
基于FPGA 的虚拟听觉系统设计
2022-07-07 09:40陈鑫,高博,龚敏
电子与封装 2022年6期
陈 鑫,高 博,龚 敏
(1.微电子技术四川省重点实验室,成都 610064;2.四川大学物理学院,成都 610064)
1 引言
头相关传输函数(Head-Related Transfer Function,HRTF)由于包含着重要的声源定位信息,常被用来实现虚拟听觉。从信号处理的角度来看,使用HRTF 实现虚拟听觉的实质就是在频域上求HRTF 与输入音频信号的乘积[1]。但是,如果直接对输入音频信号进行频域乘积运算,需要连续进行傅里叶正逆变换才能获得最终结果;为了提高系统的实时性,人们常选择用数字滤波器来进行等价的时域卷积运算。FPGA 由于具有灵活性高、实时性好等优点,常被用来实现数字滤波器,被很多人选为虚拟听觉系统的实现平台。
丁林[2]设计了一个以4 阶级联型无限脉冲响应(Infinite Impulse Response,IIR)滤波器组为核心的虚拟听觉系统,通过降低滤波器阶数的方式减少了硬件资源消耗,但其设计仍使用了过多的乘法器资源。此外,由于这个系统采用的是传统的虚拟三维音频合成方式,因此还存在着垂直方向正确率低的问题。KUGLER 等人[3]采用对输入音频信号进行上采样和增加滤波器组通道数的方法来改进IIR 滤波器组,成功地提高了虚拟听觉系统的平均正确率,但这同时也增大了乘法器的资源消耗。SINGHANI 等人[4]设计了一个以有限脉冲响应(Finite Impulse Response,FIR)滤波器组为核心的虚拟听觉系统,通过把FIR 滤波器改进为折叠型结构,将乘法器的使用量减少到8 个,但是依旧忽视了系统垂直方向正确率低的问题。
本文提出了一种基于输出声音响度来辨别垂直方向的方法,并设计了一个折叠型FIR 滤波器,在此基础上构建了一个基于FPGA 的虚拟听觉系统。
2 虚拟听觉的基本原理
在自由场中,声波从声源到双耳的传输过程可以看作一个线性时不变的声滤波系统,这个系统的传输函数就是HRTF[5]。HRTF 的时域形式被称为头相关脉冲响应(Head-Related Impulse Response,HRIR),与HRTF 互为傅里叶变换对。本文采用的耳间极坐标系如图1 所示[6],该坐标系使用方位角和仰角来确定一个声源的方向。方位角θ 定义为声源矢量P 和双耳中垂面的夹角,取值范围为-90°~90°;仰角φ 定义为P0和水平面前半部分的夹角,取值范围为-90°~270°。在主观听音实验中,为了减小受试者辨别声源方位的难度,大多数工作[1-4]都选择只对水平面和双耳中垂面上的方向进行测试。其中,水平面上的方向被称为水平方向,双耳中垂面上的方向则被称为垂直方向。
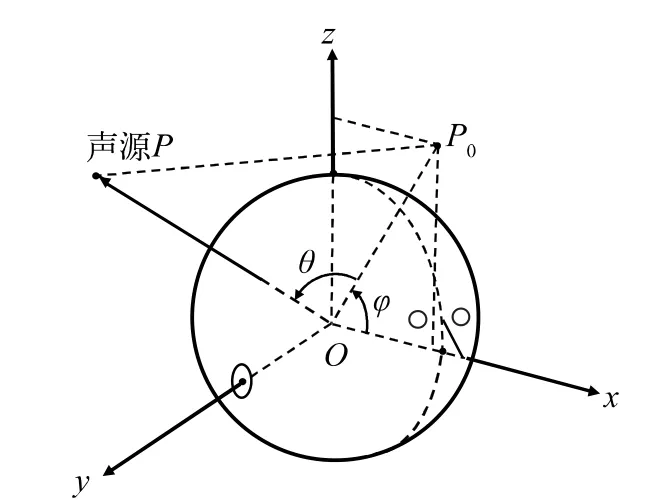
图1 耳间极坐标系
在设计数字滤波器时,一般采用HRIR 数据作为滤波器的系数。本文所使用的HRIR 数据来源于CIPIC 数据库[6],这个数据库包含43 个成人和2 个KEMAR 人体模型的HRIR 测量数据。对于一个受试者,测试人员会对其在25 个方位角和50 个仰角上的HRIR 进行测量,再加上左右耳的HRIR 一般是不同的,因此每个受试者都会有2500 组HRIR 数据[6]。HRIR 数据的采样频率为44.1 kHz,采样点数为200个,使用高精度的浮点数进行表示。本文最后选择用KEMAR 人体模型的HRIR 数据作为FIR 滤波器的系数,这可以有效减小由于没有使用个体化的HRIR 数据所带来的系统定位误差[7]。此外,考虑到耳机等音频播放设备一般只有两个输出通道,因此本文采用一个两通道的FIR 滤波器组来进行数据处理。
3 虚拟听觉系统设计
3.1 系统设计思路
为了减小量化误差,本文将FIR 滤波器的系数数据与输入音频数据都量化为补码表示的16 位定点数。如前所述,KEMAR 人体模型共有2500 组HRIR 数据。为减小存储系数数据所需的内存空间,此处选择对仰角进行间隔采样,将HRIR 数据的数量先减少一半。在进行定点量化后,每组HRIR 数据都会转化为200 个16 位补码,也就是400 B 的数据。那么,1250 组HRIR 数据在量化后就是大约488 kB 的数据,使用512 kB 的SRAM 可以装下它们。在对仰角进行间隔采样后,方位角和仰角都只有25 个角度值;然后按照角度值从小到大的顺序,使用自然数对方位角和仰角分别进行编号,并将方位角编号和仰角编号分别记为Iaz和Iel,二者的取值范围均为0~24。
研究表明,在主观听音实验中,受试者对垂直方向上的声源进行辨别时,正确率要明显低很多,会出现声源定位上下颠倒和前后混淆的现象[1,8]。在经过多次实验后,发现造成这种现象的主要原因是垂直方向上的声源在两耳之间产生的双耳时间差十分接近,并且耳机输出声音响度在不同垂直方向上的差异非常小,导致受试者很难进行区分。为了解决这个问题,本文提出了一种基于输出声音响度来辨别垂直方向的方法。FIR 滤波器组的响度因子kL的表达式为:

其中,α 是仰角编号为0 时的响度因子;β 是仰角编号的总数,这里取值为25。在进行系统测试时发现,当α大于4 或小于2 时,系统的虚拟听觉效果都会变差,因此本文选择将α 设为3。将FIR 滤波器的系统差分方程y(n)乘以kL,得到修订后的系统差分方程y′(n)。
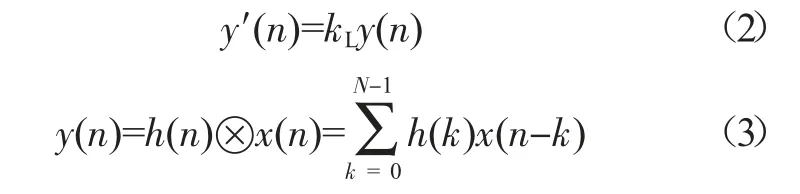
其中,x(n)是滤波器输入数据,h(k)是滤波器系数,N 是滤波器抽头数。
对于垂直方向而言,其方位角是相同的(θ=0°),只有仰角存在差异;当仰角编号从0 增大到24 时,表示声源方位逐渐由下方移动到前方,再经过上方和后方,最后回到下方[6]。与此同时,响度因子kL会变得越来越小,导致耳机输出声音的响度同样也会变小。因此,不同垂直方向的输出声音响度是不同的,受试者可以根据输出声音响度来区分不同的垂直方向,从而有效提高系统的垂直方向正确率。
3.2 系统的总体架构
虚拟听觉系统的总体架构如图2 所示,主要可分为上位机端和FPGA 端两部分。上位机通过通用异步收发传输器(Universal Asynchronous Receiver/Transmitter,UART)串口与FPGA 进行通信,在它上面有1 个用QT 开发的上位机软件。这个上位机软件主要用于产生由仰角编号与方位角编号组成的定位信号,以及将所有的滤波器系数从上位机端发送到FPGA 端。FPGA 端主要包含FIR 滤波器组、系数更新器、UART 接口和音频编解码器驱动等模块。其中FIR滤波器组由两个FIR 滤波器组成,用于输入音频信号进行滤波处理;而系数更新器则是定位信号的处理单元,用于对FIR 滤波器组的系数和响度因子进行更新。
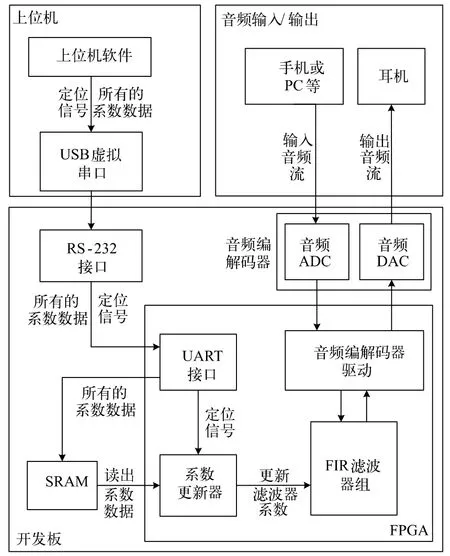
图2 虚拟听觉系统的总体架构
在系统进行初始化前,需要先使用上位机软件将所有的系数数据通过UART 串口发送到FPGA 端,并预先存储到一个512 kB 的SRAM 中。当上位机软件发出新的定位信号时,系数更新器会执行两个操作:一是根据仰角信号更新FIR 滤波器组的响度因子,以调节耳机输出声音的响度;二是根据定位信号对SRAM进行寻址,从SRAM 中读取出所需的系数数据,并用这些系数数据对FIR 滤波器组的系数进行更新。由于滤波器的传输函数与滤波器系数相对应,因此更新滤波器组的系数就能够更改定位方向。
系统正常工作时,由手机或PC 等音频播放设备产生的模拟音频信号(输入音频流)会通过3.5 mm 音频线传输到FPGA 端。FPGA 端的音频ADC 会将输入音频流转换为数字音频信号,再通过FIR 滤波器组完成滤波处理。音频DAC 会将FIR 滤波器组的输出还原为模拟音频信号(即输出音频流),并用耳机进行重放。一般来说,系统的输入音频流是单声道音频信号,即左右声道信号完全一样的音频信号。在经过滤波处理后,输出音频流的左右声道信号会产生差异,受试者可以根据这种差异来辨别声源方向[9]。
3.3 FIR 滤波器设计
FIR 滤波器的滤波功能是通过一系列乘法运算和加法运算来实现的,因此可以用乘累加器(Multiply Accumulator,MAC)来实现FIR 滤波器。如果FIR 滤波器采用传统的直接型结构,要实现199 阶的FIR 滤波器需要200 个MAC,这将占用过多的乘法器资源。为了减少滤波器的乘法器资源消耗,此处将FIR 滤波器改进为折叠型结构。改进后的FIR 滤波器采用一个数据RAM 来缓存最新的200 个输入音频数据,通过对MAC 进行时分复用,只使用1 个MAC 来完成200 次乘累加运算。折叠型FIR 滤波器的结构如图3 所示,主要由FIR 控制器、数据RAM、MAC、响度因子乘法器和系数交替缓冲器组成。其中,FIR 控制器是滤波器的控制单元,它采用滑动对齐机制来实现系数数据与音频数据的对齐。数据RAM 是一个深度为200 位、位宽为16 位的RAM,最多可以存储200 个音频数据。MAC 是滤波器的运算单元,用于完成系数数据与音频数据的乘累加运算。响度因子乘法器是1 个16 位的乘法器,用于完成MAC 输出结果与响度因子的乘法运算。系数交替缓冲器主要由2 个系数RAM 组成,用于对系数数据进行交替缓存。这两个系数RAM 都是深度为200 位、位宽为16 位的RAM,最多可以存储200 个系数数据。当系数更新器对FIR 滤波器的系数进行更新操作时,它会先将新的系数数据写入空闲的系数RAM;然后在系数写入操作完成后,再让FIR 控制器读取空闲的系数RAM。
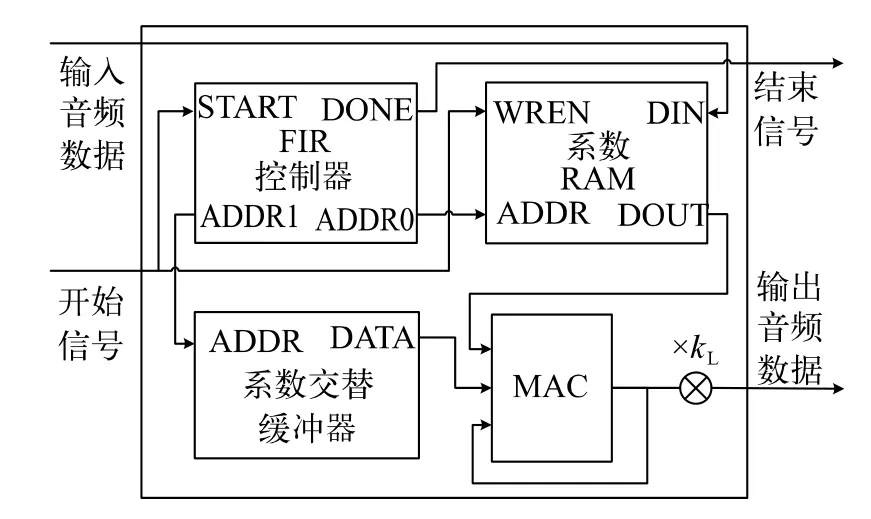
图3 折叠型FIR 滤波器的结构
3.4 滑动对齐机制
FIR 滤波器采用滑动对齐机制来实现系数数据与音频数据的对齐。在FIR 控制器中有两个计数器,分别为计数器0 和计数器1。计数器0 用于产生数据RAM 的写地址,而计数器1 则用于产生数据RAM 和系数RAM 的读地址。图4 为滑动对齐机制的示意图,此处假设FIR 滤波器正在进行第i 次滤波处理,而j是i 除以200 的余数。
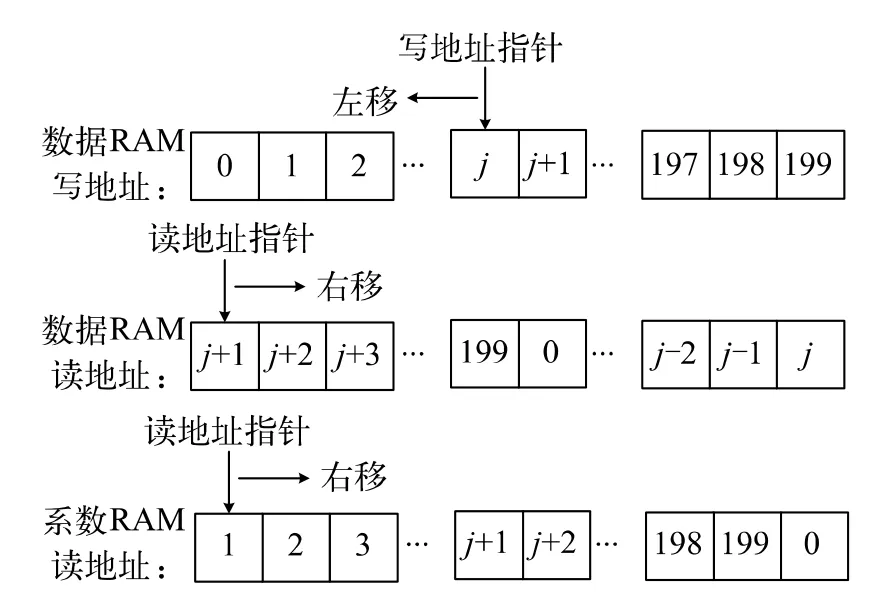
图4 滑动对齐机制
在最开始,滤波器会先将最新的1 个音频数据写入到数据RAM 的地址j 处,替换掉数据RAM 中最旧的那个音频数据。然后,滤波器会让数据RAM 的读地址指针指向地址j+1 处,并让系数RAM 的读地址指针指向地址1 处,以实现系数数据与音频数据的对齐。在这种对齐机制下,系数RAM 的读起始地址是不变的,而数据RAM 的读起始地址会不断往右滑动,因此这种对齐机制被形象地称为“滑动对齐机制”。
接着,滤波器会让数据RAM 和系数RAM 的读地址指针一起逐渐右移,从数据RAM 和系数RAM 中逐对地读出音频数据和系数数据,并进行乘累加运算。当两个读地址指针到达数据RAM 或系数RAM 的最右侧时,都会以环形方式绕回到它们的最左侧。FIR 滤波器每完成一次滤波处理,都需要进行200 次这样的乘累加运算,最后可以得到1 个新的16 位输出数据。
4 FPGA 上板验证
在进行FPGA 上板验证时,本文选用的FPGA 器件是Altera Cyclone II EP2C35F672C6N。为了测试虚拟听觉系统的性能,本文选取了10 位受试者来进行主观听音实验。在主观听音实验中,受试者们需要对来自10 个不同方向的声音进行方位辨别。这10 个方向可以分为水平方向和垂直方向两类,其(θ,φ)坐标分别为(-80°,0°)、(80°,0°)、(-45°,0°)、(45°,0°)、(-45°,180°)、(45°,180°)、(0°,0°)、(0°,180°)、(0°,90°)、(0°,-45°)。在进行实验数据统计时,平均正确率为:

其中,AH是水平方向正确率,AV是垂直方向正确率。
实验在一个相对安静的房间里进行,每位受试者需要参与20 次测试,每个方向的声音都会出现2 次,但出现的顺序是随机的。在一次测试中,受试者需要戴上头戴式耳机,听一段时长为5 s 的音乐片段,然后在纸上记下自己感觉到的声源方向。为避免测试选用的音乐片段对测试结果产生影响,整个实验都采用同一段单声道的纯音乐片段来作为原始音频。在实验开始前,受试者们需要先对原始音频进行试听,以确保原始音频本身没有方向感,并在不知道声源方位的情况下试听一组测试音频,以熟悉声音的方位感。
经过实验和数据统计,表1 给出了不同系统的关键参数。本设计在主观听音实验中取得了78.8%的垂直方向正确率和76.9%的平均正确率,均高于文献[2,4]的正确率。这主要得益于本设计采用了基于输出声音响度来辨别垂直方向的方法,有效地解决了系统垂直方向正确率低的问题。此外,本设计的乘法器使用量仅为4个,相比于文献[2]减小了93.75%,相比于文献[4]减小了50%。这主要得益于本设计采用了折叠型FIR 滤波器作为系统的核心数据处理单元,同时减小了滤波器组的通道数。
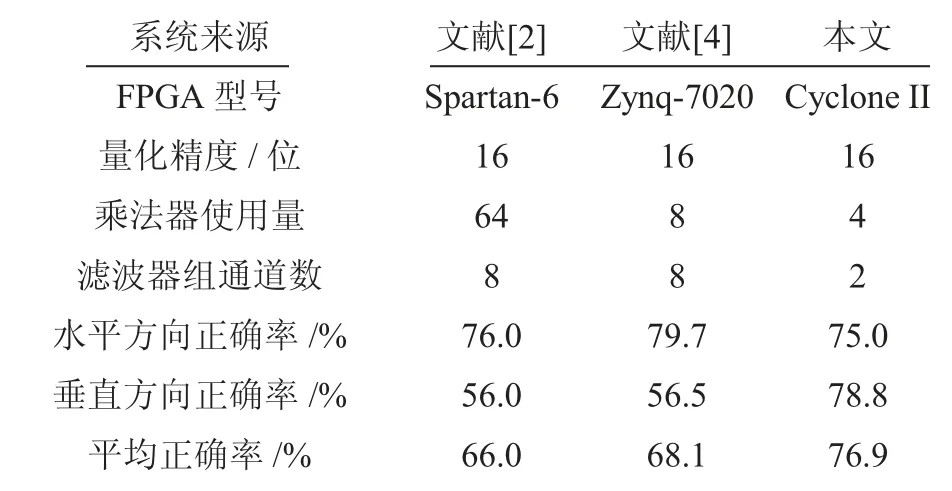
表1 不同系统的关键参数
值得注意的是,文献[4]没有直接给出虚拟听觉系统的3 种正确率,而只给出了对应的角度误差平均值和标准差,但这两者之间存在着某种转换关系[10]。本文采用逐步回归分析方法来获取转换公式,在对本文的实验数据进行逐步回归分析后,得到的转换公式为:
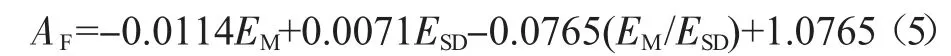
其中,AF是某种正确率,EM是角度误差平均值,ESD是角度误差标准差。文献[4]一共进行了3 项测试,由测试2 和测试3 的结果可以分别计算出水平方向正确率和平均正确率,垂直方向正确率则可通过式(4)求得。
5 结论
本文构建了一个基于FPGA 的虚拟听觉系统,该系统很好地实现了虚拟听觉功能,并具有以下两个优点:一是通过把FIR 滤波器改进为折叠结构以及减小滤波器组的通道数,进一步减少了乘法器资源消耗;二是提出了一种基于输出声音响度来辨别垂直方向的方法,有效提高了系统的平均正确率。FPGA 上板验证结果表明,该系统将乘法器的使用量减少到了4 个,并在主观听音实验中取得了76.9%的平均正确率。由于只用很少的硬件资源就能实现该系统,在后续工作中可以考虑将该系统定制为一个小型化的芯片,并将其制作成一个电池供电的便携式设备。
猜你喜欢
客联(2022年4期)2022-07-06
成都信息工程大学学报(2022年2期)2022-06-14
无线互联科技(2022年2期)2022-04-20
初中生世界·九年级(2020年2期)2020-04-10
科技传播(2018年5期)2018-04-07
演艺科技(2017年8期)2017-09-25
中学生数理化·八年级物理人教版(2016年8期)2016-12-24
科技视界(2016年15期)2016-06-30
智能计算机与应用(2016年1期)2016-03-02
红领巾·成长(2009年8期)2009-01-12
