
一种新闻类WORD格式文件数据抽取算法研究
2022-07-06 01:17张志强王伟钧张修军
成都大学学报(自然科学版) 2022年2期
张志强,王伟钧 ,张修军,施 达
(成都大学 计算机学院, 四川 成都 610106)
0 引 言
LexisNexis是著名的法律类、新闻报刊类及财务类商业信息数据库.从LexisNexis中产生的信息文件,如新闻类信息文件,多以WORD文件格式保存.由于有时需要对这些时事新闻信息进行搜索和数据分析,常用的方式是直接在WORD文件中进行新闻信息的人工检索和分析,但这种方式效率较低.为了提高信息检索和处理效率,本研究考虑首先从新闻类WORD文件中抽取新闻信息数据,构建新闻信息数据库,然后在数据库中进行数据快速检索和数据挖掘分析处理.
针对数据抽取技术,目前已有众多文献进行了相关研究.针对Web环境中网页数据特征,文献[1-4]结合大数据技术提出了利用XPath、改进的数据记录识别算法及计算相似度为依据的多种策略进行网页数据抽取操作;针对关系型数据库系统,文献[5-7]提出了利用Redo日志数据抽取模型、时间戳方式及深度学习的降维技术等多种策略进行数据抽取操作;针对Excel格式数据文件,文献[8]提出了一种利用Aspose.Cell插件进行数据抽取操作;文献[9]基于神经网络方法论述了神经网络事件抽取技术的发展方向;文献[10-11]探讨了基于知识图谱构建的知识抽取技术的发展方向,也提出了基于知识图谱技术的国内关键词抽取算法进行CNKI数据库抽取文献数据的操作;文献[12]分析了信息抽取技术在农业领域知识服务中的应用前景;文献[13]提出了一种从PDF文件中抽取表格数据的方法,通过该方法实现了数据从PDF文件导入数据库的过程;文献[14]提出了一种数值信息抽取算法,并将该算法应用于数据侵权追踪系统的设计和实现;文献[15]提出了一种基于医学文献命名实体识别算法模型,利用该算法模型对医学文献信息进行抽取,从而实现了医学文献标注管理功能;文献[16]利用正则表达式对公共文化服务机构的年报数据建立模板进行数据匹配和抽取操作,实现了多源数据环境下的年报数据集成工作;文献[17]提出了一种增量抽取数据算法,利用该算法实现了医院数据抽取到大数据平台的过程;文献[18]提出了一种基于哈工大语言技术平台和双向编码器的数据抽取方法,利用该方法实现了文本内容的抽取过程.
虽然以上众多文献对数据抽取技术进行了探讨,但由于从LexisNexis中产生的新闻类WORD文件格式不同于其他数据文件格式,已有的数据抽取技术不能用于这类数据文件.为此,本研究设计新的数据文件抽取算法,实现对这些新闻类WORD格式文件的数据抽取操作,从而为后期新闻信息数据的快速检索和数据挖掘分析提供基础数据源.
1 算法设计
新闻类WORD数据文件中新闻内容信息、新闻索引信息、甚至文件格式信息等往往混合在一起,使得在抽取数据时需要先解决非新闻内容信息的清洗问题.另外,新闻信息数据源往往会产生大量的信息数据文件来保存新闻信息.抽取数据时,为了提高批量数据文件读取的效率,也需要能自动快速读取多文件.为了解决以上问题,本研究设计了一种有效的新闻类WORD格式文件数据抽取算法,利用该算法实现非新闻内容信息的清洗及批量数据文件的快速自动抽取,并构建数据库.
1.1 新闻类WORD文件抽取策略
从LexisNexis数据库产生的新闻类WORD格式文件的内容包含总新闻索引信息和多篇新闻.新闻索引信息与新闻正文信息WORD格式分别如图1与图2所示,其中每篇新闻格式由新闻标题、新闻来源、获取新闻的时间、新闻内容长度(单词数)、新闻热点、新闻正文内容、新闻图片引源信息、新闻正文结束标记及新闻文章结束标记等构成.若要抽取文件中指定的多篇新闻信息数据,则需要先识别和清洗无用的信息数据.

图1 新闻索引信息WORD格式

图2 新闻正文信息WORD格式
根据WORD格式文件内容,算法设计的各部分信息识别关键词如表1所示.
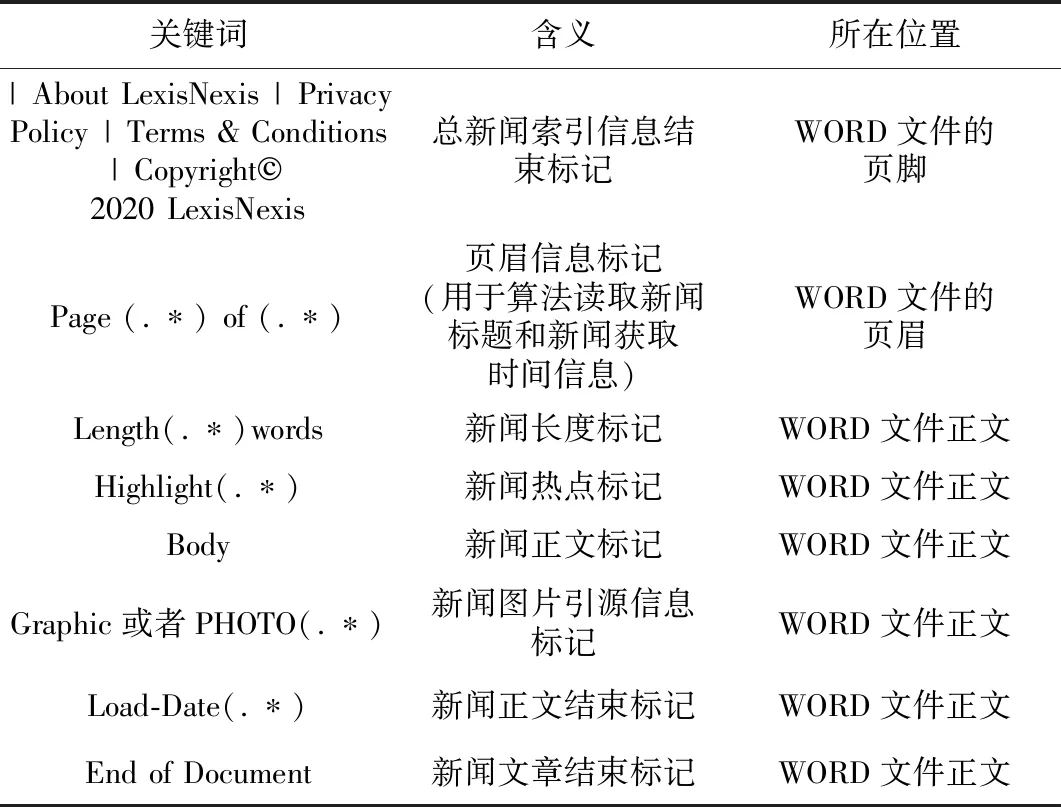
表1 算法设计的各部分信息识别关键词
表1中,页眉信息标记、新闻长度标记、新闻热点标记、新闻图片引源信息标记、新闻正文结束标记等会随着WORD文件中新闻信息的变化而变化.这些标记采用正则表达式表示,在算法中以正则表达式进行匹配搜索.
新闻类WORD文件抽取策略主要采用识别关键词的方式清洗非新闻内容信息数据和抽取新闻内容信息数据.具体的抽取策略如下:1)将WORD文件中的所有数据读取到设定的内存缓冲区,对缓冲区清洗空行数据,删除空行字符串;2)识别总新闻索引信息结束标记,清洗文件中的总新闻索引信息头,删除文件头到总新闻索引信息结束标记之间的字符数据;3)识别页眉信息标记,清洗页眉信息,删除页眉字符串,然后抽取新闻标题和获取新闻的时间数据;4)识别新闻长度标记,抽取新闻长度数据;5)识别新闻热点标记,抽取新闻热点数据;6)识别新闻正文标记,作为抽取新闻内容信息的起始位置来抽取新闻信息数据,直到识别到新闻图片引源信息标记或识别到新闻正文结束标记(有些新闻文章没有新闻图片引源信息标记)为止;7)识别新闻文章结束标记,结束1篇新闻信息数据的抽取操作,并将抽取的新闻标题信息、获取新闻的时间数据、新闻长度数据、新闻热点数据、新闻正文信息等组合成SQL语句,写入新闻信息数据库;8)转到3)继续抽取下篇新闻信息数据,直到缓冲区中的字符数据全部处理完为止.
新闻类WORD文件抽取策略如图3所示.

图3 新闻类WORD文件抽取策略
1.2 批量文件自动搜索读取策略
因为新闻类别的多样性和新闻获取时间的多点性,将有大量新闻类WORD格式文件从LexisNexis数据库中产生.为了提高数据抽取的效率,本研究需要考虑批量文件的自动搜索读取和数据抽取操作,为此设计了批量文件自动搜索读取策略.
该策略中,首先将需要抽取的批量新闻类WORD数据文件复制到指定的磁盘工作目录,根据新闻类别或新闻获取时间来构建该磁盘工作目录的子目录结构,再在子目录结构中放置各类新闻类WORD数据文件,获取该目录结构下所有的WORD文件地址信息,将每个WORD文件的地址信息(绝对路径名+文件名构成的字符串信息)写入XML文件缓保存.本研究采用XML文件缓保存的目的是为后期文件自动读取而提供批量文件地址信息.后期文件数据抽取操作如下:首先读取XML文件,将每个WORD文件的地址信息写入内存的列表变量中;然后依次遍历列表变量,每次遍历获取1个WORD文件的地址信息,根据1.1节的新闻类WORD文件抽取策略进行文件数据抽取操作,直到列表变量中所有文件地址信息遍历结束,则表明完成了批量文件自动搜索读取操作.整个批量文件自动搜索读取策略如图4所示.

图4 批量文件自动搜索读取策略
2 算法实现
本研究提出的算法实现的关键是批量文件自动搜索读取策略和WORD文件数据抽取策略.具体的算法代码结构如下:
Algorithm1 WORD_Data_extraction(filename_parameter,filename_xml)
参数说明:filename_ parameter: 工作环境配置参数文件名
filename_xml: 存储WORD文件地址信息的XML文件名
begin
从filename_ parameter文件中读取磁盘工作目录;
根据磁盘工作目录地址从磁盘中获取工作目录中所有
WORD文件的地址信息;
将WORD文件的地址信息写入filename_xml文件中;
从filename_ parameter文件中读取数据库参数;
根据数据库参数构建指定数据库;
从filename_xml文件中读取WORD文件地址信息,
并写入内存列表变量L;

end
3 实验测试
本研究采用Java实现Algorithm1算法,使用SQL Server 2008 R2设计数据库系统,利用Apache的POI框架3.17版本对WORD文件进行读写.测试环境为Windows7(64-bit),CPU为Intel core i5,内存为12 GB.实验测试的样本文件为从LexisNexis数据库产生的15个新闻类WORD文件,其分类如表2所示.从表2可知,将批量新闻类文件按照生成时间进行归类,每个样本文件包含多篇新闻,样本文件包含的新闻总篇数为2 210.
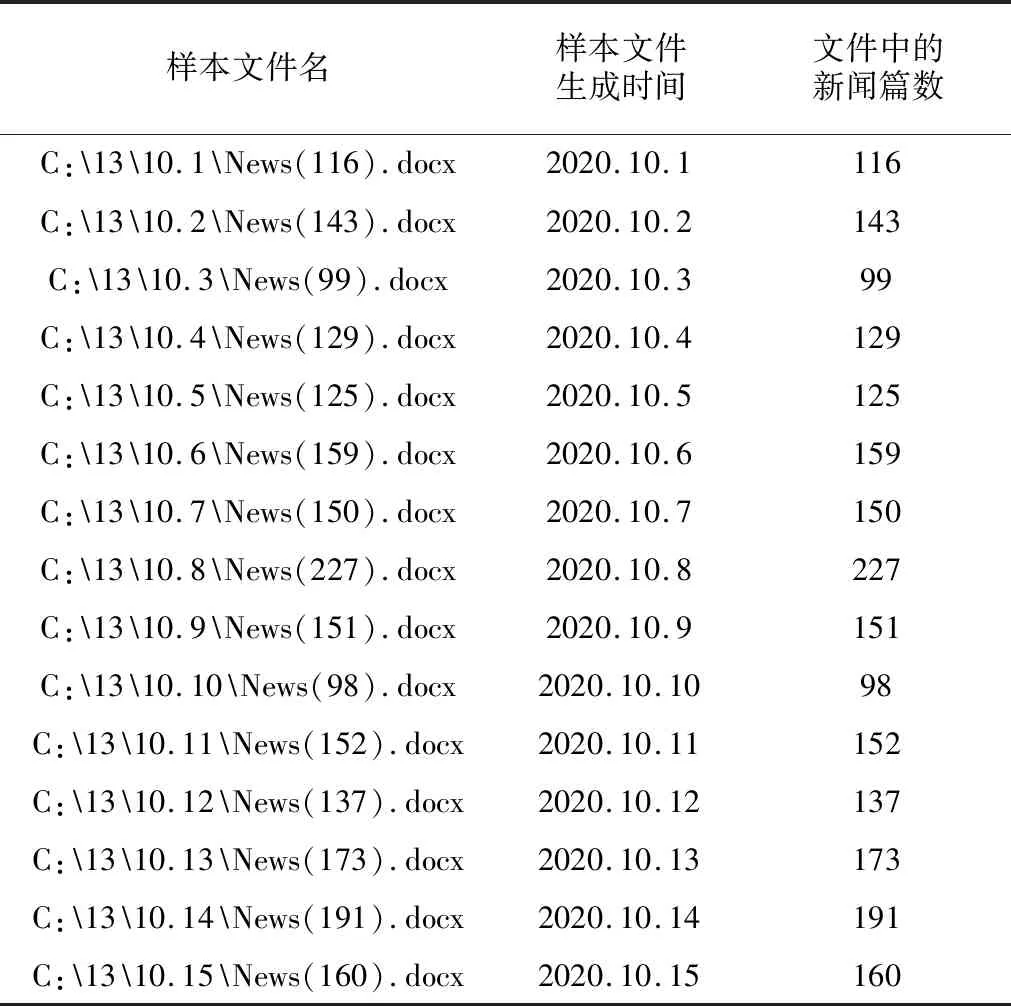
表2 样本文件分类表
算法运行的配置参数设置在XML文件中,文件内容如图5所示.

图5 算法运行的配置参数
从图5可知,“C:13”为设置的磁盘工作目录,“localhost”为算法访问的数据库服务器地址,“sa”为数据库服务器登录名,“cdu”为数据库服务器登录密码,“1433”为算法访问数据库服务器的端口号,“article_matching”为存储数据的数据库名.
算法产生的XML文件内容如图6所示.从图6可知,根据磁盘工作目录,算法自动搜索磁盘中的新闻类文件,并将这些文件的批量地址信息写入XML文件中保存,为算法后期数据抽取阶段提供批量文件数据源地址.

图6 算法产生的XML文件内容
表3为算法生成的新闻信息表.

表3 新闻信息表
算法对样本文件进行自动读取并抽取新闻数据,将抽取的新闻数据写入数据库“article_matching”的新闻信息表中.算法抽取新闻数据创建的数据表如图7所示.从图7可知,数据表包含2 210条记录数据.每条记录数据存储1篇新闻信息,其中article_id字段自动产生数据值.算法会根据每篇新闻文章信息进行抽取,并写入对应的title、date、length、highlight及articletext等字段中.

图7 算法抽取新闻数据创建的数据表
4 结 论
对新闻类WORD文件内容进行有效地数据抽取并构建数据库是后期提高数据检索和新闻数据分析操作效率的关键.本研究设计的数据抽取算法能有效地完成新闻类WORD文件内容的无用数据清洗和有用数据抽取操作,且能进行批量文件的自动读取和抽取操作并构建数据库,最终提高了数据抽取操作的效率.
猜你喜欢
速读·下旬(2021年11期)2021-10-12
云南画报(2021年6期)2021-07-28
科学家(2021年24期)2021-04-25
电脑爱好者(2020年5期)2020-05-11
大东方(2019年12期)2019-10-20
科学与财富(2017年22期)2017-09-10
商情(2017年1期)2017-03-22
财经(2017年2期)2017-03-10
财经(2016年15期)2016-06-03
财经(2016年3期)2016-03-07
