
基于多尺度卷积和注意力机制的LSTM 时间序列分类
2022-08-24 06:29玄英律万源陈嘉慧
计算机应用 2022年8期
玄英律,万源,陈嘉慧
(武汉理工大学理学院,武汉 430070)
0 引言
时间序列是按时间顺序排列的一组数据,广泛存在于商业、医学和社会科学等领域中。时间序列分类在数据挖掘领域具有重要的研究价值,其目标是根据时间序列的特征信息为其分配正确的类标签[1]。具有不同长度的子序列包含不同时间跨度的特征信息,称为时间序列的多尺度特征。在分类任务中,这些特征的重要程度不同[2-3]。除此之外,时间序列之间或内部存在复杂的相关关系,这种相关关系被称为时间序列相关性。因此,在时间序列分类任务中,如何有效地提取多尺度特征、评估特征重要程度并处理时间序列相关性问题是一个巨大的挑战。
时间序列分类模型可大致分为两大类:基于传统机器学习的模型和基于深度学习的模型。传统的时间序列分类模型中,基于距离的模型使用距离函数计算时间序列间的相似性,并结合最近邻法(1-Nearest Neighbor,1NN)预测类标签[4-5];基于特征的模型利用特征对时间序列进行分类,如Schäfer 等[6]提出的 BOSS(Bag of Symbolic Fourier Approximation Symbols),根据词分布形成词直方图,并通过词直方图的距离得到分类结果。
然而,大多数传统的时间序列分类模型都需要进行繁杂的特征工程或数据预处理工作,深度神经网络在时间序列分类中的应用有效地解决了这一问题,并进一步提高了分类准确率[7]。Wang 等[8]在实验中验证了多层感知机(MultiLayer Perceptron,MLP)处理时间序列分类问题的效果,MLP 通过全连接神经元的形式对整体时间序列数组的每一个元素逐层赋予权重,计算各类别概率,并输出最终的类标签;但MLP直接学习所有元素之间的相关关系,不能有效地提取特征[8-9]。Shelhamer 等[10]提出了全卷积神经网络(Fully Convolutional Network,FCN),使用卷积层替换多层感知机最后的全连接层,加入批标准化层和全局池化层,防止网络过拟合,增强了网络的特征提取能力;但FCN 以固定大小的卷积核进行卷积,无法提取不同尺度的子序列特征,存在特征丢失问题。Franceschi 等[11]提出的USRL-Combined(1NN)模型,通过堆叠casual 卷积层获取更丰富的序列特征表示,其分类效果普遍优于传统的时间序列分类模型。Cui 等[12]提出一种新的基于卷积神经网络(Convolutional Neural Network,CNN)的深度架构——多尺度卷积神经网络(Multiscale Convolutional Neural Network,MCNN),该网络包含三个网络支路,分别进行恒等映射、滑动平均以及下采样处理用以提取时间序列数据的多尺度特征,在一定程度上解决了特征丢失问题,然而其分类性能在很大程度上取决于超参数的选择和数据的预处理质量[13-14],模型仍有较大的改进空间。Chen 等[15]为了提高深度学习模型的鲁棒性,提出了一种结合多尺度特征提取和注意力机制的端到端网络MACNN(Multi-scale Attention Convolutional Neural Network),该网络设计了基于CNN 的多尺度卷积模块(Multi-scale Convolutional Module,MCM),CNN 具有较为鲁棒的特征提取能力[8],网络堆叠多个模块,能产生不同范围的感受域,从而获取不同尺度上的时间序列特征信息。
注意力机制借鉴了人类视觉所特有的信息处理机制。人类视觉通过快速扫描全局信息,获得需要重点关注的目标区域信息之后,对重要的信息投入更多注意力资源,从而提取关键的细节信息,同时抑制其他无用信息,注意力机制能够显著地提高信息处理的效率与准确性。近年来,在已有的多尺度特征提取的工作基础上,Huang 等[16]将注意力机制应用于时间序列分类任务中,使模型能够自动学习并关注重要的特征,高效地分配计算资源以聚焦对分类结果有重要贡献的特征表示,抑制贡献较小的特征。
但时间序列数据常常存在复杂的相关性,上述深度神经网络只能独立地处理输入的时间序列信息,无法在时间域中获取隐含的序列依赖关系。循环神经网络(Recurrent Neural Network,RNN)[17]是一类专门处理序列数据的网络,其特点是前一时刻的输出将对之后的输出产生影响。然而,在处理长序列时,RNN 容易发生记忆丢失和梯度消失问题,导致网络难以继续训练[18]。针对此问题,Hochreiter 等[19]基于RNN提出长短时记忆(Long Short-Term Memory,LSTM)网络,引入记忆细胞(memory cell)保存序列的长期信息,并通过门机制(gate mechanism)增加或舍弃即将进入细胞状态中的信息,在一定程度上解决了传统RNN 存在的梯度消失的问题,可以学习长期相关信息[20]。为了提高网络的特征提取能力,同时考虑时间序列相关性的问题,Karim 等[14]提出一种并行深度架构LSTM-FCN,使用LSTM 提取时间序列数据的相关性信息,并利用FCN 作为特征提取模块提取时间序列高维特征,相较于LSTM,该模型显著地增强了分类性能,但仍存在不能提取多尺度特征的问题。2020 年,Xiao 等[21]基于LSTMFCN 作出改进,提出了RTFN(Robust Temporal Feature Network for time series classification),该网络使用LSTM 结合CNN、跳跃连接结构和自注意力机制提取多尺度时间序列特征。
上述模型仍存在两个问题:1)在提取序列特征时,网络以固定大小的卷积核提取序列特征,导致无法有效提取多尺度特征,而对于时间序列分类任务而言,充分地利用多尺度特征能够有效增强网络的分类能力。2)大多数基于深度学习的分类模型未考虑序列特征的重要性差异,在计算资源有限的条件下,如果网络对所有特征视为同等重要可能造成资源的浪费,而且当对分类有较大贡献的特征被忽视时,将会严重影响网络的分类性能。
针对上述的问题,本文提出一种新的基于多尺度卷积和注意力机制的LSTM(Multi-scale Convolution and Attention mechanism based LSTM,MCA-LSTM)模型以提高时间序列分类的准确率。该网络为两个支路组成的并行架构,结合LSTM 和多尺度卷积注意力模块(Multi-scale Convolutional and Attention Module,MCAM)。其中LSTM 使用门机制和记忆细胞控制序列信息的传递,有利于网络学习时间序列的相关性信息。多尺度卷积注意力模块由多尺度卷积模块(MCM)和注意力模块(Attention Module,AM)组成,在多尺度卷积模块中,为CNN 设置了三种不同大小的卷积核,能产生多个感受域提取时间序列数据在不同尺度上的特征,进而将融合提取的特征传入注意力模块。该模块沿用SE Net(Squeeze and Excite Network)[22],通过降低通道数融合通道间的特征信息并学习特征的重要性程度,在输出特征图前恢复原通道数计算特征图的注意力权重,最后融合带有注意力权重的多尺度特征和时间序列相关性信息,输出分类结果。
本文的主要工作如下:
1)基于多个并行的CNN 构造网络的特征提取模块,充分提取时间序列的多尺度抽象特征。
2)在多尺度特征的提取过程中,结合通道注意力机制,自动学习特征的重要程度,并利用重要的多尺度特征进行分类,有效提高分类准确率并降低模型的时间复杂度。
1 相关工作
1.1 LSTM网络
LSTM 网络是基于循环神经网络的一种改进模型,使用门机制和记忆细胞控制序列信息的传递,在处理长序列信息时,可以有效解决记忆丢失和梯度消失问题[19]。LSTM 主要由记忆细胞和多个控制序列信息流动的“门”组成,相关函数的公式如下所示:
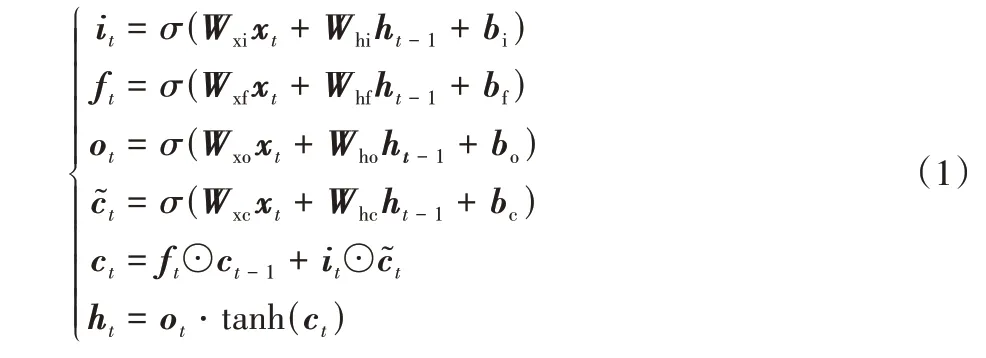
其中:xt表示t时刻的信息输入;c表示细胞状态,用于保存网络提取到的序列信息;i表示输入门,控制xt输入至记忆细胞中的信息量;f表示遗忘门,控制t-1 时刻的细胞状态ct-1输入t时刻细胞状态ct的信息量;o表示输出门,控制ct传递至t时刻隐藏层状态ht的信息量;Wxi、Wxf、Wxo、Wxc分别表示输入层到输入门、遗忘门、输出门与细胞状态的权重矩阵;Whi、Whf、Who、Whc分别表示隐藏层到输入门、遗忘门、输出门与细胞状态的权重矩阵;bi、bf、bo、bc分别表示输入门、遗忘门、输出门与细胞状态的偏置向量;σ(·)表示Sigmoid 激活函数;tanh(·)表示双曲正切激活函数;⊙表示两个同阶矩阵中对应元素相乘的运算,称为Hadamard 乘积。
1.2 注意力机制
根据人类的视觉机制,Vaswani 等[23]提出的注意力机制近年来已广泛应用于语音识别、自然语言处理等领域,使用注意力机制的模型能够自动学习并关注重要的特征,高效地分配计算资源以获取最重要的特征表示[24-25]。最近的研究表明,通道注意力机制已被广泛应用于时间序列分类领域。Hu 等[22]提出SE Net,在通道维度上融合信息,学习各通道间的相关关系,并计算衡量特征图重要性的注意力权重。Huang 等[16]基于ResNet[26]提出残差注意力网络(Residual Attention Net),针对跨领域的序列数据,将Universal-Transformer 架构[27]和残差网络相结合,从而识别更高层次的序列模式。
1.3 多尺度特征提取
时间序列数据内部往往存在复杂的特征信息,充分地提取特征,并利用重要的特征进行分类,能够有效提高时间序列分类模型的性能。Cui 等[12]提出的MCNN 在频域将时间序列自动平滑去除噪声,在时域通过不同程度的下采样处理获取多尺度特征。在端到端的深度学习模型中,Shuang 等[28]提出卷积-反卷积词嵌入(Convolution-Deconvolution Word Embedding,CDWE)网络,结合LSTM 与卷积-反卷积词嵌入模型,融合特定的上下文信息和特定任务信息。Fawaz 等[29]在GoogLeNet[30]的基础上,改进并应用于时间序列分类领域,提出Inception-Time 架构,其核心是基于并行CNN 的Inception 模块,通过堆叠该模块产生多个尺度的感受域,并且使用不同长度的卷积核,提取多个时间跨度的潜在层次特征。Tang 等[31]提出OS-CNN(Omni Scale-CNN)架构,利用根据数据集序列长度自适应网络参数的全尺度模块(Omni Scale block,OS block)捕捉序列的多尺度局部特征,挖掘数据的层次表示和层次结构中的相关关系。本文在深度网络中结合通道注意力机制和多尺度卷积,以充分提取多尺度特征,聚焦重要的序列多尺度特征,从而提高模型的分类性能。
2 多尺度注意力长短时记忆网络
2.1 整体架构
MCA-LSTM 的结构如图1 所示,该网络由LSTM 支路和基于多尺度卷积注意力模块(Multi-scale Convolutional and Attention Module,MCAM)的支路组成。网络中多次使用两个MCAM 和一个池化层(Pooling)的结构,下文称这样的结构为Section。
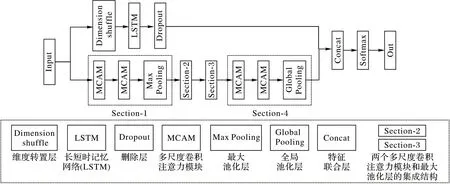
图1 MCA-LSTM的整体结构Fig.1 Overall structure of MCA-LSTM
多尺度卷积注意力支路堆叠4 个Section 用于获取重要的特征,池化层用于减少网络的参数量、防止网络过拟合。其中,Section-1 与Section-2、Section-3 均使用最大池化层且具有完全相同的结构;Section-4 则使用全局池化代替传统的全连接层[32],以降低网络参数量。
在LSTM 支路上,时间序列数据首先输入维度转置层(Dimension shuffle),使网络将长度为N的单变量时间序列样本视为长度为1、具有N个变量的多变量时间序列,维度转置操作可以显著提高LSTM 的训练速度[14]。LSTM 控制序列信息的传递,提取序列相关性信息。随后将提取的特征输入丢弃层(Dropout)[33],在网络训练过程中按一定的概率p移除神经元,防止模型产生过拟合,增加模型鲁棒性。加入Dropout操作后,网络计算公式如下:
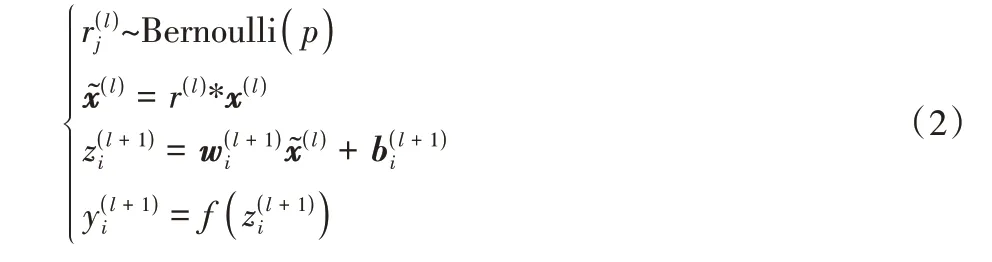
其中:Bernoulli 表示伯努利分布;参数p表示移除神经元的概率分别以概率p和1 -p取1 和0 为值,用于调整神经网络的输入分别表示第l+1 层上第i个神经元的权重向量和偏置向量;f(·)为线性整流单元(Rectified Linear Unit,ReLU)激活函数。最后使用特征联合层连接两个支路提取的多尺度注意力特征和相关性信息,输入Softmax 计算类别概率,输出分类结果,并在网络的输出层提供监督,根据交叉熵损失函数学习网络参数。
2.2 多尺度卷积模块
时间序列数据的子序列包含复杂的信息,在时间序列分类中,网络中存在的子序列特征丢失问题往往会导致数据被错误分类。在基于深度学习的时间序列分类模型中,可以利用不同范围的感受域获取更丰富的时间序列特征信息。为了提取多尺度特征,进一步解决局部特征丢失问题,本文使用多尺度卷积模块(MCM),同时提取时间序列的多尺度特征,融合更丰富的局部信息,更加充分地利用序列内部隐含信息。
由于时间序列是一维的,在CNN 上使用一维卷积核对时间序列数据进行卷积操作。第l 层CNN 上第i个滤波器t时刻激活值的计算公式如下:
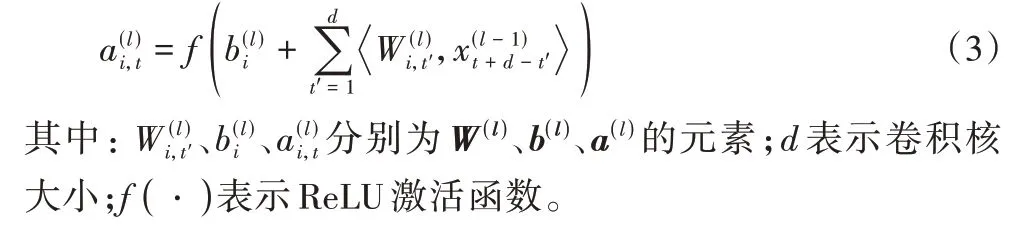
在MCA-LSTM 中,3 个并行CNN 的卷积核大小分别设置为d1、d2、d3,且满足d1<d2<d3,对应提取时间序列的短、中、长期特征。进而将多尺度特征输入特征联合层(Concatenate Layer)进行特征融合,传入批标准化(Batch Normalization,BN)层对样本进行标准化操作:

最后一层为激活层,使用ReLU 作为激活函数,其优点是能够增强网络的非线性表示关系,产生较为稀疏的学习参数矩阵,从而在一定程度上降低网络的计算复杂度;为了提高模型的收敛速度和鲁棒性,本文结合使用BN 操作和ReLU 激活函数[35]。模块的输出由式(6)计算得到:
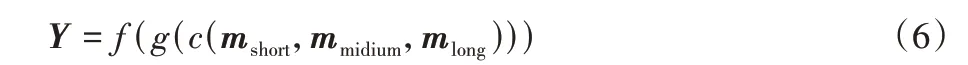
其中:mshort、mmidium、mlong表示卷积核大小等于d1、d2、d3的卷积核提取到的特征图,对应时间序列的短、中、长期特征;c(·)表示特征连接操作;g(·)表示批量标准化操作;f(·)表示使用ReLU 激活函数计算激活值。
2.3 注意力模块
时间序列的子序列所包含的特征信息通常具有不同的重要程度,为了进一步提高模型性能,本文创新地使用基于空间注意力机制的注意力模块(AM)建模时间序列卷积特征的通道之间的相互依赖关系,网络根据前向误差自动学习特征权重,聚焦重要的特征信息,以提高网络产生的特征表示的质量。
注意力模块的结构如图2 所示。首先,多尺度模块输出的特征图作为注意力模块的输入进行全局池化操作:

图2 多尺度卷积注意力模块的结构Fig.2 Structure of multi-scale convolutional and attention modules

最后两层分别使用激活函数为ReLU 函数和Sigmoid 函数的两个全连接层,r表示降维因子。在第1 个全连接层中压缩特征图的通道数为输入时的1/r,融合通道的全局特征信息,利用全局信息获取各通道之间的非线性相关关系;第2 个全连接层中进行升维操作,将特征图通道数恢复至输入时的通道个数,计算特征图的注意力权重向量,融合多尺度特征,根据式(8)计算得到注意力权重S:

其中:δ表示ReLU 激活函数;σ表示Sigmoid 激活函数;W1、W2分别表示第1、2 个全连接层中神经元的权重参数。
多尺度卷积模块的输出特征向量Y与对应的注意力模块输出的权重矩阵S逐元素相乘,得到注意力模块的输出矩阵Z,并输入后续的网络层,对特征赋注意力权重的计算公式如下:

对应元素的计算公式如下:

如果特征越重要,其对应注意力权重si越接近1;反之,注意力权重si越接近0。网络可根据权重的大小判断特征yi的重要程度,为重要的特征分配更多计算资源,抑制不重要的特征,从而提高网络产生的特征表示的质量。
3 实验与结果分析
3.1 实验数据集与评价指标
3.1.1 数据集
本文模型使用Xiao 等[21]在对比实验部分使用的UCR 档案[36]中的65 个单变量时间序列数据集,共涉及心电图、图像、运动、传感器、模拟、和图谱分析6 个领域。序列长度为24~2 709,数据集的样本数为20~4 500。这些数据集对现实时间序列数据具有较强的代表性,得到的实验结果能够验证模型的性能和泛化能力。
3.1.2 评价指标
本文选择三种常用的时间序列分类评价指标对各个模型进行综合评价,并使用Wilcoxon 符号秩检验和Nemenyi 后续检验对比本文模型和其他模型的性能差异。具体定义如下:
1)算术平均排名(Arithmetic Mean Rank,AMR)表示目标模型在所有数据集上准确率排名的算术平均值,该值越低说明模型的综合性能越好,计算公式如下:

其中:ri表示目标模型在第i个数据集上的准确率排名;N表示数据集的总个数。
2)几何平均排名(Geometric Mean Rank,GMR)表示目标模型在所有数据集上准确率排名的几何平均值,与AMR 共同度量模型在数据集上的综合性能。如果某模型具有较大的GMR 值,说明该模型在多个数据集上的准确率排名靠后。计算公式如下:

3)平均错误率(Mean Error,ME)表示目标模型在所有数据集上取得的准确率,该值越低说明模型性能越好,计算公式为:

其中:ai表示目标模型在第i个数据集上的Top-1 准确率。
4)Wilcoxon 符号秩检验(Wilcoxon Signed rank Test,WST)是一种非参数统计检验,对比其他模型在各数据集上准确率排名,检验本文模型的性能是否显著优于其他对比模型,其原假设和备择假设如下:

其中:m表示模型在所有数据集上准确率排名的中位数。
5)Nemenyi 后续检验(Nemenyi Test),当存在两个模型在WST 中拒绝原假设后,说明模型间的性能表现有显著差异,此时进行Nemenyi 后续检验进一步区分模型的优劣程度。根据相应的置信度计算临界差(Critical Difference,CD),比较模型的算术平均排名是否超出该临界值以判断性能差异,临界差C的计算公式如下:

其中:qα在自由度为α下的置信度;k表示模型个数;N表示数据集的总个数。在本文的实验条件下,置信度α=0.05,qα=2.85。
3.2 实验设置
本文在UCR 档案中挑选了8 个涉及多个领域、具有不同序列长度的单变量时间序列数据集,用于选择最优的模型架构与网络参数设置,具体情况见表1。
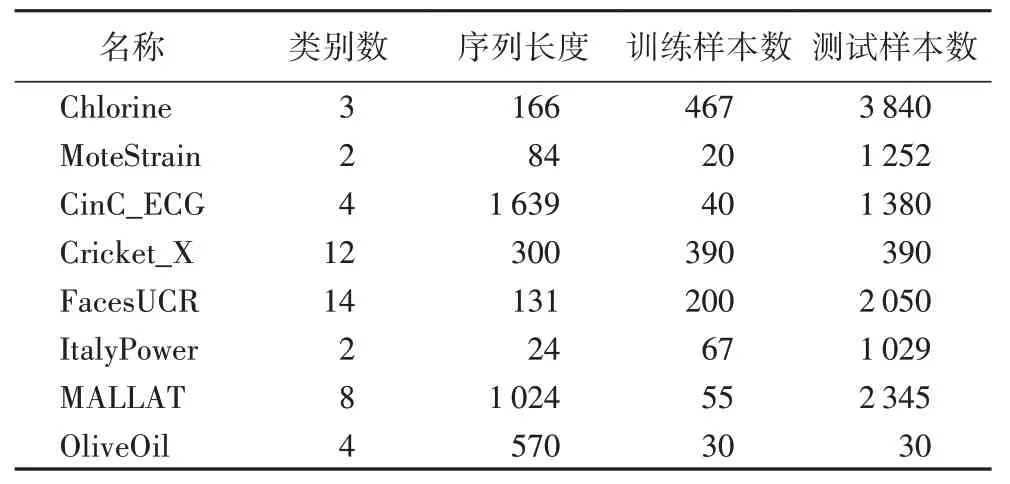
表1 8个时间序列数据集细节Tab.1 Details of 8 time series datasets
3.2.1 网络架构搜索
MCA-LSTM 的多尺度卷积注意力支路,可以通过堆叠多个Section 产生不同大小的感受域以提取重要的多尺度时间序列特征。但由于本文所使用数据集的样本序列长度不等,在提取短、中、长期特征时,需要产生大小合适的感受域以适应大多数数据集。此外,如果堆叠的层数过多,可能会在某些数据集上发生过拟合问题。因此,本文对包含不同数量Section 的网络架构进行性能对比实验。实验的网络参数设置沿用文献[14-15]和文献[22]中的设置,其中批处理大小设置为128,学习率设置为0.001,降维因子设置为16,训练轮数设置为2 000。在8 个数据集上分别运行包含1~6 个Section 的网络架构,架构搜索的实验结果如图3 所示。
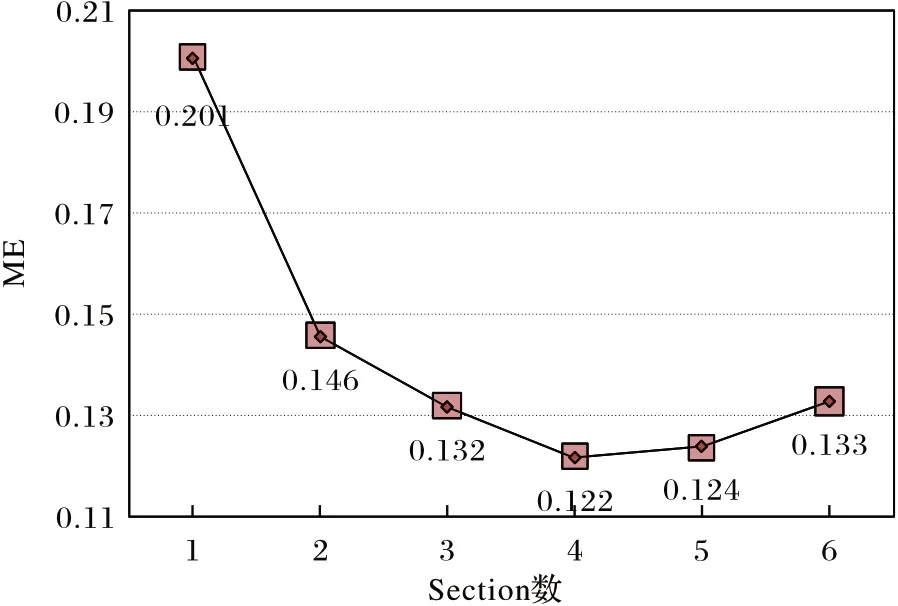
图3 不同架构的平均错误率Fig.3 Mean errors of different architectures
根据架构搜索结果发现,当网络堆叠的Section 数小于等于3 时,增加网络的深度能够提高分类的准确率;当Section数大于5 时,模型的性能开始下降。这可能由于网络层数过少时,未能充分提取时间序列特征,而当Section 数大于等于5 时,网络中发生了过拟合问题。包含4 个Section 的网络架构达到最低的平均测试错误率为0.122,因此本文选择在多尺度卷积注意力支路中堆叠4 个Section 作为MCA-LSTM 的网络架构。
3.2.2 网络参数选择与设置
确定网络架构之后,为了选择适合MCA-LSTM 的参数组合,本文沿用文献[15]的超参数搜索方法和初始超参数组合:首先,依次设置批处理大小、训练轮数、降维因子和丢弃率的初始值为32、2 000、16、0.8。然后采用基于该超参数组合的贪婪策略搜索最优参数取值。具体来说,先固定后3 个参数,对第1 个参数的不同取值进行实验,选取使得模型达到最低错误率的取值作为该参数的最优值;然后固定第1、3、4 个参数,选取第2 个参数的最优值,以此类推。应注意的是,已选取最优值的参数将在接下来的参数搜索实验中恒被固定为最优值。
本文根据文献[14-15]设置网络参数搜索空间,分别在{32,64,128,256}、{1 500,2 000,2 500,3 000}、{8,16,32}和{0.5,0.6,0.7,0.8,0.9}中依次搜索批处理大小、训练轮数、降维因子和丢弃率。表2 为各个网络参数组合的平均错误率,粗体超参数取值和平均错误率分别表示超参数在贪婪策略下的局部最优取值和局部最低的平均错误率。
从表2 可看出:在给定的网络参数空间中,模型取得最小的平均错误率为0.130 9,其中,训练轮数为2 500 和3 000时取得的模型表现相同,在节省计算资源的原则下,选择2 500 作为训练轮数的最优值。因此模型最终的参数选择情况如下:批处理大小设置为128,初始学习率设置为1E-3,训练轮数设置为2 500,并使用Adam 优化器[37]。在训练过程中,如果模型在测试集上的准确率连续100 轮未获得提高,学习率将降低为原来的,直至降低为1E-4。在MCALSTM 的多尺度卷积模块中,3 个CNN 的卷积核大小分别设置为3、6、12,卷积的滑动步长设置为1,卷积核个数均设置为32,最大池化层的滑动步长设置为2。注意力模块中降维因子设置为16。LSTM 的记忆细胞数在8、64、128 中选择,丢弃层的丢弃率设置为0.8。
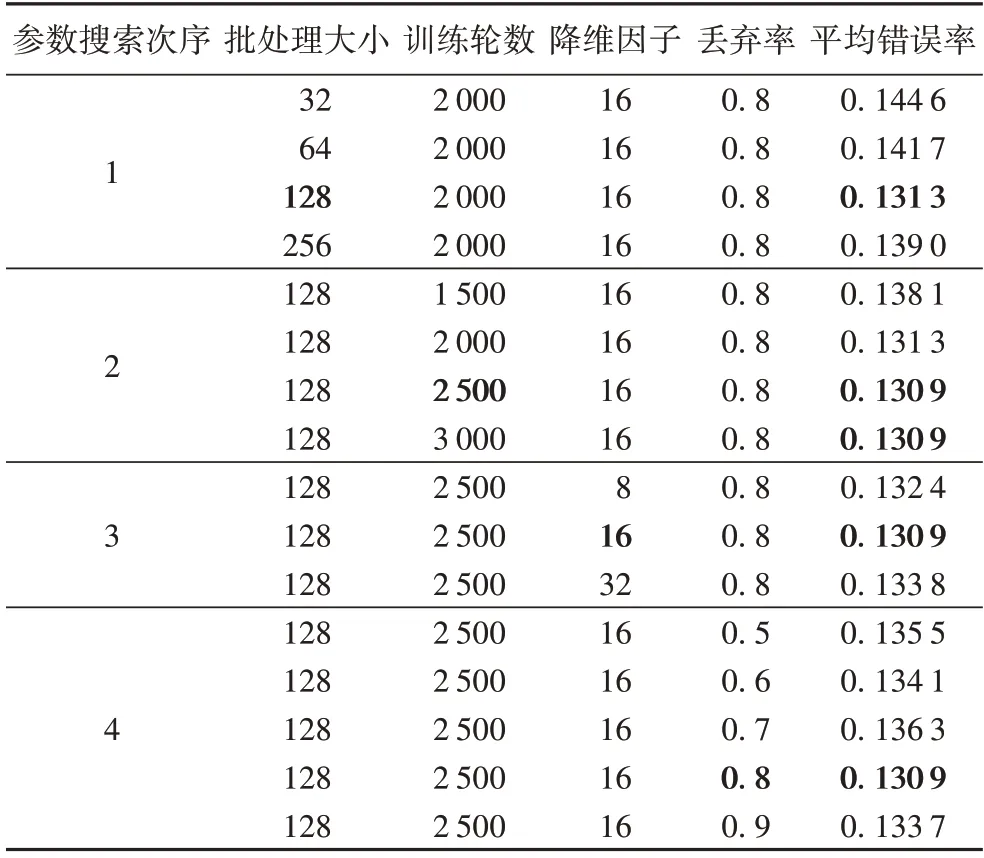
表2 各参数组合的平均错误率Tab.2 Mean error of each parameter combination
3.3 实验结果与分析
MCA-LSTM模型的代码使用深度学习框架Keras[38]编写,并在NVIDIA GeForce RTX 2080 GPU 上进行训练。由于神经网络使用随机初始权重,进行了10 次实验以平均由初始权重引起的误差。此外,在本文的设置中,数据集序列长度小于200 称为短序列数据集,序列长度介于200 到500 之间称为中序列数据集,长度大于500 的称为长序列数据集。
3.3.1 Top-1准确率对比
本文选择5 种基于深度学习的时间序列分类模型作为对比模型,包括:USRL-FordA(Unsupervised Scalable Representation Learning-FordA)[11]、USRL-Combined(1-NN)[11]、OS-CNN[31]、Inception-Time[29]和RTFN(Robust Temporal Feature Network for time series classification)[21]。本节将展示MCALSTM 和5 种对比模型在65 个单变量时间序列数据集上取得的Top-1 准确率,实验结果如表3 所示,粗体表示所有对比模型在某数据集取得的最高分类准确率。

表3 65个数据集上的Top-1准确率对比Tab.3 Comparison of Top-1 accuracy on 65 datasets
相较于5 种基于深度学习的时间序列分类模型,本文模型共在28 个数据集上取得最高的Top-1 准确率。具体来说,相较于没有使用多尺度卷积和注意力机制的深度模型,如USRL-FordA 和USRL-Combined(1-NN),本文模型分别在54个和57 个数据集上取得更高的准确率。对比同样使用了多尺度卷积的OS-CNN 和Inception-Time,本文模型分别在37 个和38 个数据集上取得了更优秀的表现,分别在10 个和7 个数据集上与上述两种多尺度模型的准确率持平。相较于最新的RTFN,该模型在编码器-解码器结构中使用多尺度卷积和自注意力模块,本文模型仍在30 个数据集上取得了更好的结果,并在另外11 个数据集上的准确率与之持平。对实验结果分析发现,在个别数据集上,如BeetleFly 和OliveOil,MCA-LSTM 的分类准确率普遍低于其他对比模型。其中的原因是,这两个数据集的序列长度均在500 以上。当序列长度较大时,MCA-LSTM 只能在相对较短的尺度上提取特征,导致对长序列数据集的分类准确率提升有限。而MCA-LSTM 在短、中序列的数据集上的分类准确率均取得了较为明显的提升,说明本文模型更有利于处理短、中序列的数据集。不同序列长度的数据集上的平均Top-1 准确率对比如表4 所示,粗体表示不同序列长度下对比模型得到的最高平均Top-1 准确率。从表4 可以看出:相较于最新的RTFN 模型,MCA-LSTM 在短、中、长序列数据集上的平均错误率分别降低了2.1、0.02、-0.02 个百分点。总的来说,两种模型在中、长序列数据集上的分类能力相近,而在短序列数据集的处理上MCA-LSTM 具有更明显的优势。
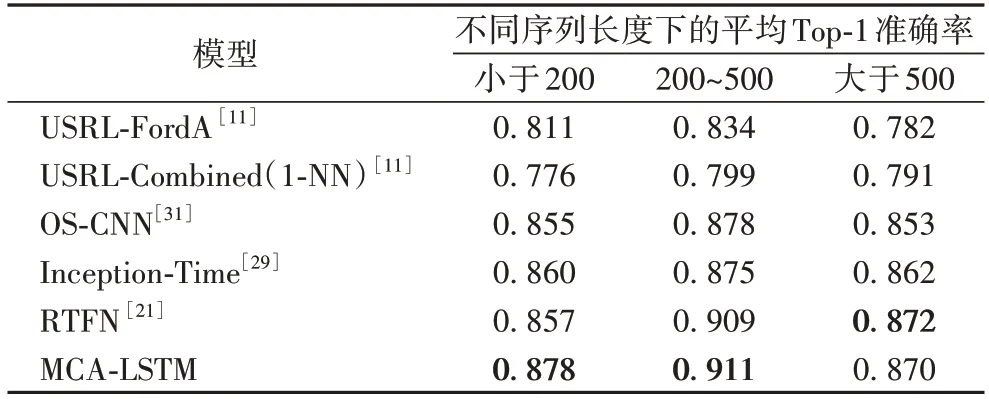
表4 按序列长度分组的不同模型的平均Top-1准确率Tab.4 Average Top-1 accuracies of different models grouped by sequence length

续表
3.3.2 评价指标对比
为了评价MCA-LSTM 和其他模型在所有数据集上的整体性能表现,根据式(11)~(13)分别计算评价指标平均错误率(ME)、算术平均排名(AMR)和几何平均排名(GMR),分析表5 可以得出以下结论。
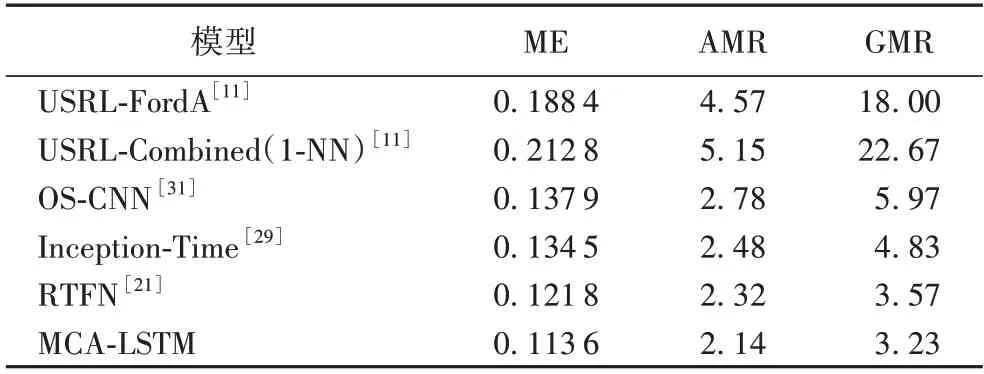
表5 评价指标对比Tab.5 Comparison of evaluation indicators
相较于其他5 种基于深度学习的时间序列分类模型,本文模型在UCR 档案中的65 个单变量时间序列数据集上取得的ME、AMR 和GMR 三种评价指标均优于其他5 种对比模型。三种评价指标的具体数值分别为11.36%、2.14 名、3.23名 。具体来说,相较于USRL-FordA 和 USRLCombined(1-NN),MCA-LSTM 的ME 分别降低了7.48 个百分点和9.92 个百分点;对比其他提取多尺度特征进行分类的模型架构,如OS-CNN 根据序列长度自适应分配卷积核大小提取多尺度特征,Inception-Time 通过堆叠基于CNN 的特征提取模块产生不同感受域提取多尺度特征,MCA-LSTM 相较于OS-CNN,ME 指标降低了2.43 个百分点,AMR、GMR 分别提升0.64 名和2.74 名。相较于Inception-Time 模型,ME 降由于MCA-LSTM 和RTFN 之间以及其他部分模型之间的性能差异未通过显著性检验,进行Nemenyi 后续检验,由式(15)计算CD,进一步判断各个模型性能的优劣程度。根据各模型间的临界差图(如图4 所示)可以得出结论:本文模型的总体分类性能显著优于未使用多尺度卷积的USRLCombined(1-NN)和USRL-FordA,在一定程度上优于使用多低2.09 个百分点,AMR、GMR 分别提升0.34 名和1.60 名。这归功于MCA-LSTM 在多尺度卷积的基础上结合了注意力机制,使模型能够更有效地融合多尺度信息,并关注重要的特征。对比结合多尺度卷积和自注意力机制的RTFN,本文模型在平均错误率上降低0.82 个百分点,算术平均排名、几何平均排名上分别提升0.18 名和0.34 名,这是由于MCALSTM 堆叠了较多基于CNN 和注意力机制的MCAM 协助网络进行特征提取,较深的网络结构使得MCA-LSTM 能够更充分地学习数据间的非线性关系,并提取到更多有利于分类的潜在时间序列特征。

图4 基于算术平均排名的临界差图Fig.4 Critical difference diagram based on arithmetic mean ranks
为了探究各模型之间分类准确率的显著性差异程度,将MCA-LSTM 与其他模型进行Wilcoxon 符号秩检验,若检验的p值小于0.05,则拒绝原假设,说明两个模型的分类性能具有显著差异;反之接受原假设,说明两个模型的性能相近。表6 中的加粗p值表示接受原假设,即对应模型之间的分类性能无显著差异,本文模型与USRL-FordA、Inception-Time、USRL-Combined(1-NN)、OS-CNN 的性能具有显著差异,但和RTFN 的性能差异不显著。尺度卷积的RTFN、Inception-Time 和OS-CNN。
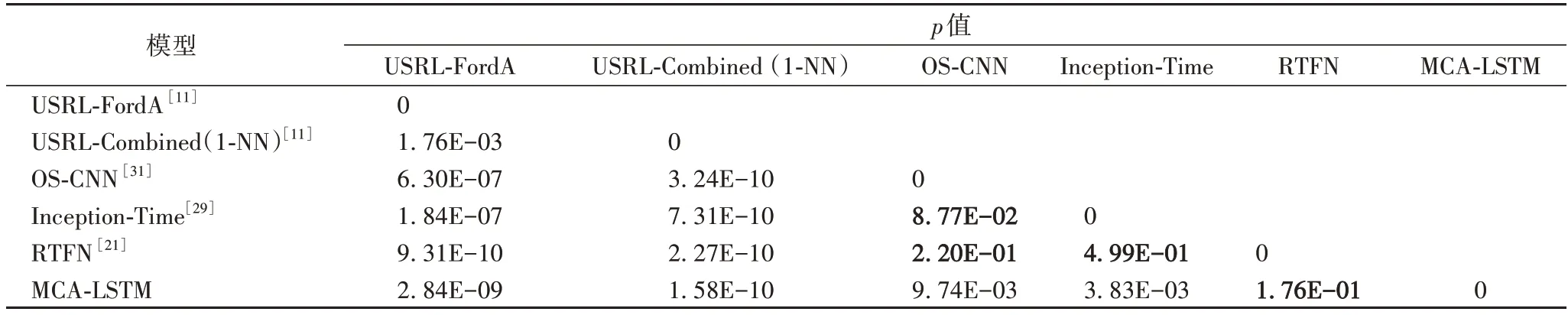
表6 各模型间Wilcoxon符号秩检验结果Tab.6 Wilcoxon signed-rank test results between different models
综合上述实验结果可知,本文模型在65 个实验数据集上取得了优于所有对比模型的综合表现,这表明结合多尺度卷积和注意力机制,能让网络取得更良好的分类表现。因此,相较于其他基于深度学习的模型,MCA-LSTM 在解决单变量时间序列分类任务方面更有优势。
4 结语
为了提高单变量时间序列的分类准确率,本文提出一种基于多尺度卷积和注意力机制的LSTM 模型——MCALSTM。该网络为两个支路组成的并行架构,结合LSTM、多尺度卷积模块和注意力模块:LSTM 控制序列信息的传递,使网络能够有效地学习序列的相关性信息;多尺度卷积模块通过产生多个感受域提取时间序列数据在不同尺度上的特征,获取更丰富的特征表示;注意力模块融合通道特征信息,使网络聚焦于重要的特征。在UCR 档案中的65 个单变量数据集上进行的实验和评价结果表明,相较于其他5 种基于深度学习的时间序列分类模型,MCA-LSTM 的分类性能更为优秀,从整体上提高了分类准确率。然而,本文模型对长时间序列的分类效果提升不够明显,除此之外,尚未将模型应用至多变量时间序列分类数据集中,在未来的工作中将在此模型的基础上深入研究解决多变量、长序列分类问题的模型架构。
猜你喜欢
计算机研究与发展(2022年1期)2022-01-19
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
计算机应用(2020年12期)2020-12-31
马克思主义哲学研究(2020年1期)2020-11-26
电子制作(2019年11期)2019-07-04
太空探索(2016年5期)2016-07-12
文苑(2015年9期)2015-09-10
时代英语·高三(2014年5期)2014-08-26
