
建成环境非线性作用下汽车客运站最高聚集人数模型
2022-07-22 14:09唐秋生
重庆理工大学学报(自然科学) 2022年6期
唐秋生,许 浩
(重庆交通大学 交通运输学院, 重庆 400074)
0 引言
伴随着我国城镇化进度加快和国民经济水平提升,汽车客运站在设计初期因缺乏历史客流数据、最高聚集人数测算方法泛化能力低等因素所导致的场站资源浪费问题日益严重。为此,探求汽车客运站最高聚集人数在现状城市空间数据下的作用机理以完成人数测算尤为重要。传统汽车客运站最高聚集人数测算主要有3种方法:① 聚集系数法:根据最大月均乘车人数统计值和聚集系数计算;② 单向列车次数法:根据单方向发车次数和不平衡系数计算;③ 概率法:根据车站行车计划表,假设旅客服从某一分布到达场站进行人数仿真[1]。之后,众多学者针对概率法进行改进,完成对最高聚集人数的近似估计。姚加林等[2]认为因列车的出发方向不同,在概率法基础上计算的聚集人数存在统计学差异;狄智玮等[3]认为旅客聚集规律受旅客出行目的、出行方式等个人因素影响较大;李兆丰等[4]建立了多特征融合的客流预测模型,其中不仅包括旅客个人特征,还包含天气、日期等环境特征。至此,众多学者展开了基于环境特征对场站聚集人数的研究。崔叙等[5]以站域范围的兴趣点、周边房价、路网密度等数据构建旅客流量预测模型;姚加林等[6]引入城市交通环境可靠性相关指标,结合概率法探求其对场站最高聚集人数的影响机理。
参考国内外针对环境特征展开的研究,Chen等[7]在考虑空间异质性的基础上提取建成环境指标,探求针对多式联运出行方式的影响机理; Ding等[8]构建以建成环境数据为基础的交通通勤行为预测模型,以此解释空间异质性对交通行为的非线性作用;Ramezani等[9]从建成环境角度综合研究了一系列交通行为,包括活动空间、小汽车保有量、出行行为等;Hasnine等[10]将建成环境指标与区域气象指标相结合,构建网约车需求预测模型;Tu等[11]选取成都市为分析单元,探求旅客出行方式划分与建成环境间的作用机制。
综上,最高聚集人数测算研究从立足于场站自身数据(行车时刻表、车位配比等)分析逐渐转向多源数据特征提取预测。利用建成环境差异性分析交通行为获得了较好的反馈[12-13],而最高聚集人数是旅客交通行为的派生变量,故本研究从空间异质性角度考虑最高聚集人数受建成环境变化的非线性作用机理。
1 研究数据描述
1.1 研究范围
基于重庆市现有交通运输枢纽场站总量,结合实际运营情况,选取其中具备基本场站功能区且发班正常的汽车客运站作为研究对象。共得到143个有效样本,包括一级汽车客运站7处、二级汽车客运站30处、三级汽车客运站12处、四五级汽车客运站94处。区位涵盖重庆市主城都市圈、渝东南、渝东北城镇群共29个行政区县(图1)。

图1 样本数据区位分布示意图
建立于空间角度的建成环境数据分析应注意尺度效应与区划效应[14]。考虑到所有样本数据点均分布在重庆市各区县,故以重庆市行政区划作为基本分析单元。为保证建成环境指标对样本关联性,同时考虑各样本数据附近建成环境测度的异质性,参考相关建成环境划分研究成果,因汽车客运站多为区域性交通服务设施,最终选取场站为圆心、半径1 000 m形成的圆形缓冲区作为基本分析尺度。
1.2 数据获取
各样本的最高聚集人数来自重庆市各区县综合交通“十四五”发展规划中场站设施部分和地方交通局工作简报,具体报告由重庆市国际投资咨询集团有限公司提供。汽车客运站经纬度坐标由百度地图开放平台API接口爬取。建成环境数据包含至市中心距离、土地利用混合度、交叉口数量、路网密度、道路服务水平、公交站密度、地铁站密度、邻近CBD距离、发车位配比9类表征变量。其中,地理信息类数据均由Python程序通过百度API接口进行爬取,交通信息类数据由开源地图网站OSM截取,重庆市域范围路网数据通过ARCGIS软件缓冲区分析得出。
1.3 建成环境变量描述性统计
最高聚集人数受建成环境影响主要体现在可达性、公共交通支撑、路网复杂度、环境多样性。通过计算市中心的距离、邻近CBD距离表征建成环境的可达性影响,由各样本点经纬度坐标和爬取的邻近CBD经纬度坐标以及重庆市中心(选取重庆解放碑)经纬度坐标计算欧氏距离得到。公共交通环境的数据表征使用Python程序,借助百度地图开放平台计量各汽车客运站缓冲区内公交站、地铁站数量得出。路网复杂度包括交叉口数量、路网密度、道路服务水平,均由ArcGIS缓冲区工具生成数据采集范围,再利用分析工具获取。环境多样性主要由缓冲区内土地利用混合程度表征,统计缓冲区范围内工业、商业、政府、医院、公园、学校6类POI数量,完成土地利用熵指数[15]计算,见式(1)。

(1)
式中:pij为缓冲区j内第i种设施所占的比例;Nj为缓冲区j内包含的POI种类计数。
综合上述9个建成环境指标,构建各汽车客运站建成环境测度模型。建成环境变量描述性统计见表1。

表1 建成环境变量描述性统计
2 模型构建
最高聚集人数与建成环境之间的具体作用方式受交通出行人心理、年龄结构等因素影响,呈现非线性关系,传统的统计学模型难以捕捉各变量对因变量的影响程度。梯度提升决策树(GBDT)模型是一种基于集成学习的决策树算法,通过对残差的不断拟合学习逐渐提高预测精度。该模型在交通行为预测领域应用较为广泛。最高聚集人数是交通行为的派生变量,本文中尝试构建GBDT模型研究建成环境作用于最高聚集人数的非线性关系。为保证模型有效性,需对基础数据进行空间自相关分析和多重共线性检测。
2.1 空间自相关分析
地理信息领域常用莫兰指数(Moran’sI)表达变量在空间上的相关关系[16]。本文中进行假设检验,提出零假设:备选变量在空间上不存在显著相关关系;备择假设:备选变量在空间存在显著相关关系。通过ArcGIS空间相关性工具进行计算,计算结果见表2。可以发现,最高聚集人数在空间自相关分析中的p值小于0.05,拒绝零假设,说明存在显著关系;前8个变量通过p检验,说明在空间尺度下均存在统计学意义,但作为第9个变量的发车位配比p值为0.138,未通过检验,考虑其莫兰指数为0.51,值较高,故暂时保留该变量,进一步分析变量间的线性相关性。

表2 莫兰指数分析
2.2 共线性分析
构建模型的因变量为最高聚集人数,自变量为9个建成环境指标。为避免因变量间的共线关系影响模型预测精度,对变量数据集进行多重共线性检测。通过Matlab软件内置的Corr函数,对变量两两进行Pearson相关性分析,结果见表3。表3内数据结构为(R,P)。可以发现,交叉口数量与路网密度之间存在强相关关系且通过显著水平检验。考虑到交叉口与路网结构的依存关系和空间自相关分析结果,选择保留该变量;发车位配比分别与4个变量存在显著相关关系,同时考虑空间自相关分析结果,认为发车位配比不仅在空间上不存在统计学意义,还严重影响其余变量的正常表征,故剔除发车位配比变量;其余变量间均通过Pearson相关性检验,表明无显著相关关系,故保留变量x1~x8。

表3 变量共线性检验结果
2.3 梯度提升决策树模型
GBDT模型的核心思想是回归树的迭代学习,不同于分类树,其计算值以累加的形式呈现,故对损失函数L(yi,η),yi为第i个样本最高聚集人数值与预测估计值的差,η为使得损失函数最小的参数,即有:
(2)
利用负梯度下降(梯度提升)的方式不断拟合损失函数,直到达到预测精度或最大迭代步数完成学习,最终得到:

(3)

梯度提升决策树模型的具体学习步骤如下:
步骤1损失函数参数估计:初始化最高聚集人数计算模型F0(x),各回归树参照初始常数值设置进行损失函数参数η估算,有:
(4)
步骤2梯度计算:计算损失函数L(yi,η),并求偏导计算梯度:
(5)
其中:rim为负梯度,m为迭代次数,F(xi)为估计函数。
步骤3回归树参数估计:利用回归树hm(x,βj)对残差进行拟合求解,使得残差最小的回归树参数βm有:
(6)
其中:βm为第m次迭代时回归树参数;hm(x,βm)为第m次迭代时回归树的估计结果;N为样本数。
步骤4回归树权重估计:迭代到目前步骤,已完成损失函数、回归树参数估计,还需估计回归树权重系数。继续使用损失函数对回归树权重进行估计,有:
(7)
步骤5更新模型:
Fm(x)=Fm-1(x)+γmhm(x,βm)
(8)
步骤6判断精度或步数:针对当前迭代结果进行精度检验,若达到预设精度则输出最终模型;或检查迭代步数是否达到最大步数,若达到则输出模型;否则,返回步骤2继续迭代。
对于决策树类模型,因其集成学习的特殊性,可由所有基学习器(即子决策树)计算分析各个变量对因变量的影响程度:

(9)
(10)

针对上述GBDT模型,借助Python程序“sk-learn”包中“ensemble”模块进行求解,构建综合考虑建成环境影响的最高聚集人数计算模型。在建模学习过程中,需要对模型的超参数进行设置,模型学习率与学习步长通常情况下具有耦合关系,需协同调整。当学习率较大时,需要更长的迭代次数以防止过拟合;反之,当学习率较小时,需要较小的迭代次数增强模型的泛化能力。采用五折交叉验证法进行模型检验[12]。考虑研究样本数据量为143,属于偏小,故学习率和迭代步长不宜过小。为防止过拟合现象,设置学习率值为0.91,迭代步长为30;为表征所有指标对因变量产生的影响程度,并体现与OLS模型的区别,将单颗回归树深度结构控制为5,所含特征数即指标数量为8;原始样本中各指标数据由“爬虫”技术爬取,存在一定误差,故样本噪声处理系数值取0.7进行降噪处理。
3 模型结果分析
3.1 全局分析
通常使用检验集拟合优度R2来检验模型的预测情况。为体现GBDT模型在建成环境非线性作用影响下的预测精度,采用传统线性回归(OLS)和随机森林模型(RF)进行对比论证,具体结果见表4。RF模型的训练超参数设置与GBDT模型超参设置在最大程度上保持一致,设置迭代步长为30,单颗决策树深度限制为5,单颗决策树最大特征树取值为8,其余决策树叶子数量和初始数生成方法等参数均使用缺省值。
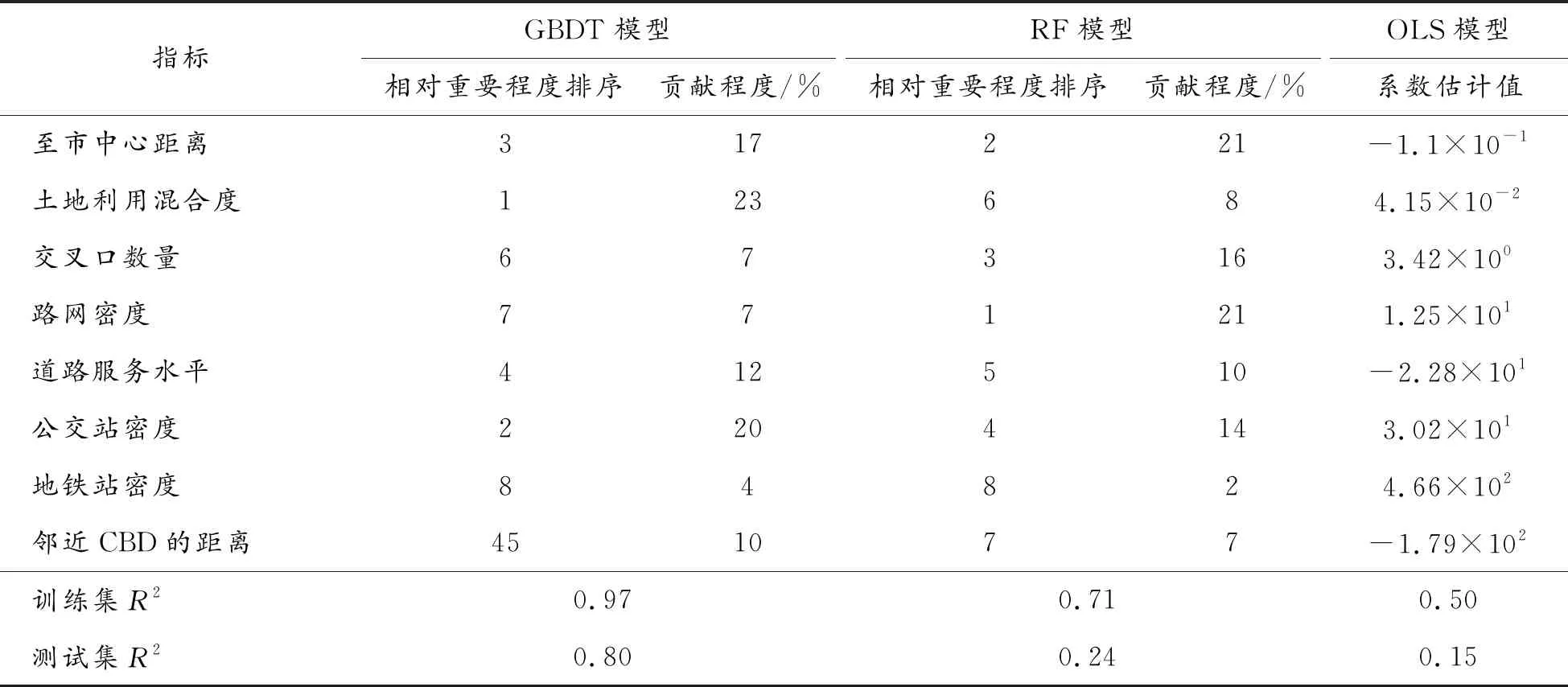
表4 模型预测精度分析结果
经过对比分析发现,GBDT模型在训练集和测试集2个维度上均优于RF模型和OLS模型。在GBDT与RF模型之间,因GBDT模型的基学习器由回归树组成,而RF模型由分类树和回归树共同组成,故对于纯数值变化类型的样本数据集,GBDT模型更能有效捕捉自变量对因变量的影响程度;在GBDT与OLS模型的拟合优度对比方面,说明最高聚集人数与建成环境指标间的作用方式倾向于非线性影响。模型适用性方面,通过GBDT模型和RF模型的训练集表现可发现,2种模型均能较好地表征样本数据内部作用关系。模型泛化能力方面,针对最高聚集人数方面的研究中,变量属性多为纯数值变量,故GBDT模型的基学习器回归树更为占优,而RF模型的基学习器为分类树,更适合在指标为逻辑变量和数值变量混合时使用。在泛化能力方面,GBDT模型在最高聚集人数测算方面表现较好。
从模型的显著水平来看,所有变量均与最高聚集人数存在显著相关关系。根据变量重要程度指标分析,影响最高聚集人数的最重要指标是土地利用混合度,贡献程度为23%;其次是公交站密度和至市中心距离,贡献程度分别为20%、17%,除地铁站密度(4%)之外,其余变量贡献程度在7%~12%范围浮动。不难看出,土地利用混合度表征建成环境的多样性,即表明该区域的综合发展程度,故出行人在选择汽车客运站时,倾向于选择周边环境便利、发展程度高的汽车客运站。公交站密度与地铁站密度表征该建成环境的交通设施服务水平,研究结果表明周边交通配套设施的齐全程度对最高聚集人数有主要影响。
3.2 单变量分析
采用控制变量法,取所有变量样本数据均值为基础数据,以上、下限为界独立分析各变量与最高聚集人数的作用机制。
建成环境可达性指标对最高聚集人数的影响见图2。

图2 建成环境可达性指标对最高聚集人数的影响
最高聚集人数随着至市中心距离的增大而逐渐减少,可理解为至市中心远的区域为郊县,其出行量必然小于主城都市区。其中,距离为12 km时达到最大值1 473人,之后随距离增加而逐渐降低;在37~183 km区间内趋势平稳,人数稳定在900左右;在210~310 km区间,人数稳定在550左右。出现2个平台的原因可能是城市聚集效应影响导致阈值效应明显,城区范围内的汽车客运站受距离影响较大,而近郊和远郊的汽车客运站因距离过大受影响较轻。与邻近CBD距离整体呈负相关,距离越大,最高聚集人数越低。
建成环境多样性对最高聚集人数的影响见图3。土地利用混合度峰值作用明显,在混合度为0.385时取得最大值1 504,小于该值时呈上升趋势,大于该值时呈下降趋势,最终趋于稳定。在土地利用混合度低时,说明区域基础设施建设不完全,无法为出行人提供便利;在混合度较高时,区域发展水平高可能导致区域结构复杂,同样不利于出行。

图3 建成环境多样性对最高聚集人数的影响
建成环境路网复杂度对最高聚集人数的影响见图4。交叉口数量在0~20区间走势平稳;从20开始最高聚集人数陡增至1 350,此后呈下降趋势。路网密度变化趋势相同,在1~1.7区间最高聚集人数上升至1 200,呈现U型关系。道路服务水平阈值作用明显,在密度值为5.04时转折聚集人数由900下降至230并趋于稳定。交叉口数量、路网密度和道路服务水平均表征建成环境路网复杂度,其值过小说明该区域交通组织存在局限,其值过大说明该区域复杂程度高,易增加出行人的心理负担,进而影响最高聚集人数。
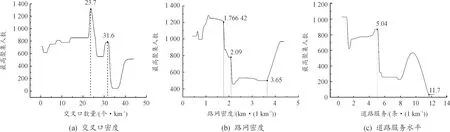
图4 建成环境路网复杂度对最高聚集人数的影响
建成环境公交支撑度对最高聚集人数的影响见图5。公交站密度与最高聚集人数之间整体呈正相关,在0.859~15.8区间人数逐渐上升。地铁站密度与聚集人数存在明显阈值效应,当密度值为0.366时,最高聚集人数为948;当密度值为0.844时,最高聚集人数为1 541。公交站布设难度小,布设站点广,能基本表明该区域的公共交通支撑度,密度值高说明该区域公交便捷,利于换乘;而地铁站密度受轨道线路布设影响大,样本数据周围至多存在3座地铁站,大部分为0座,故考虑是样本数据结构问题导致阈值效应。
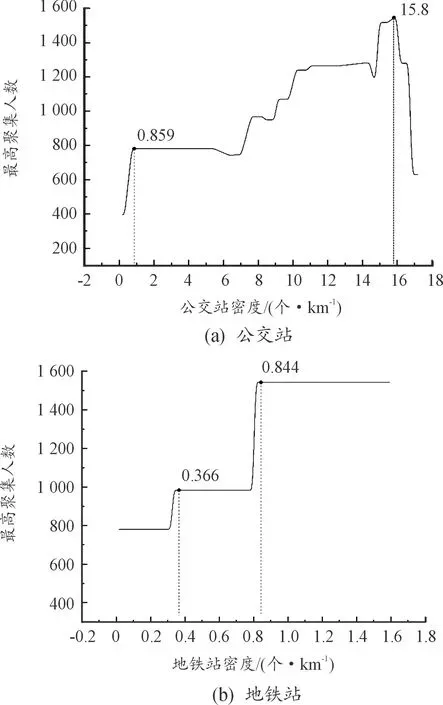
图5 建成环境公交支撑度对最高聚集人数的影响
4 结论
1) 最高聚集人数的变化趋势在空间信息上存在显著相关,且与建成环境指标有密切关联。土地利用混合度贡献程度最高,为23%;接下来是公交站密度,贡献20%和至市中心距离,贡献17%。这表明在新建或改建汽车客运站时,可结合区域控制性规划着重考虑以上3个因素进行聚集人数的合理测算。
2) 在各变量的局部分析中,变量对最高聚集人数的非线性作用明显,并有效诠释了不同测度下对聚集人数影响的差异。其中,表征建成环境可达性的市中心距离和邻近CBD距离均呈现负相关趋势;建成环境多样性的土地利用混合度峰值效应明显,于0.385时取得最大值;建成环境路网复杂度中的交叉口密度指标随着数值变化逐步增大,于23.7时取得最大值,随后逐步减少。此外,路网密度和道路服务水平均呈现U型关系,故建议规划时将取值控制在适宜区间;建成环境公交支撑度中的公交站密度呈正相关,地铁站密度阈值效应明显,故建议在汽车客运站建设时控制地铁站密度。
猜你喜欢
中国交通信息化(2022年9期)2022-10-28
人民交通(2022年12期)2022-07-14
现代企业(2020年3期)2020-04-13
环球时报(2018-12-07)2018-12-07
商情(2017年4期)2017-03-22
中学生数理化·八年级物理人教版(2015年12期)2016-01-25
中学生数理化·八年级物理人教版(2015年12期)2016-01-25
中学生数理化·八年级物理人教版(2015年12期)2016-01-25
