
自动语音辨识对抗攻击和防御技术综述
2022-07-21 09:44李克资张思聪闫嘉乐
计算机工程与应用 2022年14期
李克资,徐 洋,张思聪,闫嘉乐
贵州师范大学 贵州省信息与计算科学重点实验室,贵阳 550001
语音交互正在改变人们与日常智能设备互动的方式。智能终端设备算力的不断增强,加上无线网络覆盖率提升和速度的提高,为语音控制技术提供了新的发展环境。自动语音辨识(automatic speech recognition,ASR)可以帮助智能设备准确有效地解释收到的语音信号,从而使用者能够远程发送语音命令和控制智能设备。在2009年以前,主流的语音识别框架是高斯混合模型(Gaussian mixture model,GMM)加隐马尔可夫模型(hidden Markov model,HMM)[1-2],这种声学模型容量小,表达能力弱。随着深度神经网络(deep neural networks,DNN)的兴起[3-5],目前深度神经网络已经成为语音辨识框架的标配,这使得语音辨识准确率得到了显著提升,常见的语音辨识系统有Kaidl[6]、DeepSpeech[7]等。
最近的研究发现,深度神经网络算法有着严重的脆弱性。在原始样本上添加精心设计的对抗扰动(adversarial perturbations,APs)生成的对抗样本(adversarial examples,AEs),可以欺骗模型使其预测错误的结果,从而使设备执行恶意的控制命令。现有工作中,对抗样本的研究主要集中在图像分类[8]、图像分割[9]、目标检测[10]、自然语言处理(natural language processing,NLP)[11]等方面。构建音频对抗样本攻击和防御研究相对分散,关于ASR系统已知和新漏洞分类的综合结论较少。因此,需要对当前的研究现状进行全面的总结,为今后的研究提供参考。
本文首先分别对音频对抗样本生成和防御技术的研究现状进行分析总结,主要选取近几年在ASR对抗样本研究领域代表性方法。然后介绍ASR系统对抗样本生成和防御技术相关挑战。最后讨论该领域有待进一步研究的问题和思路。
1 简介
1.1 对抗样本定义
音频对抗样本是指在原音频样本中通过人工添加人耳无法察觉或在经处理不影响整体的人耳察觉的细微扰动所形成的样本,这类样本会导致训练好的模型以高置信度给出与原样本不同的分类或转录输出。图1展示对抗样本的一个示例,即向原始数据添加一个微小扰动使得ASR产生错误的结果。
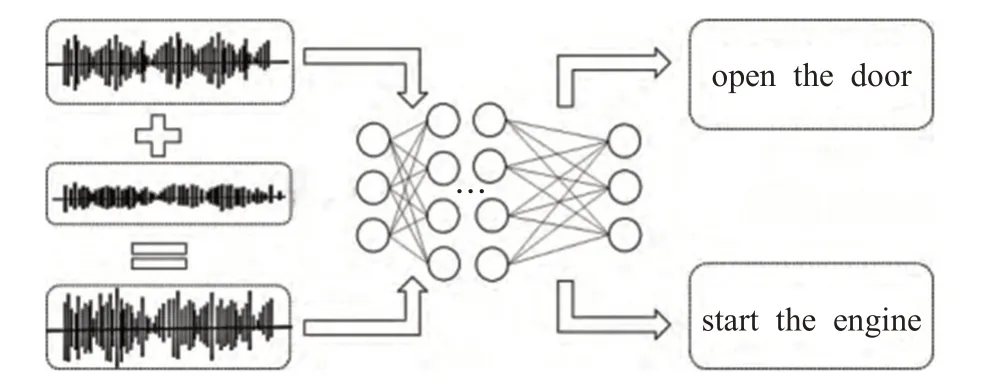
图1 对抗攻击示例Fig.1 Sample of adversarial attack
1.2 相关概念
对抗扰动:对抗样本的重要组成部分。扰动需满足两个方面的要求:一是要保证其微小性,达到添加后人耳无法察觉或者人耳能够察觉但不影响音频整体的听觉效果;二是将其添加到原有音频数据上之后,所产生的新音频具有迷惑原有深度模型的作用。
对抗攻击(adversarial attack):指的是构造对抗样本对模型进行攻击,主要分为黑盒攻击和白盒攻击。
黑盒攻击(black box attack):未知模型内部结构与参数,从输入、输出数据的对应关系进行攻击的方法。
白盒攻击(white box attack):在已知模型内部结构与参数的情况下进行攻击的方法,与黑盒攻击相对。
对抗防御(adversarial defense):指的是减弱或者防止对抗样本对模型的攻击。
对抗样本的鲁棒性(robustness of adversarial examples):指的是对抗样本在经过无线播放(over-the-air)或防御过程后,仍保持对模型攻击能力的一种性质。
目标/定向攻击(targeted attack):目标ASR最终的转录结果是攻击者预先指定的单词、短语或句子。
非目标/非定向攻击(untargeted attack):目标ASR最终的转录结果是除正确结果以外的任意值。
1.3 基本流程
对抗样本的生成方法和防御方法有多种,但是究其根本都有一定的操作流程。总体来说,对抗样本的生成与防御可以归纳为图2所示流程图。
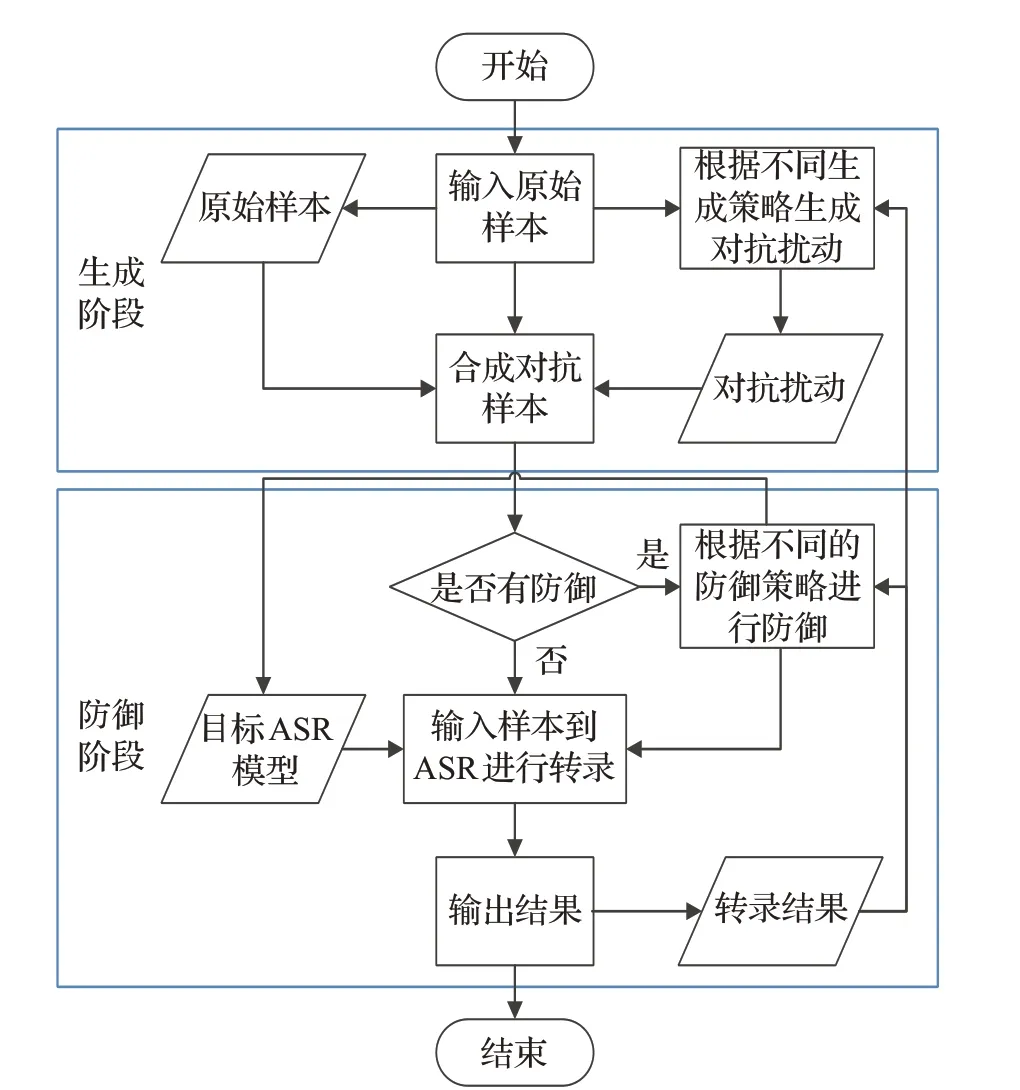
图2 对抗攻击和防御流程Fig.2 Flow chart of adversarial attack and defense
2 起源
2.1 前期工作
在ASR对抗样本生成的前期工作中,Vaidya等人[12]、Carlini等人[13]已经证明,针对深度学习ASR的定向对抗攻击是可能的。他们通过微调音频的梅尔倒谱系数(Mel-frequency cepstrum coefficient,MFCC)声学特征直至被ASR系统误读,然后将微调过的MFCC特征重构回语音波形以生成对抗样本。然而,这样的方法产生的对抗音频与原始音频差别很大。在大多数情况下,人类无法理解生成的音频并且会将其认为是噪音。一旦听者知道可能隐藏声音指令,生成的音频能够轻易地让人类产生怀疑。
Zhang等人[14]提出了克服这一限制的方法,Dolphin-Attack。他们已经证明,攻击者可以利用麦克风的非线性来调制超声波基带音频信号,并将其注入到环境中,以实现隐藏语音指令。但DolphinAttack方法的主要缺点是,攻击者需要在被攻击的系统附近放置一个超声波发射器,并且需要从特定麦克风记录的音频信号中检索信息,然后将攻击定制到一个特定的设置,这在实践中是昂贵的。Song等人[15]和Roy等人[16]引入了类似的基于超声波的攻击,但其未产生对抗样本,而是在人类听不到的频率范围与ASR系统交互。
与调制语音命令到超声波的DolphinAttack不同,Yuan等人[17]提出了CommanderSong,将恶意命令注入到常见的歌曲中。他们利用迭代优化算法来寻找最小扰动。此外,他们还通过噪声模型将硬件设备噪声引入到对抗样本中,使他们的方法实现了无线播放攻击。然而,他们的方法中使用的噪声模型仅对特定的设备有效,并且实验是在近距离进行的。Carlini等人[18]提出了一个以原始音频作为输入的基于梯度下降最小化(类似于之前对图像分类的对抗攻击)创建最优的音频对抗样本生成算法。其使用CTC-Loss(connectionist temporal classification)构建针对ASR系统的定向攻击,其工作证明音频对抗样本可以使ASR系统将一段音频转录为任意的文本。
相比以上在白盒攻击假设下的研究,在黑盒对抗样本生成领域,因无法获取目标模型的内部信息,Alzantot等人[19]通过使用遗传算法生成语音关键字识别系统[20]的对抗样本,其为语音对抗样本黑盒生成方面的研究提供了研究思路。Taori等人[21]基于遗传算法引入梯度估计算法求解近似解,以弥补遗传算法的缺点。Khare等人[22]为了拓展算法处理短语和句子,引入了CTC损失函数。并且为了加速样本生成在遗传算法的基础上引入动量变异,对遗传算法中变异的环节进行优化。
随着对抗攻击技术的不断发展,对抗样本防御方法也得到广泛关注和研究,通过攻击防御的博弈以提高模型的安全性。在ASR对抗防御的前期工作中,主要是从消除对抗扰动和提升ASR模型鲁棒性两方面出发。在消除对抗扰动方面,音频领域的对抗防御很大程度上参考图像领域的方法,如特征压缩、JPEG压缩、量化、随机平滑等基于输入变换的防御方法[23-25]方法。通过结合音频的特性(如时序性等)和输入变换方法以消除对抗扰动。在提升ASR模型鲁棒性方面,一是通过对抗训练[26]的方法,使用混合对抗样本和原始样本的数据集对基于深度学习的ASR模型进行训练,提高ASR模型对于对抗样本的敏感性。二是通过蒸馏网络[27],通过对模型内部参数进行优化选取,提升ASR模型的鲁棒性。
2.2 对抗攻击基本原理
为了欺骗ASR系统,通过添加少量噪声轻微干扰合法的音频文件或语音特征来生成对抗样本。音频剪辑的人听不到添加的噪声,或只将其视为微弱的背景噪声,但噪声扰动会导致ASR模型对输入进行错误分类和转录,甚至转录成攻击者指定的字段。
ASR系统任务的对抗样本可描述如下:通过在原始音频中添加微小的、人类几乎无法察觉的扰动,以使得ASR系统产生错误的转录结果。假设给定一个ASR系统f和一个原始语音样本x,生成一个对抗样本x′可以被描述为一个有约束条件的优化问题:
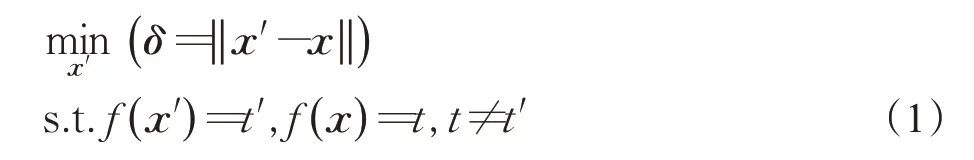
t和t′分别表示x和x′的转录结果。表示添加在x上的对抗扰动。表示对扰动进行距离度量。
3 对抗样本生成
接下来主要在白盒、黑盒两个假设条件下对生成技术展开综述。
3.1 语音对抗样本白盒生成技术
白盒生成技术(白盒攻击)是指攻击者在已知目标模型所有知识的情况下生成对抗样本,对目标系统进行攻击。由于攻击者可以得到目标模型的信息,相比黑盒攻击方案,白盒攻击方案具有容易实施的优点。现有对抗样本研究工作大多基于白盒条件的假设。下面从普适性、鲁棒性、隐蔽性三方面进行综述。
3.1.1 普适性对抗样本生成技术
现有的对抗样本生成算法大多为输入依赖型(inputdependent),即针对一个原始样本生成一个对抗扰动。如公式(2)中对应一个原始样本xi,生成一个对抗扰动δi以欺骗模型。
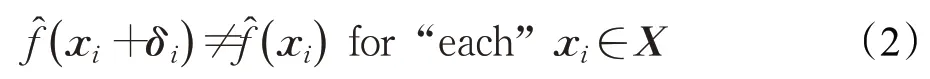
表示模型函数,表示对应x∈Rd的预测标签。但在非数字空间的现实场景下,攻击者通常无法事先预知音频的具体内容,无法针对不同的模型、数据集进行一一分析训练产生对抗扰动。为解决这一问题,是否可以根据同一分布数据集中少量数据,产生一个适用于所有样本的对抗扰动呢?假设μ∈Rd表示音频的分布,则普适性扰动δ∈Rd,使得:

最早在2017年,Moosavi-Dezfooli等人[28]指出针对基于卷积神经网络的图像识别模型能够生成有效的普适性对抗扰动向量。添加对抗扰动的样本能越过深度模型决策边界,这个扰动向量满足:
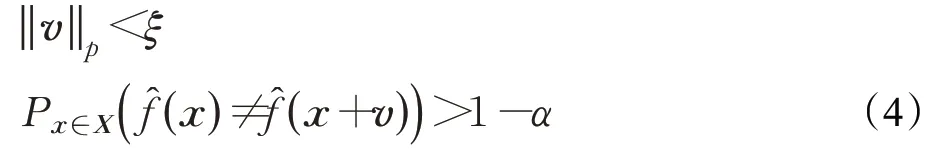
ξ限制普适扰动向量v的大小,α控制所有对抗样本的失败率。
扰动向量寻找方式如图3所示[28]。在图3中,数据点x1、x2和x3被叠加,分类区域Ri用不同的颜色表示。算法按照公式(5)通过对最小扰动Δvi序列进行聚合,将当前扰动点xi+v发送到相应的分类区域Ri之外。

表示模型函数,表示对应x∈Rd的预测标签。v表示普适扰动向量,Δvi表示最小扰动。

图3 用于计算普适性对抗扰动算法的示意图Fig.3 Schematic representation of proposed algorithm used to compute universal perturbations
在文献[28]中寻找Δvi使用DeepFool[29]算法。此处需要注意,根据不同的反向传播梯度方向可以得到不同的普适性对抗扰动向量,但是最后达到的效果相同。
在Moosavi-Dezfooli等人[28]工作基础上,Vadillo等人[30]和Abdoli等人[31]首先尝试扩展到音频领域,Vadillo等人重构了文献[28]中的算法并且聚集了扰动向量δ,对于每个迭代,利用DeepFool方法[29]得到每个输入数据的最小样本扰动,并且更新扰动到总的扰动中。实验结果表明,生成的普适扰动会使扰动后的音频被误分类为除原音频外的其他类,即实现了非定向无目标攻击,但并未研究定向目标攻击。
Abdoli等人[31]使用DDN L2[32]方法代替文献[28,30-31]中使用的DeepFool[29]方法,其目的是实现目标攻击。此外,Abdoli等人又提出了一个新的惩罚公式,以寻找定向有目标和非定向无目标的普适对抗扰动。其设计的定向有目标攻击惩罚公式如式(6):

其中SPL(sound pressure level,SPL)控制扰动量级,SPL(δ)=20 lgP(δ)。g(*)j为分类器f的Pre-Softmax层对标签类型j的输出,c为惩罚系数,c>0。k控制样本误分类的置信水平。yt为目标类,θ为分类器f的参数。
对于非定向无目标攻击只需修改公式(6)如下:
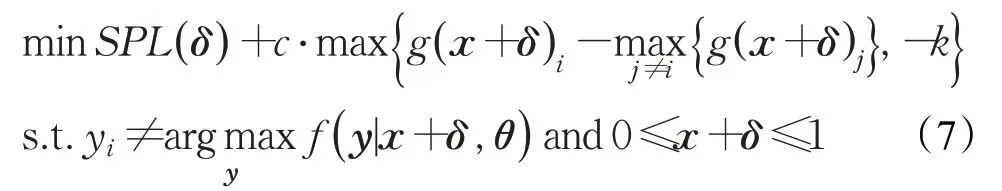
实验评估其方法对基于一维CNN模型的语音分类模型,定向攻击达到85.4%攻击成功率,非定向攻击产生83.1%成功率。
Vadillo等人[30]和Abdoli等人[31]的研究针对语音分类模型。然而,生成ASR系统普适性对抗扰动相比于语音分类更困难,因为构造优化损失函数需要将ASR系统的转录输出与目标序列比对,而由于目标序列的重复、移位等,标签的种类大幅增加,导致计算量骤增。
Neekhara等人[33]提出针对ASR系统普适性对抗扰动生成方法,主要目标是寻找扰动δ使得:
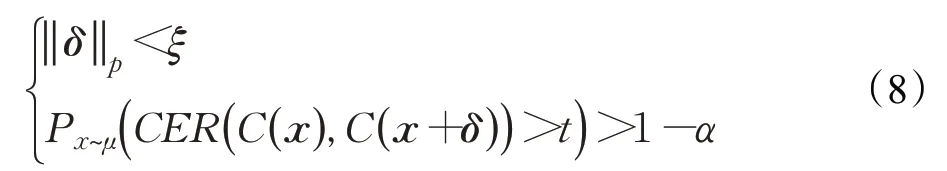
C(x)表示ASR的转录结果;
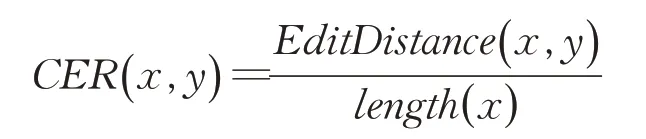
表示字符串x,y之间字符错误率(character error rate,CER)。编辑距离(edit distance),又称Levenshtein距离[34],是指两个字符串之间,由一个转换成另一个所需的编辑操作次数。许可的编辑操作包括替换、插入、删除。编辑距离越小,两个字串之间的相似度越大。
相比语音分类普适性对抗扰动生成任务,ASR对抗扰动生成成功的判定条件由标签的不同更换为转录结果与目标序列的CER。即求得的CER大于阈值t,说明扰动生成成功。
生成方法依旧借鉴文献[28]中的迭代思路,不过由于ASR模型的特殊性,不能直接应用在图像中的DeepFool方法寻找最小扰动。而是通过迭代梯度符号方法,具体寻找公式如下:
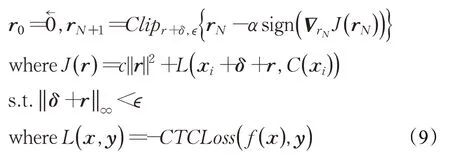
Neekhara等人[33]的工作对于DeepSpeech的非目标攻击成功率为89.06%,并未实现目标攻击。
Lu等人[35]对基于端到端(end-to-end)ASR系统生成定向有目标的普适性对抗扰动,主要探索了LAS[36]、CTC[37]和RNN-T[38]三种模型的普适性研究。另外研究了两种扰动添加方式,加性(additive)和预加性(prepending),论证了生成普适性扰动不必对一个音频的全部数据进行扰动,并且可以将扰动添加到输入音频的任何位置。其中加型扰动是添加与原始音频样本等长的扰动,即对每个数据点进行修改如公式(10)所示:
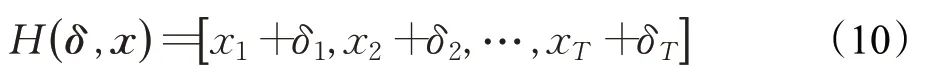
另一种预加性扰动是在原始音频数据前添加一定长度的扰动数据如式(11):

此方式可以不对音频的内容数据进行修改,极大地保留了音频本身,并且能够提升错误率。另外因加入的对抗扰动在整体音频之前,不会被人轻易察觉是音频本身的原因,而会理解为信号或硬件问题。但是相比于加性方式,预加性扰动的幅度会很大,刺耳的噪音能轻易地被发觉,并且同时增加了音频的长度。
Lu等人[35]在常用的基于LAS、CTC和RNN-T的模型下进行对比实验。实验发现,在三种模型中,LAS是最容易受到扰动的。RNN-T对加性扰动更有鲁棒性,特别是在长话语上。CTC对加性和预加性扰动都是鲁棒的。对于攻击RNN-T,预加性扰动比加性扰动更有效,并且可以误导模型对任意长度的话语预测相同的短目标。
除了基于优化和基于梯度符号方法生成对抗样本,近来基于生成模型的方法[39-40]也逐步被研究,其核心思想为通过生成模型生成器学习扰动的分布,然后根据分布快速生成对抗扰动,基于生成模型的方法主要工作在于生成模型的架构搭建以及损失函数的构建和优化,因为本质是神经网络生成模型如自动编码机(auto encoder,AE)[41]和生成对抗网络(generation adversarial network,GAN)[42]。基于生成模型的方法可以快速生成对抗样本,缺点是需要训练出深层多参数的生成器。
3.1.2 鲁棒性对抗样本生成技术
音频传入ASR的途径可以分为两类:直接传入(over-line)、无线传入(over-air)。直接传入是直接将原始音频或者生成的对抗样本音频直接输入到模型中,如图4(a)。无线传入指的是音频经过扬声器播放和麦克风记录再传入ASR模型,如图4(b)。
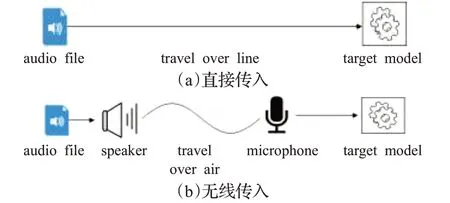
图4 音频传播示意图Fig.4 Audio transmission diagram
鲁棒性对抗样本的产生困难之处在于经过扬声器播放和麦克风录制后,音频文件中会引入环境的混响和设备的噪音。相比直接传入方式,在无线传入的方式下,对抗样本需要对未知的环境和设备产生鲁棒性。
针对混响和噪音的问题,Yakura等人[43]提出在对抗样本生成的过程中添加带通滤波器、脉冲响应(impulse response,IR)和高斯白噪声,用以模拟噪音和混响的影响。其想法来源借鉴图像领域Athalye等人[44]的工作,即对图像进行旋转、放大、缩小、改变亮度、增加噪音等模拟环境对图像的影响,以增加生成的对抗样本鲁棒性。Yakura等人提出的方法优化目标如下:
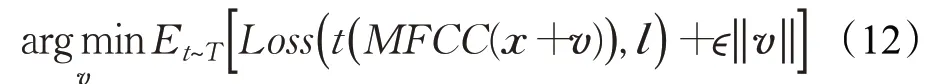
式中,t(*)表示带通滤波器、脉冲响应和高斯白噪声等的转化操作。其中带通滤波器用来限制扰动的频率范围,脉冲响应用以模拟现实环境混响,高斯白噪声用于模拟自然界的随机噪声。最后具体的优化公式如下:

其中,BPF为带通滤波器,Conv为卷积操作,ω为高斯白噪声,H表示脉冲响应集合。
类似Yakura等人[43]提出的方法,Qin等人[45]考虑房间脉冲响应(room impulse response,RIR),使用声学房间模拟器,通过文献[46]中方法生成RIRr,然后与输入音频进行卷积操作t(x)=x*r得到经过混响后的音频t(x)。其产生鲁棒性的对抗样本优化过程如下:
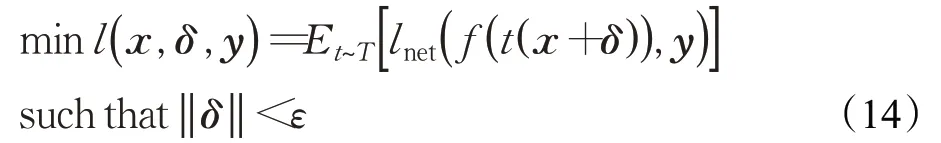
x为原始音频,y为攻击目标内容,f(*)为目标ASR模型,δ为添加的扰动,T表示脉冲响应集合,lnet(*)表示目标ASR的损失函数。文中针对基于LAS-Attention的ASR模型生成对抗样本,其模型能够处理长句子而不只是处理单词短语。其实验结果表明增加了鲁棒性的对抗样本经过模型之后甚至能够取得比原始音频更低的词错误率(word error rate,WER)和更高的准确率,充分说明了其生成方法的有效性。然而,和Yakura等人[43]的方法一样,Qin等人[45]通过使用模拟环境进行仿真实验得到的鲁棒性对抗样本只能在特定的模拟环境下攻击成功,不能在实际环境中产生攻击效果。Szurley和Kolter[47]也提出多个环境下的鲁棒性对抗样本生成,然而,其对抗样本只能在专门设计消除RIR的消音室有效。
针对环境独立(environment-independent)对抗样本,Schönherr等人提出Imperio攻击[48],其目标是产生在不同的实际环境下的鲁棒性对抗样本。Imperio攻击中仍然需要使用RIR仿真等技术模拟无线播放产生的混响和噪音,不同的是该算法使用DNN模拟RIR滤波器集,通过反向传播可以直接对原始音频进行优化得到鲁棒性对抗样本,优化目标如下所示:
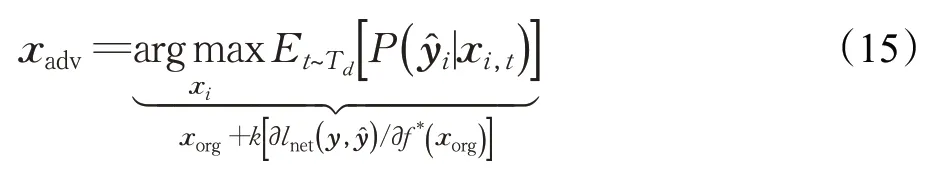
d、k、f*()分别表示上述DNN模型的过滤集维数、学习率和激活后函数。由于Imperio攻击中包含的EOT操作是动态的,所以适合各种房间设置,包括会议室、演讲大厅和办公室。Imperio针对ASR混合模型Kaldi进行测试,相比端到端的ASR(如Deepspeech),攻击更难一些。多组对比实验证明其方法具有不同环境下生成定向鲁棒对抗样本的能力。
由于扬声器和麦克风的特性对音频的影响,信道脉冲响应(channel impulse response,CIR)滤波器集被整合为Metamorph对抗攻击[49]中EOT操作的一部分。这种攻击的公式如下:
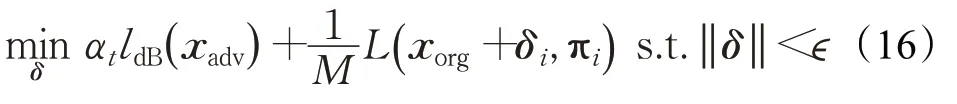
其中,αt是精心制作的对抗信号的质量和攻击算法在目标模型上的总体成功率之间的平衡系数,M表示封闭环境中话筒位置的个数。这些超参数在制造强大的对抗样本中起着关键作用,攻击者应该精确地定位这些信号。Metamorph对抗攻击的有效性已经在DeepSpeech系统中被证明。然而,代价是使用各种CIR文件集。
以上基于EOT的方法,其局限性在于转换分布必须是事先已知,如果实际的转换不满足设计的分布,EOT算法效果会很差,并且基于EOT的方法需要消耗大量的计算时间和计算力。为实现一种快速高鲁棒的音频对抗样本生成方法,Liu等人[50]提出了加权扰动技术(weighted perturbation technology,WPT)和微取样扰动技术(sampling perturbation technology,SPT)。其中WPT通过利用音频序列定位(audio sequence location,ASL)模型找到权重较大的关键点,然后使用迭代梯度法不断调整音频向量不同位置的权重大小,从而达到快速生成音频对抗样本的目的;SPT基于音频识别过程中上下文相互关联的特性,通过减少扰动的音频向量点的个数,以提高音频对抗样本的鲁棒性。WPT和SPT有良好的扩展性,能够和当前提出的音频对抗样本攻击相结合,从而增强效果。其实验表明文中方法可以在4~5 min分钟构造出一个强鲁棒性的音频对抗样本。
Esmaeilpour等人[51]介绍了一种新的对抗算法攻击最先进的ASR系统,即DeepSpeech,Kaldi和Lingvo[52]。其方法是建立在利用Cramer积分概率度量对对抗优化公式的传统失真条件进行扩展的基础上。最小化这个度量,衡量原始和对抗样本分布之间的差异,有助于将对抗样本制作得非常接近合法语音记录的子空间。这有助于在不使用昂贵的EOT或静态房间脉冲响应模拟的情况下,产生更鲁棒的对抗音频。其方法在CER和句错误率(sentence error rate,SER)方面优于其他定向和非定向算法。此外,其方法是无EOT的,与其他昂贵的基于EOT的对抗算法相比,对连续的无线回放显示了相当强的鲁棒性。
3.1.3 对抗样本距离度量(隐蔽性)
根据对抗样本定义,生成人类无法听到或者人类无法理解的对抗音频是关键的。这体现在对抗样本生成过程中对抗样本与原始样本的距离度量,即对抗扰动的量级。也可以解释为对抗样本的隐蔽性。
在对抗样本距离度量前期研究中,研究者广泛采用lp范数对扰动进行约束。lp范数优势为易于实现;劣势为计算量大且无法保留音频的时序性特点。不同于使用lp范数,Zhang等人[14]提出DolphinAttack方法,其主要通过人耳无法察觉的超声波作为载体,并且利用麦克风的漏洞产生人类不可察觉的对抗样本,可以成功攻击目标系统。其方法主要缺点为,高频扰动易被取音设备中的低通滤波器过滤,对抗样本从而失效。Schönherr等人[53]首个提出使用基于心理声学的方法产生不可感知的音频对抗样本,相比之前工作采用的lp范数对扰动进行约束,其提出使用听觉阈来限制扰动,其方法产生定向的对抗样本成功率达到98%,并且没有人能够识别出对抗样本。但是其没有对其他方面(如无线播放等)进行实验,其主要是提供了一种新的约束扰动的思路。
受Schönherr[53]启发,Qin等人[45]通过用频率掩蔽方法替代lp范数约束对抗扰动。其优化方法如下:
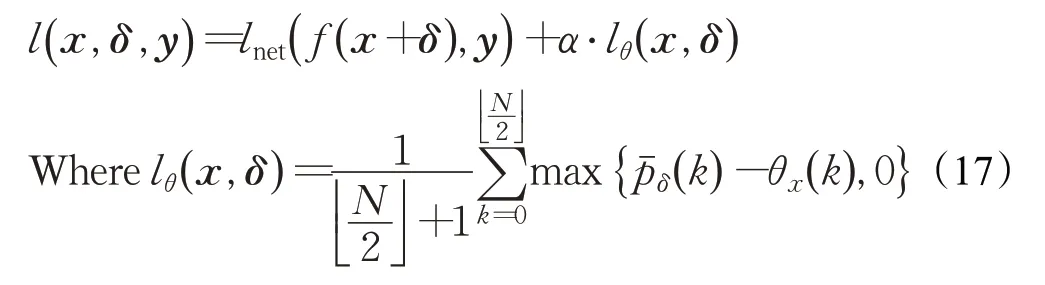
lnet(*)表示Cross-entropy损失函数。α·lθ(x,δ)约束扰动产生。表示原始音频的频率掩蔽阈值,表示归一化功率谱密度,px(k)为功率谱密度。其核心思想为设置一个频率阈值θx(k),只要pˉδ(k)低于阈值,即可产生有效的对抗扰动。
Liu等人[50]对lp范数进行对比实验,以比较哪种范式适合音频对抗样本生成,并且提出结合总变差去噪(total variation denoising,TVD)[54]以减少噪声干扰,让对抗样本在听觉方面更像原始音频。TVD的原理是,一个含有杂讯的讯号相较于其未受杂讯影响的讯号,会有较大的总变差值,即其梯度绝对值的总和较大。因此若能找到一个与原始讯号相似且总变差较小的讯号,即可作为原始讯号的降噪结果。此算法可以在去除杂讯的同时保留边缘,即使在低讯号杂讯比的情况下,依然能有效地去噪和保留边缘。在TVD过程之后,可以移除对抗样本中的大部分脉冲,使失真更加难以察觉。该方法可以使生成的对抗样本达到100%的攻击成功率和31.9 dB的信噪比。
最后从普适性、鲁棒性、距离度量三方面将前文白盒对抗样本生成技术进行归纳总结为表1。
3.2 黑盒对抗样本生成技术
在黑盒攻击假设下,攻击者只能充当一个可以得到ASR模型输出结果的普通用户。相比白盒攻击,黑盒攻击难度更大。但由于不需要掌握目标模型,黑盒攻击更容易在低控制权场景下部署和实施,更加具有实际意义。由于黑盒攻击本身的局限,现有的工作主要是针对定向生成和鲁棒性对抗样本生成。

表1 语音对抗样本白盒生成技术研究总结Table 1 Summary of speech adversarial example white box generation technology
3.2.1 定向对抗样本生成技术
在黑盒攻击的假设下,攻击者无法获取系统的任何信息,所以无法使用在白盒场景下反向传播方法。在此基础上Alzantot等人[19]通过使用遗传算法生成语音关键字识别系统[20]的对抗样本。其算法流程为:首先在音频取样的随机子集的最低有效位上增加随机噪音生成对抗样本候选种群。然后计算种群中适应度最高的样本,如果能够被目标模型识别为目标词则结束,未被有效识别则再经过交叉和变异等操作形成新的候选种群。最后迭代以上算法,直到得到有效地对抗样本或者到达最大迭代次数。
论文实验效果在非定向攻击取得了100%的成功率。在定向攻击实验中,文中实验为10类关键词的语音,对于每一类生成其余9类的定向对抗样本,其取得了87%的成功率,平均生成每个对抗音频的时间为37 s,原始音频与对抗样本拥有85%的相似度。Alzantot等人[19]为语音对抗样本黑盒生成方面的研究提供了研究思路,但是其局限在于,对于文中的语音关键字识别对抗样本生成,效率较低。其中未能尝试对大规模ASR系统和长句子的攻击,对于无线播放攻击也未进行实验论证。
Taori等人[21]为了拓展算法处理短语和句子,引入了CTC损失函数,并且为了加速样本生成提出引入动量变异的遗传算法,见图5。此外,因遗传算法适用于搜索具有潜在有益变异方向的大目标空间。而当对抗扰动接近目的扰动,遗传算法的作用就会变弱。为了解决遗传算法的问题,Taori等人引入梯度估计算法,提出基于遗传算法和梯度估计算法对DeepSpeech进行黑盒对抗样本生成。其方法最后取得了89.25%字相似度,94.6%的对抗样本和原始音频的相似度,但是成功率只有35%。并且文中并未做多组对比实验,相比Alzantot等人[19]的方法,其受限于ASR模型最后一层给出的信息,并且需要知道模型的损失函数。
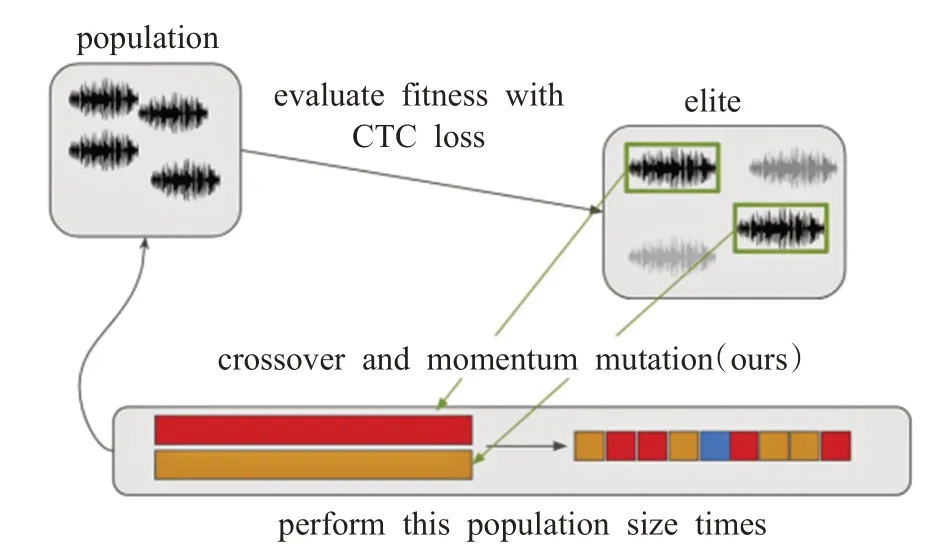
图5 基于遗传算法的黑盒对抗样本生成Fig.5 Black box adversarial example generation based on genetic algorithm
针对DeepSpeech和Kaldi系统,Khare等人[22]提出基于多目标进化优化的算法生成对抗样本。考虑两个目标:减少文本相似度;保持音频声学相似度。并对比使用MOGA[55]、NSGA[56]两个遗传算法生成对抗样本。其非定向生成实验增加较大词错误率,音频相似度在非定向和定向任务中分别达到了98%、97%。
3.2.2 鲁棒性对抗样本生成技术
相比于白盒条件下对抗样本鲁棒性的研究,黑盒条件下的对抗样本鲁棒性研究相对较少。为黑盒对抗攻击开发EOT操作是极具挑战性的,因为攻击者不能访问受害者模型及其相关参数设置。为了应对这一限制,文献[57]开发了一种在线技术来代替无线EOT操作。然而,这种技术需要大量的实验来捕获局部和全局的环境场景分布。
Chen等人[58]针对商业黑盒ASR系统构建物理世界的对抗攻击。其关键思想为通过小数量的策略查询构建一个替代模型,并且通过开源的ASR系统增强替代模型,用于处理复杂的目标系统。实验验证,其方法对于某些黑盒设备98%的目标命令可以产生至少一个成功的对抗样本,但是成功率较低,并且攻击所使用的设备不具有普适性,有些设备自带降噪功能,文中并未进行描述。
为探究真实攻击环境下,扰动的播放时延对原始音频的对抗攻击生成的影响,Ishida等人[59]提出时间鲁棒的对抗样本生成算法。其主要使用进化的多目标优化方式在黑盒条件下针对语音关键词模型生成鲁棒对抗样本,其主要优化以下三个目标函数:
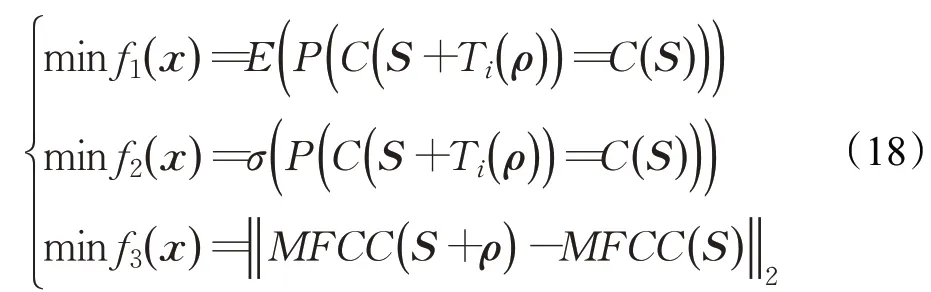
E(*)、σ(*)分别表示期望和标准差,Ti(*)表示±Tmax的时间差,S为目标样本,ρ为添加的扰动。然后通过加权切比雪夫方法,将多目标优化问题简化为多个单目标优化问题,然后使用多目标进化算法生成对抗样本。实验结果证明,其方法产生了更平滑的音频,并生成了对时间鲁棒的对抗样本,为更鲁棒的对抗样本生成提供了新的研究方向和思路。
最后将前文所列黑盒假设下对抗样本生成技术的文献关键研究点进行总结为表2。
3.3 对抗样本生成总结
如表1和表2所列,本节从白盒和黑盒对抗样本生成两个方面综述了ASR音频对抗样本生成的研究现状。在白盒方面,从对抗样本普适性、鲁棒性和隐蔽性三个角度进行综述分析。对于普适性,结合现实攻击考虑,生成不依赖输入样本的普适性扰动能够满足现实攻击的要求。对于鲁棒性,对抗音频的播放和记录是实现在现实环境下攻击的关键,没有鲁棒性,对抗攻击只能停留在理论层面;对于隐蔽性,生成不易被人类察觉的扰动是重要的,这也是对抗样本定义中的要求。在黑盒生成方面,由于黑盒本身具有较大的难度,所以从定向和鲁棒性两个角度进行综述分析。对于定向方面,在不知道模型内部细节的情况下,定向攻击模型具有很大威胁性和现实意义。结合鲁棒性,既有定向又有物理鲁棒性的攻击可以完全攻破ASR模型。
4 对抗防御
本章将总结近年来具有代表性的对抗防御方法,主要分为主动防御和被动防御。主动防御是指提高模型的鲁棒性。被动对抗防御是指在模型已经训练完成后,对要输入的数据进行某些特定的处理以至于模型能够分辨出对抗样本和正常样本。主动对抗防御方法主要包括对抗训练(adversarial training)和扰动消除。被动防御方法通常包括对抗检测和网络验证(network verification)。
4.1 主动对抗训练
4.1.1 对抗训练
对抗训练是最早提出来的防御对抗样本攻击的方法,也是常用的防御方法。主要思想如图6所示[60]。

图6 标准与对抗决策边界的概念说明Fig.6 Conceptual illustration of standard vs.adversarial decision boundaries
在图6(a)中决策边界能够较好地区分两类数据点,但是有一些数据点离决策边界过近。假设每个数据点有一个人类无法察觉邻域,如图6(b)所示,表示为每个点的一个范数邻域,在这个邻域内的数据点对于人类无法区分,这个时候图6(b)上的星形点就是对抗样本。对抗训练就是把这些星形点代表的对抗样本加入到训练样本中去,改变模型的决策边界,使得模型能够正确区分这些对抗样本,当邻域中的所有数据点都不会越过决策边界的时候,即图6(c)所示,这一模型就具有在这一邻域范围内的对抗鲁棒性,即对数据点的改变不超过这一邻域的对抗扰动都无法改变模型的分类结果。

表2 语音对抗样本黑盒生成技术研究分类总结Table 2 Summary of speech adversarial example black box generation
Sun等人[61]提出使用结合对抗数据的自然数据增强方法训练模型。他们针对MFCC特征,通过使用快速梯度符号方法(fast gradient signal method,FGSM)[26]对每个小批量(mini-batch)产生对抗数据,动态地将FGSM生成的对抗样本整合到训练集中,通过使用结合对抗样本的增强数据重训练语音分类(speech-to-label)模型。此外,他们利用师生训练(teacher-student)[62]使他们的方法更加健壮(robust)。他们在定制的卷积神经网络以及Aurora-4和CHIME-4任务做了实验。对抗训练方法使相对单词错误率降低了23%。然而,尚无研究证明对抗训练可以使ASR系统具有鲁棒性。
4.1.2 扰动消除
扰动消除防御方法已经得到了广泛的研究,其重点是消除对抗扰动。样本去除扰动的过程称为去噪。在转换后,对抗样本不会影响深度神经网络模型的原本预测。
在CommanderSong[17]工作中,作者提出了两种防御音频对抗样本的方法。第一种方法的灵感是,扬声器或背景的噪音降低了对抗样本攻击的成功率,而对合法音频命令的识别影响很小。因此,作者提出在输入音频中添加噪声。如果这种扰动输入与原始输入的ASR系统的识别结果不同,则可以将该输入视为对抗样本。然而,这种方法并不适用于3.1.2节提到的模拟了扬声器和背景噪音生成的鲁棒性对抗样本。第二种方法是通过降低采样率来压缩输入。如果这两种输入对ASR有不同的结果,那么它很有可能是一个对抗样本。通过实验对该方法的有效性进行了评估,结果表明该方法适用于无线播放环境。
Das等人[63]设计并实现了一个名为ADAGIO的工具,允许对抗音频攻击和防御的交互实验。采用音频压缩作为防御手段。他们认为,产生的对抗扰动过于脆弱,可以通过简单的音频处理技术,如自适应多速率(adaptive multi-rate,AMR)编码和MP3压缩,轻易消除。这两种方法与上面的CommanderSong方法有着相同的理念,即修改输入以衰减添加到原始音频中的精心制作的扰动。
Latif等人[64]提出了一种基于GAN的防御方法。他们利用生成模型,通过将对抗样本移回原始样本的分布来消除对抗扰动。对将多种环境噪声添加到良性样本中生成的对抗样本和良性样本组成的对抗样本数据集进行评估,实验结果表明,该方法能够去除对抗样本中的一些扰动。同样采用GAN,Esmaeilpour等人[65]提出CC-DCGAN来应对先进的ASR系统。与传统防御方法不同,该方法不直接采用低级转换,例如自动编码给定的输入信号,以消除潜在的对抗干扰。相反,通过最小化给定测试输入和生成网络之间的相对弦距,以找到一类条件生成对抗网络(condition generation network,CGAN)的最优输入向量。然后,根据合成的频谱图和给定的输入信号的原始相位信息重建一维信号。因此,这种重构没有给信号添加任何额外的噪声,并且根据其实验结果,在WER和SER方面明显优于传统的防御算法。
Esmaeilpour等人[66]提出了一种新的对抗攻击的防御方法。利用深度神经网络平滑光谱图减少对抗扰动带来的影响。然后对平滑后的光谱图进行动态分区和网格移动处理,提取加速鲁棒特征。最后输入支持向量机(support vector machine,SVM)。实验结果表明,该方法能够有效地消除后门(backdoor)攻击和DolphinAttack[14]所带来的干扰。该方法充分结合卷积深度学习的去噪优点和支持向量机的分类性能,能够较好地权衡深度神经网络和支持向量机的准确性和弹性。
Tamura等人[67]比较了不同ASR输入的转录结果,提出了一种基于沙盒的防御方法。他们首先利用动态下采样和去噪技术消除对抗扰动,然后比较ASR转录结果的CER,将CER大于阈值的样本视为对抗样本。通过对3个数据集构建的混合数据集的评估结果表明,他们的方法能够成功防御对抗攻击。然而,他们并没有在评估中指定使用的具体攻击,这不能评估他们对现有攻击的防御效果,并且扰动消除技术只具备雏形,需要继续对其进行优化以提升效果。
Yang等人[68]提出了一种新的基于U-Net的注意力模型U-NetAt,使ASR系统对对抗样本具有鲁棒性。受U-Net语音增强的启发,他们将注意门集成到上采样块中,从输入中提取高级特征表示,保持了音频特征。最后,U-Net的输出是增强的音频和对抗扰动。实验结果表明,他们的方法能够消除Khare等人[22]和Yakura等人[43]提出的方法所引入的对抗扰动。
4.2 被动对抗防御
被动防御的重点是在ASR系统建立后发现对抗样本。根据防御策略的不同特点,从对抗检测和网络验证两个方面对被动对抗策略进行综述。
4.2.1 对抗检测
对抗检测可以看作是一种二分类任务,目标是将对抗样本和正常样本进行二分类。
为了防御Alzantot等人[19]提出的对抗攻击,Rajaratnam等人[69]提出了一种对抗检测方法。他们独立使用多种音频预处理方法(压缩、语音编码、滤波等)检测对抗样本。此外,他们使用不同的集成策略来组合这些方法。实验结果表明,他们的方法可以达到93.5%的正确率和91.2%的召回率。然而,Rajaratnam等人提出的方法对于其他对抗攻击方法有效性有待研究。
Samizade等人[70]设计了一个基于CNN的分类神经网络,见图7。该模型以语音信号的二维倒谱特征作为输入,通过卷积、池化、全连接最后输出分类置信度。实验检测Carlini等人[18]和Alzantot等人[19]提出的攻击时,检测准确率可以接近100%。此外,他们的方法可以检测未知的攻击。不过,此方法也需要训练新的判别模型并且需要构造合适的训练集进行针对性训练。
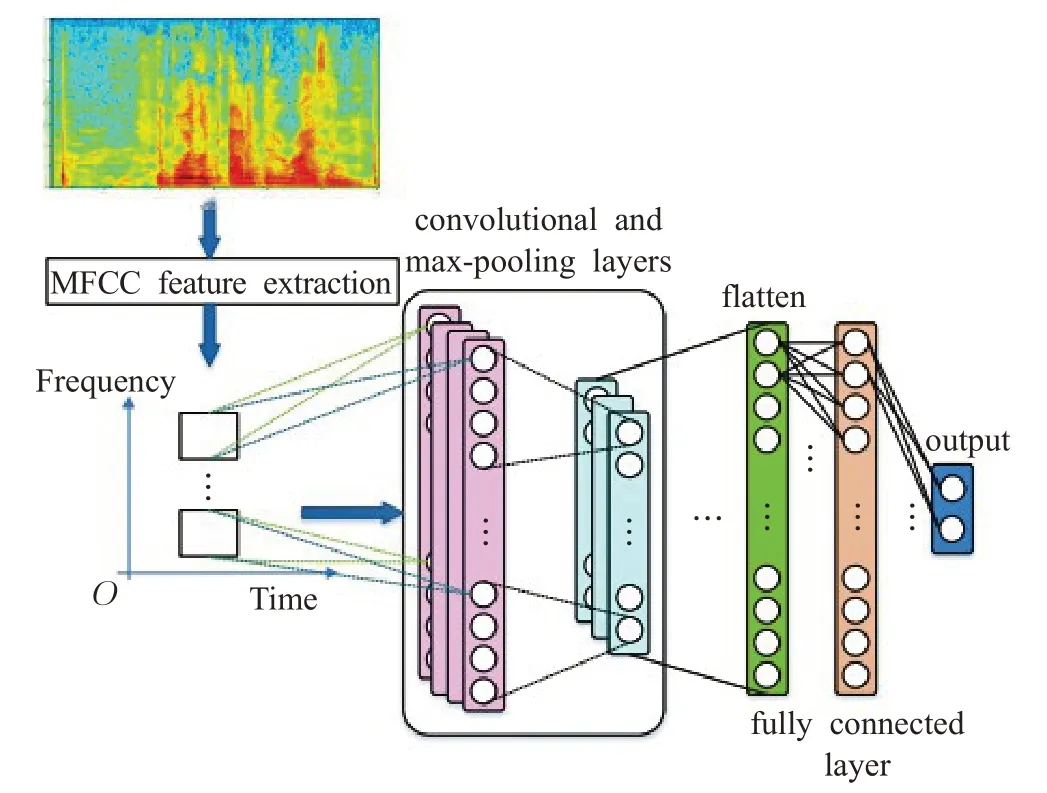
图7 基于CNN的分类神经网络Fig.7 Classification neural network based on CNN
4.2.2 网络验证
网络验证通过确定目标神经网络的性质,然后判断输入符合或者违反网络的性质。该类方法对目前尚未出现的对抗样本攻击方式也有潜在的检测效果,因此网络验证是一种备受关注的防御方式。例如,利用不同ASR上的转录差异,对比输入加入微小噪声后的输出差异。这种防御方法可以检测到不可察觉的攻击,是对抗样本防御的一种有前景的解决方案。
受多版本编程原理的启发,Zeng等人[71]提出了一种检测语音对抗样本的新方法。基于不同ASR系统对单一正常语音的转录结果应该是相同的这一事实,他们计算了在多个ASR系统中,每两个ASR系统并行输出的相似度评分。对相似度低于阈值的样本分类为对抗样本。对文献[18]提出的攻击,检测准确率可以达到98.6%。
受语音分类器对自然噪声的相对鲁棒性的启发,Rajaratnam等人[72]提出了一种新的方法来防御对抗攻击。与利用音频预处理来检测对抗样本不同,他们将随机噪声添加到特定的频带,然后通过计算训练数据集中对抗和良性样本的识别分数来找到一个阈值。识别分数小于阈值的测试样本被视为对抗样本。此外,为了使防御方法更具鲁棒性,他们利用集成方法对不同配置下的识别分数进行了组合。实验结果表明,他们的检测方法达到了91.8%的准确率和93.5%的召回率。
Kwon等人[73]根据音频修改对输入添加低失真后,对比转录结果的差异,利用这种差异来检测对抗样本,不同的转录结果被视为对抗样本。实验结果表明,他们的方法能够成功地检测Carlini等人[18]生成的对抗样本。但是,他们的检测方法需要原始的样本和对应的对抗样本,这在实践中是不现实的,因为防御者不能同时获得两类样本。
由于音频序列具有明显的时间依赖性(temporal dependency,TD),Yang等人[74]提出了一种基于时间依赖性的对抗样本检测方法,方法流程如图8所示。
在图8中,给定一个音频序列,首先分别计算输入音频全部和前k部分转录结果得到Swhole、Sk,然后比较Swhole的前k部分S{whole,k}与Sk。对于正常样本,S{whole,k}和Sk是相似的。对于对抗样本,由于失去了TD,S{whole,k}和Sk将产生很大差距。实验结果表明,他们的方法可以检测Yuan等人[17]、Carlini等人[18]和Alzantot等人[19]提出的方法产生的对抗样本。他们的方法为研究对抗攻击提供了一种新颖的思路。
与Yang等人[74]类似,Ma等人[75]提出了一种基于音频和视频流时间相关性的高效、直观的检测方法。根据对抗样本中音频和视频之间的关联低于正常样本的特点,利用同步置信度作为音视频相关性的阈值,低于阈值的分数将被视为对抗样本。实验结果表明,该方法能够成功检测Carlini等人[18]生成的对抗样本。
4.3 对抗防御总结
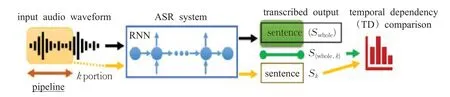
图8 基于时间依赖的音频对抗样本判别方法Fig.8 Pipeline of temporal dependency based method for discriminating audio adversarial examples
本节从主动和被动防御两个方面总结了对抗防御的研究现状。主动和被动防御方法各有优劣。对于主动防御方面,主动防御方法需要较多的训练数据和训练时间,但是有较好的防御能力。对于被动防御方面,被动防御方法需要压缩、采样率改变等转换方法,时间相对少,但是防御效果可能会较差。研究音频对抗样本的通用防御方法,权衡时间和效率是极为关键的,同时也要结合音频的特点,如时序性、声学信号处理等。
5 面临的挑战与解决办法
尽管ASR对抗样本研究已经取得了一些有前景的成果,但在最先进的方法和用户期望之间仍存在差距,这表明人们仍然需要在该问题上持续探索。另外,ASR系统中存在对抗样本的内在原因也有待研究。就目前来说,还面临着不少挑战,接下来分别对攻击和防御两方面进行阐述。
5.1 对抗攻击
前文已分别对白盒和黑盒假设下的普适性、鲁棒性和距离度量三个方面对抗样本生成方法进行了总结。通过总结可以发现,为了构造有效的音频对抗样本,目前仍有以下问题需要解决。
5.1.1 构建全面的对抗攻击
在对抗样本研究领域中有黑盒和白盒攻击场景,白盒攻击场景为对抗样本研究的基础场景,研究者期望首先对白盒攻击研究以实现黑盒攻击。因此现有的对抗样本生成方法研究大多针对白盒攻击场景。通过前文对于白盒攻击场景下的总结,现有的工作只针对普适性、鲁棒性、隐蔽性中的单个方面。然而在实际应用场景下,这是不够的,所以需要构建全面的对抗样本生成方法。构建方法可以采用集成策略,通过集成现有的普适性、鲁棒性、隐蔽性研究中的方法。此外,(1)研究能够直接产生具有多个性质的对抗样本生成方法也是一个思路。(2)通过攻击和防御的博弈也是提升对抗样本攻击效果的一个必要条件。
5.1.2 对抗样本迁移性
图9(a)为单个目标模型A的对抗样本实例。在图9(a)中,模型A是目标模型。对应的线为目标模型的决策边界。如果样本在目标模型的边界内,则该样本被目标模型A正确地识别。否则,沿目标模型的边界生成对抗样本X1。

图9 迁移性对抗样本Fig.9 Examples of transferability
可迁移性(transferability)的概念是,针对单个模型的对抗样本有可能攻击同一类型数据的其他目标模型。在图9(b)中,X2、X3都是模型A的对抗样本,同时X2也可以使得模型B产生错误结果,X3可以使得模型A、B、C全部产生错误结果。X3作为模型B的对抗样本也可以迁移到模型C使其产生错误。
通过研究对抗样本的可迁移性,攻击者可以在白盒条件下生成具有迁移性对抗样本,然后利用对抗样本迁移性攻击未知黑盒ASR系统。相比文献[58-59]等基于替代模型和进化算法的工作,迁移性攻击具有更好的研究前景和现实意义。在图像领域,研究人员利用集成方法使对抗样本具有一定的可迁移性[76]。然而,关于语音对抗样本的相关研究较少。Cisse等人[77]的方法表明,针对DeepSpeech2[78]系统生成的对抗样本对Google Voice具有一定迁移性。Kreuk等人[79]的方法表明,对抗样本可以保持在同一架构下的不同数据集上训练的两个模型之间的可迁移性。因此,构建更多可迁移的对抗样本可从以下两个方面考虑:一方面,类似对抗防御,研究数据层面的操作(如数据转换)对样本的影响;另一方面,在模型层面,研究深度神经网络的可解释性[80],通过分析模型的架构、参数和预测以生成ASR系统的迁移性对抗样本。
5.1.3 对抗样本隐蔽性
在图9(a)中,攻击者希望原始样本X和对抗样本X1之间的距离尽可能小,即添加的对抗扰动尽可能隐蔽。现有的对抗样本生成方法,因为攻击成功率往往和扰动量级成反比,所以攻击者需要权衡对抗扰动量级和攻击成功率之间的比例。在这种权衡下生成的对抗样本质量并不够好,总能够听到远离音频本身的杂音。在对抗样本研究前期工作中,Vaidya等人[12]、Carlini等人[13]通过微调音频的声学特征直至音频被ASR系统误读,然后将微调过的特征重构回语音波形以生成对抗样本。Yuan等人[17]提出了CommanderSong,将恶意命令注入到歌曲中。因此,是否可以借鉴上述工作,转变一下思路不寻求扰动的最小,而是寻求有现实意义的对抗扰动。可以从以下两方面考虑:(1)可以研究将对抗样本重构成不同于原始音频的内容如歌曲音乐。(2)可以将生成的对抗扰动修改为背景音乐,在保持对抗性的基础上更不易被怀疑。此外,因背景音乐对抗扰动会远离决策边界,可能会具有较高的迁移性。
5.2 对抗防御
对抗样本存在的原因目前仍是一个悬而未决的问题,如何保证ASR的安全性也是一个挑战。本节将从主动防御和被动防御两方面阐述现有方法的问题并探讨一些可行的改进策略。
5.2.1 主动防御
对抗训练以及集成对抗训练确是防御对抗样本攻击的基础方法,但是也存在着很大的局限性。(1)对抗训练会大幅度降低模型对正常样本的识别准确率,这一现象称为标签泄露[81-82]。(2)对抗训练需要不断输入新类型的对抗样本,从而不断提高模型的鲁棒性。为了保证模型不被新型攻击方法攻破,需要使用多种方法生成高强度的对抗样本,并且网络架构要有充足的表达能力。最关键的是,无论使用多少混合原始和对抗样本的数据集进行训练,都会存在新的对抗样本能够对网络进行欺骗和攻击。尽管有不少的防御方法,但是也无法完全区分对抗样本和正常样本,对抗攻击的安全隐患依然存在。
Sun等人[61]提出了动态对抗训练来提高语音分类网络的鲁棒性。然而,尚无研究证明对抗训练可以使ASR系统具有鲁棒性。因此,需要进一步研究对抗样本进行对抗(再)训练对ASR系统鲁棒性的影响。此外,利用语音增强去噪,对ASR系统的输入进行预处理,也是一种有前景的防御对抗样本的方法。如Latif等人[64]、Esmaeilpour等人[65]使用不同的生成模型消除对抗扰动。
5.2.2 被动防御
虽然近年来提出了多种对抗防御方法,在有效性方面,对抗性训练表现出较好的性能,但计算成本很高。在效率方面,许多基于随机的防御/检测系统的配置只需几秒钟。因此被动防御研究仍具有前景。在识别系统方面,Zeng等人[71]利用ASR的多样性差异识别结果来检测对抗样本;Yang等人[74]提出了一种基于时间依赖性的对抗样本检测方法;Kwon等人[73]利用ASR对扰动样本和正常样本的不同识别结果来检测对抗样本。因此,可以考虑使用ASR系统和音频信号本身的特点,如声学特征处理、时序依赖等快速检测对抗样本。此外,结合图像领域对抗攻击和防御的研究[83-88]看,最近的许多论文表明很多防御方法并没有他们声称的那样有效。所以应当考虑研究权衡准确性和有效性的可证明防御理论。
6 结束语
最近的研究表明,基于DNN的系统容易受到对抗样本的影响。在图像领域已经对对抗攻击和防御进行了广泛研究。但在语音领域,在ASR场景下,研究相对分散,所以本文回顾了ASR领域现有的对抗样本生成方法。在对抗防御方面,对主动和被动防御的方法进行了综述。通过对现有的对抗样本攻击和防御技术的回顾,探讨了对抗样本在ASR领域的发展,并提出了面临的挑战以及未来的研究方向。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
北京航空航天大学学报(2021年7期)2021-08-13
科技研究·理论版(2021年22期)2021-04-18
空间科学学报(2020年6期)2020-07-21
农业机械学报(2020年2期)2020-03-09
中国惯性技术学报(2019年3期)2019-10-15
中华建设(2019年7期)2019-08-27
中国惯性技术学报(2019年6期)2019-03-04
电脑知识与技术(2016年28期)2016-12-21
