
基于分解的多路选择器工艺映射方法设计
2022-08-31 07:57谢尚銮王晨阳
电子与封装 2022年8期
谢尚銮,惠 锋,刘 佩,王晨阳,张 立
(无锡中微亿芯有限公司,江苏无锡 214072)
1 引言
FPGA 芯片以配置灵活、开发周期短等特点而被广泛应用于图像处理、汽车电子、人工智能等领域,其设计流程包括综合、装箱、布局布线和码流生成等环节。工艺映射是综合的重要步骤,可将由寄存器传输级(RTL)描述文件解析所得的逻辑单元与芯片上的各类器件进行绑定以获得工艺网表,是物理实现数字系统的关键。
查找表(LUT)是FPGA 的主要逻辑资源,K 输入LUT 可以实现任意K 变量的逻辑函数,针对仅由LUT与时序器件组成的同构FPGA,已存在成熟的结构化映射算法[1-3],相关工作以动态规划算法为基础,通过分割枚举、分割排序、最佳分割选取等步骤用K-可行锥集覆盖逻辑网表,最后将每个K-可行的锥绑定到K输入LUT。随着设计水平的不断提高,商业FPGA 通过在片上嵌入多种专用功能模块来缩小与专用集成电路在性能上的差距,其中既有与LUT 一起集成于可编程逻辑块(CLB)的专用多路选择器与进位链,也有集成在FPGA 特定位置的存储器与数字信号处理器硬核[4]。为了支持异构FPGA 的工艺映射,研究人员做了诸多努力。在工业界,FPGA 三大厂商Xilinx、Altera和Lattice 提供的综合工具不公开相关映射技术。在学术界,JAMIESON 等[4]介绍了异构FPGA 的层次化映射流程;路宝珠等[5-6]通过区域重组技术打破专用功能模块与LUT 的层次边界,减小了映射解的面积和延时开销,并且实现了对专用进位链的映射支持;徐宇等[7]提出存储单元的优化映射算法,合理利用片上存储器满足用户的存储需求。
目前,公开的面向异构FPGA 的多路选择器工艺映射方法较少。多路选择器是数字系统的常见元件,在低功耗应用领域更是扮演了主要角色,但其逻辑资源开销大[8-10],若可高效地将该类单元映射至专用功能模块,将有助于节省芯片逻辑资源并加速数据交换。本文针对Xilinx 公司的Virtex-7 系列FPGA 架构[11],提出一种基于分解的多路选择器工艺映射方法。
2 基础知识介绍
2.1 多路选择器
多路选择器一般由RTL 描述文件的“case”、“if-else”及有限状态机等分支控制语句解析得到,每个单元的N 个待选信号、K(K=lb N)位选择信号及各路信号与其他单元的连接关系等均可被识别。K 位选择信号可形成2K个条件分支,设计者利用其中N 个分支对待选信号进行一对一绑定以实现选择输出[10],若N=2K,所有条件分支均被利用,此时称多路选择器是规则的;否则,称多路选择器是不规则的。
将每个多路选择器的选择信号从最低位至最高位的顺序编码为s0,s1,...,sK-1;同时将待选信号按照对应选择信号组成的二进制码值升序排列,依次编码为i0,i1,...,iN-1。为了表述方便,本文将N 选1 多路选择器简称为N 选1 单元。
在保证逻辑等价的前提下,N 选1 单元可分解为2 层的树状结构,第1 层为1 个T 选1 单元,2≤T≤N-1;第2 层为T 个子单元U0,U1,...,UT-1,对应待选信号数量为m0,m1,...,mT-1,每个子单元的输出为T 选1 单元的1 个待选信号且m0+m1+...+mT-1=N,对于其中任一单元Ui,2≤mi≤N-1;第2 层的各子单元可继续递归分解,形成层数更多、单元粒度更细的多路选择器树[8-10,12-14]。
2.2 LUT 与专用多路选择器的集成方式
Virtex-7 芯片的每个CLB 包含2 片Slice,而每片Slice 又包含4 个6 输入LUT、8 个时序器件、1 个专用进位链以及两级专用多路选择器。为了便于观察,完整的Slice 结构未画出,仅展示LUT 与专用多路选择器的集成方式,LUT 与专用多路选择器的集成方式如图1 所示。与LUT 相连的2 个1 级多路选择器为MUXF7,与2 个MUXF7 相连的2 级多路选择器为MUXF8,MUXF7/MUXF8 均能接受外部输入作为选择信号,但MUXF7 仅能接受前向2 个LUT 的输出作为待选信号,MUXF8 仅能接受前向2 个MUXF7 的输出作为待选信号。

图1 LUT 与专用多路选择器的集成方式[8]
3 多路选择器工艺映射实现
在异构FPGA 的设计流程中,解析所得多路选择器、存储器等单元不参与逻辑优化而直接实现工艺映射,以避免边界知识丢失[5-6]。该操作不仅可为专用功能模块的利用提供基础,还可减轻逻辑优化环节的压力从而支持对超大规模电路的处理,但其难点在于为相关单元寻找对应的“最优映射方案”。基于此,本文为多路选择器设计了一种有效的映射方法。
3.1 规则单元的映射步骤设计
利用Slice 内部附加的专用多路选择器可优化映射8 选1 单元与16 选1 单元,其中8 选1 单元仅需要2 个LUT 与1 个MUXF7,16 选1 单元仅需要4 个LUT、2 个MUXF7 与1 个MUXF8,而4 选1 单元直接映射至LUT 即可[8],相关单元的优质工艺网表如图2 所示。已知规则的2K选1 单元可分解成1 个2i选1单元与2i个2j选1 单元(i+j=K,i≥1,j≥1),若选择上述3 类单元为基准单元并保存相应工艺网表作为模板,再将2K选1 单元分解为若干层基准单元并由模板实现映射,有助于提升映射结果的性能。需要说明的是,解析所得2 选1 单元仅3 个输入,若将其直接映射至LUT 会造成逻辑资源的浪费,因此该类单元交由逻辑优化环节处理,不在本文方法作用域中。

图2 相关单元的优质工艺网表
本文所设计的2K选1 单元映射方式为规则映射,具体步骤如下。
(1)已知2K选1 单元的选择信号编码为s0,s1,...,sK-1,待选信号编码为i0,i1,...,iN-1,将其作为目标单元,分解为1 个2i选1 单元与2i个16n选1 单元,i=K%4,n=K/4。若i=0,目标单元直接形成16n选1 单元,不需分解;否则,将目标单元的待选信号按编码升序等分为2i组,每组的2K-i个待选信号分别作为一个16n选1单元的待选信号,并以2i个16n选1 单元的输出作为2i选1 单元的待选信号;将目标单元从低至高的(K-i)位选择信号s0,s1,...,sK-i-1同时作为所有16n选1 单元的选择信号,并以sK-i,sK-i+1,...,sK-1作为2i选1 单元的选择信号。此时若n=1,直接跳转步骤(3);否则,将所有16n选1 单元依次传入步骤(2)以执行递归分解操作,之后转到步骤(3)。
(2)将16n选1 单元作为目标单元分解为1 个16选1 单元和16 个16n-1选1 单元。将目标单元的待选信号按照编码升序等分为16 组,每组的24(n-1)个待选信号分别作为一个16n-1选1 单元的待选信号,并以16个16n-1选1 单元的输出作为16 选1 单元的待选信号;将目标单元从低至高的4 (n-1) 位选择信号s0,s1,...,s4(n-1)-1同时作为所有16n-1选1 单元的选择信号,并以s4(n-1),s4(n-1)+1,s4(n-1)+2,s4n-1作为16 选1 单元的选择信号。基于递归原则,将每个16n-1选1 单元作为新的目标单元继续分解直至n=2。
(3)调用模板实现分解所得子单元的映射,分解出的2 选1 单元直接映射为LUT3。
3.2 不规则单元的映射步骤设计
3 选1 单元仅5 个输入信号,可直接映射至LUT;而对于N≥5 的不规则单元,本文将其分解为若干个规则子单元并送入规则映射流程,继续借助模板实现映射。以选择信号编码为s0,s1,...,sK-1,待选信号编码为i0,i1,...,iN-1的不规则单元为目标,本文为之设计的映射步骤如下。
(1)若目标单元N-2(K-1)=1,跳转步骤(2);否则,跳转步骤(3)。
(2)将目标单元分解为2 选1 单元A 与2(K-1)选1单元B,以i0,i1,...,i2(K-1)-1作为B 的待选信号,以s0,s1,...,sK-2作为其选择信号;以B 的输出与iN-1作为A的待选信号,以sK-1作为其选择信号。执行B 的规则映射,结束分解。
(3)将目标单元分解为2 选1 单元A、2(K-1)选1 单元B 及N-2(K-1)选1 单元C,其中,以i0,i1,...,i2(K-1)-1作为B 的待选信号,以s0,s1,...,sK-2作为其选择信号;以B、C 的输出作为A 的待选信号,以sK-1作为其选择信号;令R=lb[N-2(K-1)],以i2(K-1),i2(K-1)+1,...,iN-1作为C 的待选信号,以s0,s1,...,s「R⏋-1作为其选择信号。执行B 的规则映射,若此时R≤2,将C 直接映射至LUT,结束分解;若R>2 且=R,执行C 的规则映射,结束分解;否则,基于递归原则将C 作为新的目标单元继续分解,更新N=N-2(K-1),将待选信号重编码为i0,i1,...,iN-1,转回步骤(1)。
在步骤(2)~(3)中,每次仅用1 个2 选1 单元来连接分解出的两部分待选信号并以目标单元的最高位选择信号sK-1作为其选择信号,从而实现相关条件分支的无关变量优化,使不规则单元分解所得树状结构更紧凑。129 选1 单元的分解如图3 所示,其选择信号为s0,s1,...,s7且待选信号为i0,i1,...,i128,分解得到128选1 单元B 与2 选1 单元A。其中i128在s7=1’b1 时即可定位,因此本文将i128条件分支的无关变量s0,s1,...,s6优化,令i128为A 的待选信号并由s7直接选择输出。

图3 129 选1 单元的分解
另外,递归分解所得2 选1 单元还将前后相连形成带优先级的选择器链,为了进一步优化面积与时延,本文将链上的单元尽可能映射为MUXF7 或MUXF8,具体步骤设计如下。
(1)将选择器链上的P 个单元按照选择信号编码值升序标识为A0,A1,...,AP-1,对于任一单元Ai,将其待选信号分别称为b0、b1,在选择信号为0 时Ai输出b0,否则输出b1。在A0中,若b0由LUT 驱动而b1为非组合逻辑单元的输出信号q,则创建与门单元D,以sK-1与q 为D 的输入信号,更新b1为D 的输出。若D 存在,将其映射至LUT,初始化i=0,转入步骤(2)。
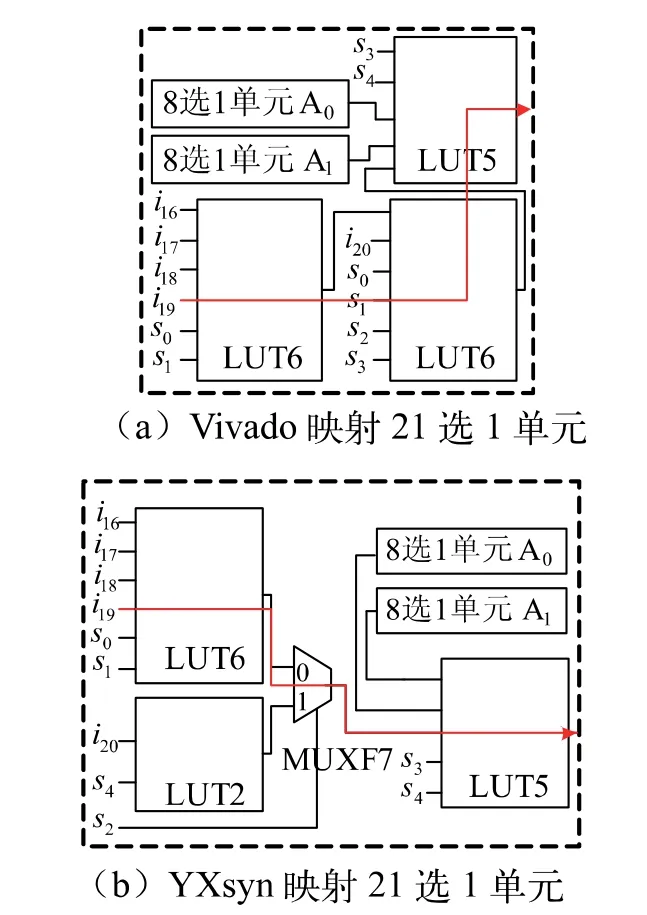
(2)对于目标单元Ai,若i (3)将Ai+1的待选信号分别称为a0、a1,在选择信号为0 时Ai+1输出a0,否则输出a1,a1即Ai的输出信号。当a0由MUXF7 驱动时,若b0由LUT 驱动,则将Ai映射为MUXF7,若此时b1由专用多路选择器驱动,将该器件用LUT 替换;当a0不是由LUT 驱动时,若b0与b1均由MUXF7 驱动,则Ai可映射为MUXF8;若b0与b1均由LUT 驱动而且2 个LUT 的不相同输入信号数大于5,则Ai可映射为MUXF7;其余情况,将Ai映射为LUT3。更新i=i+1,跳回步骤(2)。 (4)i=P-1,若b0由LUT 驱动,则AP-1可映射为MUXF7,若此时b1由专用多路选择器驱动,将该器件用LUT 替换;若b0与b1均由MUXF7 驱动,则AP-1可映射为MUXF8;其余情况,将AP-1映射为LUT3。若当前选择器链源于N>16 的不规则单元,且其中有多个单元均映射至LUT 并互连形成子网表,则借助结构化映射算法实现相关网表的再映射,避免浪费逻辑资源。 标记N 选1 单元分解出的所有2 选1 单元,若任一单元A 最终被映射为LUT3,则执行A 的映射后优化,在不增加LUT 的基础上减少专用多路选择器数量。 (1)当A 有且仅有1 个待选信号由专用多路选择器驱动时,则将A 与该模块互连所得子网表用1 个LUT5 替代。 (2)当A 的待选信号均由专用多路选择器驱动时,若这2 个模块的选择信号相同,则将A 与其互连形成的子网表用1 个LUT6 替代;若选择信号不相同,确定其中选择信号编码值最大的一个,将A 与该模块互连形成的子网表用1 个LUT5 替代。 本文方法以C++ 语言实现并封装为应用程序YXsyn,利用Verilog 语言描述的多路选择器单元测试例集加以验证。YXsyn 可支持任意N 选1 单元的映射,为了验证其正确性,对用户设计中使用频率较高的3 选1 单元至128 选1 单元等126 个测试例均进行了试验,其中每个单元的输入与输出位宽均设为8 bit,未利用的条件分支均绑定至缺省信号0。选择学术界著名的开源综合工具ABC[15]与Xilinx 公司的FPGA 配套支持工具Vivado[16(]version 2018.3)与YXsyn进行LUT 开销、时延等性能的对比,3 个应用程序均在Linux 系统、配置为Intel Core 3.40 GHz 处理器、16 GB 内存的PC 平台上运行,映射结果的时延参照文献[8]所述模型进行估算,以LUT 的时延为1 个单位,将I/O 缓冲器与连线的时延设为0,将MUXF7/MUXF8 的时延设为LUT 的1/6。 YXsyn 与ABC 的实验结果对比如图4 所示,图4(a)为LUT 开销数据对比,图4(b)为时延数据对比,图4(c)为运行速度数据对比,运行速度为运行时间的倒数。3 个子图均为散点图形式,其中每个点代表1 个单元。虽然ABC 集成了强大的结构化工艺映射算法,但无法支持专用多路选择器的映射,而本文通过将N选1 单元分解为若干层基准单元并基于模板完成映射,实现了对专用多路选择器的高效利用。经统计,YXsyn 与ABC 相比可平均减少20.82%的LUT 开销和29.51%的时延。另外,结构化映射算法包括分割枚举、分割排序与最佳分割选取等诸多环节,时间复杂度高,而YXsyn 的步骤相对简洁,其平均运行速度比ABC 快4.28 倍。 图4 YXsyn 与ABC 的实验结果对比 YXsyn 与Vivado 的实验结果对比如图5 所示,图5(a)为LUT 开销数据对比,图5(b)为时延数据对比,由于Vivado 报告的运行时间实际上包括硬件信息载入、时序约束配置等操作的开销,因此无法准确对比YXsyn 与Vivado 的运行速度,不记录相关数据。经统计,YXsyn 与Vivado 相比可平均减少1.01%的LUT开销与5.61%的时延,可充分说明其实用性。 图5 YXsyn 与Vivado 的实验结果对比 YXsyn 的时延性能优于Vivado 的主要原因是本文设计的分解操作可优化相关条件分支中的无关变量,使子单元间的连接更加紧凑。以21 选1 单元为例,图6(a)为Vivado 映射结果,图6(b)为YXsyn 映射结果,其中8 选1 单元A0与A1分别对待选信号i0,i1,...,i7与i8,i9,...,i15进行选择,其工艺网表包含1 级LUT与1 级MUXF7,时延为1.17 s,详细结构见图2。由于在s4s2=2’b11 时便可定位i20,因此本文将i20条件分支中的无关变量s0,s1,s3优化,并将其与s4集成为1 个与门以实现对MUXF7 的利用,最终使信号的最长输出路径为LUT6→MUXF7→LUT5,见图6(b)中红色标识线,电路时延为2.17 s;而Vivado 将i20的条件分支完整实现,信号的最长输出路径为LUT6→LUT6→LUT5,见图6(a)红色标识线,电路时延为3.00 s。 图6 映射结果示例 针对Xilinx 公司的Virtex-7 系列FPGA 架构,本文提出基于分解的多路选择器工艺映射方法,首先将N 选1 单元递归分解为若干层基准单元,接着利用预设的模板实现其映射。实验结果表明该方法具有优越的多目标优化能力,可以有效减少映射结果的LUT 开销与时延。本文方法适用于2 级专用多路选择器与6输入LUT 相集成的芯片架构,为了扩大其适用范围,后续将对不同厂商、不同系列的FPGA 架构进行对比与分析,在此基础上引入更多类型的模板并丰富N 选1 单元的分解方式,提高本文方法的兼容性。3.3 映射后优化
4 实验及分析


5 结论
猜你喜欢
中学生数理化·八年级物理人教版(2021年10期)2021-11-22
中学生数理化·七年级数学人教版(2021年10期)2021-11-22
中学生数理化·中考版(2021年10期)2021-11-22
通信电源技术(2020年8期)2020-07-21
山东电力技术(2020年6期)2020-07-09
科学与财富(2019年19期)2019-12-11
花火B(2019年3期)2019-04-27
电子制作(2019年23期)2019-02-23
数码世界(2018年5期)2018-06-04
软件工程(2018年3期)2018-05-15
