
基于残差编解码器的通道自适应超声图像去噪方法
2022-07-27 09:13曾宪华李彦澄赵雪婷
电子与信息学报 2022年7期
曾宪华 李彦澄 高 歌 赵雪婷
①(重庆邮电大学计算机科学与技术学院 重庆 400065)
②(图像认知重庆市重点实验室 重庆 400065)
③(重庆安琪儿妇产医院超声科 重庆 400065)
1 引言
近年来,超声检查在医疗实践中不断发展并广泛应用,尤其在心脏病筛查、妇科检查以及孕妇常规检查等场景中,它是最重要的成像手段之一[1]。由于成像环境和设备性能的限制,获得的图像极有可能被噪声或伪影损坏,导致超声图像丢失关键信息,特别是斑点噪声,模糊了相关细节,降低了超声图像中软组织的对比度,甚至将图像的特征信息掩盖,给医师造成了严重的视觉干扰并影响判断。因此,超声图像去噪具有重要的临床应用价值。
国内外学者在超声图像的噪声建模上以及去噪方法上付出了巨大的努力。最初,研究者使用具有自适应能力的滤波器对超声图像去噪,如中值滤波器[2]和双边滤波器[3]等。这类基于投影域滤波器的方法有较低的计算复杂度,但缺乏对图像内容的适应性,导致图像纹理过度平滑,模糊了图像的边缘信息。运用低等级技术对超声图像去噪,如低秩张量近似[4]等,虽然计算复杂度变低,但不能保证图像的纹理细节。基于后处理技术的超声图像去噪[5],能减少计算时间上的开销,对斑点噪声的抑制也有明显的效果,但在训练数据的过程中会对超声图像的细节造成一定的损失。在图像修复领域中,图像去伪影和超分辨率的相关处理方法[6,7]也被运用到图像去噪领域,针对具体的场景,需要改进超分辨率算法,才能在图像去噪上达到较好效果。随后,文献[8,9]提出将深层卷积编码解码框架用于图像恢复并取得了良好的性能。结合自编码器和卷积神经网络的残差网络,Chen等人[10]又提出将浅层残差编解码模型用于CT图像去噪,在对称的编解码结构中采用跳跃连接。本文提出的去噪模型不同于典型的编解码结构,该模型包括了残差学习[11],以便于卷积层和相应的反卷积层的操作。但斑点噪声形式复杂且在空间上可变,同时依赖信道,具有组织依赖性,导致现有去噪方法不能直接运用在超声图像去噪上。
本文提出一种基于残差编解码器的通道自适应去噪模型,以达到进一步有效去除超声图像中噪声的目的。针对超声图像中的特征信息与噪声信号相似以及去噪任务不适定的特点,基于残差编解码器的通道自适应去噪模型(Residual Encoder-decoder with Squeeze-and-Excitation Network, RED-SENet)模型的编码器部分能对超声图像的主要信息编码,同时去除无用信息。对于注意力解码器部分,在反卷积后引入注意力机制,通过对特征通道间的相互依赖关系进行显式建模,来自动获取每个通道的重要程度,然后根据重要程度去提升有用的特征并抑制无用的特征,使解码器部分更关注编码中的有用信息,恢复图像中细节信息的同时,降低解码过程中对噪声等无用信息的关注程度,以此来优化去噪模型的性能。相比之前的方法,本文方法1)实验代码见https://github.com/liyanch/RED-SENet。显著提高了模型的去噪效果,获得了良好的去噪性能。
2 本文方法
2.1 去噪模型
超声图像中的噪声是由于换能器引起的电磁波分散[12],使超声图像上出现颗粒状图案,那么超声图像中这些随机产生的小斑点则是斑点噪声。当粗糙纹理上的反射波对纹理产生影响时,就会在图像中产生噪声,并与图像中的纹理结构混淆。超声图像去噪的难点在于超声图像中的噪声信号是由乘性噪声和加性噪声混合而成的斑点噪声,因此斑点噪声不容易被准确地建模。斑点噪声与组织对象的幅值相依赖,不同的组织对超声波的阻抗程度不同,这会严重干扰医师对病变的检测。特别是在低信噪比、低对比度的超声图像中,斑点减少过程是非常必要的,以提高对象检测的准确性,而不影响图像的重要诊断特征。为了进一步完善去噪方法,重要的是要有一个准确可靠的模型。具有斑点噪声的图像的较为良好的模型可以模拟为


2.2 基于残差编解码器的通道自适应去噪模型结构(RED-SENet)
超声图像中斑点噪声依赖图像信息的特点,导致已有的RED-CNN[10]去噪模型在超声图像去噪上无法达到良好的去噪效果。为解决上述问题,使用基于残差编解码器的RED-CNN去噪模型能够进一步有效地去除超声图像中的噪声,本文在解码器中构造出新的注意力反卷积残差块(Attention Deconvolution Residual block, ADR)使去噪模型提高对内容特征的敏感性,捕获通道依赖关系,学习到图像内容特征在各个通道中表现的重要程度。这些内容特征可通过后续的转换加以利用,以解决超声图像中斑点噪声对内容特征的依赖而造成成像质量差的问题。在提升去噪模型有效性的同时,尽可能地保留超声图像的纹理细节。针对去噪对象,有用信息是指超声图像中的纹理结构和边缘细节信息,而无用信息是指超声图像中的噪声信息。RED-SENet去噪模型包含5个卷积层(编码器)、2个注意力反卷积残差块以及1个反卷积层(注意力解码器),本文提出的去噪模型结构如图1所示。
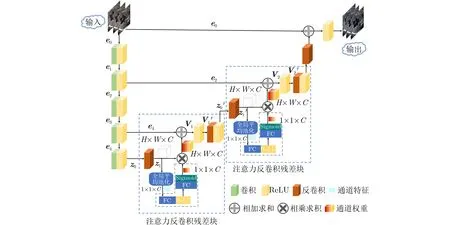
图1 RED-SENet总体模型结构图

与传统自编码器不同,RED-SENet去噪模型使用5个相连的卷积层堆叠成编码器,并丢弃了每个卷积层后的池化层,以避免丢弃重要的结构细节,使图像噪声和伪影由低到高的逐级抑制,以保留被提取图像块中的基本信息。在RED-SENet中,注意力解码器由2个注意力反卷积残差块和1个反卷积层组成。网络把直接映射问题转化为残差映射[13]问题,每两个卷积层引出1个残差连接,连接到对应的反卷积层,这样有助于避免在训练过程中当网络很深时出现梯度消失。但仅通过残差连接,仍无法从根本上减少内容特征在解码过程中的损失。而注意力解码器很好地解决了过多的损失导致图像重建不理想的问题,它不仅能保证已有去噪模型恢复细节的能力,而且增加了对通道有用信息的关注度,忽略无用信息,能使超声图像在注意力解码器中,更有针对性地恢复结构纹理信息。
RED-SENet的去噪过程描述如下:输入带有噪声的超声图像,超声图像经过5个卷积层构成的编码器噪声去除后得到图像的深度编码。深度编码顺序地经过编码器之后的2个注意力反卷积残差块,得到注意力深度编码,最后通过1个反卷积完成对超声图像的结构和纹理细节的恢复。
2.2.1 编码器

2.2.2 注意力反卷积残差块(ADR block)
近年来,注意力机制广泛运用于计算机视觉领域,尤其是Hu等人[14]提出的通道注意力。本文将通道注意力的特性运用到提升超声图像去噪的性能上,并构建注意力反卷积残差块。在注意力反卷积残差块中,第1个反卷积层输出的特征向量经过全局平均池化层后,特征向量中每个通道的特征信息被平均化。再经过2个全连接层之后,能学习到超声图像特征各通道之间的非线性交互和一种确保可以强调多个通道的非互斥关系,从而完全捕获通道依赖关系,学到这些特征信息在各个通道中表现的重要程度。然后用Sigmoid激活函数将每个通道的重要程度归一化到0~1,通过把每个通道的重要程度与原始输入对位相乘,从而使它们的重要程度再次分布在与输入维度相同的不同通道中。得到有区分重要程度的特征向量与第4个卷积层后的ReLU激活函数输出特征向量对位相加后,再使用ReLU激活函数激活,最后再进行一个反卷积运算和ReLU非线性函数激活,即经过了一个完整的注意力反卷积残差块。由注意力反卷积残差块组成的解码器组成了注意力解码器。注意力解码器中连续经过2个注意力反卷积残差块后,再进行一次反卷积运算和非线性激活函数,这样就可以将超声图像中的结构细节和纹理信息更有效地恢复。因此,本文提出的注意力反卷积残差块能更好地应用到基于残差编解码器的去噪模型中。
注意力反卷积残差(ADR)块侧重于以计算效率高的方法模拟通道关系增强网络的表示能力。因此,通过ADR块,本文方法可以学习并利用全局信息来选择性地强调通道信息特征,在通道重要性自适应的过程中抑制无用的特征,并凭借ADR块提高网络的去噪性能。ADR块结构如图2所示。

图2 注意力反卷积残差(ADR)块
2.2.3 注意力解码器
本文方法中的注意力解码器用于增强有用信息的敏感度,更有针对性地恢复图像结构的细节,卷积操作有噪声过滤的作用,但仍会减少输入信号的细节信息。因此,将2个ADR块和1个反卷积层整合到网络中[10]可以增强解码器恢复结构细节和保持纹理信息的能力。通过卷积层和ADR块的跳跃连接残差数据遵循“先进后出”原则,即输入图像跳跃连接到对应的最后一个反卷积层,第2个卷积层跳跃连接到对应的倒数第1个ADR块。注意力解码器是由ADR块、反卷积层和ReLU单元组成的。ADR块描述如下:
在ADR块中,首先,经过第1个反卷积运算后输出的C个通道特征图的计算为

2.2.4 损失函数

2.3 基于残差编解码器的通道自适应去噪模型训练算法
RED-SENet去噪模型训练算法如表1所示。首先,使用随机权重初始化去噪模型φd,输入训练集S={(X1,Y1),(X2,Y2),...,(XN,YN)}用于训练去噪模型φd,X为带噪声的超声训练样本,Y为干净的超声图像, (Xi,Yi) 为 训练集中第i张超声图像以及对应的干净图像。进行第tepoch训练时,随机打乱训练集中的样本,从训练样本中随机输入图像对(Xi,Yi)到去噪模型中,通过一系列卷积操作提取出图像特征,再经过注意力解码器得到注意力特征图,进一步恢复图像细节信息,生成去噪后的预测图像Pi。利用均方误差损失函数计算去噪模型预测输出和期望输出之间的误差,如式(11)。然后利用式(12)计算损失梯度,通过表1算法的步骤(9)来更新优化去噪模型参数θd,循环往复,不断更新优化去噪模型。在模型推理过程中,将测试的超声图像输入到经表1的算法优化完成的去噪模型φd中,经过该模型推理后,输出去噪结果。

表1 RED-SENet超声图像去噪模型训练算法
3 实验
本文用4个超声数据集验证本文方法的保真度和鲁棒性,再与其他去噪方法比较,并分析结果。
3.1 数据集
(1) 胎儿心脏超声数据集(Fetal Heart ultrasound dataset, FH)。FH超声数据集采集自中国重庆一家妇产医院,该数据集由2019—2020年的临床检查超声图像构建而成。从医院获得的原始超声图像数据集包含1000例,每例包含11个切面,40张超声图像。剔除数据集中测值、多普勒加彩等的图像,数据集中每个切面共1000张图像。为了验证REDSENet去噪模型的有效性和保持病理不变性,本文选取4腔心切面进行实验。
(2) 胆囊结石超声数据集(Gallstone ultrasound dataset, GS)。GS超声数据集由中国重庆的另一家医院提供,该数据集由2014年到2015年的临床检查超声图像构建。从医院得到的原始图像数据集包含25659名患者的腹部超声图像数据集,每位患者提供一张超声图像。从中选择有大量超声图像样本的疾病类别,删除常规产前检查的超声图像,构建的超声图像包含3个器官,分别为胆囊、肾脏和肝脏。数据集包含9种疾病,分别为胆囊结石、胆囊息肉、正常胆囊、肾积水、肾结石、肾囊肿、脂肪肝、血管瘤和正常肝脏,共6563张图像。
(3) 胎儿头部测值超声数据集[16](fetal Head Circumference ultrasound dataset, HC18)。此数据共有1334张标准平面的胎儿头部超声图像,原始超声图像的大小为800像素×540像素。对数据进行预处理,本文将图像均处理为长宽一致的图像集。
(4) 成人心脏超声数据集[17](Heart ultrasound dataset, CAMUS)。CAMUS数据集由来自450名患者临床检查的2维超声心脏图像组成,共1800张成人心脏超声图像。
通过分析超声图像中噪声的特征,了解到超声图像中的噪声是加性噪声和乘性噪声混合而成的。原始超声图像集是使用物理校正手段采集的图像集,其本身含有少量超声图像真实的噪声,以此作为实验数据,一定程度上保证了模型的实用性。通过在原始超声图像加入加性高斯白噪声,部分模拟超声图像中的噪声,便于控制图像集的噪声水平进行多组实验,以此评估本文方法的鲁棒性。因此,本文通过对上述4个超声图像数据集添加加性高斯白噪声来模拟超声图像中的加性噪声,不仅能模拟超声图像中的部分噪声,同时也能通过控制所添加的噪声量来区别超声图像中的噪声程度,使得提出的模型在不同程度下验证其是否具有鲁棒性。此外,按照留出法,从加有模拟斑点噪声的图像中随机选出上述4个数据集的训练集和测试集。
3.2 参数设置
该网络用Pytorch实现,训练网络输入的图像块为64像素×64像素大小的图像块。在实验中,对几个参数进行评估,最终确定如下参数设置:初始学习率lr为 10-4,逐步衰减到1 0-5。批次大小为16,训练200 epoch,使用第200 epoch的权重参数进行测试。最后一层的卷积核数量设为1,其他层卷积核数量为96。所有层的卷积核大小都设为5×5。卷积和反卷积的步长为1,填充为0。在本文实验过程中,所有网络都使用Adam算法进行优化,它能基于训练的数据迭代地更新神经网络的权重。本文设计的去噪模型与参数配置如表2所示。

表2 RED-SENet去噪网络结构与参数配置
本文提出的网络能处理任意大小的图像,未经裁剪的测试图像可直接送入网络去噪。本文从峰值信噪比(Peak Signal-to-Noise Ratio, PSNR)、结构相似性(Structural SIMilarity, SSIM)和均方根误差(Root Mean Square Error, RMSE)3个方面定量评价图像质量。在本文用到的几项评价指标中,PSNR和SSIM越大说明图像质量越高,RMSE值越小说明去噪后的图像与真实图像的差异更小,图像质量更优。本文方法与MLP[18](Multilayer Perception),BM3D[19](Block Matching and 3D collaborative filtering),K-SVD[20](K Singular ValueDecomposition),CNN10[21](Convolutional Neural Network),RDN10[22] Residual Dense Network)和RED-CNN[10](Residual Encoder-Decoder Convolutional Neural Network)共6种先进的方法比较。其中MLP, BM3D和K-SVD是常用的图像去噪传统算法。RED-CNN基于编解码器并广泛应用于医学图像去噪方法。CNN10的网络模型是根据CNN简化的版本,也可将它看作基于CNN的超声图像恢复模型[21]的一个变体。RDN10是用于图像超分辨率任务RDN的简化版本。
3.3 实验结果
本文方法与MLP, BM3D, K-SVD, CNN10,RDN10以及RED-CNN这6种方法分别在FH, GS,HC18和CAMUS共4个超声图像数据集上实验,并在4个不同的噪声程度上进行主观效果和图像评价指标的对比,来验证RED-SENet的性能,如表3—表5和图3—图5所示。在评价指标的表格数据中,加粗为最优,下划线为次优。本文通过改变高斯噪声的大小控制超声图像中噪声程度。

图3 在同一噪声程度下(σ =25),不同方法的去噪结果可视化

图5 相对于噪声图像的绝对差分图像
表3是在FH超声数据集上实验得出的各项评价指标值。从表3得出,本文方法相比RED-CNN在客观指标上领先,平均PSNR高出将近0.2 dB,相比RED-CNN方法的SSIM,也略微领先。传统去噪方法用于超声图像去噪效果普遍低于基于深度学习的方法,从表格中的最后一行看出,本文方法在几种对比方法中,指标表现为最优或次优。在表3中,本文方法和RDN10在FH数据集上的去噪性能表现良好,本文方法的性能略优于RDN10。表4是在GS超声数据集上实验得出的各项评价指标值。从表4看出,本文方法在所有不同噪声程度上的评价指标都表现最优,CNN10和RED-CNN在某些噪声程度上的评价指标表现为次优。在HC18超声数据集上对比各个方法的指标如表5所示,在噪声变量取值为10和15时,RDN10各项评价指标值高于表中其他方法,本文方法的各项指标值仅低于RDN10;在噪声变量为25和30时,本文方法的各项评价指标高于其他方法。表5是HC18超声数据集各个方法的对比,从表中仍然能观察到,在噪声变量为10和15时,本文方法各种评价指标值表现为次优,在噪声程度为25时,本文方法各项指标均优于其他方法,表明本文模型的性能较优。从表3—表6看,无论PSNR还是SSIM, RED-SENet去噪方法噪声抑制都表现优良。
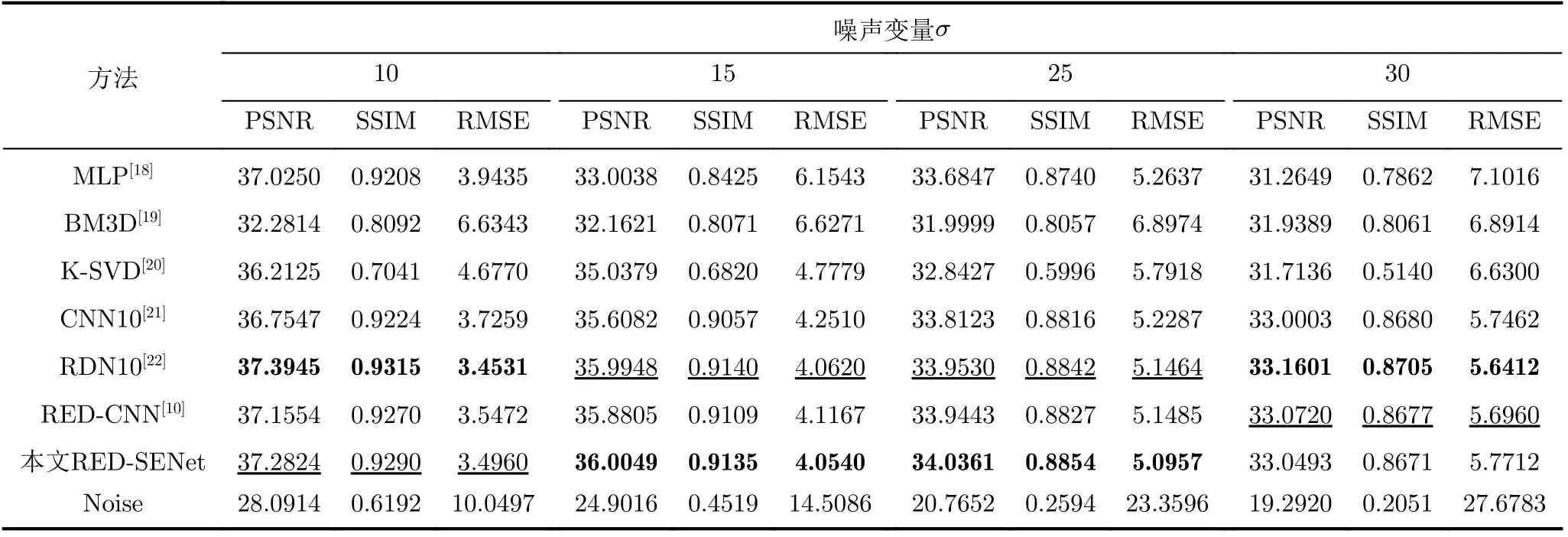
表3 胎儿心脏超声数据集在不同噪声情况下的实验对比

表4 胆囊结石超声数据集在不同噪声情况下的实验对比

表5 胎儿头部超声数据集在不同噪声情况下的实验对比

表6 CAMUS头部超声数据集在不同噪声情况下的实验对比
图3(a)是FH超声图像上的结果。图3(a1)是干净的胎儿4腔心切面的超声图像,图3(a2)是带有噪声的胎儿4腔心切面图像。用于和本文方法对比的方法都对超声图像中的噪声有不同程度的抑制。图3(a3)使用MLP方法对图3(a2)中的图像去噪,可以明显地看到胎儿4腔心的一些重要的小结构变得光滑。BM3D和K-SVD比MLP保存了更多的细节,但在组织处能看到明显的人工生成的成分。在胎儿心脏的检查中,心脏的室间隔膜、二三尖瓣以及卵圆孔起着关键的作用。如果在去噪过程中,添加了人工成分,将缺损的室间隔恢复成完好的室间隔,会导致医生误判,造成严重的后果。从图3(a9)看到,恢复后的图像纹理结构仍然保持一致,去噪效果良好,和图3(a1)最为接近,因此,本文方法在结构保持和病理不变性方面也取得良好的评价,也能更有效地恢复超声图像中的结构纹理信息,说明本文方法去噪性能优于对比方法。
图3(a6)—图3(a9)、图3(d6)—图3(d9)都是深度学习去噪方法用于超声图像去噪的结果,图3(a)—图3(d)分别为FH/GS/HC18/CAMUS超声数据集经各种方法去噪后的图像。观察可得,在超声图像去噪过程中,几种深度学习方法的去噪效果明显优于传统方法的效果。从白色纹理部位能看到,不同方法生成的纹理不完全相同,将去噪后的图像分别和无噪声图作对比,通过本文方法进行去噪后,图像纹理与图3(a1)最为接近,最大限度上保持了原有图像的结构和纹理细节。
为了显示RED-SENet的优点,相对于干净超声图像的绝对差值图像如图4所示。从图中能清楚看到,去噪后,图4(c)丢失了很多原有的纹理细节。因此,用此方法去噪不能保持超声图像的病理不变性。图4(d)中4腔心的边缘信息和纹理几乎无法体现出来。相比图4(f)—图4(h),图4(h)中的纹理细节与原始图最接近,纹理结构分布也较均匀。另外,各方法去噪后的图像相对于带噪声图像的绝对差值图如图5所示。差值图中显示的噪声越多,代表对应模型的去噪效果越好;图5与图4(a)越接近,表示去除的噪声越多,说明对应方法去噪效果越好。图5(a)是噪声图和噪声图之间的绝对差值,图上没有任何噪声。观察图5(b)—图5(h),图5(b)式中的去噪效果比图5(c)中的略差,图5(e)中明显看出有部分区域的噪声没有被去除,图5(d)中未被去除噪声的区域略小于图5(e)中的区域,图5(f)和图5(g)最为接近,去噪效果相当。图5(h)中的噪声斑点分布得更密集更均匀,留出的黑色块更少,表明本文方法去除的噪声最多;图5中能观察到,在被去除的噪声中,图像原本的纹理结构在绝对差分图像图5(h)中最不明显,说明本文方法能更有效恢复超声图像中的结构细节和纹理信息。

图4 相对于无噪声图像的绝对差分图像
通过固定相同的噪声程度,从各个指标的数值方面进行分析。从表7可以看到,本文的方法在FH数据集中3个评价指标的值均为最高;在GS数据集中结构相似性的值表现为次优,峰值信噪比和均方根误差的值最优;在HC18数据集中本文方法的3个评价指标均表现最优;但是在CAMUS数据集上对本文方法进行效果验证时发现,本文方法仅能在结构相似性评价指标上表现最优,而RED-CNN在PSNR和RMSE评价指标上表现最好。表7的实验结果表明,本文方法在较高噪声程度污染的情况下,去噪效果普遍优于其他方法,仅在CAMUS数据集上次于RED-CNN的去噪效果。
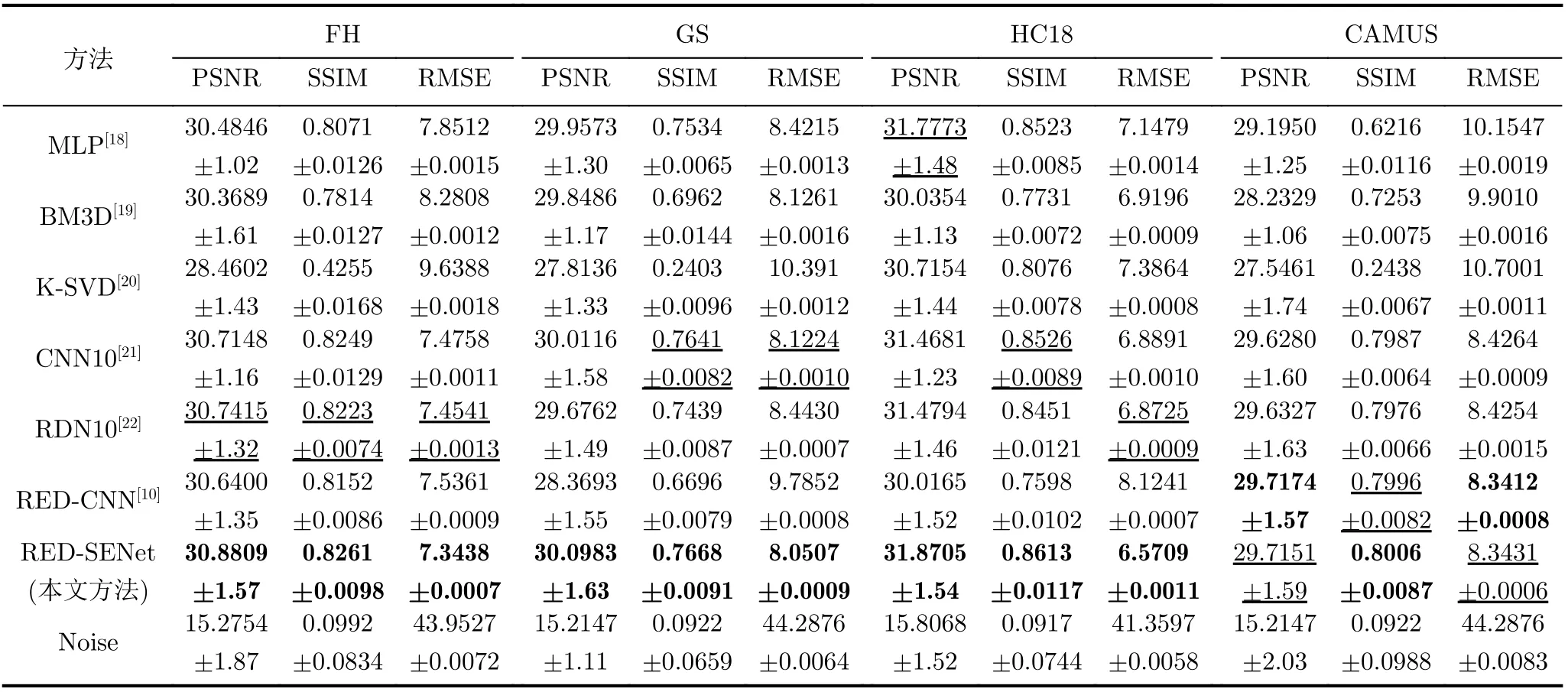
表7 不同方法在4个数据集上的定量结果分析(σ =50)
在图6中,红色虚线代表本文提出的方法在不同噪声程度下胎儿心脏数据集上3种评价指标值的变化情况,其中折线放大部分的噪声方差σ=25。图6(a)可以看到本文提出的方法的PSNR高于REDCNN和CNN10方法处理后图像的PSNR,图6(b)和图6(c)同理。本文为了再次验证模型的有效性和实用性,使用文章中所提到的同等条件下训练好的模型,对未使用物理手段采集到的超声图像去噪,在上述6种方法上进行实验。

图6 不同噪声方差σ 下,胎儿心脏(FH)超声图像去噪后的平均评价指标
在主观视觉方面,本文从图7可以观察到,未使用物理校正手段采集的超声图像经过传统方法去噪后的超声图像失真较大,去噪后的超声图像的纹理过于平滑,这些失真主要表现在超声图像的纹理结构上。由此可见,上述2种传统去噪方法对恢复超声图像的纹理细节的性能较差。对比之下,4种深度学习去噪方法对未使用物理校正手段采集的超声图像的去噪效果普遍优于传统的去噪方法。同时,使用4种深度学习方法去噪后所得到的主观图给专业超声科医师评价打分,得到了良好的评价结果,一定程度上改善了视觉效果,为专业医师的诊断减少了一定的干扰。特别地,图7中可以看到,从纹理细节上,本文方法所得到的图像(如图7(g))的纹理结构保持更良好;从4腔方面观察,腔内的噪声也明显减少,比其他3种深度学习方法表现更佳。另外,为了能从多个角度验证模型的有效性,同样采用绝对差分法,将采用上述6种方法去噪后的主观图与去噪前的图像进行差值映射,如图8所示。从绝对差分图中观察到,经上述6种方法进行去噪操作后所减少的噪声量,白色斑点为去除的噪声,减少的噪声越多,去噪的效果越好。
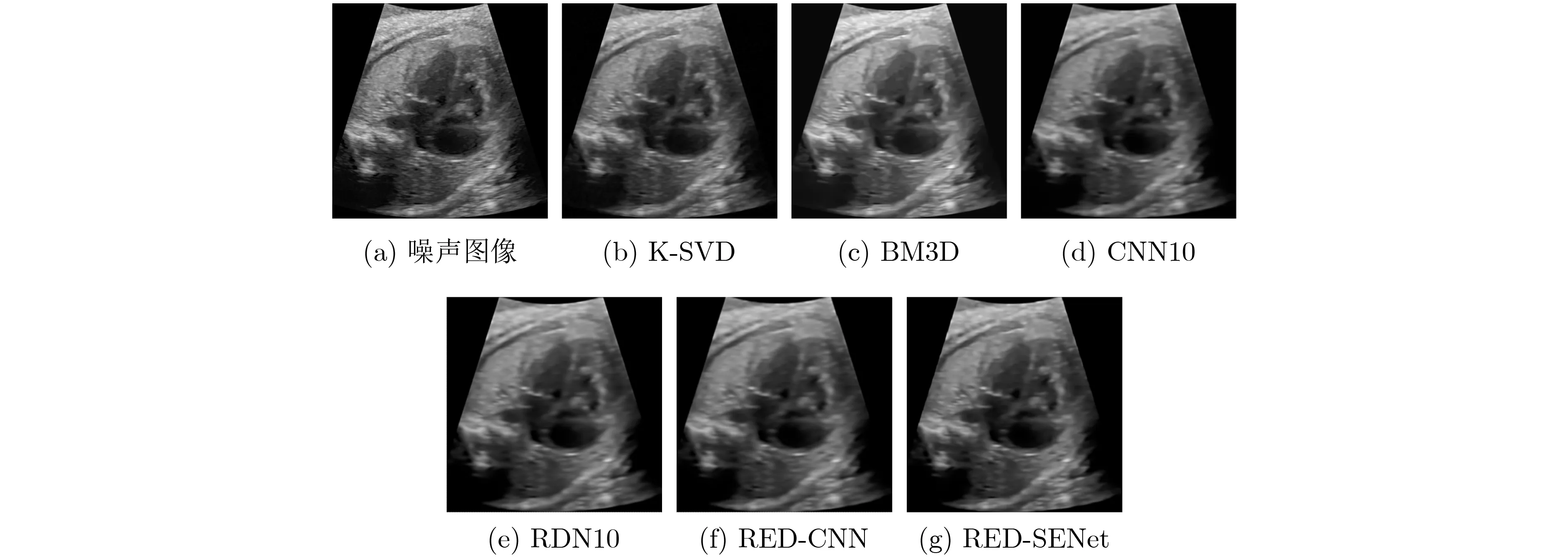
图7 未使用物理手段采集的超声图像去噪前后的主观图对比
对比图8(a)可知,在图8(a) —图8(g)中,如果绝对差分图的白色斑点越多,则去除的噪声越多。图8(a)和图8(b)中,去除的噪声比图8(d)—图8(g)多,但去除了部分的纹理结构和边缘信息,导致图像失真。再观察图8(d)—图8(g),各方法的图像边缘信息恢复情况大致相同,观察图中的黑色圆形区域,图8(g)的黑色圆形最大,且周边白色斑点稀疏。此黑色圆形为4腔心,根据实际去噪情况来看,与去噪前的图像对比最为接近。因此,以上实验也验证了本文提出的去噪模型的有效性和实用性。
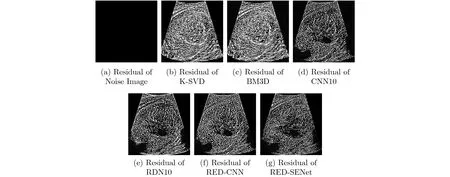
图8 相对于噪声图像的绝对差分图像
4 结束语
针对超声图像中的斑点噪声与其纹理结构相似而干扰医师诊断的问题,本文设计了一个基于残差编解码器的通道自适应去噪网络来有效去除斑点噪声。与一些先进的方法对比,无论从定性评估还是定量分析上,本文模型都取得优良的评价。模拟结果表现出深度学习在超声图像中噪声抑制和结构保持等方面的潜力,并能以较高的速度进行计算。在之后的研究里,继续优化模型的去噪性能,同时在其他形态的图像上也达到很好的去噪效果。
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
网络安全与数据管理(2022年3期)2022-05-23
小学生必读(低年级版)(2021年10期)2022-01-18
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
北京航空航天大学学报(2020年10期)2020-11-14
软件(2020年3期)2020-04-20
家庭影院技术(2019年8期)2019-12-04
北京航空航天大学学报(2019年9期)2019-10-26
摄影之友(影像视觉)(2018年12期)2019-01-28
