
基于深度强化学习的服装缝制过程实时动态调度
2022-09-22 14:56柯文博
纺织学报 2022年9期
刘 锋, 徐 杰,2, 柯文博
1. 武汉纺织大学 纺织科学与工程学院, 湖北 武汉 430200; 2. 武汉纺织大学 省部共建纺织新材料与先进加工技术国家重点实验室, 湖北 武汉 430200; 3. 广东前进牛仔布有限公司, 广东 佛山 528000)
服装制造业是我国国民经济的重要组成部分,伴随国内生产成本的上升,我国服装产业已进入提质增效的关键时期。同时,服装生产需求也在发生着深刻的变化。由于客户的个性化需求增加以及品牌商为避免存货和滞销成本,现今的服装生产需求已明显由过往的少品种、大规模转为多品种、小批量、短交期,这对服装生产企业的柔性生产以及快速响应能力提出了挑战。应对上述挑战最为直接的方法是对生产设备进行革新,采用新型柔性化设备。但一方面,由于投资费用与生产利润的相互制约,导致实际生产过程中设备更新缓慢;另一方面,新型设备所带来的效率提升也存在瓶颈,且不少企业由于管理水平有限,存在无法充分有效利用设备资源的问题。生产调度方法是通过将现有的制造资源进行有效合理地分配,从而实现生产能力提升[1],且该方法极具经济性[2],更符合我国以中小企业为主的服装制造类企业的实际需求。
在现有条件下,有效的生产调度方法可作为提升服装制造业竞争力的核心技术之一。在过往数十年,有众多生产调度方法被提出,但大多数基于静态生产环境的假设,即车间制造信息事先完全已知且不会发生变化。然而,由于现有服装生产过程中存在大量插单返单、订单到达时间随机、加工人员流动、设备故障等动态因素,对已有调度方案产生干扰,使生产安排与生产实际严重脱离,造成生产混乱。为提升服装生产企业对动态事件的响应能力,确保生产的高效性、稳定性与连续性,动态调度方法成为现今的研究重点。
过往的生产调度算法研究主要分为精确算法和近似算法。精确算法,例如分枝定界法,能确保求出最优调度方案,但难以应对NP-hard问题,较少运用于生产实际。而近似算法能求出近优或最优解,且适用于中大规模问题,成为该领域的研究热点。元启发式算法和启发式算法是研究和应用较多的二大类近似方法。其中,元启发式算法能适用于多种类型问题求解,并能提供较好质量的解。在服装生产调度领域,遗传算法[3]作为一种通过模拟达尔文自然进化过程的元启发式算法得到广泛运用。郑卫波等[4]通过遗传算法求解服装生产调度模型,实现了减少订单总体拖期时间的目标;谢子昂等[5]利用遗传算法结合滚动窗机制解决了服装吊挂流水线的动态调度问题。然而,该类算法计算量会随着问题规模呈指数增长,面对中大规模动态调度问题无法实时响应。相对而言,启发式算法(如NEH算法[6])源自专家知识或经验,能有效且快速地解决特定的调度问题[7],但该类方法是基于特定条件而归纳出来的算法,相同的算法在不同条件下会有迥然不同的表现。动态调度本质上是顺序决策问题,通常形式化为马尔科夫决策过程,其从问题的顺序中间状态确定一系列最优决策以实现优化目标。由于中间状态不断变化,单一启发式算法显然无法一直提供最优解。
随着人工智能技术的快速发展,强化学习方法近年来得到广泛关注,并应用于包括智能调度在内的各类决策问题[8-10]。强化学习本身基于马尔可夫决策过程,由智能体与环境的不断交互过程中逐步完善策略,目标是实现最大的长期奖励。在服装生产动态调度问题中,启发式调度规则可被视为强化学习中的可选动作,通过与环境不断交互所构建的策略(本质上是一个启发式调度规则的自适应选择器),可实时有效地响应生产状态的变化,最终达到调度目标。为此,本文面向服装的缝制生产过程,以最小化最大完工周期为目标,提出利用深度强化学习算法对缝制生产过程进行实时动态调度,以期提升缝制生产的高效性和连续性。
1 强化学习基本原理
1.1 强化学习与Q-learning方法
强化学习是一种机器学习算法,其通常基于马尔科夫决策过程进行建模。马尔科夫决策过程是顺序决策的数学模型,通常采用四元组[S,A,R,P]来表示。在决策时间点t,st∈S代表当前状态;at∈A,代表在t时刻所采取的动作;P(st+1,rt+1|st,at)∈P,表示状态st时采取动作at转移到状态st+1以及获得相应即时奖励rt+1概率。
强化学习的目标是使智能体在与环境交互过程中找到一个最优策略。在此,策略π(a|s)是指状态到动作的映射,如果从状态s一直遵循最优策略π*,能获得最大累积奖励的期望。通常,状态s在策略π的指导下,所能获得的累积奖励的期望用状态价值函数Vπ(s)=E[rt+1+γrt+2+γ2rt+3+…|st=s]表示或状态动作价值函数Qπ(s,a)=E[rt+1+γrt+2+γ2rt+3+…|st=s,at=a]来表示。其中,γ∈[0,1],是为了区分短期奖励与长期奖励之间的相对重要性。Vπ(s)和Qπ(s,a)之间的关系可用式(1)和(2)描述:
(1)
(2)
将式(1)代入式(2),可得到贝尔曼期望方程
(3)
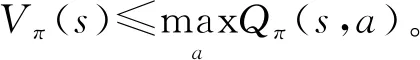
(4)
标准的Q-learning方法即基于贝尔曼最优方程演化而来[11]。
1.2 DQN与DDQN算法
由于标准的Q-learning利用表格法存储和查询状态-动作的Q值,因此,仅能处理具有离散及有限状态的问题。为解决该不足,Mnih等[12]提出Deep Q-network(DQN)算法,即利用深度神经网络来拟合状态特征与各动作的Q值之间的对应关系,从而能处理大型且连续的复杂问题。由于标准DQN算法在最大Q值确定过程中,评估和选择均采用同一网络进行,易造成对Q值的过估计。Van等[13]提出Double DQN(DDQN)算法,该算法体系与DQN算法基本相同,只是对最大Q值的评估过程采用正在更新的网络,而选择过程采用目标网络,因此,该过程所选出的最大Q值一定小于或等于标准DQN算法所选择的值,从而减少过估计,更接近真实Q值。本文即采用DDQN算法框架建立Q值网络,并据此在决策节点选择最合适的调度规则。
2 服装缝制调度问题的描述
在服装缝制生产中,当缝制线调整完毕后,主要加工同一类型服装,即具有相似加工顺序的服装,而同类型不同款式服装在加工过程中,主要体现为各工序加工时间不同。本文缝制生产调度问题可描述为:n件服装需要在m道工序上进行顺序加工,每个工序有x个并行加工工位,调度的目的是确定所有待加工服装的加工顺序及其在各工序并行工位上的分配方案,以达到生产调度目标。
同时,基于服装加工特点以及生产现状,做出以下假设:1)1个工位同一时间只能缝制1件服装;2)由于现有服装缝制生产大多基于吊挂系统,工序之间物流传递时间固定,将物流传递时间以及加工准备时间直接计入加工时间;3)工序之间有充足的缓冲区。
本文以最小化最大完工时间f为调度目标(见式(5),最大完工时间是指所有服装加工完成的时间),根据生产实际及其相应约束条件建立混合整数规划模型,所涉及的相关模型参数描述见表1。

表1 模型参数说明
Min:f=(maxCi,m|i=1,2,…,n)
(5)
(6)
(7)
(8)
(9)
(10)
式(6)表示每道工序只能由唯一1个并行工位完成;式(7)表示此工序的开始时间不能早于上一工序的结束时间;式(8)表示第一工序的开始时间不能早于加工任务的下达时间;式(9)确保任意时刻,在任一工序上加工的服装总数不能超过该工序上的并行工位数;式(10)表示缝制过程不能中断,在相同工位上,后一顺位所加工的服装不能插入前一顺位的加工过程。
3 基于深度强化学习的调度方法
将深度强化学习方法应用于服装缝制生产调度,首先需要通过定义状态、动作、奖励、探索和利用方法等将调度问题转化为一个顺序决策问题。然后,利用本文采用的DDQN算法基于过往生产数据训练调度策略。最后将该调度策略用于解决加工任务动态到达的服装缝制过程调度问题。本文提出的方法框架如图1所示。

图1 基于深度强化学习的服装缝制过程实时动态调度方法总体框架
3.1 状态特征
状态特征是对状态变量的数值表征,用于描述调度环境的状况及其变化。本文将任意时刻的状态以2张二维结构表格和1张一维结构表格进行表达,并抽取特征(见图1)。
1)加工中服装各工序加工时间表(A表):该表横坐标表示加工工序,纵坐标表示正在加工的服装,纵坐标从上至下的排列顺序表示服装的加工顺序,表中数据为归一化后的不同服装在各工序上的加工时间。归一化的目的是为了避免神经网络不同输入之间的尺度相差过大,造成影响力不同,归一化依据式(11)进行。
(11)
式中:x为原数据;xmax、xmin分别为原数据中的最大与最小值;xscale为归一化后的数据。
2)加工中服装各工序预估完工时间表(B表):此表表示根据已安排加工服装排序及工位分配方案,所计算出的每个工序的完工时刻。该表中横纵坐标与A表相同,表中数据为归一化后不同服装在各工序上的预估完工时刻,该完工时刻可通过生产中实际完工时刻进行实时修正。
3)各加工设备的预估利用率(C表):该表中设备利用率是指,从当前决策时刻t开始,到当前所有正在加工中的服装在工位M上预计全部完成的时刻tM之间的利用率,即利用率UM=TM/tM-t。其中TM是指t-tM时间段内设备的使用时间。
针对A表和B表,分别利用不同尺寸的一维卷积核,包括2×m、3×m、4×m,来提取相邻工序和相邻加工任务之间不同尺度上的关联特性,并将生成的卷积特征做最大池化处理,最后与C表中数据相结合作为状态特征(见图1)。相对于直接利用表中数据进行描述,该方法自适应挖掘特征能力更强,在应用中具有更好的泛化效果。
3.2 动作空间
启发式规则能够有效且快速地解决特定的调度问题,但任何规则在所有的生产状态下不可能均取得良好效果,因此,根据不同的生产状态应选择不同的调度规则。本文构建了由16项规则组成的动作空间(见表2),所学习出的最佳策略会依据不同的状态选择相应的规则,依据该规则从待加工服装中进行挑选并加工,最终实现最小化生产周期的目标。

表2 候选动作集
3.3 奖励函数
奖励函数的设计与调度目标密切相关,但在调度规模或产品不同的情况下,生产周期差距巨大,故无法直接利用生产周期作为奖励函数的构成依据。而生产周期与机器利用率密切相关,在约束条件不变的情况下,生产周期越短的工位(设备)平均利用率越高[14-15],因此,本文直接利用所有加工任务加工完成后的工位平均利用率,作为学习过程的总奖励,如式(12)所示。
(12)
式中:ti,j表示第i件服装在第j工序的加工时间;Mtotal表示缝制线上总工位数;Cmax为最大完工周期。
3.4 探索与利用
探索(exploration)的目的是找到更多有关环境的信息,挖掘可能获取更大Q值的动作。而利用exploitation是在已知的最优策略的基础上,直接选Q值最大动作,用以最大限度地提高奖励。为平衡探索与利用之间的分配,本文采用ε-greedy算法,即1-ε的概率随机从动作空间中选取动作,以ε的概率从中选取已知Q值最大的动作a:

(13)
式中,ε并非固定值。在学习初期对环境的认知较低,需要加大对环境的探索,而在学习中后期需要利用已知环境信息最大的提升奖励,因此,本文中ε将按下式进行变化:
ε=εmaxmin(1,2eiter/Nepisode)
(14)
式中:εmax为能达到的最大ε值,本文中设为0.95;eiter为当前的学习次数;Nepisode为设定的总学习次数。
3.5 算法框架
本文训练方法是基于DDQN算法框架,在训练过程中,新加工任务可随时加入待排任务组中,每当首加工工序中有工位出现空闲时被定义为决策时刻t,在该时刻从待排任务组中选择一件服装进入加工过程。整体算法框架如表3所示。

表3 基于DDQN训练算法框架
4 实例仿真
4.1 参数设置与模型训练
本文以牛仔裤前片缝制为例,按工艺流程分解为顺次的15个工序,为保证流水线各工序生产平衡,每工序上有1~3个等速加工工位,如表4及图1所示。对表中前7款牛仔裤的前片加工任务进行调度,所生成的调度方案如图2(a)所示。

图2 调度方案

表4 牛仔裤前片缝制流程及不同款式加工时间
本文所提出的方法在 python 3.6中进行编程,计算环境为AMD Ryzen 7 4800 H@ 2.9 GHz CPU,16 GB RAM,windows10系统。其中,深度神经网络部分使用Keras进行搭建,该网络输入层的设置如3.1节所述,另外包含全连接隐含层4层,每层的神经元个数分别为512、512、256、128, 激活函数为softplus,输出层含16个神经元对应16个动作,损失函数为mean_squared_error,优化器为Adam,网络参数采取随机初始化策略。训练样本从历史生产数据中进行选取,训练时采用20个加工任务作为训练样本。前6 000次训练过程中工位利用率如图3所示。可以看出,工位利用率曲线随着训练次数增加而逐渐平稳,表明所训练的Q值网络已经有效地学会在不同情况下选取适当的调度规则。

图3 训练过程工位利用率变化
4.2 仿真结果及分析
利用已训练出的模型对加工过程进行调度,调度目标为总加工周期最小。图2(a)所示的表4中前7款牛仔裤的最大完工周期为1 038 s。整个决策过程是在决策点(首工序有空余工位时),分7次逐步选取下一项需加工款式,每次决策时间约为85 ms,总决策时间为595 ms(7×85 ms)。
本文利用在服装生产调度研究中常用的遗传算法进行对比,遗传算法对该问题调度的最大完工周期为1 014 s,略优于本文所提出方法(采用遗传算法所求得最大完工周期比本文方法短约2.3%),但遗传算法的总决策时间为6.9 s(迭代800次),明显劣于本文方法(采用遗传算法的决策时间是本文方法的10.6倍,本文方法决策时间大幅减少91.4%),且遗传算法由于求解过程中存在随机性,并不能保证每次求解均能达到该优化水平。另外,遗传算法的决策时间会随着所需排产任务数量的增加而大幅增长,例如排产加工50个款式约需59.1 s决策(迭代800次),而本文方法每次决策点的决策时间基本没有较大变化。
同时,本文考虑了订单动态到达的情况,假设前7款任务开始加工100 s后,表4中第8款服装的加工订单到达,排产目标依然为总加工周期最小,采用本文方法调度方案(见图2(b))得到所有加工任务最大完工时间为1 080 s。加工任务的动态到达未对本文所提出方法的决策过程产生明显影响,依然是在决策点进行决策,选择下一项任务进入加工过程。而采取遗传算法等元启发式算法,需在加工任务达到时或滚动窗口激活时,对包含新到任务在内的未开始加工的任务进行重新安排,当任务量较大时无法实现实时响应。
5 结 论
本文针对现有服装生产调度过程中面对动态事件自适应性能差,以及实时响应能力差的问题,提出基于深度强化学习的服装缝制过程动态调度方法。由于强化学习本身基于马尔科夫决策过程,相较于现有服装生产调度过程中所采用的启发式算法或元启发式算法,该方法具有更高的动态性和实时性。实验表明,针对牛仔裤前片缝制过程,所提出的方法相较于遗传算法,在调度目标的达成度方面略逊2.3%,但决策时间大幅减少91.4%。该结果表明,针对订单动态到达的调度问题,该方法能够实现有效的实时响应,确保了缝制生产的高效性与连续性。
猜你喜欢
数字技术与应用(2022年3期)2022-04-14
科技与创新(2022年6期)2022-03-24
现代青年·精英版(2021年6期)2021-07-06
小猕猴智力画刊(2021年2期)2021-02-22
汽车实用技术(2020年15期)2020-10-20
作文周刊·小学一年级版(2020年20期)2020-09-02
意林(2020年10期)2020-06-01
纺织服装周刊(2020年2期)2020-02-10
大经贸(2018年12期)2018-02-20
小学阅读指南·高年级版(2017年5期)2017-05-18
