
基于无标签半监督学习的商品识别方法
2022-08-10 08:12刘文豪姜胜明
计算机应用与软件 2022年7期
刘文豪 姜胜明
(上海海事大学信息工程学院 上海 201306)
0 引 言
新零售[1]是最近几年的一个热门话题,一般采用条形码来进行商品识别,然后通过人工结算,在一定程度上提高了结算效率。然而随着电子射频技术的发展,RFID技术开始在商品识别中应用[2],该技术是在商品上粘贴一个电子标签,然后通过RFID读取器来读取商品的详细信息,最后在后台自动进行结算,由于零售行业对成本比较敏感,现实生活中,该技术只能在部分场景下应用。
自深度学习技术在2012年的imageNet[3]图像识别大赛上取得了突破性的进展之后,深度学习不管是在理论研究,还是在实践应用中都取得了长足的发展。随着新零售概念日益流行,文献[4-5]提出了利用深度学习技术来解决商品识别的问题,不但可以降低成本,还能做到全自动化结算,为用户带来了全新的购物体验[6]。
现有基于深度学习的目标检测[7]技术主要是识别图片中物体的种类以及确定物体位置信息,常见的有one-stage[8-11]和two-stage[12,13]两大类检测算法。但这两类算法本身需要大量训练样本,只有训练样本数量足够多、多样性足够广,才能使模型准确率足够高。然而在商品识别中,图像数据往往是复杂多变的,例如数据采集困难、标注需要大量的人工、无标签数据大量存在等问题,都在一定程度上影响了目标检测技术在商品识别中的应用。Tonioni等[5,14]提出的基于深度学习的货架商品识别技术是目前最优秀的解决方案,利用深度学习技术识别物体,使用全局描述符搜索匹配物体,但是没有考虑到实际情况下数据集的问题。通常货架商品数据的获取是通过部署在货架上某个固定位置的摄像头,使用网络将数据传输到后台服务器,该途径是一种比较便捷常规的方式,会产生海量的样本数据。然而只是简单的图像数据并不能直接被神经网络利用,需要额外的人工标注,来确定图像中商品的种类和位置信息,这是一种强度高、劳动密集的工作,往往需要多人耗时数周乃至数月的时间来完成。现有的深度学习商品识别方案中就是使用已经标注好的数据来训练模型,最后将模型部署进行预测,严重依赖已标注好的数据。
此外,在实际应用中,也要考虑到被识别物品本身的变化,例如在该套系统下添加一个新的产品、更换产品的包装等一系列变化。因此,要让已有的模型快速地利用无标签的海量数据来适应各种变化,降低训练的成本,构建一套适用的商品识别数据集[15]也成为了要解决的问题。
针对商品识别中的问题,即有标签数据集获取成本较高,无标签数据大量存在的问题。在特征分布上,无论是有标签数据还是无标签数据都具有相同的特征分布,为充分利用无标签数据来提高模型的特征学习能力,本文提出了一种半监督学习[16]框架,具体是:
1) 使用少量的有标签数据分别训练SSD[8]和YOLOv3[9]两个目标检测模型,在达到稳定之后,通过self-training的方式来利用无标签数据;
2) 在self-training阶段中,对目标检测网络损失函数添加基于熵的正则化损失项,使预测的结果更加准确。
3) 解决self-training阶段中由于错误伪标签数据重复利用导致模型精度变糟糕问题。采用co-training训练方法,将无标签数据分别在两个不同的模型上进行预测,产生一些伪标签数据,再将伪标签结果分别在另一个模型上训练,不断迭代,使其能够从数据中学习更多的特征信息。
1 数据集
将基于RFID的无人售货柜进行改装,在每层加装两个摄像头,我们选用了市面上销售量比较大的20种饮料,模拟实际使用场景,20种类别的饮料被放置在同一售货柜的不同层,这里选用其中的一层进行说明,其他层具有相同的场景设置。
对于每一层,经过测试发现,在该硬件条件下能够放置8列饮料,这一特点受到摄像头的镜头、层高、箱体宽度等因素影响。考虑到实际应用过程,每行饮料的类别是完全相同的,其中每个摄像头能够看到4种类型的饮料,每个摄像头看到的排列情况会因为实际情况不同会有所差别,但仍然可以看成是在同一个摄像头下拍摄的图片。图1展示了同一时刻左右两边两个摄像头看到的商品。

(a) 左侧摄像头图像(b) 右侧摄像头图像图1 左右两侧同一时刻拍摄的画面
针对20种饮料,每个摄像头能够看到的是4种类型,根据数学中排列组合理论,我们可以得出全排列的结果是116 280,即该数据集的所有解为116 280种结果。为了在较少标注工作量以及满足实际应用场景,并没有列举所有的结果,而是采集了20种饮料抽取4种组合的方式,即4 845种组合方式,作为基础数据集,并进行了标注,用于基础模型的训练。为了模拟实际应用中产生的其他的组合方式,我们随机采集了无重复的10 000多幅无标签数据,作为无标签数据集,图2展示了有标签数据和无标签数据不同。

(a) 使用labelImg标注的有标签数据
此外为了验证模型的训练效果,从4 845种组合中选取480种不同的组合方式,每种组合按照与训练集不同的排列方式进行采集,最后进行标注,形成标准训练集,表1展示了构建的数据集详细信息。
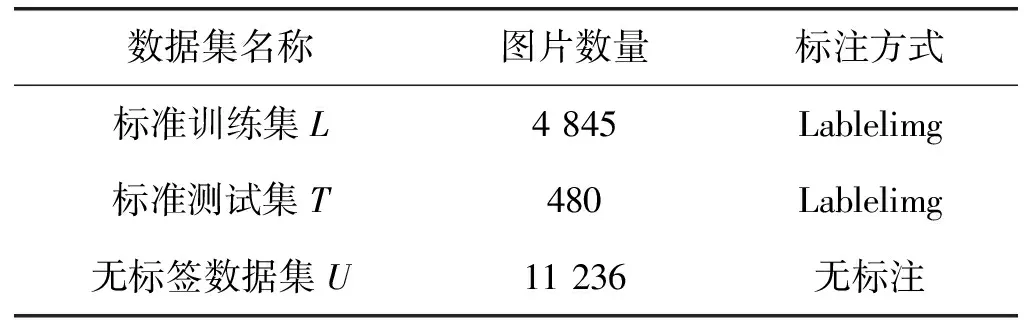
表1 数据集信息
2 SSD和YOLOv3模型及初始化
SSD(Single Shot MultiBox Detector)模型[8]和YOLOv3[9]模型分别是刘伟在2016年提出和Joseph Redmon在2018年提出的one-stage深度学习目标检测模型,该类模型将目标检测中分类和位置回归整合到一个网络中,使模型的训练更加简单,相比于two-stage目标检测模型来说,在运行效率上快了许多,十分适合于商品检测对场景的要求。SSD模型和YOLOv3模型使用了卷积神经网络中的多层特征,每层特征代表着不同的语义信息,总体上提高了模型的表达能力。
在商品识别中,除了对准确率等技术指标有要求之外,也应该充分考虑实际的使用场景中,对实时性的要求,SSD和YOLOv3相对于R-CNN系列模型FPS普遍要高。这两个模型采用完全不同特征提取网络,SSD使用VGG-16,如表2所示,YOLOv3使用darknet-53,如表3所示。两个神经网络通过特征提取之后,将位置预测和类别预测整合到一个网络中,从而达到one-stage目标检测的目的。从深度学习抽象层理解的话,两个模型分别代表着不同的视角来学习数据集中存在的特征,避免不同的特征在后期的训练中出现无效的重复学习。

表2 SSD提取网络特征参数

表3 YOLOv3特征提取网络模型参数

续表3
SSD主要是使用VGG作为基础的网络,将全连接层(FC6和FC7)替换为卷积层,并在后面加上额外的卷积层,用于多层特征的预测。
dark-net网络主要是由一系列的1×1和3×3的卷积层组成,每个卷积层后都会跟一个BN层和一个LeakyReLU层,一共有53层卷积(包括全连接层),所以称为darknet-53。
分别利用VOC数据集训练好的权重参数,初始化SSD和YOLOv3模型,这种pre-training训练方式在目前的深度学习参数初始化中方法十分常见。将同样的训练集分别转换为SSD和YOLOv3可以识别的格式,按照作者原文中的训练方法对模型继续训练,直到训练结束,这种被称作有标签的全监督训练。
3 半监督学习框架
3.1 自训练
模型的初始化训练是一个利用有标签数据的全监督学习过程。为了提高大量无标签数据的利用率,从中提取到有用的特征信息,可以采用自训练的方式。先使用训练好的模型在无标签数据上进行预测,选择置信度比较高的伪标签数据加入到训练数据集中,直到无标签数据集中的数据不再变化为止,参考算法1。
算法1Self-training算法
Input:训练集U和L、学习率η
repeat:

3:根据预测出来的结果,将(xu,yu)加入到L中,并将xu从U中移除。

自训练的方式虽然能够在一定程度上利用无标签数据,但伪标签的选择一直是自训练的核心,本文中采用基于熵正则化的方法来选择伪标签数据。假设模型预测的结果呈现某种分布,如果在结果中比较集中于某个类别,那么就有大概率认为是属于这个类别,通常用熵表示分布的集中程度,分布越集中,则熵越小。用yu代表模型预测中分类结果,则:

(1)
式中:等式右边第一项是针对有标签的损失函数,和全监督训练时使用的损失函数一样,第二项是针对无标签预测的类别熵,λ为协调有标签数据和无标签数据对损失函数的影响系数,最后通过最小化损失函数求解模型的参数。
3.2 协同交叉训练
SSD和YOLOv3模型产生了不同的标签数据,这些数据结果从一定意义上来说可信的,但即使可信度再高,依然有一部分是错误数据。为了避免模型重复使用错误的数据,致使模型朝着糟糕的方向训练,引入了一种类似于对抗机制。如图3所示,使用自训练之后的模型在无标签数据集U下进行预测,SSD和YOLOv3模型分别获得伪标签数据集PLa和PLb,将标准训练集分别与PLa和PLb合并,形成新的有标签数据集NLa和NLb,最后使用SSD模型在NLb下训练,使用YOLOv3模型在NLa数据集下训练,通过交叉协同训练直到满足迭代停止条件。

图3 协同交叉训练流程
4 实 验
4.1 模型的训练
为了快速验证半监督学习框架的有效性,在深度学习平台Pytorch框架下,使用Python代码编写SSD算法和YOLOv3算法,实验软件环境为ubuntu 16.04系统,硬件平台使用的是一块GTX 2080Ti 11G显卡,intel E5处理器,模型的训练和测试都是在显卡GPU上进行,CPU处理器主要完成简单的数据处理工作。
4.1.1有标签数据的训练
为了使模型的初始训练能够获得更好的效果,两个模型在训练之前都采用了图像增强技术,如随机裁剪、图像归一化、色彩扭曲、随机水平翻转等。其中SSD模型的初始化参数使用基于VOC数据集权重结果,图片的输入大小为300×300,采用SGD权重更新策略,学习率为0.001,在整个数据集上迭代了200个epoch之后停止训练,YOLOv3模型的初始化采用了官方[9]权重结果,图片的输入大小为416×416,同样经过了200个epoch的训练,采用了adam权重更新方法,学习率为0.001,在数据集迭代训练200次。
4.1.2无标签数据的训练
无标签数据的训练主要分为两个部分,自训练和交叉协同训练。在自训练中,我们采用4.1.1节训练好的模型在无标签上进行预测,将结果和标准训练集合并成新的训练数据集,之后在新数据集下训练50个epoch,学习率调整为更小的0.000 5,整个过程经过多轮迭代,完成SSD模型和YOLOv3模型训练。
由于自训练固有的缺陷,接下来采用交叉协同训练,其中主要是学习率的设置与前面有所不同,因为在训练的后期,主要是模型的微调,所以我们进一步降低学习率,将两个模型的学习率都调整为0.000 1,在达到10次交叉训练之后终止训练,每次交叉训练,模型迭代15个epoch,最终经过1天左右的时间完成交叉协同训练。
4.2 实验结果及分析
采用原始的SSD模型和YOLOv3算法模型,对有标签的数据集进行了训练,随着迭代次数的增加,模型的损失函数不断下降,直到趋于稳定;对于无标签数据的训练分为自训练阶段和协同交叉训练阶段,加入自训练和协同交叉训练之后,模型的损失值进一步下降,图4展示了在数据集下不同阶段训练的结果。

图4 不同阶段训练损失值曲线
为了防止训练的模型存在过拟合的问题,需要在测试集上进行评估,首先需要评估的是模型在有标签数据集下的预测效果,我们采用在目标检测中常用的mAP(mean average precision)指标来确定网络模型的分类和定位性能,半监督学习的检测也采取相同的评价指标,确保半监督学习前后评估方法的一致性,更加科学合理地评估半监督学习算法。
和传统的分类任务类似,首先需要计算precision和recall,这些指标依赖于真正例(TP)、假正例(FP)、真负例(TN)和假负例(FN)。IOU(交并比)的设置决定检测结果是正确还是错误,最常用的阈值是0.5。使用P代表precision,使用R代表recall,则:
式中:TP是根据IOU的值检测正确的数量;FP为检测错误的数量;FN表示漏检的数量。


表4 有标签数据集下模型AP值结果
在完成有标签的学习之后,采用self-training和co-training对伪标签数据进行学习,这些伪标签数据的学习效果直接影响着最终模型的性能。最后的验证部分,以是否使用伪标签为基准,分别对比使用伪标签前后模型的性能是否有所提高。伪标签性能验证时,每经过10个epoch,在验证集T上进行一轮验证实验,图5和图6分别展示了SSD和YOLOv3模型使用伪标签前后的实验结果。实验发现,无论是SSD模型还是YOLOv3模型在使用伪标签数据之后,相比没有单纯使用有标签数据,模型的mAP值都有所提高。

图5 YOLOv3使用伪标签前后性能结果

图6 SSD使用伪标签前后性能结果
在半监督学习框架下完成自训练和交叉协同训练,并在每个训练阶段的结束后,在测试集上进行一次性能测试,结果如表5所示。

表5 半监督框架实验结果对比
实验结果表明,在经过无标签数据集的训练后,SSD模型的精度从90.6%提高到了97.2%,YOLOv3模型精度从91.7%提高到了96.9%,半监督学习框架相比全监督学习方法有明显提高,说明了半监督学习框架的有效性,在模型的预测中有很好的效果,能够准确地预测图片中商品的位置和类别,如图7所示。在实验环境中达到了60帧/s的实时处理效果,完全能够满足实际需要。

图7 半监督学习框架预测结果展示
5 结 语
基于半监督框架的商品识别算法在一定程度上解决了有标签数据不足、无标签数据无法利用等实际问题,为基于图像的商品识别应用提供了一种可行的解决思路。利用有标签数据进行预训练,再用无标签数据进行交叉训练,最终提高了模型的准确性,但依然存在一些问题,例如如何减少模型训练时长等,这些问题也将成为下一阶段的研究重点。未来无人售货这种新型的零售方式也将给人们带来全新的购物体验。
猜你喜欢
中国交通信息化(2022年9期)2022-10-28
中学生数理化·高二版(2022年4期)2022-05-09
中学生数理化·高二版(2022年4期)2022-05-09
汽车工程师(2021年12期)2022-01-18
海峡姐妹(2018年3期)2018-05-09
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
少儿科学周刊·儿童版(2015年2期)2015-07-07
金点子生意(2014年4期)2014-04-10
网络与信息(2009年6期)2009-07-31
