
基于特征图分块偏移的二值化卷积神经网络*
2022-08-23 01:52张邦源
通信技术 2022年7期
张邦源,沈 韬,曾 凯
(昆明理工大学,云南 昆明 650500)
0 引言
随着深度学习[1]的不断发展,卷积神经网络(Convolutional Neural Network,CNN)在计算机视觉、自然语言处理、语音识别等领域都取得了显著进展,并且CNN 已被证明在图像分类[2-6]、目标检测[7-10]和语义分割[11-13]等领域是可靠的,因此在实践中得到了广泛的应用。
为了追求更高的精度,近年来,CNN 模型的计算规模变得更加庞大,网络结构更加复杂、不规则且参数量巨大,对运算平台的存储容量和计算能力也提出了较高的要求,这就限制了CNN 等算法在功耗和性能受限的嵌入式平台上的发展。
因此,很多研究人员开始提出各种模型压缩算法和技术,即容忍一定的精度下降,来降低CNN的运算强度和模型参数量。其中,量化模型由于在硬件上移植会非常方便,因此神经网络模型的量化是一项有效的解决方案。神经网络二值化能够最大限度地降低模型的存储占用和模型的计算量,将神经网络中原本32 位浮点数参数量化至1 位定点数,降低了模型部署的存储资源消耗,同时极大加速了神经网络的推断过程。二值化神经网络(Binarized Neural Network,BNN)由于可以实现极高的压缩比和加速效果,所以它是推动以深度神经网络为代表的人工智能模型,在资源受限和功耗受限的移动端设备和嵌入式设备上落地应用的一种非常有潜力的技术。
二值化神经网络最初源于Courbariaux 的BinaryNet[14],在近几年的发展中,各种二值化的优化方法被不断提出,如XNOR-Net[15]、BNN+[16]、BinaryDenseNet[17]、Bi-Real Net[18]、MeliusNet[19]、IRNet[20]、ReActNet[21]等。
二值化神经网络的提出是为了解决现阶段神经网络存在的浮点运算冗余、运算速度低、对硬件设备内存占用过高的问题。研究者期望无须借助片外存储设备,通过二值化处理就可以将神经网络模型应用在资源受限的硬件设备上,从而提高网络模型计算的实时性。事实上,早在20 世纪50 年代,研究者提出的人工神经网络模型就是一种二值神经网络,但是二值神经网络一直受困于缺乏有效的反向传播算法。相比之下,全精度神经网络因为有精确的梯度下降算法,可以很好地完成深度神经网络的学习,从而取代二值化神经网络成为神经网络研究中的主流。
直到2015 年,Courbariaux 等人[22]提出的BinaryConnect,第一次把全精度网络中的权重进行1 bit 量化,这为二值化卷积神经网络的诞生打下了基础。Courbariaux 等人[14]在另一篇文章中进一步介绍了BNN,在BinaryConnect 中只将权重量化到了1 bit,而BNN 进一步将激活值也变成1 bit,既减少了内存消耗,也将许多乘加操作简化成了按位操作XNOR-Count。以上二值化方法具有节省计算资源的优点,因为它们以非常简单的方式量化网络。但是,由于不考虑二值化在前向和反向过程中的影响,这些方法不可避免地会在很多任务中造成精度损失。
近年来,研究人员从不同方向入手,对二值化卷积神经网络进行优化,使其得到了较大发展。考虑到权重二值量化的误差,Rastegari 等人[15]提出了XNOR-Net,引入尺度因子缩小二值化的权重与全精度权重的误差,并将网络中第一层和最后一层保留为全精度权重,同时改变网络中的卷积层和批归一化(Batch Normalization,BN)层的顺序,在alexnet 上将权重量化到1 bit 时,能够达到跟浮点权重一样的性能。BinaryDenseNet、Bi-Real Net和MeliusNet 的3 篇论文[17-19]在网络结构中加入shortcut 和concat 操作,增强模型的质量和容量,从而提升性能。Qin 等人[20]提出的IR-Net 用一个自适应误差衰减估计器(Error Decay Estimator,EDE)来减少训练中的梯度误差,并用其他可微的函数来代替Sign函数,并且在训练过程中不断地逼近真正的Sign,使得整个训练过程中梯度传递得更加平滑。
虽然二值化卷积神经网络近年来得到巨大发展,但是其中依旧存在一些问题没有得到太多的关注,例如:
(1)二值化卷积神经网络中特征图的负值信息是否同样重要?在降采样层使用最大池化(MaxPooling)操作进行降采样时,只保留了池化块中的最大值,而这个值一般是大于0 的,这样就导致降采样层特征图负值信息的丢失。
(2)二值化网络中,全精度特征图在进行二值化操作时,对于分布不均的特征图,在数值较小的区域会全被二值化为-1,数值较大的区域则被二值化为+1,如此二值化后的特征图在局部将无法保留细节特征。
鉴于国内外研究中存在的问题,本文有针对性地做出了研究,主要贡献有以下3 点:
(1)提出了一种新的池化方法——最小池化(MinPooling),即在池化操作时,保留每个池化块中最小的值,并结合最大池化和最小池化设计出一种新的降采样层,有效保留了特征图中的正负值信息。
(2)提出特征图分块偏移二值化,通过改变全精度特征图的分布,使二值化卷积神经网络得到保留了细节信息的二值化特征图,提高了二值化网络的特征提取能力。
(3)为了验证二值化卷积神经网络中负值信息与正值信息拥有同样的重要性,本文进行了大量实验。实验表明,在降采样层使用最大和最小池化比仅使用最大池化或者仅使用最小池化效果更好。实验还验证了特征图分块偏移二值化对网络性能的提升。在CIFAR100 数据集上,本文提出的方法比目前所有的二值化网络提升了3.08%的准确率,与全精度网络的准确率差距仅有1.37%。通过消融实验证明,相对于基准模型,使用最大最小池化提升了2.47%的准确率,使用特征图分块偏移二值化提升了0.98%的准确率,两者同时使用提升了3.72%的准确率。
1 二值化卷积神经网络
在全精度卷积神经网络中,卷积核权重和中间层的激活值都是32 位浮点型的。二值化卷积神经网络在全精度网络的全精度卷积核的权重和激活值二值化为{+1,-1}。
在卷积神经网络的前向推理过程中,卷积运算包含了大量的浮点运算,包括浮点乘法和浮点加法。大量的浮点运算造成了卷积神经网络在前向推理过程中效率低下的问题,并且32 位浮点数权重需要占用较大的存储空间。卷积神经网络的二值化方法有以下优势:
(1)能够有效减少存储消耗。相比全精度网络的32 位浮点数权重,量化到{+1,-1}的二值化卷积神经网络在实际部署模型时,每个权重仅占用1 bit,可以达到32 倍的存储空间压缩。
(2)降低卷积计算复杂度。当权重和激活值量化为{+1,-1}时,网络中卷积层的大量浮点乘法操作可以使用位运算代替,从而能够大幅度提高计算速度,降低计算能耗,并且利于现场可编程门阵列(Field Programmable Gate Array,FPGA)等硬件的部署。
1.1 二值化函数
网络二值化的目标是通过二值化函数权值和激活值量化为{+1,-1}。二值化方法主要有确定型(Deterministic)和随机型(Stochastic)两种。其中确定型方法采用符号函数作为二值化函数,即大于等于0 时为+1,小于0 时则为-1,可以表示为:
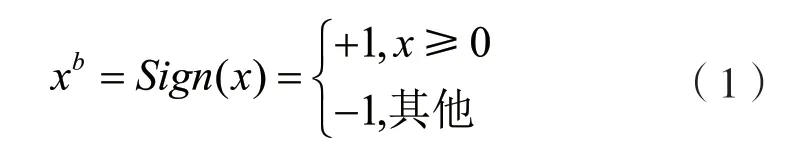
式中:x为网络模型中全精度的特征值(或权重);xb为二值化后的特征值(或权重);Sign是符号函数。
另一种方法是随机型,即以一定的概率进行二值化。随机型方法利用概率生成函数σ生成输入数据x取值的概率图,然后根据概率图决定x的量化输出,其中概率生成函数σ使用“hard sigmoid”函数,则其计算方式为:
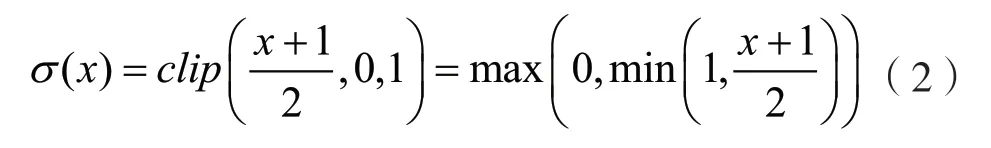
式中:x为网络模型中全精度的特征值(或权重);min 表示取最小函数;max 表示取最大函数;clip为截取函数;σ为得到的概率生成函数。
随机式二值化方法的二值化函数为:
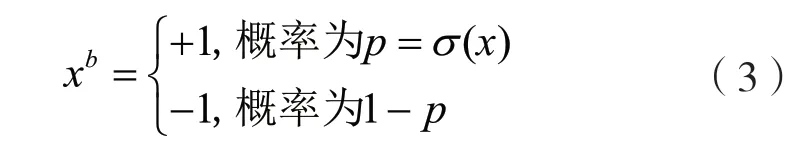
式中:x为网络模型中全精度的特征值(或权重);xb为二值化后的特征值(或权重);σ为得到的概率生成函数;p为全精度值量化为+1 的概率。
随机二值化比符号函数更具吸引力,但需要额外的计算,而且硬件难以实现,因为它需要硬件产生随机比特。相比随机式方法,确定式方法更利于硬件部署,所以本文采用确定式方法作为二值化激活方法。
1.2 二值化卷积
二值化卷积是二值化卷积神经网络的重要组成单元之一,对于一个全精度的卷积神经网络,假设其某一层的输入特征图为I,该卷积层的权重为W,二值化后得到的特征图为Ib,权重为Wb。为了近似全精度的权重,减少量化误差,XNOR-Net 提出全精度的缩放因子α,并使用二值的权重以及一个缩放因子代替全精度的权重,即W ≈αWb,则二值化的卷积为:
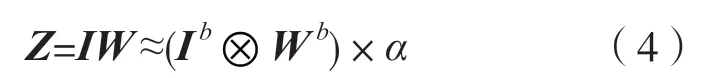
式中:Z为二值化卷积的输出特征图;⊗表示卷积运算;⊕表示没有乘法的卷积计算。
缩放因子α的计算公式为:

缩放因子的引入使二值化卷积神经网络能更接近全精度的卷积神经网络,但这样做增加了网络中的浮点运算。
1.3 二值化网络的训练
与训练全精度神经网络模型类似,在训练二值化卷积神经网络时,仍然可以直接采用基于梯度下降的反向传播(Back Propagation,BP)算法来更新参数。然而,二值化函数(如Sign函数)通常是不可微的,函数的部分导数值会消失,如Sign函数导数值几乎都为0。因此,常用的基于梯度下降的BP算法不能直接用于二进制权值的更新。
Hinton 等人[23]提出一种名为直接估计器(Straight-Through Estimator,STE)的技术,用于解决符号函数二值化训练深度网络时出现的梯度消失问题。STE 的定义如下:
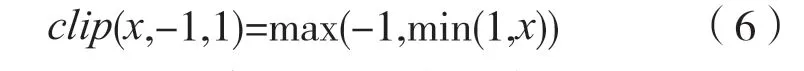
通过STE,可以使用与全精度神经网络相同的梯度下降法,直接训练二值神经网络。但由于Sign的实际梯度与STE 之间存在明显的梯度不匹配,极易导致反向传播误差积累的问题,致使网络训练偏离正常的极值点,使得二值网络优化不足,从而严重降低性能。对于近似Sign函数梯度的方波梯度,除了[-1,+1]范围之内的参数梯度不匹配外,还存在[-1,+1]范围之外的参数将不被更新的问题。精心设计的二值化近似函数可以缓解反向传播中的梯度失配问题。Bi-RealNet 提供了一个自定义的近似Sign函数ApproxSign,来替换Sign函数,进行反向传播中的梯度计算。该梯度以三角波形式近似Sign函数的梯度,拥有与冲激函数更高的相似度,因而更贴近于Sign函数梯度的计算。
2 二值化卷积神经网络的优化
本文主要研究二值化卷积神经网络在降采样层保留负值特征信息的重要性和在特征图二值化激活时特征图局部信息丢失的问题。针对第一个问题,本文提出了新的池化方法——最大最小池化(Max-MinPooling);针对第二个问题,提出了基于特征图分块偏移的二值化方法。
2.1 多分支的二值化卷积神经网络
多分支与单路二值化卷积神经网络的结构如图1 所示。

图1 多分支与单路二值化卷积神经网络
从图1 可以看出,在多分支的二值化卷积神经网络结构中,shortcut 结构在两个基本块之间传递了浮点特征信息,增加了网络的信息流,但这样的结构中,网络需要额外的空间来存储全精度的特征值。然而,在单路的结构中,网络在卷积求出浮点特征值后,可以立即进行二值化,不需要再对浮点特征值进行存储,减少了硬件的存储开销,并且在单路的二值化卷积神经网络中,可以在模型训练结束后,将BN 层以及二值激活层进行合并,从而有效简化模型,提高运算效率,具体合并方法在3.4节中详细介绍。
2.2 最大最小池化
在卷积神经网络的下采样层,图像分辨率会直接降低4 倍,这个过程中的信息损失是不可逆的,而在二值化卷积神经网络中,会存在更加严重的信息丢失。目前的二值化卷积神经网络有以下两种常用的下采样操作:
(1)最大池化作为下采样层。最大池化只取覆盖区域中的最大值,其他的值都丢弃。最大池化操作在不增加额外卷积运算和参数的前提下减小输入大小,使得神经网络能够专注于最重要的元素。在全精度的网络中,通常认为最重要的元素是最大的数,但在一个特征图中,往往会出现在一个池化块里最大数并非绝对值最大的情况。不同于全精度网络,二值化卷积神经网络中负值的特征值也是至关重要的,而最大池化却忽略了负值特征信息。
(2)使用步长为2 的卷积层来进行下采样。这种方法可以保留更多的信息。在目前的二值化卷积神经网络中,通常使用全精度的卷积来计算,避免造成较大的精度损失,但这样又带来了大量的全精度卷积运算和额外的存储空间消耗。
在二值化卷积神经网络中,特征图中的正负值是带有等量的信息的,所以不能只关注正值特征信息,而最大池化在每个池化块中只保留了最大值,池化后的结果大部分为正,主要保留了特征图中的正值信息,这样会导致大量的负值信息丢失。基于此,本文提出了一种新的池化方法——最小池化,如图2 所示,即在池化操作时,保留每个池化块中最小的值。基于此,结合最大池化和最小池化设计出一种新的降采样层——最大最小池化(Max-MinPooling),有效保留了特征图中的正负值信息。
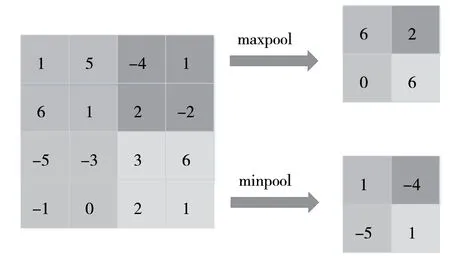
图2 最大池化及最小池化
如图3 所示,在降采样层分别使用最大池化和最小池化,并将两种池化后的结果拼接在一起,作为降采样层的输出。
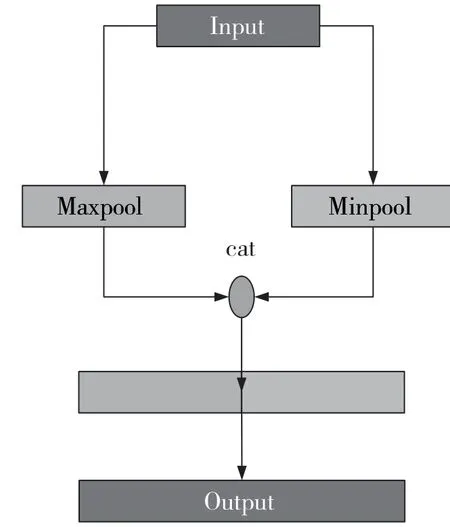
图3 基于最大最小池化方法的降采样层
2.3 特征图分块偏移二值化
卷积神经网络的内在特性是学习从输入图像到输出的映射。一个性能良好的二值化卷积神经网络应该拥有与全精度网络接近的学习能力。然而,离散的量化值限制了二值化卷积神经网络像全精度网络一样学习丰富的分布表示。为了解决这一问题,XNOR-Net 引入了缩放因子,将权重的分布近似于全精度网络;IR-Net 提出Libra-PB 将权重量化值的量化误差和二值参数的信息熵同时作为优化目标。
不同于关注对权重的优化,本文的研究关注对二值化特征图分布的优化。在全精度特征图中添加一个微小的偏移,会导致绝对值较小的部分特征值符号发生改变,这会极大地影响二值化后特征图的+1,-1 分布,进而影响网络最终性能。但在训练一个网络之前是无法提前找到合适的偏移量并设置在网络中的,所以在二值化前的全精度特征值中引入了可学习的偏移,以增强二值卷积神经网络学习二值特征图分布的能力,减少特征图二值化过程中的信息丢失。加入偏移后的二值函数可以表示为:

式中:x为网络模型中全精度的特征值(或权重);Sign为符号函数;b为特征图的偏移量。
在全精度网络中,因为权重和激活是连续的实值,对特征图的微小偏移量只会使特征图平移,并不会改变特征图的整体分布。然而,对于二值化网络来说,因为二值化网络的激活值只能是{-1,+1},在符号函数上加入一个小的偏移,可能会输出完全不同的二值化特征图,这将直接影响二值化特征图的信息量,对最终的准确性产生重大影响。
为了更直观地说明,绘制了实值输入特征图及二值化特征图,如图4。
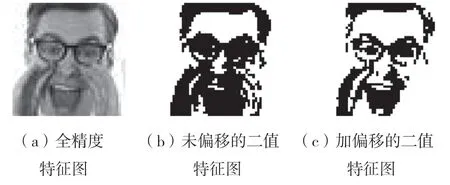
图4 偏移量对二值特征图的影响
从图4 可以看出,未偏移的二值特征图中眼睛和嘴巴附近有严重的细节信息丢失,加偏移的二值特征图能有效地改善未偏移的二值特征图中的信息丢失问题,但却完全丢失了左手的信息。因此,对全精度特征值进行的偏移虽然在一定程度上改善了二值化激活中信息丢失的问题,但局部的细节信息丢失却是无法避免的。基于此问题,如图4(a),如果将特征图分块,在每一块中使用不同的分布偏移,这样在颜色较浅(特征值较大)的区域加上正偏移量,在颜色较深(特征值较小)的区域加上负偏移量,就能保证二值化时不会出现局部特征值全为+1 或-1 的情况,有效保留了特征图局部细节信息,从而得到保留了更多细节信息的二值化特征图。如图5,分块二值化的二值特征图更好地保留了特征图信息。

图5 基于特征图分块偏移的二值化特征图
图6 展示了一个更明显的例子,可以看出,未偏移的二值特征图中的脸部信息基本完全丢失;加偏移的二值特征图中鼻子附近有所改善,但信息丢失依旧严重;特征图分块偏移的二值特征图中保留了人脸上的细节信息。因此,对于特征值分布不均的全精度特征图,使用分块偏移的二值化方法效果更好。

图6 使用不同方法得到的二值化特征图对比
2.4 BN 层与二值化激活层的融合
对于BN 层,需要先计算一个minibatch 中元素的均值方差,然后对于x需要减去均值μ除以标准差,最后利用缩放因子γ和偏移β进行仿射变换,即可得到最终的BN 输出,具体过程如下:
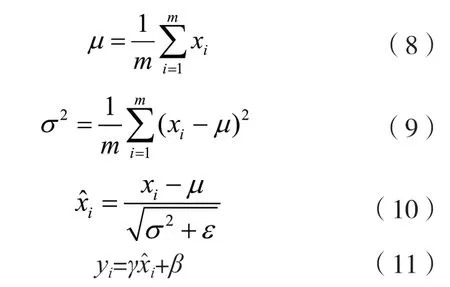
式中:xi为BN 前的特征值;x^i为特征值进行标准差标准化后的值。
BN 层与二值化激活层的融合为:

式中:yi为BN 后的输出特征值;t为BN 层与二值化激活层融合后,二值量化的新阈值。
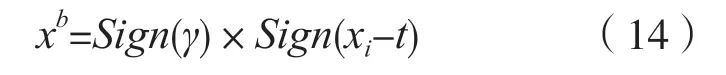
二值化卷积的输出特征值xi为[-9,+9]区间内的整数,可以将t向上取整,则有:

式中:Ceil()为向上取整函数。BN 层和二值化激活层融合后可表示为:
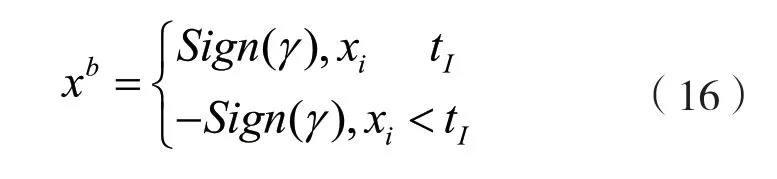
其中,Sign(γ)和tI均可在模型训练好后求出,这样就简化了网络的前向传播过程,即只需将二值化卷积计算出的特征值和提前计算好的二值化阈值进行比较,即可得到二值化的特征值。
3 实验结果及分析
为了验证本文提出的方法的有效性,使用Vggsmall 作为基准模型,对其进行二值化。Vggsmall是VGG 在小数据集上的衍生模型,包含了6 个卷积层和1 个全连接层,采取3 次下采样。相比VGG 系列模型,Vggsmall具有更浅的网络层和更少的参数量,在小数据集中拥有更高的参数效率。将Vggsmall 中除第一层卷积层和全连接层外全部进行二值化,得到本节实验采用的二值化网络模型,如图7 所示,并在4 个常用的小型数据集MNIST[24]、SVHN[25]、CIFAR-10、CIFAR-100[26]上训练和测试该模型。为了更客观地评价所提方法的有效性,将使用上述方法得到的实验结果与经典的二值化模型进行比较,评价指标是准确率(Accuracy),计算方法是预测正确的样本数除以总样本数。

图7 二值化VGG-Small 结构
3.1 MNIST 和SVHN 数据集上的实验结果
在MNIST 和SVHN 数据集上进行实验的结果如表1 所示,在MNIST 数据集上,本文模型达到了98.63%的准确率,与其他二值化模型相比,本文模型基本能够保持同样的精度,而且在模型大小上本文模型小于其他模型。
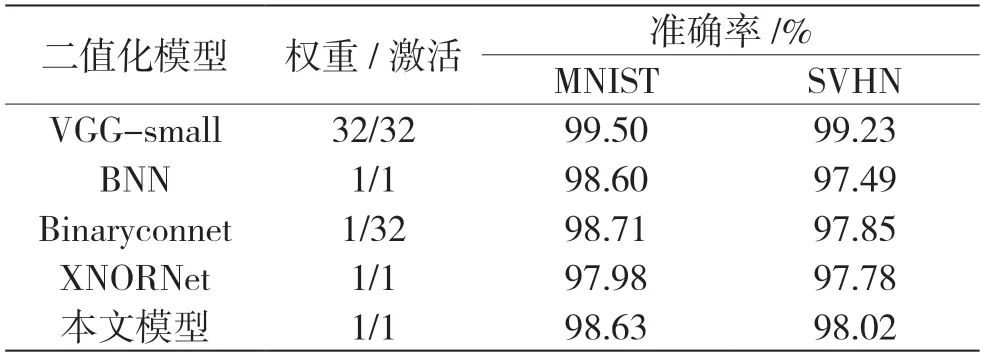
表1 MNIST 数据集与SVHN 数据集的实验结果
3.2 CIFAR-10 和CIFAR-100 数据集上的实验结果
在CIFAR-10 和CIFAR-100 数据集上的实验结果如表2 所示。在CIFAR-10 数据集上,本文模型取得了91.27%的准确率,与全精度的网络仅相差0.63%;在CIFAR-100 数据集上,本文模型取得了71.86%的准确率,与全精度的网络仅相差0.37%。与其他二值化模型相比,本文模型取得了更好的效果,超越了BNN、XNOR 这种同样没有额外分支的二值化模型。此外,ReActNet、IR-Net、Bi-RealNet-18 这类模型在CIFAR 数据集上存在过拟合现象,本文模型因为没有了额外分支,在这种小型数据集上有效避免了过拟合。因此,本文模型不仅在模型大小上有一定的优势,而且在精度上也得到了提升。在CIFAR-100 数据集上实验得到的损失曲线和准确率曲线如图8 和图9 所示。
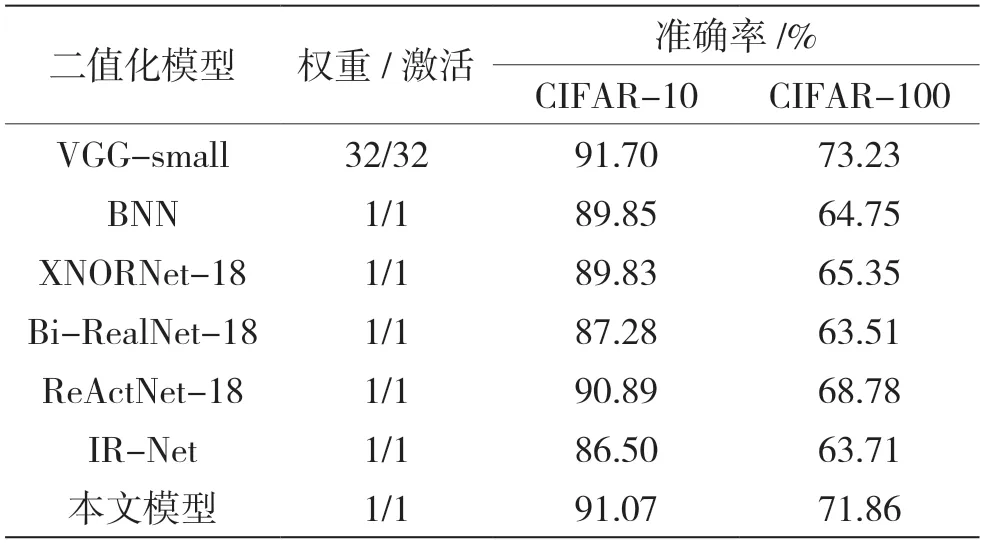
表2 CIFAR-10 数据集与CIFAR-100 数据集的实验结果
3.3 CIFAR-100 数据集实验结果
为了验证本文提出的最大最小池化和特征图分块偏移二值化在模型中的提升效果,本文在CIFAR-100 数据集上进行了大量的对比实验。
3.3.1 不同特征图分块大小的实验结果
上文提出对全精度特征图分块后进行不同程度的偏移再二值化,能够在二值化特征图中有效保留局部细节信息,提升二值化卷积神经网络的性能。而特征图分块方式与大小影响了二值化的性能,因此对不同的分块方式进行了对比实验。
(1)实验1。无论特征图大小,统一按照一定的块尺寸对特征图分块,按照2×2,4×4,8×8,16×16 4种不同尺寸分块得到的实验结果如表3 所示。从实验结果可以看出,使用该分块方式时,将特征图按照8×8 尺寸分块得到的效果最优。
(2)实验2。根据特征图大小,将尺寸较大的特征图分成较大的块,将尺寸较小的特征图分成较小的块,即按照一定的比例将特征图分块,实验结果如表4 所示。从实验结果可以看出,使用该分块方式时,特征图按照(H/2)×(W/2)(H和W分别代表特征图的高度和宽度)分块得到的效果最优。根据以上实验结果,第2 种分块方式优于第1 种分块方式。

表4 特征图按不同比例分块得到的准确度对比
3.3.2 不同池化方式的实验结果
VGG-small 网络在每一次降采样操作之后的卷积层进行通道数扩张,Max-MinPooling 在降采样层进行了通道数扩张。为了排除降采样层扩张通道数这一操作的影响,本文使用不同降采样方法做对比实验,实验结果如表5 所示。从实验结果可以看出,降采样层扩张通道数能够给网络带来一定的增益,使用最大最小池化方法明显优于仅使用最大池化或者最小池化。

表5 不同降采样方法下模型准确率对比
3.3.3 消融实验
为了验证所提方法的有效性,对两种方法进行了消融实验,实验结果如表6 所示。由表6 可知,本文提出的两种方法都为二值化卷积神经网络带来了增益。

表6 消融实验设置及对应准确率对比
4 结语
本文提出了一种基于特征图分块偏移激活的二值化卷积神经网络,解决了二值化卷积神经网络中信息丢失的问题。本文所提出的最大最小池化方法,充分考虑了二值化卷积神经网络中正负值信息的重要性,有效减少了二值化卷积神经网络中降采样层的信息损失。此外,本文提出的特征图分块偏移的二值化方法,关注了特征图的细节信息,保留了特征图二值化激活过程中的局部细节信息,有效增强了二值化网络学习特征图分布的能力。在公开数据集CIFAR-100 上的实验表明,本文提出的方法提高了二值化卷积神经网络模型的性能。
考虑到二值化网络提出的最初目的,就是在性能受限的嵌入式平台上实现深度学习算法的部署,未来的工作将针对FPGA 特性进行网络模型优化,将模型移植到FPGA 开发板上。
猜你喜欢
计算机应用(2022年9期)2022-09-25
北京航空航天大学学报(2022年8期)2022-08-31
房地产导刊(2022年4期)2022-04-19
软件导刊(2022年3期)2022-03-25
曲阜师范大学学报(自然科学版)(2021年3期)2021-08-26
新生代(2019年10期)2019-10-18
计算机技术与发展(2019年1期)2019-01-21
电子产品世界(2018年1期)2018-09-21
新教育时代·教师版(2018年19期)2018-07-21
智能计算机与应用(2018年2期)2018-05-23
