
基于注意力机制的农资标签文本检测*
2022-09-21 03:06殷昌山杨林楠胡海洋
中国农机化学报 2022年10期
殷昌山,杨林楠,胡海洋
(1. 云南农业大学大数据学院,昆明市,650201; 2. 云南省农业大数据工程技术研究中心,昆明市,650201;3. 绿色农产品大数据智能信息处理工程研究中心,昆明市,650201)
0 引言
农资标签是印刷于农资包装上的文字,主要包括有效成分含量、产品名称、登记证号、生产许可证号、产品标准号等用于描述该产品相关信息的内容。农民根据该信息查询并判断该产品是否符合自身需求,农资监督机构根据该信息进行农资安全相关的检测和分析,国外购买者依据该信息对出口农资进行识别。作为农资标签识别的必要步骤,农资标签的文本检测对于农资安全监督和识别出口农资非常重要。
目前,基于深度学习的文本检测方法主要分为基于区域建议和基于分割这两类。基于区域建议的算法根据文本独有的特点,在目标检测通用算法模型的框架下对其进行改进。Tian等[1]借助了Faster RCNN中anchor回归机制,提出了CTPN网络框架来获得图像中的文本行,对水平方向文本检测效果良好。Shi等[2]借助一阶段检测框架SSD,提出了Seglink算法,该算法让模型学习文本框的旋转角度,对水平方向和多方向的文本检测有较好的鲁棒性,但对任意形状的文本不能准确定位。而基于分割的方法则是受到经典语义分割算法的启发,在像素级上对每个点进行分类,经后处理输出文本区域。Li等[3]提出了PSENet,该网络使用渐进式扩张算法,有助于紧密文本区域的分离,能够精确地定位任意形状的文本实例。Liao等[4]提出的DB算法用近似可微分的二值化替代固定阈值,使后处理过程变得简单且泛化能力更强。该类方法可以适应任意形状的文本目标。
不同的农资包装包含不同尺寸、颜色、形状、对比度的标签文本,并且农资标签的背景更加复杂,其文本分布大多数是比较密集的,文本形状以水平形状规则文本居多,但也有任意形状文本存在。基于以上难题,提出了一个基于注意力机制的农资标签文本检测模型,并在自建的农资包装图片数据集上进行试验,能够较为精确地检测出农资图像中的文本。
1 基于注意力机制的农资标签文本检测模型
1.1 模型架构
本文提出的模型架构如图1所示,具体来说首先采用Swin-Transformer[5]作为主干网络,用于多层次特征图的特征提取。通过4个Stage构建不同大小的特征图C1、C2、C3、C4,除了Stage1中先通过一个Linear Embeding层外,剩下3个stage都是先通过一个Patch Merging层进行下采样。然后,按照FPN中的特征金字塔设计,选择C1、C2、C3、C4进行上采样和特征聚合。在特征聚合阶段,使用TFFM模块来整合局部和全局上下文的特征表示,并通过通道聚合将增强的C1、C2、C3、C4特征映射融合起来,进一步将语义特征从低层次升到高层次,并在检测头也使用TFFM模块,用来增强特征的信息表征能力。最后,将缩放式扩展算法生成的分割结果聚合到输入图像的原始规模,以预测文本区域并重建文本实例。

图1 模型基本架构
1.2 双特征融合模块
目前基于分割的文本检测方法在像素级上对图像区域进行划分,只提取感兴趣区域的文本,忽略了全局特征的存在,对文本检测结果的准确性有很大影响,所以本文的动机就在于建立融合局部和全局特征的关系模型,首先想到的是全局自注意力机制,此方法能够很好地捕捉到全局信息,但也会带来过多的额外计算负担。受到DANet[6]的启发,设计了双特征融合模块TFFM,该模块利用注意力机制,将全局特征中更强的语义信息与局部特征中更好的细节感知能力融合起来,以此来得到更丰富的特征表示,增强模型对文本的检测能力。模块具体结构如图2所示,其中r为系数。

图2 双特征融合模块结构
对于通道数为C、高度为H、宽度为W的输入特征图Fi(i=1,2,3,4),首先各自应用一个1×1×C的卷积层,改变通道数,然后由通道注意力模块(Channel Attention Module,CAM)和外部注意力模块(External Attention Module,EAM)这两个注意力模块分别对卷积后的特征进行优化,最后将两个注意力模块提取的特征相加以此来得到输出特征outi如式(1)所示。
outi=CA(Conv1(Fi))+EA(Conv1(Fi))
∀i={1,2,3,4}
(1)
式中:CA(·)——CAM运算;
EA(·)——EAM运算;
+——对应元素相加。
其中CAM先做全局的平均池化,将输入特征F综合为通道为C的一维特征向量,然后通过全连接神经网络MLP来比较全面地得到通道级别的依赖,获得各个通道的权重,其中MLP是由两个全连接层和ReLu激活函数组成,最后将权重与原始特征融合起来,运算细节如式(2)所示。
CA(F)=σ(MLP(AvgPool(F)))
(2)
EAM是对线性自注意力机制的应用,其计算复杂度是线性的,减小了网络的计算开销。先将维度扩充到四倍,然后采用线性层Mk通过式(3)得到注意力图A,并对A在第一维用了Softmax操作,在第二维用了L1-norm来归一化,最后采用线性层Mv通过式(4)获得输出EA。
A=Mk(Reshape(F))
(3)
EA=Linear(Reshape(Mv(A)))
(4)
式中:σ(·)——激活函数Sigmoid;
Linear(·)——全连接层,把特征图恢复成原来的维度。
1.3 缩放式扩展算法
经典的目标检测模型采用NMS算法来筛选候选框并标出物体类别。然而,文本本身有其独有的特点,文本大多以长矩形形式存在,即长宽比一般较大或较小,候选区域经IOU筛选后,预测的结果仍会出现边界框重叠现象,影响检测效果,受到PSENet中渐进尺度扩展算法的启发,采用了缩放式扩展算法。
渐进尺度扩展算法产生n个分割结果,然后根据尺度扩展将文本实例从最小一步步扩充到最大,这样可以很好地解决紧靠的文本实例,从而保证文本实例的准确位置,但是农资文本在印刷过程中,为了更好地展现产品,相邻的文本实例并不太密集。考虑到农资文本的特殊性,使用三个收缩率系数来实现扩展算法,分别为0.5、0.8和1.0,具体算法如图3所示,先通过最小内核的文本实例的分割结果S1生成连通域,并用数字标记出来,然后通过尺度扩展展开内核轮廓,以便将前景像素分配到文本实例,扩展到最大的内核S3,对于每一个文本实例,将点坐标序列表示的文字遮罩转换为文字边界点坐标,最后得到实例边界及其实例置信度,即文本实例的最终检测结果。
使用Vatti算法[7]来缩小原始多边形文本框,以此来得到对应的不同内核的分割结果,在图4(a)左边边框是基于最大内核的文本实例,也就是原始标注的多边形边框,而图4(b)左边边框是基于最小内核的文本实例,图4(a)和图4(b)的右边是对应的分割标签掩码,可以看到文本边框明显缩小了,相比于左边原始的文本区域的边框p与缩小后的文本区域的边框pi之间的偏移di如式(5)所示。
(5)
式中:Ai——第i个多边形的面积;
Li——第i个多边形的周长;
smooth——平滑系数;
ri——内核的收缩率;
Shrinkmax——最大收缩距离。

图3 生成文本框的流程

(a) 最大内核

(b) 最小内核
1.4 loss函数
本文使用的损失函数L由文本实例损失函数Lt和内核实例损失函数Lk两部分组成,如式(6)所示。
L=αLt+(1-α)Lk
(6)
式中:α——平衡系数。
为了避免网络只预测图像中的很小部分范围的问题,使用Dice系数s来注重对前景区域的检测,使网络更倾向于文本区域。Dice系数s用来计算Ground Truth分割图像和Pred分割图像之间的相似度,取值范围为[0,1],如式(7)所示,内核实例损失函数Lk如式(8)所示。此外,为了处理检测网络中容易出现的正负样本不均衡的问题,在文本实例损失函数中加入了难样本挖掘(Online Hard Example Mining,OHEM)[8]策略,正负样本比例设定为1∶3,将通过难样本挖掘算法的掩膜记为M,则Lt计算公式如式(9)所示。
(7)
(8)
Lt=1-s(X·M,Y·M)
(9)
式中: |X|——Ground Truth元素个数;
|Y|——Pred元素个数;
|X∩Y|——X和Y之间的交集,可近似为Ground Truth和Pred之间的点乘,并将点乘元素的结果相加。
2 材料与方法
2.1 数据集
目前公开数据集大多是关注自然场景图像,没有对农资方向做研究,因此通过自建数据集形式进行模型训练和试验研究。数据集大多来源于网络图片,这些图像涵盖了农药、化肥、农机铭牌等主要农资组成部分,有不同颜色以及透明的袋、瓶和罐状包装,得到农资包装图像共计708幅。图像中含有不同形状的农资标签文本,文本框总共11 322个,其中矩形文本框10 136 个,多边形文本框1 186个。在标注过程中利用labelme图像标注软件对数据集进行人工标注,再转换成CTW1500格式,文本区域由若干个坐标点顺时针连接构成的多边形表示,可以满足任意形状的文本检测。原始图像和人工标注如图5所示。

图5 原始图像和标注图像示例
由于数据集数量较少,故采用自助采样法对数据集进行划分,如表1所示,其中训练集图像为448幅且包含7 171个文本框,测试集图像为260幅且包含4 151 个文本框。
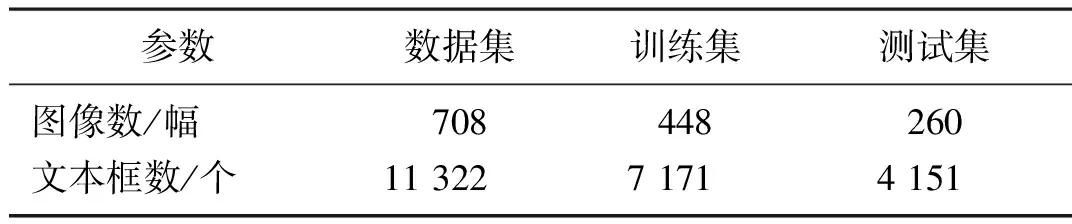
表1 数据集信息Tab. 1 Datasets information
2.2 试验平台
实验室服务器的主要配置为2块NVIDIA 3090显卡,cpu型号为Intel(R) Xeon(R) Silver 4210R CPU @ 2.40 GHz,操作系统为Ubuntu20.04,在此基础上,搭建Pytorch框架对模型进行训练和测试。
2.3 模型训练细节
使用Swin-Transformer模型作为骨干网络,首先在IC17-MLT训练集上预训练600个epoch,然后在试验中,模型又在自建数据集上做600个epoch的微调训练,采用自适应梯度优化器,初始学习率为0.000 1,在第200次、第400次迭代进行学习率衰减。
为了提高模型的泛化能力,增强模型的鲁棒性,对训练图像按50%的概率进行水平翻转、随机缩放、色彩抖动来做在线数据增强,最后将图像尺寸随机裁剪成640×640。
3 结果与分析
3.1 评价指标
现有评价指标一般用准确率(Precision)、召回率(Recall)和F值(F-score)这三个参数进行比较。一般来说三个指标的值越高,检测算法的性能越好。其具体计算公式如式(10)~式(12)所示。此外,采用基于IoU的评估协议。IoU是一种基于阈值的评估协议,默认阈值为0.5。
(10)
(11)
(12)
式中:TP——真阳性;
FP——假阳性;
FN——假阴性。
3.2 骨干网络的影响
本文对比了ResNet-50、ResNet-50-Dcnv2和Swin-Transformer骨干网络对试验结果的影响,首先将三个骨干网络各自在IC17-MLT训练集预先训练,之后进行试验,具体结果如表2所示。

表2 骨干网络对模型的影响Tab. 2 Influence of different backbone network on our model
从表2可以看出,使用Swin-Transformer骨干网络,模型在三项指标上分别提升了1.3%、3.3%和2.4%,在召回率上上升尤为明显,这体现了该方法的有效性。由于骨干网络提取特征能力的不同,使用Swin-Transformer模型能获得更丰富的特征,从而提高检测方法的能力。
3.3 双特征融合模块的影响
为了验证双特征融合模块对模型的影响,通过试验对比改进前后的模型检测性能。使用IC17-MLT训练集预先训练过的ResNet-50作为主干,并构建了图1中的模型,在C1、C2、C3、C4进行上采样和特征聚合, 并在检测头也使用了TFFM。在这部分试验中,通过与是否加入TFFM进行比较,研究并验证了双特征融合模块的有效性。在表3中,可以看到,加入TFFM后,在与改进前的模型相比,各项指标都有显著的增长,在精确率、召回率、F分数分别达到了89.2%,85.9%和87.5%,各项评测指标的提升率为1.6%、2.6%和2.1%。相较于改进前单纯使用特征金字塔的方式,通过增加双特征融合模块使得全局信息和局部信息在特征融合中进行了加强,减少了在相邻尺度特征融合过程中造成的信息缺失,即在自顶向下的特征融合过程中会改变通道数,使得全局特征中相当多的语义信息丢失了,而双特征融合模块利用通道注意力机制和线性自注意力机制来学习高层的语义信息和低层的定位细节,在一定程度上减少了语义信息的丢失,增强了多尺度特征的表达能力。
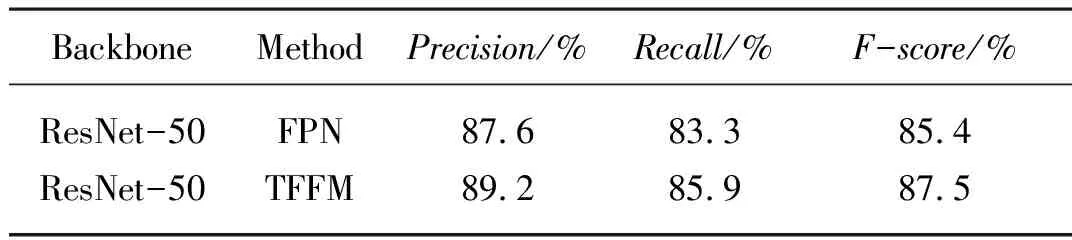
表3 双特征融合模块对模型的影响Tab. 3 Influence of TFFM on our model
3.4 缩放式扩展算法的影响
对提出的缩放式扩展算法对模型的效果进行了试验,试验结果如表4所示。使用该方法的准确率、召回率和F分数都有了提升,在召回率和F分数上分别提升了3.2%和1.8%,由于农资图像中文本自身的特点,缩放式扩展算法在一定程度上简化了文本实例扩展的复杂度,并增加了文本框的匹配正确个数,这使得召回率和F分数提升效果更明显,也证明了缩放式扩展算法能提高检测效果。

表4 缩放式扩展算法对模型的影响Tab. 4 Influence of scaling expansion algorithm on our model
3.5 消融试验
在自建数据集上进行了消融试验,以此来展示本文提出的骨干网络、双特征融合模块以及缩放式扩展算法的有效性,试验结果如表5所示,Baseline是PSENet模型,ResNet-50是Baseline使用的骨干网络,从表中可以看出,使用Swin-Transformer骨干网络对模型改进效果很大,而在使用Swin-Transformer骨干网络的基础上分别使用双特征融合模块和缩放式扩展算法,在三项指标上均有较高的提升。同时使用改进方法,本文提出的模型在准确率、召回率和F分数达到了91.4%、87.3%和89.3%,在三个指标上达到了较好效果,相比之前未修改的模型,在各个指标上都有大幅提升,充分证明了文本方法对农资标签文本检测有很好的效果。
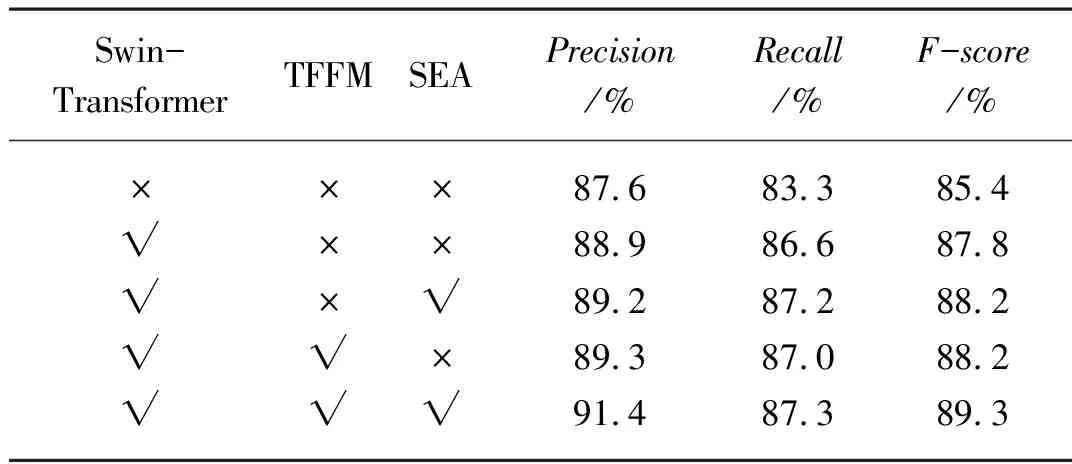
表5 不同设置对模型的影响Tab. 5 Influence of different settings on our model
3.6 不同算法模型比较
为了验证本模型的可靠性,将本文提出的模型与近年来优秀的文本检测算法在自建数据集上进行了对比[9-20],结果如表6所示,试验结果证明了所提出方法对农资标签文本检测有很好的效果。
对农资标签文本检测效果不优秀的问题主要在于标签文本丢失或者检测不准确,PSENet模型在检测较小文本时存在丢失问题,该方法核心是对不同分割结果进行渐进尺度扩展算法,但是如果文本区域较小时,算法分割的内核就不明显,导致检测文本区域的丢失。FCENet[9]模型虽然能检测到较小文本,但它的强项在于通过傅里叶变换来拟合任意形状文本,对规则文本拟合的效果不好,存在偏差,但整体效果比PSENet效果要好,准确率、召回率和F分数上分别达到了89.5%、85.9%和87.7%。在自建数据集上,本文算法与基于区域建议算法的FCENet相比,在三项指标上分别提升1.9%、1.4%和1.6%,与基于分割算法的PSENet相比,在三项指标上分别提升3.8%、4%和3.9%,所以综合来看本文算法优于其他模型,可以充分提取图像中文本区域特征,能有效地对其进行检测,在很大程度上提升了农资标签文本的检测效果。

表6 不同算法模型对自建数据集的比较Tab. 6 Comparison of different algorithm models on our datasets
4 结论
1) 提出了一种基于注意力机制的农资标签文本检测模型,在自建的农资包装图像数据集上,对模型骨干网络结构、双特征融合模块和缩放式扩展算法的改进使得文本检测的效果有了大幅的提升,本文提出的模型在准确率、召回率和F值上分别达到91.4%、87.3%和89.3%,优于目前主流的自然场景文本检测模型。
2) 采用Swin-Transformer骨干网络来提取更丰富的特征,相比于原来模型的ResNet-50骨干网络,在三项指标上均有提升,分别提升了1.3%、3.3%和2.4%。针对基于分割的文本检测方法中忽略全局特征的问题,本文采用了双特征融合模块,将全局特征中的语义信息与局部特征中的定位细节融合起来,增强了模型对文本的检测能力,与未使用双特征融合模块作对比,各项评测指标提升了1.6%、2.6%和2.1%。
3) 针对农资包装图像中相邻的文本实例不太密集的特点,本文采用了缩放式扩展算法,该算法在一定程度上简化了文本实例扩展的复杂度,提高了文本检测效果,相对于原有算法,在召回率和F分数上分别提升了3.2%和1.8%。
猜你喜欢
今日农业(2022年13期)2022-11-10
初中生世界·九年级(2018年12期)2018-12-22
吉林农业(2017年7期)2017-07-12
农家顾问(2016年6期)2016-05-14
读者(2015年9期)2015-05-04
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
初中生世界·八年级(2014年2期)2014-03-15
意林(2011年10期)2011-05-14
