
基于相关性特征选择和深度学习的网络流分类
2022-09-20 01:43刘会霞董育宁邱晓晖
南京邮电大学学报(自然科学版) 2022年4期
刘会霞,董育宁,邱晓晖
(南京邮电大学通信与信息工程学院,江苏 南京 210003)
网络流量分类(Network traffic classification,NTC)可用来区分不同业务的需求,对网络资源管理和网络空间安全至关重要[1],是一个重要的研究领域。
传统的NTC方法主要有基于端口[2]、基于深度包检测[3]和基于统计特征的方法[4]。 其中,基于端口和深度包检测的方法仅适用于未加密的流量[5]。机器学习(Machine learning,ML)和深度学习(Deep learning,DL)方法依赖于统计特征或时间序列特征,能够处理加密和未加密流量[5]。对于基于ML的分类方法,其有效性在很大程度上取决于特征选择(Feature selection, FS)的准确性和有效性[6]。Wang等[1]利用公共数据集,在基于流的六分类任务中,使用一维卷积神经网络(One-dimensional convolutional neural network,1D-CNN)分类准确率可达 98.60%;Aswad等[7]使用人工神经网络(Artificial neural network,ANN)在ISCX数据集(简称为 ISCX)[8]上准确率可达 96.76%;Lotfollahi等[9]将数据包字节特征作为1D-CNN和堆叠自编码器(Stacked auto-encoder, ASE)的输入,应用和业务流分类的平均f1-score都可达到95.0%。
在NTC任务中,有研究者使用了特征融合(Feature fusion, FF)和 FS相结合的方法。Mcgaughey等[10]提出了用于NTC的FS系统方法,利用二阶运算(加、减、乘)生成融合特征(Fused feature,fuf),并使用快速正交算法对 fuf进行 FS。文献[11]同样使用二阶运算(加、乘、绝对值加)作为FF方法,使用嵌入式FS算法,将FS与随机森林(Random forest,RF)相结合,分类效果优于核函数FF方法[12]。针对现有FF运算方法比较单一,且高维特征中存在较多的冗余问题,本文提出了新的FF方法。它在网络流特征增加的同时更加多样化,经过FS选出最优特征组合,并将序列特征转换成二维灰度图(Greyscale image,gi),利用 DL模型进行分类实验。实验表明,该方法的分类准确度比现有方法有明显提升。
本文的主要贡献如下:
(1) 设计对原始特征(Original feature, orf)做相应运算,生成高维fuf,将生成的特征矩阵转换成gi,使用CNN模型对gi进行流分类;
(2)设计通过计算皮尔森相关系数(Pearson correlation coefficient,pcc),将特征与标签和特征之间的pcc结合考虑,消除冗余特征,发现阈值为0.9时,分类性能最优;
(3)在两个实际网络数据集上进行了方法的分类性能测试,并与现有方法比较。结果表明,本文方法明显优于文献方法。
1 相关工作
1.1 FF方法
典型的FF方法是将多个特征通过某种运算融合成一个高维组合特征集,然后使用FS方法对高维特征集进行降维[13]。 Sugandhi等[14]将现有统计特征与新提出的特征做FF,可以提高对人体步态的识别性能;Zhong等[15]将静态和动态两个不同尺度的特征融合成一个新的特征,可以完成视频火焰识别任务;Nguyen-Quoc等[16]将特征进行拼接形成单一、增强的fuf,然后使用相关性分析方法对fuf进行降维。在 NTC方向,对于 FF方法也有一些成果。Shen等[12]提出使用核函数形成 fuf集;Mcgaughey等[10]使用二阶加、单向减、乘运算和三阶乘运算融合方法,形成fuf,最后与orf拼接成组合特征,并对网络流量进行识别;袁梦娇等[11]使用二阶加、乘、绝对值加3种FF方法,实验结果证明可以提升视频流量识别的准确率和性能。基于以上研究,本文使用二阶运算FF方法,除了加、乘、绝对值加3种融合方法外,将单向减改为双向减运算,另外提出乘、开方、线性加(4种)、线性减(4种)共14种融合方法。
1.2 特征选择方法
FS通过搜索最优特征子集,一方面,可以降低特征维数,使模型的泛化能力更强,减少过拟合;另一方面提升分类的时间性能[17]。 Zhao等[18]指出FS对于NTC有很大的影响。FS方法分为:过滤式、包裹式和嵌入式[17]。 Xue 等[19]提到包裹式通常优于过滤式,但其计算复杂度较高;嵌入式通常与特定的分类模型有关,特别是决策树、RF等ML方法;过滤式计算简单、快速,且不依赖于分类算法,只与特征本身有关[20]。因此,在本实验中采用过滤式FS方法,将特征与标签和特征之间的pcc相结合,所选择的最优特征组合在两个数据集上都表现出了比较好的分类性能。
1.3 分类器
DL在图像处理和自然语言处理领域已经取得了很大的成就。近年来,DL也被广泛应用于NTC。Wang等[1]将流量数据以类似于MNIST数据集的形式进行处理,并利用卷积神经网络(Convolutional neural network,CNN)对流量进行分类,结果表明,CNN的分类准确度要高于ML的准确度;Song等[21]指出网络流量数据与文本数据具有相似的层次结构,将网络流量数据转换为文本数据,利用文本卷积网络进行分类,取得了不错的分类效果;Raikar等[22]应用 AlexNet、ResNet和 GoogLeNetDL 三种 DL模型进行NTC,结果发现,ResNet网络具有较高的准确度。本文使用LeNet5[23]模型,对网络流量转换的gi进行分类,实验表明可以取得良好的分类效果。
2 研究方法
本文方法流程图如图1所示。在预处理阶段,首先,把pcap文件转换成txt文件,然后将持续较长时间(大于5 min)的流数据分割成多个30 s的流段。将不足30 s的流删除。然后,组成网络视频数据集(Video dataset,VD)和ISCX。其他信息在下文介绍。
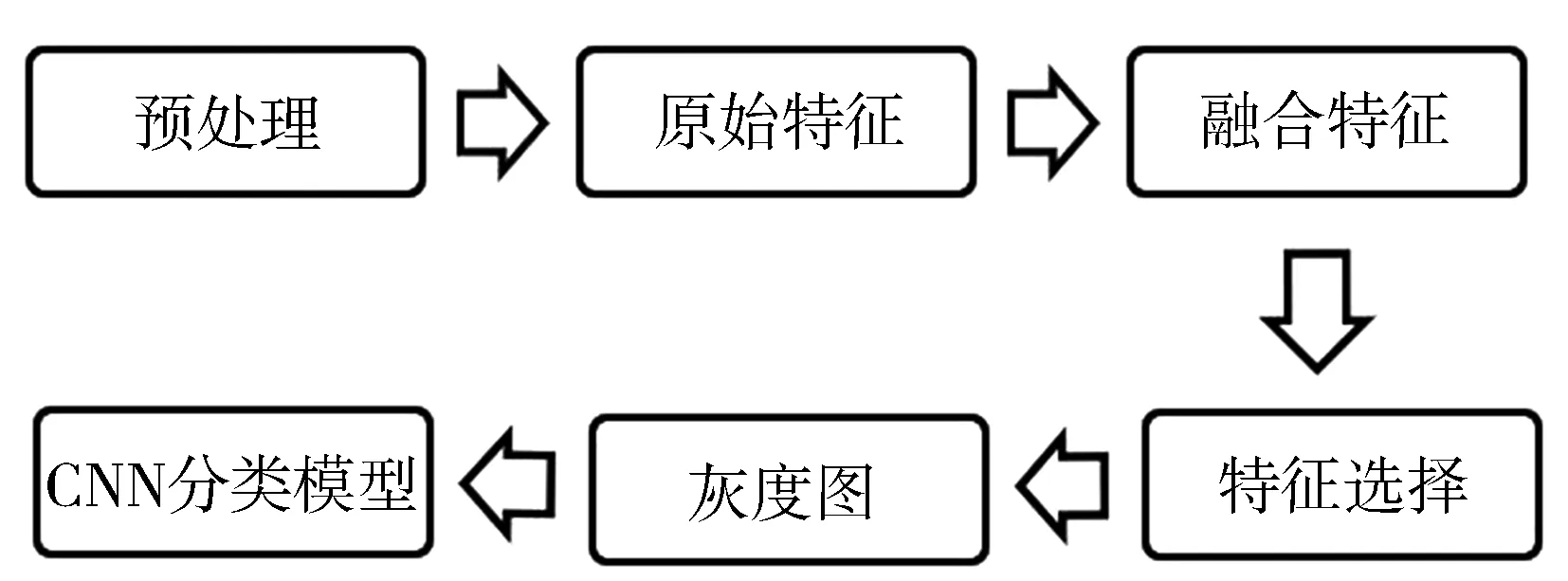
图1 方法流程图
2.1 数据集
两个数据集中的样本都是持续时间为30 s的流。VD是本实验室使用WireShark通过南京邮电大学校园网采集的互联网视频数据,采集时间是2019年10月至2020年3月,包括直播和点播视频流,详细介绍如表1所示。表2为ISCX选择的4种业务,分别为语音通话、文字聊天、视频和IP语音。

表1 网络视频数据集(VD)

表2 ISCX部分数据集[8]
2.2 原始特征提取
通过对流数据进行统计计算,提取了包括上行、下行和整体的包大小、包到达时间、字节效率、有效IP比等56个orf,具体特征描述如表3所示。式(1)Fo所示为56个orf序列。

表3 原始特征(orf)
当具有相同源地址的包出现时,称为一个子流[24]。有效IP数定义为使用TCP/IP协议的包数,有效IP比为有效IP数与数据包总数的比值。
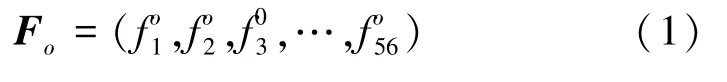
2.3 特征融合
式(2)至式(15)是本文所采用的14种 FF方法,其中式(2)至式(4)是文献[11]中的融合方法,式(5)至式(15)是本文提出的新融合方法。
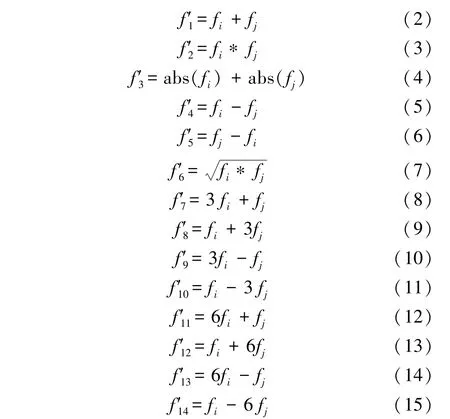
式中,i<j,abs 为绝对值运算,式(8)至式(15)称为线性加(减)运算。
FF的目的是使特征更加多样,从而提高分类准确度。考虑到orf具有数值大小相差较大的特征,如果直接运用,可能会有极大的数值特征(最大包大小可能为1 500)与一个极小的数值特征(上下行包个数比值为0.3)做某种算术运算,比如加,那么fuf为1 500.3与orf几乎没有差别,这样就失去了FF的原本意图。所以,在进行FF之前把所有特征归一化在[0,1]。 式(16)为归一化后的 56个 orf序列F′o, 其中;式(17)为采用上述14种融合方法生成的21 560个fuf序列Ff;式(18)为 orf和 fuf拼接成的21 616个全部特征(All features, af)序列F。
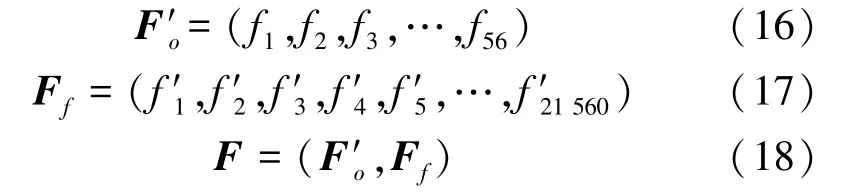
2.4 相关性特征选择
F中包含着大量的冗余特征,会影响分类器的性能。经过相关性FS,可以尽可能地删除冗余特征,保留重要的特征。本文采用pcc对特征进行降维[25]。
步骤如下:
(1) 计算每个特征与标签的 pcc[25],并且按照pcc由强到弱对特征进行排序;
(2)从排在前面的特征开始,计算特征之间的pcc,如果pcc大于阈值δff,则删除其中与标签相关性(Label correlation,lc)较弱的一个特征;
(3)重复第2步,直到所有FS完毕。
式(19)为选择的特征(Chosen features, cf)序列Fs,n表示cf个数。
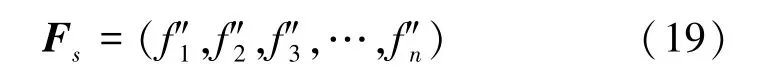
例如F=[F1,F2,F3,F4,F5], 经过特征选择后,Fs=[F5,F2,F1], 图 2 为特征选择过程示意图。
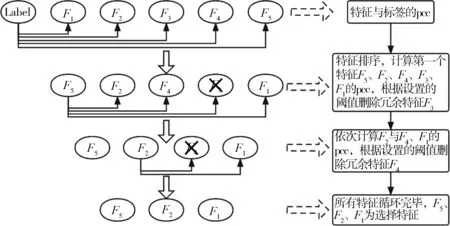
图2 特征选择示意图
由于lc相同的特征所占比例<10%,如图3和图4所示,所以,当lc相同,且特征之间的pcc大于δff时,随机删除其中一个特征。
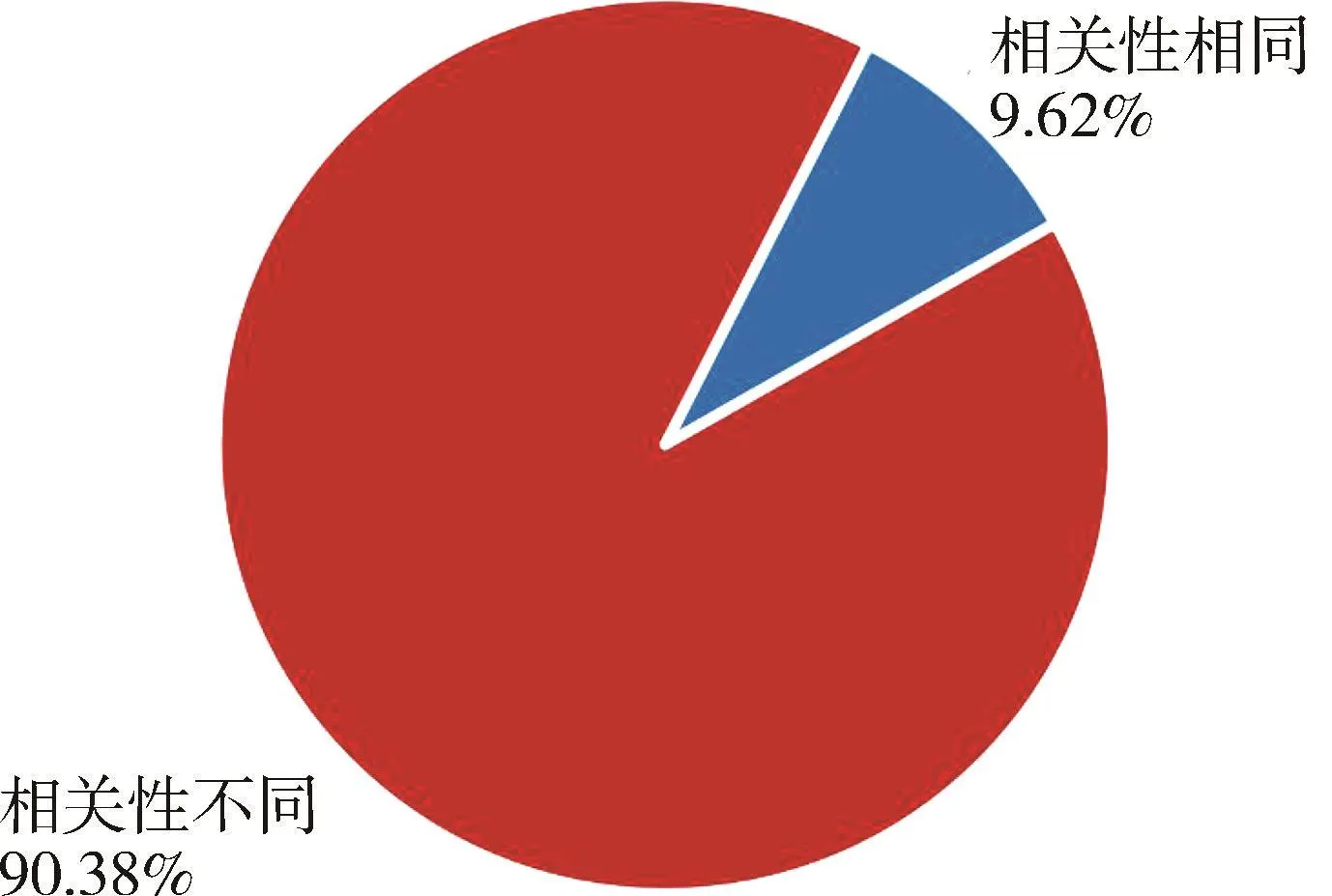
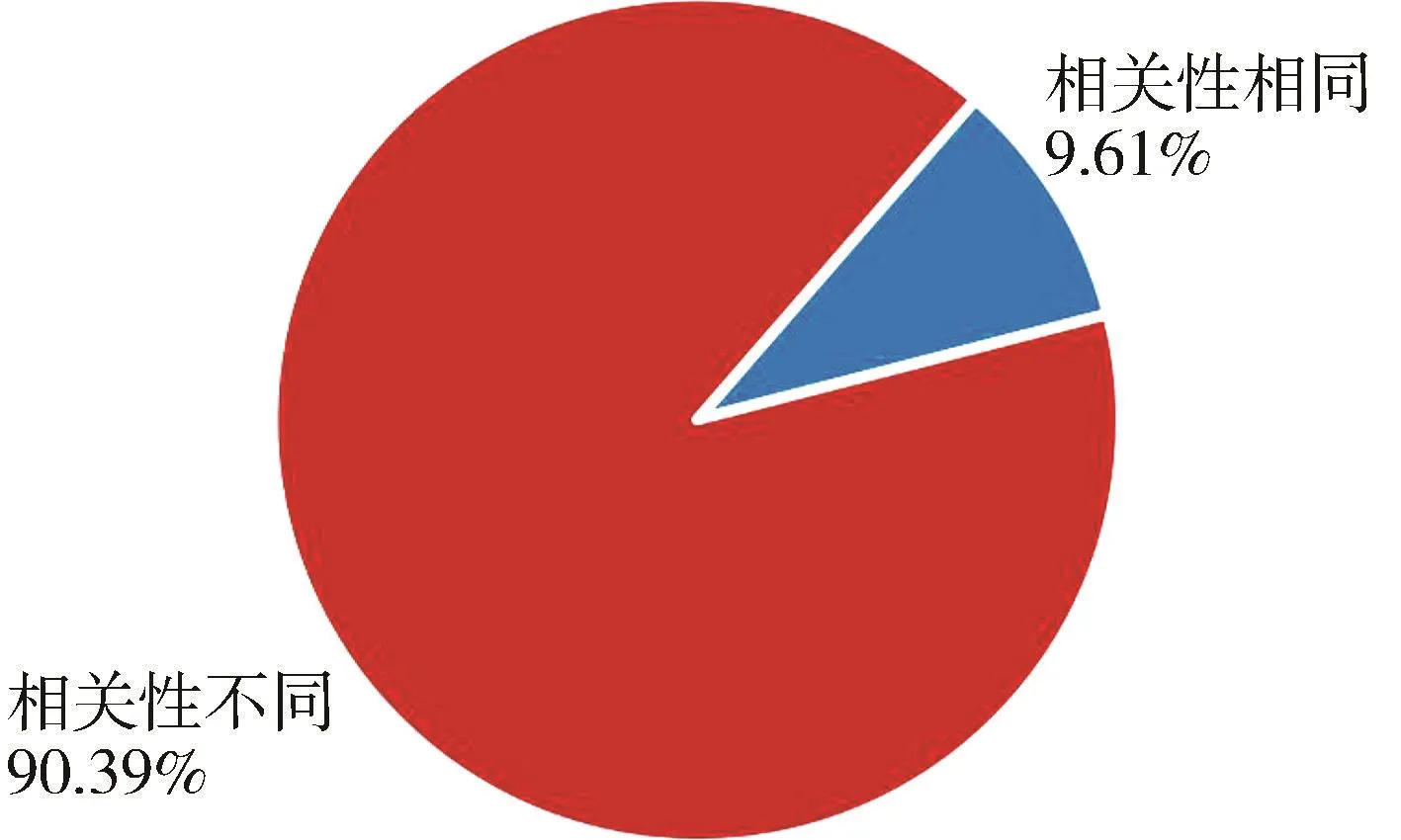
图4 ISCX中fuf与lc分布
另外,当阈值过大会导致冗余特征删除不充分,阈值过小会导致过度删除特征,从而导致准确率下降。所以选择合适的相关性阈值δff,是需要考虑的问题。
最后,将Fo、F、Fs分别归一化到[0,255],每一个数值特征对应一个像素点,生成N×N的gi。
3 性能评估
3.1 评价指标
本文采用4种评价指标,分别是总体准确率(acc)、查准率(P)、查全率(R)和F1 测度(f1_score),其中acc是指所有分类正确的样本占全部样本的比例;P为预测是正例的结果中,确实是正例的比例;R是所有正例样本中被找出的比例;f1_score是P和R的调和平均;具体计算如式(20)至式(23)所示,式中TP和TN分别是真例和假例被正确分类的样本数,FP和FN分别是真例和假例被错误分类的样本数[1]。

3.2 实验场景和参数设置

图5 损失函数收敛曲线图
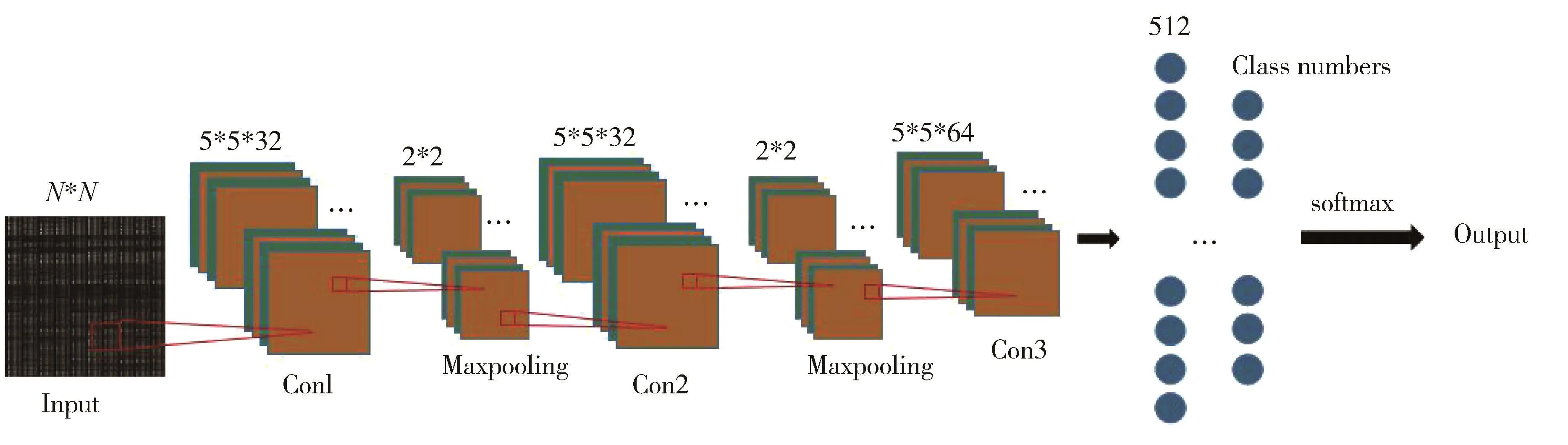
图6 LeNet5 模型[23]
4 实验结果与分析
4.1 网络视频数据集
表4所示为设置不同δff的实验结果,随着δff减小,cf数目在下降,相对应的训练时间(Training time, tt)和识别时间(Inference time, int)也减少;当δff=0.90时,在该数据集上的acc最高。图7所示为δff对 acc、int和 tt的影响。
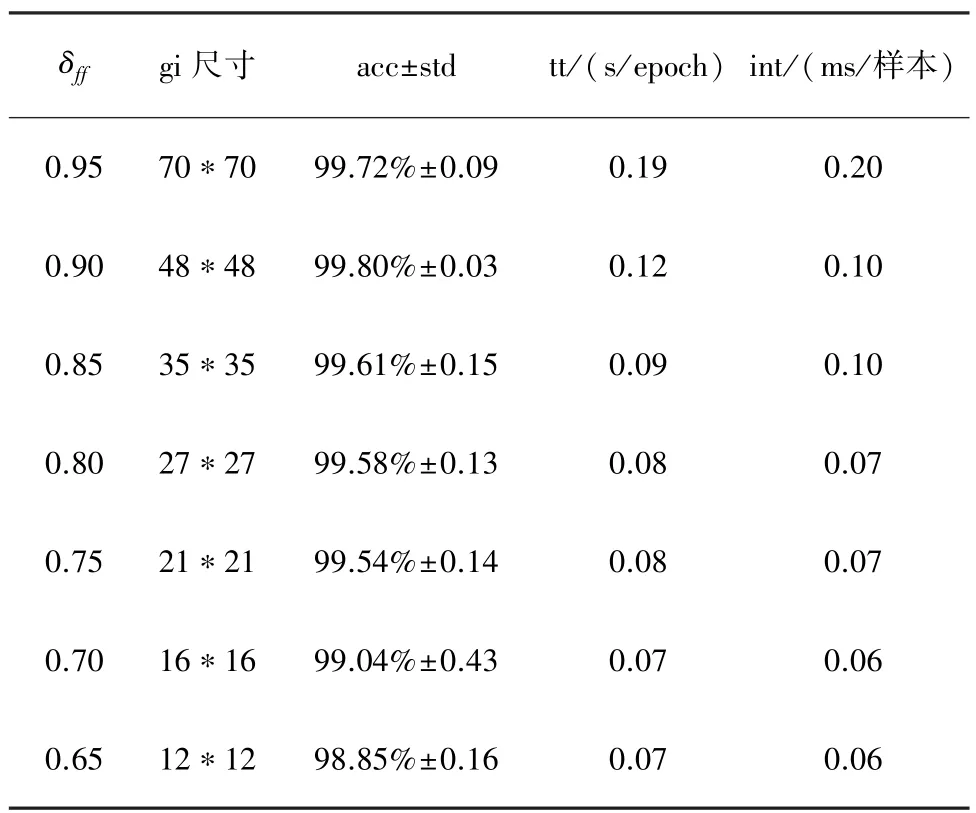
表4 VD用不同的 δff进行 FS后的 acc、tt和 int(orf提取时间=1.36 s,FF 时间=17.2 ms/样本)
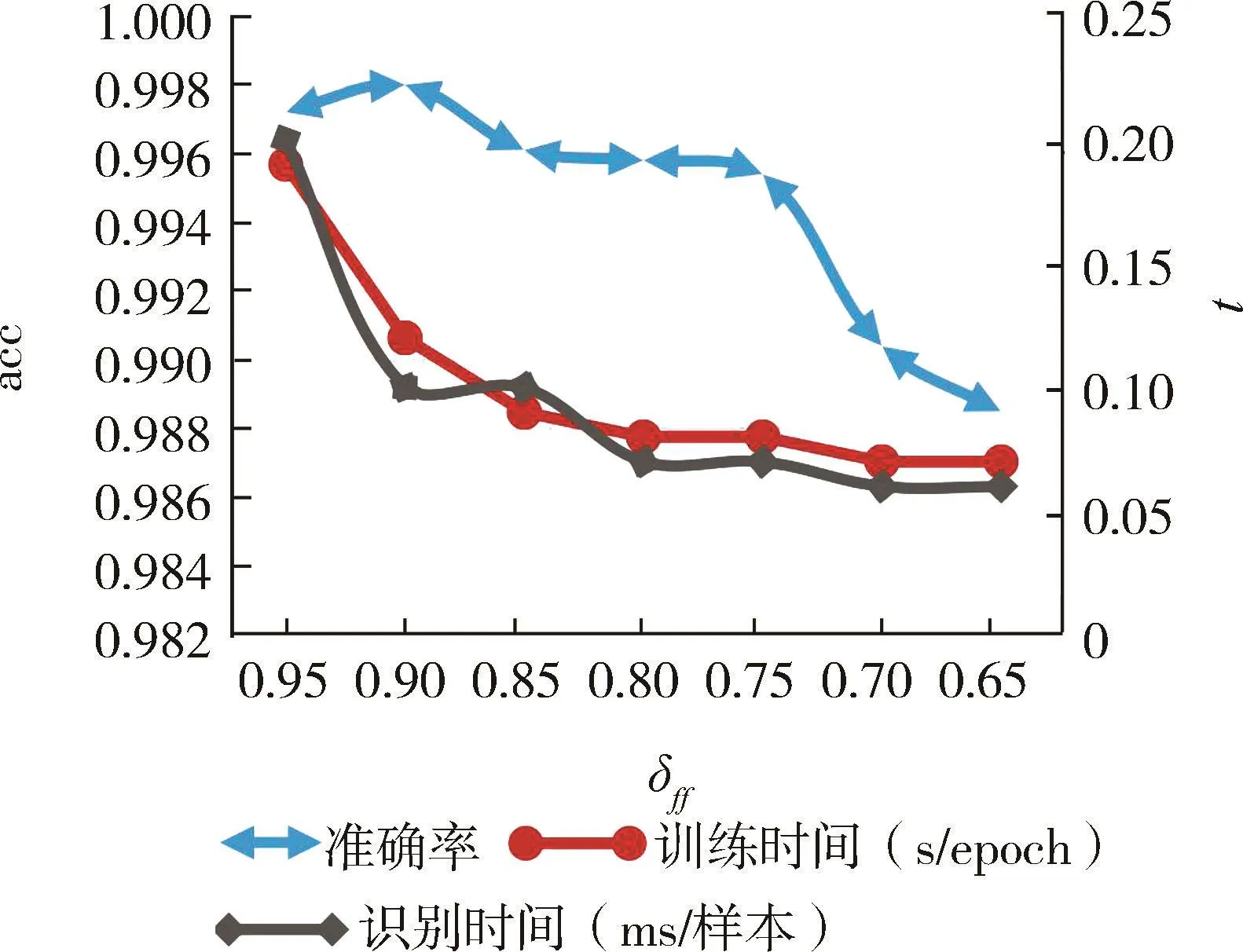
图7 δff对 acc、int和 tt的影响
由图7可以看出,当δff从0.95减小到0.90时,int和 tt下降最大;δff=0.90 时,acc 最高。 所以,δff=0.90最佳;此时 cf的个数为 2 328个(n=2 328);式(24)为选择的特征序列Fs1, gi大小为 48×48,acc为 99.80%,int为 0.1 ms/样本,tt为 0.12 s/epoch。
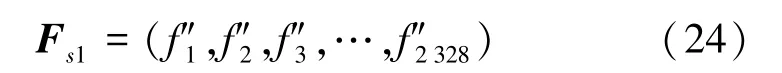
图8显示Fs1、Fo和F的acc结果比较。虽然orf所使用的时间最少,但是它的分类结果最差,只有75.09%;其次,af分类结果较orf从75.09%提升到了 99.71%,但是 int为 0.58 ms/样本,耗时最长;经过最佳δff的 FS之后,不仅 acc较 af提升了近0.10个百分点,为99.80%,而且int也减少了82.76%,减少到0.1 ms/样本。可见,经过FS在保持acc不变(甚至略有提高)的条件下能够显著减少运行时间。
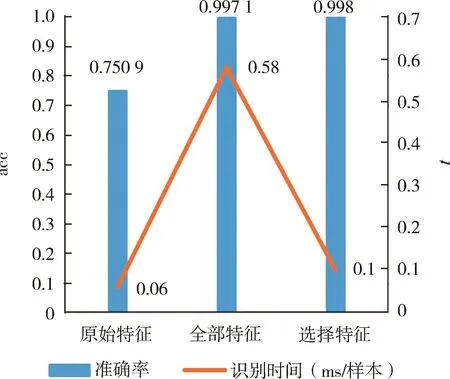
图8 VD的orf、af与cf的acc和int对比
从图9混淆矩阵中可以看出,af与orf相比,逐类流的 acc都有所提高,特别是直播 480/1080和点播1 080;cf与 af相比,虽然直播720的acc略有下降,但点播720和直播1 080的acc提高了;综合考虑,cf的分类结果较好。图10为利用Fo、F和Fs1对 VD中逐类别的 f1_score对比,Fo序列长度为56,通过在特征尾部补零的方式生成的gi大小为8×8;F序列长度为21 616,生成140×140的 gi。随着特征个数的增多和 gi尺寸的增大,每类的 f1_score都明显增加,最高为99.88%,最低也可以达到98.83%;其次,Fs1序列长度为2 328,生成48×48的 gi;cf与 af相比,不仅 acc增加了 0.1个百分点,而且逐类别的f1_score都达到了99.2%以上,有小幅度提高。
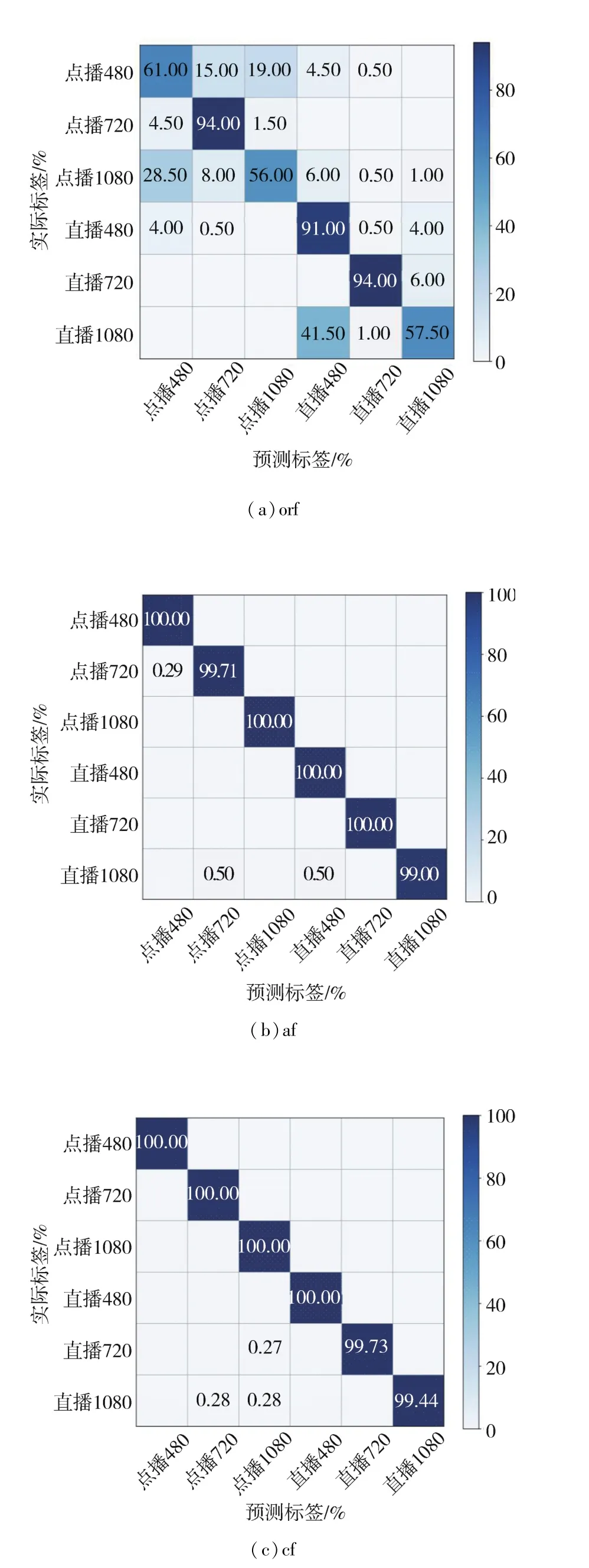
图9 VD上orf、af和cf分类的混淆矩阵
综上,可以得出如下结论:
(1)使用af对视频流进行分类时,int虽然较长,但是acc较orf从75.09%提升到99.71%(提升24.62个百分点);逐类别的f1_score(如图10所示)也明显提高;
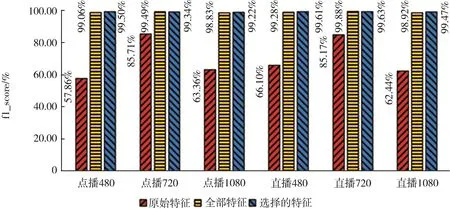
图10 VD用orf、af和cf进行分类的f1_score比较
(2)当特征之间的δff为0.90时,可以有效删除冗余特征;FS后的acc可以达到99.80%,较af提升0.1个百分点左右,int显著减少(减少了约82%),逐类别的 f1_score也可以达到 99.2%以上。
4.2 ISCX数据集
在ISCX上测试本文方法的有效性和通用性,并与文献[9]和文献[11]方法作对比。
由于特征提取(Feature extraction,FE)和FF是在FS之前,所以δff对它们没有影响。从表5可以看出,当δff=0.95和 0.90时,acc最高为 99.84%,其中δff=0.90 运行时间较少;而且,由图 11 可见,δff从0.95变化到0.90时,int和tt的下降最大,所以在该数据集上,最佳δff为0.90;这与在VD上的结果基本一致。图 12为利用Fo、F和式(25)的Fs2(n=2 463)的acc与int对比;可以看出,F较Fo准确率从70.35%提升到99.64%(上升29个百分点左右),Fs2较F准确率从99.64%提升到99.84%(提升0.2个百分点),int从 0.58 ms/样本减少到 0.12 ms/样本(减少约80%)。可见,有效的FS可以改善分类的准确性和时间性能。


表5 ISCX用不同的 δff进行 FS后的 acc、tt和 int(orf提取时间=0.91 s,FF 时间=14.5 ms/样本)

图11 δff对 acc、int和 tt的影响
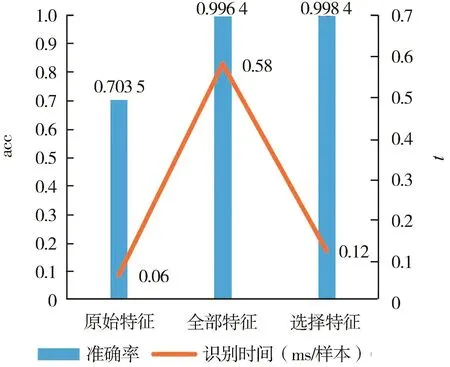
图12 ISCX的orf、af与cf的acc和 int对比
图13为利用Fo、F和Fs2进行分类的 f1_score结果对比。可以看出,利用Fo进行分类时f1_score≤80%,分类性能欠佳;利用F进行分类的效果明显优于Fo,且f1_score明显提高。这是因为,F拥有更加丰富的特征,对于分类有利,不过如图12所示int较长;利用Fs2进行分类时,f1_score并没有随着特征个数的减少而降低,甚至略微提高。如前文所述,cf的acc较af相比也提升了约0.2个百分点,int降低了约80%。图14为3种特征集合的混淆矩阵,分别为 orf、af和 cf;af与 orf相比,逐类别的acc都有明显的提高,其中语音通话改善最明显;cf与af相比,在af的基础上进一步提高了视频和IP语音的acc;综合分析,cf的分类结果最好。

图13 用orf、af和cf进行分类的f1_score比较

图14 ISCX orf、af和cf分类的混淆矩阵
表6为本文方法使用2 463个cf与文献[9]和文献[11]方法在ISCX上的acc对比。可以看出,本方法与文献[9]相比,acc提升约2个百分点,int减少了1.7 ms/样本左右,但是增加了FE和FF时间。与文献[11]相比,由于本文方法的orf和fuf个数更多,所以FE和FF时间相应增加了约 0.2 s和12 ms,int增加不到 0.2 ms/样本,但是acc提升了约4个百分点。从图15中可以看出,针对逐类别的f1_score,本文方法要明显优于文献[9]和文献[11]的方法。

图15 ISCX上本文方法与文献[9]和文献[11]方法的f1指标对比
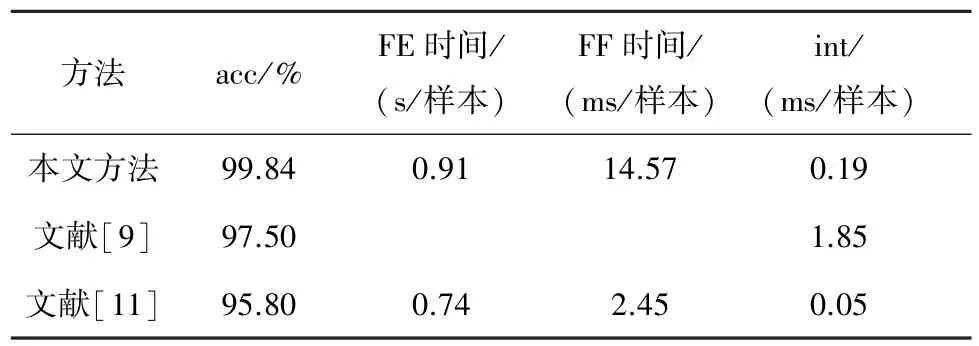
表6 本文方法与文献[9]和文献[11]方法的性能对比
探其原因:第一,文献[9]将字节特征作为1D-CNN的输入,要想达到高acc,需要更多的隐藏层和神经元,即需要计算更多的参数;第二,本文通过从高维特征集里选择最优特征子集,比字节特征的区别性更大;第三,文献[9]通过补零的方式截取1 500个字节,但在像聊天这样的流中大多数数据包远小于1 500个字节,会补充较多的零;第四,本文将NTC转换成 gi识别,从而识别效果更好。
与文献[11]方法对比,第一,本文所采用的FF方式比文献[11]的更加多样,cf也更多样;第二,文献[11]的方法在包含单一网络视频流上的分类结果具有优越性,但是在包含多种应用的业务分类上的性能会相对降低;第三,文献[11]所采用的嵌入式FS与模型有关,选出的特征子集中可能存在对模型贡献相同的冗余特征。尽管文献[11]方法的运行时间最短,但其acc最低。
5 结束语
本文首先对56个orf做加、绝对值加、减、绝对值减等14种运算,将56个orf扩展到21 560个fuf和21 616个 af。然后使用 pcc方法,对 af进行降维,从而有效删除冗余特征。在VD和ISCX两个数据集上进行了方法验证和对比实验;结果表明,设置特征之间的δff为0.90时,cf(分别为2 328个和2 463个)在两个数据集上的acc较使用af分别提高了约0.1个百分点和0.2个百分点,达到了99.80%和99.84%;int分别减少约80%。在ISCX上的对比实验结果表明,本文方法逐类别的f1_score都优于文献[9]和文献[11],acc较文献[9]和文献[11]的方法分别提高了约2个百分点和4个百分点。
本文方法的局限性:(1)在acc提升的同时,时间复杂度有所增加;(2)相关性FS只对线性相关敏感,而不能确定是否存在非线性关系;(3)在两个数据集上都证明,当特征之间的δff等于0.90时,所选取的特征可作为最优特征子集,但不排除最佳δff的选择可能会受到不同数据集的影响。
猜你喜欢
中学生数理化(高中版.高考数学)(2022年1期)2022-04-26
计算机研究与发展(2022年1期)2022-01-19
南京理工大学学报(2021年4期)2021-09-15
计算机应用(2020年12期)2020-12-31
数学小灵通(1-2年级)(2020年6期)2020-06-24
小型微型计算机系统(2018年5期)2018-07-04
计算机应用(2017年3期)2017-05-24
中学生数理化·八年级数学人教版(2017年2期)2017-03-25
电子制作(2017年23期)2017-02-02
文苑(2015年9期)2015-09-10
