
林火视频烟雾检测算法综述
2022-07-21 09:44朱弥雪刘志强李文静苏佳新
计算机工程与应用 2022年14期
朱弥雪,刘志强,张 旭,李文静,苏佳新
1.内蒙古工业大学 信息工程学院,呼和浩特 010080
2.内蒙古建筑职业技术学院,呼和浩特 010020
火灾对自然环境的影响体现在改变全球碳循环、植被更新、土壤性质和气候变化等方面,对社会的影响体现在危及生命和公共财产安全,造成巨大的经济损失。由于森林、草原火灾一旦发生就难以控制和扑灭,因此对火灾的及时检测非常重要。大火未至,烟雾先到。火灾发生时,烟雾往往比明火出现得要早且前期特征更为明显,若能及时准确地检测到烟雾,则对于火灾预警和扑救都有重大意义。烟雾探测器不仅易受环境中粉尘等细小颗粒的干扰,而且只有当烟雾达到一定浓度时才能引发警报。由于户外环境空旷、空气流动等因素导致烟雾易飘散,使得烟雾探测器的检测精确度大幅降低。视频烟雾检测技术凭借其成本低、监控范围广的优势有效弥补了烟雾探测器的不足,尤其适用于森林、草原等场所,众多学者对其开始研究。
基于可见光图像和视频的烟雾检测是烟雾检测领域的重要研究方向,不仅极具理论研究价值,且在实际应用中也取得了一些成果。例如王晓薇等[1]利用烟雾的运动、纹理和烟雾的颜色特征,结合深度置信网络(deep belief networks,DBN)来检测烟雾,鲁棒性较好。郝建红等[2]提出ELU激活函数,替换卷积神经网络[3](convolutional neural networks,CNN)中的Sigmoid、Tanh和RELU激活函数,能够提高烟雾检测准确率,降低误检率和漏报率,同时还提高了模型训练速度。
为综合分析和了解现今各种深度网络模型在烟雾检测中的应用,首先介绍了烟雾检测存在的难点问题,分析了传统视频烟雾检测算法的不足;其次探讨了烟雾检测常用的深度网络模型,对比分析其优势和不足,又根据研究动机对视频烟雾检测改进算法进行分组对比,总结现有模型和方法在实际应用中存在的优势和不足,最后讨论了视频烟雾检测算法的进一步研究方向。
1 烟雾检测的研究背景
1.1 烟雾检测的难点
森林防火要求“打早、打小、打了”,因此烟雾检测不仅对算法的实时性要求较高且对检测精度也有着极高的要求。现有烟雾检测算法还不能完全满足烟雾检测的要求,其主要面临的主要挑战如下:
(1)待检测视频背景复杂。不仅有树木等的遮挡,还存在类烟雾干扰、光照变化影响等。(2)烟雾自身特性变化问题。烟雾为非刚性物体,形状、颜色、纹理易随时间变化导致无法提取到烟雾最本质的特征。(3)烟雾检测对实时性的要求高。为保证检测精度难以避免网络层数增加、参数变多、计算量增大的问题,导致实时性提升受到一定的限制。(4)获取真实火灾烟雾样本难度大,现有样本多是人为模拟火灾的烟雾,存在样本不足且背景单一、样本不平衡的问题。
1.2 传统视频烟雾检测算法
大多数传统的视频烟雾检测算法采用模式识别过程,模式识别过程主要包括特征提取和分类,由人工提取特征和设计识别器。在提取候选区域后,利用静态和动态烟雾特征进行烟雾识别。虽然相较于探测器取得了一些进展,但大多数算法仅对火灾的快速探测有效,难以提取到烟雾最本质的特征,检测过程也相对缓慢。刘长春等[4]利用HSV(hue、saturation、value)颜色空间,计算连续帧的局部区域信噪比来提取烟雾的动态变化特征,检测烟雾发生区域,然后结合LBP(local binary patterns)纹理特征采用支持向量机区分出烟雾区域。该模型在其测试数据集上平均检测精确率较高,但其误警率较高。王韦刚等[5]提出TDFF(triple multi feature local binary patterns and derivative gabor feature fusion)烟雾检测算法,捕捉到更清晰的纹理特征和优化的图像边缘灰度信息,该算法在文中数据集上的平均检测率较高,误警率较高。
传统视频烟雾检测方法虽取得了一定的效果,但仍存在着以下问题:(1)准确性差。特征提取需要依靠专业知识进行人工特征选择,存在特征设计不合理及外在因素干扰,例如光照、背景等,导致识别效果差。(2)鲁棒性差。传统视频烟雾检测算法通常只在某一场景下检测效果好,而不适用于其他场景。
与传统视频烟雾检测方法不同,基于深度学习的视频烟雾检测算法能实现端到端、自动选取烟雾特征,特征种类和规模更加丰富,这在一定程度上解决了传统视频烟雾检测算法鲁棒性差的问题。
2 基于深度学习的视频烟雾检测算法
深度学习(deep learning,DL)是机器学习(machine learning,ML)领域的重要研究方向。越来越多的学者开始研究运用深度学习来检测烟雾,研究人员提出多种网络结构,例如AlexNet[6]、VggNet[7]和ResNet[8]等,借助多层结构逐级提取图像特征,相比传统方法精度更高、鲁棒性更好、实时性更好。
基于深度学习的烟雾识别算法可分为基于区域提取的检测模型、基于回归的检测模型和基于卷积神经网络改进的烟雾检测算法。其中,基于区域提取和基于回归的检测模型同属深度学习的目标检测领域,两者主要区别在于基于区域提取的检测模型需先划定目标候选区,而基于回归的检测模型则不用,这使得基于区域提取的烟雾检测算法可以得到较好的检测精度,但实时性相对较差;基于回归的烟雾检测算法精度稍逊色,但更能满足烟雾检测对实时性的要求。
2.1 基于区域提取的烟雾检测算法
R-CNN[8](region-CNN)系列算法的核心是卷积神经网络,它具有局部连接和权值共享优势。两阶段目标检测器采用了两段结构采样来处理类别不均衡的问题,生成候选区(region proposal network,RPN)使正负样本更加均衡,使用两阶段级联的方式来拟合边界框,先粗回归,再精调。两阶段目标检测速度较慢,但精度较高,由于火灾检测对实时性要求较高,因此在检测烟雾时很少有学者使用该系列方法。
R-CNN[9]的主干网络为VGG-16网络,特征提取、分类、回归并不能同时训练,需要先把每一阶段的结果保存在磁盘上再输入下一阶段。由于它的RPN和非极大值抑制(non-maximum suppression,NMS)算法通过选择性搜索算法工作都是由中央处理器(central processing unit,CPU)计算完成的,因此消耗了大量的计算和时间,完全达不到烟雾检测对实时性的要求。
Fast R-CNN[10]将特征提取器、分类器、回归器合并,不再将每段结果保存磁盘单独训练,可以一次性完成。受到SPPNet[11]的启发,Fast R-CNN加入ROI(region of interest)层处理候选区域的特征,不仅提高了检测速度,也提高了检测准确率,但其缺点在于候选框的提取使用选择性搜索,检测时间大多消耗在这里。
在Faster R-CNN[12]中,添加生成候选区移除选择性搜索,真正意义上做到端到端,把物体检测整个流程融入到一个神经网络中,选择性搜索按照颜色和纹理不断合并得到候选区域,其产生没有规律,而RPN是每个Anchor都有对应的固定数量的候选区域,精确度更高,但RPN网络需要额外训练,增加了训练负担。
2.2 基于回归的烟雾检测算法
与基于区域提取的目标检测算法相比,基于回归的目标价检测算法不需要先获取候选区域,通常具有更快的检测速度且更适用在烟雾检测等对实时性要求较高的场景中。YOLO(you only look once)和SSD(single shot multibox detector)是单阶段目标检测中的经典算法。
2.2.1 YOLO系列
Redmon等提出了YOLO系列,其核心思想是把目标检测转变成回归问题,利用整张图作为网络的输入,仅经过一个神经网络得到边界框的位置及其所属的类别,与Faster R-CNN相比精度有所降低但速度较快,更能满足烟雾实时性检测的要求。
YOLO v1[13]是基于GOOGLENET自定义的网络,比VGG16速度快,但是精度相对略低。其所使用的误差损失函数、定位误差是影响检测效果的主要原因,尤其对于小的边界框影响更大。它直接对边界框的位置进行预测,这样做虽简单,但由于没有类似R-CNN系列的推荐区域,所以网络在前期训练时困难,很难收敛。YOLO v1的一个网格只预测两个框,并且只属于同一类,因此对相互靠近的物体以及烟雾小目标群体检测效果较差,且对于视频中不常见角度拍摄的烟雾泛化性能更弱。
YOLO v2[14]使用Darknet-19作为特征提取网络,在每一层卷积后增加批量标准化(batch normalization,BN)对数据进行预处理(统一格式、均衡化、去噪等),这样网络就不需每层都去学数据的分布,收敛会变得更快,因此能够提高训练速度,提升训练效果。相比于YOLO v1利用全连接层直接预测边界框的坐标,YOLO v2借鉴Faster R-CNN的思想,引入Anchor机制,利用K-means聚类方法在训练集中聚类计算出更好的Anchor模板,提高了算法的召回率。YOLO v2通过添加Passthrough Layer,把高分辨率的浅层特征连接到低分辨率的深层特征进行融合和检测,提升模型性能,更加利于烟雾早期的小尺度检测,但是当数据集过小时容易产生过拟合问题。
YOLO v3[15]将YOLO v2的骨干网络Darknet-19改进为Darknet-53。Darknet-53在每个卷积层之后加入一个批量归一化层和一个Leaky ReLU,以防止过拟合。借鉴DSSD(deconvolutional single shot detector)的做法,YOLO v3加入跳跃连接和上采样,以实现高层和底层的融合,使用多尺度的特征图来预测结果,使得对小目标烟雾的检测效果更好;引入残差网络思想,让网络提取到更深层特征,同时避免出现梯度消失或爆炸;将网络中间层和后面某一层的上采样进行张量拼接,达到多尺度特征融合的目的,以有效检测图中不同尺寸的烟雾,一定程度上提高了易飘散的烟雾的检测率,但存在识别物体位置精准性较差且召回率较低的问题。
YOLO v4[16]的主干特征提取网络CSPDarknet-53是由YOLO v3的Darknet53改进过来的,将Darknet-53与CSPnet[17]结合,将原来残差模块的堆叠进行拆分,另外添加了一条捷径分支从输入直接连通到输出,目的是为了保留部分浅层特征,避免丢失太多信息,实现对图片信息进行浅层的初步提取;使用Mish激活函数代替Leaky ReLU,使信息在深度神经网络中更好地传播,从而提高准确性和泛化性;引入空间金字塔池化(spatial pyramid pooling,SPP)结构和PANet[18](path aggregation network)结构,SPP结构是使用不同尺寸的池化核对卷积后的输出进行最大池化,从而极大地增加感受野,分离出最显著的上下文特征,但是当烟雾和天空相似时,最大池化由于只保留每个池的最大值信息,很容易误把天空信息保留下来而丢失了烟雾信息;通过PANet的卷积,上采样以及堆叠和下采样操作对三个不同尺度的特征层进行反复的特征提取,最终将三个初步提取出的特征层进行特征融合,将浅层的语义信息和深层信息堆叠在一起,获得更丰富且更有效的特征层。由于在YOLO v4中采用了大量的残差块,在特征金字塔部分又反复进行特征提取和频繁进行特征融合,导致运算参数量大,内存占用大,且运行速度一般。
YOLO v5在工程应用中相较于YOLO v1~v4效果更好,它采用了跨领域网格,并在不同输出层匹配,极大地扩增了正样本anchor,加速模型收敛速度并提高模型召回率。其整体结构与YOLO v4相差不大,YOLO v4的Neck结构中采用的都是普通卷积,而YOLO v5的Neck结构采用借鉴CSPnet设计的CSP2结构,加强网络特征融合能力。YOLO v5改变了对正样本的定义,在YOLO v3中,其正样本区域也就是anchor匹配规则为IOU最大,而YOLO v5采用shape匹配规则并且将GT(target grid)的中心最邻近网格也作为正样本anchor的参考点,增加了高质量的正样本anchor能够加速模型收敛并提高召回,但是在置信度方面,模型将与GT的IOU过小的低质量anchor引入计算BCE,因此模型容易产生误检,即将非目标推测为目标物体,并且YOLO v5更适合用于检测大目标烟雾。
2.2.2 SSD系列
SSD[19]与YOLO同属于单阶段的目标检测算法,但它吸收了Faster R-CNN的一些长处,在不损失精度的情况下保持了快速的特性。SSD采用VGG16作为基础模型,在其基础上利用多尺度的特征图做检测;它利用类似Faster R-CNN模型中的Anchor机制和YOLO模型中的端到端思想,模型的推理速度有一定的提升,能在一定程度上平衡烟雾检测所要求的精度和实时。但是SSD网络中预选框的基础大小和形状不能直接通过学习获得,需要手工设置,导致调试过程非常依赖经验。
DSSD[20]使用ResNet替换SSD中的VGG网络,模仿特征图金字塔网络(feature pyramid networks,FPN)进行特征融合的思路,使用反卷积对高层特征上采样后与浅层特征结合,增加浅层语义信息来提高小目标烟雾检测的准确性,然而由于其模型复杂度增加,检测速度较慢。
RSSD[21]利用分类网络增加不同层之间的特征图联系,减少重复框的出现,增加特征金字塔中特征图的个数,使其可以检测更多小尺寸烟雾,以略微降低速度的方式提高检测准确率。
FSSD[22]提出特征融合模块(feature fusion module),把某些特征调整为同一尺寸后连接,得到一个像素层再生成金字塔特征图。该方式与FPN相比,只需要融合一次,较为简单,提高了对小目标烟雾的检测精度。该算法与DSSD相比检测速度有所提升,但与SSD算法相比其检测速度有所下降。常见的烟雾检测算法优缺点对比如表1所示。
2.3 基于深度学习的烟雾检测改进算法对比分析
为有效分析现有视频烟雾检测算法的优点和不足,将烟雾检测改进算法按照其研究动机进行分组对比。主要归纳为烟雾背景复杂、特征提取不完全、实时性差以及数据集问题四种。
2.3.1 背景复杂问题
在森林、草原等户外场景中,背景天空有时会与烟雾颜色相近,难以区分。烟雾视频中不仅包含烟雾,还有其他无关背景信息,例如与烟雾颜色相近的白云、湖面、雾气等。类烟雾在颜色和纹理特性上与烟雾非常相像,因此在烟雾提取特征时非常易受背景环境的干扰,导致误检率高。自然环境中的光照变化也会带来干扰,引起图像的某些特征发生变化,影响图像后续处理,如特征提取、识别等。强光时某些物体反射形成类烟雾,弱光的情况下噪声会比较多,影响识别率。针对背景复杂问题烟雾检测改进方法对比如表2所示。
在原有深度模型的基础上融合背景差分算法、ViBe算法、混合高斯模型算法、光流法等烟雾运动检测算法可以有效减少背景中类烟雾的干扰,降低误检率。但是,基于烟雾运动特性筛选候选区在烟雾本身变化缓慢或远距离摄像导致的变化缓慢时检测精度会有所降低。叶寒雨等[33]提出将图像输入LiteFlowNet3网络中得到烟雾的光流估计,再使用YOLO v4检测图像中潜在移动物体,去除其他移动物体的光流,最后对最终的光流估计进行降噪处理。该方法减少了运动物体的干扰,提高了检测准确率。但是模型较大且对视频质量要求较高。Sheng等[34]图像结合CIELAB颜色空间,利用简单线性迭代聚类SLIC对其进行分割,生成具有烟雾区域光谱特征的超像素图像。然后利用基于密度的空间聚类应用与噪声(DBSCAN)将相似的超像素聚类成簇,进而利用CNN提供更好的烟雾探测精度。利用SLIC分割后的图像减少了背景当中类烟雾的干扰,该方法鲁棒性较好对烟雾图像的分类性能有所提高。但是SLIC对于混合超像素图像会造成识别精度的失真,且DBSCAN在原始图像中的参数选择比较困难,导致该方法误报率高。Pundir等[35]提出一种基于双深度学习框架的烟雾检测方法。首先采用深度学习框架从烟雾斑块中提取基于图像的特征,采用超像素算法提取图像特征,包括烟色、烟纹理、锐边检测和周界无序分析。第二个深度学习框架用于提取烟雾运动区域、增长区域和上升区域检测等基于运动的特征;采用光流法对烟雾的随机运动进行捕捉。将这两个框架的特征结合起来训练支持向量机和端到端分类器。该算法减少了对云、雾、沙尘暴、云和水上云图等非烟雾对识别结果的影响,精度和鲁棒性较好,但是网络参数较多、模型过大。

表1 常见的烟雾检测算法优缺点对比Table 1 Comparison of advantages and disadvantages of common smoke detection algorithms
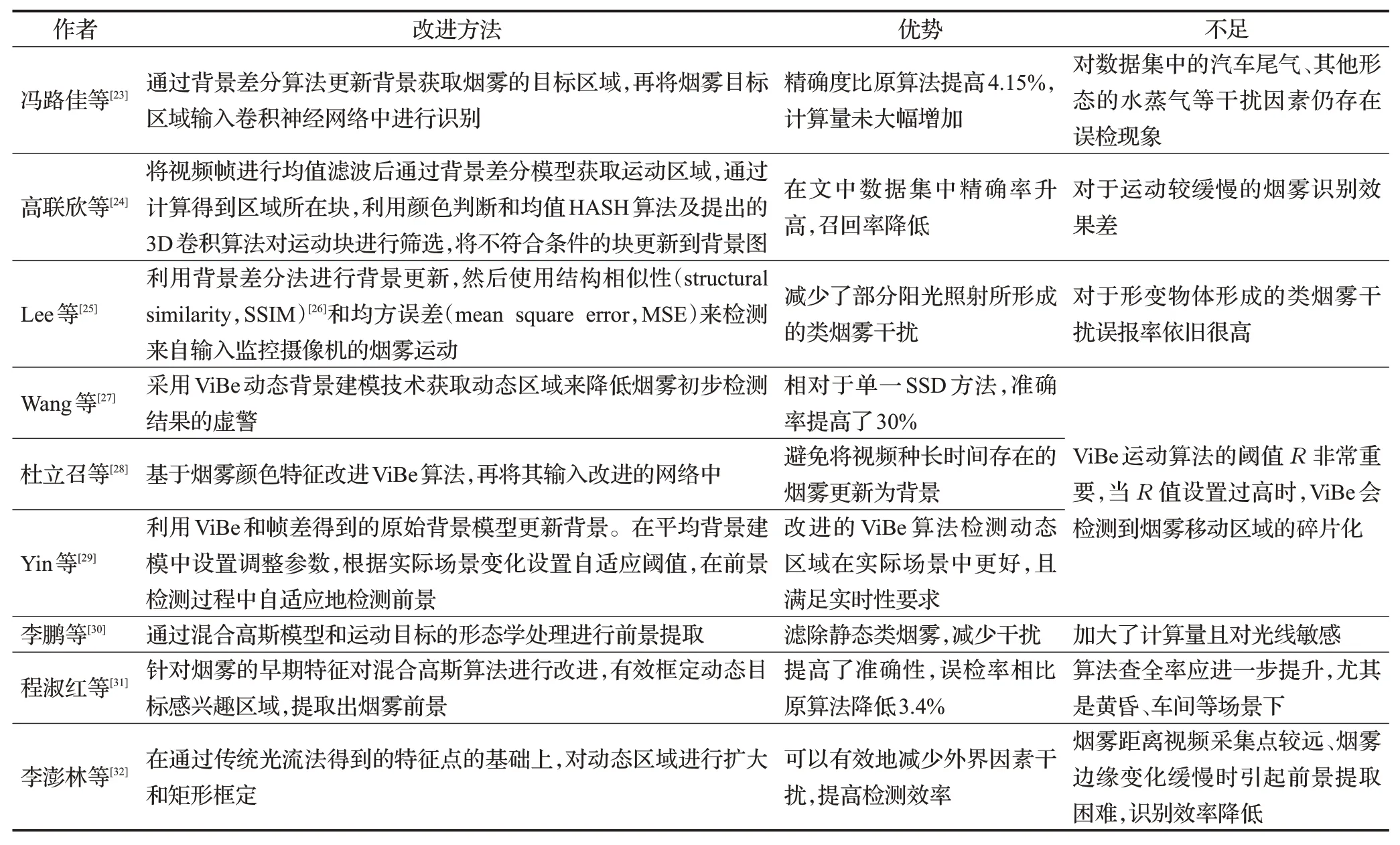
表2 针对背景复杂问题改进的烟雾检测方法对比Table 2 Improved method of smoke detection for complex background problems
2.3.2 特征提取问题
烟雾具有丰富的特征,如颜色、纹理、形状、运动等,利用这些特征可以将烟雾与其他物体区分开来。很多烟雾检测算法主要基于单一特征或烟雾的多个静态特征融合,这会导致检测精度低,深度学习自动提取烟雾特征,有效避免了主观影响,在一定程度上提高了烟雾探测性能,对于识别较为稀薄的烟雾准确率也能有一定提升。
高联欣等[24]提出多尺度3D卷积神经网络(6M3DC)(如图1所示)来进行视频烟雾检测,使用3D卷积从不同尺度去提取烟雾的特征,之后将其融合在一起,保持多尺度特征的共存。使用Global Average Pooling 3D来增强特征图内的响应,每块前面都接上BN层,提高训练速度的同时防止网络加深产生的梯度扩散问题。3D卷积除了从空间特征的角度,还在时间角度上进行检测判断,提高了精确率和稳定性,但是对远距离烟雾的平均召回率较低,有待于进一步提升。
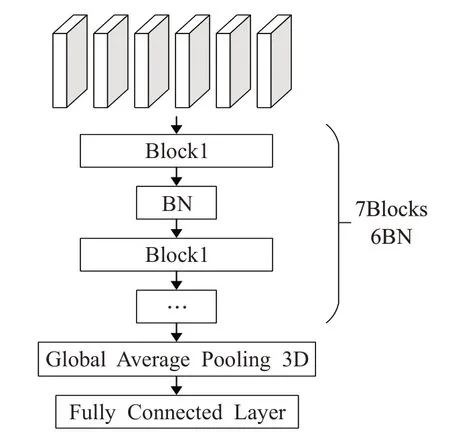
图1 6M3DC结构Fig.1 6M3DC structure
Bai等[36]选择YOLO与VGG网络相结合,提高对小烟雾和小火焰的识别率。对于VGG网络只保留其特征提取层,改进其全连接分类层,将原来的3层全连接层改为第2层,从而减少网络参数量,利用Leaky ReLU激活函数,增加Dropout层防止过拟合,得到收敛速度更快的分类网络,并显著提高了单幅图像的识别速度。在YOLO网络中增加F-CSP网络(如图2所示)模块后仍不能满足精度要求,因此又增加了分辨率较小的特征尺度分支,充分学习浅层特征,从而提高网络对多尺度特征的集成能力。该算法检测精度和实时性有所提升,能在一定程度上满足烟雾检测的需求,但随着新的特征尺度的增加,网络复杂性也会增加。
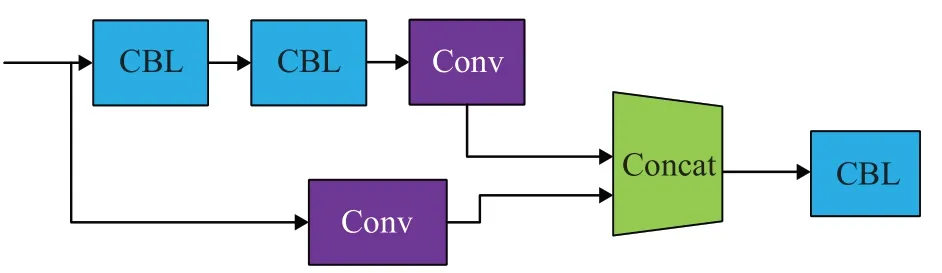
图2 F-CSP结构Fig.2 F-CSP structure
谢书翰等[37]在YOLO v4网络预测头加入通道注意力模块SENet[38](如图3所示),虽然带来了少量的参数但是提升了网络预测头对特征信息的提取能力,从而提升了网络性能。使用K均值聚类(K-means)为烟雾数据集生成新的候选框尺寸,选择符合烟雾大小特征的候选框尺寸有助于烟雾预测框位置的回归,通过精简损失函数、剔除分类误差,使算法收敛更快。该算法的检测精度和召回率都有所提升,但修改后的网络参数增多、模型变大,每秒检测帧率降低。
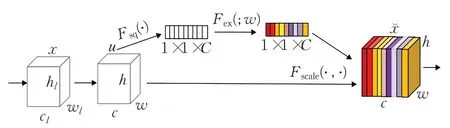
图3 SENet结构Fig.3 SENet structure
汪梓艺等[39]提出改进DeeplabV3网络算法,在最后一个级联的空洞卷积后,增加扩张率较小的两个单元,使采样点更加密集,增强像素间的交互关系,消除网格效应。为进一步恢复烟雾的空间细节,在特征图融合前,引入自己设计的通道注意力机制CAM模块(如图4所示)。该模型的检测率较高,有一定的实用价值,但是处理效率与实际需求仍有差距,运算效率较低。
Cai等[40]提出YOLO-SMOKE模型,在YOLO v3的基础上利用高效通道注意模块(efficient channel attention module,ECA)[41](如图5所示)对残差模块进行细化,提高模型的精度和鲁棒性。在每个卷积层后添加dropblock,避免了公共数据集背景过于简单而导致模型过拟合。该方法具有较好的精度和鲁棒性,网络结构加深带来更好表征能力的同时也增大了网络参数量,每秒检测帧率降低。
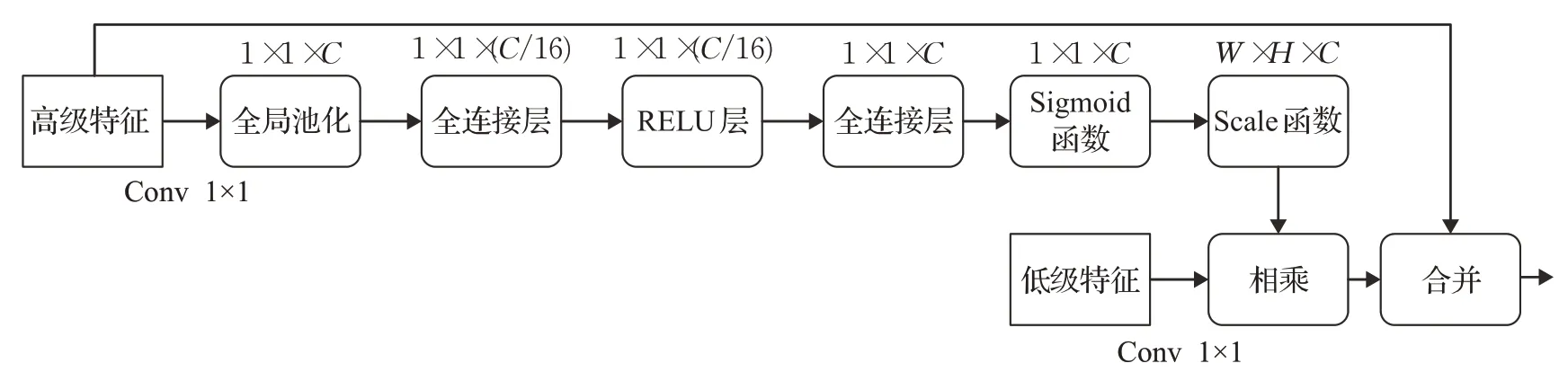
图4 CAM结构Fig.4 CAM structure
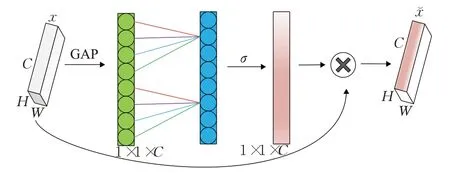
图5 ECA-Net结构Fig.5 ECA-Net structure
Zhang等[42]设计了基于CBAM[43](如图6所示)注意力机制的卷积神经网络模型,通过对图像中具有明显分辨能力的区域进行聚焦,在骨干网的辅助下提取更精确的局部特征进行火灾烟气识别骨干网络用于粗略提取图像特征;分支网络用于针对特定区域提取细粒度的图像特征。网络通过注意提议网络预测候选区域,并对候选区域进行放大,再通过分支网络提取精细特征;结合两种不同尺度的图像特征,通过全连通层和softmax层对最终结果进行预测。该模型的泛化能力较好,误报率较低,在准确率上有很大的提高,但是注意力机制的加入还是增加了少量网络参数。
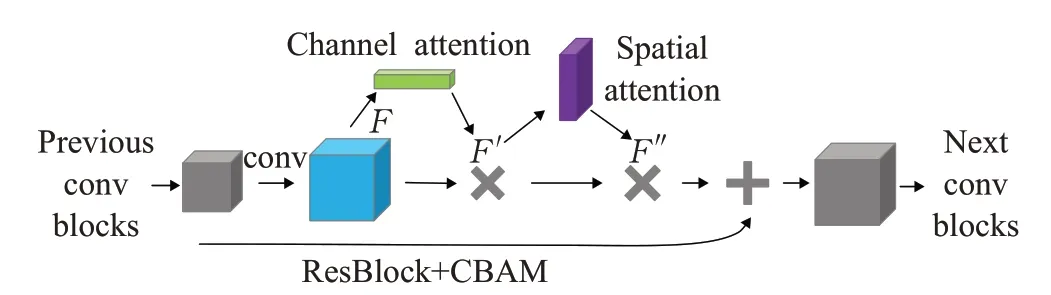
图6 CBAM+ResBlock结构Fig.6 CBAM+ResBlock structure
网络模型的特征提取能力极大地影响烟雾检测效果。当深度学习模型网络层数较小时,虽然计算量小,但是提取烟雾细节特征较为困难,可以通过增强主干网络的特征提取能力来解决该问题:一是增加网络深度,然而网络深度过大时,可能会出现梯度消失问题,导致更高的检测误差,因此在增加网络深度时应权衡网络特征提取能力与其深度,不宜过深;二是改善特征提取层,增大感受野、融合残差模块、注意力机制模块等以更好地提取烟雾特征。更多针对特征提取改进的烟雾检测算法如表3所示。
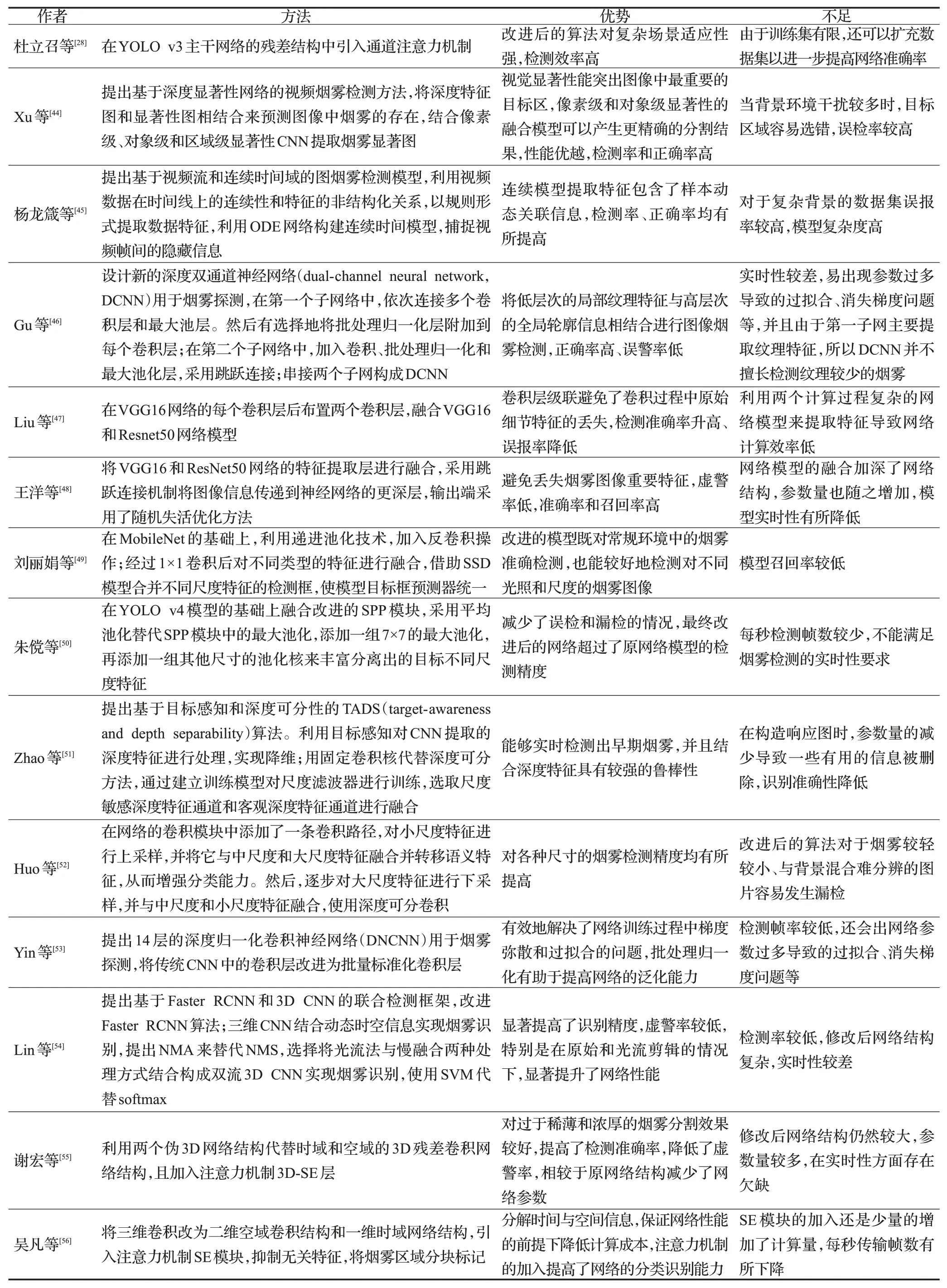
表3 针对特征提取问题改进的烟雾检测改进方法对比Table 3 Comparison of improved smoke detection methods for feature extraction problems
2.3.3 实时性问题
烟雾检测对实时性的要求极高,但大多视频烟雾检测算法为追求高精度,增加了网络层数,从而网络参数变多、计算量变大,导致算法实时性降低。针对实时性问题改进的烟雾检测算法对比如表4所示。
实时性改进的本质就是改小网络结构、减少参数量、减少计算量。其技术路线主要有以下方法:
(1)轻量网络设计。对现有网络进行优化加速,例如采用深度可分离卷积代替标准卷积块;重新设计新型网络结构。
(2)模型裁剪。在保持现有模型的准确率基本不变的前提下,在某个尺度上筛选掉卷积层中重要性较低的权重,从而达到降低计算资源消耗和提高实时性的效果。
(3)模型蒸馏。利用大模型的监督特征帮助计算量较小的模型达到与大模型相似的精度,实现模型加速。
2.3.4 数据集问题
真实场景的火灾烟雾数据样本难以获取。现有的烟雾数据集大多为人工模拟火灾的烟雾,存在数量少且背景单一的问题,与实际应用场景差距较大。
(1)样本不足问题
现有的几乎所有的深度学习方法都依赖于大量的标注数据,因此样本的不足会限制烟雾检测深度模型精度的提升。但是对于小样本的烟雾对象,采集大量的数据是一个挑战。Xie等[62]介绍了两种可控烟雾图像生成神经网络(CSGNet和CSGNet-v2)来生成烟雾图像。首先提出基于CSGNet的多尺度烟雾图像生成算法,该算法将烟雾组件控制模块和烟雾图像合成模块集成在一起,实现了烟雾图像的多尺度生成;通过改变指定的烟雾分量潜码,可以生成具有指定烟雾分量的烟雾图像;通过微调单片机中的烟雾成分潜码,对生成的烟雾图像中的烟雾成分进行微调;又在CSGNet的基础上提出CSGNet-v2,通过增加烟雾图像微调模块,使生成的烟雾图像更加逼真。Li等[63]针对烟雾样本少的问题提出了一种基于注意力的混合少镜头学习方法,在每个卷积块中添加了批量归一层,然后再添加卷积层,融入CBAM模块来进一步降低疑似烟区的误报率,设计了一个元学习模块来缓解烟雾图像有限导致的过拟合问题。与其他小样本方法相比精度、实时性较优越,但是不如Alexnet等骨干网络的检测精度高。Yin等[29]利用深度卷积生成对抗网络(DCGAN)以生成尽可能逼真的图像。Cai等[40]采用镶嵌数据增强方法对数据集进行扩充。Gu等[46]将图片随机旋转以增强数据。文献[37,40,50,64-65]采用随机裁剪,水平翻转和旋转以数据增强缓解样本少的问题。张倩等[66]将真实烟雾图像、模拟烟雾插入森林背景图像中,通过合成图像来缓解样本少的问题。Lin等[54]也采用了合成烟雾的方法来缓解数据集有限的问题。
针对真实采集的烟雾数据集有限的问题,既可以对这些数据集采用随机反转、改变亮度、添加噪声等手段进行数据增强,也可以采用部分合成烟雾来扩充数据集,减少样本较少对模型精度的影响,但是上述方法得到的样本相较于真实采集样本训练效果略微逊色。
(2)样本不平衡问题
烟雾数据集样本不均衡会导致样本量少的分类包含的特征过少,很难从中提取规律,即使得到分类模型,也容易因过度依赖有限的数量样本出现过拟合问题,当模型应用到新的烟雾数据集上时,模型的准确性和健壮性将会很差。Yin等[29]对训练样本的数据进行了增强,以解决正负样本不平衡和训练样本不足的问题。Zhang等[42]通过优化带权的交叉熵损失函数,提高了网络在非平衡森林火灾数据集上的性能。袁梅等[67]提出使用数据增强技术从原始数据集生成更多训练样本解决由于训练数据少或不平衡引起的过度拟合。

表4 针对实时性问题改进的烟雾检测算法对比Table 4 Comparison of improved smoke detection algorithms for real-time problems
数据集的扩充既可以有效缓解样本不平衡问题,又有助于提升烟雾检测算法检测效果,尽快建立公开统一的数据集是非常有必要的。
3 结语
为了综合分析深度网络模型在烟雾检测中的应用,首先介绍了烟雾检测存在的难点问题,分析了传统视频烟雾检测算法的不足;其次探讨了烟雾检测常用的深度网络模型,针对视频烟雾检测算法存在的一些难点问题,分析总结了现有烟雾检测算法在这些问题所提出的解决方法,虽在一定程度上有所改善,但未从根本上克服这些难点,距离实际工程应用还有很大距离。烟雾检测算法未来要在以下方面进行深入研究:
(1)分别建立完备公开统一的森林、草原场景下的烟雾及火灾数据集,针对现有数据集样本不足且背景单一问题扩充样本数量。
(2)改进特征提取网络及特征融合方式。针对稀薄烟雾、远景小目标烟雾检测困难,构建合适特征检测层;通过构建更深更宽的网络结构、融合残差模块与注意力模块等增强对烟雾的特征提取能力,减少复杂背景环境带来的影响。
(3)通过模型裁剪、模型蒸馏等技术减小网络模型的同时引入性价比较高的注意力机制等类似模块来提高检测精度。
(4)构建轻量级模型,用于嵌入无人机等计算力与存储有限的移动设备中,以便于更好地实时检测火灾。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
小学阅读指南·低年级版(2021年3期)2021-03-19
电子制作(2019年13期)2020-01-14
华人时刊(2019年13期)2019-11-26
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
电子制作(2019年11期)2019-07-04
电子制作(2018年19期)2018-11-14
北京航空航天大学学报(2018年1期)2018-04-20
