
基于数据聚类的多目标跟踪信息融合方法
2022-09-20 00:47王奎武
电光与控制 2022年9期
王奎武, 张 秦
(空军工程大学,a.防空反导学院; b.研究生院,西安 710000)
0 引言
多目标跟踪(MTT)问题是将测量值或标记分配给目标,并按时间步长来处理多个目标航迹的问题[1-2],目标数量的估计是提高多目标跟踪性能的前提。基于随机有限集(RFS)的概率假设密度(PHD)[3]滤波是多目标贝叶斯滤波算法的有效的次优近似,其主要途径是在滤波期间递推传播多目标状态的一阶矩估计;其中,高斯混合(GM)和序贯蒙特卡罗(SMC)滤波是解决非线性问题的两种方法,即GM-PHD[4]和SMC-PHD[5]。
由于PHD具有简单易用的特性,目前被广泛应用于目标跟踪[6-8]、计算机视觉[9]、移动机器人[10]和车辆跟踪[11]等领域的研究。
在PHD滤波框架下,有效划分量测集是解决问题的主要思路,目的就是要把目标与其量测集一一对应起来,其结果的有效性将直接影响后续多目标数量估计的性能。如果充分考虑所有可能的划分子集,划分次数会因目标数量的增加而变得庞大,为此,文献[12]提出了一种基于距离划分的方法,该方法能有效降低计算量;在PHD滤波器的实现中,文献[13]采用K-means算法划分子集,适合多目标跟踪过程中目标数量未知且时变的情况,但是当量测数目变多时,其计算负担会变大;文献[14]针对初始点选择问题进行改进并提出了K-means++聚类算法,该算法提高了量测集划分的稳定性,但是对于量测中心的讨论并不够明确。为此,在充分考虑目标数量时变的前提下,提高杂波环境下的目标数量估计的准确性是提高PHD滤波性能的有效途径。
本文采用聚类算法中的模糊C-均值(FCM)聚类,通过目标数量补偿来提高目标数量估计的准确性,从而达到提高PHD滤波性能的目的。其中,基数补偿过程使用了信息加权共识滤波器(ICF)[15]进行信息融合,能有效提高估计的准确性。另一方面,在PHD滤波器的实现中,使用K-means改进聚类算法来提取估计值是一种常见的方法[16],然而,该方法对杂波的存在很敏感。为了解决这个问题,一般使用对噪声和杂波相对稳定的FCM聚类。此外,即使应用FCM聚类,也需要确定最佳聚类次数以提高聚类性能。为此,本文将从PHD滤波器中获得的目标数量信息和聚类基数信息进行融合。在聚类候选的数目中,选择滤波器基数信息作为基数补偿的信息,以此来提高目标数量估计的准确性。
1 SMC-PHD滤波器
1.1 PHD
PHD滤波是多目标跟踪的常用方法,PHD滤波器是一种近似的多目标贝叶斯滤波方法,在递推过程中PHD滤波器不用传播多目标的密度[17],而只需传播多目标的PHD。多目标贝叶斯递推过程与PHD滤波递推过程的关系如下:
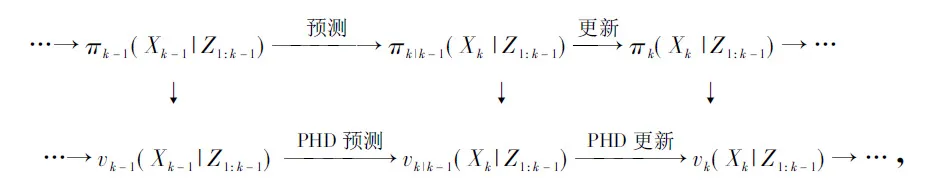
其先验方程为
(1)
假设多目标的先验概率近似服从泊松分布,则PHD滤波器的后验方程为[18]
vk(x)=[1-PD]vk |k-1(x)+
(2)
其中:vk|k-1(x)和vk(x)分别表示多目标的先验和后验密度函数;bk(xk)表示新生密度强度;λ为泊松杂波分布的密度;c(zk)为泊松杂波分布的概率密度函数;Ps为目标在k时刻的生存概率;PD为检测概率;g(zk|ηk)表示k时刻给定状态的似然函数。
1.2 SMC-PHD
SMC-PHD滤波器的递推过程包括预测步和更新步。
1) 预测步。
假设给定k-1时刻的后验强度vk-1,即
(3)
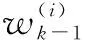
(4)
式中[17]:
(5)
(6)
(7)
(8)
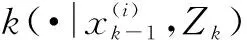
2) 更新步。
假设给定时刻的预测强度vk|k-1,即
(9)
则更新的强度vk可表示为[19]
(10)
式中[19]:
(11)
(12)
如果可以提高多目标数量估计的准确性,那么可以减少目标丢失导致的跟踪损失。因此,本文重点研究多目标数量估计的准确性,以提高PHD滤波器的跟踪性能。
2 FCM聚类
本文基于SMC-PHD,对重采样粒子进行FCM聚类,将聚类的中心值提取为状态变量,并用其进行数量估计,聚类性能将直接影响PHD滤波器的状态估计性能。
FCM允许一个数据属于两个或多个集群[19],适用于混入噪声的集群。FCM算法结构与K-means算法结构相似,且需要更多计算时间,但选择FCM的原因是为了提高目标数量估计的准确性。
假定n个数据样本为X={x1,x2,…,xn},把数据集划为l个类别{A1,A2,…,Al},各类别的聚类中心为(v1,v2,…,vl),样本j属于第i个聚类中心的隶属度为ui j,则定义FCM目标函数为[20]
(13)
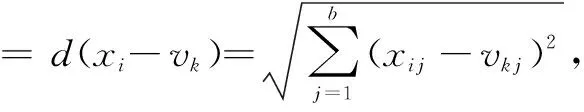
(14)
上文提到需要用FCM聚类算法进行迭代,因此需要对目标函数求极值,利用拉格朗日乘法将约束条件放入目标函数[21],分别计算样本xi对于Aj的隶属度ui j和聚类中心{vi},即
(15)
(16)
用式(15)和式(16)反复修改数据隶属度和聚类中心,当算法收敛时,理论上可得到各类的聚类中心以及各个样本的隶属度,根据所得的各聚类中心点以及原始数据集合,通过隶属度算式对隶属度矩阵进行更新,从此可以看出它是一个加权平均,当类别确定后,就可以求得隶属度,然后根据每个点的隶属度找到其所属的类别。
对3组目标量测值利用FCM聚类进行迭代聚类,将候选聚类中心数设置为3,最终迭代次数为50,如图1、图2所示。
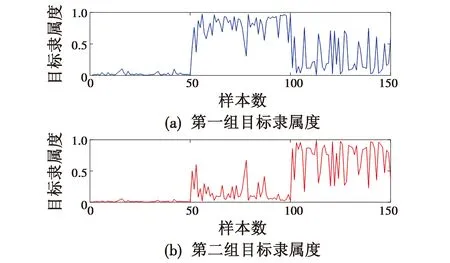
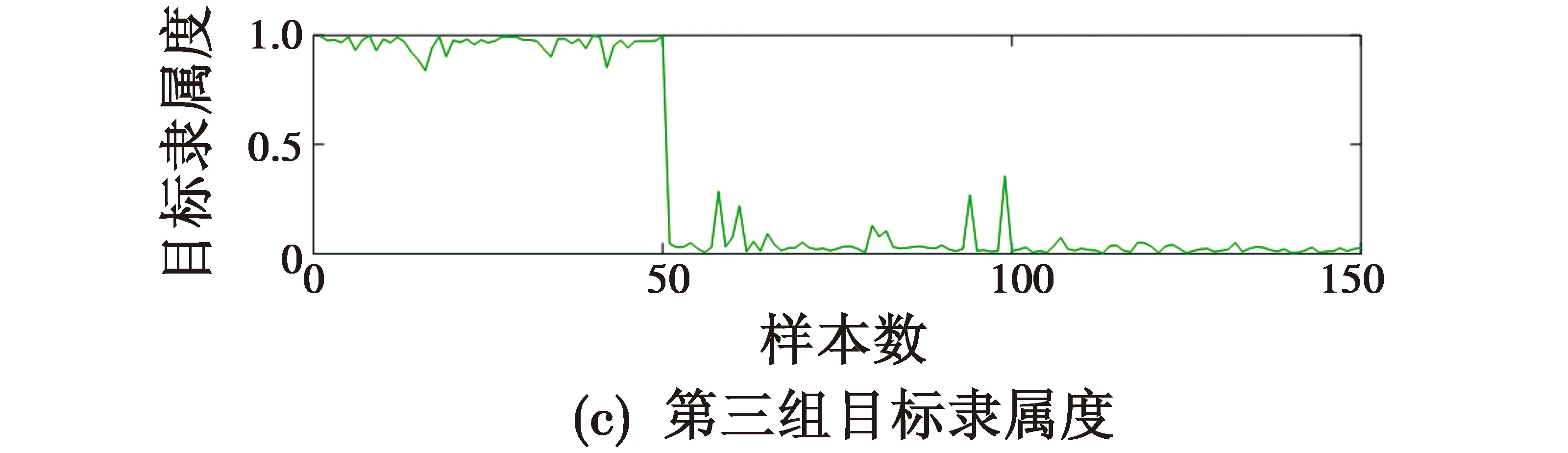
图1 隶属度矩阵值Fig.1 Membership matrix value
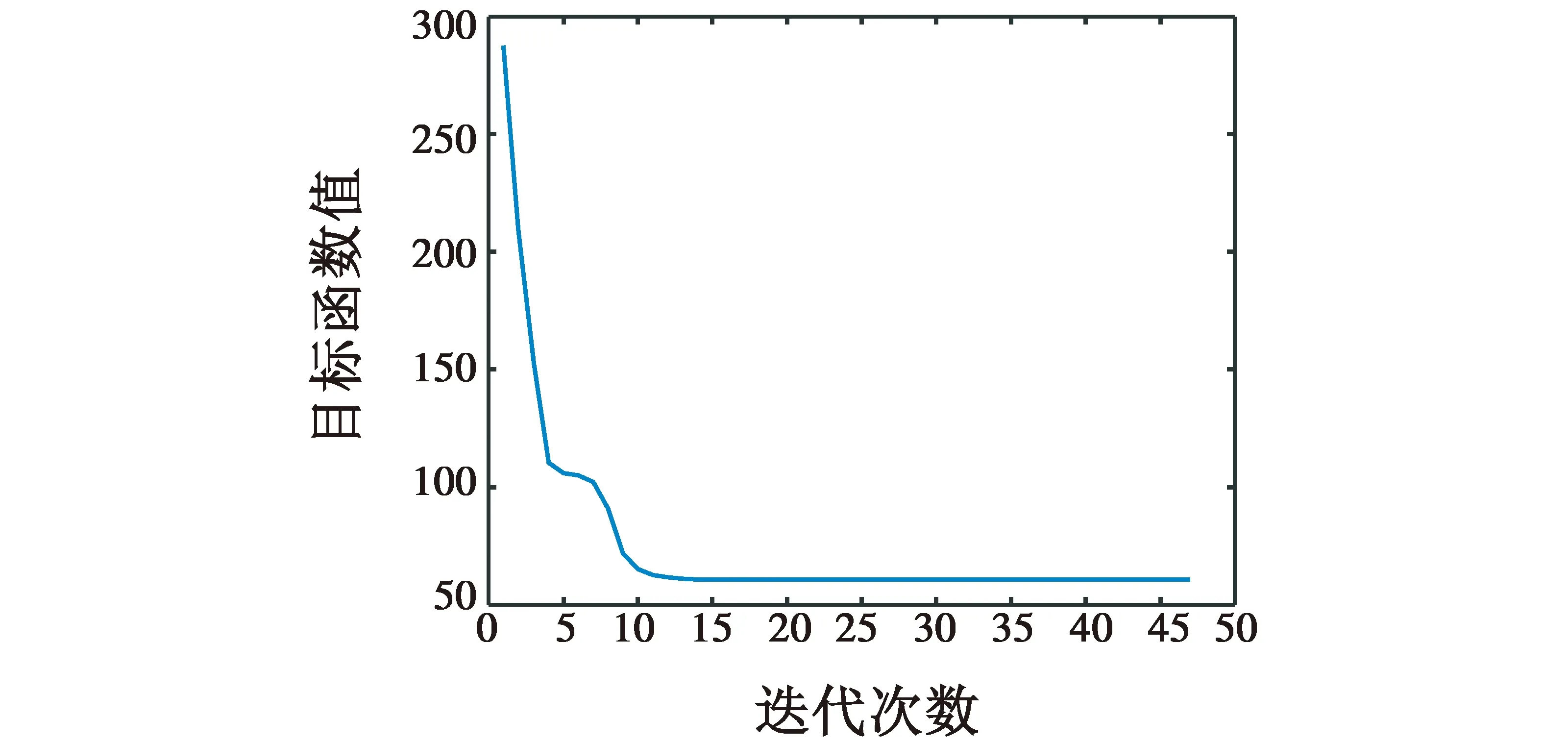
图2 目标函数值Fig.2 Objective function value
由图1和图2中可以看出,大概经过8次迭代,目标函数值就能达到一个比较稳定的状态,因此,可以根据每个类别的隶属度来确定目标数量,找到其中最大隶属度即认为这个点属于这一类。
3 目标数量补偿
目标数量补偿是通过两部分进行的。首先,目标基数是通过基于FCM迭代聚类计算得到的,然后将使用PHD滤波器获得的估计基数和从聚类结果中量测的目标基数进行融合,得到最终的目标数量估计,该方法在使用聚类技术和数据融合从基于SMC的PHD滤波器中提取状态变量时,可以用比现有的SMC-PHD滤波器更小的误差估计目标数量,从而能够有效改善PHD滤波器的性能。算法结构如图3所示。
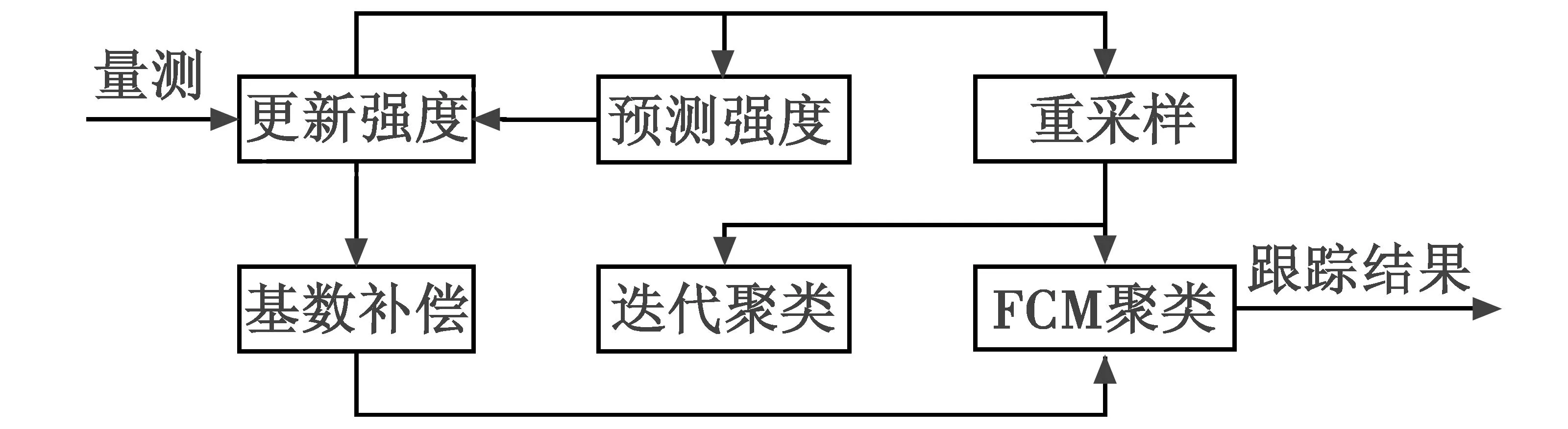
图3 算法结构Fig.3 Algorithm structure
信息融合方法用于组合两种不同来源的信息以提高目标估计数量的准确性。其中,ICF[15]用于融合信息以提高PHD滤波器中基数估计精度,并且是用于多传感器融合的一致性滤波技术之一。
ICF的状态模型和量测模型分别为
xicf(k+1)=Fxicf(k)+w(k)
(17)
zi(k)=Hi(k)xicf(k)+vi(k)
(18)
其中:系统噪声w(k)和测量噪声vi(k)均被简化建模为具有零均值、方差分别为Q和Ri的高斯白噪声;F为状态转移矩阵;Hi为量测矩阵。
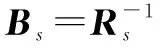
(19)
(20)
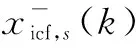
信息矩阵Cs和第s个节点传感器的矩阵向量cs独立执行平均共识,重复式(11)和式(12)从t=1到t=Tt(Tt为迭代次数),即
(21)
(22)
其中:h代表所有用于信息融合的传感器;ε为速率参数,应在0和1/Δm之间选择,Δm为连接传感器的最大数量。
下面给出基数补偿方法:
2) 计算初始信息矩阵C0和向量c0,并独立对C0和c0进行平均共识;
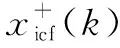
(23)
W+(k)=NCt;
(24)
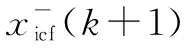
(25)
W-(k+1)=(F(W+(k))-1FT+Q)-1
(26)
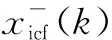
本文中设置N=2(一个来自PHD滤波器,另一个来自聚类过程)。
4 仿真实验
以二维平面的多目标跟踪为例,采用OSPA(Optimal Sub-Pattern Assignment)距离定量分析跟踪性能,其定义为
(27)
式中:Xk为目标状态值;c为分离参量,c>0,p为距离敏感性参数,1≤p<∞,选取p=1和c=200;OSPA距离越小,状态估计的精度越高。
目标的状态向量由其位置和速度组成,即xk=[px,kpy,kvx,kvy,k],在滤波中,分别选取匀速模型(CV)和转弯模型(CT)。
匀速模型(CV)运动方程为
(28)
转弯模型(CT)的运动方程为
(29)
其中:ω为角速度;采样间隔T为1 s,总跟踪时间为100 s;过程噪声wk是均值为零且标准差为5 m/s2的高斯噪声。产生的目标的过程噪声是高斯分布,均值为零,协方差为
(30)
式中,diag(·)表示对角矩阵。量测向量表示目标的位置,zk=[pzx,kpzy,k],量测方程为
(31)
式中,量测噪声为高斯分布,均值为零,标准差为5 m。
4.1 场景设置
观测区域中,x,y轴分别取值为x∈[-2000,2000],y∈[0,2000],单位为m,有10个相继出现的运动目标,该场景下目标真实轨迹如图4所示,其中,∘为目标起始位置,△为目标终止位置。
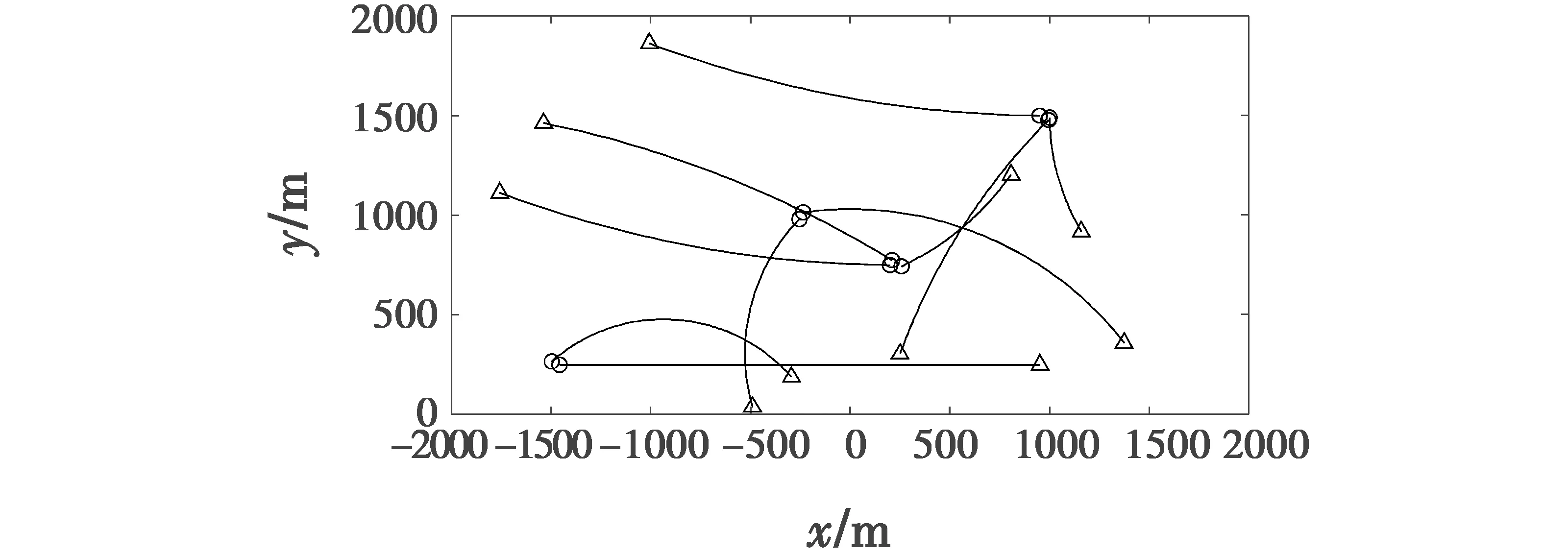
图4 真实目标轨迹Fig.4 Real target trajectory
4.2 仿真结果
图5所示为在4.1节场景设置下的跟踪结果,错误量测服从泊松分布,在100 s内均匀生成。
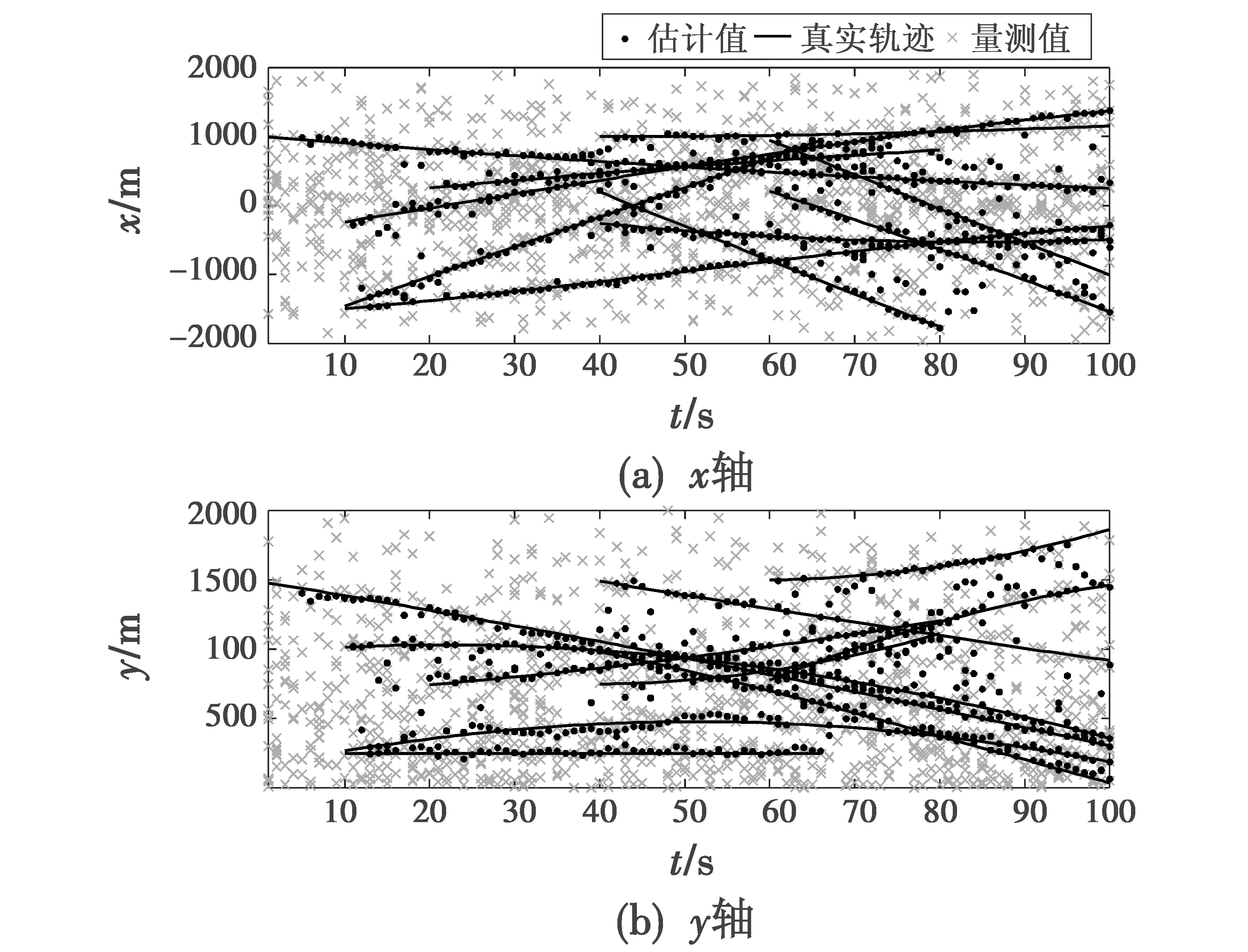
图5 跟踪结果Fig.5 Tracking results
其中,黑色实线是没有量测噪声的目标真实轨迹,分别展示在x轴和y轴上,·和×分别表示具有量测噪声和杂波的目标组成的量测,每次扫描的平均杂波数为60。
图6为K-means聚类、FCM聚类和本文所提算法经过信息融合后的OSPA距离和运行时间对比。
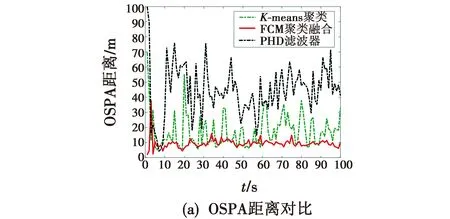
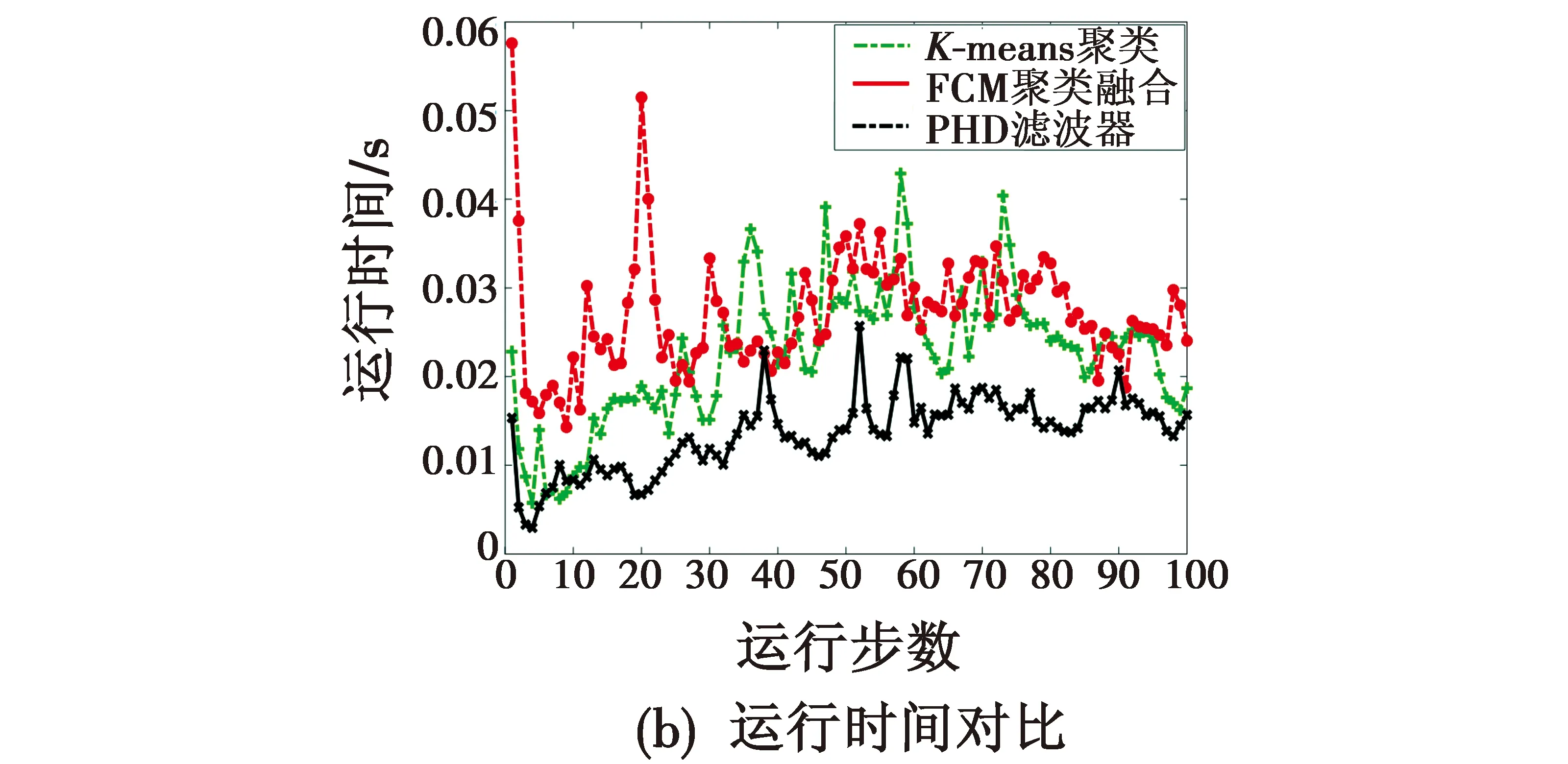
图6 不同算法性能对比Fig.6 Comparison of the performance of different algorithms
由图6(a)可以看出,量测值经K-means聚类后,其OSPA距离较大,是因为估计值与真实值误差较大造成的。而使用FCM聚类的跟踪性能明显好于K-means聚类以及PHD滤波器的跟踪性能。本文算法中的信息融合算法能够使其跟踪性能明显提高。图6(b)中,横轴表示运行步数,纵轴表示每个步数的运行时间,由此可以看出,FCM聚类融合算法运行时间略长于K-means聚类算法,但FCM聚类融合算法的跟踪精度明显高于其他两种算法。
图7显示了多目标真实数量、K-means聚类后目标数量、FCM聚类融合后目标数量以及PHD估计数量,其中,实线为真实值,点为估计值。估计的目标数量是100次蒙特卡罗模拟的平均值。
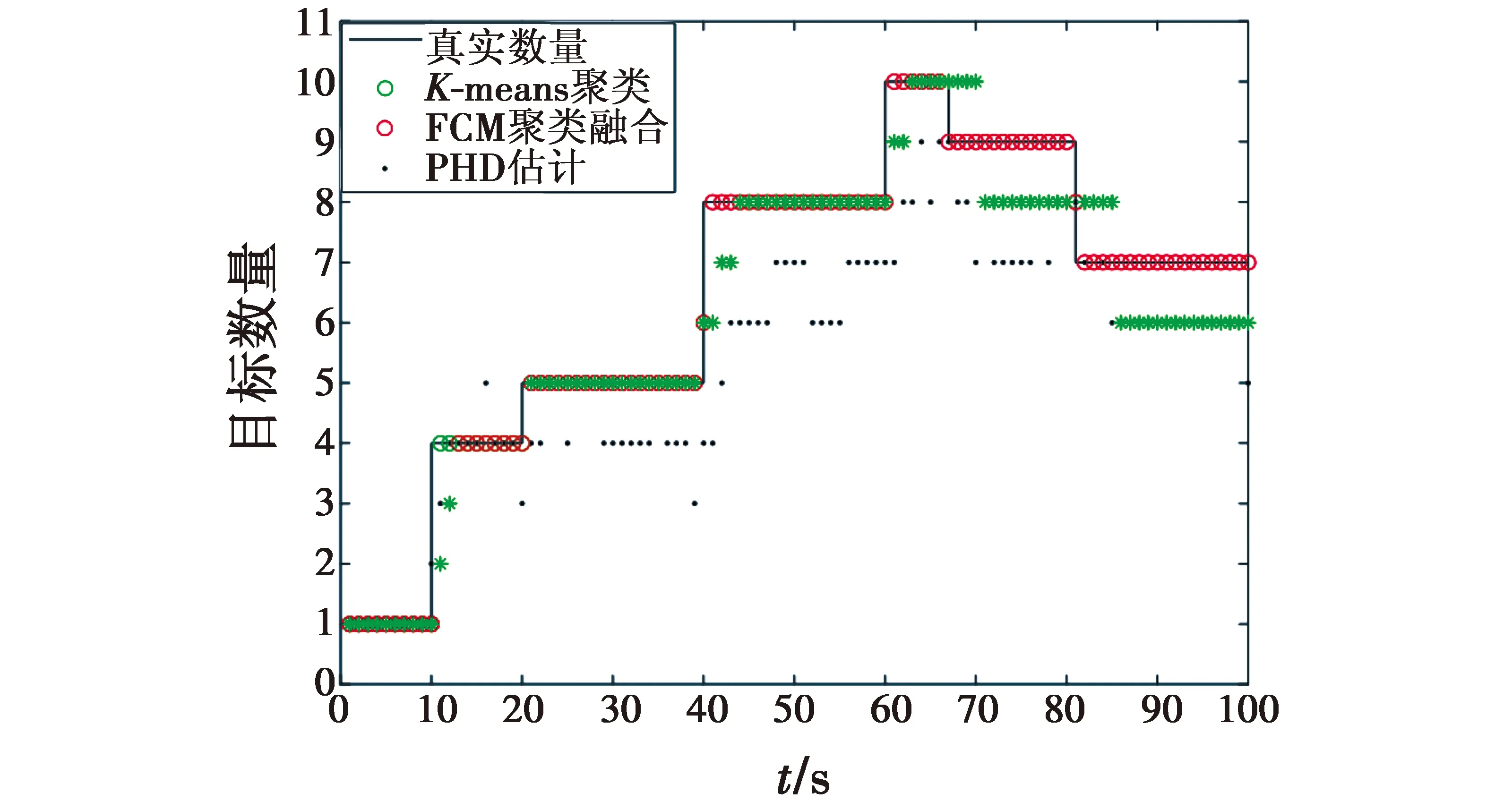
图7 目标数量估计Fig.7 Estimation of the number of targets
由图7可知,应用基数补偿的聚类融合算法对目标数量的估计效果明显好于其他两种算法。
仿真结果证明,密集杂波环境中在传统PHD滤波器中提取状态变量时使用FCM聚类而不是K-means聚类获得的基数,能够使估计性能得到提高。同时表明,使用基数信息进行补偿后估计性能得到了较大的提高。
5 总结
本文提出了基于ICF信息融合的方法,在PHD滤波器结构中,状态变量的提取使用了FCM聚类算法,与K-means相比,其在有较强噪声和异常值情况下,具有更强的鲁棒性。此外,通过ICF,利用迭代聚类算法得到的基数对目标数量估计进行补偿,可有效减少跟踪误差,提高跟踪性能。
猜你喜欢
无锡职业技术学院学报(2019年4期)2019-12-27
文萃报·周五版(2019年13期)2019-09-10
电子制作(2019年11期)2019-07-04
电子制作(2018年16期)2018-09-26
电子制作(2018年16期)2018-09-26
小学生必读(中年级版)(2018年6期)2018-09-05
电子制作(2018年1期)2018-04-04
火控雷达技术(2016年3期)2016-02-06
火控雷达技术(2016年2期)2016-02-06
海军航空大学学报(2015年1期)2015-11-11
