
基于数据结构特征发现的脚本引擎内置对象别名关系识别
2022-08-16 09:34张羿伟万欣宇郭苏越
信息安全学报 2022年4期
张羿伟,游 伟,梁 彬,万欣宇,郭苏越
中国人民大学信息学院 北京 中国 100872
1 引言
脚本语言具有简单易用的特性,越来越多的软件支持通过脚本语言可编程式地调用各项程序功能。这些软件通过内置的脚本引擎对脚本代码进行解析并执行。内置脚本引擎除了支持标准的脚本语言规范,还提供了一系列扩展的应用程序编程接口(Application programming interface,API)和内置对象。用户可以通过调用扩展 API 来执行由本地代码(Native code)实现的程序功能。
脚本引擎在丰富软件功能的同时,也引入了额外的攻击面。攻击者可以利用脚本引擎漏洞,编写特定攻击代码,达到控制用户设备、窃取用户隐私等目的。根据漏洞库中的信息,近年来频繁出现脚本引擎相关的程序安全漏洞,已造成大量经济损失与安全危害[1]。通过对已公开的漏洞利用样本进行分析[2],我们发现绝大多数的脚本引擎漏洞是由于扩展API和内置对象使用不当产生的。
针对脚本引擎中的程序漏洞,目前主流的检测技术为模糊测试(Fuzzing)[3],使用特定的生成/变异策略产生大量测试样本,并监测测试样本的执行是否触发程序异常。然而,现有的模糊测试研究工作主要关注如何生成符合脚本语言语法规范的测试样本。虽然取得了一定的成效,但是这些研究工作仅能检测出脚本引擎浅层解析代码中的漏洞,难以有效检测出脚本引擎深层代码中的漏洞。
脚本引擎中的深层次漏洞通常与扩展API 及内置对象相关。以释放后使用(Use-After-Free,UAF)漏洞为例,其本质为通过悬挂指针非法访问了被释放的内存区域。在脚本引擎中,通过调用特定的API序列,可以创建内置对象内部的共享内存区域,进而产生不同对象在共享内存区域上的别名关系。释放其中一个对象内部的共享内存区域,将会在与其存在别名关系的另一对象内部产生悬挂指针,访问该悬挂指针会触发释放后使用漏洞。现有的模糊测试技术没有关注内置对象内部结构,因而在发现释放后使用漏洞方面效果较差。
为了检测由对象别名关系导致的释放后使用漏洞,需要解决两个关键的技术挑战。其一,如何高效地识别内置对象别名关系。脚本引擎中的内置对象由脚本引擎负责维护,用户可以通过使用API 的方式来创建、更改和删除内置对象。生成合理的API序列对不同对象进行有针对性的操作是首要解决的问题。除此之外,由于内置对象别名关系与对象结构紧密相关,需要实现一种机制快速检测API 序列的执行是否建立了对象间的共享内存区域。其二,如何利用识别出的对象别名关系检测脚本引擎的释放后使用漏洞。为了触发脚本引擎释放后使用漏洞,需要构造性地利用对象别名关系以产生悬挂指针。别名关系代表不同内置对象内部存在共享内存区域,因此需要考虑如何生成API 序列释放对象内部的共享内存区域,以产生悬挂指针。进一步,利用API 序列针对性地访问悬挂指针,触发释放后使用漏洞。
为了解决上述挑战,我们提出了一种基于数据结构特征发现的脚本引擎内置对象别名关系识别方法,并利用内置对象别名关系辅助检测脚本引擎中的释放后使用漏洞。具体而言,通过生成特殊的脚本引擎API 调用序列,建立内置对象别名关系,并使用对象数据结构特征,将内置对象别名关系识别转化为图连通性识别,加快了内置对象别名关系识别速度。在此基础上,我们提出了一种利用别名关系构造式触发释放后使用漏洞的检测方案。对于具有别名关系的两个对象,通过调用特殊的脚本引擎API 序列,释放其中一个对象内部的共享内存区域,从而在另一个对象内部产生悬挂指针,随后调用特殊的脚本引擎API 序列访问另悬挂指针,以触发释放后使用漏洞。
本文的主要贡献有:
(1) 提出了一种基于数据结构特征的脚本引擎内置对象别名关系识别方法。通过利用内置对象数据结构特征,自动化提取脚本引擎API 参数信息并生成合理API 序列,提高了对象别名关系的产生概率。同时,利用对象数据结构特征,将内置对象别名关系识别转化为图连通性识别。在保证识别准确率的前提下,显著减小了性能开销,加快了内置对象别名关系识别速度。
(2) 创新性地将内置对象别名关系应用于检测脚本引擎释放后使用漏洞。通过使用内置对象别名关系,搭配特殊API 序列,增加了释放操作产生的悬挂指针数量。相比于传统释放后使用漏洞,由对象别名关系导致的释放后使用漏洞更容易利用且更难修补。
(3) 设计并实现了别名关系识别方法的系统原型,成功提取出了284 组内置对象别名关系,并设计评估实验证明了方法的高效性与准确性。进一步,针对真实软件中的脚本引擎进行了漏洞检测,成功发现了4 个未知释放后使用漏洞,帮助提高了软件安全性。
2 相关工作
针对脚本引擎中的安全漏洞,目前主流的检测技术为模糊测试(Fuzzing)技术。模糊测试技术根据特定的生成策略产生大量测试样本,并监测测试样本的执行能否触发程序异常。按照技术细节不同,具体又可分为生成型模糊测试以及变异型模糊测试[4]。
生成型模糊测试技术基于给定的规范(如语言语法,样本结构等)生成测试样本,部分生成型模糊测试框架也会借助语料库信息[5],常见的测试框架有SPIKE[6]和jsfunfuzz[7]等。为了生成语法正确的测试样本,通常使用上下文无关语法作为规范[8-9]。除此之外,HyungSeok 等人[10]和Soyeon 等人[11]提出利用现有正确测试样本中的语法信息来完善样本生成规范。进一步,Suyoung 等人[12]提出利用神经网络来训练模型以产生样本生成规范,旨在通过完善规范来提升测试样本质量。然而,不同脚本语句之间存在依赖关系,生成型模糊测试技术无法捕获此类依赖关系,因而无法避免由依赖关系导致的运行时异常。
变异型模糊测试技术基于给定的种子输入,采用不同的变异策略(如比特翻转,随机替换等)生成新的测试样本,常见的测试框架有AFL[13]和SymFuzz[14]等。变异型模糊测试技术通常以代码覆盖率为指标评估测试样本的质量,认为代码覆盖率越高测试样本质量越好。为了提高测试样本的质量,常使用污染传播[15-16],符号执行[17]和约束求解[18]等技术。除此之外,Sanjay 等人[19]通过设置程序路径权重,有针对性地进行变异以生成测试样本,以及Caroline 等人[20]提出在变异过程中加入已知漏洞样本(Proof of Concept)信息,以生成高质量测试样本。然而,变异型模糊测试容易破坏种子输入的完整性,导致无法通过完整性校验。
在测试脚本引擎漏洞方面,Sung 等人[21]提出了一种使用内置API 和内置对象来测试JavaScript 脚本引擎的方法,以减少运行时错误的产生。该方法虽然利用脚本引擎API 和内置对象信息减少了运行时错误的数量,但测试样本的生成不够自动化,且需要一些先验知识做引导。除此之外,Nicolas 等人[22]提出利用程序运行时的内存访问信息来改进测试样本,以测试更复杂的程序模块,但对于大型脚本引擎效果不佳。
别名分析的主要目的在于确定程序中指针的具体指向,进而判定指针操作是否存在潜在风险[23]。现有别名分析技术主要分为静态别名分析以及动态别名分析。静态别名分析通过分析程序源代码来识别别名关系,常结合控制流图或调用图进行分析[24],即过程间分析[25-26]。通常静态别名分析所需时间与控制流图的复杂程度成正比,为了精简控制流图,Tobias 等人[27]提出将分支条件与变量状态关联,并依据变量状态来删除冗余分支。动态别名分析则通过监控内存中变量的变化来识别别名关系,常在中间代码层面进行程序插装以判断不同变量之间是否共享同一内存区域[28-29]。Manu 等人[30]提出实施简单的可达性分析,缩小监控范围提高分析性能。然而,由于脚本引擎结构复杂,使用现有技术获得精确分析结果存在性能开销大的问题,且内置对象结构特殊,无法使用通用的处理策略。
3 脚本引擎与释放后使用漏洞
脚本引擎作为脚本语言运行的载体,负责解析执行脚本语言,以及提供相应的运行环境。脚本引擎提供了一系列定制的应用程序接口(Application programming interface,API)来帮助用户高效使用内部功能,我们称之为特殊API,如Adobe Reader 内嵌脚本引擎中的Doc.createIcon 负责在文档中创建按钮元件。与特殊API 类似,脚本引擎中的内置对象也具有特殊的结构和语义,如Adobe Reader 内嵌引擎中的Doc 对象代表当前文档。特殊API 以及内置对象是脚本引擎的重要组成部分,不同脚本引擎中特殊API 以及内置对象的数量和功能均有较大差异,合理使用特殊API 与内置对象能触及更多、更深层次的引擎代码。
在使用脚本引擎API 时,需要遵照特定的使用规范,即提供正确数量和类型的参数。当脚本引擎API 参数的数量或类型错误时,脚本引擎会抛出运行时异常,并终止脚本代码的执行。脚本引擎中API参数的类型包括布尔类型,整数类型,浮点类型,字符串类型以及对象类型五类,不同类型之间可以动态转化。
进一步,经过实验发现,脚本引擎API 在运行时需要特定结构的内置对象,因此需要分析内置对象的细粒度类型信息。通常,对于脚本引擎API,软件开发者会提供一份官方的使用规范,说明不同脚本引擎API 需要的参数个数以及类型。然而,以Adobe Reader 内嵌脚本引擎为例,官方提供的使用规范并不详细,未说明脚本引擎API 对象参数的细粒度类型信息。我们统计了Adobe Reader 内嵌脚本引擎中的386 个API,其中使用对象类型参数的API 有255个,占比约66%。为了减少运行时错误,我们需要提取API 参数的细粒度类型,进而正确且针对性地使用脚本引擎API 和内置对象。
内置对象的生命周期由脚本引擎负责维护,在生命周期结束时被脚本引擎回收。用户可通过调用脚本引擎API 来创建,更改和删除内置对象,即能够通过调用脚本引擎API 影响内置对象生命周期。按照创建方式的不同,具体可以分为静态内置对象以及动态内置对象。静态内置对象由脚本引擎预创建,可直接使用对象名称访问,而动态内置对象需要调用脚本引擎API 创建后才能访问。
对于静态内置对象以及动态内置对象,脚本引擎采用一个活跃对象集合维护其生命周期。活跃对象集合存储脚本引擎中存活的内置对象,其状态随着内置对象的创建和删除实时变化。活跃对象集合由脚本引擎负责维护,用户无法直接更改其状态,但可以通过影响内置对象生命周期,间接影响活跃对象集合的状态。活跃对象集合常用于查询内置对象生命周期信息,在脚本引擎中具有重要意义。
脚本引擎在通过丰富的API 以及内置对象提供便利的同时,也引入了更多安全漏洞。攻击者可利用脚本引擎API 以及内置对象构造特殊的攻击代码,触发多种类型的安全漏洞,对用户造成危害。其中,释放后使用漏洞与非法内存操作紧密相关,可利用性强,常成为攻击者的重点关注目标。释放后使用漏洞的本质为通过悬挂指针访问了被释放的内存区域,而悬挂指针是指向被释放内存区域的指针,是由于对象释放后缺乏合理的访问检查导致。我们以图1 为例具体说明释放后使用漏洞的触发模式和修补方式。
图1 展示了1 个典型释放后使用漏洞的触发模式。首先执行创建操作(malloc)创建对象p(对应标号为①的语句)。接着调用合适的API 序列执行释放操作(free),释放创建出的对象p并产生了悬挂指针(对应标号为②的语句)。最后,使用(use)被释放的对象p并访问其内部的悬挂指针,触发了释放后使用类型的安全漏洞(对应标号为③的语句)。现有工作针对释放后使用漏洞的修补方式对应语句⑤⑦⑧,即增加对象释放标志并根据对象状态实时维护释放标志(对应标号为⑦的语句),同时在每次访问对象前检查释放标志的状态(对应标号为⑧的语句),当对象释放标志被设置为True 时拒绝访问对象。
修复释放后使用漏洞的核心在于消除悬挂指针,现有设置对象释放标志的方式简单有效,且适用于所有类型的对象,通用性强。然而,由于脚本引擎内部存在复杂对象关系,比如内置对象别名关系,导致不同内置对象内部存在共享内存区域,进而在释放时出现多个悬挂指针。相比于原有的释放后使用漏洞,使用对象别名关系可以在不同对象中引入悬挂指针,增加了漏洞的不确定性,利用释放标志进行修补也更加困难。我们将由对象别名关系导致的释放后使用漏洞触发模式总结为图2 所示。
如图2 所示,首先执行创建操作产生了对象p和对象q(对应标号为①②的语句)。接着,通过执行特定脚本引擎API 序列,建立了对象p和对象q之间的别名关系(对应标号为③的语句),具体对应对象p,q内部的共享内存区域。之后,执行释放操作释放对象p(对应标号为④的语句),产生了悬挂指针。不同于传统释放后使用漏洞触发模式,在最后访问悬挂指针时,并未使用上一步中释放的对象p,而是使用了与对象p存在别名关系的对象q(对应标号为⑤的语句)。
相较于传统的释放后使用漏洞,通过建立内置对象别名关系,引入了更多的悬挂指针,增加了释放后使用漏洞的可利用性。传统的释放后使用漏洞触发模式与对象别名关系导致的释放后使用漏洞触发模式有如下异同点:二者均通过访问悬挂指针触发安全漏洞,但在传统释放后使用漏洞触发模式中,释放以及使用的为同一个对象,仅产生了一个悬挂指针。在别名关系导致的释放后使用漏洞中,释放以及使用操作涉及不同对象,产生了多个悬挂指针。相较于传统的释放后使用漏洞,别名关系触发的释放后使用漏洞更为复杂,涉及不同内置对象的交互,并且现有的防御措施无法有效抵御别名关系导致的释放后使用漏洞。
4 别名关系识别
本研究提出了一种基于数据结构特征脚本引擎内置对象别名关系识别方法,能高效准确地建立并识别脚本引擎内置对象别名关系,如图3 所示,整个内置对象别名关系识别方法共分为三个阶段。
第一阶段对应文章3.2 节,负责提取脚本引擎内置对象的数据结构特征。该阶段主要采用动态插装的方式,使用脚本引擎API 创建并访问内置对象并监控程序执行,获取程序运行时内置对象的内存地址。进一步,通过识别与对象起始地址相关的内存单元类型,提取脚本引擎内置对象的数据结构特征。
第二阶段对应文章3.3 节,负责生成参数类型正确的脚本引擎API 调用实例。此阶段我们采用静态分析技术来提取脚本引擎API 对象参数的内存访问模式,并与第一阶段中提取的对象数据结构特征匹配,获得API 对象参数候选集。进一步,使用获得的API 对象参数列表,生成参数类型正确的脚本引擎API 调用语句,并组合不同API 调用语句产生测试样本。
第三阶段对应文章3.4 节,负责监测共享内存区域来识别内置对象别名关系。该阶段主要使用动态测试的技术,获取程序运行时对象的内存地址,提取对应的内置对象数据结构特征,并转化为数据结构特征图存储。通过在API 执行前后插入检查点的方式,分析数据结构特征图的变化,并根据数据结构特征图的变化识别内置对象别名关系。
在接下来的部分,我们首先介绍内置对象数据结构特征的定义,之后依次介绍流程每个阶段的具体实现。
4.1 内置对象数据结构特征
内置对象数据结构特征T定义为由不同类型内存单元组成的,具有明显分层与指向关系的一种内存特征。我们以字长为单位划分内置对象所在的内存区域,并将划分后的字长大小的内存区域称为内存单元。字长的大小与操作系统相关,在64 位操作系统中字长大小为8 字节,32 位操作系统中字长大小为4 字节。对于内置对象数据结构特征T,我们采用有向图的方式表示如下:
其中,V代表有向图中顶点的集合,E代表有向图中边的集合,具体如下:
顶点集合V中每个元素vi均对应一个内存单元,vi的具体定义如下:
vi定义为由Value,Type和Ancient 组成的三元组,其中Value 代表运行时内存单元中存储的数值,随着脚本引擎API 的执行发生变化。Type 代表内存单元数值的类型,具体包括可变数值类型(Number),固定数值类型(Padding)以及指针类型(Pointer)3 种,在具体实现时用不同数值代表3 种类型(如指针类型对应数值0x1)。固定数值类型代表内存单元中数据的数值固定,即相同类型的内置对象拥有相同的数值。同时,固定数值类型对应的数值与运行状态无关,即多次创建出相同类型的内置对象,其固定数值类型对应的数值均相同。可变数值类型的定义与固定数值类型相反。对于相同类型对象,可变数值类型内存单元中数据的数值不固定,且与运行状态紧密相关,在多次运行中会得到不同的数值。指针类型的内存单元代表该内存单元中的数据指向其他合法内存单元,能够通过指针解引用操作进行层级展开。Ancient为内存单元所属标识,代表该内存单元从属于特定内置对象。我们为同一内置对象下属所有内存单元设置统一的Ancient,并使用唯一Ancient值以区分不同内置对象。通常,Ancient 值被设置为内置对象运行时内存起始地址,方便查询内置对象信息。
边集E中每个元素ei代表有向图中顶点的指向关系,其具体定义如下:
其中,vs和ve分别代表该有向边的起始顶点和终止顶点,对应顶点集合V中的元素。Offset 为顶点vs代表内存单元到顶点ve代表内存单元的内存偏移。在ei中,顶点vs对应指针类型的内存单元,我们根据其中包含的指向信息划分对象数据结构特征内部的层级。以Stream 对象为例,Stream 对象起始地址对应的内存区域称为第一层级,第一层级中指针类型指向的内存区域为第二层级,以此类推。
我们将存储对象数据结构特征的有向图称为数据结构特征图。数据结构特征图中的根节点代表具体内置对象,每个子节点对应数据结构特征中的每个内存单元。以Stream 类型对象为例,最终转化成的数据结构特征图如图4 所示。以图4 右下角阴影标注的顶点为例,三元组中Value 的值为0x1340,代表运行时内存单元中的数值为0x1340。Type 值为0x1代表该顶点的类型为指针类型。Ancient 值为0x1220对应对象根节点的Value 值(即图4 中Stream 标注的顶点),标明该顶点属于Stream 对象。
内置对象数据结构特征中的层级个数以及内存单元个数可自主配置。通常而言,使用的层级个数和内存单元个数越多,特征的分类效果越好,而性能开销则越大。为了确定合适的配置,我们进行了相关探索,结果如表1 所示。当层级个数为1,每个层级中内存单元的个数为4 时,所有内置对象被归为一个类,没有任何区分度。随着层级个数与内存单元个数的增加,内置对象种类的数量也随之上升,上升幅度呈递减趋势。最终,出于平衡性能开销与分类效果的考虑,确定层级个数为3,层级中内存单元个数为8。第6 章的实验评估结果也表明,这样的配置可以保证较高的测试用例生成效率。
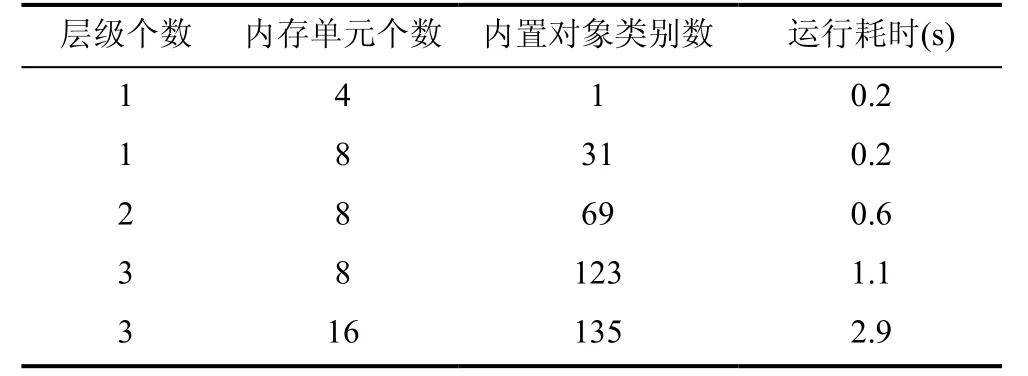
表1 内置对象种类统计表Table 1 Statistics of built-in object type
4.2 提取内置对象数据结构特征
在该节中我们具体介绍如何提取内置对象数据结构特征。该阶段主要采用动态插装的方式,获取程序运行时内置对象的内存地址,具体又分为获取对象内存地址以及内存单元类型识别两部分。进一步,通过识别内置对象内存地址相关的内存单元类型,提取出内置对象的数据结构特征。
4.2.1 提取内置对象列表
首先需要提取脚本引擎中所有静态、动态内置对象。为了提取脚本引擎所有的静态内置对象,我们采用深度优先遍历的方式,从文档根节点出发依次访问文档中所有节点。具体实现时我们使用for-in的方式进行遍历,对于访问到的每一个节点,调用内置操作符typeof 判断其节点类型,并记录对象类型节点的信息,即静态内置对象信息。同时,为了避免遍历过程陷入死循环,我们标记了所有已访问的节点,并以集合的方式存储。当某次访问的节点位于标记集合中时,不再从该节点出发进行更深层次的遍历。
脚本引擎中的动态内置对象需要调用脚本引擎API 创建。由于官方文档的说明信息不全,如针对Collab 这一类型的内置对象,官方文档中仅包含三个子方法说明,而实际存在23 个子方法。因此,需要提取不在官方文档中的脚本引擎API,以获得完整的脚本引擎API 列表。我们同样采用从文档根节点出发深度优先遍历的方式,记录类型为函数的节点信息,将其整理为最终的脚本引擎API 列表,使用提取出的API 列表可以获得所有动态内置对象。接下来,针对提取出的所有内置对象,提取对应的数据结构特征。
4.2.2 获取内置对象内存地址
为了获得内置对象内存地址,需要使用脚本引擎API 创建和访问内置对象。通过在脚本引擎API执行前后插入检查点,结合动态插装技术来获得内置对象内存地址。我们以图5 中伪代码为例,说明如何获得内置对象内存地址。
为了获取对象内存地址,我们生成脚本引擎API 调用语句创建和访问内置对象,对应图5 中②④,同时在每条脚本引擎API 调用语句前后设置检查点,对应图5 中①③⑤行。使用微软提供的动态调试工具Windbg 可以在检查点判断上一条API 调用语句返回值的类型,根据返回值的类型可以获取部分由API 创建的动态内置对象内存地址。除此之外,还可以依据脚本引擎活跃对象集合状态的变化获取内置对象内存地址。当创建新内置对象时,活跃对象集合将相应地增加新元素,通过分析活跃对象集合的变化可以获取内置对象内存地址。
4.2.3 识别内存单元类型
在获取了内置对象内存地址后,需要识别内存单元类型,具体为从对象内存地址出发,识别其对应内存区域中内存单元数据的类型。接下来,我们将结合图6 阐述识别内存单元数据类型的具体流程。
为了提取对象数据结构特征,需要将内存单元识别为指针类型,可变数值类型或固定数值类型。进一步,依据指针类型内存单元的指向关系,识别出层级结构特征,并组合各个层级形成对象数据结构特征。我们使用进程的内存布局信息作为先验知识来初步区分指针类型或数值类型。在Windows 系统中程序的内存布局可大致分为代码段,数据段,栈以及堆。对于指针类型的内存单元,其存储数值对应的内存地址位于堆中。通过获取进程运行时内存布局信息,得到堆起始和终止内存地址,并依据内存单元中数据数值是否位于堆范围来初步区分指针类型与数值类型(超出堆范围的数据可判定为数值类型)。使用进程的内存布局信息能识别大约90%的内存单元类型,但仍有10%的数据因数值特殊而无法区分,如数值类型中存在位于堆的范围的特殊值。此类数据对应的内存单元(后续称为待定数值单元)将进一步进行内存单元的类型识别。
我们发现开启地址随机化之后,在多次测试中,待定数值单元中的数值每次均位于堆范围内的概率较小。因此,可以进行多次独立测试,并统计待定数值单元中数值位于堆范围的次数,来判断该待定数值单元的类型。同时,由于固定数值类型在多次测试中将具有相同的数值,也可用该方法来区分可变数值类型与固定数值类型。从内置对象内存起始地址出发进行层级展开时,我们通过配置参数的方式设置层级的个数以及层级的大小,并通过不断实验调整配置参数,以达到最好的区分效果。最终,结合各层级中的内存单元类型可以提取出准确的内置对象数据结构特征。
在提取出内置对象数据结构特征后,需要将数据结构特征转换为数据结构特征图进行存储。在转换的过程中,我们重点关注指针类型对应的内存单元,并将其指向关系对应的内存偏移映射为数据结构特征图中的边。
4.3 生成参数类型正确的API 序列
官方文档中对于脚本引擎API 的描述通常较为粗略,如针对脚本引擎API 参数的描述中仅说明了参数的基础类型(整数类型,布尔类型,对象类型等),而没有说明参数的细粒度类型。根据统计,在Adobe Reader 内置脚本引擎中总共包含163 种不同类型的内置对象。当一个脚本引擎API 的参数为对象类型时,能接收脚本引擎中所有类型的内置对象,且不会提示类型错误。然而,当输入参数的细粒度类型与脚本引擎API 参数需求的细粒度类型不符时,API 无法正确处理所提供的参数,从而无法产生对象别名关系。我们发现当为脚本引擎API 提供正确类型的对象参数时,涉及的参数内存访问模式能够匹配对应的对象数据结构特征。
我们按照脚本引擎内置对象具体数据结构的不同,划分内置对象的细粒度类型。相较于粗粒度类型,即基础类型(如对象类型,字符串类型,整型等),细粒度类型能够更全面地展现不同脚本引擎内置对象的差异。使用内置对象细粒度类型,我们可以在调用脚本引擎API 时针对性地搭配内置对象,在最大程度上保证API 调用具有合法语义,同时也减少了运行时错误的产生,间接增加了代码覆盖率。
在获得脚本引擎API 对象参数信息之后,将生成脚本引擎API 调用语句。对于API 需求的对象类型参数,我们根据参数候选集,选取类型符合的内置对象作为输入。当参数包含多个候选对象时,需分别使用不同候选对象生成对应的API 调用语句。同时,在单个测试样本的生成过程中,我们以列表的形式记录已生成的内置对象,方便后续使用。当引用新的静态内置对象或由于API 调用产生了新的动态内置对象时,需要相应地更改对象列表的内容。对于其他基础类型的API 参数(整数类型,字符串类型等),我们通过构建常量表的方式,每次采用随机策略从常量表中选择类型合适的数据填充。
4.3.1 API 参数内存访问模式
对于API 参数内存访问模式M,我们采用如下定义:
M=<函数名,参数位次,内存解引用序列>
其中函数名为具体脚本引擎API 的名称,参数位次代表参数在API 调用时对应的序号,而内存解引用序列为该参数被使用时,按照层级的访问顺序,依次对应层级跳转时的内存偏移。
以Collab 内置对象下属getInitiatorSource方法为例,该方法在使用时需要两个 Stream 类型或类Stream 类型的参数,而官方文档中仅说明了两个参数为基础对象类型。对于Collab.getInitiatorSource 方法中参数的内存访问模式和对应的对象数据结构特征,我们总结如图7 所示。以Collab.getInitiatorSource的第二个参数为例,提取出的内存访问模式可表示为
在图7左侧标号①②的语句为具体脚本引擎API,在语句①中通过API Collab.newWrStream ToCosObj创建了FileStream 类型的内置对象ObjA,并作为语句②中API 的第二个参数使用。图7左侧下半部分为API Collab.getInitiatorSource 对应函数体的伪代码,函数体中的*号代表指针解引用操作,即读取指针指向内存单元中的数据。在脚本引擎 API Collab.getInitiatorSource 对应的函数体中,首先对第二个参数进行了指针解引用操作,并将读取的值存储于变量v1中,其内存访问模式偏移为0x0(下划线部分)。之后,通过将变量v1传给函数G,并将函数的返回值赋值给变量v2。函数G 针对传入的参数再次进行了指针解引用操作,此时的内存访问模式偏移为0x4(下划线部分)。据此,可以发现Collab.getInitiatorSource 对应的函数F 中对第二个参数进行了两次指针解引用操作,对应的内存访问模式偏移分别为0x0以及0x4。
在图7 右侧为FileStream类型内置对象的部分数据结构特征,其中存在0x0 和0x4 的特征信息(虚线框部分,分别为第二层级到第三层级,以及第三层级到第四层级对应的内存偏移),与Collab.getInitiatorSource 函数第二个参数的内存访问模式相匹配。同时,不同内置对象的数据结构特征拥有不同的内存偏移信息,而不同脚本引擎API 中对象参数的内存访问模式也不同。因此,可以通过匹配脚本引擎API 对象参数的内存访问模式与内置对象内存结构特征,推断脚本引擎API 对象参数的候选列表。
对于两个不同类型的内置对象,其数据结构特征中包含的偏移信息分别为(0x1,0x2,0x4)以及(0x1,0x2,0x6,0x8),而脚本引擎API对象参数内存访问模式对应的偏移为(0x1,0x2),则该脚本引擎API 参数候选集将同时包含上述两种内置对象。精确的静态分析技术需要考虑多种因素,如控制流信息,数据依赖等,针对大型脚本引擎存在性能开销过大的问题。我们的目标在于尽可能地缩小测试样本生成时API 的搜索空间,因此我们提出了一种上下文不敏感,路径不敏感,流不敏感的过程间数据流分析方法,用于提取API 对象参数的内存访问模式。基于内存访问模式,可以获得参数类型的候选列表,即正确参数类型的超集。该方法在缩小脚本引擎API 参数搜索空间的同时,保证覆盖正确的API 对象参数类型,减少参数类型错误导致的运行时异常。接下来,我们将介绍如何提取脚本引擎API 对象参数的内存访问模式。
4.3.2 提取API 参数内存访问模式
不同于已有的基于控制流图或程序调用图的静态分析技术,我们将重心放在提取脚本引擎API 对象参数的内存访问模式,主要关注API 实现体中与对象类型参数相关的处理逻辑。
我们的分析方法为上下文不敏感以及路径不敏感,因此我们不关注API 实现体中的分支或循环等语句的控制条件,粗粒度地认为API 实现体中每一条语句均有被执行的可能。基于数据流分析的思路,我们认为API 实现体中涉及对象参数的语句均为分析目标。我们提出的分析方法为过程间的数据流分析,因此遇到函数调用时,需要展开函数调用,嵌套分析函数调用内部的处理逻辑。在汇编语言中,函数调用又可细分为直接函数调用以及间接函数调用。直接函数调用以函数名为句柄调用函数,能在静态分析时直接展开;间接函数调用通过函数表的方式进行函数调用,仅能在动态执行时展开。接下来,以图8 的一段函数实现体为例,具体介绍所使用的静态分析方法。
在图8 中,脚本引擎API 对应的实现体F,其使用两个参数分别用arg1和arg2表示,其中arg1和arg2对应的参数类型为对象。为了获取参数的内存访问模式,需要跟踪函数实现体中arg1参数的使用。在函数实现体F 中,arg1被作为另一函数G 的参数使用,因而需要进一步展开函数G 以分析函数G 中参数arg1的使用情况。此处,函数G 表现为直接函数调用,可以直接展开获得具体函数实现。对于间接调用的情况,由于无法获取具体函数实现,我们将在稍后进行说明。
在函数G 中针对arg1进行了两次指针解引用操作,并最终返回指针解引用的结果。两次指针解引用分别对应的固定偏移值为0x4 和0x8。因此,我们将偏移值0x4 和0x8 作为函数G 中arg1参数的内存访问模式,记为
在函数P 的实现体中,Indirect-Call 代表间接函数调用,其将arg1作为参数使用,并将函数调用的返回值赋值给了变量b,后续变量b作为直接函数调用Q 的参数使用。对于图9 中的间接函数调用,由于无法获得具体函数实现体进行参数分析,我们粗粒度地认为变量b等同于参数arg1,即变量b提取出的内存访问模式也作为参数arg1的内存访问模式。进一步,通过分析直接函数调用Q的实现体,可以提取出函数Q 中参数arg1对应的内存访问模式,记为
使用静态分析的方式结合所有脚本引擎API 的实现体,可以提取出对象类型参数的内存访问模式。进一步,将内存访问模式与对象数据结构信息匹配,获得脚本引擎API 参数的细粒度信息。由于使用粗粒度的提取方式,最终提取结果为正确参数类型的超集,如针对Collab.getInitiatorSource 这一API,其正确参数类型为FileStream 类型,而提取出的参数候选集中包含 FileStream 类型,Stream 类型以及ReadStream 类型。除此之外,可以用同样的方法提取脚本引擎API 返回值的内存访问模式,并采用同样的方式进行存储(对于API 返回值不像参数一样区分序号,将统一用R 代替,如
4.4 识别对象别名关系
我们将3.3 中生成的测试样本输入脚本引擎,动态识别测试样本运行过程中的内置对象别名关系。由于内置对象别名关系的本质在于不同对象内部的共享内存单元,相较于已有别名关系识别方法,我们将内置对象数据结构特征转化为对应的数据结构特征图,根据数据结构特征图状态的变化来高效准确地识别内置对象别名关系。
在该节中,我们着重表述如何依据数据结构特征图识别内置对象别名关系。首先,对于脚本引擎中的每个内置对象,按照3.2 节中描述的方法,获取对应的数据结构特征图。当出现对象别名关系时,不同对象对应的数据结构特征图之间将出现新的连通节点,对应别名关系中的共享内存单元。接下来,依据建立对象别名关系前后,对象数据结构特征图的变化来具体说明如何识别对象别名关系。以Stream 类型和ReadStream 类型的内置对象为例,在建立别名关系之前,其数据结构特征图如图10 所示。
在图10 中左半部分Obj1_Id 标识的数据结构特征图代表Stream 类型的内置对象,右半部分Obj2_Id标识的数据结构特征图代表ReadStream 类型的内置对象,Obj1_Id 以及Obj2_Id 分别为内置对象运行时的内存地址。由于执行脚本引擎API 引起了内置对象的变化,需要重新计算内置对象对应的数据结构特征图。当执行完某条脚本引擎API 之后,Stream 对象和ReadStream 对应数据结构特征图的变化如图11所示。
在图11 中用我们虚线框代表别名关系对应的节点,即别名关系对应的共享内存单元。我们采用图12 中描述的算法,通过对比脚本引擎API 执行前后对象数据结构特征图的状态变化,识别内置对象别名关系。
我们设置监控粒度为单条脚本语句,如图12 所示,首先我们初始化最终输出的别名关系内置对象集合R为空集。在执行脚本引擎API 前,之后,依据内置对象内存地址集合S,计算对应的对象数据结构特征图集GA(对应算法中步骤2,3,4)。当执行完某条脚本语句后,再次计算内置对象数据结构特征图集,记为GB。最后,以对象内存地址为索引,对比先后两次生成的对象数据结构特征图,根据数据结构特征图的变化来识别内置对象别名关系。
当建立内置对象别名关系时,共享内存单元对应的数据结构特征图节点(图11 中虚线框节点)的祖先属性将发生变化。因为共享节点可以归属于不同内置对象,所以该节点的祖先属性将增多(对应图12中步骤11)。我们依据脚本引擎API 执行前后是否存在数据结构特征图节点的祖先属性符合上述变化,来判断是否建立了内置对象别名关系。
通常,在单个测试样本中,涉及的脚本引擎内置对象数量较少,因此每次重新计算数据结构特征图的性能开销较小。相比于已有的别名关系识别方法,我们提出的基于数据结构特征的方法具有更高的识别效率。
5 利用别名关系检测释放后使用漏洞
内置对象别名关系有助于检测与对象内存操作相关的程序漏洞。通过建立内置对象别名关系,并搭配合适的脚本引擎API 释放内置对象,可以在多个对象内部引入悬挂指针,进而触发释放后使用漏洞。该部分具体分为三个部分进行介绍,分别为释放后使用漏洞的检测流程,提取特殊API 序列以及生成测试样本检测释放后使用漏洞。
5.1 释放后使用漏洞的检测流程
在释放后使用漏洞中,根本原因是访问了被释放内存区域,从而触发程序错误。对于释放后使用漏洞,必不可少的环节为释放对象产生悬挂指针以及访问悬挂指针。同时,必须遵循释放操作在前,使用操作在后的原则,否则无法触发释放后使用漏洞。因此,需要针对内置对象提取释放API 序列以及使用API 序列,并基于提取的API 序列生成测试样本以检测释放后使用漏洞,整个系统的具体检测流程如图13 所示。
整个检测流程按从左到右的顺序执行,核心在于利用内置对象别名关系。为了提取释放对象API序列以及使用对象API 序列,需要使用不同的判断逻辑。进一步,利用提取出的释放序列和使用序列生成测试样本以检测脚本引擎中的程序漏洞。
对于建立的别名关系的两个内置对象(记为内置对象A以及内置对象B),分别获取API 测试样本运行时的对象内存地址。进一步,依据对象内存地址以及对象数据结构特征,获取别名内存单元对应的内存地址,又称为别名地址。我依据API 测试样本运行时是否满足设定的内置对象释放条件来提取释放对象API 序列(具体条件在4.2 节中进行描述)。在提取使用对象API 序列时,我们针对别名地址设置内存访问断点。通过监控测试样本运行过程中内存断点的触发情况,获取使用对象API 序列。
最后,需要按照一定模式组合释放对象API 序列和使用对象API序列,并在释放对象API序列执行前建立内置对象别名关系,以检测脚本引擎中的释放后使用漏洞。
5.2 提取特殊API 序列
在本节中,我们主要叙述如何提取释放对象API 序列以及使用对象API 序列,提取过程对应的具体流程如图14 所示。我们首先使用动态插装技术获得内置对象内存地址,之后结合建立的对象别名关系获得别名单元的内存地址。根据测试样本运行过程中,别名单元内存地址是否满足特定释放/使用模式,提取对应的释放/使用API 序列。
5.2.1 提取释放API 序列
首先介绍释放对象API 序列的提取,我们着重关注对象内部共享内存区域的释放情况,通过判定对象内部共享内存区域是否被释放,来提取释放对象API 序列。我们具体使用3 种检查策略来判定共享内存区域是否被释放,分别为判定别名区域中数据的状态,判定内置对象存活性以及判定系统释放函数是否触发。
我们将根据3.2 节中提取的API 参数信息,随机生成API 调用序列。通过归纳已知释放对象API 序列的特征,在填充API 参数时,尽量选择空值作为参数,如长度为0 的字符串,数字0 等。除此之外,还可以利用脚本引擎垃圾回收机制释放内置对象。通过消除内置对象的引用或引入临时变量的方式可以影响对象生命周期,如将指向内置对象的变量指向空对象,或不使用变量存储API 返回值,进而触发脚本引擎垃圾回收机制释放内置对象。
在第一种检查策略中,我们根据别名区域中数据的状态来判定对象是否被释放。当内置对象被系统回收时,对象内存区域中的数据被填充为特殊值,该特殊值可通过简单人工分析获得。根据别名地址中的数据是否等于该特殊值,可以判断别名区域是否被释放,进而判定API 序列是否触发了释放行为。
第二种检查策略直接判断内置对象存活性。在第2章中我们介绍了活跃对象集合的概念,通过检查内置对象是否从活跃对象集合消失来判定API 序列是否触发了释放行为。
第三种检查策略为监控系统释放函数。脚本引擎本质为操作系统中的进程,一切内存操作均需调用操作系统的底层函数,即使用API 创建和释放内置对象的同时,也调用了操作系统的创建及释放函数。对于操作系统底层的释放函数,其参数为需要释放的内存地址。可以通过监控底层释放函数的调用,判断参数值是否等于对象别名单元内存地址,决定当前API 序列是否触发了释放行为。
在提取释放对象API 序列的过程中,我们依旧选择单个脚本引擎API 作为插装粒度,并在单条API调用语句前后加入检查点。每当遭遇检查点时,需要实施上述三种检查策略,判断当前情景下是否发生了内置对象释放行为。同时,可以在单个测试样本中同时监控多个存在别名关系的内置对象,提高测试效率。
5.2.2 提取使用API 序列
在提取使用对象API 序列时,无需关注对象的状态,即对象存活与否与是否能访问别名区域中的数据无直接关系。虽然,正常的使用规范要求对象被释放后无法访问对象内部数据。但是,当内置对象被释放后仍能成功访问其内部数据,说明该内置对象未设置相应的释放标志位,因此更容易产生悬挂指针。综上,在提取使用对象API 序列时,仅关心对象内部的别名区域是否能被成功访问。
接下来介绍如何提取使用API 序列。为了提取使用API 序列,在生成API 测试样本时,将待测内置对象作为API 参数使用以满足内置对象访问条件。我们利用Windbg 调试工具提供的内存读写监控功能来判断当前API 序列是否能够访问特定内置对象。通过将内置对象内部别名单元内存地址设置为读断点,依据API 测试样本运行过程中是否触发了读断点,提取对应的使用API 序列。我们针对每一对存在别名关系的内置对象,分别提取对应的使用API 序列。
5.3 生成测试样本检测释放后使用漏洞
为了检测脚本引擎中的释放后使用漏洞,需要构造特殊的脚本引擎API 调用序列以满足释放后使用漏洞的模式,对应到脚本引擎中为先调用释放对象API 序列,后调用使用对象API 序列。由于单悬挂指针导致的释放后使用漏洞容易被修补,需要引入内置对象别名关系以创建多悬挂指针,具体的测试样本生成策略如图15 所示。
对于存在别名关系的内置对象(记为对象A以及对象B),我们分别搭配对应的释放API 序列集合以及使用API序列集合,如图15中对象A搭配释放API序列集合,对象B搭配使用API 序列集合。按照第2章中介绍的别名关系释放后使用漏洞触发模式,我们选取释放API 序列集合和使用API 序列集合中的元素进行组合,并遵循释放在前使用在后的顺序,生成不同测试样本。同时,在执行释放API 序列之前需要先建立内置对象别名关系。
在实验中我们发现,为了提高内置对象间别名关系的出现概率,需要脚本引擎API 间需要具有较强的关联性。通过提取API 参数和返回值的内存访问模式,可分别获得参数以及返回值的候选对象列表,记为Param_Set 以及Return_Set,而不同脚本引擎API 之间Param_Set 和Return_Set 存在交集。在生成具体测试样本时,我们考虑将脚本引擎API 的返回值作为另一API 的参数,以增加API 之间的关联性。同时,为了保证合理语义,如API-1 的Param_Set与API-2的Return_Set存在交集,在生成测试样本时,将优先调用API-2 创建内置对象,再将API-2 的返回值作为API-1 的参数。最后,将产生的测试样本输入脚本引擎,以检测脚本引擎中的释放后使用漏洞。
6 实验结果评估
本章中,我们针对论文中提出的内置对象别名关系识别方法设计多项评估实验,分别从别名关系准确率,测试样本生成效率以及别名关系识别开销三个方面进行评估。同时,对于提出的释放后使用漏洞检测方法,我们在真实软件Adobe Reader 内嵌JavaScript 引擎上实施了漏洞检测实验,评估该方法检测释放后使用漏洞的性能,验证该方法的有效性和可用性。
6.1 别名关系准确率
论文的一个核心点在于利用对象数据结构特征建立并识别内置对象别名关系,因此需要评估内置对象别名关系的准确性。
为了评估测试样本中内置对象别名关系是否准确,我们生成了长度相同的测试样本,分批识别其中的内置对象别名关系。对于每个待测样本,依据提取出的脚本引擎API 参数类型信息,生成100 条脚本引擎API 调用语句,并动态监测样本运行过程中是否建立了内置对象间别名关系。最终,我们统计了100 个测试样本的运行结果,总计包含18354 条别名关系记录,平均每个测试样本包含183 条别名关系,平均每条脚本引擎API 生成了1.8 个内置对象别名关系。通过对18354 条别名关系记录进行去重,我们最终提取出284 条不同的内置对象别名关系,共涉及27 个不同类型的内置对象,占动态内置对象比例的51%。
我们采用图16 中的模式来评估内置对象别名关系识别的准确性。针对一组待验证别名关系的内置对象,变更其中一个内置对象的状态,如改变对象属性值等,并监控另一内置对象的变化。依据待验证别名关系的内置对象状态是否同步变化,来判定内置对象别名关系是否准确。
存在别名关系的两个内置对象分别记为ObjA和ObjB,并将ObjA对象与ObjB对象最终存在别名关系的内存单元抽象为ObjA.X.Y以及ObjB.E.F(对应图16 中共享内存单元M)。初始时,共享内存单元M中存储的数值为1。我们使用脚本引擎API 对ObjA.X.Y进行赋值操作,更改M中的数值为2。之后,通过ObjB.E.F读取M中存储的数值,并判断读取的数值是否等于更改后的数值。当读取的数值为1 时,我们认为识别ObjA对象和ObjB对象间别名关系时产生了误报;当读取的数值为2 时,我们认为对象别名关系识别正确。我们采用如上方式对提取出的284 条内置对象别名关系进行了评估,并人工审查了评估结果。最终,我们证明了提取出的284 条内置对象别名关系真实存在,即提出的内置对象别名关系识别方法没有产生误报。
同样,我们采用图16中的模式来评估文中提出的别名关系识别方法是否存在漏报现象。我们将测试范围设置为全体内置对象,即脚本引擎中存活的所有静态内置对象以及动态内置对象。通过运行测试脚本代码,并统计不同状态下脚本引擎中存在的所有内置对象别名关系,以此作为对比的标准。在实验过程中,针对全体内置对象别名关系进行多次统计,排除内置对象随机初始化数值引发的干扰。在统计多次实验结果后,平均每个测试样本中包含总计196条内置对象别名关系,使用论文中的别名关系识别方法能识别出183条内置对象别名关系,最终漏报率约6.6%。
进一步,我们将本文中提出的别名关系识别方法与现有研究中的别名关系识别方法进行对比,比较不同方法在识别脚本引擎内置对象别名关系时的性能差异。我们选用Pintool 工具[31]实现现有研究中的别名关系识别方法[32],核心思想为监测程序运行过程中的内存读写操作。当监测到内存写指令涉及的不同操作数分别属于不同内置对象时,认为出现了内置对象别名关系。在保持测试样本一致的前提下,我们分别统计了相同时间内,不同别名关系识别方法的相关指标,包括别名关系数量、误报率及漏报率,同时将测试样本中别名关系总数作为对照标准,最终统计结果如表2 所示。
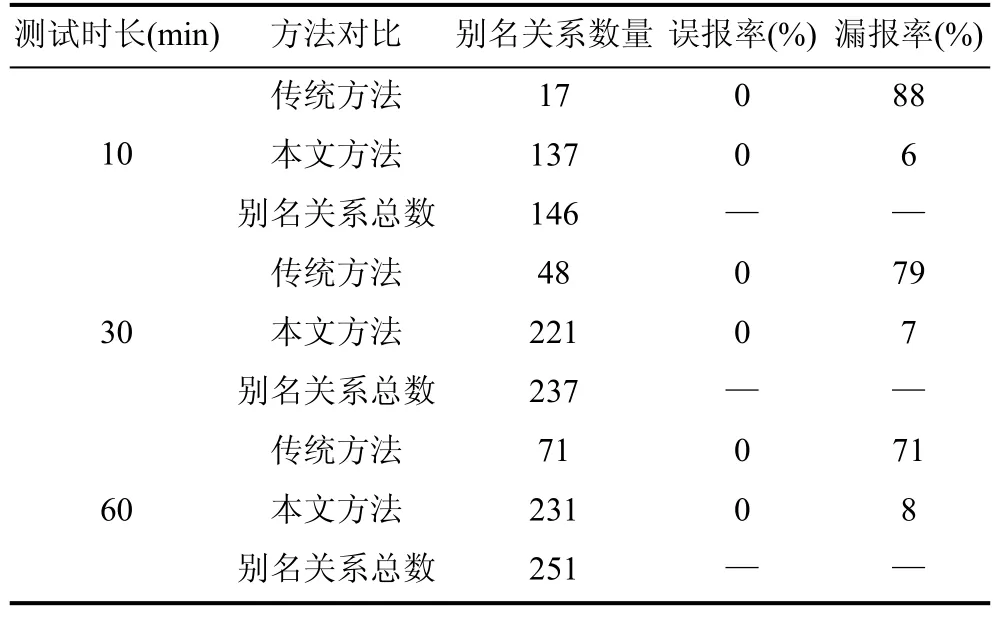
表2 别名关系识别方法对比Table 2 Comparison of different alias relationship recognition method
从结果中可见,在测试时长为10 min 时,使用传统别名关系识别方法,总共识别出17 组内置对象别名关系,漏报率为88%,而使用论文中提出的基于数据结构特征的别名关系识别方法能够识别出137组别名关系,漏报率为6%,明显优于传统方法。同样,我们分别测试了30 min 以及60 min 条件下,不同别名关系识别方法所能识别出的别名关系数量,最终证明了论文中的别名关系识别方法相较于传统方法有较大优势。
6.2 测试样本生成效率
本节中,我们主要评估使用对象数据结构特征对于生成测试样本的影响。当脚本引擎API 参数为对象类型,生成测试样本时搜索空间的大小与API参数候选集的大小成正比。在不提取细粒度参数类型的情况下,API 参数候选集的大小等于脚本引擎中所有内置对象的个数。依据统计结果,平均一个脚本引擎API 需要3 个对象参数,而脚本引擎中共包含237 个API 以及163 种内置对象,则生成测试样本时最终搜索空间大小为237*163*163*163。我们通过实验发现,不同脚本引擎API 需要不同细粒度类型的内置对象作为参数,而传递其余类型的内置对象将引发运行时错误。通过提取脚本引擎API 参数的内存访问模式,结合内置对象数据结构特征,缩小了脚本引擎API 对象参数的候选集大小。
我们分析并提取了每个脚本引擎API 的细粒度参数信息,最终确定了每个脚本引擎API 中对象参数的候选集大小,最终的统计结果如图17 所示。根据图17 中的统计结果可以发现,约80%脚本引擎API 的参数候选集的大小不超过6。通过提取脚本引擎API 细粒度参数信息,能明显优化生成测试样本时的搜索空间,大幅减少待测样本个数(从237*163*163*163 缩小为237*6*6*6),提高了测试效率。
除此之外,提取脚本引擎API 细粒度参数信息对于减少运行时错误有明显助益。我们分别在使用API 细粒度参数信息与不使用的情况下,生成相同数量的测试样本,并统计测试样本运行过程中产生的运行时错误。通过对比运行时错误数量,评估脚本引擎API 细粒度参数信息对于减少运行时错误的效果,具体统计结果如表3 中所示。

表3 运行时错误数量Table 3 Number of runtime errors
在表3 中,我们分别生成了100 个,200 个,300个以及400 个测试样本,并统计产生运行时错误的样本数量。在使用API 参数细粒度信息时,存在运行时错误的样本数量分别为17 个,32 个,46 个以及57个,而在不使用API 细粒度参数信息时,运行时错误的数量分别为73 个,153 个,231 个以及316 个。可以发现,使用API 细粒度类型信息生成的测试样本中,包含的运行时错误数量明显少于不使用细粒度参数信息。因此,可以证明提取脚本引擎API 细粒度信息对于减少运行时错误,提高测试样本质量有明显帮助。
6.3 别名关系识别开销
为了评估论文中别名关系识别方法的高效性,即相较于已有别名关系识别方法,我们提出的别名关系识别方法具有较短的检测时长。我们生成了包含随机数量脚本语言代码的测试样本,统计了测试样本在不识别别名关系,使用传统别名识别方法以及基于对象数据结构特征识别别名关系三种场景下的运行时长,取单条脚本语言代码平均运行时长作为性能评估的依据。
传统别名关系识别通过监控内存数据的方式进行实现,具体为监控程序运行过程中的内存读写指令,根据读写指令涉及的操作数来识别对象别名关系。内存读指令用于标明操作数与对象的从属关系,内存写指令用于判断对象别名关系。当内存写指令涉及的两个操作数分别来自不同对象时,认为检测到对象别名关系。我们总计测试了100 组数据,结果如图18 所示。
在图18 中,运行耗时以秒为单位。在不识别内置对象别名关系时,单条脚本语言代码的平均运行时长约为1 s。使用传统别名识别方法时,单条脚本语言代码的平均运行时长为269 s,相比于不识别别名关系,其运行耗时明显增加。采用我们提出的基于对象数据结构特征的别名关系识别方法,单条脚本语言代码的平均运行时长为13 s。虽然相比于不进行别名分析运行时长有所上升,但额外提取了内置对象别名关系,且性能开销仍在可接受范围。同时,相比于传统别名关系识别方法能显著缩短运行时长。因此,我们提出的基于对象数据结构特征的别名关系识别方法,能快速检测脚本引擎内置对象别名关系,提升了别名关系识别效率。
6.4 别名关系识别方案的通用性
在软件内嵌脚本引擎中,为了方便用户,定义了不同结构的内置对象与不同功能的脚本引擎API,搭配使用脚本引擎API 与内置对象可实现多种复杂功能。根据我们的调查结果,脚本引擎中的安全漏洞常与内置对象紧密相关,究其原因在于内置对象的内部结构复杂,且可通过脚本引擎API 建立深层次联系,使得管理和维护内置对象具有较大难度。在本文中,为了检测脚本引擎中的深层次安全漏洞,我们将重心放在识别内置对象别名关系。进一步,为了证明论文中别名关系识别方法的通用性,我们设计了如下实验。
在软件内嵌脚本引擎中,除了具有特殊结构的内置对象,还存在用户自定义对象,即由用户自定义对象内部结构及属性。我们采用包含自定义对象的数据集,并使用论文中方法识别内置对象别名关系。进一步,使用6.1 节中描述的方法来验证别名关系的准确性,最终实验结果如表4 所示。
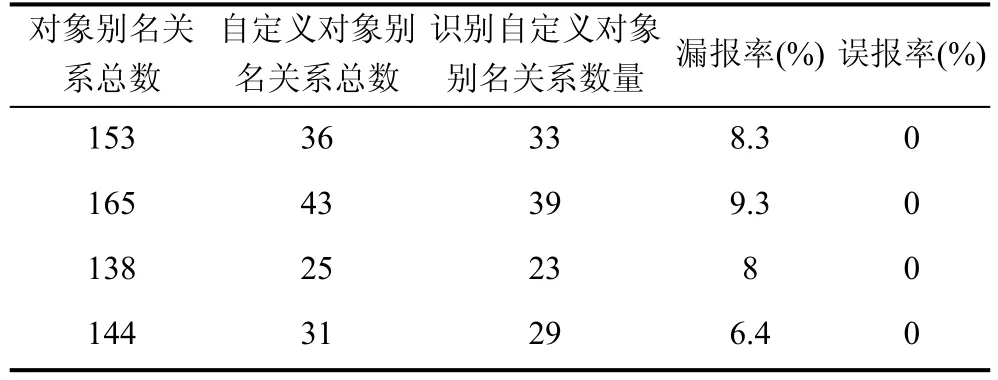
表4 自定义对象别名关系识别统计表Table 4 Statistics of custom object alias relationship
如表4 所示,在所使用的数据集中,总共包含对象别名关系153,165,138 以及144 组,其中自定义对象别名关系总数为36,43,25 以及31 组,而使用论文中的方法共能识别出自定义对象别名关系33,39,23以及29。进一步我们计算了自定义对象别名关系识别的漏报率以及误报率,其中误报率采用6.1 节中方法计算,最终证明无误报现象,而漏报率分别为8.3%,9.3%,8%以及6.4%,证明了论文中方法能以较高效率识别自定义对象别名关系,从而证明方法的通用性。
6.5 释放后使用漏洞检测结果
在本节中,我们以发现的未知释放后使用漏洞为例,介绍具体的检测思路。首先是漏洞编号“CVE-2020-3745”的释放后使用漏洞,具体漏洞代码如图19 所示。
通过调用脚本引擎API util.streamFromString 创建了Stream 类型的内置对象,记为ObjA对象,对应图19 中第①行。在图19 第②行中,调用了脚本引擎API Collab.drivers.getInitiatorSource 并将ObjA对象作为参数,创建了ReadStream 类型的内置对象,记为ObjB。同时,该API 也建立了ObjA对象和ObjB对象间的别名关系。之后,通过调用API this.reset-Form 释放了ObjB对象。由于ObjA对象和ObjB对象存在别名关系,导致ObjA对象内部出现了悬挂指针。在图19 第④行中,通过API util.stringFrom-Stream 访问了ObjA对象内部的悬挂指针,触发了释放后使用漏洞。我们将上述漏洞的触发模式总结为图20。
通过使用论文中提出的方法,总计检测出4 个未知的释放后使用漏洞,现将每个未知释放后使用漏洞对应的漏洞编号,及其涉及的具体脚本引擎内置对象信息总结如表5 所示。

表5 检测出的释放后使用漏洞列表Table 5 List of detected UAF vulnerabilities
7 总结与展望
在脚本引擎漏洞挖掘领域,利用模糊测试来检测漏洞的方法已经被证明有效,但现有的模糊测试方法主要关注如何生成符合脚本语言语法规范的测试样本,未能很好地利用脚本引擎API 以及内置对象,在挖掘脚本引擎深层次漏洞方面未能取得较好的效果。
针对上述局限性,本研究提出了一种基于数据结构特征的脚本引擎内置对象别名关系识别技术,通过快速识别内置对象别名关系来辅助检测释放后使用漏洞。与传统脚本引擎漏洞检测方案不同,我们重点关注脚本引擎中的特殊API 及内置对象,采取自动化的方式提取内置对象数据结构特征,并基于提取出的对象特征识别脚本引擎API 细粒度参数信息。进一步,搭配合理API 参数,我们可以生成高质量的测试样本,提高内置对象别名关系的出现概率。同时,我们利用对象数据结构特征快速准确地识别内置对象别名关系,大幅缩短了现有别名分析技术所需时间。最后,利用识别的内置对象别名关系,搭配特定API 序列有针对性地释放和使用内置对象,构造性地检测脚本引擎中的释放后使用漏洞。最终,我们提取出284 组内置对象别名关系,并据此检测出4 个未知的释放后使用漏洞。
诚然,本方法也存在诸多不足和需要继续改进的地方。首先,在提取脚本引擎API 细粒度参数信息时,现有的静态分析方法在处理间接函数调用时粒度较粗,提取的参数信息不够精确,后续可针对识别精度进行改进,进一步缩小脚本引擎API 参数候选集的大小,实现精确的API 参数细粒度类型识别。
其次,生成测试样本时,对于如何填充脚本引擎API 的参数考虑不足,如针对基础类型只是简单地选取随机常量值,对象类型仅考虑了参数候选集中的元素。在后续工作中,可以更深入地探究脚本引擎API的执行逻辑,探究参数对于API执行轨迹的影响,从而更针对性地提供API 所需参数。除此之外,使用内置对象别名关系检测释放后使用漏洞时,提取的内置对象别名关系数量及释放API 序列数量较少。对于这一问题,可以通过加强脚本引擎API 的关联性,以及改进监控策略,来发现更多的释放API 序列。
最后,本工作未在JavaScript 以外的脚本引擎中进行实验,后续考虑将实验移植到JavaScript 语言以外的脚本引擎中,进一步证明方法的通用性。在其他脚本引擎中,可通过分析对象内部结构,来识别对象内部别名关系,进而检测安全漏洞。
猜你喜欢
课程教育研究(2021年23期)2021-04-13
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
中国信息技术教育(2020年22期)2020-12-08
电脑爱好者(2018年6期)2018-04-23
军事文摘·科学少年(2016年10期)2016-12-08
意林小文学(2016年6期)2016-04-11
作文与考试·小学低年级版(2014年9期)2014-12-02
现代计算机(2009年2期)2009-12-11
作文与考试·小学高年级版(2009年2期)2009-01-17
计算机教育(2006年2期)2006-02-23
