
基于挤压激励的轻量化注意力机制模块
2022-08-24 06:29吕振虎许新征张芳艳
计算机应用 2022年8期
吕振虎,许新征,2*,张芳艳
(1.中国矿业大学计算机科学与技术学院,江苏徐州 221116;2.光电技术与智能控制教育部重点实验室(兰州交通大学),兰州 730070;3.宁夏大学智能工程与技术学院,宁夏中卫 755000)
0 引言
注意力机制模块是计算机视觉领域研究中的一个重要方向,可以使卷积神经网络(Convolutional Neural Network,CNN)模型增强对特征图中关键信息的学习与理解,被广泛嵌入卷积神经网络模型中,用于提高模型在图像分类[1-2]、目标检测[3-4]和语义分割[5]等领域的应用精度。对于研究注意力机制模块问题而言,由于将其嵌入模型会增加模型所需要的计算资源,所以如何在提高模型应用精度的同时,减少增加的参数和计算量是当前研究的一个热点。
在注意力机制模块研究中,最经典的是Hu 等[6]2018 年提出的挤压激励(Squeeze and Excitation,SE)模块,因为卷积层局部感受野的限制,模型只能学习到特征图局部位置的依赖关系,而SE 模块通过全局平均池化获得每个特征图的全局信息,使用全连接层学习特征图之间的全局依赖关系。SE 模块使用全局平均池化和缩减率减小增加的参数和计算量,目前仍被广泛的使用。2018 年,Park 等[7]提出了瓶颈注意力模块(Bottleneck Attention Module,BAM),BAM 在SE 的通道注意力基础之上添加了使用卷积模块操作的空间注意力机制,两者并行执行。BAM 由于并行执行两种注意力机制,虽相比SE 进一步提高了模型的应用精度,但增加的参数和计算量比SE 更多。由于BAM 的缺点,Woo 等[8]在同年提出了卷积块注意力模块(Convolutional Block Attention Module,CBAM),CBAM 是BAM 的改进版本,将BAM 中并行执行的两种维度注意力机制分为两个独立的部分。CBAM先使用通道注意力增强特征图,然后将增强后的特征图输入到空间注意力模块中进行处理。在空间注意力模块中CBAM 与BAM 不同的是先使用平均池化和全局池化提取特征图的全局信息,然后使用一个卷积层进行处理,而BAM 使用了四个卷积层,因此CBAM 相比BAM 减小了向模型中增加的参数量和计算量。
随着研究的进展,Wang 等[9]在2020 年提出了高效通道注意力(Efficient Channel Attention,ECA)模块。Wang 等认为SE 模块中使用缩减率降维的方法会妨碍特征图通道之间的信息交互,ECA 模块通过自适应大小的一维卷积实现无降维的局部通道交互策略。因为ECA 模块使用了自适应的一维卷积,所以模块的复杂度相比SE 模块、BAM 和CBAM 更低一些,同时增加的参数量和计算量更小。Hou 等[10]在2021年提出了协调注意力(Coordinate Attention,CA)模块。由于SE 模块忽略了特征图中感兴趣目标的位置信息,而位置信息对生成空间注意力图很重要,所以CA 模块对每一张特征图沿横向和纵向分别使用平均池化获取不同方向上的信息,然后将获得的信息进行拼接操作,使用1×1 卷积进行降维,将降维后的信息沿着空间维度进行分解,之后分别使用1×1卷积进行升维操作,最后将获得的信息与特征图对应相乘。使用CA 模块增加的参数和计算量相比SE 模块更少,提高的模型的应用精度更高一些。
根据上述内容,注意力机制模块研究存在两个问题:1)怎样在使用注意力机制模块提高模型应用精度的同时,增加更少的参数和计算量;2)从SE 的通道注意力到BAM 的空间注意力,与后来的CA 模块的位置信息,表明特征图中可能仍存在着没有被利用的信息。
针对上述问题,本文在逐维度卷积高效网络(Dimension-wise convolutions for efficient Network,DiceNet)[11]使用的卷积方法基础上提出了基于挤压激励的轻量化注意力机制模块:高度维度挤压激励(Height Dimensional SE,HDSE)模块和宽度维度挤压激励(Width Dimensional SE,WDSE)模块,分别在特征图的高度维度和宽度维度上进行挤压激励操作,捕获特征图的信息,在提高模型应用精度的同时,增加比SE 模块、CA 模块、CBAM 更少的参数和计算量,同时说明了特征图中仍存在着可利用的信息。
1 相关理论
1.1 DiceNet的卷积方法
卷积核的可接受域有限,在通道维度上无法获得特征图全部有用的信息。DiceNet 不再局限于常规的通道维度卷积,它采用多维度卷积操作,对每一层的特征图分别在通道维度、高度维度和宽度维度上做卷积提取特征信息,进而提高模型的精度,三种卷积类型如图1 所示。图1 中的H和W表示特征图的高和宽,D和n分别表示特征图通道数目和卷积核尺寸。图1(b)、(c)中的卷积核通道数目分别与特征图的高度和宽度的大小相等。
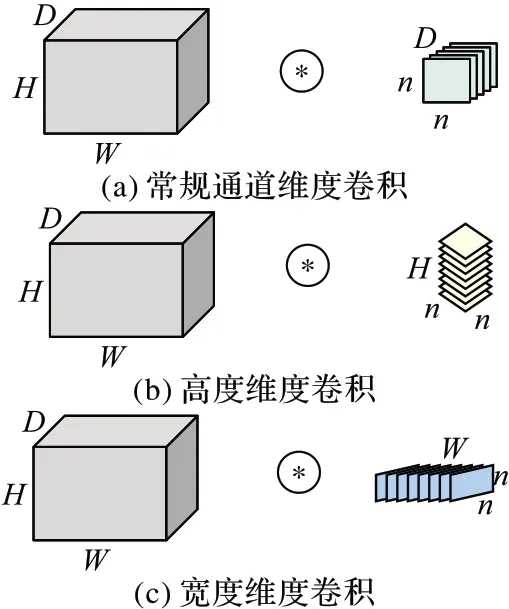
图1 三种类型的卷积Fig.1 Three types of convolutions
DiceNet 使用多维度卷积操作证明了在特征图的高度维度和宽度维度上存在模型可用的信息,为本文的方法提供了重要的理论支持。
1.2 挤压激励操作
挤压激励操作由Hu 等[6]于2018 年提出。由于标准的卷积操作无法捕获特征图通道之间的关系信息,SE 模块通过全局池化和全连接层构建特征图通道间的相互依赖关系,使用全局平均池化使网络模型捕获特征图通道的全局信息,这是卷积操作无法做到的。
如图2 所示,SE 模块主要由三部分组成:挤压操作(squeeze)、激励操作(excitation)以及特征图重标定(scale)操作,完成对特征图通道自适应关系的重新校准。首先使用全局平均池化进行挤压操作提取每个特征图通道的全局信息,如式(1)所示:

图2 SE模块Fig.2 SE module

其中:Fsq表示挤压操作;U表示特征图张量;c表示通道索引。
然后,将挤压操作得到的特征向量Z输入到激励操作中,如式(2)所示:
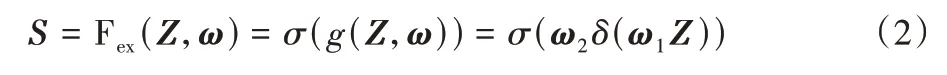
其中:Fex表示激励操作;ω1与ω2分别是全连接层或者卷积层的降维权值与升维权值;σ表示Sigmoid 函数;δ代表线性整流函数(Rectified Linear Unit,ReLU)。
最后,将通道权值向量S与U对应相乘,得到重标定的特征图,将重标定的特征图输入下一卷积层继续执行。
上述就是挤压激励操作的全部过程。当前,作为经典的注意力机制模块,挤压激励操作仍被广泛使用于图像分类、目标检测等领域中。
2 HD-SE和WD-SE模块
卷积神经网络模型卷积层输出的特征图U∈RC×H×W是一个包含深度、高度与宽度的三维张量。常规的挤压激励操作是在深度维度上,以每个特征图的通道为单位去处理。而HD-SE 模块是从特征图的高度维度去捕获有用的信息,增强高度维度上的每一个特征图张量。在将特征图输入到HD-SE 模块进行操作之前,首先将特征图按照高度维度转置成U1∈RH×C×W。然后,HD-SE 模块使用全局平均池化对U1进行挤压操作,得到Y∈R1×1×H特征向量;之后使用降维卷积模块对Y进行降维得到Y1∈R1×1×H/r,使用升维卷积模块对Y1进行升维得到转置后的每个特征图的权重系数Y2∈R1×1×H;将Y2与U1对应相乘,得到重标定的转置特征图;最后,将惩罚系数β运用到挤压激励后的U1中,U1恢复到RC×H×W维度,输入到下一个卷积层。
WD-SE 模块与HD-SE 模块的不同之处是WD-SE 模块是对在宽度维度上转置后的特征图进行操作。WD-SE 模块首先将特征图转置成U2∈RW×H×C,之后在U2上使用全局平均池化,得到Z∈R1×1×W,先后使用升维卷积块和降维卷积块,得到转置后的每个特征图的权重系数,将权重系数与U2对应相乘,将处理后的特征图乘以惩罚系数β。最后将U2转置回原来的维度,输入到下一个卷积层。
HD-SE 模块的整个处理过程,如图3 所示。转置之前,特征图的高度为H,宽度为W,个数为C,在使用tran-H 操作在高度维度上转置之后,特征图高度变为C,宽度不变,个数变为H。Fsq(·)、Fex(·,ω)和Fscale(·,·)与图2 中的含义相同,分别表示挤压操作、激励操作和特征重标定操作。⊗符号表示相乘操作,β表示惩罚系数。因为WD-SE 模块与HD-SE 模块极为相似,此处不再给出其处理过程。

图3 HD-SE模块的流程Fig.3 Flow of HD-SE module
HD-SE 模块或者WD-SE 模块都对特征图进行转置处理后进行挤压激励操作。因为转置操作会破坏掉特征图正常的结构信息,将转置后的特征图进行挤压激励操作,在得到对模型有用的信息的同时,会获取到一些干扰、无用的特征。所以,本文提出的HD-SE 和WD-SE 模块中使用惩罚系数β,能削弱特征图转置操作带来的干扰。在模型训练测试初始阶段,惩罚系数β在削弱无用信息的同时,也会对特征图潜在的有用特征造成影响,但随着模型的不断学习,这种影响会越来越小。
当前,主流的卷积神经网络结构包括简单的卷积块的堆叠,如VGGNet(Visual Geometry Group Network)[12];残差连接结构,如ResNet(Residual Network)[13];深度卷积和逐点卷积结构,如MobileNetV1[14];在MobileNetV1 和ResNet 的基础上提出的倒残差结构,如MobileNetV2[15]。本文将提出的HDSE 和WD-SE 模块分别嵌入这四种不同的结构中。为了与SE 模块、CA 模块和CBAM 公平比较,HD-SE 与WD-SE 的嵌入方式是单独嵌入,不将两者级联或者并联嵌入,以验证其作用,具体结构如图4 所示。图4(a)和(b)分别是HD-SE、WD-SE 的详细结构,Transpose 表示转置操作,GAP(Global Average Pooling)表示全局平均池化操作;图4(c)~(f)中HDSE/WD-SE 表示嵌入HD-SE 或者WD-SE。在VGGNet 简单的卷积块堆叠结构中,一个完整的卷积操作包括卷积+BatchNorm+ReLU,所以本文将HD-SE、WD-SE 嵌入ReLU 函数之后,如图4(c)所示;在ResNet 残差结构中,一个残差块中包括2 个卷积操作,将HD-SE、WD-SE 嵌入于第2 个卷积操作之后,能够获得更多的特征图隐藏的信息,如图4(d)所示;在MobileNetV1 深度卷积和逐点卷积结构中,深度卷积是通过廉价的操作提取特征,而逐点卷积作用是融合特征图中的信息,逐点卷积之后的特征图包含的信息比深度卷积处理后的更丰富,所以将HD-SE、WD-SE 嵌入到逐点卷积之后更为合适,如图4(e)所示;在MobileNetV2 的倒残差结构中,使用文献[10]在结构中嵌入的位置,如图4(f)所示。

图4 HD-SE与WD-SE模块的嵌入位置Fig.4 Embedding positions of HD-SE and WD-SE modules
3 实验与结果分析
3.1 实验设置
本文实验环境为Xeon Gold 5120 处理器,NVIDIA GeForce RTX 2080 11 GB 显存,软件环境为Ubuntu16.04,CUDA10.1。使用PyTorch1.4.0[16]深度学习框架,在CIFAR10/100[17]分类数据集上进行验证,CIFAR10/100数据集包含50000张训练图片和10000张测试图片,分别含有10/100个类别,在VGGNet、ResNet的子模型VGG16、ResNet56和MobileNetV1、MobileNetV2模型上进行实验验证。
常规的卷积神经网络,如VGG16、ResNet56 网络中,使用SE 模块时,由于网络模型卷积层输出的特征图通道数远远大于缩减率r,所以缩减率通常根据经验设置为4、16、32 或64。本文提出的HD-SE 模块与WD-SE 模块的操作对象是将特征图在高度维度和宽度维度转置后的特征张量,转置后的特征图数目为H(H=W)。在上述网络模型中,随着卷积层数的增加,特征图的高和宽是递减的,会出现转置后的特征图通道数目小于缩减率最小值(r=4)的情况,所以当H与W小于缩减率r时,本文设定r等于H。
本文将提出的HD-SE 和WD-SE 与SE、CA、CBAM 和ECA模块在测试精度、增加的参数量和计算量三类指标上进行比较。为了能够让上述四种模型对CIFAR10 和CIFAR100 进行训练测试,本文使用文献[18]提供的VGG16 和ResNet56 变体模型,文献[19]提供的MobileNetV1 和MobileNetV2 变体模型,以适合CIFAR 数据集32×32 分辨率大小的图片。
基本的训练参数设置与文献[18]相同。VGG16、ResNet56 和MobileNetV2 在CIFAR10 和CIFAR100 数据集上,训练160 个epoch,训练批次和测试批次设为64,初始化学习率设为0.1,并在第80 和第120 个epoch 减少1/10,动量设置为0.9,权值衰减设为0.000 1。在MobileNetV1 上,训练100个epoch,学习率初始化与VGG16、ResNet56 和MobileNetV2相同,在第50 和第75 个epoch 减少1/10。使用Cross-Entropy损失函数,利用随机梯度下降(Stochastic Gradient Descent,SGD)学习方法。将简单的数据增强操作,如随机裁剪和随机水平翻转运用于训练集。为了避免参数动荡带来的精度误差,每个实验本文都运行3 次,取3 次的平均值作为最终结果。为了让HD-SE 和WD-SE 起到更好的作用,在VGG16 和MobileNetV1中,惩罚系数β,设置为0.1;在ResNet56、MobileNetV2 设置为1。
3.2 实验结果
1)VGG16。
将SE、CA、CBAM、ECA 和本文提出的HD-SE、WD-SE 分别嵌入VGG16 中,在上述设置下进行实验,实验结果如表1和图5 所示。在CIFAR10 上:与SE、CA 和CBAM 相比,HDSE 的测试精度提升了0.17、0.11、0.26 个百分点;参数量降低了0.9×106、0.18×106、0.29×106;计算量降低了0.9×106、1.07×106、0.27×106。在CIFAR100 上:与SE、CA 和CBAM 相比,WD-SE 的测试精度提升了0.77、0.63、1.53 个百分点;计算量降低了0.9×106、1.07×106、0.27×106;HD-SE 测试精度为73.81%,虽比WD-SE 测试精度差,但比其余模块的测试精度好。HD-SE、WD-SE 与ECA 相比较,参数量和计算量相似,但HD-SE 和WD-SE 的测试精度比ECA 高。六种模块的训练损失与测试精度如图5 所示。
图5 六种模块在VGG16上训练损失与测试精度的比较Fig.5 Comparison of training loss and test accuracy of six modules on VGG16
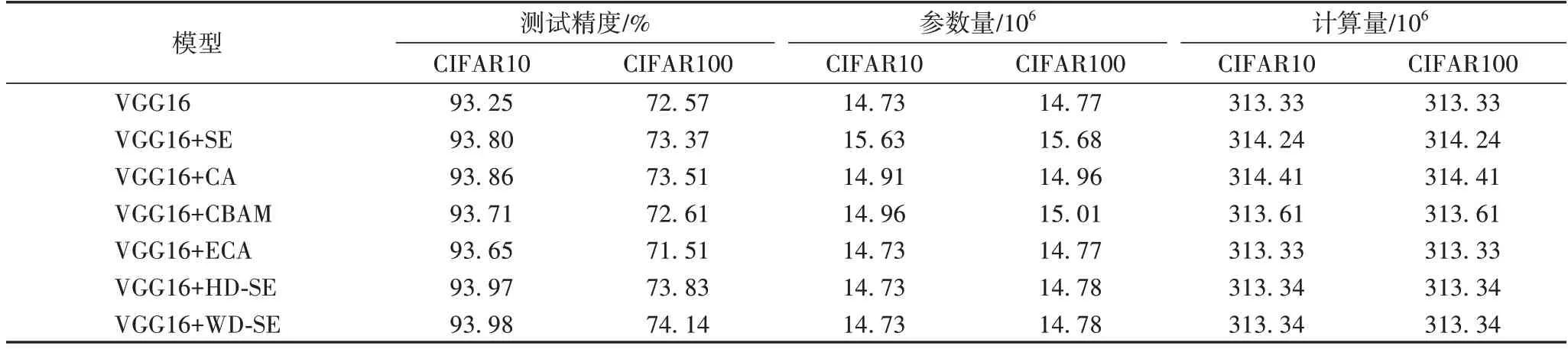
表1 VGG16在CIFAR10/100数据集上的结果Tab.1 Results of VGG16 on CIFAR10/100 datasets
2)ResNet56。
将SE、CA、CBAM、ECA 模块和本文提出的HD-SE 和WD-SE 模块按照图4(d)嵌入ResNet56 模型中,实验结果如表2 和图6 所示。HD-SE 模块在CIFAR10 上的结果:与SE 相比,测试精度提升了0.09 个百分点;与CA、CBAM 相比,测试精度降低了0.3、0.14 个百分点;与SE、CA 相比,参数量降低了0.02×106;与SE、CA、CBAM 相比,计算量降低了0.01×106、0.46×106、1.18×106;WD-SE 模块测试精度为93.84%,与HDSE 效果相近。WD-SE 模块在CIFAR100 上的结果:与SE、CA、CBAM 相比,测试精度提升了0.27、0.31、0.28 个百分点;参数量降低了0.03×106、0.03×106、0.01×106;计算量与CIFAR10 下的HD-SE 相同;HD-SE 测试精度为72.39%,与WD-SE 相比,降低了0.14 个百分点。HD-SE 和WD-SE 增加的参数量和计算量与ECA 相比,增加了0.01×106,但在CIFAR10 上三种模块实现的结果相似。在CIFAR100 上,与ECA 相比,HD-SE 和WD-SE 实现了更好的测试精度。训练损失和测试精度详情如图6 所示。
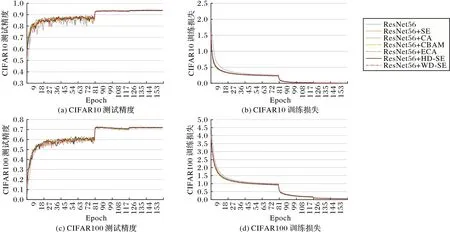
图6 六种模块在ResNet56上训练损失与测试精度的比较Fig.6 Comparison of training loss and test accuracy of six modules on ResNet56
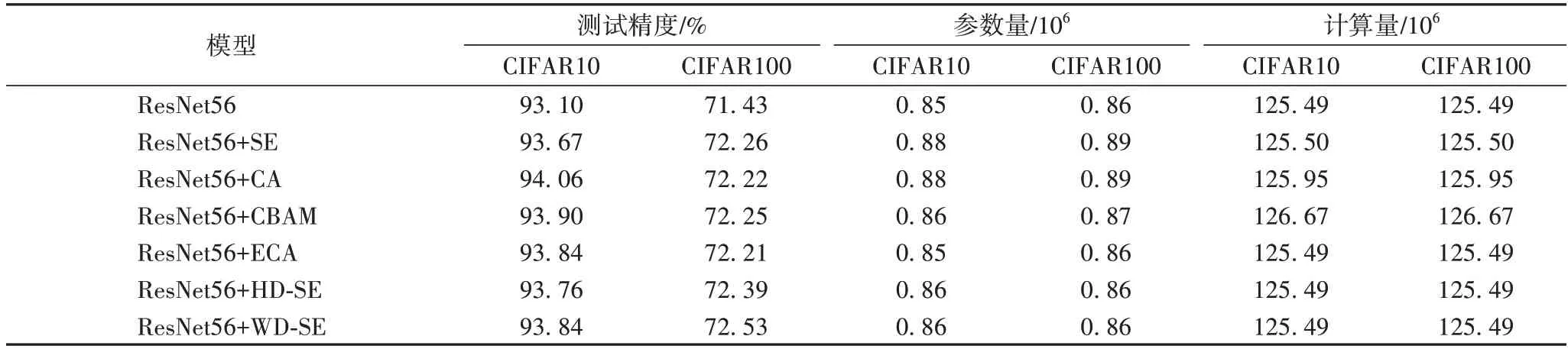
表2 ResNet56在CIFAR10/100数据集上的结果Tab.2 Results of ResNet56 on CIFAR10/100 datasets
3)MobileNetV1。
将SE、CA、CBAM、ECA 模块和本文提出的HD-SE、WDSE 模块分别嵌入MobileNetV1 逐点卷积之后进行实验。实验结果如表3 和图7 所示。HD-SE 模块在CIFAR10 上的结果:与SE、CA、CBAM 和ECA 相比,测试精度提升了0.31、0.27、0.46、0.65 个百分点;与SE、CA 和CBAM 相比,参数量降低了1.92×106、0.37×106、0.48×106;计算量降低了1.91×106、1.66×106、0.17×106;与ECA 相比,计算量增加了0.01×106。WD-SE 实现了91.92%的测试精度,比HD-SE 低,但比其余模块高一些。在CIFAR100 上:HD-SE 和WD-SE 比其余模块实现了更好的结果,其中HD-SE 的测试精度比WD-SE高0.15 个百分点,本文提出的HD-SE 和WD-SE 增加的参数量和计算量比SE、CA 和CBAM 都要低。训练损失和测试精度如图7 所示。

图7 六种模块在MobileNetV1上训练损失与测试精度的比较Fig.7 Comparison of training loss and test accuracy of six modules on MobileNetV1

表3 MobileNetV1在CIFAR10/100数据集上的结果Tab.3 Results of MobileNetV1 on CIFAR10/100 datasets
4)MobileNetV2。
将SE、CA、CBAM、ECA 模块和本文提出的HD-SE 和WD-SE 模块分别嵌入MobileNetV2 倒残差块(Inverted Residuals Block)中的3×3 深度卷积之后,根据上述设置进行的实验结果如表4 所示。HD-SE 模块在CIFAR10 上的结果:与SE 相比,测试精度提升了0.13 个百分点;与CA、ECA 相比,测试精度降低了0.07 和0.18 个百分点;与SE 相比,参数量、计算量降低了2.25×106、2.26×106;WD-SE 的测试精度为93.43%,与SE 相似。在CIFAR100 上:HD-SE 的测试精度为75.01%,比WD-SE 降低了0.14 个百分点。训练损失和测试精度如图8 所示。
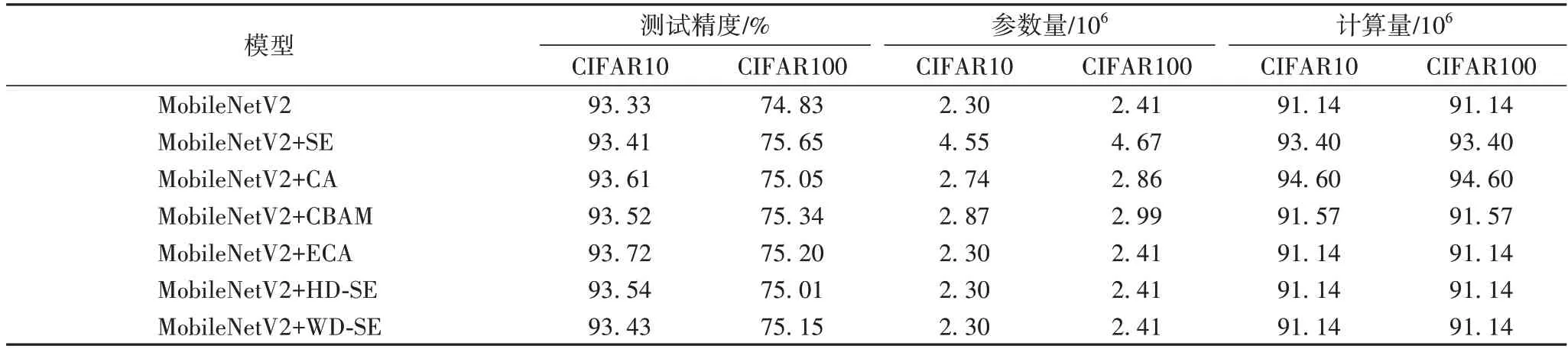
表4 MobileNetV2在CIFAR10/100数据集上的结果Tab.4 Results of MobileNetV2 on CIFAR10/100 datasets
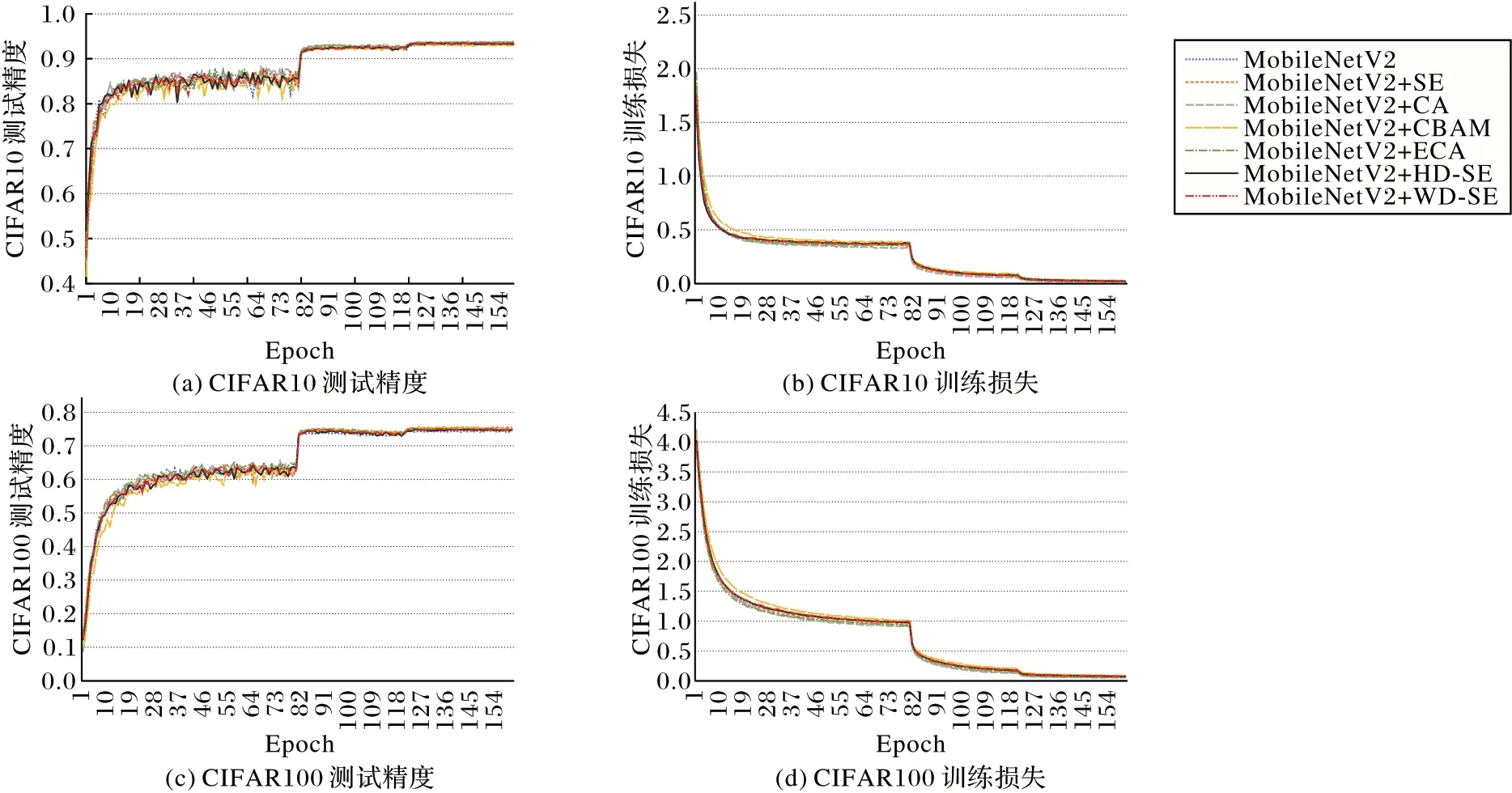
图8 六种模块在MobileNetV2上训练损失与测试精度的比较Fig.8 Comparison of training loss and test accuracy of six modules on MobileNetV2
3.3 实验结果分析
从实验结果可看出:本文提出的HD-SE 与WD-SE 模块能够增强网络模型的学习能力,提高模型应用精度。嵌入HD-SE 与WD-SE 模块对网络增加的参数和计算量比SE、CA模块和CBAM 要少得多,可以忽略不计。在VGG16 与MobileNetV1 中,本文设置的惩罚系数β为0.1,而在ResNet56 残差网络和MobileNetV2 中设为1。通过实验发现,β为1 时,VGG16 与MobileNetV1 在CIFAR10/100 数据上的精度比SE 与CA 模块低,甚至还会低于基础模型的精度;同样,在残差网络ResNet56 和MobileNetV2 中,当β为0.1 时,仍然会低于基础模型的精度。VGG16 和MobileNetV1 两个模型与ResNet56 和MobileNetV2 的不同之处,是前两者没有残差连接,而后两者有残差连接。似乎是因为残差连接保留了原特征图的结构信息,而不需要惩罚系数,所以在ResNet56 和MobileNetV2 中惩罚系数设为1。在VGG16 与ResNet56 模型中,HD-SE、WD-SE 模块会加速模型的收敛,比SE、CA、CBAM和ECA 模块要好,如图5~6 所示。在MobileNetV1 中,HDSE、WD-SE 使网络最后的收敛损失比SE、CA、CBAM 大,但实现的测试精度相似,甚至更好。这是因为在特征图的高度维度与宽度维度进行挤压激励虽能够捕获对模型有用的信息,但同时破坏了特征图的正常的结构信息,导致模型收敛损失较大。
HD-SE 与WD-SE 模块在MobileNetV2 上的实验结果表明,与SE、CA 模块和CBAM 相比,虽然测试精度降低了,但减少了参数量和计算量;与ECA 模块相比,HD-SE 和WD-SE 模块不具备优势,可能是因为MobileNetV2 中的多种结构(深度卷积、逐点卷积、残差连接)在提取原图片特征时,提高了特征图信息的复杂性;HD-SE 与WD-SE 模块中的转置操作又可能会进一步加深特征图信息的复杂性,使其阻碍了更多有用信息的提取。所以,HD-SE 与WD-SE 模块在MobileNetV2上的性能比ECA 模块稍差。
实验结果表明:与SE、CA、CBAM 和ECA 模块相比,本文所提HD-SE 和WD-SE 模块在结构简单的卷积神经网络模型,如VGG、ResNet 和MobileNetV1 中更具优势。同时可以看出,在一般的普通卷积块的堆叠或加上残差连接的网络模型中适合使用WD-SE 模块,在如MobileNetV1 结构的模型中适合使用HD-SE 模块。
4 结语
本文为了解决注意力机制模块研究领域存在的问题,以DiceNet 中的逐维度卷积为理论基础,借鉴挤压激励方法,设计了基于挤压激励的两种轻量化注意力机制模块。通过实验结果表明,本文提出的模块是可行的。未来将在更多图像视觉上进行实验,进一步优化其结构。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
成都信息工程大学学报(2022年2期)2022-06-14
北京大学学报(自然科学版)(2022年1期)2022-02-21
一重技术(2021年5期)2022-01-18
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
北京航空航天大学学报(2020年10期)2020-11-14
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年11期)2019-07-04
