
基于DE 蝙蝠算法的混合推荐模型设计*
2022-08-26 09:39何昌隆
计算机与数字工程 2022年7期
何昌隆 文 斌
(成都信息工程大学通信工程学院 成都 610225)
1 引言
在计算机和网络技术快速发展的今天,推荐系统作为解决信息过载的有效手段而愈来愈受到商业界和研究者的重视。
推荐系统的主要思想在于通过分析用户的行为信息,构建用户的兴趣偏好模型,并以此向用户推送潜在需求信息。但由于主流单一的推荐算法有其各自的不足,如数据稀疏[1]、推荐准确度不高等问题,于是通过将两种或两种以上的推荐技术进行融合以期待获得更好推荐效果的混合推荐系统[2]应运而生,比如Marcos提出了一种结合用户行为信息与内容推荐的混合推荐系统,并应用在音乐推荐领域[3]。湖南大学的谢晓赟提出了基于内容和协同过滤的混合推荐模型,并用卡尔曼滤波来反馈调节权值[4]。Suriati把基于内容与基于物品的协同过滤两种算法进行加权混合推荐并应用在电影领域[5]。但其中大部分加权混合推荐系统的权值分配都存在推荐系统冷启动效果不佳及难以收敛到全局最佳的问题。
蝙蝠算法是一种高效的生物启发式算法,由YANG XinShe教授在2010年提出[6],并广泛应用于科研与工程问题中。肖辉辉等提出将差分进化算法嵌入到蝙蝠算法中,对蝙蝠算法的易于陷入局部极小点等问题做出了改善(DEBA)[7]。
本文针对单一推荐算法有其各自的不足,而在以往的研究中,加权混合推荐模型通常使用算术平均加权法、几何平均加权法或者线性回归等方法来进行模型权值的分配,冷启动效果不佳以及难以收敛到全局的最佳权值的问题,提出一种基于DE 蝙蝠算法的加权混合推荐模型,将多种经典的推荐算法使用DE蝙蝠算法进行线性融合从而得到更好的推荐效果。
2 主流推荐算法
2.1 基于内容的推荐算法
基于内容的推荐算法(CB)[8]思想是找出与用户点击、购买或好评的物品类似的物品进行推荐,算法流程如下。
Step1:抽取所有物品的特征标签来建立物品的属性模型,通常由向量来表示,向量中每一个元素都由物品的特征进行填充。
Step2:利用用户喜欢或者购买的物品数据来构建用户的兴趣特征。
Step3:通过生成用户兴趣特征和物品的特征矩阵的相似度进行推荐,或者依据相似度预测评分,相似度的计量方式有许多种,如:欧几里得距离,皮尔逊相关距离,余弦相似度[9]等。这里选择使用余弦相似度,见式(1):
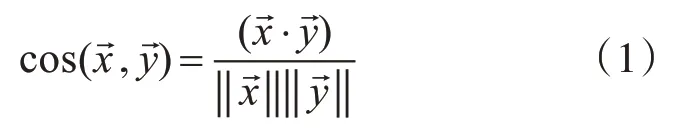
2.2 协同过滤推荐算法
协同过滤推荐算法(CF)[10]思想是对与以前感兴趣的物品类似的物品进行推荐。与2.1小节所诉算法不同之处在于,基于物品的协同过滤推荐算法是通过用户的行为数据来对物品中的相似程度进行定义,其相似度的计量方式与基于内容的推荐算法相同,算法的基础流程也是分为三步。
Step1:对用户和物品等相关历史数据进行整理并建立用户-物品矩阵。
Step2:根据用户的以往的点击评分或者购买行为,对物品之间的相似程度进行计量,构建物品-物品相似度矩阵。
Step3:根据物品之间的相似度矩阵和用户的历史记录计算用户对各个物品的兴趣度或者评分预测,最后根据用户对物品兴趣度或者预测评分的大小进行推荐。
2.3 基于矩阵分解的推荐算法
在矩阵分解模型(MF)[11]中,历史的用户-物品评分矩阵R 可以分解为用户兴趣矩阵U 与物品特征矩阵V两个低维矩阵,见式(2):

使用已有的评分数据进行训练,忽略缺少的评分,并将训练后的两低维矩阵(U,V)相乘,得到新的评分预测矩阵,进而根据预测评分推荐用户。具体评分预测见式(3):

3 基于DE蝙蝠算法的混合推荐模型设计
3.1 使用DE蝙蝠算法权值寻优
DE 蝙蝠算法混合推荐模型是通过多个推荐算法加权混合得到的,其中使用DE 蝙蝠算法迭代寻优分配全局最佳权值是整个混合推荐模型的核心部分。
蝙蝠算法(Bat Algorithm)是一种高效的生物启发式算法,由2010 年杨教授(YANG XinShe)所提出,能有效地搜索到全局最优解并具有并行性,分布式,收敛速度快等优点。它通过生成一组随机解模拟自然界中的蝙蝠,并设计适应度寻找到当前种群的最佳值,然后模拟蝙蝠的回声定位加强迭代中的局部搜索能力,在值域内进行飞行迭代不断更新当前种群的最优解直至收敛得到最终全局的最优解,最后输出作为各个推荐模型的权值进行分配。设计适应度函数f(xn)来对种群中蝙蝠的每一次更迭做出评估,见式(4),所述模型权值变量为X=(x1,x2,…,xd)T,定义虚拟蝙蝠位置xi速度vi值更新的公式(5)~(6):
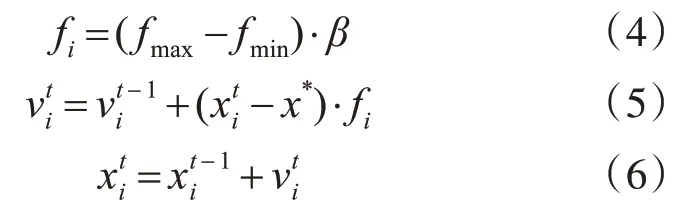
式中β属于在一个均匀分布的[0,1]的随机采样值;fi是蝙蝠i 的搜索频率,fmax,fmin是搜索频率范围;、各自表示单个蝙蝠i 处于t 和t-1 时间的速度;、各自表示单个蝙蝠i 在t 和t-1时刻的位置;x*代表当前所搜索到的最优解。
当寻找到新猎物(新解)时,其蝙蝠的响度Ai与脉冲发射率ri也会产生变化,见式(7)~(8):
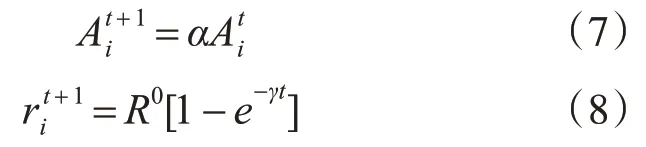
式中:α为子蝙蝠的响度衰减系数;γ为子蝙蝠的频率增强系数;R0为最大脉冲率。
而DE蝙蝠算法则是为了提高蝙蝠算法的收敛精度,收敛速度,以及鲁棒性,将差分进化算法(DE)[12]融入基本的蝙蝠算法,在更迭蝙蝠位置时进行差异化的演化。差分进化算法(DE)的基本步骤如下。
Step1:变异
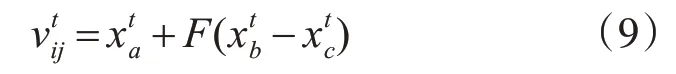
式中:xa,xb,xc是在蝙蝠中随机选择的个体,且互不相等,F为变异因子。
Step2:交叉
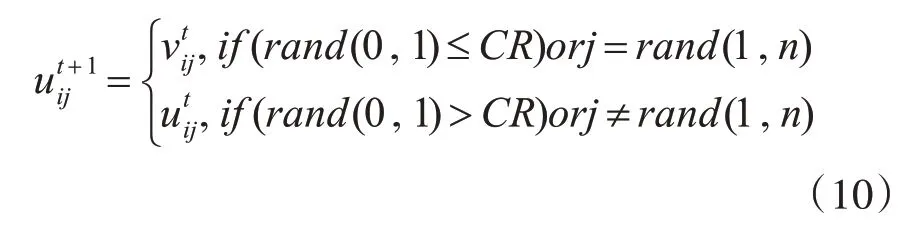
式中:CR 代表交叉概率,范围在[0,1]之间;该式确保uij(t+1) 中至少有一个分量由vi(t)提供。
Step3:选择
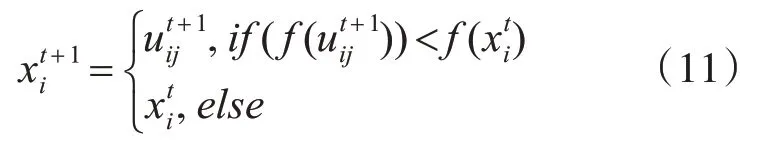
3.2 DE蝙蝠算法构建的混合推荐模型
本文所提出的新型加权混合推荐模型,即DE蝙蝠算法混合推荐模型是将蝙蝠算法中的迭代寻优与推荐模型相结合的一种加权混合推荐模型。它使用蝙蝠算法优秀的全局寻优能力分配一个适当的权值,来对多种主流的推荐模型(CB.CF,MF)进行加权融合,生成最终的用户评分预测矩阵进行物品推荐,提高推荐准确率。其中对于多个推荐模型融合配比权重的思路:将(X1,X2,…,Xm)T作为m个推荐算法的模型权值目标变量,X1,X2,…,Xm代表着各个模型的权重,通过蝙蝠算法更迭寻优为所有模型分配全局最佳权重X,实现共赢,定义各模型加权算法见式(12):
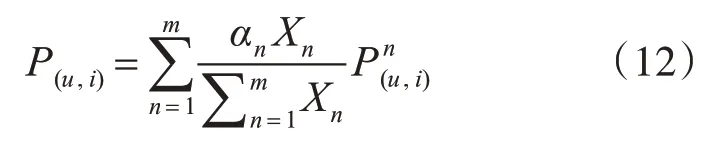
式中,表示在第n 个模型里,用户u 对物品i 评分估计,αn表示模型n 的个性化系数,分配初始权值时设为1。模型n的权重为该模型经过蝙蝠算法更迭寻优的最佳权重Xn与个性化系数αn之积在所有模型的全局最佳权重之和中所占的比例。
在DE 蝙蝠算法混合推荐模型的实现上,选取在第2 节所介绍的基于内容(CB),协同过滤(CF),矩阵分解(MF)这三种主流的推荐算法进行加权混合推荐,并使用差分进化蝙蝠算法迭代寻优分配权值,得到最终结果。其具体流程如下:
Step1:计算基于内容的推荐算法的预测评分Pcb(u,i)。
Step2:计算基于物品的协同过滤推荐算法预测评分Pcf(u,i)。
Step3:计算基于矩阵分解的推荐算法预测评分Pmf(u,i)。
Step4:使用蝙蝠算法更迭寻优拟合数据集分配权值,具体步骤如下:
1)首先将三个模型的权值,看作在三维空间随机分布‘蝙蝠’的位置Xi=(xcb,xcf,xmf)T,蝙蝠种群数量自己决定。
2)定义适应度公式f(Xi),见式(13),评价每‘蝙蝠’的适应度,适应度最高的‘蝙蝠’位置即是当前全局最优。

3)根据3.1 小节所诉的迭代寻优方法,‘蝙蝠’往当前最佳位置不断飞行,模拟真实蝙蝠的回声搜索猎物,多次更迭得到最终的全局最优解Xcb,Xcf,Xmf,作为最终权值输出。
Step5:据式(12),加权混合得到最终的预测矩阵P(u,i),作为最终预测结果输出。
4 实验与结果分析
4.1 实验数据集
实验使用MovieLens 公开数据集(https://grouplens.org/datasets/movielens/)来对算法的效果进行验证。该数据集中包含了671 位用户对9066 部电影的10k 条评价数据,其中评分的分数范围在1~5之间。为了有效地对各个算法的推荐效果进行验证,实验将数据集分为训练集,拟合集以及测试集,其比例分别为80%,10%和10%,三种数据集各自独立不重复。其中训练集用于构建推荐算法的预测矩阵,拟合集用于混合推荐模型中的多个推荐算法权值的分配,最后测试集则用于实验算法的效果。
4.2 评价标准
推荐算法的评价指标多种多样,但其本质都是通过其预测评分矩阵与实际值之间的偏差进行推荐效果的评估。实验使用常用的评估标准中的经典指标即均方根误差(RMSE)[13]以及绝对平均误差(MAE)[13],其中绝对平均误差表示计算评分与真正评分绝对差的均值,而均方根误差表示计算评分与真正评分的离散度,公式如下:

上式中的pi代表预测结果,ri代表实际值,E 代表测试集。
4.3 实验结果与分析
首先采用在第2节中所介绍的基于内容(CB),协同过滤(CF),矩阵分解(MF)这三种传统的推荐算法。然后选取加权混合模型中常用的等权融合法(AW)[14],拟合数据集并通过线性回归来分配最终权值的线性回归模型(LR)[15]以及DE 蝙蝠算法混合推荐模型,这三种将CB,CF,MF 三种单一的推荐算法进行加权混合的混合推荐模型。通过以上算法总计设计六组实验在MovieLens公开数据集基础上进行实现,来探究推荐算法的有效性。
实验流程是在训练集得到三种经典算法的预测矩阵,加权混合推荐算法使用三种算法的预测矩阵在权值拟合集更迭得到最终的权值分配,组合得到加权混合推荐算法的预测矩阵,最后在测试集中计算评价指标RMSE 与MAE 来反映各个推荐算法的准确度,实验结果见表1。
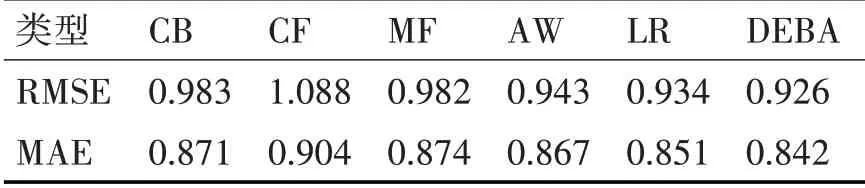
表1 实验结果
结果柱状图展示见图1、图2。
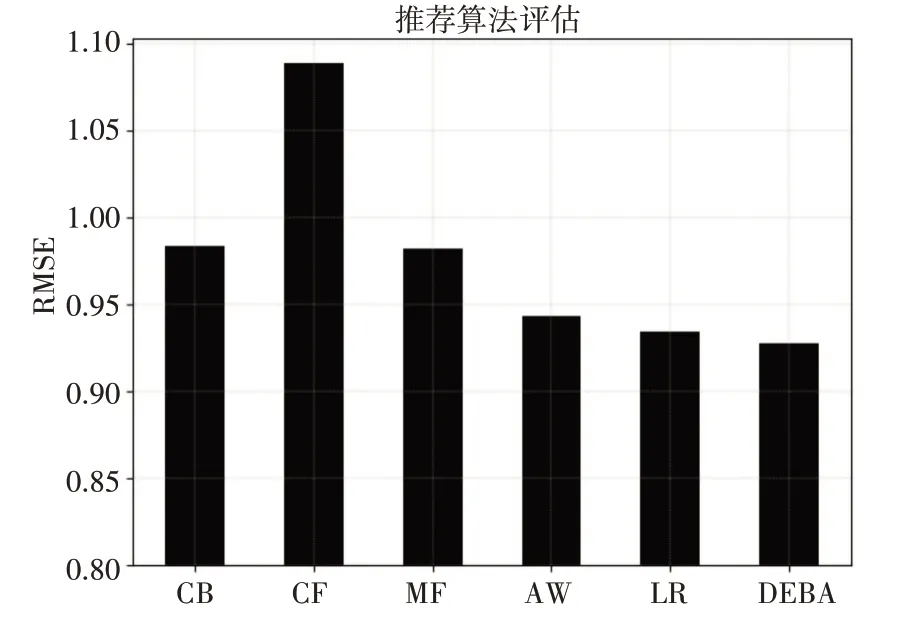
图1 RMSE指标结果对比图
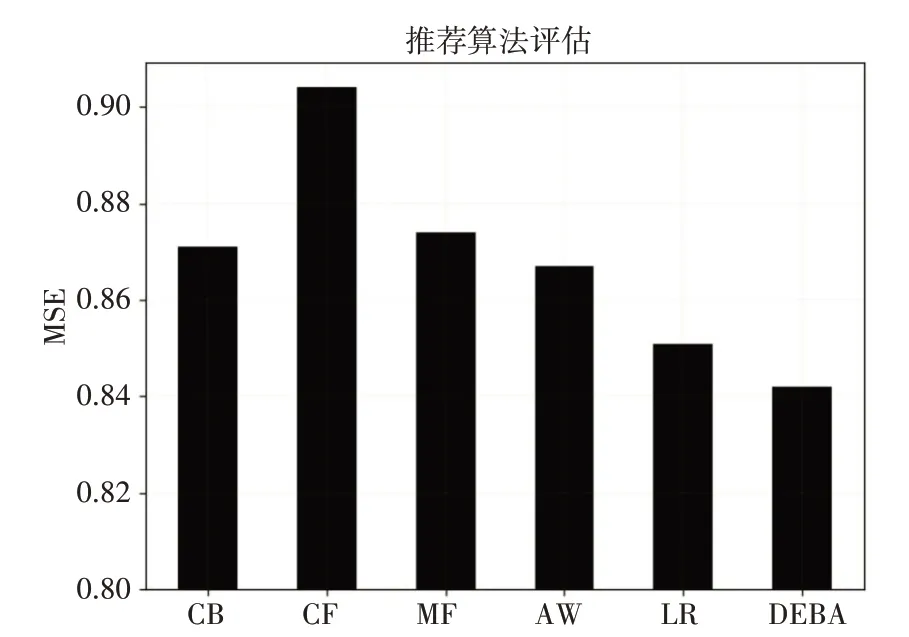
图2 MAE指标结果对比图
接着将MovieLens公开数据集随机选择50%的数据来模拟数据极其稀疏的情况,同样使用上面六种推荐模型得到其预测矩阵,使用评价指标RMSE与MAE 指标来反映各个推荐算法的准确度,实验结果见表2。
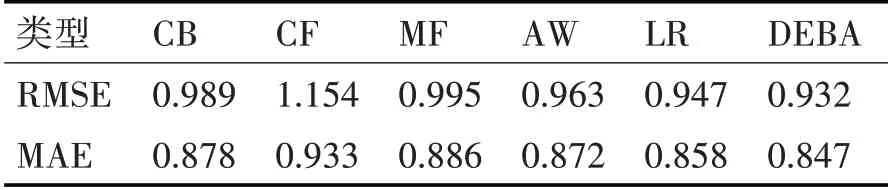
表2 50%数据量实验结果
50%数据量结果柱状图展示见图3、图4。
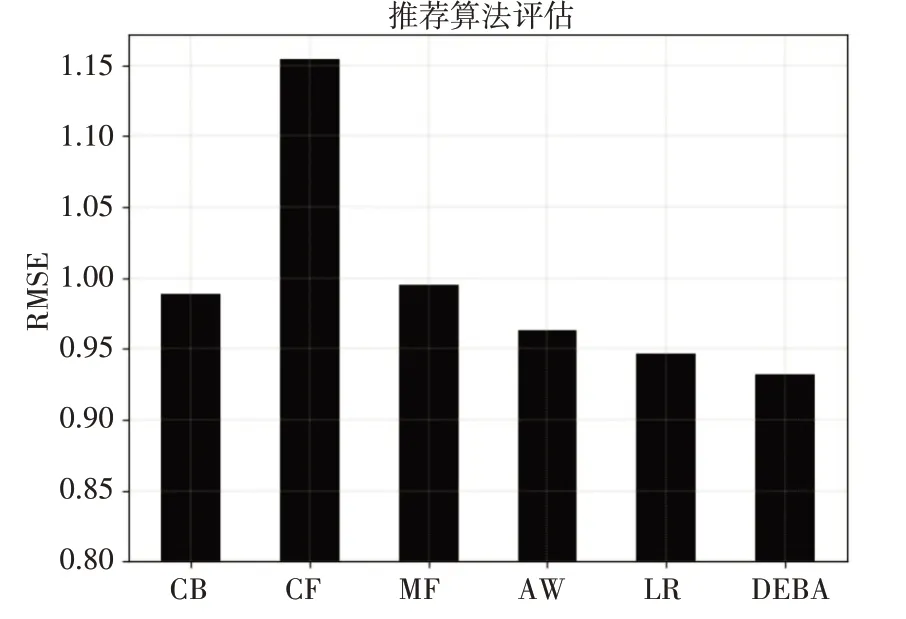
图3 50%数据量RMSE指标结果对比图
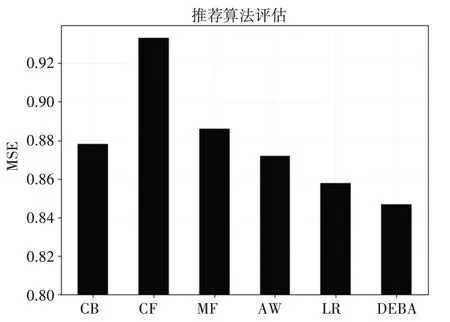
图4 50%数据量MAE指标结果对比图
结果表明DE蝙蝠算法混合推荐模型在预测评分矩阵上对比其他推荐模型具有更好的效果,各模型权值能够快速收敛到全局最佳,在推荐系统数据稀疏的冷启动场景中的表现对比其他推荐模型也有明显的提升。
5 结语
本文针对单一推荐算法数据稀疏,推荐精度不高,常用加权模型研究冷启动效果不佳以及初始权值分配难以收敛到全局最优解的问题,提出了DE蝙蝠算法混合推荐模型,通过差分进化蝙蝠算法优秀的全局寻优能力来分配一个适当的权值,对多种主流的推荐算法(CB.CF,MF)进行加权融合。试验结果说明,在计算预测评分上,与传统的单一推荐算法相比,该算法模型有效地提高了预测准确度,同时对比常用的加权混合模型,该模型的融合度最好,预测误差最小,能够有效地分配最佳初始权值,提高推荐系统性能。但本算法尽管可以自动更迭分配权值,可实时性依旧不足,因此加入反馈调节增强混合推荐模型的实时性与个性化将是下一步的研究方向。
猜你喜欢
读与写·教育教学版(2017年10期)2017-11-10
小溪流(画刊)(2016年12期)2017-02-04
科技视界(2016年1期)2016-03-30
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
物联网技术(2015年7期)2015-07-21
微型小说选刊(2015年5期)2015-06-05
小学生·多元智能大王(2014年5期)2014-07-24
