
基于事件表示的机器阅读理解模型
2022-07-29 08:17王元龙刘晓敏张虎
计算机应用 2022年7期
王元龙,刘晓敏,张虎
基于事件表示的机器阅读理解模型
王元龙*,刘晓敏,张虎
(山西大学 计算机与信息技术学院,太原 030006)( ∗ 通信作者电子邮箱ylwang@sxu.edu.cn)
要真正理解一段语篇,在阅读理解过程对原文主旨线索的把握是非常重要的。针对机器阅读理解中主旨线索类型的问题,提出了基于事件表示的机器阅读理解分析方法。首先,通过线索短语从阅读材料中抽取篇章事件图,其中包括事件的表示、事件要素的抽取和事件关系的抽取等;然后,综合考虑事件的时间要素、情感要素以及每个词在文档中的重要性,采用TextRank算法选出线索相关的事件;最后,依据所选出的线索事件构建问题的答案。在收集了339道线索类题组成的测试集上,实验结果表明所提方法在BLEU和CIDEr评价指标上与基于TextRank算法的句子排序方法相比均有所提升,具体来说,BLEU-4指标提升了4.1个百分点,CIDEr指标提升了9个百分点。
自然语言处理;阅读理解;主旨线索类型问题;事件表示;篇章事件图
0 引言
机器阅读理解(Machine Reading Comprehension, MRC)任务旨在让机器阅读理解给定的文档,能够从文档中寻找答案用于回答用户提出的问题,其目标是通过综合运用文本的表示、理解、推理等自然语言处理与理解技术,使计算机具有和人类一样理解文章的能力。由于文章和问题均采用人类语言的形式,其背后涉及到词法、句法、语法和语义等多方面的信息,因此这一任务的评价效果成为衡量机器对自然语言理解能力的重要指标。
目前,针对机器阅读理解中的问题类型分为不同的任务:完型填空类问题,问句是将文档中一个句子中的某个实体抽掉所产生,要求机器能正确预测被抽掉的实体,如数据集包括CNNDM(Cable News NetworkDailyMail)[1]和讯飞、哈工大的中文完形填空数据集HFL-RC(joint laboratory of HIT and iFLYTEK research-Reading Comprehension)[2]等;选择类问题,每篇文章对应多个问题,每个问题有多个候选答案,机器需要在候选答案中找到最合适选项,如数据集MCTest(Machine Comprehension of Test)[3]、RACE(ReAding Comprehension dataset collected from English Examinations)[4]等;片段抽取类问题,通常给定文章和问题,机器需要在文章中找到答案对应的区域,给出开始位置和结束位置,如数据集SQuAD(Stanford Question Answering Dataset)[5]、TriviaQA[6]等;自由形式问题,该类问题是来自搜索引擎或社区问答,其问题和答案是由人工整理的,需要理解多个段落回答问题,如DuReader[7]、HotpotQA[8]、NarrativeQA[9]等。
从上述机器阅读理解任务的问题可以感受到人工智能技术正在为计算机赋予阅读、分析和归纳文本的能力。为了反映机器更深的理解能力,很多学者针对高考语文阅读理解任务进行了研究。针对选择类型题,郭少茹等[10]提出了基于多维度的投票方法,该方法将不同维度的语义相关性作为度量标准,运用投票算法的思想选取问题的最佳选项。王元龙等[11]先把选项按不同的特征分为4类,并针对因果关系类选项提出了相应的解决方案,该方法仅是对选项的因果关系支持度分析做了一些探索,没有考虑文档中的篇章关系。针对问答类题型,王智强等[12]利用篇章框架语义分析方法抽取答案句,该方法能够从相似性与相关性两方面获得更好的答案句抽取结果。谭红叶等[13]对抽取的答案句提出了句子融合方案,使得答案更加简洁、流畅。张兆滨等[14]提出了基于多任务层级长短时记忆网络的问题扩展建模方法用于回答观点类问题。谭红叶等[15]提出了一种基于BERT(Bidirectional Encoder Representation from Transformers)的多任务阅读理解模型,利用注意力机制获得丰富的问题与篇章的表示,实现了问题的多样性解答。杨陟卓等[16]针对阅读理解中概括型问答题提出了基于词语相似度匹配、框架匹配、篇章主题同时抽取候选句的方法,该方法可以有效抽取与问题相关的内容要点以及作者的观点态度句,但仍缺乏对原文的句间关系分析以及对背景材料进行深层语义理解。
本文关注高考语文中的文学作品阅读理解任务,重点解决主旨线索类型的问答类型题。该任务中问题的答案是原文中的主旨线索,需要先对原文进行深度理解,包括整体语篇结构、作者情绪变化等。该类任务的问题形式如例1和例2所示:
例1 [北京/2016]:作者对老腔的认识经历了怎样的变化过程?请结合全文作简要说明。
线索:很难产生惊诧之类的反应→生出神秘感来→因相见恨晚而觉得懊丧自责→老腔具有强烈的呼应和感染力,触动了当代人的神经→观众与老腔应该是融为一体的,自己这种拉开间距寻求客观欣赏的举措是多余的
例2 [北京/2018]:本文题目“水缸里的文学”意蕴丰富,综观全文,你如何理解其中的寓意?以此为题有怎样的表达效果?
线索:水缸与我童年密切相伴,是我童年认识世界,体味人生,引发文学梦的主要对象→水缸引发了关于河蚌故事的论述,激发了作者诗意的想象,是作者阅读和体会世界的方式→因为小时候物质所限,作者渴望但无法阅读儿童书,水缸刺激作者的想象、智力→水缸是作者童年时期的记忆,保留了作者的好奇心,保留了奇迹般的创造力
为了更好地理解原文的主旨线索,本文借助Zwann等[17]提出的事件索引假设理论,该理论指出在语篇阅读中人们会根据不同的索引来整体地建构所阅读过的信息。文献[17]中认为,阅读故事时,读者监控情境模型并更新之,情境模型有5个维度:时间、空间、因果、意图和实体(客体、主角、主角的情绪等)。因此本文提出基于事件表示的阅读理解模型,以事件作为篇章的基本单元和处理单位,存储组成事件的概念及其之间的关系,进而回答阅读理解中主旨线索类型的问题。首先,构建原文的事件结构图,需要考虑适合文学作品的事件表示;然后,根据重要度选出线索相关的事件;最后,依据线索相关事件整理出主旨线索答案。
1 相关工作
不同领域对事件的定义存在差异,并且体现了该领域所关注的实际问题。信息领域则更关注事件在信息处理中的应用,包括事件的识别以及事件应用。事件识别也称作事件抽取(event extraction),是信息抽取领域中重要的一个组成部分,包括事件要素识别及事件关系识别。
1.1 事件要素识别
在事件抽取的过程中,一个事件往往被更形式化地定义为包含了事件触发器(event trigger)、事件类型(event type)、事件元素(event argument)和事件元素角色(event argument role),因此事件抽取的任务就是识别出上述事件要素并且进行结构化组织[18]。ACE(Automatic Content Extraction)2015定义了8种事件类别(life,movement,conflict,contact等)和33种子事件类别(born,marry,injury,transport,attack等),每种事件类别对应唯一的事件模板,如子事件born,事件模板(template)包括person、time-within、place等。
1.2 事件关系识别
目前,时序关系和因果关系是最重要的事件关系。Chambers等[19]提出脚本叙事性事件链(narrative event chain)概念,认为这是一种新的知识结构化表示方式,叙事性事件链由一系列的叙事性事件按照时序组合形成,并进一步在这个工作的基础上,组织了相关的评测TimeML(Time Markup Language)。TimeML评测主要还是集中在对时序关系事件的识别,大致任务分成两部分:一是识别两个事件实体,其次是判定两个事件之间的时序关系。之后,事件之间的因果关系(Causality)也被人们提出,具有代表性的因果关系标注语料库有Palmer等[20]提出的PropBank 以及Prasad等[21]提出的PDTB (Penn Discourse TreeBank),前者标注了动词与动词、动词与从句之间的因果关系,后者标注了从句之间的因果关系,两个因果关系标注语料库进一步推动了事件因果关系抽取技术的发展。Kruengkrai等[22]用 MCNNs(Multi-Column Neural Networks)从海量语料中寻找一个事件对的因果关系路径,从而判断事件对之间是否有因果关系。Kang等[23]也是从文本中挖掘因果特征来对时序事件的因果关系进行判断。
本文借鉴上述事件要素和事件关系识别的思想,进一步提出了适合文学作品的事件表示、事件要素和关系类型定义及其抽取方法,进而构建篇章事件结构图,用于回答阅读理解中主旨线索类型的问题。
2 基于事件表示的阅读理解方法
要真正地理解一个语篇,对原文主旨线索的把握是非常重要的阅读理解过程。文章主旨线索是在文章的不同段落中都可见的词、句子或是情节等,是文章结构的红线。它能贯穿全文,使文章浑然一体,使结构完整严谨。为了让机器能够以一种更为接近于人脑的知识结构体系去理解语篇,本文提出了基于事件表示的阅读理解模型。
本文借助事件标记模型来构建阅读理解模型,给出了主旨线索类问题的解决方案。首先,通过事件要素抽取和多粒度事件表示构建原文的事件结构图,需要考虑适合文学作品的事件表示;然后,基于TextRank算法选取关键事件;最后,依据关键事件构建线索答案。
2.1 篇章事件图构建
本文以事件作为基本单位把阅读理解中的原文表示成事件图。事件图的构建包括事件表示以及事件间关系的表示。
2.1.1事件表示
文学作品阅读理解中的事件是指发生在一段时间内,由若干实体参与,表现出某些情绪或动作的描述,通常是一个句子或句群。因此本文将情境模型的五维事件进行整合,给出了适合文学作品的事件形式化定义,具体为:
(,,)
其中:表示动作;表示实体(包括主体和客体);表示时间;表示情绪。
2.1.2事件要素抽取方法
本文对不同的事件要素采用了不同的抽取方法,其中动作和实体要素采用基于规则的方法,时间要素采用基于汉语框架网(Chinese FrameNet, CFN)的方法,情绪要素采用基于词典的方法。具体抽取方法如下:
1)基于规则的动作和实体要素抽取。本文借助哈工大的LTP(Language Technology Platform)的语义角色标注和语义依存句法标注来抽取动作和实体要素。具体规则如下:①在语义角色标注结果中如果有明确的论元,即有A0、A1的标注,就采用语义角色标注的结果;②否则基于语义依存标注提取句子中的动词短语表示事件要素,动词短语的关系类型包括主谓关系(SuBject-Verb, SBV)、动宾关系(Verb-OBject, VOB)以及动补关系(ATTribute, ATT)。另外,动词前的程度词和否定词对事件抽取起到重要的作用,因此,本文构建了程度词和否定词表,将其并入动作要素中。
2)基于CFN的时间要素抽取。
本文采用与时间相关的框架识别时间要素,其中包括时间测量、时间向量、时间跨度、历法单位、时量场景、时间亚区以及相对时间框架。每个框架包括若干与时间相关的词元,如表1所示。

表1 时间相关框架描述
3)基于词典的情绪要素抽取。
情绪要素抽取采用大连理工大学自然语言处理课题组发布的情感词典[24],在原文中出现的情感词当作该事件的情绪要素,该词典包含27 466个情感词。
2.1.3多粒度事件关系表示
为了更好地表达原文中的线索,本文依据句内事件关系和句间事件关系,提出了多粒度事件关系表示。首先,扫描文本,按句号分割原文,识别句间的事件关系;然后,按照上述方法识别句子中的单个事件,依据事件关系线索词识别事件与事件之间的关系。目前有因果、转折和时序三种事件关系。例:[朋友跟我说老腔如何如何,我却很难产生惊诧之类的反应。因为我在关中地区生活了几十年,却从来没听说过老腔这个剧种。]表示为如图1所示的多粒度事件关系表示。

图1 多粒度事件关系表示
2.2 基于TextRank算法的事件选取方法
在提取原文的主旨线索时,通常需要考虑以下几个特点:1)时间连“线”,用时空词语连接线索;2)以物作“线”和反复出“线”,高频词和关键词经常出现在线索中;3)以情导“线”,情感词有助于分析材料之间的内在联系,理清感情发展变化的轨迹。基于上述特点,本文提出了将事件中的四种要素当作事件排序的重要要素成分,提出了基于TextRank算法的事件选取方法,具体如算法1所示。
算法1 重要事件选取。
输入 原文事件关系图;
输出 重要事件所在的句子。
步骤1 为每个事件找到向量表示(四种要素的词向量);
步骤2 计算事件向量间的相似性并存放在矩阵中;
步骤3 将相似矩阵转换为以事件为节点、相似性得分为边的图结构;
步骤4 利用TextRank算法,将排名最高的6个事件输出构成最后的重要事件;
步骤5 基于识别的重要事件检索出其所在的句子。
2.3 答案构建
本文按照原文句子顺序将其所抽取的重要事件所在句子进行排序。为了使答案更加合理,对事件句子进行了融合。如果抽取出的两个事件为转折关系,只保留后面的事件(转折后的事件更重要)。如果抽取出的两个事件为因果关系,只保留结果的事件。而对于时序关系的事件放在一个片段描述,具体格式如下:

其中,表示事件,小括号()表示时序关系的事件集合。另外,为了让答案更加合理,将答案中的第一人称代词用“作者”代替。
3 实验与结果分析
3.1 评测语料及标准

本文采用了BLEU-(BiLingual Evaluation Understudy)(=1,2,3,4)[17]和CIDEr(Consensus-based Image Description Evaluation)[19]5个评价指标对抽取的答案进行评价。其中,BLEU-指标更关注抽取答案的准确性和流畅度,用于分析抽取答案中有多少元词组出现在参考答案中。CIDEr指标主要评价模型有没有抓取到关键信息,计算参考译文和候选译文之间的TF-IDF(Term Frequency- Inverse Document Frequency)向量余弦距离,以此度量二者的相似性。
3.2 结果分析
为了验证本文方法的效果,采用基于TextRank算法的句子排序方法作为基线方法,把文本分割成若干组成单元(单词、句子)建立图模型, 利用投票机制对文本中的重要成分进行排序, 利用单篇文档本身的信息实现重要句排序,TextRank算法输出Top-6的句子作为主旨线索。
表2给出了本文方法与句子排序方法在5个评价指标上实验结果比较。从表2可以看出,本文方法相较直接采用TextRank算法的句子排序在5个评价指标上均有所提升,表明本文方法答案的准确性和流畅度以及抓取到关键信息的能力均优于直接采用TextRank算法的句子排序方法。另外,本文还测试了文献[16]中基于词语相似度匹配、框架匹配、篇章主题匹配同时抽取候选句的方法用在线索类题型的效果,如表2所示。实验结果表明,文献[16]所提方法在5个评价指标上比基线方法略高,低于本文方法,进一步验证了本文方法的有效性。
表2不同方法对比实验结果 单位:%

Tab.2 Experimental results comparison of different methods unit:%

例3 [北京/2016]:作者对老腔的认识经历了怎样的变化过程?请结合全文作简要说明。
参考答案:作者从没有听过老腔,认为老腔影响小。认为老腔演出者不过是民间演出班社。到后来听过一次老腔,深深地被老腔震撼。为自己的小说《白鹿原》中没有加入老腔的表演而遗憾,到最后在中山音乐堂再次领悟了老腔的震撼力。对老腔的理解更加深入了。
本文方法抽取的答案句:
2)因为我在关中地区生活了几十年[时间测量],却从来没听说过老腔这个剧种,可见其影响的宽窄了。

构建答案:
1)作者第一次看老腔演出,是前两三年的事,朋友跟作者说老腔如何如何,作者却很难产生惊诧之类的反应。2)开幕演出前的等待中,这是华阴县的老腔演出班社,老腔是了不得的一种唱法,也就能想到他们是某个剧种的民间演出班社,作者对老腔便刮目相看了。3)直到后来小说《白鹿原》改编成话剧,让作者有了一种释然的感觉。4)后来还想再听老腔,却难得如愿。
为了验证本文抽取的线索句是否容易聚集在原文中的某个段落或片段内,本文统计了原文前50句被抽取到作为文中线索句的文章数量,具体如图2所示。其中,横坐标为文中句子编号,纵坐标为某句作为抽取结果的文章数量。从图2中可以看出,与基于TextRank算法的句子排序方法相比,本文方法抽取到的句子分散在原文,更符合作者的线索思路。
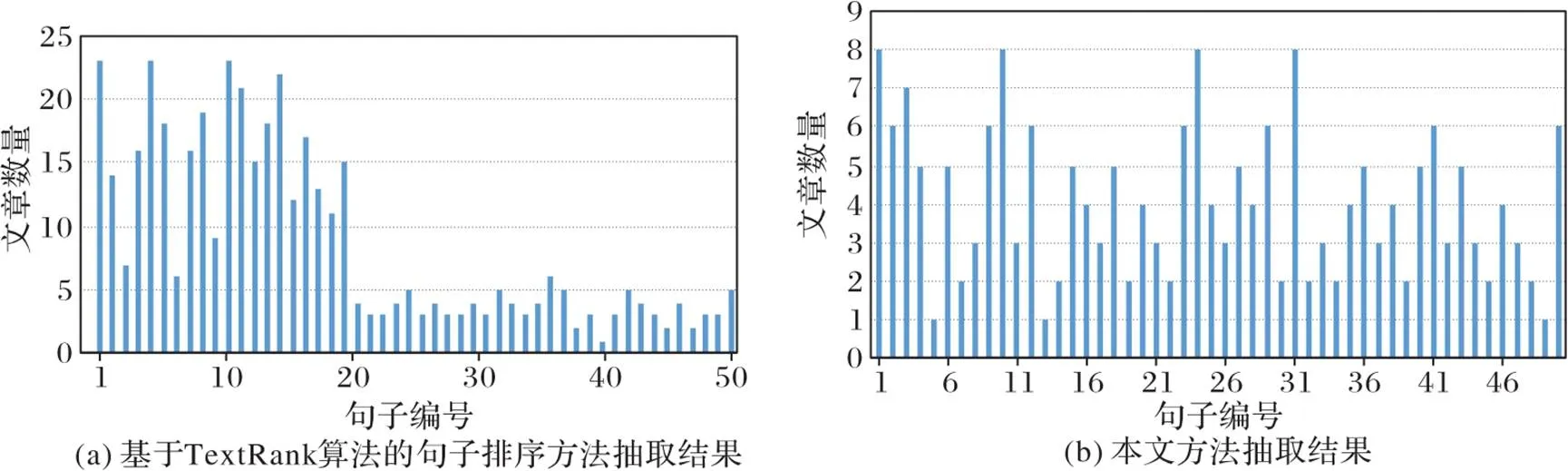
图2 线索句抽取结果比较
4 结语
本文关注高考语文中的文学作品阅读理解任务,重点研究解决主旨线索类型的问题。借助事件标记模型,本文提出了基于事件表示的阅读理解模型,以事件作为篇章的基本单元和处理单位,存储组成事件的概念及其之间的关系,进而回答阅读理解中主旨线索类型的问题。实验结果表明,本文方法可以抽出答案要点,较好地反映出原文的线索及行文思路。
但是本文还存在如下不足:1)答案为从原文中抽取的结果,缺乏归纳能力;2)时间片段识别不够准确,造成抽取的线索片段不均匀。这些不足是我们未来需要改进的方向,以期在原来基础上进一步研究探索出性能更优的线索抽取方 法。
[1] CHEN D Q, BOLTON J, MANNING C D. A thorough examination of the CNN/Daily Mail reading comprehension task[C]// Proceeding of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg, PA: Association for Computational Linguistics, 2016: 2359-2367.
[2] CUI Y M, LIU T, CHEN Z P, et al. Consensus attention-based neural networks for Chinese reading comprehension[C]// Proceeding of the 26th International Conference on Computational Linguistics: Technical Papers. [S.l.]: The COLING 2016 Organizing Committee, 2016:1777-1786.
[3] RICHARDSON M, BURGES C J C, RENSHAW E. MCTest: a challenge dataset for the open-domain machine comprehension of text[C]// Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2013: 193-203.
[4] LAI G K, XIE Q Z, LIU H X, et al. RACE: large-scale Reading comprehension dataset from examinations[C]// Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2017:785-794.
[5] RAJPURKAR P, ZHANG J, LOPYREV K, et al. SQuAD: 100,000+ questions for machine comprehension of text[C]// Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2016: 2383-2392.
[6] JOSHI M, CHOI E, WELD D S, et al. TriviaQA: a large scale distantly supervised challenge dataset for reading comprehension[C]// Proceeding of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg, PA: Association for Computational Linguistics, 2017: 1601-1611.
[7] HE W, LIU K, LIU J, et al. DuReader: a Chinese reading comprehension dataset from real-world applications[C]// Proceedings of the 2018 Workshop on Machine Reading for Question Answering. Stroudsburg, PA: Association for Computational Linguistics, 2018:37-46.
[8] YANG Z L, QI P, ZHANG S Z, et al. HotpotQA: a dataset for diverse, explainable multi-hop question answering[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2018:2369-2380.
[9] KOČISKÝ T, SCHWARZ J, BLUNSOM P, et al. The NarrativeQA reading comprehension challenge[J]. Transactions of the Association for Computational Linguistics, 2017, 6:317-328.
[10] 郭少茹,张虎,钱揖丽,等. 面向高考阅读理解的句子语义相关度[J]. 清华大学学报(自然科学版), 2017, 57(6):575-579, 585.(GUO S R, ZHANG H, QIAN Y L, et al. Semantic relevancy between sentences for Chinese reading comprehension on college entrance examinations[J]. Journal of Tsinghua University (Science and Technology), 2017, 57(6):575-579, 585.)
[11] 王元龙,李茹,张虎,等. 阅读理解中因果关系类选项的研究[J]. 清华大学学报(自然科学版), 2018, 58(3):272-278.(WANG Y L, LI R, ZHANG H, et al. Causal options in Chinese reading comprehension[J]. Journal of Tsinghua University (Science and Technology), 2018, 58(3):272-278.)
[12] 王智强,李茹,梁吉业,等. 基于汉语篇章框架语义分析的阅读理解问答研究[J]. 计算机学报, 2016, 39(4): 795-807.(WANG Z Q, LI R, LIANG J Y, et al. Research on question answering for reading comprehension based on Chinese discourse frame semantic parsing[J]. Chinese Journal of Computers, 2016, 39(4): 795-807.)
[13] 谭红叶,赵红红,李茹. 面向阅读理解复杂问题的句子融合[J]. 中文信息学报, 2017, 31(1):8-16.(TAN H Y, ZHAO H H, LI R. Sentence fusion for complex problems in reading comprehension[J]. Journal of Chinese Information Processing, 2017, 31(1):8-16.)
[14] 张兆滨,王素格,陈鑫,等. 阅读理解中观点类问题的扩展研究[J]. 中文信息学报, 2020, 34(6): 89-96, 105.(ZHANG Z B, WANG S G, CHEN X, et al. Question expansion for machine reading comprehension of opinion[J]. Journal of Chinese Information Processing, 2020, 34(6): 89-96, 105.)
[15] 谭红叶,屈保兴. 面向多类型问题的阅读理解方法研究[J]. 中文信息学报, 2020, 34(6): 81-88.(TAN H Y, QU B X. An approach to multi-type question machine reading comprehension[J]. Journal of Chinese Information Processing, 2020, 34(6):81-88.)
[16] 杨陟卓,李春转,张虎,等. 基于CFN和篇章主题的概括型问答题的解答[J]. 中文信息学报, 2020, 34(12): 73-81.(YANG Z Z, LI C Z, ZHANG H, et al. Question answering for overview questions based on CFN and discourse topic[J]. Journal of Chinese Information Processing, 2020, 34(12): 73-81.)
[17] ZWANN R A, RADVANSKY G A, HILLIARD A E, et al. Constructing multidimensional situation models during reading[J]. Scientific Studies of Reading, 1998, 2(3):199-220.
[18] HUANG L F, JI H, CHO K, et al. Zero-shot transfer learning for event extraction[C]// Proceeding of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg, PA: Association for Computational Linguistics, 2018: 2160-2170.
[19] CHAMBERS N, JURAFSKY D. Unsupervised learning of narrative event chains[C]// Proceedings of the 46th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2008:789-797.
[20] PALMER T, GILDEA D, KINGSBURY P. The proposition bank: an annotated corpus of semantic roles[J]. Computational Linguistics, 2005, 31(1): 71-106.
[21] PRASAD R, MILTSAKAKI E, DINESH N, et al. The Penn Discourse TreeBank 2.0 annotation manual[R/OL]. (2007-12-17) [2021-02-12].https://www.seas.upenn.edu/~pdtb/PDTBAPI/pdtb-annotation-manual.pdf.
[22] KRUENGKRAI C, TORISAWA K, HASHIMOTO C, et al. Improving event causality recognition with multiple background knowledge sources using multi-column convolutional neural networks[C]// Proceedings of the 31st AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2017:3466-3473.
[23] KANG D, GANGAL V, LU A, et al. Detecting and explaining causes from text for a time series event[C]// Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2017:2758-2767.
[24] 徐琳宏,林鸿飞,潘宇,等. 情感词汇本体的构造[J]. 情报学报, 2008, 27(2): 180-185.(XU L H, LIN H F, PAN Y, et al. Constructing the affective lexicon ontology[J]. Journal of the China Society for Scientific and Technical Information, 2008, 27(2): 180-185.)
WANG Yuanlong, born in 1983, Ph. D., associate professor. His research interests include natural language processing, machine learning.
LIU Xiaomin, born in 2000, M. S. candidate. Her research interests include natural language processing.
ZHANG Hu, born in 1979, Ph. D., associate professor. His research interests include natural language processing.
Machine reading comprehension model based on event representation
WANG Yuanlong*, LIU Xiaomin, ZHANG Hu
(,,030006,)
In order to truly understand a piece of text, it is very important to grasp the main clues of the original text in the process of reading comprehension. Aiming at the questions of main clues in machine reading comprehension, a machine reading comprehension method based on event representation was proposed. Firstly, the textual event graph including the representation of events, the extraction of event elements and the extraction of event relations was extracted from the reading material by clue phrases. Secondly, after considering the time elements, emotional elements of events and the importance of each word in the document, the TextRank algorithm was used to select the events related to the clues. Finally, the answers of the questions were constructed based on the selected clue events. Experimental results show that on the test set composed of the collected 339 questions of clues, the proposed method is better than the sentence ranking method based on TextRank algorithm on BiLingual Evaluation Understudy (BLEU) and Consensus-based Image Description Evaluation (CIDEr) evaluation indexes. In specific, BLEU-4 index is increased by 4.1 percentage points and CIDEr index is increased by 9 percentage points.
natural language processing; reading comprehension; question of main clues; event representation; textual event graph
This work is partially supported by National Natural Science Foundation of China (61806117, 62176145).
1001-9081(2022)07-1979-06
10.11772/j.issn.1001-9081.2021050719
2021⁃05⁃07;
2022⁃02⁃21;
2022⁃02⁃25。
国家自然科学基金资助项目(61806117, 62176145)。
TP391.1
A
王元龙(1983—),男,山西大同人,副教授,博士,CCF会员,主要研究方向:自然语言处理、机器学习; 刘晓敏(2000—),女,山西朔州人,硕士研究生,主要研究方向:自然语言处理; 张虎(1979—),男,山西大同人,副教授,博士,CCF会员,主要研究方向:自然语言处理。
猜你喜欢
金秋(2022年14期)2022-11-01
走向世界(2022年18期)2022-05-17
海峡姐妹(2019年6期)2019-06-26
美文(2018年18期)2018-09-18
名作欣赏(2017年25期)2017-11-06
延河(2016年6期)2016-08-04
债券(2015年9期)2015-09-29
债券(2015年7期)2015-08-08
小学生·多元智能大王(2014年7期)2014-08-22
小雪花·初中高分作文(2009年7期)2009-11-16
