
基于自然语言处理技术的专门用途汉语教材快速编写模式研究
2022-07-28 05:22张辰麟
大理大学学报 2022年7期
张辰麟
(大理大学国际教育学院,云南大理 671003)
“一带一路”倡议提出以来,随着经济、商贸、能源、医疗卫生、旅游等方面合作的全面展开。沿线国家对汉语教学,尤其是专门用途汉语教学(CSP)的需求激增〔1-3〕。专门用途语言教学,作为衡量一种外语教学成熟的标准〔4〕,是国际中文教育未来发展中不可忽视的一个问题。“一带一路”沿线国家多为发展中或经济欠发达的国家,汉语教学资源尚存在较大缺口,汉语教材,尤其是国别化的专门用途汉语教材面临数量稀少、更新速度慢、难成体系的问题。经典的教材编写模式以领域专家学者为核心编委,该模式不仅需要专家学者消耗大量精力进行分析研判,同时也面临教材编写周期较长的问题。在知识信息快速迭代的今天,该模式难以迅速满足大量沿线国家的汉语教学需求,也一定程度滞后于语言更新的速度。
专门用途汉语教材往往以词汇作为中心,以单元形式组织话题进行特定需求场景下的汉语教学。“话题—词汇”体系,是专门用途汉语教材组织编写过程中的核心。借助计算机科学与技术中的自然语言处理相关技术与算法、成熟模型与平台等,可以从实时更新的特定领域语料中,迅速获取关键词汇、话题聚类等词汇之间的关系,以构建完善的专门用途汉语“话题—词汇”体系〔5〕,以便进行课文编写、难度评估等任务。从而达到快速形成教材,同时保证教材的科学性、时效性的目的。本文将结合自然语言处理领域相关算法与成熟平台,介绍一种全新的专门用途汉语教材的快速编写模式,以期迎合日益增长的海外专门用途教学需要。
本文结合自然语言处理相关算法与平台,将专门用途汉语教材编写分为四个主要步骤,分别为:语料收集与词表获取、“话题—词汇”体系构建、需求调研与教材编写、难度估计与本土化。图1展示该教材编写模式的总体流程,每个步骤的具体流程将在下文中分章节逐个论述。
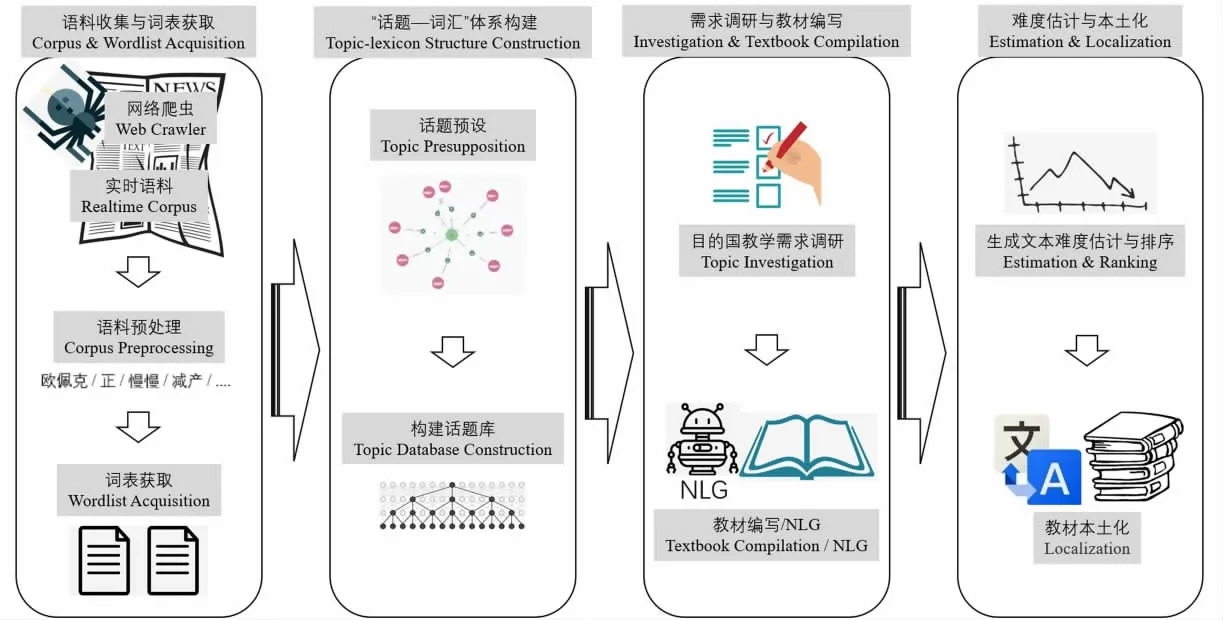
图1 专门用途汉语教材快速编写模式示意图
一、语料收集与词表获取
教材的编写周期往往较长,这就造成教材所涉及的部分词汇,尤其是具有较高时效性的科技、财经、医学等词汇往往不能得到及时的更新,对专门用途汉语教材而言,该现象造成的影响尤为巨大。而新兴领域词汇的增补,不仅考验教材编写者知识的广度,也常常需要面临客观性与权威性的问题。为了解决这一痛点,获取具有较高时效性、代表性、权威性、客观性的领域词表,我们借助自然语言处理相关技术,具体工作分为如下三个步骤。
(一)语料获取
自然语言处理领域获取语料的方式一般有两种,一是使用成熟的语料库,如CCL语料库、人民日报语料库等,二是通过网络爬虫技术对网页的文字信息进行爬取,目的是快速获得大规模语料,以便进行信息的抽取与检索。对于专门用途语言教学的教材编写而言,语料越新、领域性与专业程度越强、规模越大、在领域内覆盖面越广越好,如果领域内还有多个子领域,语料分布最好能够相对均衡。本文以SmoothNLP〔6〕财经新闻语料作为研究语料,以商务汉语作例子对教材的快速编写模式进行说明。该语料包含了4万篇2018年至2019年的财经新闻与专题报道,规模约6 700万字。
(二)语料预处理
中文没有天然的分词,因此中文的预处理,分词往往是第一步〔7〕,在自然语言处理领域中,中文分词一直是热门话题。分词工具包如Jieba、NLPIR、Stanford等在中文分词任务上正确率均超过95%,表现良好,可以用于对大规模语料进行快速、自动分词,以便进行后续处理。以下是使用Jieba分词工具包进行分词的财经新闻示例。
【例1】新华社/石家庄/5月/16日/电/(/记者/闫起磊/、/杨帆/)/16日/,/“/为/奥运/喝彩/”/奥林匹克/艺术/博览会/城市/系列展/石家庄/特展/在/石家庄/美术馆/开幕/。
对6 700万字左右规模的语料而言,使用Jieba分词工具包,全文分词仅需要数分钟,且正确率非常可观。
(三)词表获取
对语料全文进行分词之后,需要构建全文词表,即整个语料库出现过哪些词,同时运用工具包可以快速统计出每个词的词频与出现在多少个篇章当中。以往,语言学研究常以词频作为衡量一个词是否常用的标准。但对于专门用途教材编写而言,单纯使用词频这个统计量无法反映出词汇的“重要程度”。以本文使用的财经新闻语料为例,如果单纯统计词频,并按照词频进行降序排列,则高频词往往是如“你”“我”“的”“一”等这些不论在任何领域、任何语体的语料中词频都占绝对优势的汉语词汇,进而造成无法有效抽取出真正重要的领域核心词汇。解决该问题的方法分为以下两步。
第一,改进算法。不单纯使用词频,而是使用TF-IDF〔8〕倒排索引的形式来抽取词表。TF-IDF公式如式(1)所示:
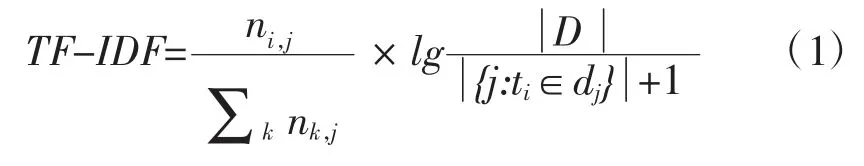
在式(1)中,i为当前词的序号,j为篇章序号,ni,j表示当前词i在任意篇章j中出现的词频总和。k为语料库中的任意词,Σknk,j表示所有k个词出现在任意篇章j中的总词频,即整个语料库词频的总和,|D|为篇章数量之和,|{j:ti∈dj}|表示出现了词i的篇章条目数,+1的作用是数据平滑。在式(1)中,TFIDF最终值越大,证明该词对专门用途教材编写越“重要”。使TF-IDF值变大需要两个自变量的共同作用,一个是ni,j,即某个词i在语料中的词频要尽量高;另一个是|{j:ti∈dj}|的数值不能太大,即词i不能出现在过多的篇章当中,即需要i存在一定的特殊性而非普遍性。
第二,使用停用词表。在使用了TF-IDF进行词表抽取后,仍有一些汉语常用词与领域词汇无关,无法被自动过滤,因此就需要使用停用词表进行人为过滤。一般来讲,在自然语言处理任务当中通常使用四川大学或哈尔滨工业大学编制的汉语停用词表,其中包括了2 000多个汉语常用词、数字、特殊符号等。
经过以上两步,以本文所使用的财经新闻语料为例,抽取的前100个词如下所示。
公司、数据、零售、创新、提供、资金、战略、投资者、三星、完成、企业、发展、应用、工作、实现、传统、价值、建设、厂商、渠道、产品、融资、创业、元、团队、销售、线下、超过、获得、设计、手机、经济、云、需求、行情、功能、滴滴、政策、支持、计划、品牌、营销、领域、上市、体验、股份、规模、国家、商品、升级、游戏、科技、同比、全球、美团、系统、方式、共享、设备、网站、电商、微信、合作、集团、交易、成本、显示、员工、股东、收购、智能、消费、媒体、管理、诊股、使用、提升、活动、选择、竞争、投资、基金、信息、人工智能、场景、资产、推出、社区、资源、人民币、业务、移动、资本、苏宁、客户、物流、监管、微博、搜索、商业。
从大规模财经语料中抽取的前100词中可以看出,其中绝大部分词汇,做专门用途汉语教材(商务汉语)的生词,都具有较高的质量。该词表不仅包括财经商务实务中常用的词汇如“公司”“企业”“产品”等,还抽取出了很多具有很高时效性的新词,如“云”“人工智能”“电商”等。按照TF-IDF值降序排列继续向下抽样,第200个词为“变化”、第500个词为“周期”、第1 000个词为“特朗普”、第2 000个词为“民生”。可以看出,即使继续抽样,大部分词汇都与财经商务有紧密关系。
但是,在抽取的词表中仍然存在有例如“苏宁”“广州”“乔布斯”等人名、地名、品牌名、机构名等,不宜作为教材编写中的生词。在自然语言处理领域有专门研究对人名、地名、机构名等进行标注的“命名实体识别”任务。通过使用工具包可以对命名实体进行自动识别并且标注,如“苏宁(ORG/机构品牌名称)”“广州(LOC/地名)”“乔布斯(PER/人名)”等。但不建议将这些词汇完全剔除出词表,因为这些词汇虽然不能作为汉语生词进行教学,在教材编写过程中却能够协助构建课文的话题和情景,因此保留命名实体对专门用途教材编写有一定的意义。
二、“话题—词汇”体系构建
借助自然语言处理相关技术算法与工具,可以快速高效获取语料并抽取专门用途教材编写所需要的核心词汇。但专门用途教材的编写往往是以话题为单元,因此还需要区分出“哪些词跟哪个话题关联更紧密”,以便构建“话题—词汇”体系。在自然语言处理领域,这种任务类似于聚类算法,但却又不完全相同。其区别在于,对于教材编写而言,一个词可以与多个话题、多个教学单元相关联,而不是非此即彼的对应关系。且专门用途教学每个单元都有一定的目的性,对应专门用途汉语交际的特定场景,因此话题的聚类需要在语言知识的背景下有监督地进行。在这一步骤中,我们采用预设话题与核心词的方法,通过计算核心词与词表其他词之间的关系强弱并排序,以构建一个完整的“话题—词汇”体系。本章主要分为两个部分工作,一是根据以往的专门用途教材,预设好话题与核心词,二是使用自然语言处理相关算法计算词与词之间的关系,并进行排序。
(一)话题预设
为了防止无监督聚类造成聚类结果话题不明,同时也为了继承以往专门用途汉语教材中的优秀话题与单元。以商务汉语为例,我们将以往经典教材中的教学单元总结为以下26个话题,并从上一章抽取到的词表中,为每个话题匹配一个核心词,该核心词需要兼具较高的词频和较高的TF-IDF值,话题与核心词的对照关系如表1所示。
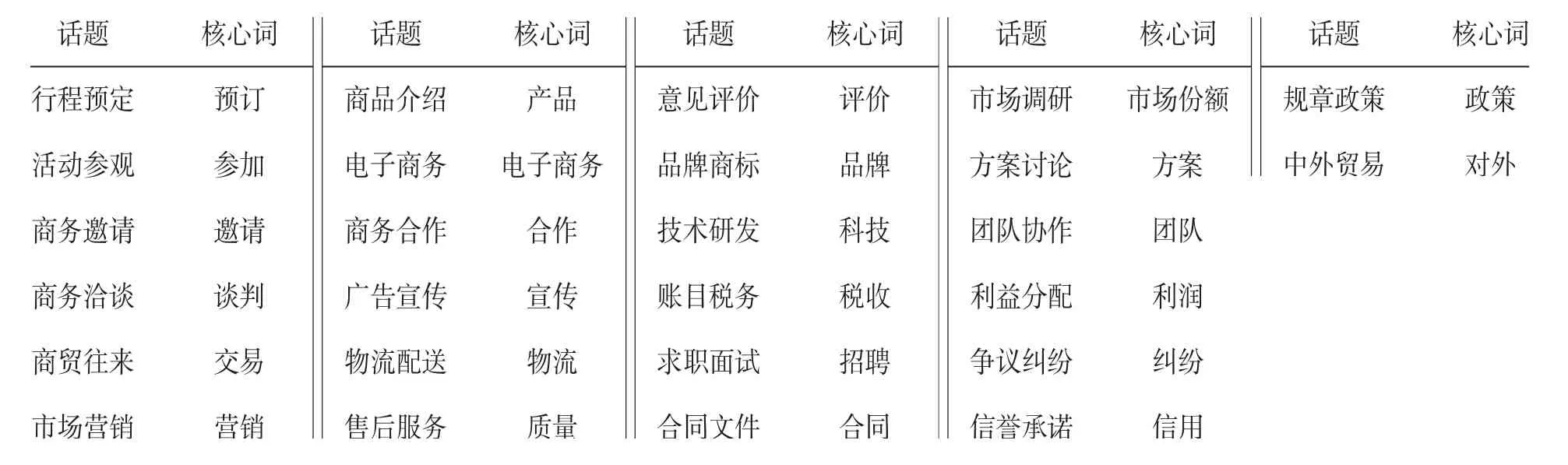
表1 商务汉语“话题—核心词”对照表
(二)构建话题库
在获取了每个话题的核心词之后,需要计算每个话题的核心词与词表中其他所有词的关系紧密程度,本文中使用点相对熵〔9〕对词与词之间的关系进行度量,点相对熵的计算方法如式(2):

点相对熵是一种度量两个词汇在大规模语料中共现关系的算法。式(2)中,p(wcore)表示核心词wcore出现在篇章中的概率,p(wi)表示任意一个词wi出现在篇章中的概率,p(wcore,wi)表示核心词wcore与wi同时出现在篇章中的概率,当且仅当二者尽可能共同出现时,二者关系密切,PMI(wcore,wi)值趋向较大。表2以物流配送这一话题为例,展示与该话题最相关,PMI值最大的Top 100词。
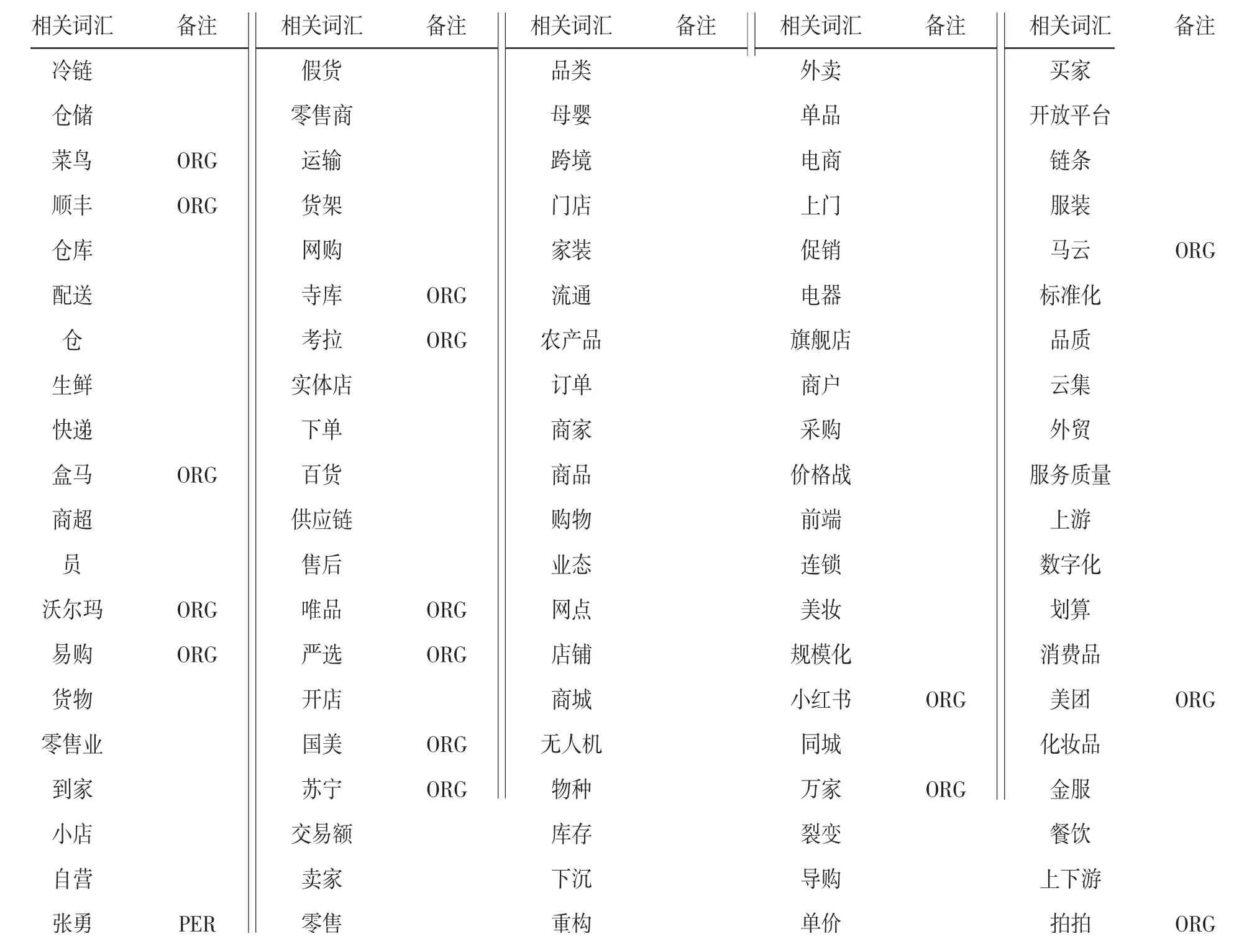
表2 与话题“物流配送”(核心词:物流)相关的Top 100词
从表2中可以看出,相关度T op 100词中的绝大部分词都与物流配送这一话题高度相关,教材编写者可以自由选取其中的一部分进行课文编写,丰富的命名实体词汇也可以为课文编写提供话题、人物和场景。如与快递相关的命名实体“顺丰”“菜鸟”搭配“网购”“下单”“快递”“配送”“到家”等生词,可以编写出一则有关网上购物与收发快递的课文;或使用命名实体“盒马”“马云”搭配“冷链”“生鲜”“供应链”“餐饮”等词汇,向汉语学习者介绍中国当今买菜的“新变化”;又或者加入“无人机”“数字化”等新词以介绍“中国智造”带来的“文化自信”。基于自然语言处理技术对大规模语料进行高速、自动化的处理,并建立“话题—词汇”体系,可以极大程度上提高专门用途汉语教材编写所使用的词汇的客观性、时效性。
三、需求调研与教材编写
在专门用途汉语的领域,构建较为完整的“话题—词汇”体系后,教材编写者需要对目的国家的需求进行调研,以便选取合适的话题构成教材的各个单元。该部分主要分为两个阶段,一是目的国教学需求的调研与分析,二是教材课文的编写。
(一)需求调研
各国的经济发展水平不同,文化背景不同,因此即使对相同的领域,其学习者在专门用途汉语中的需求、兴趣也不尽相同。以本文所列举的商务汉语为例,我们对来自不同国家的数名汉语学习者进行问卷和访谈,并让每位被调查者从26个商务汉语话题中,选取自己最感兴趣、商务往来中最需要学习的12个话题(约等于一本教材的单元数量)。在发放问卷前,调查问卷均已针对受访者母语进行了本地化翻译。问卷结果如表3所示。

表3 各国商务汉语话题需求Top 12
在了解目的国汉语学习者的需求后,就可以从“话题—词汇”体系中选择相应的话题与相关的词汇进行教材编写,以满足国别化汉语学习者的学习需求。
(二)教材编写
教材编写阶段围绕“话题—词汇”体系与不同国别的汉语学习者需求展开,本节以大多数国家汉语学习者都比较关心的“行程预定”这一话题为例,该话题的核心词为“预订”,我们直接取前15个与话题相关度最高的词汇(包括核心词本身与命名实体)编写一篇针对韩国学习者的课文“行程预定”,示例如下。
生词:预订、机票、民宿、预定、目的地、酒店、房东、航空公司、景区、游客、房源、旅游。命名实体:携程(ORG)、海航(ORG)。
【例文】
王小明:金俊贤,听说你下周要到大理来旅游,你已经预订好机票了吗?
金俊贤:我已经预订了海航的机票,听说这个航空公司服务不错。
王小明:你已经有预定好的行程了吗?打算哪里玩?
金俊贤:还没有具体的目的地。听说大理的景区风景非常不错!
王小明:你打算待多长时间?
金俊贤:我打算待一个月。我正在携程APP上看酒店。
王小明:你要住一个月的酒店,这不划算。我建议你看看按月租赁的民宿的房源。这里的房东对游客都很友好!
金俊贤:谢谢你的建议!
通过使用“话题—词汇”体系的词汇库,可以帮助教材编写者快速编写课文,同时也可以增加专门用途汉语教学课文的时效性。而命名实体则可以为教材的课文丰富会话情景,帮助汉语学习者了解中国的生活现状,构建语言学习的文化背景。
除了人工编写课文以外,在自然语言处理领域,自然语言生成技术可以帮助根据关键词生成段落文本,但目前自然语言生成技术能够生成的文本,多为具有严格模式的“定型文体”,如天气预报、股市行情、球赛解说等,会话的生成尚有一定的困难,句子之间的连贯性较差,因此根据若干关键词生成课文会话尚有难度,不过随着人工智能行业的飞速发展,成熟的模型和算法也将很快出现,届时教材编写者可以根据词汇库,选取同一话题下的若干词汇,让计算机自动生成多份课文文本,并进行挑选和后编辑,从而更进一步加快教材的编写。
四、难度估计与本土化
汉语的难度估计、词汇等级、易读性研究等也是近来语言教学、计算语言学等领域的热门话题,已经有不少学者将难度的量化引入国际中文教育的研究领域当中〔10-12〕。对于专门用途汉语教学而言,文本难度的量化意义尤为重要。专门用途汉语教学往往以短期班教学为主,而根据学生的汉语水平选取相应难度的教材,则往往可以使教学效果事半功倍。因此在教材编制时,应对课文进行客观的难度的量化评估,并进行标注。
以上一章编写的“行程预定”这一话题的课文为例,我们使用“汉语阅读分级指难针”〔13〕工具对课文的难度进行评估可以得到如图2结果。
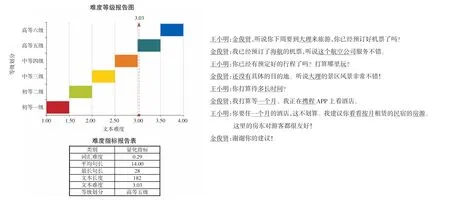
图2 “行程预定”课文难度分析
从难度指针给出的报告可以看出,该段对话的难度为高等五级,文本难度为3.03。属于仅适合汉语高级学习者的文章,但实际阅读课文不难发现,该课文远低于高级水平,查看字词的具体分析报告我们发现,“汉语阅读分级指难针”对命名实体识别能力较弱,且分词也存在一定的问题,如无法识别命名实体中的人名“王小明”“金俊贤”,机构名“海航”“携程”,地名“大理”等。短语“多长时间”“一个月”等也没有正确进行分词,因此无法对应到HSK等级或者词汇等级大纲〔14〕,从而全部判定为了“超纲词”(上文中下划线部分),使难度指数显示虚高。因此建议在使用时,人为或者通过命名实体识别与标注工具,事先将命名实体剔除,再进行难度评估,从而使难度评估更客观,更接近真实难度。例文剔除了命名实体之后,评估的难度如图3所示。
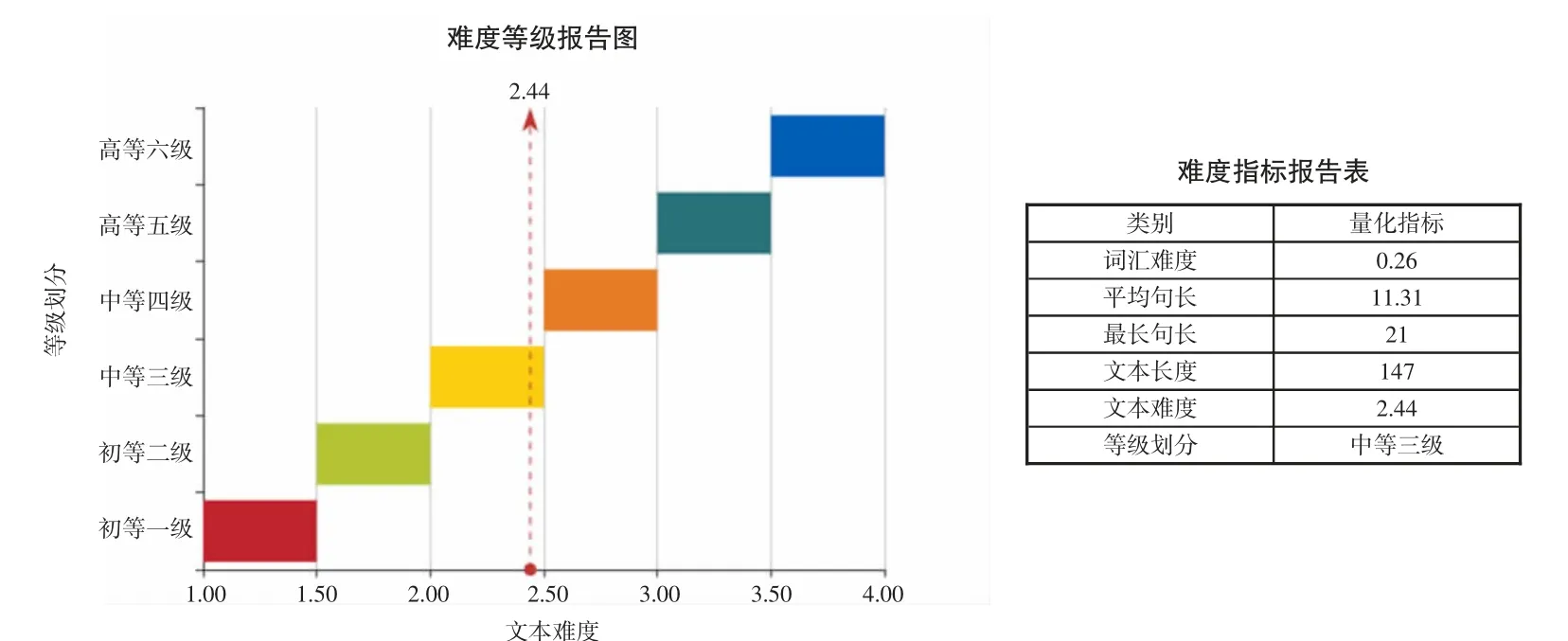
图3 修改命名实体后“行程预定”课文难度分析
剔除命名实体之后,课文文本难度指数下降为2.44,适合中等三级难度,难度评估指数与实际的经验值较为吻合。
教材本土化也是教材编写中不可忽略的一个问题。其中对于目的国家需求的调研,前文已经讲过,本部分仅对课文与生词的翻译,尤其是小语种的翻译问题提出建议和看法。对于专门用途汉语教材而言,其生词往往是来自专业领域的专业词汇,教材编写时常缺少相应的领域翻译人才,从而造成教材本土化翻译质量的下降。在自然语言处理领域,机器翻译可以解决基本的翻译问题,但对于小语种的翻译,质量也难以得到保证,“一带一路”沿线国家,小语种较多,因此可以使用机器与人工相结合的方法,构建“机器翻译+后编辑”的模式,由机器翻译系统先进行翻译,教材编写者与目的国本土教师/学生共同进行译后编辑,从而提高机器翻译的质量,以达到较高质量本土化翻译的目的。
综上,随着“后疫情时代”的到来,世界正经历着百年未有之大变局。变革预示着机遇,也带来挑战。国际中文教育的勃发代表的是中国的文化软实力,在“一带一路”的倡议下“汉语热”本身也代表着国际话语权〔15〕。国际中文教育教材编写的意义也已经不止于教材本身,而是中国“文化自信”的一种表现形式,是“走出去”战略的一部分。随着“一带一路”合作的不断加深,专门用途汉语的教学必将迎来更大的缺口,同时也会带来更大的契机。结合自然语言处理等人工智能新技术与算法,保持专门用途汉语教学内容、教材的时效性,是为世界全面展示蓬勃发展、与时俱进的中国形象的一个窗口,也是未来学科发展必将要关注与研究的重要问题。期待自然语言处理相关技术和算法能给教材编写带来更多便利的同时,也期待越来越多的国际中文教育研究者关注新技术以及跨学科研究与合作,共同推进国际中文教育的发展。
猜你喜欢
现代计算机(2021年33期)2022-01-21
长江丛刊(2019年25期)2019-11-15
电脑知识与技术(2019年23期)2019-11-03
小雪花·初中高分作文(2016年5期)2016-05-14
儿童故事画报·智力大王(2016年1期)2016-02-25
读者·校园版(2015年7期)2015-05-14
心理学报(2014年4期)2014-02-02
教学与管理(理论版)(2009年9期)2009-11-04
视野(2009年2期)2009-03-11
