
医学博士英语听力测验题目分析与认知诊断研究
2022-07-14 07:16张泉慧
考试研究 2022年4期
张泉慧 张 颖 冯 攀
全国医学博士外语统一考试是根据国务院学位委员会颁发的《临床医学专业学位试行办法》和《口腔医学专业学位试行办法》,为医学博士研究生招生单位提供服务而设置的考试。考试包括英语、日语、俄语三个类别,旨在考查考生掌握和运用外语的实际能力,保证医学博士学位的授予质量[1]。考试自2002 年起实施,2018 年修订考试大纲,2019 年正式实施新的考试大纲。新大纲更加注重考查学生的外语应用能力和交际能力,要求考生在听、说、读、写的应用方面加强训练。因此,本研究试图通过对考试数据的分析,了解大纲修订后听力理解题目结构变化对考生作答的影响,分析考生在听力属性上的掌握情况变化。
以往,对于考试的研究分析主要集中在经典测验理论的难度、区分度等指标的评价上。这些指标较为笼统,对于试题开发和考生个人的指导作用相对有限。相比而言,项目反应理论在参数估计方面表现更稳定,能提供更多有价值的题目信息,本研究在对比大纲修订前后题目参数变化时,主要采用项目反应理论进行分析。以往的考试很少探查到考生作答背后所涉及的认知心理加工过程及属性表现。随着认知诊断这一测验新理论的出现,认知水平与能力评估建立了更密切的关系,从题目反应获得更细致的属性评价成为可能,向考生个人提供更有效的分数解释得以实现,这使得认知诊断研究成为近年来的热点。本研究试图通过认知诊断模型探讨题目考查属性的变化和考生的属性掌握情况。
当前认知诊断应用的模型已超过六十种,主要分为两类:一类是多成分潜在特质模型,即通过考生作答反应分析其具备的潜在特质,如线性逻辑斯蒂克特质模型、多成分潜在特质模型以及多维项目反应理论下的一系列模型;另一类是潜在分类模型,即按照考生的得分模式找到潜在特质上质的差异并据此分类,如Tatsuoka 等提出的规则空间模型、新发展起来的融合模型、统一模型、DINA 模型、G-DINA 模型等。其中,G-DINA 模型是当前使用较为广泛的一种认知模型,由de la Torre[2]提出,该模型假设相对宽松,认为试题各认知属性对试题答对概率有着不同的贡献比例,掌握部分认知属性的被试也有一定的答对概率,具有补偿性、饱和性特征。一些国内研究者认为,G-DINA 模型的补偿性特征契合了语言测验的综合性和多元性,饱和性特征则比较理想地应对了语言属性的抽象性和难区分性,因此对语言测验的多元性和抽象性特征有较高的适应度[3,4]。
从近些年的文献来看,国内已有一些研究者对该模型进行了探索与研究:吴婷使用G-DINA 模型对九年级学生进行数学学科中“圆认识”专题的诊断分析[5];胡泊、泰中华以2019 年英语专八阅读选择题为例,应用G-DINA 模型进行实证研究[6];王磊等基于G-DINA 模型分析高中数学测验[7];董艳云等对比分析了Mixed-CDMs 与G-DINA 模型在英语听力诊断测评中的应用[8];刘欢在小学五年级阅读能力测评中采用五种认知诊断模型(含G-DINA)进行研究[9];肖云南使用G-DINA 模型对大学英语分级测试听力理解做了认知诊断研究[3];孟亚茹应用G-DINA 模型对大学生听力能力进行诊断[11];陈慧麟、陈劲松分别应用G-DINA 模型的补偿模型及饱和模型对PISA阅读测试进行了认知诊断[4]。但总体来看,G-DINA应用于语言测试领域的相关研究仍较为有限,涉及听力理解的认知诊断数量较少,研究更多停留在分析探讨阶段,运用到实际考试反馈中的不多。
基于此,本研究采用IRT 估计试题参数,对比考试大纲修订前后题目参数的变化;采用G-DINA 模型进行认知诊断,分析考生听力属性考查点的变化与考生属性掌握情况的变化,探讨具体原因,最后形成考生个性化分数报告模板,尝试为后续反馈试题命制、促进教学、帮助考生了解自身潜质与不足起到参考作用。
一、研究对象与方法
(一)研究对象
2018 年与2019 年全国医学博士英语统一考试听力理解测验,测验长度30题,作答时间30分钟,内容对比如表1所示:

表1 听力理解测验内容结构
(二)研究方法
根据两个年度的测验,描述考生构成及成绩,采用IRT 估计试题参数,划分听力属性,使用探索性结构方程模型分析数据与模型拟合度,最后应用G-DINA模型进行认知诊断。
具体方法如下:应用Visual Foxpro9.0 自编程序描述考生构成及成绩。采用R 软件包,估计IRT 试题参数。认知诊断时,根据以往文献中有关听力属性的划分,请相关专家逐题标注题目属性;采用MPLUS.7 软件中的探索性结构方程模型分析数据,根据标准化残差均方根(Standardized Root Mean square Residual,SRMR)、近似均方根误差(Root Mean Square Error of Approximation,RMSEA)、相对拟 合 指 数(Comparative Fit Index,CFI;Tucker-Lewis Index,TLI)等相关指标分析数据与模型的拟合程度;最后选择G-DINA 模型进行认知诊断,了解考生在不同听力能力属性上的掌握情况,模型计算公式如下:

其中,考生完成试题j时被细分为个潜在类别组,代表题目j所需的属性;P() 代表考生对试题j的答对概率,δj0是猜测答对概率,即不具备任何认知属性时的答对概率;δjk是掌握单一的认知属性αlk时对答对概率的影响;δjkk′是指认知属性αlk和αlk′的掌握对答对概率的交互性作用;δj2...k*是全部认知属性的掌握对答对概率的交互性作用。
二、研究结果
(一)考生构成及成绩描述
如表2 所示,两个年度考生年龄集中在30-40岁,比例接近60%;考生男女比例接近,各自约占一半;学历构成中,硕士研究生比例最高,两个年度占比都在90%左右。

表2 考生背景构成
如表3 所示,2019 年考生人数增加,平均分和试卷信度均高于2018 年,显著性检验P <0.01,具有统计学意义。

表3 考生成绩描述
(二)IRT参数估计
IRT 包括单参数、双参数和三参数模型,三个模型下的参数估计结果显示:题目参数良好,其中三参数模型数据与模型拟合更优,拟合度指标——残差均方(Mean-square,MNSQ)为1.005(单参数模型为1.012,双参数模型为1.009),理想拟合情况下的MNSQ 值为1,MNSQ 值在0.5-1.5 之间表示数据与模型预期拟合程度可接受,三参数拟合度最接近1,拟合更好;参数估计标准误数值为0.03(单参数模型为0.04,双参数模型为0.06),误差最小。
IRT 理论中,难度b数值越大,难度越大;区分度a数值越大,题目区分度越大。和2018 年相比,2019年听力测验平均难度降低,整体区分度提高,题目猜测度接近。2019 年试卷总信息量高于2018 年,测量误差更小,测量精度和稳定性更好。具体结果如表4所示:

表4 两个年度听力理解测验题目参数
(三)认知属性的构建与验证
研究参照以往第二语言测试中听力理解相关文献研究的结果,结合博士英语听力理解考试的题型结构,并与命题专家讨论,初步确定了该考试中涉及的七个认知属性A1~A7(通过与专家的讨论,并参考已有文献,假设属性之间没有固定的层级关系),分别为:
➢A1 理解词语与词组
➢A2 理解句子及结构
➢A3 定位事实和细节
➢A4 识别语境
➢A5 总结与概括
➢A6 推理
➢A7 选择性注意
如表5 所示,这些认知属性主要划分为两个层面,语言知识和理解策略;两者之间相互并行,考生作答时可同时使用不同层面的认知属性。
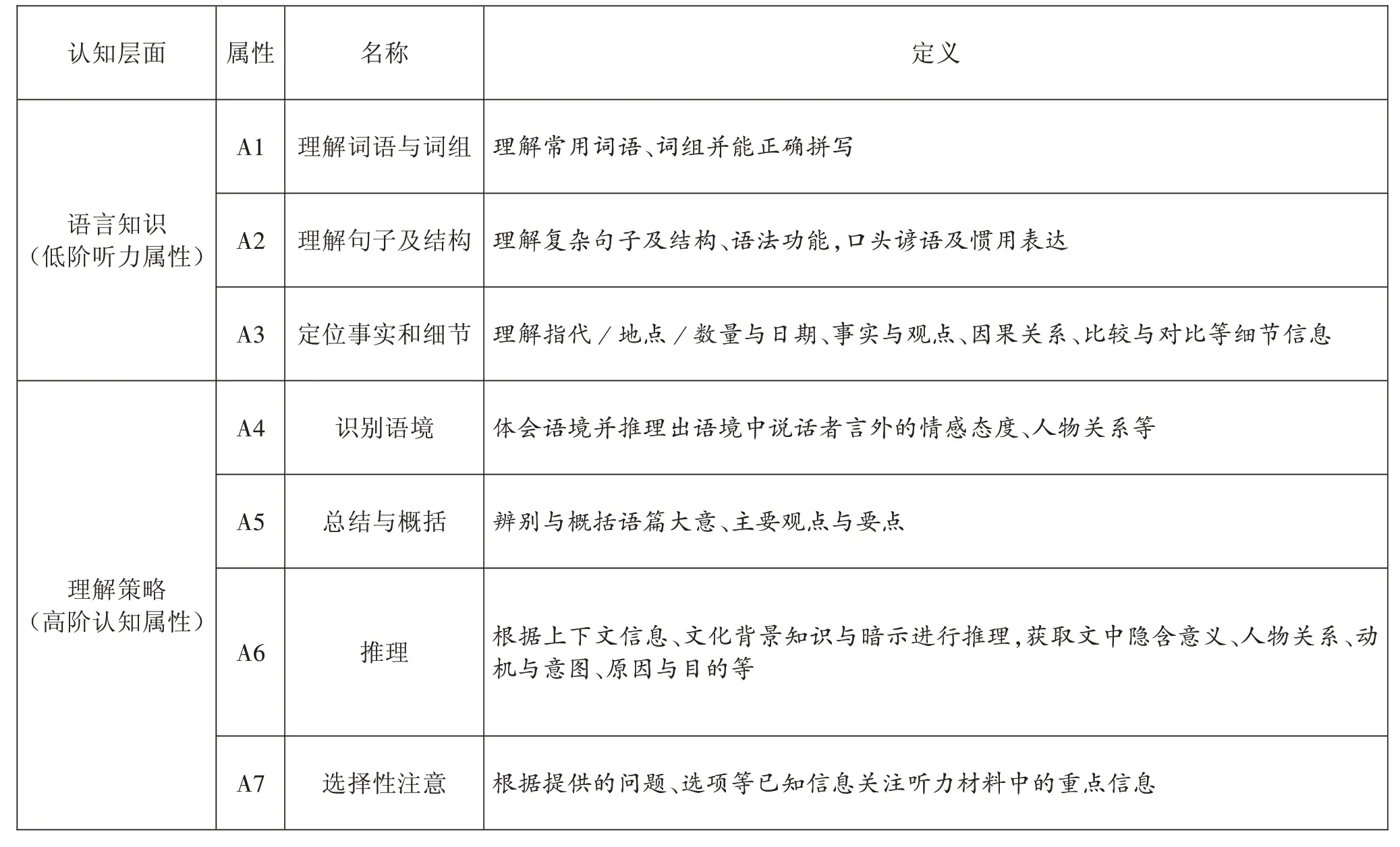
表5 听力认知属性界定
根据表5 听力属性划分,研究标注并对比了两个年度中每道听力试题所涉及的属性,表6 为题目标注情况,考查到的属性标注1,未考查的属性标注为0,一道题目可以只考查一项属性,也可以同时考查多个属性。

表6 听力理解的认知属性Q矩阵
表7 显示了模型与数据的拟合情况。一般来说,相对拟合指数(CFI、TLI)大于0.90,说明数据与模型拟合良好;标准化残差均方根(SRMR)、近似均方根误差(RMSEA)的结果越小,代表模型对参数的估计越接近真值,两个年度TLI、CFI 都在0.9 以上,SRMR、RMSEA 数值小,均低于0.01,可知两个年度的拟合情况都良好,模型与数据是匹配的。

表7 模型拟合情况
表8 显示了两个年度听力题目中属性考查的频次,可以看出两个年度考查的属性总频次是接近的,2019年考查的属性略多;在前三项听力属性中,2018年比2019年考查的频次更多,在后四项听力属性中,2019 年比2018 年考查的频次更多。可以看出,2019年更多地测试了“理解策略”方面的高阶听力属性。

表8 两个年度听力测验属性考查频次
表9 所示为两个年度考生在各认知属性上的掌握情况,2019 年考生在“语言知识”的掌握情况上略低于2018 年,但在“理解策略”方面的掌握情况明显好于2018年。
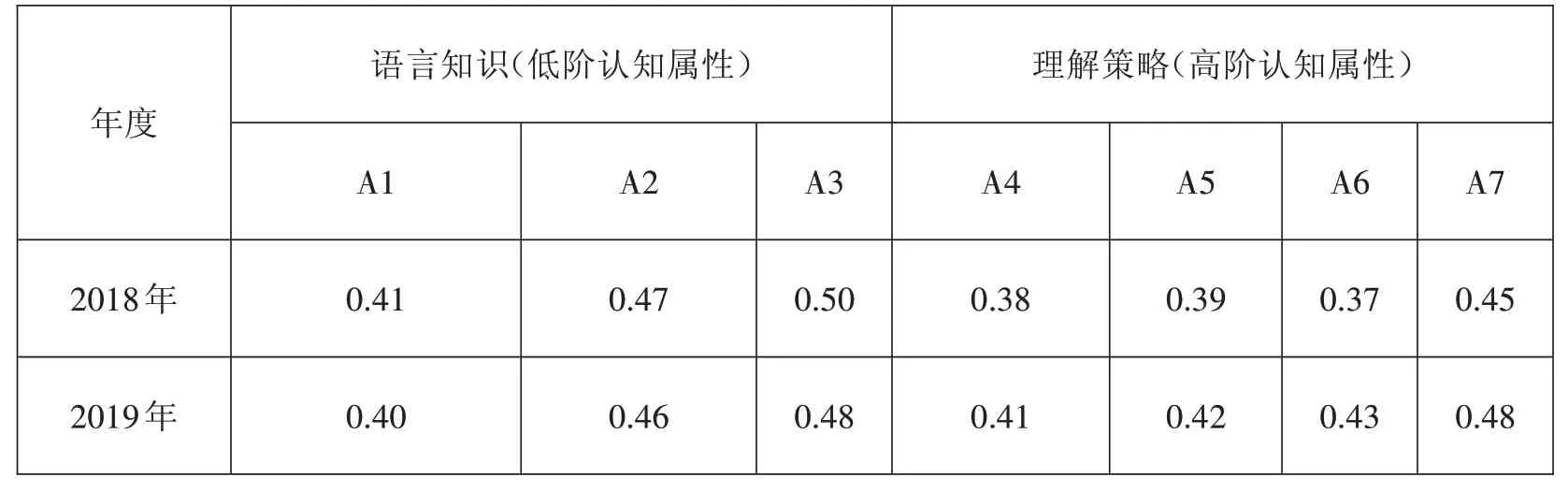
表9 考生掌握各认知属性的掌握概率
根据考生得分情况,将得分前27%的考生划分为高分组,得分后27%的考生划分为低分组。如表9所示,2019 年考生在低阶认知属性的掌握率与2018年接近;高阶认识属性的掌握率优于2018年。

表10 不同分组群体属性掌握百分比(%)

图1 2018、2019年度考生在听力认知属性上的掌握率(%)
三、讨论
(一)大纲修订后的题目参数变化
与大纲修订前(2018 年)相比,2019 年的听力测验平均难度有所降低,这可能与考生整体水平的提高有关,博士和硕士研究生整体人数较2018 年增加,博士研究生人数比例略有升高。2019 年听力测验的整体区分度提高,说明题目能更有效地区分不同能力水平的考生,同时测验信度有所上升,测验的可靠性与稳定性更好。
(二)大纲修订后的听力属性考查情况
两个年度听力认知属性的考查频次各有不同。2018 年考查各属性的总频次为56 次,其中语言知识属性(涉及A1、A2、A3 三个属性)考查了18 次,理解策略方面(涉及A4、A5、A6、A7 四个属性)考查了38次;2019年属于修订大纲后的第一次考试,考查各属性的总频次为60 次,其中语言知识属性考查了11次,理解策略考查了49 次。可以看出,修订大纲后,题目更多地考查了理解策略,即更高阶的听力认知属性,这与大纲修订的初衷相符,考试更加侧重对语言应用的考查,而非单个知识点的识记。
(三)大纲修订后的考生掌握情况
掌握概率描述的是考生掌握某项属性的可能性。听力属性中语言知识方面,2018 年考生的总体掌握情况略好于2019 年;在“理解策略”方面(涉及A4、A5、A6、A7四个属性),2018年不及2019年,由于2019 年听力理解部分的平均分高于2018 年,可以推知2019 年的考生在理解策略上的得分更高,也就意味着考生在高阶的听力认知属性掌握情况越好,对分数的贡献越大。
(四)对教学的启发
7 个听力认知属性中,考生在A2(理解句子及结构)、A3(定位事实与细节)、A7(选择性注意)的掌握概率在45%以上,高于其他属性掌握情况,说明这三个属性的难度相对较小,容易掌握。具体到不同认知层面,考生对“语言知识”的掌握概率介于0.4~0.5之间,对“理解策略”的掌握概率在0.3~0.5 之间,可见,考生掌握“理解策略”的难度比“语言知识”更大。在使用“理解策略”时,考生A4、A5、A6 掌握率比A7要低,提示考生在“理解策略”中掌握薄弱的环节集中在识别语境、总结概括及推理;A7 掌握情况最好,意味着考生在听文段的过程中,对特定词汇等听力信息进行筛选、抓取的能力尚可,具备一定的有针对性捕捉相关信息的能力。
对高低水平组听力属性掌握情况进行单因素方差分析,可知:两组群体对7 种属性的掌握概率存在统计学差异(P<0.01)。其中,低水平组对于理解策略的掌握情况明显低于语言知识;相比之下,高水平群体对两个层面的所有属性掌握较为良好,大致在70%~83%之间浮动,“理解策略”的掌握概率要好于“语言知识”,其包含的四个属性中,A5、A6、A7 这三个属性的掌握情况最好,说明考生在总结概况、推理和选择性注意方面的能力较强。这也意味着,如果想获得更好的成绩,考生需要加强整体语境、文段大意、文意推理等方面的能力,而这些能力本身需要知识的积累、语感的培养和不断的练习才能有所提升。
同时也发现,考生对听力理解策略的使用与听力水平高低密切相关,高水平组对各种策略的掌握率更高;而低水平组成功使用各种策略的概率较低,会更多地将精力集中于语音语调辨认、词组及语法成分识别等低阶的听力属性,应用高阶认知属性存在困难,因此建议医学生的英语教学应关注学生听力理解过程中的策略培养与使用,针对学生的薄弱环节有的放矢地练习。
(五)考生分数报告模板的编制
为了向考生提供更有效的分数反馈,研究编制了考生分数报告,报告中的提示能够帮助考生在后续学习中针对自身的薄弱环节有目的地进行改善。

图2 考生分数报告模板
四、结语
全国博士英语统一考试在大纲修订后,考试内容结构有所调整,从内容上更侧重交际能力的考查,题目的区分度更高,对听力各认知属性的考查频次更高,尤其是听力属性中涉及的高阶认知属性,考查更多,体现了以能力为导向的要求,符合实际需求,与目前的教学评价改革的要求是一致的,这将对后续的学校教学、考生学习及考试改革等均起到积极的促进作用。
猜你喜欢
工会博览(2022年33期)2023-01-12
中国典型病例大全(2022年12期)2022-05-13
趣味(语文)(2018年7期)2018-06-26
体育时空(2017年5期)2017-06-17
考试周刊(2016年88期)2016-11-24
课程教育研究·学法教法研究(2016年14期)2016-06-29
军事体育学报(2016年2期)2016-06-15
新课程学习·下(2015年2期)2015-10-21
少年科学(2014年10期)2014-11-14
少年科学(2009年12期)2009-07-07
