
基于集成学习的文本摘要抽取方法研究*
2022-08-26 09:39祝超群彭艳兵
计算机与数字工程 2022年7期
祝超群 彭艳兵
(1.武汉邮电科学研究院 武汉 430070)(2.南京烽火天地通信科技有限公司 南京 210019)
1 引言
目前,互联网技术迅猛发展,大量文本信息迅速产生,“信息过载”问题逐渐出现在人们的日常生活中,而互联网的普及也使得人们有了更便捷的方式去获取信息、处理信息。如何在互联网中快速有效地捕捉到关键信息成为目前急需解决的一个问题,自动文本摘要[1~3]被认为是解决该问题的一项关键技术,它能够做到有效地概括出文本中的重要信息。
自动文本摘要研究的意义在于其具有广泛的应用场景,如各搜索引擎关键信息检索、相同主题文本的智能推荐以及舆情监督系统的热点挖掘和专题追踪等。因此,本文希望可以引入文本摘要抽取、集成学习等算法模型实现文本信息自动化的有效抽取,为各应用场景提供一些帮助。
集成学习[4](Ensemble Learning)是一种优化算法,通过将多个单一学习器进行结合,常可获得比单一学习器更加显著的泛化能力。其潜在思想是即使一个弱分类器得到了一个错误的结果,其他弱分类器也有一定概率可将此错误纠正。总体来说,集成学习在一些特定场景学习效果可能不如最优的单一学习器,但是在大部分情况下,集成学习的学习效果更贴近或者超过单一最优学习器,且集成学习的泛化能力要优于单个学习器。
目前国内外关于集成学习算法的应用研究已有很多。高欢[5]等将集成学习思想用于挖掘消费者在线评论的情感倾向,对商家提供服务建议具有重要意义;张玉华[6]等将集成学习思想应用于计算机视觉研究领域进行人体行为识别;刘擎超[7]等基于集成学习对多状态交通情况进行预报。
本文针对单一摘要抽取算法泛化能力弱的问题,提出了利用多种文本摘要抽取算法进行集成学习的文本摘要抽取模型,根据每种算法抽取出的关键句进行非平均投票,最终加权得出分数最高的句子作为摘要句,并且在NLPCC 2017 的中文单文档摘要评测数据集[16]上的实验验证了此方法的有效性。
2 抽取式文本摘要研究综述
国内外对于自动文摘相关的研究是近些年才逐渐发展起来的,但这一概念在20 世纪中期就已被IBM 公司的Luhn[8]提出,Luhn 于1958 年发表了一篇有关自动文摘的论文,开启了一个领域的研究进程,诸多学者加入研究行列,使得该领域的研究越发成熟。目前根据摘要生成方式的不同,将自动文本摘要主要分为抽取式摘要(Extractive Summary)和生成式摘要(Abstractive Summary)[10]两种方式。抽取式摘要,顾名思义,仅从文本中抽取信息,结果均是文本中的原生内容,主要通过计算原文中各句子的重要性排名,再根据排名和句子顺序抽取句子。生成式摘要则旨在分析文本结构并且加以文本语义理解,最后用合理的表达来重新完成摘要内容,更类似于人类阅读文章后总结概括。
目前无监督抽取式文本摘要主要包括三大类,分别是基于统计、图模型[9]以及基于潜在语义的方法。
基于统计类文本摘要算法更着重于文本结构以及浅层信息,比如词汇出现的频率、句子所在位置以及句子长度等信息。基于统计类算法进行摘要抽取,简单、便捷且易于实现,但是仅以文章的表层信息难以挖掘句子的整体语义,而且没有考虑句子的上下文信息,难以全局性地选出符合要求的句子。
基于图模型的方法将文本中的句子表示为图中的节点,通过节点之间的迭代计算得出每个句子的重要程度。Text Rank[11]算法是一种经典的基于图模型的排序算法,算法由Mihalcea,Rada 等提出TextRank,其算法理论基础基于Brin S 和Page L 于1998 年提出的PageRank[12]算法,两者都是排序算法,不过应用场景不同,TextRank 用于文本关键词或者句子的重要性排序任务,PageRank 用于超文本链接的重要性排序问题。但是基于图模型的抽取式摘要也存在着忽视文本主题信息、抽取信息冗余、有效信息覆盖率低等问题,且上述问题并没有得到很好的解决。
基于潜在语义的方法则是使用主题模型挖掘文本隐含主题,通过文本主题分布判断句子的重要性,常见的主题挖掘算法有LDA[13]和BTM[14]。基于潜在语义的方法进行摘要自动提取在一定程度上考虑了句子隐含的语义信息,抽取的句子更加贴合文本的主题分布,但LDA 在确定主题时候也仅是从词形的角度考虑,无法避免同义词的影响和描述复杂的语义。
上述各算法因侧重点不同,所以各自存在一些不足,因此本文基于集成学习,在摘要抽取算法中选择目前较为流行且效果较佳的MMR 算法[15]、TextRank 算法以及LDA 模型,考虑到新闻文本摘要句子的位置信息对全文的影响程度,加入Lead_N 算法(顾名思义,即取文本的前N 句)增加文本首句对摘要的影响力。根据上述四种算法给句子进行加权投票,筛选得分排名靠前的句子作为摘要句,即遵循多个算法都认为重要的才是重要的准则。
3 研究方法
3.1 抽取式文本摘要框架
抽取式自动文本摘要任务主要是结合不同的特征对句子进行打分和排序。为了提取出质量更高、更能代表文本信息的摘要,本文提出一种基于集成学习的无监督文本摘要抽取模型,其步骤如图1所示。
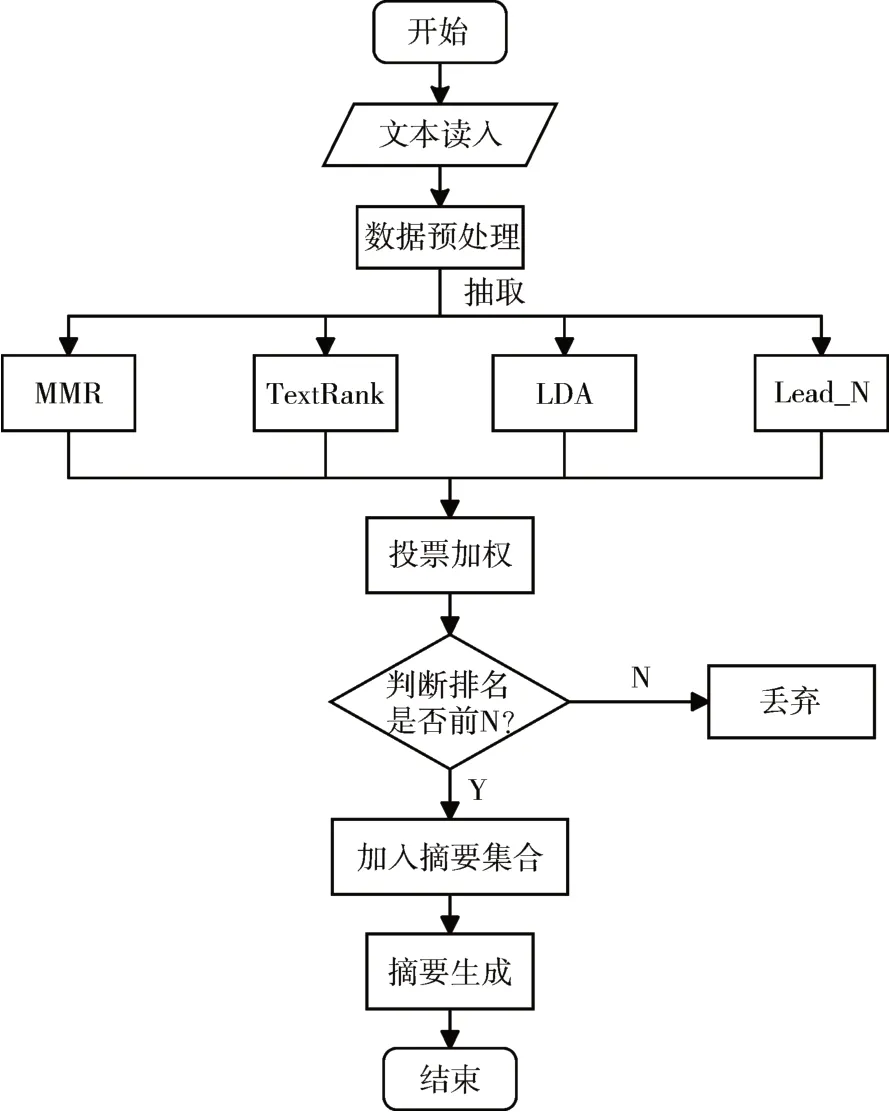
图1 抽取式文本摘要框架流程图
首先是数据的预处理阶段,本文选取的数据是由自然语言处理相关会议发布任务提供的竞赛数据,数据没有经过预先处理,因此需要除去无用的标点符号、特殊字符,然后全角半角字符转换以及中文的简繁体转换,处理结束后将原文与人工标注的摘要分开保存。
第二步是将预处理好的文本通过选择的各种单一抽取算法去提取出对应条数的摘要句。
第三步是对句子进行投票加权,根据每种算法应对单句以及多句摘要的表现结果,赋予每种算法抽取句子不同的权值分数。然后通过多个算法打分后进行投票加权得到每一个句子的加权得分。最终基于总得分对文本中所有的句子进行降序排序,选出排名前N 的句子作为最终抽取的摘要集合。
3.2 摘要句选择
本文选择了目前较为流行且效果较佳的MMR、TextRank、LDA 以及Lead_N 算法进行摘要句子单独抽取。MMR(Maximal Marginal Relevance)中文名字为最大边界相关法,此算法在设计之初是用来计算待查询文本与被搜索文档之间的相似度,然后对文档进行排序的算法,如式(1)所示。
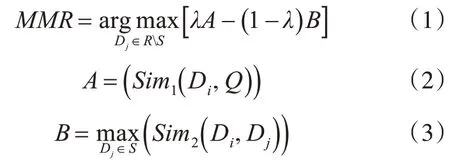
其中A表示被搜索文档与查询文本相似度,B表示当前被搜索文档与之前被搜索文档的相似度,λ为调节参数。为了能够更好地适用于文本摘要抽取任务,将式(1)稍作修改,如式(4)所示。
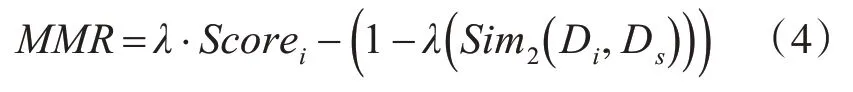
其中Score计算的是当前被选择句子的重要性分值,Di表示当前所选择句子,Ds表示前面已选择的摘要句集合,负号说明抽取摘要集合的句子间的相似度越小越好。此处体现了MMR 的算法原理,即同时考虑到文本摘要的重要性和多样性。这种摘要提取方式与TextRank不同,TextRank只取文本中计算分值高的句子进行排序形成摘要,忽略了所抽取信息的全面性,冗余较高。
从上述描述可知,MMR 算法当抽取多句作为摘要时能更好地考虑到全文信息,冗余较小。因为TextRank、LDA 应用已经非常成熟,这里便不再赘述。关于Lead_N 算法的融入是考虑了新闻文本的特殊性,首句有较大概率与新闻标题相似度高,更能表达新闻含义,故将Lead_N 算法加入,使得本模型更适用于新闻文本摘要抽取任务。
根据抽取摘要的句子数量以及各算法在摘要抽取方面的表现,本模型对各算法抽取的摘要句进行不同权值赋值。抽取单句时无需考虑冗余问题,且考虑到文本结构,故赋予TextRank 算法以及Lead_N 算法较高权重。随着抽取句子数量增加,信息冗余情况出现,故提升MMR算法的权重赋值,并降低Lead_N 算法对摘要结果的影响。权重赋值如表1所示。
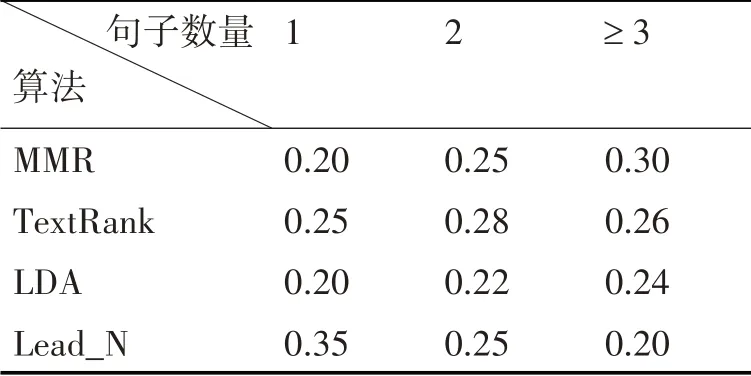
表1 各算法权重赋值
根据上表赋予各算法的权重,对各算法抽取的句子进行加权投票计算,选择出得分最高即最能代表文本信息的句子作为摘要。
3.3 摘要生成
因为根据权重排名得到的句子对于整篇文本来说是无序的,为了贴合人们的阅读习惯,将3.2小节抽取出的摘要句子集合根据其所在文本中的位置进行正序排序,然后将其组合在一起作为最终的摘要。
4 实验验证
4.1 实验数据集和实验环境
本文使用的验证集为NLPCC 2017的中文单文档摘要评测数据集[16]。该数据集测试数据包括两部分,一部分包含人工标注摘要,另一部分只有新闻文本,没有摘要,本文从含有摘要的50000 对新闻以及对应摘要信息中多次随机抽取1000 对进行测试,所抽取新闻文本包含时政、娱乐、体育等各领域新闻。本文算法实现采用的是编程语言Python ,版本为3.6,在Windows 系统下运行,计算机CPU 为Intel Core(TM)i7-9750H @2.6GHz,内存大小为16G。
4.2 评测指标
Rouge[17]系列评测指标是评估文本摘要以及机器翻译相关任务的一组指标。通过比较根据模型得到的候选摘要(以下称为Candidate Summary)与人工标注的参考摘要(以下称为Reference Summary),计算得出相应的分值,来表示通过算法得到的摘要与人工标注的摘要的相似度。本文选取Rouge-1、Rouge-2、Rouge-L 作为本文研究的评测指标。
直观看,Rouge-1 可以代表自动摘要的信息量,Rouge-2 则侧重于评估摘要的流畅程度,但本文进行的是文本摘要抽取任务,并非生成,暂不考虑流畅程度。而Rouge-L 可看成是摘要对原文信息的涵盖程度的某种度量。其中Rouge-N 的计算方法如式(5)所示。
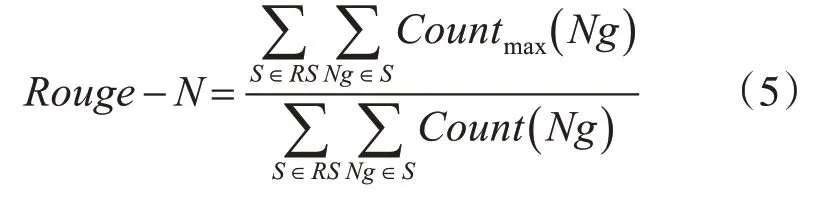
其中,RS表示参考摘要,Ng表示N 元词,Countmax(Ng)表示Candidate Summary 和Reference Summary 同现的相同N-gram 的最大数量,Count(Ng)表示标准摘要中出现的N-gram个数。
Rouge-L 中的L 是LCS(最长公共子序列)的首字母,Rouge-L 考虑的是Candidate Summary和Reference Summary 中最长的公共部分的长度,如式(6)所示。

其中,分子是Candidate Summary 和Reference Summary 中最长的公共部分的单词数量,分母是Reference Summary中的单词数量。
4.3 实验结果分析
在实验中,我们将对比本文提出的模型与四种基线方法进行评测对比,评测任务分为单句以及多句摘要。对比单句摘要是为了找出文本中最能代表文本含义的句子,对比多句摘要则是因为选择的数据为长文本,往往摘要包括多句内容,而不是一句话标题,一条句子难以覆盖整篇文本的关键信息。本文多句摘要分别选择抽取2句和3句。
4.3.1 单句摘要实验结果
单句摘要的实验结果如表2 所示,分别为四种基线方法MMR、TextRank、LDA、Lead_N 与本文提出的基于集成学习的文本摘要抽取模型的结果。对比表2 中的结果,Rouge-1 评分中Lead_N 方法效果最差,出现这样的情况的原因可能是由于首句长度不够,包含的词数量较少、信息量不足,但是Lead_N 的Rouge-2 与Rouge-L 评分要高于其他几种算法,与预期结果相符合,表明新闻文本首句有效信息较多,文本结构对新闻文本影响较大。本文提出的基于集成学习的文本摘要在Rouge-1 评分中达到最优,比其他几种基准模型高了0.3个至4.1个百分点不等。Rouge-2、Rouge-L 评分略低于Lead_N 算法抽取效果,但是比其他三种抽取方法效果更好,整体抽取效果最优。
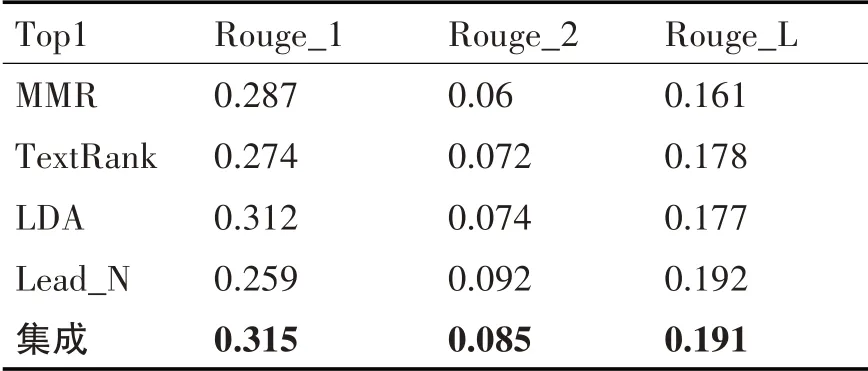
表2 单句摘要抽取效果
4.3.2 多句摘要实验结果
多句摘要(2 句、3 句)的实验结果分别如表3、表4所示。
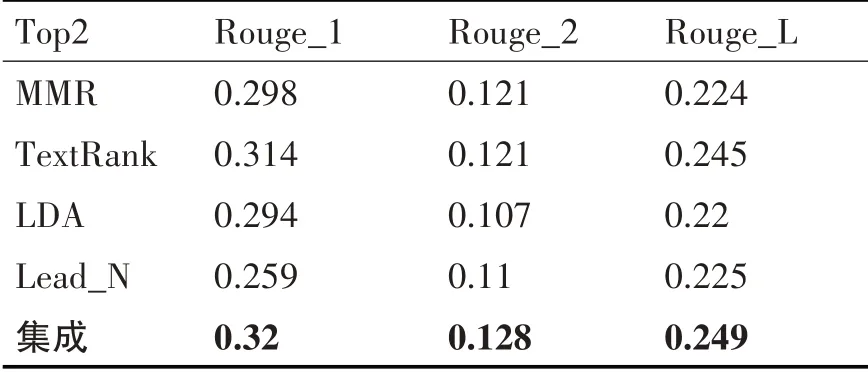
表3 多句摘要抽取效果_2

表4 多句摘要抽取效果_3
对比表3 中抽取两条句子作为候选摘要的Rouge 值,本文提出模型的Rouge-1、Rouge-2 比四种算法中表现最好的TextRank 算法分别高出约0.6 个、0.4 个百分点,Rouge-L 比TextRank 算法高出约0.7个百分点,效果最好。
对比表4 中抽取3 条句子作为候选摘要的Rouge 值,本文提出模型的Rouge-1、Rouge-2 比基线方法中效果最好的MMR 算法分别高出约1.7个、1.3 个百分点,Rouge-L 比MMR 算法高出约1.5个百分点。
通过对单句以及多句摘要结果对比,可以发现,在提取多句摘要时,MMR 效果在逐步提升,而本文提出的基于集成学习的文本摘要抽取模型在多句摘要抽取任务中,各评分都要优于所选基准模型中最优的算法,整体抽取效果达到最优。
5 结语
本文提出了一种基于集成学习的无监督中文文本摘要自动抽取模型。以NLPCC 2017的中文单文档摘要评测数据集作为验证集,运用集成学习将多种无监督文本摘要抽取算法应用到中文文本摘要抽取任务中,根据新闻文本的特性以及各算法的优缺点,为每种算法选取合适的权重,然后根据抽取句子的权重投票计算,得到最终摘要结果。根据Rouge 系列评测标准对比人工标注的参考摘要与模型得出的候选摘要,发现本文提出的模型在中文文本摘要抽取任务中可以达到较优的效果,与其他几种基准模型对比,整体抽取效果最优。
实际上,在候选摘要与参考摘要进行评测时,因为人工生成的参考摘要有一些人工总结性词汇,在原文中可能并未出现,这也就导致了Rouge 评分较低,后期可以考虑根据抽取式摘要与生成式摘要不同的特点,设计一套更加合理的评测指标,更好地指导摘要的抽取任务。
猜你喜欢
名家名作(2021年4期)2021-05-12
科普童话·学霸日记(2020年1期)2020-05-08
小天使·一年级语数英综合(2019年2期)2019-01-10
时代英语·高二(2015年2期)2015-05-18
时代英语·高二(2015年1期)2015-03-16
时代英语·高二(2014年4期)2014-08-27
时代英语·高二(2014年5期)2014-08-26
微型计算机(2009年4期)2009-12-23
现代计算机(2009年9期)2009-12-02
移动信息(2009年4期)2009-06-18
