
基于乘积格拉斯曼流形的人体骨架动作识别
2022-09-06 13:17林枫
计算机应用与软件 2022年8期
林 枫
(中国科学技术大学计算机科学与技术学院 安徽 合肥 230027)
0 引 言
动作识别一直是计算机视觉领域中的重要研究分支。根据数据源的不同,它可以划分为基于RGB图像的动作识别和基于3D人体骨架数据的动作识别[1-3]。近年来,随着深度摄像等技术发展,基于3D人体骨架数据的动作识别受到越来越多的关注。相比于RGB图像,3D人体骨架数据表达能力更高,且在不同的光照、视角、移动速度等条件下具有更好的鲁棒性[4]。
动作识别的目标是在对人体骨架实施的动作进行判别分析。人体骨架通常可表示为一个由关节连接起来的刚性段组成的铰链系统,而骨架的动作则可以视为这些刚性段在空间形态上的连续演化[5]。因此,3D人体骨架动作数据主要描述人体骨架的空间变化,通常以人体多关节点坐标的时间序列的形式呈现。这种数据往往比较复杂,难以用简单的向量进行表示。
针对3D人体骨架的动作识别任务,研究者提出很多方法,包括基于人工特征的方法[6-7]、基于几何模型的方法[8-11]和基于深度学习的方法[12-14]。相比于其他方法,基于几何模型的识别方法注重挖掘骨架数据的几何结构,通过格拉斯曼流形[15]、李群[6,16]等几何模型来描述数据空间,同时强调动作序列的鲁棒表示,具有更好的可解释性。由于数据维数较高,这类方法能用降维的方式把高维序列样本直接映射成几何空间的一个点,有效减少数据的冗余信息,但这个压缩过程所造成的时序信息损失很容易会被忽略。文献[17]指出一个动作从开始执行到完成的演化过程蕴含一种本征性的时序。这意味着时序信息对动作的确定十分关键。因此,这种损失最终会影响动作的识别效果。文献[18]试图通过构造汉克尔矩阵的方式编码时序信息,但能包含的时序信息非常有限[19]。其他研究者则大多利用线性动态系统(Linear Dynamic System,LDS)来建模时序[20-22]。然而,这种基于连续帧建模的方式通常是高度冗余的,会大大增加计算代价[23]。
为了在保持降维优点的同时考虑时序信息,本文提出一种基于乘积格拉斯曼流形的动作识别方法。针对流形表示中时序信息缺失的问题,引入乘积格拉斯曼流形来建模不同时间视角下的局部动作变化,从而构造一种自包含时序信息的序列表示。基于这种表示,利用流形上的非线性度量分析骨架动作序列的异同,对序列数据进行学习,得到动作序列的分类判别模型,实现更加准确的动作识别。
1 相关理论
1.1 格拉斯曼流形核
在格拉斯曼流形上的经典内积定义为:
〈X,Y〉=tr(XTY)
(1)
式中:X和Y为格拉斯曼流形上的任意两点。
文献[24]指出,在实际中,利用投影映射:

(2)
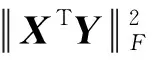
(3)

由上述内积诱导出相应的距离度量,可以写成如下形式:
(4)
事实上,格拉斯曼流形上有效的核函数不止投影核一种,还有Binet-Cauchy(BC)核、不定核、仿射核、归一化核等其他种类[26-27]。它们被统称为格拉斯曼核(Grassmann Kernels)。可以基于这类核函数进行格拉斯曼流形上的学习。文献[26]讨论了以子空间为单位在格拉斯曼流形上进行判别学习的可行性,基于线性判别分析(Linear Discriminant Analysis,LDA)的思想和格拉斯曼核提出了格拉斯曼判别分析(Grassmann Discriminant Analysis,GDA),通过最大化类间距离、最小化类内距离得到最佳判别函数。除此之外还有图嵌入判别分析[28]、投影度量学习[25]等方法陆续被提出。
1.2 乘积格拉斯曼流形
由多个格拉斯曼流形空间的笛卡尔积构成的乘积空间也是一个光滑流形,被称为乘积格拉斯曼流形(Product Grassmann Manifold,PGM)。可以表示为:
(5)
对于PGM上的任意两个点,X={X1,…,Xm}和Y={Y1,…,Ym},可以构造出PGM上的度量:
(6)
作为一族格拉斯曼流形的组合模型,乘积格拉斯曼流形非常适合于表示有多级变化因子的数据[29]。
2 本文方法
2.1 基于PGM的序列表示
给定一组序列数据,考察其中一个样本。例如一个动作序列X,它可以描述为:
X=[X1,X2,…,XT]
(7)
式中:Xi(i=1,2,…,T)是时刻i的3D骨架数据,它通常为一个3×J的矩阵或简化成一个长为3J的向量,J表示骨架中关节的个数。
不妨假设所有动作在时序上都是可比较的,即每个动作序列的本征时序都能用一个固定长度m的有序分组表示。
式(7)中序列X可重新表示为:
{[X1,…,Xt1],[Xt1+1,…,Xt2],…,[Xtm-1+1,…,XT]}
(8)
本文简记:
Sj=[Xtj-1,…,Xtj] 1≤j≤m
(9)
t0=1且tm=T。
Sj(j=1,…,m)描述的是动作第j个时序阶段执行的局部子动作。它可能包含多个可描述的动作单元,但为了降低序列表示的冗余信息,我们并不关注这个局部子动作在每一个时刻的表示,而只考虑它在当前阶段的全局表现。注意到,除非|tj-tj-1|足够小,否则Sj的维数依然会很高。因此,我们需要对Sj进行降维表示,提取其中的主要信息。因为Sj跨越的是一个相对较小时间段,在计算时,不必担心局部时序信息的损失,可以直接将它映射到格拉斯曼流形上。
考虑对Sj进行奇异值分解(Singular Value Decomposition,SVD):
(10)
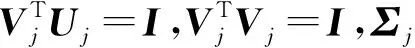
P(X)={Π(U1),…,Π(Um)}
(11)
这种PGM表示自然包含了动作序列的本征时序,因此能为动作识别带来很大的方便。
2.2 PGM上的学习
对于单格拉斯曼流形,研究者已经提出一些有效的判别分析方法。事实上,这些方法都遵循着传统机器学习的思路,即构造一个目标函数并优化从而得到最佳的模型参数。只不过优化的目标函数不再是普通向量,而是子空间。

(12)
式中:ω是模型参数;C是正则化参数;φ(X)是X的子空间表示;l(·)是基本损失函数,当它为合页函数l(X,y;ω)=max{0,1-yωTφ(X)}时,上述分类器即为格拉斯曼流形上的支持向量器(Support Vector Machine,SVM)。类似地,逻辑回归或者概率向量机模型[30]等也可以扩展到格拉斯曼流形上。
单格拉斯曼流形上的分类方法可以推广到PGM上。这里以SVM为例。应当注意到,PGM上的点的分布是其在组成该PGM的各个单格拉斯曼流形上投影的分布叠加作用的结果。因此,可以构造经验损失函数:
(13)
这里的φ是一个非线性映射函数。
最小化式(13)中的目标函数并不是一件容易的事。因此,可以不直接优化该函数,而是去求解其对偶问题,引入核方法,这样做大大降低了求解难度,也提高了求解效率。
2.3 核方法
通过引入一个辅助变量α=(αi)i=1,…,n,本文可以将PGM上的分类模型式(13)转换成为一个带核模型:
(14)
式中:Kt(·,·)是格拉斯曼核。注意到式(14)的形式和通常的SVM优化函数非常相似,只有核函数的部分是有差异的。我们可以提取出式(14)中的核:
(15)
本文将K(·,·)称为PGM核。它是一个格拉斯曼核的加性组合。显然,影响PGM核的关键是各单格拉斯曼核的形式。当然,最常用的核自然是投影核,其形式如式(3)所示,不再赘述。
式(15)中的PGM核将每个单格拉斯曼流形核对结果的贡献度都看作是一致的,但事实上不同的局部可能会产生不同的影响。因此,也可以考虑将简单的加法模型修正为一个加权的多核模型:
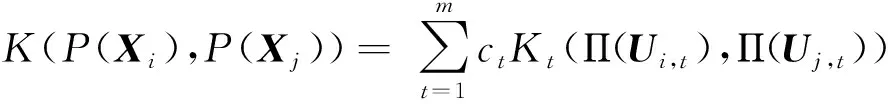
(16)
在确定核的形式之后,可以基于数据的PGM表示事先计算核矩阵,再最小化式(14)中的目标函数。
2.4 算法流程与代价分析
为了挖掘序列数据的流形结构,本文提出一种基于PGM的动作识别算法。该算法以3D骨架动作序列为输入,再将序列映射到PGM上得到降维表示。基于这种PGM表示,利用多核学习的方法可以计算出核矩阵。之后的参数学习过程就可以像求解一般SVM优化问题那样去求解目标函数式(14)的最小化问题,得到最佳的模型参数核评分函数。最后利用训练得到的模型,对一般的骨架动作序列进行分类识别。算法的步骤如图1所示。
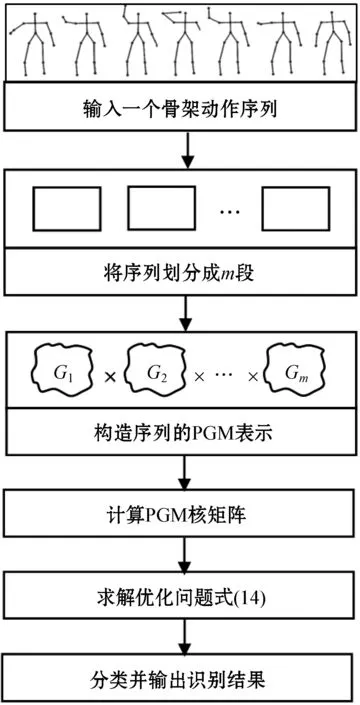
图1 基于PGM的人体骨架动作识别
值得注意的是,该算法在构建降维表示时的计算代价与PGM的因子个数m成正比,并受SVD分解的效率影响,因此复杂度约为O(mSLr),S是骨架坐标表示的维数,L是序列长度,r是降维SVD分解时保留的奇异值个数。为了降低信息的冗余,通常m不会很大;而局部包含信息通常比全局信息少,因此降维时r也会较小。这时,算法复杂度与一般基于格拉斯曼流形的降维表示方法相近。因此,其计算代价并不会高于其他在格拉斯曼流形上进行学习的方法。同时,训练出的分类器具有很好的泛化能力,能够实现高效、准确的动作识别。当然,受到SVM方法自身的限制,其实时预测的效率一定程度上依赖于核矩阵的计算。为了更好地提高识别的实时性,可通过一定策略[31]对分类器进行在线优化。
3 实验分析
实验使用了MATLAB R2017b作为开发工具,并使用了LibSVM工具包[32]。
3.1 实验数据集
本文在MSR Action3D[33]、Florence 3D[34]和KARD[35]三个常用的3D人体骨架动作数据集上进行了实验,数据集信息如表1所示。

表1 数据集信息
MSR Action3D数据集来自于微软研究院,通过深度相机收集。但这些样本有一部分有缺失,因此实际中往往会弃用这部分数据。KARD数据集则利用微软Kinect相机捕捉骨架坐标,数据更加可靠、准确。而Florence 3D数据集由佛罗伦萨大学的研究者收集得到,同样是利用了Kinect相机。该数据集中的动作具有高度的类间相似性和类内的波动性,因此该数据集的动作对于机器识别起来会有一定困难。
3.2 实验设置
本文的三个实验均按照相应数据集文献中的标准实验进行。对于MSR Action3D数据集,依照文献[28]中的设定将它划分为三个数据子集。而每个子集则按动作执行对象将数据的50%用于训练,50%用于测试。在Florence 3D数据集上则采用每次留一人(Leave-one-subject-out)用于测试的学习规则。而对于KARD数据集,同样将它划分为三个识别难度不同的数据子集,但是使用了更多不同的实验设置。在KARD数据集上进行了三个子实验(A/B/C),分别使用(A)每个对象数据的1/2、(B)每个对象数据的2/3和(C)全部数据的1/2用于训练。
为了选择合适的参数,本文在所有的实验中均使用了10折交叉验证。其中,分类器参数C的选择范围为-103~104,而控制局部降维的参数r则通常不超过10。m作为PGM表示最重要的参数,在本文实验中从1~10中进行筛选。在实际测试中,m不宜过大也不宜过小。
3.3 结果分析
为了验证本文方法的有效性,在MSR Action3D数据集上,将本文方法与文献[14]、文献[25]、文献[26]、文献[28]和文献[36]提出的方法进行实验对比,如表2所示。
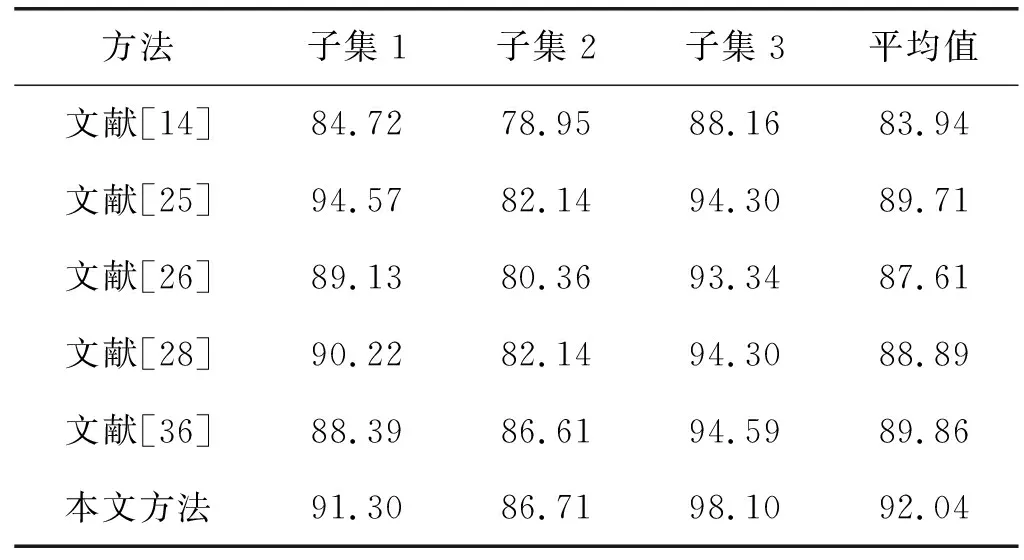
表2 MSR Action3D数据集上的准确率结果比较(%)
可以看出,相比其他算法,本文方法在这三个不同的子集上均表现良好。在子集1上虽然比文献[25]的方法略有不如,但比其他方法的准确率都要更高;在子集2上也达到了最高的识别准确率;而子集3上的识别准确率更是远超其他算法。本文方法平均识别准确率也大幅上升,比其他方法提高了2%,这充分说明该算法对于常规动作有很强的识别能力。该方法在不同子集上的混淆矩阵如图2所示。可以看出,它在大多数类别动作的判别上表现很好,只是对少数几个易混淆类动作的识别还有待提高。整体上看,矩阵对角线的颜色明显比非对角线的更深,表明本文方法分类效果较好。
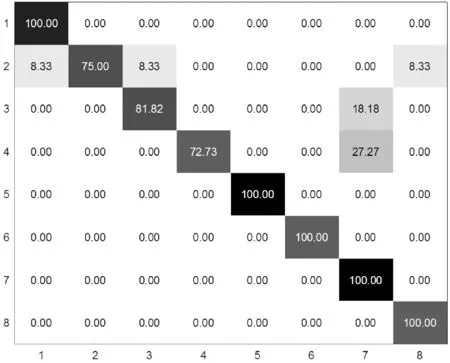
(a) 子集1
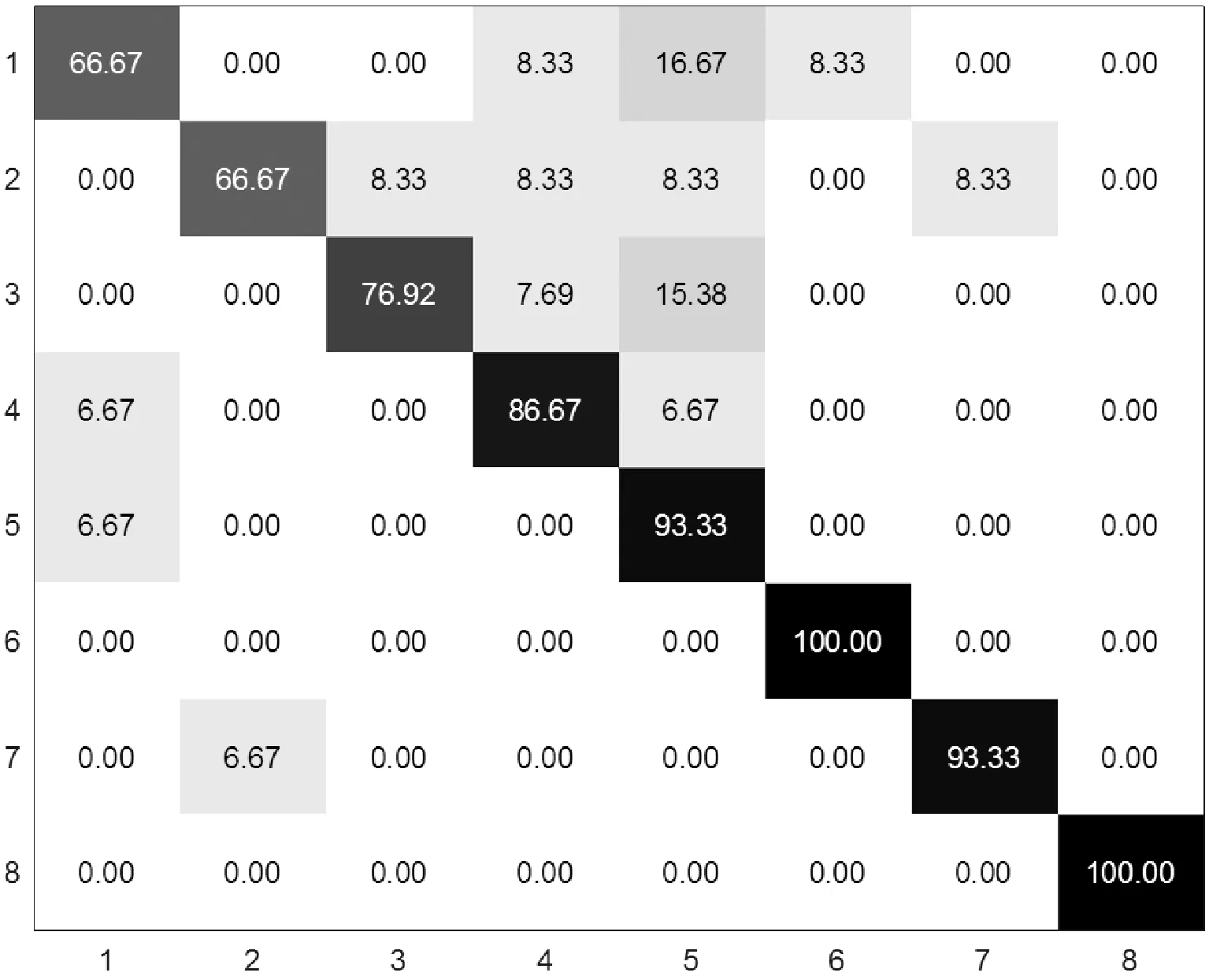
(b) 子集2

(c) 子集3图2 MSR Action3D子集上的混淆矩阵
除了MSR Action3D数据集,我们还在Florence 3D数据集上进行了实验,结果如表3所示。该实验的结果是经过10次测试取平均值得到的。从表3可以看到,本文方法在该数据集上能取得最高的准确率。这体现了它在小规模数据集上良好的泛化能力。

表3 Florence 3D数据集上的实验结果(%)
为了进一步验证算法对骨架动作数据建模的流形结构是有效的,本文又在KARD数据集的三个不同子集上进行了三组实验,并将结果与文献[25]、文献[26]和文献[28]等基于流形的方法进行比较,如表4所示。
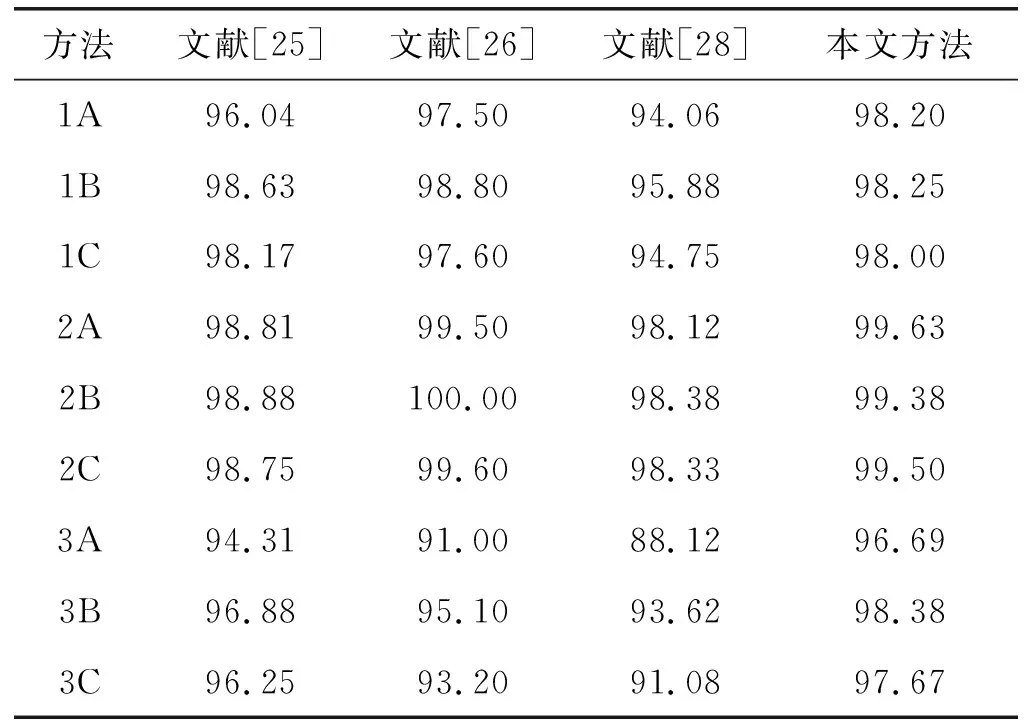
表4 KARD数据集上的准确率结果对比(%)
可以看出,在第一个子集上采用实验设置A的时候,本文方法是其中识别最准确的;在B和C设置下结果也与准确率最高的算法非常接近。在第二个子集上,文献[26]的方法表现非常突出,本文方法的识别率也相差无几。第三个子集是区分难度最大的子集。在这个子集上,无论什么设置,本文方法都有着最高的识别准确率。综合来看,其他算法在动作识别时都有一定的不稳定性,可能在某个子集上效果非常好,但在另一个子集上的效果却相对较差。这表明它们对数据的建模可能存在一定偏差,泛化能力不足。而本文方法在三个数据子集上的表现都很稳定,准确率很高,结果不会因为实验设置的改变或者数据子集的变化而产生巨大波动。这意味着相比于其他几个基于流形的算法,该方法对数据的建模可能更接近数据的真实结构。
4 结 语
本文提出一种基于PGM的3D人体骨架动作识别方法。该方法将动作序列数据投影到PGM上,直接在流形上进行学习。为了保留低维表示优点的同时捕捉时序信息,本文的方法利用PGM可以表示多因子数据的特点,提取时间序列在不同时间视角下的局部信息,并整合进行模型训练。实验结果表明该方法在多个数据集上均能有效提高识别效果。在未来的研究中,我们会将这种方法的思想推广到其他流形,进一步提高这种方法在不同数据环境下的准确性与鲁棒性以及算法的实时预测能力,并探索方法在更广泛的时间序列学习上的应用。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
电子乐园·上旬刊(2022年5期)2022-04-09
电子乐园·上旬刊(2022年5期)2022-04-09
中学生数理化·高一版(2022年1期)2022-04-05
华东师范大学学报(自然科学版)(2022年2期)2022-03-31
小猕猴智力画刊(2022年3期)2022-03-28
农业工程学报(2022年1期)2022-03-25
意林·作文素材(2021年23期)2021-01-22
发明与创新·大科技(2020年6期)2020-06-22
农业工程技术·温室园艺(2017年3期)2017-07-13
