支持向量机等,还有部分将分类器的结果进行了融合,文献[1]中首先将文本划分为关键句集和细节句集,然后在关键句集、细节句集和全文集分别训练分类器,然后根据3个基分类器的后验概率进行累加判别文本的情感类别(Combined Classifier),取得了较好的效果。由此得到启发,不同分类器具有不同的分类效果,集成多个分类器的分类结果可获得比单一的分类器更强的泛化能力,即集成学习中的Bagging算法,其具体过程如图2所示。

图2 Bagging算法过程
Bagging算法训练集使用bootstrap抽样(有放回的随机抽样)并行训练不同的基分类器,然后将不同基分类器的结果采用投票法进行结合,既节省了大量的时间又结合了不同分类器的优点,提高了分类正确率。投票法主要分为hard_voting和soft_voting两种方法。其中,hard_voting中各基分类器直接输出类标签,根据少数服从多数的原则得到最终结果。hard_voting中认为所有的基分类器贡献度相同,但更合理的投票法应该根据不同基分类的分类效果赋予不同的权值,即soft_voting。soft_voting中各基分类器输出类的概率,并对每个基分类器赋不同的权重值然后根据每个基分类权重对其输出的类概率加权求和,即后验概率加权求和来决定最终的情感倾向性结果。本文在WTTW算法的基础上使用soft_voting方法对提取的关键句进行情感倾向性分析(WTTW_SV方法),具体算法如算法2所示。
算法2WTTW_SV算法
输入:基于WTTW算法提取的关键句集。
输出:文本的情感倾向性。
ForeachfkinFkeydo
For each基分类器ciin集成分类器En_C={c1,c2,…,cn} do
计算基分类器的输出类的后验概率c_proi
End
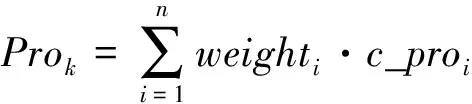
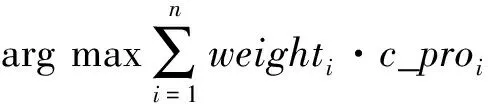
End
4 实验与结果分析
4.1 实验数据
本文通过Python爬虫爬取不同网站中的评论文本,其中酒店领域数据集数爬自携程网;电影领域数据集爬自豆瓣网;手机领域数据集爬自京东网;外卖领域数据集爬自美团网。经过去重降噪后进行人工标注,最后在各领域选取了正向评论和负向评论各2 000条,共4 000条评论信息作为本次实验的数据集,汇总表如表2所示。实验中训练集与测试集按照4 ∶1的比例进行划分,使用朴素贝叶斯作为基础分类器。
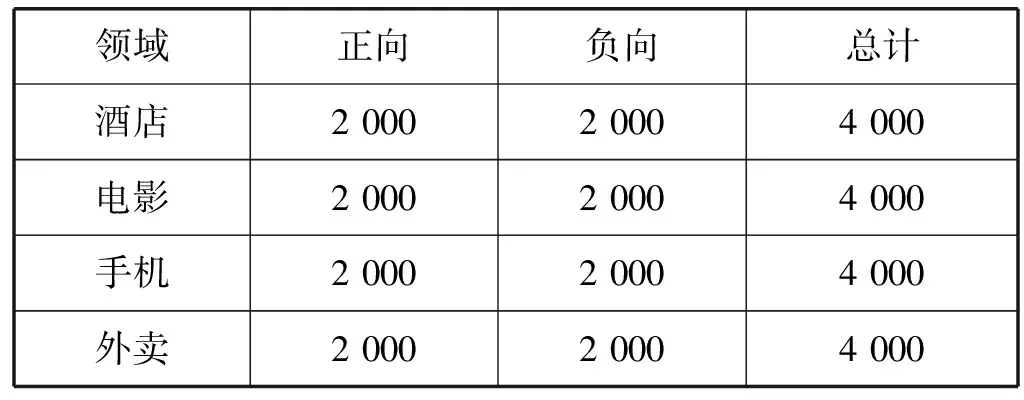
表2 实验数据集汇总表
4.2 soft_voting权重确定实验
本文的集成分类器主要是对KNN、SVM、随机森林、朴素贝叶斯和逻辑斯谛回归五个基分类器的后验概率进行加权集成,即soft_voting方法。每个基分类器的权重值直接影响了实验效果的正确性,为了得到最佳的实验结果需要对各基分类器的权重进行调试,以情感倾向性分析的准确率为依据对每个基分类的权重进行调试。
以在酒店领域为例对各基分类的权重进行调整,首先根据各基分类的分类准确率设置其初始权重,准确率越高初始权重越大,然后保持除了需调整的基分类器的权重外其他基分类器的权重不变,将横坐标设为基分类的权重,纵坐标设为情感倾向性的准确率,对每个基分类的权重循环进行调试直至情感倾向性分析的准确率收敛停止调试,情感倾向性分析的准确率随分类器权重值变化实验结果如图3所示。

图3 基分类器权重调试
可以看出,当KNN分类器权重值为4,SVM分类器权重值为0,朴素贝叶斯分类器权重值为4,逻辑斯谛分类器权重值为13,随机森林分类器权重值为8时,实验准确率最高,可达0.923 8。
4.3 结果分析
本文中选取文献[1]中基于情感属性、关键词属性和位置属性提取关键句的文本情感倾向性分析作为baseline与基于全文的情感倾向性分析、基于全连接的加权TextRank(Full TextRank)、Combined Classifier和双窗口的加权TexrRank关键句提取算法(WTTW算法)进行对比,实验结果如表3所示,验证了本文提出的WTTW算法的有效性。
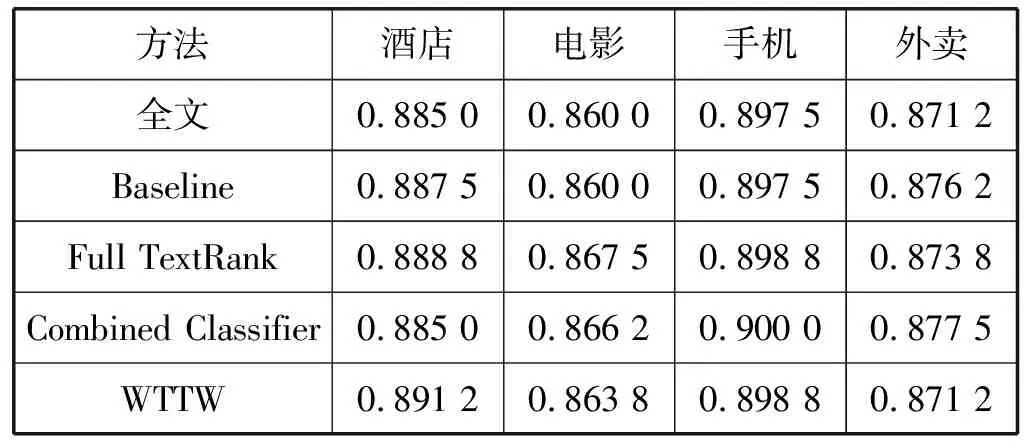
表3 关键句提取情感倾向性对比实验结果
在WTTW算法提取关键句的基础上使用不同分类器进行情感倾向性分析。选取soft_voting中集成的KNN、SVM、Naive Bayes、RandomForest和LogisticRegression五个传统分类器进行情感倾向性分析与本文的WTTW_SV方法进行对比,实验结果如表4所示。

表4 不同分类器情感倾向性对比实验结果
由表3比较结果知,尽管关键句的提取减少了实验语料,但是其准确率却不低于基于全文的情感倾向性分析。因为对于关键句的提取可以避免无关信息对情感倾向性的影响,提高情感倾向性分析的效率,当融合了全文和细节句集合的分类器结果后,其分类正确率并没有得到有效的提升,从而证明情感倾向性分析效率的提升并不依赖于实验语料的多少和分类器结果的融合,而是依赖于关键句的提取效率,正确的关键句的提取可以提高情感倾向性分析的准确率。而全连接的加权TextRank,会增加图模型的复杂性引入噪音,不仅会增加计算成本还降低了关键句的提取效率。本文提出的WTTW算法相对于baseline在各个领域的倾向性分析准确率都有不同程度上的提高;对比全连接的加权TextRank算法,其在酒店和外卖领域中准确率均低于WTTW算法,但在电影影评中准确率略高于WTTW,其原因可能是影评中句子长并且句子总数量较少,基于全连接的加权TextRank可以更好地提取句子的关键句。因此根据数据集的不同正确地选择TextRank的窗口个数可以提高关键句的提取正确性。
由表4比较结果知,将WTTW算法应用于soft_voting后,其准确率在各领域都有显著的提升。对于各基分类加权融合其后验概率之后的集成分类器可以有效地融合各基分类器的优势,其分类效果明显高于所有的基分类器。
为证明本文方法的有效性,在四个不同领域将baseline、Combined Classifier、Full TextRank与本文提出的WTTW_SV方法在准确率(A)、精确率(P)、召回率(R)和F1值(F)等四个评价指标上进行对比,其结果如表5所示。
(14)
(15)
(16)
(17)
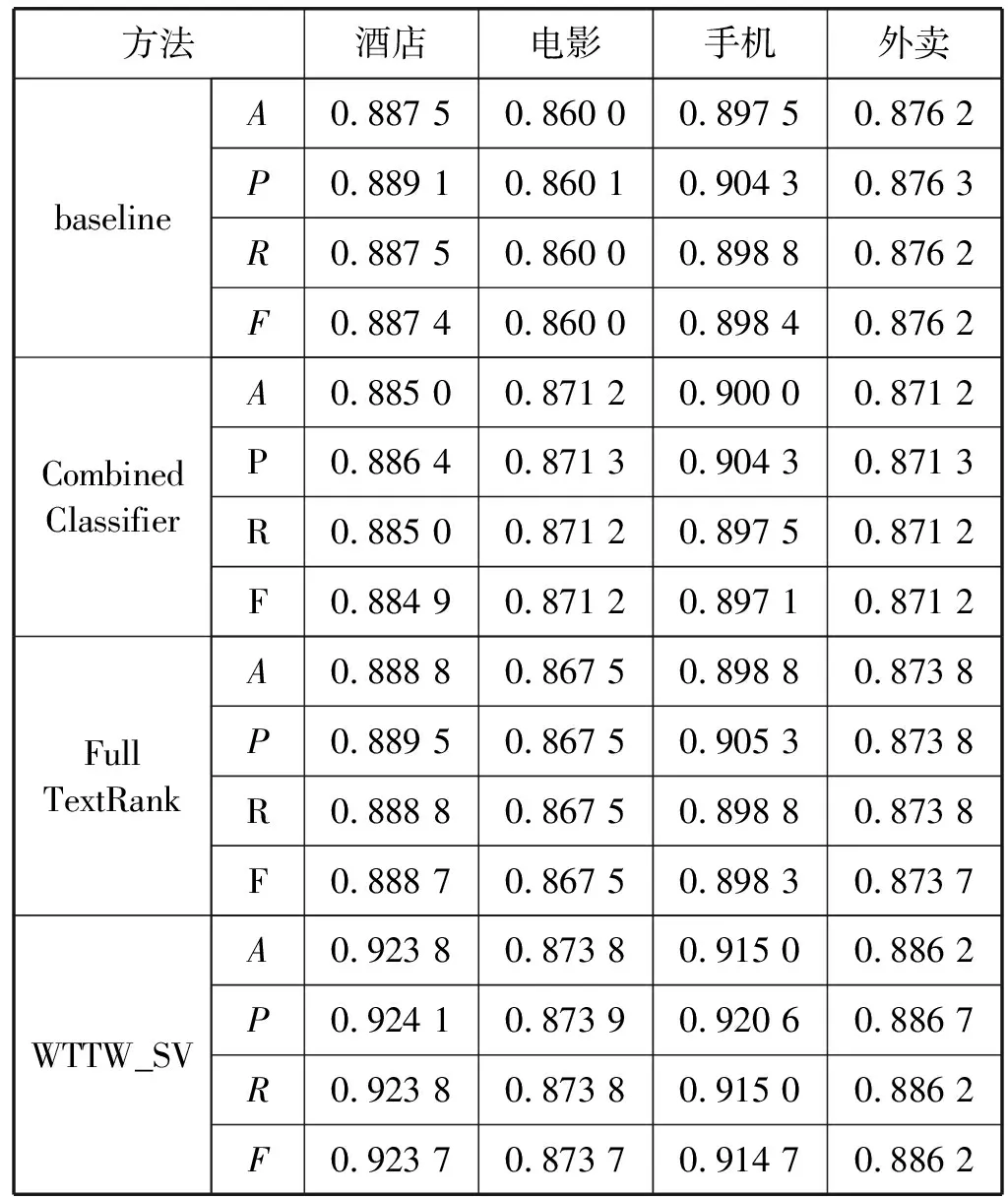
表5 不同评价指标对比实验结果
可以看出,本文方法对于不同领域在准确率、精确率、召回率和F1值上相对于baseline、Combined Classifier和Full TextRank的情感分析都有着明显的提升。其中在酒店领域提升效果最为明显,相比baseline准确率、召回率和F1值均提高0.036 3,精确率提高0.035;相比Combined Classifier准确率、召回率和F1值均提高提高0.038 8,精确率提高0.037 7;相比Full TextRank准确率、召回率和F1值均提高提高0.035,精确率提高0.034 6。这充分证明本文提出WTTW_SV方法的性能明显优于传统的基于关键句的文本情感倾向性研究,具有高效性。
5 结 语
本文在传统基于关键词属性、情感属性和位置属性提取情感关键句的文本情感倾向性的研究基础上进行改进,提出一种融合全局特征和自身特征双窗口的加权TextRank关键句提取算法(WTTW算法),然后在WTTW提取关键句的基础上使用soft_voting进行情感倾向性分析的方法WTTW_SV。实验证明本文提出的WTTW_SV方法在不同领域相比于baseline在准确率、精确率、召回率、F1值上都有明显的提升。未来,将进一步研究更有效的关键句提取算法以及数据集中句子规模与构建TextRank图模型中窗口长度的关系。
猜你喜欢
现代电子技术(2022年15期)2022-07-28
心理学报(2022年5期)2022-05-16
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
当代陕西(2020年17期)2020-10-28
人大建设(2018年5期)2018-08-16
魅力中国(2018年11期)2018-08-06
证券市场红周刊(2018年3期)2018-05-14
软件导刊(2017年4期)2017-06-20
北方文学·中旬(2017年1期)2017-03-15
