
基于深度加权特征学习的网络安全态势评估
2022-08-16 09:34杨宏宇张梓锌
信息安全学报 2022年4期
杨宏宇 ,张梓锌 ,张 良
1 中国民航大学安全科学与工程学院 天津 中国 300300
2 中国民航大学计算机科学与技术学院 天津 中国 300300
3 亚利桑那大学信息学院 图森 美国 AZ 85721
1 引言
随着通信技术和云计算技术的发展,现今几乎所有的行业都开始应用计算机网络进行办公[1]。与此同时,恶意攻击或破坏造成的网络安全事件也越来越普遍,网络和信息系统面临着众多网络攻击的威胁[2]。因此,全面掌握网络的整体安全状态是一个亟待解决的热点问题。网络安全态势评估(network security situation assessment,NSSA)可以根据相关安全事件构建合适的模型,进而评估网络系统整体所遭受的威胁程度,帮助安全管理人员掌握当前网络状况[3-4]。
目前,国内外相关研究已取得一定成果[5]。Lu等[6]将网络安全态势分为主机安全态势和网络攻击态势两部分,设计权重和计算规则以计算网络安全态势。Agrawal 等[7]基于模糊分析网络过程评估标准的权重,并通过模糊对称技术评估软件的安全性。此外,还有层次分析法(analytic hierarchy process,AHP)[8-9]、集对分析法[10]、模糊数学[11]等方法,但此类运用数学模型的方法受主观因素影响较大,没有客观的标准。Alali 等[12]提出利用模糊逻辑推理系统改进网络安全风险评估模型,并综合分析了脆弱性、威胁、可能性和影响等四个方面从而得出风险评估结果。杨宏宇等[13]基于自修正系数修匀法,通过熵关联度、自适应解和时变加权马尔可夫链改进网络安全态势的预测结果。此外,还有运用概率和知识推理的方法如贝叶斯网络[14-15]、模糊推理[16]、D-S 证据理论[17]等,这些方法依赖于专家知识库和大量的规则推理,在海量数据的网络环境下存在模型构建困难、操作复杂等问题。杨宏宇等[18]基于无监督学习,提出一种通过解析多源网络流量评估网络威胁的态势评估方法。该方法具有较强的网络威胁特征识别能力,对网络威胁态势评估有效性的提升提供了可行的思路。Hong 等[19]则将灰色关联分析理论和支持向量机(support vector machine,SVM)算法用于网络安全态势预测,实验结果表明该模型具有更高的网络风险预测精度。但此类运用模式分类的方法在实时环境中提取特征困难,建模时间长,不易于理解。
为了应对日益复杂的网络威胁和攻击,网络安全技术不断地被更新和发展,研究人员开始尝试利用深度学习的方法研究网络安全问题。Lin 等[20]基于门控循环单元(gate recurrent unit,GRU)、双向门控循环单元(bi-directional gate recurrent unit,BiGRU)等多种神经网络模型对UNSW-NB15 数据集进行检测,结果表明,与其他模型相比,BiGRU 的准确率最高。文献[21]将改进的LSTM 应用于KDD99 数据集,实验证明该方法可有效地理解和评估网络安全态势。文献[22]设计了一种基于对抗学习的态势评估模型AEDNN,解决了传统方法面对大量数据时效率低的问题。Chakravarthi 等[23]提出一种基于深度自动编码器(auto-encoder,AE)提取特征的入侵检测方法,得到了表征能力更强的特征,但使用该方法训练网络模型时存在梯度消失的问题。Moradi 等[24]将基于堆叠式自动编码器提取特征的特征学习和孤立森林相结合,获得了良好的检测结果,但文中仅检测有无攻击发生,无法满足攻击类型进行细分与检测需要。文献[25]将MapReduce 和SVM 相结合并应用于网络安全态势预测,解决了SVM 训练时间长的缺点,但未对网络态势进行全面的评估,无法反映网络的整体态势情况。Shone 等[26]将非对称深度自编码器的无监督特征学习应用于入侵检测并取得了较好的检测结果,但该方法在少数攻击类别上的检测率为0,存在着攻击类型样本数失衡导致的弱检测问题。
近年来,一些研究人员尝试用注意力机制对深度学习网络进行改进,以提高安全检测的性能。Liu等[27]采用基于注意力机制的深度神经网络进行web攻击的实时检测,在真实的网络流量上证明了该方法的可行性。Arnav 等[28]将一种基于注意力机制的自动编码器应用于异常检测,实验证明该方法相对于其他自动编码器变体具有更高的检测性能。Yang等[29]用注意力机制改进LSTM 并将其用于威胁检测,取得了较好的检测效果。
针对目前网络安全态势评估方法在获取先验知识、提取特征、构建模型、实时性等方面存在的不足,为了有效、全面地评估网络安全态势,本文提出一种基于深度加权特征学习的网络安全态势评估方法。通过并行稀疏自动编码器(parallel sparse auto-encoder,PSAE)高效、准确地提取不同攻击类型的特征并与数据原始特征融合,采用注意力机制改进BiGRU 网络(attention-based BiGRU,ATBiGRU),再使用改进后的网络模型(parallel sparse auto-encoder-attention-based BiGRU,PSAE-ATBiGRU)进行网络威胁检测,根据测试结果计算网络安全态势量化值。
2 基于PSAE 的特征提取与融合
2.1 稀疏自动编码器
自动编码器(AE)是一种无监督的特征提取算法,其结构如图1所示。AE结合了编码器以及解码器,并使用反向传播将它们联系在一起。编码器将输入转换为低维抽象来提取原始特征并学习数据表示,解码器接收低维表示并重建原始特征。
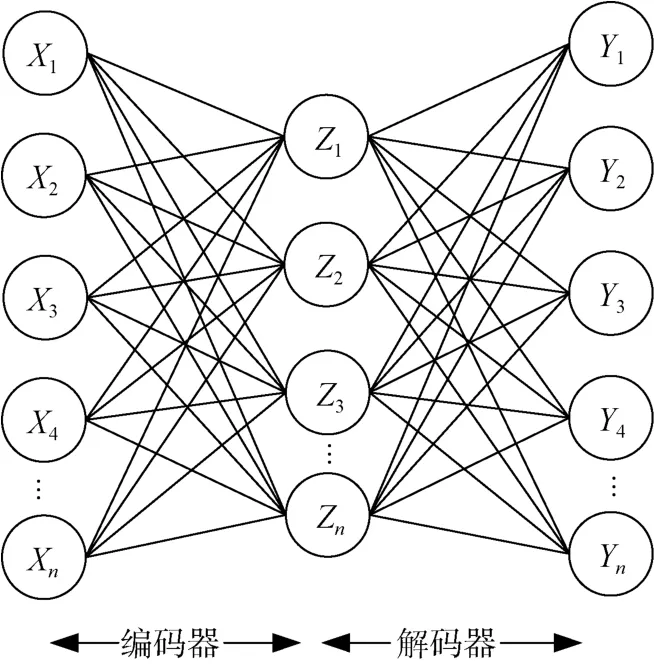
图1 自动编码器网络结构图Figure 1 AE’s network structure
稀疏自动编码器(sparse auto-encoder,SAE)[30]是在AE 基础上的改进。SAE 为了避免简单地从输出到输入的映射,在隐藏层上添加了稀疏性约束,增加模型的泛化能力,获得更好的特征描述。SAE 通过反向传播获得权重矩阵,选择Sigmoid函数g(z)=1/(1+e–z)用于激活神经网络层中的神经元。神经元的稀疏性由神经元的输出决定。如果神经元的输出接近1,认为它是活动的。如果神经元的输出接近0 时,认为它是不活动的。在使用反向传播的SAE 中,损失函数为

其中,m指输入神经元数,K指隐藏神经元数,xi指输入数据,yi指输出数据。在上式中,β控制神经元的稀疏程度,ρ表示网络中神经元的期望激活水平,表示第j个神经元的平均激活水平。此外,KL散度的计算公式为
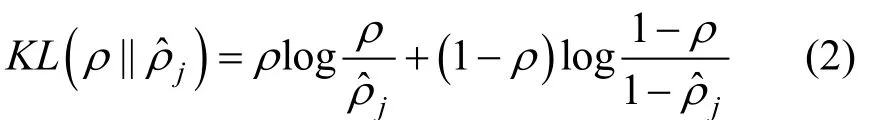
除了稀疏约束之外,通常还会通过L2 正则化避免模型过拟合的问题,因此最终的损失函数为
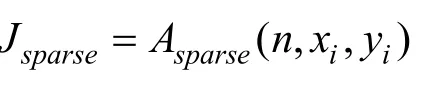
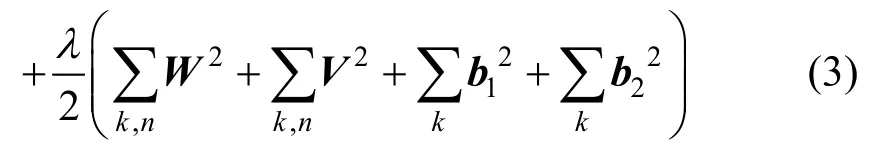
其中,λ指正则化参数,n指层数,k指当前层数,W和V指权重矩阵,b1和b2指偏置项。
2.2 PSAE 特征提取器的设计
特征学习是一种仅对属性子集的数据行为进行建模的技术,它可有效显示检测性能与数据模型质量之间的相关性。通过使用新特征对网络进行训练,可以提高网络分类效率和分类准确性。因此可通过特征提取与融合来增强原始特征的表征能力,从而提高分类的准确性。
此外,NSL-KDD 数据集[31]包含多种攻击类型,且这些类型的信息分布各不相同,通过单个SAE 进行特征提取时间长且无法很好的拟合不同攻击的分布。因此可用多个特征提取器分别学习每种攻击的分布规律,更好的表达不同攻击类型之间的信息差异。
本文设计的基于PSAE 的特征提取器结构如图2所示。首先,将数据预处理之后的数据集按照不同的攻击类型输入SAE 特征提取器进行特征提取。其中,SAE 隐藏层神经元的数量等于其编码器所学习的输入数据压缩表示的个数。编码器对原始数据进行压缩,解码器重构原始输入数据的特征表示。训练完成后,将编码器输出结果作为代表原始数据的特征,即可完成特征提取功能。最后,将提取的特征与原始特征融合,输入至ATBiGRU 模型进行训练。其中,PSAE 的训练及特征提取过程如算法1 所示。
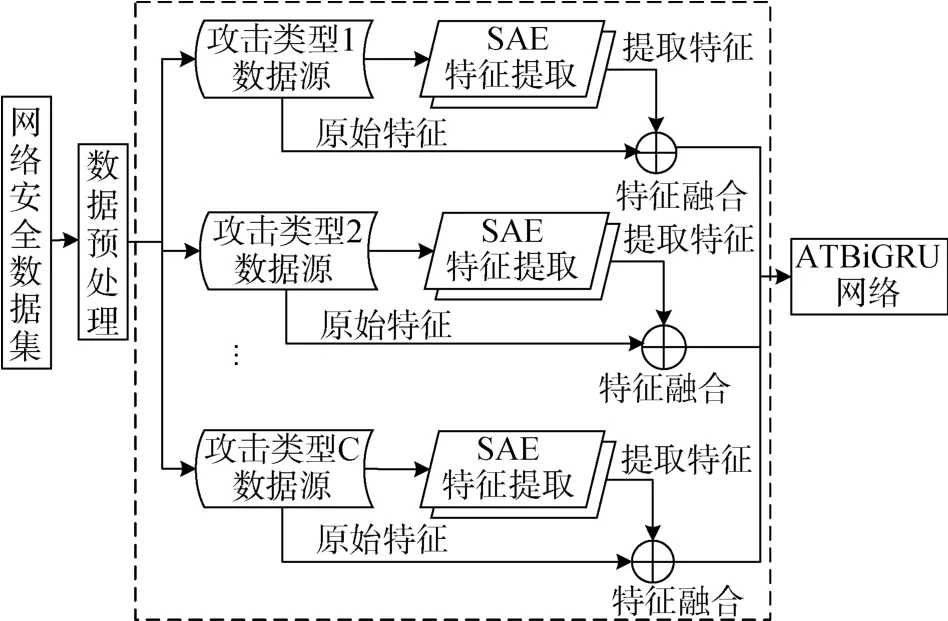
图2 基于PSAE 的特征提取器Figure 2 Feature extractor based on PSAE
算法1.PSAE 的训练及特征提取
输入:不同网络威胁的攻击类型数据:X0,X1,X2,…,XC–1,其中Xi表示攻击类型为i的所有样本数据:Xi={xi0,xi1,…,xi(n–1)}

3 ATBiGRU 网络模型
3.1 BiGRU 网络和注意力机制
BiGRU 是GRU 的改进版本,其结构图如图3 所示。BiGRU 在每个时刻的输入会经过两个方向相反的GRU,其输出结果综合考虑这两个GRU 的输出。因此,BiGRU 可以学习过去和将来状态与当前状态之间的时序关系,有助于提取更深层次的特征信息[32]。
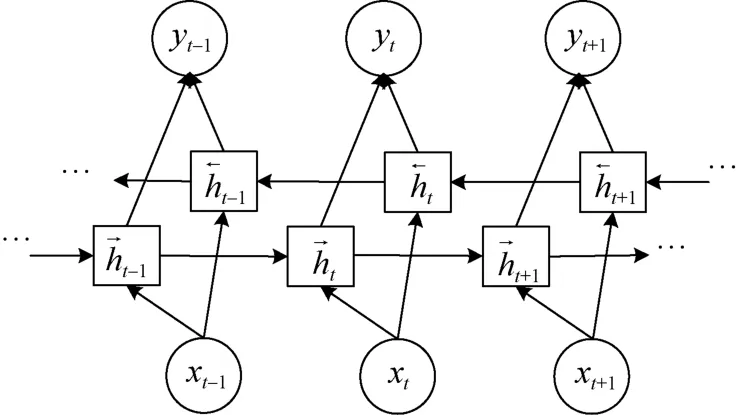
图3 BiGRU 结构图Figure 3 BiGRU’s structure
注意力模型是Treisman 和Gelade 提出的类似于人脑的资源分配模型[33],它通过对目标数据进行加权运算来突出关键特征,较好地提升了模型的拟合效果。因此,本文引入注意力机制,帮助模型可以更有效地学习潜在层特征,并对显著影响最终检测结果的关键特征进行加权,使获得的特征信息更合理、更准确,进而提高模型的检测精度及模型的鲁棒性。
3.2 ATBiGRU 网络设计
首先,由于网络威胁流量属于时间序列事件,即当前时间的攻击类型由当前时刻的数据和先前时刻的数据共同决定,因此通过BiGRU 可有效学习网络威胁流量间的表征关系,增强检测网络的特征学习能力。其次,文献[34]基于GRU 设计了一种分层注意力网络,该网络在选取句子关键词汇的任务上取得了较为不错的成绩。考虑到数据样本中不同时刻的特征信息冗余且对当前攻击类型的分类与检测有不同的贡献,这与关键词汇的选取问题有着相似性,因此采用注意力机制对关键特征加权,实现对BiGRU 网络模型的改进。图4 展示了本文设计的ATBiGRU 模型结构,ATBiGRU 的具体步骤设计如下:
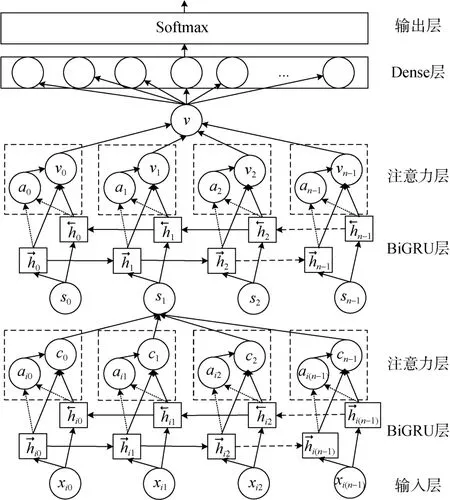
图4 ATBiGRU 模型结构Figure 4 ATBiGRU’s structure
步骤1给定若干条具有n个维度的样本,其中第i条表示为Xi={xi0,xi1,…,xi(n–1)},对应真实标签为Yi。将其输入BiGRU 网络模型,学习样本间的时序关系,并进行编码。通过BiGRU 函数对前向和反向两个隐藏状态加权求和,获得各个隐藏层的状态hij

步骤2使用注意力机制计算每个特征应分配的概率权重,突出网络威胁流量特征中的关键信息,计算局部特征向量,由公式(5)~(7)计算注意力层的权重系数以及局部特征向量
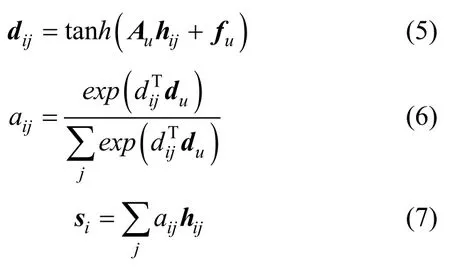
其中,dij指使用softmax函数归一化操作得到的隐藏层状态,hij指BiGRU 模型的输出,Au指加权系数,fu指偏置项,du指随机初始化的注意力矩阵。aij指不同概率权重和每个隐藏层状态的乘积之和,si指由hij与aij加权求和得到的局部特征向量。
步骤3将步骤2的局部特征向量si输入BiGRU网络模型,与步骤2 相似,全局特征向量v由概率权重ai进一步计算得到,由公式(8)~(11)计算注意力层的权重系数以及全局特征向量
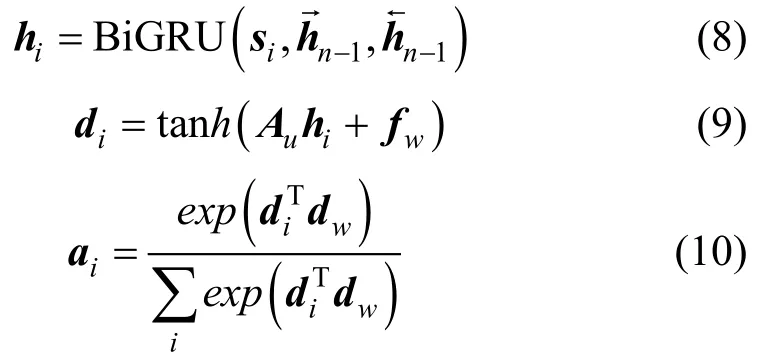

其中,Au、fw和dw分别表示第2 层注意力机制的权重系数矩阵、偏置项和随机初始化的注意力矩阵。
步骤4将步骤3 的结果通过Dense 层进一步提取特征,最后在softmax 输出层输出分类结果Y(Xi)
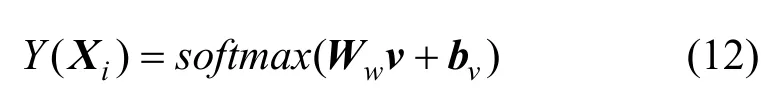
其中,Ww指分类器权重系数矩阵,bv表示分类器偏置,输出Y(Xi)表示模型预测结果。
步骤5将预测结果与原始标签对比并计算误差loss
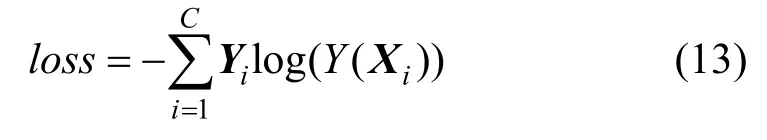
4 基于PSAE-ATBiGRU的网络安全态势评估方法
4.1 网络安全态势评估框架
本文提出的网络安全态势评估模型结构如图5所示。该模型主要包括数据预处理、PSAE-ATBiGRU网络威胁检测和网络安全态势评估3 个部分。
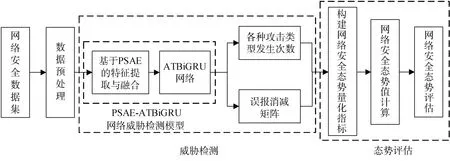
图5 网络安全态势评估模型结构Figure 5 Network security situation assessment framework
(1) 数据预处理:对采集的网络流量数据进行特征数值化、特征约简、特征最大最小值归一化、平衡数据等预处理,之后将数据输入至PSAE-ATBiGRU网络威胁检测模型中进行训练。
(2) PSAE-ATBiGRU 网络威胁检测:将数据测试集输入经过训练的威胁检测模型中,根据模型输出结果记录各种攻击类型的发生次数以及误报消减矩阵,用以计算网络安全态势值。
(3) 网络安全态势评估:依据PSAE-ATBiGRU 网络威胁检测模型的检测结果构建网络安全态势量化指标,计算网络安全态势值并进行网络安全态势评估。
4.2 网络安全态势量化评估
网络安全态势评估结果通过影响网络安全的威胁严重度和威胁影响度确定。
(1) 威胁严重度
威胁严重度由各类攻击发生的次数、误报消减矩阵、各类攻击的威胁严重因子三项指标得出。其中,各类攻击发生的次数、误报消减矩阵由PSAEBiGRU 模型测试的结果得到;各类攻击的威胁严重因子在攻击威胁严重等级的基础上,使用权系数生成法[35]计算得出。具体计算过程如下:
1) 获取各类攻击发生的次数
从测试数据集中随机选取若干组数据,并将其输入到PSAE-ATBiGRU 模型中,对其进行攻击类型检测,模型输出的各类攻击发生的次数为Ci,其中i代表攻击类型。
2) 获取误报消减矩阵
误报消减矩阵为n阶矩阵,其中n代表模型测试结果的攻击类型个数。设数据集中n个攻击类型的下标集合为A={1,2,…,n},aij是模型测试结果为攻击类型i的样本个数中误报为攻击类型j的相对概率。将训练集输入训练完成的威胁检测模型中,获得各种攻击类型发生的次数。根据模型测试结果与实际的攻击类型次数计算aij,得到模型的误报消减矩阵P
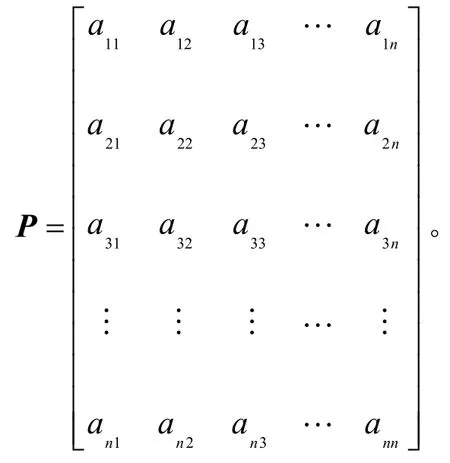
然后,计算各类攻击发生的修正次数Di
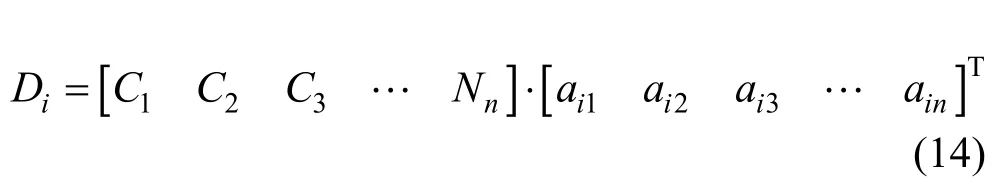
3) 获取各类攻击的威胁严重因子
根据所采集的网络数据集中各类数据类型的主要攻击影响确定其威胁等级,然后再使用权系数生成算法获取并计算各类攻击的威胁严重因子。本文采用的数据集为NSL-KDD 数据集,包括4 种网络攻击类型和1 种正常流量类型,其基本情况如表1所示。
由于权系数生成算法[35]可在已知各类攻击的威胁等级的情况下,计算各种攻击类型的威胁严重因子。所以,在本文的评估方法中,依据表1 确定各种攻击类型的威胁等级,再使用权系数生成算法计算威胁严重因子。设计具体处理过程如下:

表1 5 种数据类型的主要攻击影响Table 1 The main attack effects of the five data types
按照攻击对网络的威胁程度可将n种攻击分为f(1≤f≤n)个不同的威胁等级,等级k的威胁严重因子lk
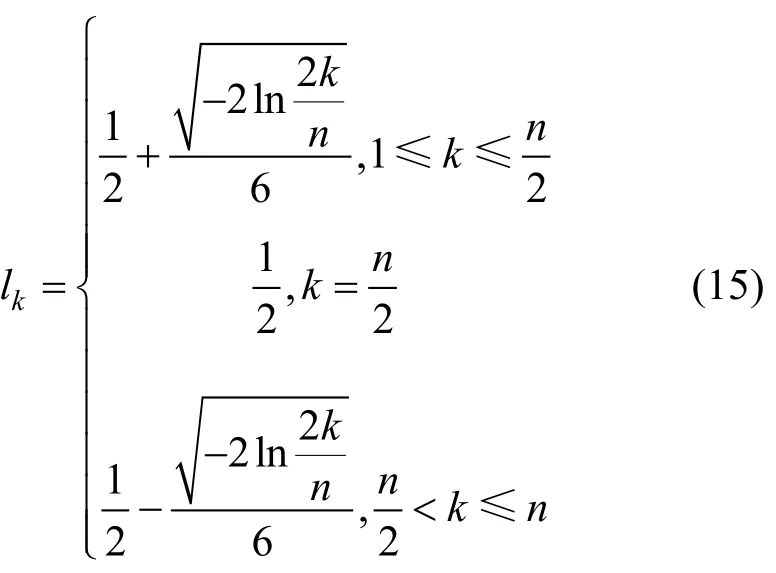
通过权系数生成算法得到各类攻击的威胁严重因子Qi,根据式(14)将各类攻击发生的次数Ci修正得到Di。最后,计算威胁严重度Ti

(2) 威胁影响度
机密性(confidentiality,C)度量攻击对信息资源的机密性的影响;完整性(integrity,I)度量攻击对完整性造成的影响;可用性(availability,A)度量攻击给受影响组件的性能带来的影响。通用漏洞评分系统(common vulnerability scoring system,CVSS)[36]中机密性、完整性、可用性的影响程度和分数如表2 所示。

表2 C、I、A 的影响分数Table 2 Impact scores of C、I、A
首先,根据表1 中各种攻击类型对机密性、完整性、可用性的影响程度进行等级划分并排序。
然后,结合表2,采用对数函数量化方法[37]计算得到各种攻击类型的威胁影响度Pi
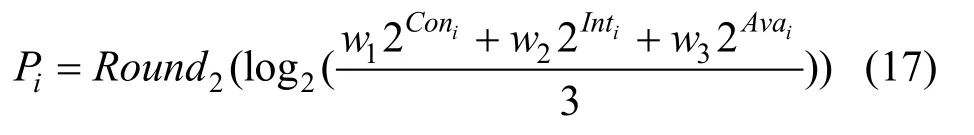
其中,Coni、Inti、Avai分别指攻击类型i的C、I、A影响分数,w1、w2、w3分别对应C、I、A的权重。
(3) 网络安全态势值
首先,计算得到网络安全态势值R

其中,N表示有N个样本,n表示有n种攻击类型,Cn表示Normal类型出现的次数。由于正常的网络流量对于网络环境无危害,因此Normal类型的威胁严重度和威胁影响度为0,只需计算n–1种攻击类型对网络安全态势的影响即可。
然后,根据R值的区间,参考《国家突发公共事件总体应急预案》[38]和Snort 手册划分网络安全态势评估等级,该安全态势评估等级包括:安全、低危、中危、高危和超危5 个等级,对应的态势值区间和具体的说明如表3 所示。

表3 网络安全态势评估等级划分表Table 3 Classification table of network security situation assessment
5 实验与结果
为验证本文方法对网络安全态势评估的有效性和全面性,通过实验验证PSAE特征提取器和注意力机制对基础模型BiGRU 性能的提升效果。同时,通过与典型方法的对比实验,验证本文方法应用于网络安全态势评估的客观性与可行性。
上述实验均在 Ubuntu 系统上进行,使用TensorFlow 编程实现网络搭建,并采用TensorFlow-GPU[39]加速网络训练。实验配置为:Intel(R) Xeon(R)Silver 处理器、32GRAM、显卡为RTX2060、内存16G。
5.1 数据集描述与数据预处理
由于NSL-KDD 数据集解决了KDD99 数据集的故有问题[40],其训练集KDDTrain+不包含冗余记录、测试集KDDTest+不包含重复记录、训练集和测试集记录数量设置合理,故选取NSL-KDD 数据集进行实验。NSL-KDD 数据集的基本信息如表4 所示。
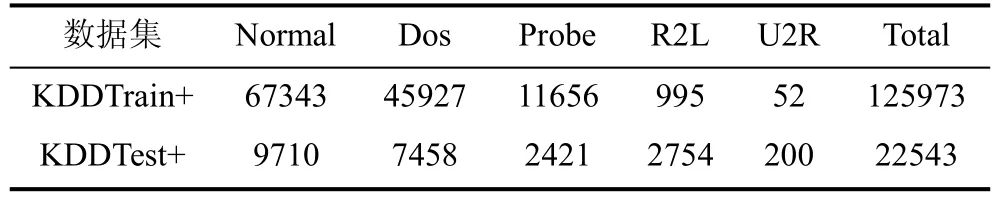
表4 NSL-KDD 数据集信息Table 4 NSL-KDD dataset information
数据预处理过程包括特征数值化、特征约简、特征最大最小值归一化、平衡数据四项操作。
(1) 特征数值化
训练网络模型时需要将分类特征转化为连续值进行输入,NSL-KDD 数据集中包括三个分类特征,因此,通过独热编码(One-Hot)将其转化为分类向量来表示每个特征。例如,“protocol_type”的属性“tcp”、“udp”和“icmp”将分别转换为(1,0,1),(1,0,0)和(1,1,0)分类特征向量。用相同的方法将其余两个分类特征转化为对应的分类向量。完成所有转换后,将数据集的特征维度从41 个扩展为122 个。
(2) 特征约简
NSL-KDD 数据集中有15 个特征为零值,由于它们的零值不会对模型训练结果产生影响且删除这些特征可以降低维度并提高训练效率,因此,删除这些冗余的特征,将数据集的特征维度从122 个缩减为107 个。
(3) 特征最大最小归一化
NSL-KDD 数据集中部分特征的最大值和最小值之间的范围差异很大,例如“duration”中最大值和最小值之间的差异最大为58329,最小为0,“srcbytes”和“dst-bytes”等特征也存在较大差异。为消除特征之间单位和尺度差异对模型训练带来的影响,应对特征进行归一化处理,提升模型的训练效果。为此,将特征映射至[0,1]区间

其中,x表示特征原始值,xmin表示特征最小值,xmax表示特征最大值。
(4) 平衡数据
从表4 可见,NSL-KDD 数据集数据类型分布不平衡,训练集KDDTrain+中Normal 类有67343 条数据,而U2R 和R2L 仅包含52 和995 条数据,不同攻击类型数据量失衡会导致模型的弱检测问题。因此,为了提高模型的检测效果,本文采用ADASYN 算法[41],根据数据分布情况对不同类别的样本采样不同数量的新样本,进而解决数据不平衡问题。
5.2 评价定义
为评估模型的性能,实验选择正确分类为正常的样本数TN(True Negatives)、错误分类为正常的攻击样本数FN(False Negatives)、正确分类为攻击的样本数TP(True Positives)、错误分类为攻击的正常样本数FP(False Positives)用于定义以下指标:
准确率(Precision,P),指学习模型正确预测为攻击的个数与学习模型预测为攻击的样本总数的百分比,表示为

召回率(Recall,R),指学习模型正确预测为攻击的个数与真实类别为攻击的样本总数的百分比,表示为

F1 值(F1-score,F1),综合考虑了P和R,是衡量模型检测性能的重要指标,表示为

5.3 模型训练与模型检测
实验选取训练集KDDTrain+中的125973 条数据作为训练集进行学习,预训练学习率为le-3,当准确率20 轮内不再提升时,将学习率减少为原来的0.5倍,每一批次输入1024 条数据,网络迭代训练200次。训练完成后,选取测试集KDDTest+中的22543条数据作为测试集进行威胁检测。
为了分析本文所提模型PSAE-ATBiGRU 的威胁检测准确率,与原始模型BiGRU、仅用PSAE 对原始模型进行改进的模型PSAE-BiGRU 和仅用注意力机制改进的模型ATBiGRU 进行对比,图6 展示了训练过程中测试集在4 种模型上的准确率变化情况。
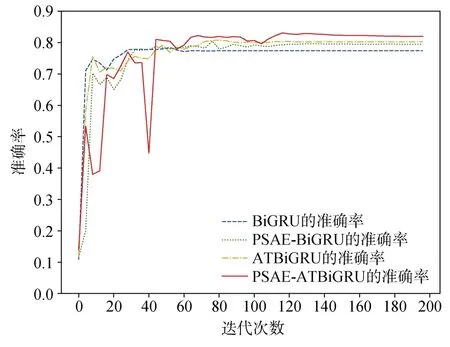
图6 4 种模型的威胁检测准确率Figure 6 Threat detection accuracy of four models
首先,从图6 我们可以看到,在训练过程中,迭代次数为40 次附近时模型的准确率波动较大,但后期准确率趋于稳定。这是由于我们在训练过程中,采用了动态的学习率调整策略,训练早期学习率较大,模型还未很好的拟合数据的分布,导致模型在最优解附近震荡。训练后期,模型已经可以较好的拟合数据分布,此时学习率动态调整到较小的值,准确率趋于稳定。
其次,由图6 可见,与BiGRU 模型相比,PSAEBiGRU 和ATBiGRU 两种模型的准确率分别提高了2.85%和3.64%,本文模型的准确率为82.13%,比BiGRU 模型提高了5.28%。原因在于本文模型采用PSAE 提高原始数据的表征能力,通过注意力机制进行加权特征学习,突出了上述两种方法的优点。
分别从准确率、召回率和F1 值方面比较分析上述4 种模型,实验结果见图7。其中,纵坐标表示模型评价得分,数字越大表明模型性能越好。对比结果表明,本文模型的准确率、召回率、F1 值均优于其他3 个模型。与BiGRU、PSAE-BiGRU 和ATBiGRU模型相比,本文模型的准确率分别提高了5.28%、2.43%、1.64%;召回率分别提高了5.65%、2.58%、1.42%;F1 值分别提高了5.46%、2.5%和1.53%。
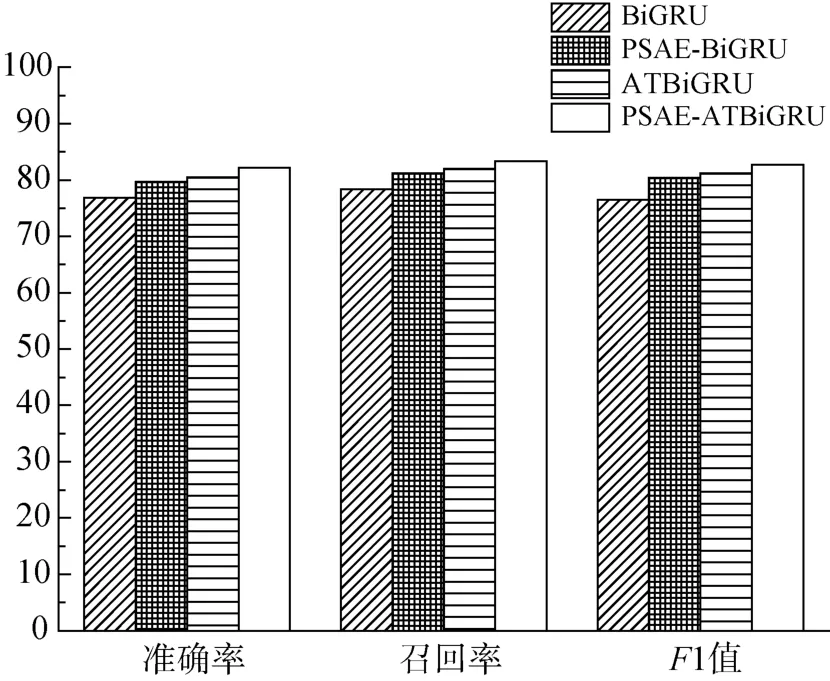
图7 4 种模型的准确率、召回率、F1 值Figure 7 Accuracy,recall,and F1 of four models
5.4 网络安全态势评估结果与分析
为评估网络的整体态势,须对影响网络安全的威胁严重度和威胁影响度两个影响因素进行量化评估。首先,通过网络威胁测试获取各类攻击发生的次数和误报消减矩阵,再结合各类攻击的威胁严重因子确定威胁严重度。然后,结合4.2 节各类攻击的威胁影响度计算网络安全态势值。最后,依据态势值区间对照表3 确定网络的整体安全态势评估结果。
随机从测试集中选取100 组相同数据数量的测试样本集合。将其作为输入数据对 BiGRU、PSAE-BiGRU、ATBiGRU 和PSAE-ATBiGRU 4 种模型进行100 组测试实验,采用本文态势值量化方法得到基于上述4 种模型的网络安全态势值,结合网络的实际态势值计算每种模型的网络安全态势值测试误差值。通过将式(16)中的Di替换为测试样本中各种攻击类型的实际次数,由式(17)、(18)计算得到实际态势值。图8 展示了其中20 组的归一化态势值测试误差值λ。

图8 4 种模型的网络安全态势测试误差Figure 8 The network security situation test errors of four models
由图8 可见,BiGRU 模型的误差值最大,而在此模型上改进的PSAE-BiGRU 和ATBiGRU 模型的误差值均小于BiGRU 模型,验证了本文方法的有效性。与3 种模型相比,基于本文模型PSAE-BiGRU得到网络安全态势值与真实值的测试误差值λ最小,这说明本文方法对网络安全威胁的检测能力更突出,计算出的网络安全态势值更符合实际的网络安全态势情况。
为进一步验证评估结果的客观性与真实性,从NSL-KDD 测试集中随机选取相同数量的测试样本,采用SVM[25]、LSTM[21]、BiGRU[20]、AEDNN[22]、PSAE-ATBiGRU 模型进行威胁检测实验。根据威胁检测结果获取每个模型在每组测试实验中各类攻击发生的次数。最后,结合每个模型的误报消减矩阵、各类攻击的威胁严重因子、各类攻击的C、I、A影响分数,采用4.2 节态势值计算方法得到基于上述5种模型的网络安全态势值。图9 展示了其中20 组实验的网络态势值对比结果。
由图9可见,PSAE-ATBiGRU模型得到的网络安全态势值和真实的态势值始终位于同一态势评估区间,而SVM、LSTM、BiGRU 和AEDNN 模型得到的态势值存在与真实态势值不在同一区间的情况。如:在第2、15 组中,SVM、LSTM、BiGRU 和AEDNN模型的网络安全态势评估结果为中危,而真实的态势情况为低危;在第3 组中,SVM、LSTM、BiGRU和AEDNN 模型的网络安全态势评估结果为中危,而真实的态势情况为高危。这表明,PSAE-ATBiGRU模型的态势评估结果更贴合实际的网络态势情况。

图9 5 种模型的网络安全态势值对比Figure 9 Comparison of network security situation values of five models
此外,图9 的部分测试结果中,SVM、LSTM、BiGRU、AEDNN 和PSAE-ATBiGRU 模型的态势值均与真实的态势值在同一态势评估区间,但是,PSAE-ATBiGRU 模型得到的网络安全态势值始终与真实的态势值更接近。如:在第1、6 组中,5 个模型的态势值与真实的态势值均在同一态势评估区间,但是PSAE-ATBiGRU 模型的态势值与真实态势值之间的误差更小。这表明,PSAE-ATBiGRU 模型对网络威胁的表征能力更强。
从测试数据集中随机选取10 组相同数量的测试样本,模拟某一时间段内网络受到的威胁攻击情况并进行测试实验。在10 个相同时间段内,分别采用SVM、LSTM、BiGRU、AEDNN 和PSAE-ATBiGRU模型计算网络安全态势值与实际安全态势值对比误差,然后计算每段时间内5 种模型的均方根误差值。由表5 可见,AEDNN 模型的均方根误差值小于SVM、LSTM 和BiGRU,因为该模型应用UOSW 算法[22]提高了U2R 和R2L 两种少训练样本类别的准确率。此外,PSAE-ATBiGRU 模型的均方根误差值最小,其学习结果优于其他4 种模型,由该模型得到的安全态势值与真实安全态势值最接近,其检测效果更符合实际。
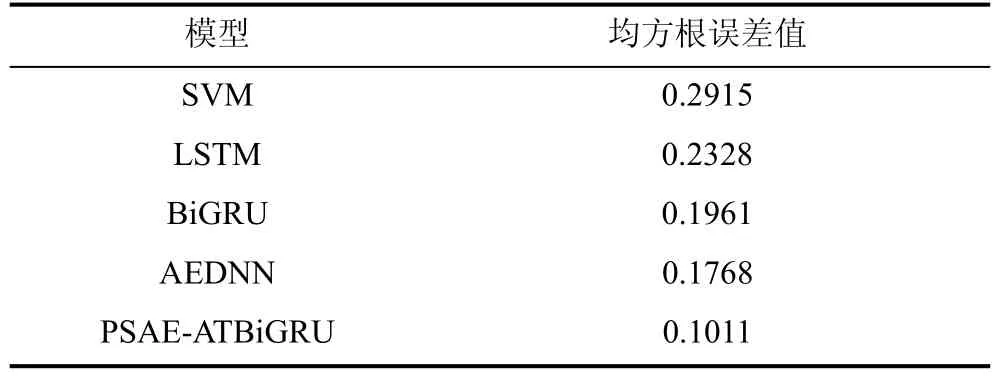
表5 5 种模型的均方根误差值Table 5 Root mean square errors of five models
表6 具体展示了由本文方法得到的10 个时间段内的安全态势评估结果与实际态势情况。由表6 可见,本文方法计算的态势值与实际态势值之间存在些许差异,但评估结果落在了相同的区域,根据表3定义的网络安全态势等级,本文方法的态势评估结果与实际情况相符。
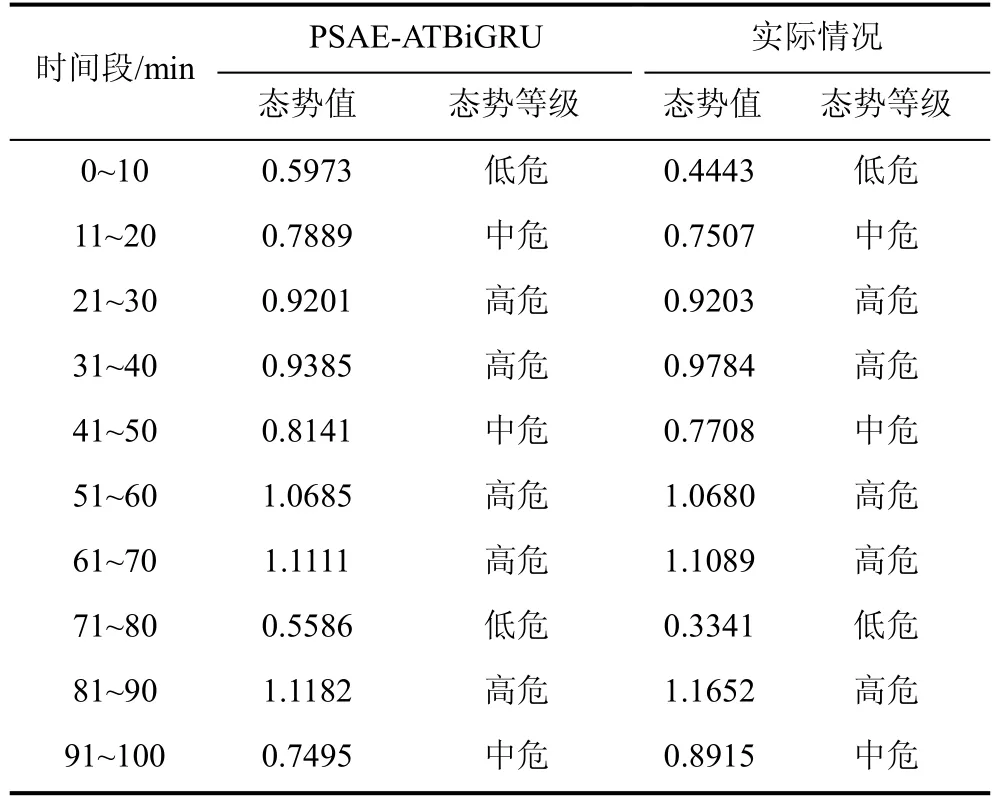
表6 态势值和网络安全态势评估情况Table 6 Situation value and network security situation assessment
6 结论
本文提出了一种基于深度加权特征学习的网络安全态势评估方法。该方法使用并行特征提取方法有效增强提取特征对原始数据的表征能力,应用注意力机制对BiGRU 网络进行改进从而确定不同特征的最佳权重。通过PSAE-ATBiGRU 对网络威胁进行检测并根据检测结果以及误报消减矩阵评估网络安全态势。通过与BiGRU、LSTM、SVM、AEDNN 等方法的评估对比实验,表明本文方法获得的网络安全态势评估结果的有效性和可靠性更具优势。
在未来的研究中,拟考虑将本文模型应用于更多种类的网络安全数据集的威胁检测。除此之外,研究更加有效的优化算法以提高模型建模速度,进一步减少模型的训练和测试时间。
猜你喜欢
社会科学战线(2022年4期)2022-06-15
红领巾·探索(2020年5期)2020-05-19
汽车与安全(2020年1期)2020-05-14
中国外汇(2019年19期)2019-11-26
科学大众(中学)(2019年2期)2019-04-08
小学生必读(中年级版)(2018年4期)2018-07-05
互联网天地(2016年1期)2016-05-04
文理导航·科普童话(2015年6期)2015-07-29
声屏世界(2015年7期)2015-02-28
中国经济信息(2004年13期)2004-07-02
