
藏语方言语音合成数据集
2022-07-03 14:05仁曾卓玛朱丽平
中国科学数据(中英文网络版) 2022年2期
仁曾卓玛,朱丽平,2*
1.中央民族大学信息工程学院,北京 100081
2.国家语言资源监测与研究少数民族语言中心,北京 100081
引 言
随着科技快速发展,越来越多的智能产品进入人们的生活,在提供极大便利的同时,使人们的生活方式变得更加丰富[1]。语音合成,又称文语转换(Text to Speech,TTS)[2]技术,作为实现人机交互的重要方法,同样得到迅速发展,但目前在市面上却极少见到支持少数民族语言的语音合成技术产品。
藏族是人口较多的少数民族,拥有本民族的语言和文字。中国社会科学院民族语言调查组在对藏语言进行调查考察研究的基础上提出的卫藏方言、康区方言和安多方言的三分说[3]。目前大部分偏远藏区的基础教育薄弱,80%左右的藏族人只会听和说藏语而不识文字[4]。因此藏语音合成技术的发展对于藏族人民使用科技发展产物起到至关重要的作用。目前科大讯飞实现了藏语(拉萨话女声)语音合成,然而第六次人口普查数据[5]显示,约700万藏族人口中只有近45%的人属于西藏户籍,其余藏族人生活中并不使用拉萨语,所以该产品在实际使用中远远不能满足现实需求。
从近年发表的文献[6-8]中发现,当前西藏大学、青海师范大学、西北师范大学等高校师生在研究藏语语音合成问题时,研究者使用的数据集都是通过网上搜集文本数据,人工在设备上录音的方式完成的。这将会使研究者将大量时间和精力花在准备语料上,且由于条件有限,语料在质量上和数量上都有提升空间。文献[9]、[10]提供了藏语语音数据,但是数据量只有26MB和666段,且只有卫藏方言没有安多和康巴方言。
为提高语音合成数据集的创建效率,弥补藏语安多和康巴方言语音合成语料的不足,本研究从喜马拉雅FM听音软件里中国西藏网的“藏语播报”专辑,同时获取音频及对应文本创建藏语方言语音合成数据集,并从语言现象的覆盖率、三大方言的语音特征等方面对数据集的质量进行了分析评估。本数据集共8.02 GB,其中安多方言2.45 GB、康巴方言2.13 GB、卫藏方言3.34 GB,压缩后总数据集大小为4.3 GB,内容包含新闻、故事、法律、生活常识等,为藏语语音合成研究和藏语三大方言语音学研究提供数据支撑。
1 数据采集和处理方法
1.1 语料选择的标准和依据
语音合成语料选择的基本标准是音频内容清晰、发音纯正、音素需覆盖均衡,音素、音律要准确,文本数据的字词句和语法要准确。根据这一标准,通过大量查阅音频资料并对比研究发现,喜马拉雅FM听音APP里的“藏语播报”专辑适合作为语音合成语料。该专辑内容多包含了近几年国内的重要新闻、有趣的小故事、普及法律知识和生活常识等,且每个音频都有相对应的文本内容。同一个文本语料对应有安多、卫藏和康巴三种方言音频,均由专业的播音员使用专业的设备在专用的录音棚内录制,并由专业人员剪辑,通过层层审核而成的。音频相较于普通录音内容,在读音、断句、语法等的准确性和音频的清晰度及完整性是毋庸置疑的。
1.2 数据采集方法
采集的数据包括藏语三大方言音频数据及其对应的文本数据,根据录音及播报时间将音频及其对应文本数据均分为四部分。
1.2.1 文本数据
本研究通过Python3.8网络爬虫技术从喜马拉雅FM听音APP“藏语播报”专辑各音频播放界面爬取文本内容。每一篇文本保存三份,分别以安多、卫藏和康巴的拼音缩写和按音频播报顺序编号命名,例如,卫藏第三部分第一篇文本命名为“wz3-1.txt。由于第一部分前32个没有对应的康巴方言的音频,所以这部分文本只有两份,其余三个部分的文本均各有三份。
1.2.2 音频数据
直接从APP获取到的音频是xm格式的文件,该文件格式不属于音频文件,xm到wav的格式转换方法繁杂,且转换后的音频会受损。经尝试发现该音频可以通过Python网络爬虫技术爬取,但本研究采用了更简单的获取方法,用安卓手机点击下载即可获得高质量的音频内容。每个音频根据所属方言和序号重命名,例如,卫藏第三部分第一个音频“wz3-1”。
1.3 数据处理方法
1.3.1 文本数据的处理
将每一篇完整的纯文本文字内容,根据完整的语义断句,划分多个具有实际意义的短句。每个语义完整的句子前添加标签,如,卫藏第三部分第一篇第一句“wz3-1-1:”。
1.3.2 音频数据的处理
每一段待处理的音频为10分钟左右的完整录音,根据已切割好的文本短句对音频进行切割,得到各文本短句对应的音频语句。本研究主要使用了Adobe Audition软件和迅捷音频转换器完成音频切割。Adobe Audition软件简称Au,是由Adobe公司开发的一个专门的音频编辑和混合环境,能提供先进的音频剪辑、混合、控制和效果处理功能[11];迅捷音频转换器是一款功能丰富的音频格式处理软件,支持数多种不同的音频格式,速度快、批量操作效率高,同时涵盖音频转换、音频剪切、音频合并、音频提取、音频录制、音频变速等多种功能。音频切割以保证每个独立句子的语义完整性为原则,切割后的音频长度为0.1-20秒,其中0.3-5秒之间的最多,音频格式为wav。
2 数据样本描述
音频文件的采样率为44.1kHz,声道为双声道立体声。分为ad(安多)、kb(康巴)、wz(卫藏)三个音频文件夹,每个文件夹按音频录制时间分成4部分内容,ab和wz各有157段音频、kb有125段音频(缺第一部分的前32段音频),处理前的每段音频有7-15分钟。
图1为数据集结构及整体数据内容展示,切割后的音频长度为0.1-20秒,其中0.3-5秒之间的最多,音频格式为wav,文本格式为txt。
3 数据质量控制和评估
(1)字丁和语音现象覆盖均衡性评估
为评估创建的语音合成数据集是否覆盖藏语基本音素组合,本研究根据藏文独特音素及构字法,通过统计数据集中藏文字丁的占比,分析各方言的语音现象的覆盖率;通过以基字为分类标准,统计同一个基字的字数来分析语音现象覆盖的均衡性。
郭须·扎巴军奶教授用14年时间研究发现藏文字丁共有18531[12],萨迦·索南孜摩编著的《正确读字法注疏》中表示藏文字丁共18745在平常能接触到的有8000多(包括牧民、农民、寺庙、学校等的领域性常用字),去除特定领域的常用字,在日常生活和交流中常用的藏语字丁约3000左右。对语料进行机器统计并经过人工审核校对后发现,本数据集共有137946个字丁,其中卫藏68796个、安多41199个、康巴有27951个,去重后卫藏有2169个、安多有1864个、康巴有1743个字丁。去重后的字丁数在三种方言常用字丁中的占比分别为卫藏72%、安多62%、康巴58%,对日常交流使用的字丁覆盖率均超过50%,但由于数据集规模不够大,并未覆盖所有字丁,后续将通过持续更新数据内容,进一步提高语音现象的覆盖率。
根据文献[13-14]藏语三大方言的不同发音特征进行总结得到藏语三大方言元音音标和辅音音标,分别如表1和表2所示。
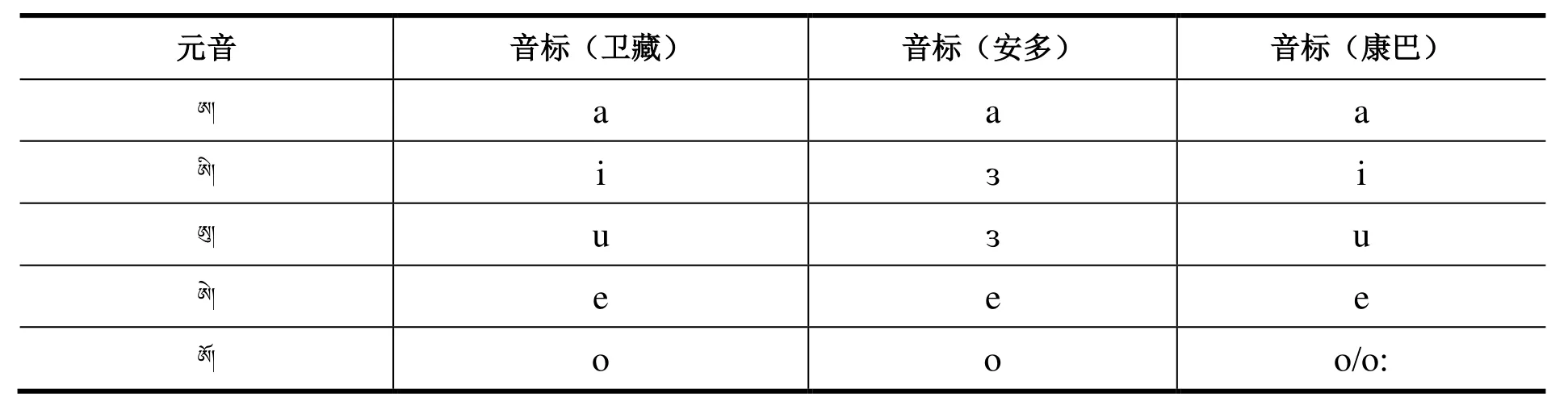
表1 藏语三大方言元音音标Table1 Vowel symbols in three Tibetan dialects
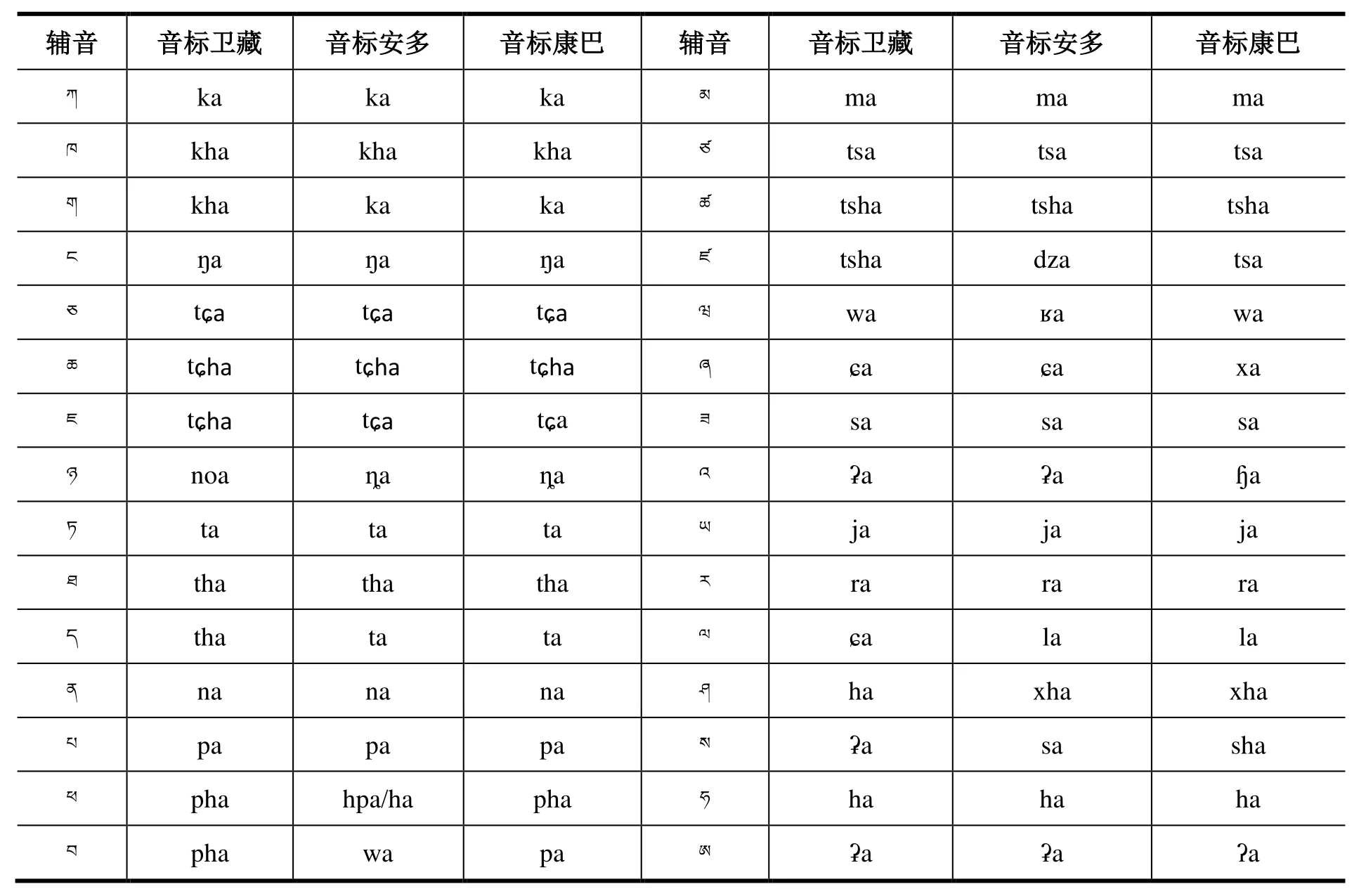
表2 藏语三大方言辅音音标Table2 Consonant symbols in three Tibetan dialects
图2为藏文字的音节结构,这是一个完整的藏文字丁,包含构字规则的所有结构,其中除了元音以外的加字和基字都属于辅音字母,发音顺序为前加字、上加字、基字、下加字、元音、后加字、再后加字,最终发出的音为整个字丁的音。
以表2中的辅音字母为基字,与加字、元音字母组合,采用机器分类结合人工审核校对方法对藏语三大方言语音现象均衡性进行统计分析,基字及每个基字在卫藏、安多和康巴数据集中出现的次数进行统计分析,结果如表3所示,单位(次)。

表3 语音现象均衡性分析Table 3 Equilibrium analysis of voice phenomena
表3中所有字丁被分为30类。以第3、11、15、13字母为基字的字数最多,而以第20、23、30、29字母为基字的字数较少,但这并不能说语音现象的均衡性不好,用藏文字的构字法分析后发现,第3、11、15、13等字数多的字母可以和上加字、下加字、前加字、后加字、后后加字组合,且基字与加字元音字组合就有更多的字丁,而20、23、30等字母很少有前加字、上加字、下加字的字丁,且日常生活中极少用。
综上所述,本数据集的语言特征覆盖率高,且语音现象覆盖均衡,在使用本数据进行藏语方言语音合成研究时,可减少因训练数据缺失或稀疏引起模型泛化性能较差等问题。
(2)文本内容专业性评估
数据来源为喜马拉雅FM听音APP“藏语播报”专辑内容,该内容转自中国西藏网,中国西藏网以中、英、藏、德、法5个文种向海内外网友介绍以西藏为主藏区信息的国家级重点新闻网站,是中国最大的涉藏专题综合性网站。所以本研究所用的文本在内容、结构及语法等方面均能够确保准确性和可靠性,且文本覆盖面广,涵盖日常生活、新闻、法律等各方面的内容。
(3)音频质量进行评估
本数据集的音频内容是由专业的播音员,在专业的设备上录制,并由专门的团队剪辑层层审核之后形成的,所以音频在发音、断句等的准确性以及语音的清晰度方面是毋庸置疑的。
(4)数据集创建人员评估
整个数据处理是由以藏语为母语的在校大学生和研究生完成,完成后的数据由相互审核完成初审核。初审核主要内容包括文本和音频校对、音频内容的完整性检查,修改有误标签、重新提取不完整的音频内容等,然后由专业人员做审核校对,最终得到可用于卫藏、安多和康巴方言合成语音的数据集。
4 数据价值
本数据集可用于卫藏、安多康巴藏语方言语音合成的训练集及测试集;同时可以根据其发音特点、停顿特点、韵律节奏特点[9]将其作为藏语三大方言语音学研究的语料库;结合机器翻译和人工审核方法,还可以将其拓展为藏语方言与其他语言之间的语音翻译数据集。
致 谢
感谢中国政法大学的戚肖克老师对数据集应用的建议,藏学研究院的贡保加同学文本语义断句方面的指导,感谢信息工程学院李宁同学在语音切割方面、郑怡扬同学在数据下载方面提供的指导。
本研究所使用的数据来源为,喜马拉雅FM听音软件里中国西藏网的“藏语播报”专辑,本数据只可用于科研相关内容,不可用于商业等其他交易内容。
数据作者分工职责
朱丽平(1970—),女,湖南省株洲市人,博士,教授,研究方向为语音翻译。主要承担工作:总体规划设计,数据集选择与采集指导,质量控制与协调管理。
仁曾卓玛(1995—),女,甘肃省甘南藏族自治州人,本科,中央民族大学硕士研究生,研究方向为语音处理。主要承担工作:卫藏第三四部分数据处理、安多第三四部分数据处理、康巴第三四部分数据处理。
加如(2000—),男,甘肃省甘南藏族自治州人,高中,中央民族大学本科生。主要承担工作:卫藏第一部分数据处理、安多第一部分数据处理。
次仁罗布(2000—),男,西藏自治区拉萨市人,高中,中央民族大学本科生。主要承担工作:卫藏第二部分数据处理、安多第二部分数据处理、康巴第二部分数据处理。
猜你喜欢
英语学习(2022年8期)2022-08-26
客联(2022年2期)2022-04-29
西藏研究(2021年1期)2021-06-09
家庭影院技术(2021年1期)2021-03-19
西藏艺术研究(2020年3期)2021-01-18
西藏艺术研究(2020年2期)2020-09-04
星星·诗歌原创(2020年3期)2020-04-27
瞭望东方周刊(2019年23期)2019-12-05
电子制作(2019年15期)2019-08-27
布达拉(2018年2期)2018-05-14
