
面向机器阅读理解的藏文数据集TibetanQA
2022-07-03 14:05孙媛旦正错刘思思赵小兵
中国科学数据(中英文网络版) 2022年2期
孙媛,旦正错,刘思思,赵小兵
1.中央民族大学信息工程学院,北京 100081
2.国家语言资源监测与研究少数民族语言中心,北京 100081
引 言
机器阅读理解是指机器根据给定的上下文回答相关问题。早期的机器阅读理解主要根据词汇和语义等信息,人工定制规则,从而计算材料中语句和问题的匹配度[1]。由于依赖人工制定的规则,其准确率仅有30%-40%,性能非常差。随着大规模数据集的应用,基于深度学习的机器阅读理解得以发展,其效果显著优于基于规则的机器阅读理解,因此,面向机器阅读理解任务数据集的创建也越来越受到业内人士的关注。到目前为止,在中英文领域,已经出现了很多大规模数据集。比如,文本开放域机器理解的挑战数据集MCTest[2]、基于监督学习的阅读理解语料CNN/Daily Mail[3]、机器阅读理解数据集SQuAD[4]、与MCTest同为选择题形式的机器阅读数据集RACE[5]、基于百度搜索和百度知道的大规模数据集DuReader[6]、基于识别不可回答的问题的数据集SQuADRUN[7]。随着这些大规模数据集的创建与应用,许多基于数据集的优秀模型相继被提出并在相关任务上取得不错的效果。最近研发的机器阅读理解系统,在斯坦福问答数据集SQuAD上可以产生优于人类理解水平的效果[7],这也代表着在优秀数据集的帮助下,机器阅读理解生成与人类理解水平相媲美的结果成为可能。
藏文作为一种低资源语言,相关公开的数据集非常少,在一定程度上阻碍了藏文信息处理的发展。大量实验表明,大规模的高质量数据集是推动数据驱动型任务的关键因素,因此,构建用于机器阅读理解的低资源语言数据集具有非常重要的价值。本文以云藏网的文本数据为基础,考虑问题类型、实际应用场景、疑问词使用方法等因素,结合藏文的语法特征、阅读理解模型的处理形式,构建了一个面向机器阅读理解的藏文数据集TibetanQA。
1 数据采集和处理方法
1.1 数据采集
本文的原始数据来源于云藏网(https://www.yongzin.com/),对获取的原始数据进行降噪处理,去除图片、表格等非文本数据,最终获得631篇文章。为了问题的多样性和有效性,舍弃小于100个音节的段落并去除不相关、不准确、残缺的数据后进行分词,最终得到903个段落作为问答对的文本数据,数据共划分为自然、文化、教育、地理、历史、生活、社会、艺术、技术、人物、科学、体育12大类。
1.2 数据处理方法
为了提高创建数据集的效率,我们开发了用于问题收集的web程序,如图1所示。并请20位藏语专业人员创建问题。
为了保证问题的统一性,我们根据《实用藏文文法教程》[8]中疑问代词的使用规则,总结了藏文与英文、中文在构建问题时的不同点,统一了提问者对疑问代词的使用习惯,从而进一步提高数据集的质量。比如,一般藏文有 5 个单一形式的疑问词(“ཅི”(What)、“ཇི”(How)、“ས”(Who)、“གང”(Which/Where)、“ནམ”(When)),其用法、意义和在文中的占比如表1所示。在实际问题创建过程中,单一疑问代词以与别的词素组成复合形式的疑问代词[8]出现。如表1所示,相对于英文,藏文中没有明确的地点疑问代词(Where)、指代疑问代词(Which),因此对于二者,这里规定一律使用泛指疑问词“གང”(Which/Where)来完成问题集的创建。
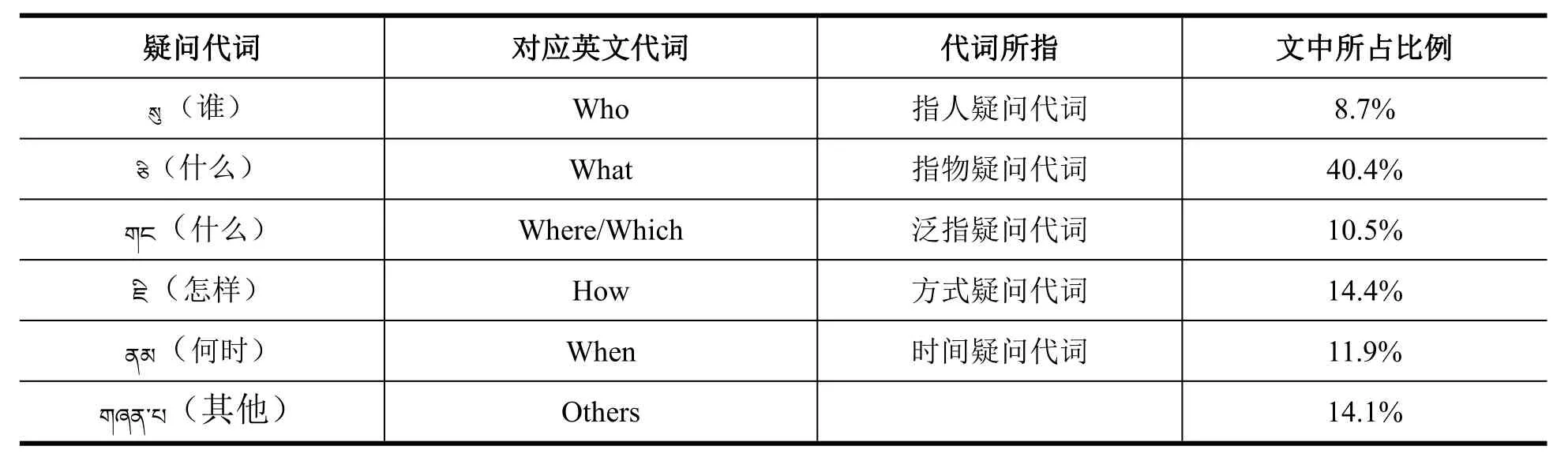
表1 藏文疑问代词及在数据集的分布Table 1 Tibetan interrogative pronouns and distribution in the dataset
最终,通过众包的形式从903个段落中创建问答对,即提问者遵循疑问代词的使用方法,通过阅读给定的标题、段落提出1-25个相关问题,并在对应的段落中选择连续的片段作为答案,组成问答对并提交到数据库。为了保证数据集的质量,我们对提出的问题进行三次校对,对内容进行了严格的筛选和处理,最终获得2,000对用于藏文机器阅读理解的问答对数据集,平均每段有2个问题,每个问题包含10-20个音节。
2 数据样本描述
本数据集包含一个命名为2000_TibetanQA的excel文件,在实际使用过程中,可以非常方便地将其转换成json、txt等格式的文件,以满足实验的数据格式要求。Excel文件中第一列为当前文章ID,第二列为文本标题,第三列为段落,第四列为问题,第五列为问题对应的答案。
数据集中,每一段文本均产生一对或一对以上的问答对,其中答案全部来自当前文本,如图2所示,用时间疑问代词“ནམ”(When)的复合形式“ནམ་ཞིག”(When)提出问题,这类问题占整个数据集的11.9%。
如图3所示,用泛指疑问代词“གང་”(Which/Where)提出问题,这类问题占整个数据集的10.5%。
如图4所示,用指人疑问代词“ས”(Who)提出问题,这类问题占整个数据集的8.7%。
如图 5 所示,用指物疑问代词“ཅི་”(What)的复合形式“ཅི་ཞིག་”(What)提出问题,这类问题占整个数据集的40.4%。
除了1.2节中提到的五个单一疑问代词和相关常用的复合疑问代词的用法之外,本次问题创建过程中,我们发现还有一部分常用的疑问代词较为常见,分别为“ག”(几)“གམ་ངམ་དམ་ནམ་་མ་མམ་འམ”(吗?)“ག་ཡཚད”(多少),在本次数据集中占14.1%,使用频率较高。其中,疑问助词中的“ནམ”(When)同时表示时间疑问代词,与表1中的When相对应。对疑问代词的总结归纳会使得我们后期的研究更具有针对性和高效性。
如图6所示,用疑问词“ག་ཡཚད”(多少)提出问题。
3 数据质量控制和评估
初始语料获取的过程中,首先使用正则匹配算法对原始文本进行去噪处理,针对网页文本杂乱无序、不规范等特点做进一步处理,将网页中的一些冗余标签替换成空白符,并删除网页文本数据中的一些无用字符,得到纯文本形式的原始文本。
同时,邀请了5位藏语专业人员对数据进行下一步筛选和审查,对于审核结果不达标的数据,进行重新编写或者将它们从数据库中删除。
在语法校对上,我们根据《实用藏文文法教程》[8]中提供的助词、格助词、从格助词等的使用规则,修改数据集的语法和拼写错误。例如,拼写错误有“ས་་་སང་”、“ག་ཡད”、“གངདག”等,其正确写法为“ས་་་་་ང་”(学习)、“ག་ཡཚད”(多少)、“གང་དག”(哪些);语法错误有“གང་བི་”“ས་གི་”等,其正确写法为“གང་གི་”(哪个)、“ས་་ི”(谁的);不符合藏文语境的有“གང་ྲ་་རིག་་”“ཅི་ཞིག་ྲ་་ཀ་ཁེྲ་”等,其正确写法为“ྲ་་རིག་་གང་དག་”(哪些职业)、“ྲ་་ཀ་ཅི་ཞིག་ཁེྲ་”(从事什么工作)。
在代词的使用上,我们将所有的代词替换为当前语句的主语。例如,“ཁ་ང་དདང་ྲ་་ག་ཡཚད་སེང་ས་་་ལེན་ན་་ས་་་མཐར་དིནམ”(他在几岁时大学毕业?),根据当前文本替换代词之后得到“དགེ་གན་ལེན་མ་་ཡ་་རིང་ཐར་དདང་ྲ་་ག་ཡཚད་སེང་ས་་་ལེན་ན་་ས་་་མཐར་དིནམ”(才让太教授在几岁时大学毕业?)。
最后,本文以藏文音节为单位统计了数据集中文章、段落、问题的平均长度和平均每段所包含的问题,如表2所示。

表2 数据集中文章和问题长度及平均每段的问题分布数Table 2 The length of articles and questions and the average number of questions in paragraphs
4 数据价值
藏文作为我国重要的少数民族文字,在西藏、青海、四川等藏族聚居地区被广泛使用。但是由于缺乏大规模公开的标记语料库,使得一些藏文信息处理任务还处于起步阶段,例如,藏文机器阅读理解任务[9]、藏文实体关系抽取[10]、藏文知识图谱的构建等任务。因此,本数据集的发布,对于促进藏文信息处理的发展具有重要的价值。本数据集可以用于评价机器理解自然语言的能力,也可用于训练藏文机器阅读理解的模型,具有较高的科研价值和社会应用价值。
致 谢
特别感谢参与本数据集工作的藏语专业人员。
数据作者分工职责
孙媛(1979—),女,山东省滨州市人,博士,教授,研究方向为自然语言处理。主要承担工作:数据质量控制与综合管理、数据采集。
旦正错(1998—),女,青海省海南州人,硕士研究生,研究方向为自然语言处理。主要承担工作:数据集的预处理和整合、数据校对、论文撰写。
刘思思(1998—),女,湖北随州人,硕士研究生,研究方向为自然语言处理。主要承担工作:数据采集、论文撰写。
赵小兵(1967—),女,内蒙古自治区呼和浩特市人,博士,教授,研究方向为自然语言处理。主要承担工作:数据集质量控制。
猜你喜欢
小学阅读指南·低年级版(2022年5期)2022-05-09
西藏研究(2021年1期)2021-06-09
疯狂英语·初中天地(2021年11期)2021-02-16
疯狂英语·初中天地(2021年12期)2021-02-12
小学阅读指南·低年级版(2020年9期)2020-10-12
布达拉(2020年3期)2020-04-13
学校教育研究(2020年3期)2020-02-18
阅读(快乐英语高年级)(2020年9期)2020-01-08
智能计算机与应用(2019年2期)2019-05-16
高中生·天天向上(2018年1期)2018-04-14
