
基于压缩提炼网络的实时语义分割方法
2022-07-29 07:27王娟袁旭亮武明虎郭力权刘子杉
计算机应用 2022年7期
王娟,袁旭亮,武明虎*,郭力权,刘子杉
基于压缩提炼网络的实时语义分割方法
王娟1,2,3,袁旭亮1,武明虎1,2,3*,郭力权1,刘子杉1
(1.湖北工业大学 电气与电子工程学院,武汉 430068; 2.太阳能高效利用及储能运行控制湖北省重点实验室(湖北工业大学),武汉 430068; 3.武汉华安科技有股份限公司博士后工作站,武汉 430068)( ∗ 通信作者电子邮箱wuxx1005@hbut.edu.cn)
针对目前语义分割算法难以取得实时推理和高精度分割间平衡的问题,提出压缩提炼网络(SRNet)以提高推理的实时性和分割的准确性。首先,在压缩提炼(SR)单元中引入一维(1D)膨胀卷积和类瓶颈结构单元,从而极大地减少模型的计算量和参数量;其次,引入多尺度空间注意(SA)混合模块,从而高效地利用浅层特征的空间信息;最后,通过堆叠SR单元构成编码器,并采用两块SA单元在编码器的尾部构成解码器。实验仿真表明,SRNet在仅有30 MB参数量及8.8×109每秒浮点操作数(FLOPS)的情况下,仍可在Cityscapes数据集上获得68.3%的平均交并比(MIoU)。此外,所提模型在单块NVIDIA Titan RTX卡上实现了12.6 帧每秒(FPS)的前向推理速度(输入像素的大小为512×1 024×3)。实验结果表明,所设计的轻量级模型SRNet很好地在准确分割和实时推理间取得平衡,适用于算力及功耗有限的场合。
语义分割;轻量级网络;实时推理;空间注意混合模块;一维膨胀卷积
0 引言
图像语义分割旨在将图像中的每一个像素分配到一个相应的类,是计算机视觉技术中重要组成部分,在机器人导航、自动驾驶和虚拟现实等领域具有巨大的应用潜力[1-3]。目前语义分割模型很难在准确性和实时性之间取得很好的平衡,大部分的模型牺牲准确性来获取实时性或者牺牲实时性来获取准确性。然而,语义分割的应用场景受限于功耗和算力;因此,开发出兼具准确性和实时性的算法模型具有重大的现实意义。
目前很多研究工作已经在语义分割的实时性和准确性间的矛盾中取得了一些实质性的进展。SegNet(semantic pixel-wise Segmentation Network)[4]采用非对称的编码解码(Encoder-Decoder)结构,以VGG16(Visual Geometry Group)作为编码器进行特征提取,而精小的编码器负责恢复特征映射。SegNet[4]的池化索引策略有助于恢复物体的空间细节,但是因为下采样程度低使得模型的接受野有限。ENet(Efficient neural Network)[5]同样采用存储池化索引策略,其利用浅且窄的模型结构来取得实时性。池化索引有助于恢复下采样丢失的空间细节但消耗过多的存储空间(存储索引);浅且窄的模型结构有助于提高推理速度但存在特征摄取能力不足、语义分辨能力低、模型接受野窄的缺陷。为了解决接受野窄和语义不充足的问题,Encoder-Decoder结构的U-Net(U-shaped neural Network)[6]采用极大的下采样及宽的模型结构,同时跳转连接能够充分地利用浅层特征的空间细节。然而,U-Net[6]宽且深的模型结构使得参数及结构极大以至于模型的实时性差,因此不适用于算力及功耗有限的移动设备。SQNet(SQueeze neural Network for semantic segmentation)[7]采用非对称Encoder-Decoder结构获得实时性。SQNet[7]以SqueezeNet(Squeeze neural Network)为编码器,解码器由融合低水平特征和高水平特征的提炼单元构成。SQNet[7]的跳转连接策略解决池化索引消耗过多内存的问题,其编码器尾部的并行膨胀卷积有助于扩大模型的接受野,但其计算复杂的提炼模块及宽的模型结构(两个拓展卷积的并操作)不适用于模型的轻量化要求。为了解决模型在浅且窄的条件下无法获得充足的接受野和强分辨能力的缺陷,ERFNet(Efficient Residual Factorized ConvNet)[8]引入了1D卷积及膨胀卷积到编码单元中。膨胀卷积使得ERFNet[8]在浅的模型结构下获得大的接受野,1D卷积减少参数和计算量以使模型有强的语义分类能力;但是,ERFNet[8]无法解决因为过大下采样造成的空间信息丢失的问题,无法实现对小物体的准确恢复。
通过对当前语义分割算法优势与劣势的充分研究,本文采用有益于实现高准确性和实时性的算法来取得两者间的平衡,提出压缩提炼网络(Squeezing and Refining Network, SRNet)模型,算法总体结构如图1所示。

图1 模型算法总体结构
本文模型1D卷积在获取近似标准卷积特征摄取能力的同时,可有效地减少计算量和参数量,类瓶颈的编码单元使得模型的计算量及参数量得到进一步减少,膨胀卷积使模型在较浅的条件下有大的接受野。模型解码器部分的空间注意机制有助于恢复空间信息及抑制浅层噪声。总的来说,本文提出的网络模型SRNet的贡献可以归结为以下两点:
1) 压缩提炼(Squeezing and Refining, SR)单元在减少计算量及参数量的同时有强的特征提取能力,类瓶颈结构使得模型推理速度得到极大的提高(起通道压缩提炼作用),并行的两条1D带膨胀率的卷积路径弥补了单一1D卷积路径感受野小的缺陷。
2) 空间注意(Spatial Attention, SA)混合单元构成的解码器利用浅层特征所包含的空间信息来恢复物体的边缘信息,同时注意机制有效地抑制了浅层特征所包含的噪声使得模型分割质量更高。此外,空间注意的形式极大地减小了传统注意机制的复杂计算。
在Cityscape数据集上验证提出模型的有效性。模型获得68.3%的平均交并比(Mean Intersection over Union, MIoU)准确性,在单块NVIDIA Titan RTX卡上实现12.6帧每秒(Frames Per Second, FPS)的推理速度(输入的像素为512×1 024×3)。同时,模型的参数量仅为30 MB,只有8.8×109每秒浮点操作数 (Floating-point Operation Per Second, FLOPS)。这些表明SRNet能够在实时性和准确性间取得平衡。
1 相关工作
在图像语义分割领域,足够大的视野及足够多的语义信息意味着模型有更高的分割准确性,浅且窄的模型结构意味着更快的推理速度,充足的空间信息意味着更强的边缘定位。目前很少有网络模型能包含所有的算法优势,大部分模型只在某些方面取得成功。因此,语义分割模型大致可以分为获取实时性、扩大视野及获取丰富内容信息和利用注意机制这几个方面。
1.1 实时性分割
由于语义分割应用场合有算力及功耗的限制,因此有相应研究针对性地解决目前语义分割不适用于移动设备或者低功耗场合的问题。ENet[5]采用早期下采样及浅窄的结构实现实时性。早期下采样使得模型在小的特征空间中推理,浅且窄的结构减小对内存的需求及计算量。SegNet[4]采用非对称的Encoder-Decoder结构,以Res18(Residual Network)为解码器负责提取特征,以瘦小的解码器负责恢复特征到原始空间大小。SegNet[4]瘦小的解码器占很小的计算量及存储空间,因此模型有很高推理速度。BiSeNet(Bilateral Segmentation Network)[9]采用空间特征提取路径和内容信息提取路径分开的策略。模型空间特征提取路径通过小步值卷积以保留充足的空间细节,内容信息提取路径则通过大的池化步值实现快速下采样以扩大视野,最后并合两个路径实现实时性语义分割。ICNet(Image Cascade Network)[10]采用不同的输入像素大小到不同的路径以获取不同的特征信息,避免了采用深且宽的模型结构,因此获得实时性推理及高准确性。LEDNet(Lightweight Encoder-Decoder Network)[11]和ERFNet[8]采用1D卷积的方式使得模型具有少的参数和计算量,同时膨胀卷积使得模型在较浅的情况下获取更大的视野。SQNet[7]采用SqueezeNet作为编码器,类瓶颈的结构使得模型在大的内核中进行特征提取,同时浅的结构使得网络具有小的浮点操作数,因此模型具有更快推理速度。ShuffleSeg(Shuffle Segmentation Network)[12]采用分组卷积策略以减少模型参数量和计算量,模型编码器几乎占据整个计算量及存储空间,简单的双线性上采样只占很小的计算量,因而具有很好的实时性。DABNet(Depth-wise Asymmetric Bottleneck Network)[13]采用深度可分离卷积减少计算量和参数量,简单的双线性上采样操作使得模型计算量更小,因此得以轻量化。为了实现实时性和准确分割,本文采用1D卷积及窄且浅的模型结构以获取到轻量级的模型。
1.2 获取大的接受野
大的接受野有助于模型获取深层的语义内容信息,提高模型的分类能力。PSPNet(Pyramid Scene Parsing Network)[14]通过附加金字塔池化在解码器的尾部以提取不同尺度的内容信息,再通过并合不同的池化输出以获取到不同程度的视野。DeepLab(“DeepLab” System)[15]系列模型采用带孔空间金字塔(Atrous Spatial Pyramid Pooling, ASPP)单元以多尺度地捕获内容和对象信息,通过这一策略模型获得更大的接受野。全卷积网络(Fully Convolutional Network, FCN)[16]、LinkNet(Link Network)[17]和DSNet(Dense Segmentation Network)[18]模型采用深的模型结构(32倍下采样)以获取大的接受野,通过跳转连接方式提高模型分割的准确性。GCN(Global Convolutional Network)[19]采用不成对的大卷积内核来增加特征映射的接受野以捕获长范围信息。DUC(Dense Upsampling Convolution)[20]利用带有网格状膨胀率的卷积在解码器阶段获取大的接受野,通过使用多个合成膨胀卷积(Hybrid Dilated Convolution, HDC)单元以获取到长范围的内容信息。Fast-SCNN(Fast Segmentation Convolution Neural Network)[21]采用全局特征摄取器来拓展接受野以捕获长范围内容信息,通过并合中层特征以利用浅层的空间信息。以上提到的算法中,大的卷积内核和多尺度池化使得模型的计算量和参数量过大不利于轻量化。为了有足够大的视野,本文模型采用分支膨胀卷积及大的下采样结构。
1.3 利用注意机制
PSANet(Point-wise Spatial Attention Network)[22]在编码器的尾部用卷积层作为信息收集器,用反卷积作为信息分布器。PSANet[22]在信息的收集和分布的过程噪声被过滤,因此这一过程可以视为是空间注意的一种形式。DFNet(Discriminative Feature Network)[23]采用通道专注块(Channel Attention Block, CAB)对浅层注入特征进行空间注意以移除噪声。CAB单元通过并合操作以获取到不同阶段的特征输入,然后通过权值向量选择特征以移除噪声。CCNet(Criss-Cross Network)[24]采用1×1卷积生成键值和查询值并通过转置生成交叉空间,最后采用乘积的形式实现交叉注意机制。文献[25]中通过计算相关矩阵以生成注意映射矩阵,然后利用注意映射矩阵实现稠密信息的聚集。文献[26]中将不同尺度的特征输入到注意模块中以获取到不同尺度的权值并以此生成注意权值指导模型训练。RefineNet(Refinement Network)[27]采用空间注意机制实现对浅层特征的噪声的抑制并提取深层特征的语义和浅层特征的空间信息。以上提到的算法虽然提高了准确率,但却是以高的计算量为代价。通过对现有专注机制优缺点的研究,本文模型采用简单的空间注意模块抑制浅层特征带入的噪声以提高提取空间的信息准确性。
2 本文提出的模型
本文提出的模型更加专注于实现准确性和实时性间的平衡,因而本文采用先进的算法追求模型的轻量化和高准确性。综合目前已取得的研究成果,本文将实时性策略、扩大感受野方法、跳转连接思想融入到模块中以便追求模型的实时性和准确性。
2.1 本文模型总体结构
SRNet总体结构如图1所示。SRNet采用一个初始单元完成对输入图像的特征提取,采用三块下采样单元完成模型的总体下采样操作。模型在第1块和第2块的卷积块中堆叠4个SR卷积单元,第3块的卷积块中堆叠7个SR卷积单元构成编码器。解码器采用第1和第2卷积块输出作为浅层特征输入,采用2块SA单元构成对浅层特征的提炼过程,最后4倍上采样恢复特征到原来的像素大小。解码器尾部的1×1的卷积层以压缩通道到类数。为了控制参数量及计算量,本文采用的上采样均为双线性上采样。
2.2 提高模型性能的策略
2.2.1实时性策略
语义分割网络的实时性对于功耗及算力有限制的应用来说非常重要。为了获取实时性,图2(a)采用瓶颈卷积单元压缩输入特征通道数,图2(b)采用1D卷积使得网络的参数量和计算量极大地减少,图2(c)为图(a)的一种变种,其中、分别表示压缩率和扩展率。受益于以上卷积单元的启发,本文设计的卷积单元如图2(d)所示,其类似于图2(c)的思想,所不同的是在单元的内部采用带膨胀率的1D非对称卷积及残差连接,其中、和SD分别表示膨胀率、通道数和空间弃权。本文设计的网络模型采用早期下采样操作、1D卷积及瓶颈模块的操作实现模型的实时性。

图2 卷积单元结构
早期下采样被广泛应用于先进模型算法中,实质是降低输入的像素大小以便在小的特征映射中进行推理。本文早期下采样在初始3×3、步值为2的卷积操作后直接使用采样单元实现,输出的特征映射变为输入的1/4倍,输出的特征通道变为32。为了压缩通道及提炼、选择特征,本文采用的SR单元类似标准瓶颈卷积单元。瓶颈1×1的卷积将输入到卷积单元的通道数减小为原来的1/2,这既减小输入通道的数量同时减小参数量和计算量。SR单元经过1×1卷积操作之后的卷积结构类似于分组卷积操作,即将输入的特征通道分为两支进行卷积,然后在输出时将通道并接为原来的通道数。未经过1×1瓶颈卷积的计算量可以公式化为式(1):

其中:表示的是输出的通道数,IP表示输入通道数,表示卷积核的大小,=×为输入的像素大小,(·)表示ELU(Exponential Linear Unit)和批归一化(Batch Normalization,BN)。
经过1×1卷积压缩通道后,每个卷积层的计算量可以公式化为式(2):
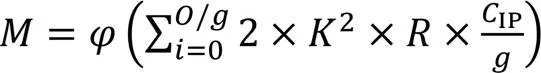
式(2)中所有的变量与式(1)一致。在式(2)中可以发现本文的结构对应分支的两个卷积层的总体计算量相较于原来减小了100×(1-2/g)%(表示通道压缩倍数)。对于参数方面,标准卷积的参数量可以公式化为式(3):

使用了类瓶颈策略之后的参数量可以公式化为式(4)(两分支构成的单层卷积):

其中表示瓶颈通道压缩倍数(对于本文采用的卷积单元可以理解为分组数),可以发现类瓶颈策略参数量(两分支)比原来的减少了约100×(1-2/g)%。
1D的卷积是将标准的卷积内核×变为两个非对称的1×和×1的卷积形式。1D卷积在减少参数量和计算量的同时卷积的特征摄取能力几乎与标准卷积相一致。通过式(1)和式(3)可以发现,1D计算量比标准卷积计算量减少了100×(1-2/)%,参数量比标准卷积减少了100×[(-2)×IP-1]/(×IP+1)%。因此,本文使用1D卷积及类瓶颈策略模型的卷积单元的每一层卷积(两分支)计算量比原来减少了100×[K-(2×)/g]%,参数量比标准卷积减少约100×(-4/g)%。
2.2.2扩大接受野的策略
模型有大的接受野可以抓取到更多的内容特征,有利于提高模型的语义分辨能力。目前先进的网络模型或采用大的下采样操作,或采用膨胀卷积以获取充足的接受野。本文设计的网络模型兼具两者的有利条件以获取充足的接受野。对于下采样单元,本文遵循ENet[5]的思想,即通过并3×3、=2的卷积和2×2、=2的最大池化完成下采样及特征通道拓展(第一块下采样采用加操作)。本文模型下采样率为16,即编码器的输出特征映射为输入的1/16。
对于膨胀卷积操作,本文两分支中一个为膨胀卷积。两个分支卷积路径有两个优势:1)不带膨胀率的分支有效地摄取特征以提高语义的分辨能力;2)带膨胀率的分支有大的接受野。卷积单元的并操作使得两个分支的通道得以拓展,获取到更加丰富的特征表达,同时非对称的卷积形式使得特征的摄取更加丰富以至于不容易过拟合。卷积单元1×1的瓶颈卷积起到特征压缩提炼的作用。因此,通过这一策略,模型有更强大的特征表达能力。在本文中,卷积块1和2采用的膨胀率均为2,第3个卷积块采用的膨胀率为=[2,2,2,2,4,8,16]。1D膨胀卷积的实现形式如图3(d)所示。

图3 扩大接受野的卷积形式(部分卷积形式未显示)
从图3中可以发现膨胀卷积和大的值都可以获得大的接受野。通过计算可以发现在相同的内核值下,第层=获得的视野为=1的(+)/K倍;带孔率为的第卷积层获取到比上一层大(+-1)/K倍的接受野。
2.2.3空间注意机制
模型大的下采样会丢失过多的空间细节,而这些空间细节很难在上采样的过程中恢复。存储池化索引和跳转连接很好地解决上采样过程中空间细节的恢复问题,但是存储池化索引消耗过多的内存,不适合实时性应用。因此,本文采用跳转连接策略恢复丢失的空间细节,即将浅层特征注入上采样模块中以利用其丰富的空间特征;但是,注入浅层特征到上采样不可避免地引入噪声使得预测结果变差。为了解决跳转连接带来的这一问题,本文采用通道级空间注意力SA模块完成空间特征的提炼及噪声的去除,公式化为式(5):

在式(5)中,(·)表示1×1Conv(Convolution) +ELU+BN,(·)表示上双线性上采样,E表示浅层特征映射,i表示前层特征映射。在这一过程中,(·)转换浅层特征为键值和查询值,经过Tanh函数(如式(6)所示)使得输入的浅层特征在模糊处得以平滑化以利于噪声的抑制。最后,SA模块中的深层特征与处理后的浅层特征叉乘及输出后再与深层特征简单的加操作,最后通过1×1的通道压缩完成整个专注过程,其单元如图1中虚线框所示。

3 实验结果与分析
3.1 实验设置
实验平台为TensorFlow2.0,在单一块的NVIDIA Titan RTX卡上训练,采用自适应矩估计(Adaptive Moment Estimation, AME)随机梯度下降优化算法加快收敛,模型初始学习率设置为1E-3,采用ploy学习率衰减策略,权值衰减及动量分别为4E-4和0.9。模型总共训练100个周期,其余的消融实验为微调模式。模型的模型评价指标采用MIoU,其计算公式如式(7):
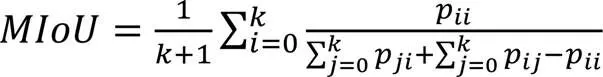
其中:P表示交叉区域的像素数量,P表示负正样本像素数量,P表示正负的样本数量,为总的类别数。
3.2 实验数据集
本实验采用Cityscapes数据集验证模型的有效性。Cityscapes数据集由2 975幅图片的训练集、500幅图片的评估集和1 525幅图片的测试集构成。此外,数据集还提供带粗糙标签数据集。在本文的实验中仅仅使用好的标签数据集。Cityscapes数据集的每幅图像的像素大小为1 024×2 048×3,本实验中考虑到收敛速度及实际应用意义,将输入裁剪为512×1 024×3。对于数据增强方面,实验采用左右、上下和随机[0.5,1.7]的裁剪。
3.3 实验与结果分析
本实验采用SegNet[4]、ENet[5]、SQNet[7]和ERFNet[8]作为比较基准方法,所有的算法模型均在像素为512×1 024×3的Cityscapes数据集上进行。为了公平比较,所有基准模型的实验参数设置都严格按照原论文的实验设置进行。为了尽可能详细地论述模型的先进性,本文分别在速度、模型大小、量化结果和预测准确性几个方面进行实验验证、分析及讨论。此外,为了对提出方法的有效性论述更加充分,消融实验也用于验证本文算法的有效性。
3.3.1网络模型实时性的分析


表1 所提算法与基准算法的实时性比较
3.3.2模型的大小及计算量分析
对于模型大小及计算量方面的比较,本文采用模型每秒浮点操作数(FLoating-point Operation Per Second, FLOPS)和参数量进行比较,比较结果如表2所示。从表2中可以发现,本文提出的模型仅有30 MB参数量,有8.8×109FLOPS。本文模型虽然比最小模型ENet[5]在参数量和计算量上分别多了18 MB和0.7 GFLOPS,但是在MIoU上比ENet[5]高出了10个百分点,是所有算法中最高的。本文提出的模型虽然在预测准确性上比ERFNet[8]只有微量的提升,但是在计算量及参数量上明显比ERFNet[8]少得多,这主要得益于SR卷积单元构成的编码器。本文模型比实时性最差的分割模型SegNet[4]在参数量和计算量上分别少了96.6%和98.6%。实验结果充分表明本文模型在准确性和模型的大小间取得了很好的平衡。

表2 所提算法与基准算法在轻量化方面的比较
3.3.3模型预测准确性分析
从表3中可以发现本文算法在人行道、墙壁、杆子、围栏、信号灯、植物、骑手、卡车、巴士、火车、摩托车和单车这些类上取得最高的预测准确率。这表明本文模型算法采用的非对称1D分支卷积形式摄取到了丰富的语义特征,提高了对稀有类的准确预测,如骑手、信号灯、摩托车和单车类。对卡车、巴士和火车的高准确率预测表明模型有大的接受野,可以获取到更多的语义信息,这主要得益于本文提出的双分支中带有膨胀率的分支起到扩展视野的作用。对人行道、墙壁和杆子的高准确性预测表明两分支的并操作及瓶颈策略可以对特征起到提炼、选择作用,提高了模型的分类能力同时有更好的实时性。在表3中的各类的预测精度上的表现表明了提出的SR特征提取单元能有效地提取特征,有更加充足的接受野和更加丰富的内容信息表达。本文模型对小物体的高准确性分割表明模型有足够的空间信息来恢复小物体目标。
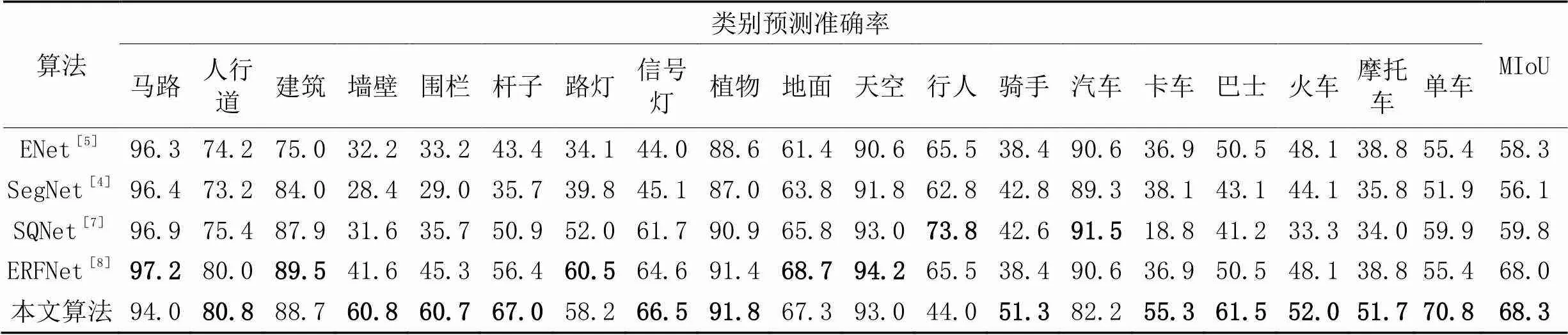
表3 所提算法与基准算法在Cityscape数据集上的比较 单位:%
3.3.4可视化分析
从图4中第1、2行可以发现本文模型对大尺寸物体预测准确性较高。在图4中除了图4(c)可以近似地分辨出第1、2行白色方框内的巴士类,其他的模型错误地将巴士分成其他类,而本文模型则可正确分辨出巴士类。在图4的第3、4行中白色标出的区域,本文模型清晰地分辨出人行道间的马路,对众多行人分割边缘更加清晰,这表明本文算法具有清晰的分辨能力。图4的实验结果表明本文算法具有更大的接受野、更强的语义分辨能力。
图5中第1、2行中用白色标出的左边窄小马路和微小竖立物体中,SQNet和ERFNet错误分类,ENet和SegNet分割平滑,而本文模型则正确分辨出相应的类别。本文方法可准确、清晰、尖锐地分割轮廓,表明模型具有更加丰富的语义摄取能力,更强的特征分辨能力。从图5中第3、4行中白色标出区域中杆子及路灯和广告牌的正确分割表明本文模型相较于其他算法模型有更加丰富的语义和特征表达。
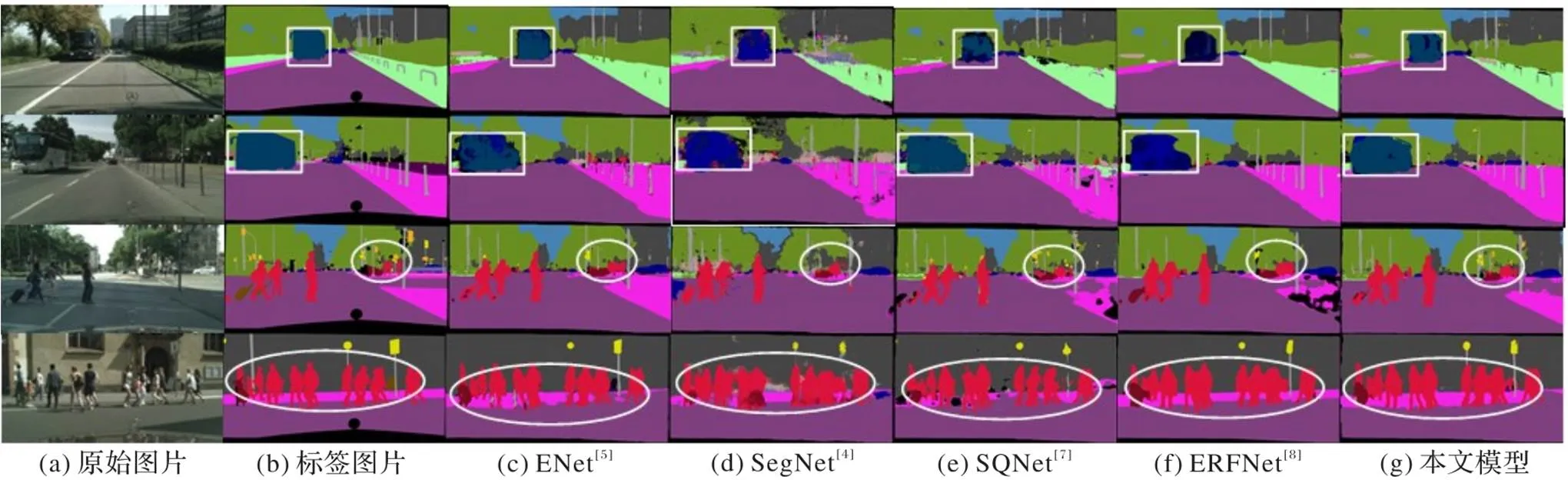
图4 大物体分割准确性的量化比较

图5 语义表达能力的量化比较
3.3.5消融实验
对于SA模块,本文采用直接去除SA模块中的Tanh函数及点级的乘函数的方法以保证实验验证的有效性,即除去SA模块中的去噪功能。对于分支膨胀卷积的消融实验,本文采用直接去除膨胀率的方法,即不采用任何的膨胀率的模型。本文对SA模块和分支膨胀卷积的消融实验结果如表4所示。表4实验结果表明:不使用SA模块使得模型的预测准确性降低了0.9个百分点,模型的速度微升0.3 FPS。这说明本文采用的SA模块中的Tanh函数能够使浅层特征变得更加平滑及其后的点级的乘能够提取相似的特征以抑制噪声引入到解码器,同时SA模块去噪部分所占用的计算资源比较少。表4分支膨胀卷积的消融实验结果表明,无分支膨胀卷积使得模型的准确性下降了1.2个百分点,说明本文采用的分支膨胀卷积获得了大的接受野,提高了模型的分辨能力。另外,无分支膨胀卷积使得模型的推理速度高了0.7 FPS,这说明膨胀卷积使模型的推理速度降低。

表4 模型消融实验的结果
为了能够使得论述更加充分,本文对消融实验结果进行量化比较。图6为AS消融实验的量化结果。图6(c)中第1行的道路被错误地分为了人和背景类,这说明无SA模块使得模型的噪声较大;同样地,图6(c)和(d)的第2行和第3行中的车辆被错误地标为其他的类,表明没有抑制低水平特征会使得预测结果带有噪声。

图6 无SA模块的量化结果
图7为分支膨胀卷积量化结果。图7的(b)、(c)和(d)的第1行中的大巴车的分割结果可以发现,不使用膨胀率使得模型不能完全地将大巴车分辨出来;又如图7(c)中的第2行中无分支膨胀卷积的模块则将草地错误地分类为了大地类,而第3行中则对树干及小车的预测轮廓不够清晰。从图7的量化比较结果可以发现,使用分支膨胀卷积使得模型的分辨能力得以提高,模型有大的接受野。

图7 无膨胀率的量化结果
4 结语
随着自动驾驶、虚拟现实等依赖于语义分割方法的应用在日常生活中扮演越来越重要的角色,对实时语义分割的需求也越来越迫切。本文在SR卷积单元中采用先进的1D分离卷积及瓶颈提炼策略使得模型的参数量仅为30 MB,计算量仅为8.8×109FLOPS。SR卷积单元两分支的策略能够摄取到丰富的语义信息,同时带膨胀率的分支又可获取到较大的接受野,最后通过使用1×1的卷积完成正确语义信息的选择提取。SA模块的使用提高了模型对浅层特征空间信息的利用,有效地避免浅层特征引入噪声的缺陷,提升了模型预测的准确性,使得预测边缘更加清晰。此外,消融实验结果证实了SA模块和SR卷积单元的有效性。在512×1 024×3的Cityscapes数据集上以68.3% MIoU实现12.6 FPS的推理速度,这表明本模型算法能够在实时性和准确性间取得平衡。
本文模型因实验条件的限制,模型没有在大规模图像数据集ImageNet上进行预训练。在模型的实验中未充分考虑到数据集Cityscapes中的均衡性,因而模型未使用类权值进行训练。本文模型SR单元中可以考虑使用纵向可分离卷积进一步地提高模型的性能。因此,未来工作可以围绕上述几个方面来增强模型的性能。
[1] 董阳,潘海为,崔倩娜,等. 面向多模态磁共振脑瘤图像的小样本分割方法[J]. 计算机应用, 2021, 41(4): 1049-1054.(DONG Y, PAN H W, CUI Q N, et al. Few-shot segmentation method for multi-modal magnetic resonance images of brain tumor[J]. Journal of Computer Applications, 2021, 41(4): 1049-1054.)
[2] 佘玉龙,张晓龙,程若勤,等. 基于边缘关注模型的语义分割方法[J]. 计算机应用. 2021, 41(2): 343-349.(SHE Y L, ZHANG X L, CHENG R Q, et al. Semantic segmentation method based on edge attention model[J]. Journal of Computer Applications, 2021, 41(2): 343-349.)
[3] 高海军,曾祥银,潘大志,等. 基于U-Net改进模型的直肠肿瘤分割方法[J]. 计算机应用, 2020, 40(8): 2392-2397.(GAO H Q, ZENG X Y, PAN D Z, et al. Rectal tumor segmentation method based on improved U-Net model[J]. Journal of Computer Applications, 2020, 40(8): 2392-2397.)
[4] BADRINARAYANAN V, KENDALL A, CIPOLLA R. SegNet: a deep convolutional encoder-decoder architecture for image segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(12): 2481-2495.
[5] PASZKE A, CHAURASIA A, KIM S, et al. ENet: a deep neural network architecture for real-time semantic segmentation[EB/OL]. (2016-06-07) [2021-04-10].https://arxiv.org/pdf/1606.02147.pdf.
[6] RONNEBERGER O, FISCHER P, BROX T. U-Net: convolutional networks for biomedical[C]// Proceedings of the 2015 International Conference on Medical Image Computing and Computer-Assisted Intervention, LNCS 9351. Cham: Springer, 2015: 234-241.
[7] TREML M, ARJONA-MEDINA J, UNTERTHINER T, et al. Speeding up semantic segmentation for autonomous driving[EB/OL]. [2021-04-17].https://openreview.net/pdf?id=S1uHiFyyg.
[8] ROMERA E, ÁLVAREZ J M, BERGASA L M, et al. ERFNet efficient residual factorized ConvNet for real-time semantic segmentation[J]. IEEE Transactions on Intelligent Transportation Systems, 2017, 19(1): 263-272.
[9] YU C Q, WANG J B, PENG C, et al. BiSeNet: bilateral segmentation network for real-time semantic segmentation[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11217. Cham: Springer, 2018: 334-349.
[10] ZHAO H S, QI X J, SHEN X Y, et al. ICNet for real-time semantic segmentation on high-resolution images[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11207. Cham: Springer, 2018: 418-434.
[11] WANG Y, ZHOU Q, LIU J, et al. LEDNet: a lightweight encoder-decoder network for real-time semantic segmentation[C]// Proceedings of the 2019 IEEE International Conference on Image Processing. Piscataway: IEEE, 2019: 1860-1864.
[12] GAMAL M, SIAM M, ABDEL-RAZEK M. ShuffleSeg: real-time semantic segmentation network[EB/OL]. (2018-03-15) [2021-04-11].https://arxiv.org/pdf/1803.03816.pdf.
[13] LI G, KIM J. DABNet: depth-wise asymmetric bottleneck for real-time semantic segmentation[C]// Proceedings of the 2019 British Machine Vision Conference. Durham: BMVA Press, 2019: No.259.
[14] ZHAO H S, SHI J Q, QI X J, et al. Pyramid scene parsing network[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 6230-6239.
[15] CHEN L C, PAPANDREOU G, KOKKINOS I, et al. DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 4(40): 834-848.
[16] LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 3431-3440.
[17] CHAURASIA A, CULURCIELLO E. LinkNet: exploiting encoder representations for efficient semantic segmentation[C]// Proceedings of the 2017 IEEE Visual Communications and Image Processing. Piscataway: IEEE, 2017: 1-4.
[18] CHEN P R, HANG H M, CHAN S W, et al. DSNet: an efficient CNN for road scene segmentation[C]// Proceedings of the 2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference. Piscataway: IEEE, 2019: 424-432.
[19] PENG C, ZHANG X Y, YU G, et al. Large kernel matters — improve semantic segmentation by global convolutional network[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 1743-1751.
[20] WANG P Q, CHEN P F, YUAN Y, et al. Understanding convolution for semantic segmentation[C]// Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2018: 1451-1460.
[21] POUDEL R P K, LIWICKI S, CIPOLLA R. Fast-SCNN: fast semantic segmentation network[C]// Proceedings of the 2019 British Machine Vision Conference. Durham: BMVA Press, 2019: No.289.
[22] ZHAO H Y, ZHANG Y, LIU S, et al. PSANet: point-wise spatial attention network for scene parsing[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11213. Cham: Springer, 2018: 270-286.
[23] YU C Q, WANG J B, PENG C, et al. Learning a discriminative feature network for semantic segmentation[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 1857-1866.
[24] HUANG Z L, WANG X G, HUANG L C, et al. CCNet: criss-cross attention for semantic segmentation[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 603-612.
[25] WANG X L, GIRSHICK R, GUPTA A, et al. Non-local neural networks[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7794-7803.
[26] CHEN L C, YANG Y, WANG J, et al. Attention to scale: scale-aware semantic image segmentation[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 3640-3649.
[27] LIN G S, MILAN A, SHEN C H, et al. RefineNet: multi-path refinement networks for high-resolution semantic segmentation[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 5168-5177.
WANG Juan, born in 1983, Ph. D., associate professor. Her research interests include artificial intelligence, computer vision, deep learning.
YUAN Xuliang, born in 1992, M. S. candidate. His research interests include artificial intelligence, computer vision, image segmentation.
WU Minghu, born in 1975, Ph. D., professor. His research interests include artificial intelligence, computer vision, deep learning.
GUO Liquan, born in 1997, M. S. candidate. His research interests include artificial intelligence, machine vision.
LIU Zishan, born in 1997, M. S. candidate. Her research interests include artificial intelligence, machine vision.
Real-time semantic segmentation method based on squeezing and refining network
WANG Juan1,2,3, YUAN Xuliang1, WU Minghu1,2,3*, GUO Liquan1, LIU Zishan1
(1,,430068,;2⁃(),430068,;3’,430068,)
Aiming at the problem that the current semantic segmentation algorithms are difficult to reach the balance between real-time reasoning and high-precision segmentation, a Squeezing and Refining Network (SRNet) was proposed to improve real-time performance of reasoning and accuracy of segmentation. Firstly, One-Dimensional (1D) dilated convolution and bottleneck-like structure unit were introduced into Squeezing and Refining (SR) unit, which greatly reduced the amount of calculation and the number of parameters of model. Secondly, the multi-scale Spatial Attention (SA) confusing module was introduced to make use of the spatial information of shallow layer features efficiently. Finally, the encoder was formed through stacking SR units, and two SA units were used to form the decoder. Simulation shows that SRNet obtains 68.3% Mean Intersection over Union (MIoU) on Cityscapes dataset with only 30 MB parameters and 8.8×109FLoating-point Operation Per Second (FLOPS). Besides, the model reaches a forward reasoning speed of 12.6 Frames Per Second (FPS) with input pixel size of 512×1 024×3 on a single NVIDIA Titan RTX card. Experimental results imply that the designed lightweight model SRNet reaches a good balance between accurate segmentation and real-time reasoning, and is suitable for scenarios with limited computing power and power consumption.
semantic segmentation; lightweight network; real-time reasoning; Spatial Attention (SA) confusing module; one-dimensional dilated convolution
This work is partially supported by National Natural Science Foundation of China (62006073).
TP391.4
A
1001-9081(2022)07-1993-08
10.11772/j.issn.1001-9081.2021050812
2021⁃05⁃18;
2021⁃09⁃22;
2021⁃09⁃24。
国家自然科学基金资助项目(62006073)。
王娟(1983—),女,湖北武汉人,副教授,博士,主要研究方向:人工智能、计算机视觉、深度学习; 袁旭亮(1992—),男,广西河池人,硕士研究生,主要研究方向:人工智能、机器视觉、图像分割; 武明虎(1975—),男,湖北恩施人,教授,博士,主要研究方向:人工智能、计算机视觉、深度学习; 郭力权(1997—),男,湖北黄冈人,硕士研究生,主要研究方向:人工智能、机器视觉; 刘子杉(1997—),女,湖北武汉人,硕士研究生,主要研究方向:人工智能、机器视觉。
猜你喜欢
水土保持学报(2022年5期)2022-10-10
农业工程学报(2022年12期)2022-09-09
计算机仿真(2022年7期)2022-08-22
计算技术与自动化(2022年1期)2022-04-15
建材发展导向(2021年24期)2021-02-12
上海师范大学学报·自然科学版(2019年5期)2019-12-13
电子技术与软件工程(2016年22期)2016-12-26
电脑知识与技术(2016年24期)2016-11-14
吉林农业(2016年4期)2016-05-14
物联网技术(2015年10期)2015-11-10
