
基于TextRank的医院信息智能处理方法研究
2022-09-28 07:20刘宇枝李翠荣
粘接 2022年9期
刘宇枝,陈 博,赵 鑫,李翠荣
(1.空军军医大学 第三附属医院,陕西 西安 710000; 2.中移铁通有限公司,北京 100038; 3.西安市红会医院,陕西 西安 710061; 4.山东第一医科大学 第一附属医院,山东 济南 250014)
随着互联网技术的发展,线上智能化服务涉及越来越多的行业。为让用户在线上精准地获取所需相关知识和相关信息,需不断优化信息的检索性能。因此,围绕相关知识和相关信息的检索,提高信息化处理效率,很多学者提出不同的方法,如引入Hadoop云框架对信息进行存储和检索,以提高信息处理效率;引入文本挖掘算法与Spark架构,以提高信息检索效率。而实际应用发现,在智能化和信息化不断普及的今天,人们更多的喜欢通过网络获取健康科普知识。但遍历发现目前针对信息的检索多为对原始数据的集成和展示,且可靠性和准确性难以保证。因此,基于以上问题,以及结合当前信息化建设背景,本文提出一种基于文本挖掘的信息检索系统,在方便用户查找相关信息的同时也提高检索的准确性和可靠性。
1 系统总体架构设计
1.1 逻辑架构设计
本文基于Spring Cloud 框架来构建微服务平台,主要包括数据检索、数据运维、问答服务、监控告警、用户中心和权限管理这6大服务器。同时把基于文本挖掘的信息检索系统分为前后2个部分,前端以CSS、JavaScript、jQuery 来对数据进行展现,后端以微服务来对后端业务进行处理。基于文本挖掘的信息检索系统分层结构如图1所示。

图1 系统整体架构
由图1可知,系统主要分为5层,分别为资源层、服务层、接口层、Web 层、访问层。其中,资源层包括储存数据的主要工具和备份工具;服务层则采用 JSON 格式对系统中各功能板块之间的逻辑进行通信;接口层则通过 API Gateway将所有的入口的流量转发给后端的服务器并进行限流、权限、缓存等拓展。
1.2 物理架构设计
物理架构是指系统的部署架构,基于Docker 实现系统内部的快速部署,有效解决系统的运转和维护。Docker在系统运作中,是以Namespace 和 Cgroups 技术来把系统中的单个应用装在沙盒中进行运行,应用之间相互隔离;具体架构设计如图2所示。

图2 系统物理架构部署
1.3 功能模块
信息检索系统主要围绕着着数据处理模块、问答系统模块和信息检索模块3大模块进行设计。其数据处理主要是对数据的准备;问答系统则是对问答数据的获取和理解;信息检索则是为用户提供智能化的信息化的检索服务。具体功能模块如图3所示。

图3 系统功能模块
2 系统模块详细设计
2.1 数据处理模块设计
数据处理模块主要是从众多的信息网站中获取和储存数据信息,并以此作为该系统的数据信息来源,为用户的信息检索提供有效的数据信息基础。该模块主要包括数据爬取、整合和补充3个部分,数据处理的具体流程如图4所示。
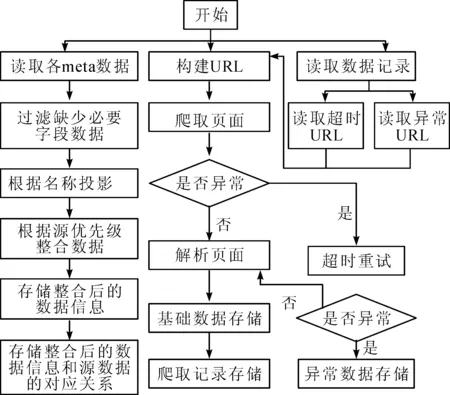
图4 数据处理的流程
2.2 问答系统模块设计
问答系统模块是指在用户提问后,该模块自动在系统中匹配该问题的相关数据并回答提问,具体流程如图5所示。
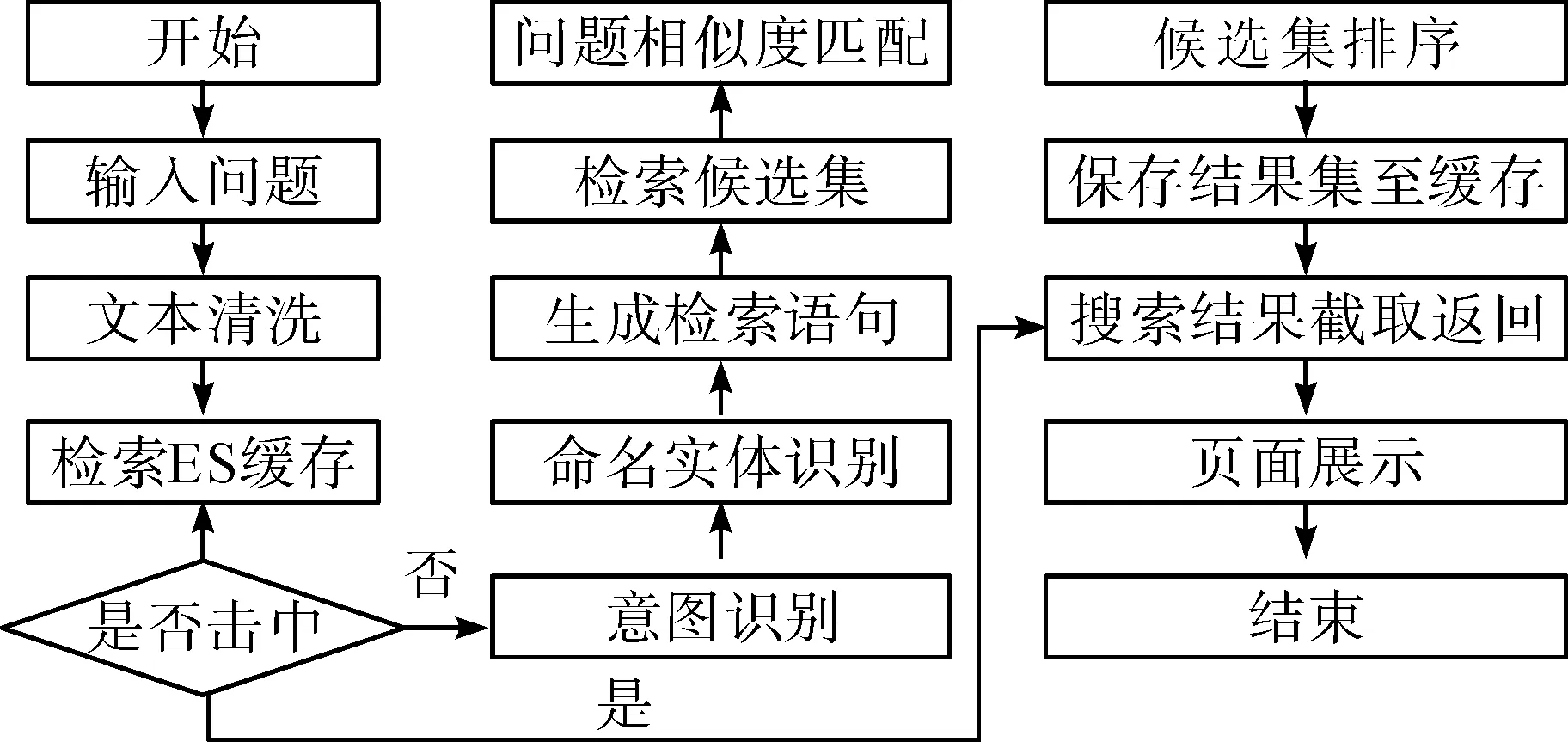
图5 问答系统流程
(1)用户主动输入问题,系统自动获取用户提问并对问题进行预处理,然后迅速访问 ES 缓存,搜寻 ES 缓存中是否有问题的记录,有就直接显示,没有就开始访问问答系统模板;(2)问答系统对用户提出的问题进行意图和实体识别,获取相关意图的关键词,生成ES检索语句检索获得相同或相关的数据信息来作为候选的问题集并返回;(3)问答系统自动将用户输入的问题和候选的问题集进行匹配,并进行排序;(4)把相似的ID列表和得分列表进行数据缓存,然后再返回到已经排序的数据结果集中。
2.3 信息检索模块设计
信息检索模块主要是把获取的相关数据存储在Elastic Search中,为用户信息检索系统提供数据服务,主要包括3大板块,分别为索引板块、搜索模块和用户模块。其中,索引板块是对用户的提问进行索引的建立、数据的入库以及数据的维修维护,包括其中工作人员及物品等信息数据和系统中科普文章、问答问题信息等文本数据;搜索模块是将获取的数据组织起来,并完善数据检索服务,以便为用户的提问进行检索需求。主要是通过用户的输入提问进行解析,并把解析后的搜索进行分布式的搜索,在各个 ES 节点进行分布式检索索引文件并对结果进行排序,然后显示给用户;用户通用模块主要是用户使用,在用户信息的检索过程中对信息的收藏、评论、点赞操作并准确记录相关操作。搜索模块的流程示意如图6所示。

图6 搜索模块流程
3 自动搜索模块算法设计
为提高搜索模块的检索效率,运用自动摘要算法TextRank来进行搜索。具体步骤为:
3.1 对文本进行分词分句等预处理并进行特征词的选择
通过对文本进行分词分句等预处理后,可以得到以下3项内容:(1)文本的集合={,,,},其中表示排序后的句子序列。(2)文本特征词的集合={:,:,,:},其中,表示单个特征词,而表示为在文本集合中所出现的词频。(3)句子的特征词集合为={1:1,2:2,,:}。
在对句子和文本特征词的选择时,采用的是TF-IDF权值法来对该系统中句子和本文的特征词进行评估。在运用TF-IDF权值法时,根据本文的长度规范权值,以词频对数来代替词频。特征词的权值计算公式为:

(1)
式中:表示特征词的总个数;表示在词典中出现的次数;()表示特征词的权重。
对特征词的权值计算后,可以得到权值较高的特征词,然后对权值进行排序,构成文本中所对应的关键词列表。
3.2 建立 TextRank 图模型
以文本的集合中节点和中特征词的边权重为边,共同构建出无向加权的 TextRank 图模型,进而计算节点的权重为:
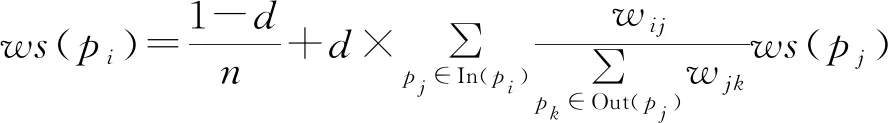
(2)
式中:表示节点和节点的连接权重;表示阻尼系数,一般取值为085;In()表示指向节点的所有节点的集合;Out()表示节点连接出的所有节点的集合;()表示节点的最终权重排序。
要计算其中的连接权重,则根据余弦函数公式:
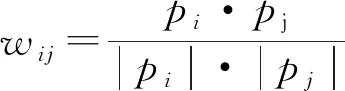
(3)
4 实验验证
4.1 测试环境
本研究运用Centos 7.3系统作为该系统测试环境的系统服务器,以128 G,CPU64核作为内存,以谷歌、IE、搜狗作为测试浏览器。其中的数据处理软件的版本分别为:Elastic Search 6.1.2版本,JDK 1.8版本,MySQL 5.7.17版本。测试浏览器为谷歌、IE。
4.2 功能性测试
本研究以黑盒测试原理为基础,对该系统的功能性进行测试,以检查该信息检索系统能否满足功能性需要,主要包括数据处理、索引模块、搜索模块的功能性测试。功能性测试用例结果如表1所示。

表1 功能性测试用例结果
4.3 非功能性测试
除了对信息检索系统进行功能性测试外,还进行非功能性测试; 运用Meter、Selenium和Kibana工具来辅助完成非功能性测试。非功能测试用例结果如表2所示。
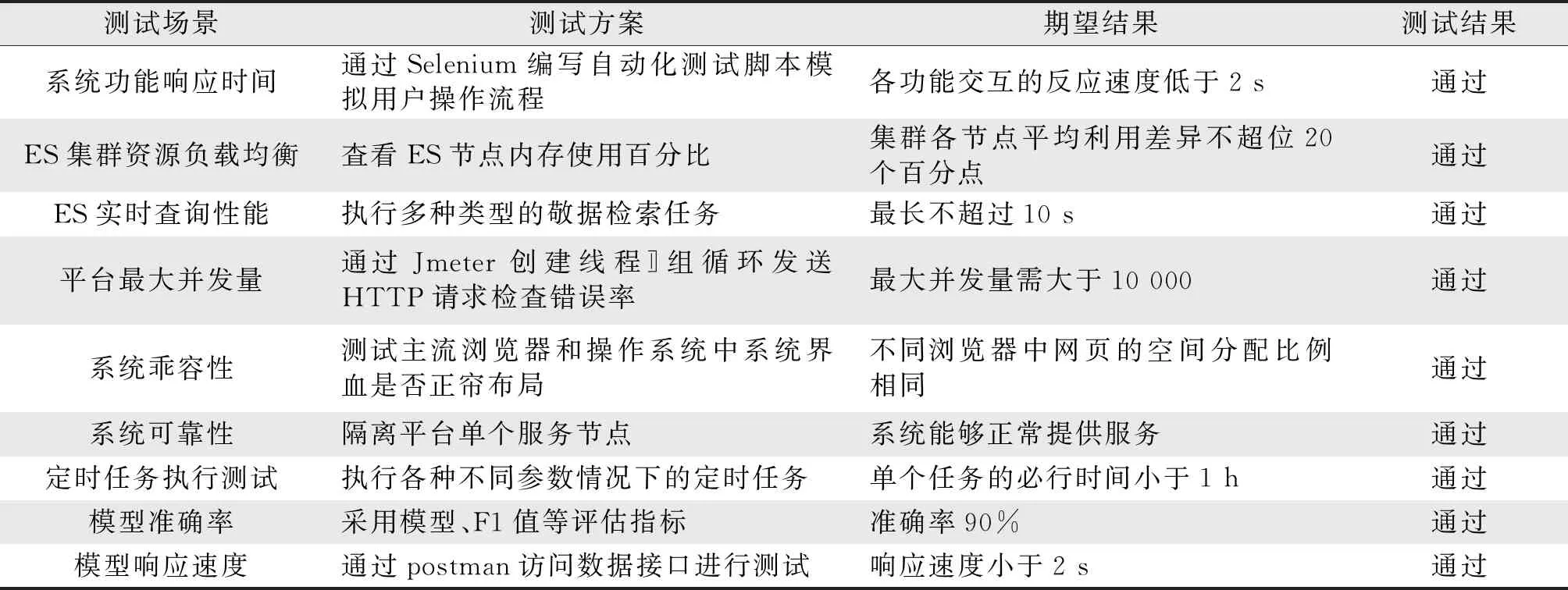
表2 非功能测试用例结果
5 结语
本文通过对数据处理模块、问答系统模块和信息检索模块优化创新后设计了完整的信息检索系统,该系统能够收集获取相关专业网站的信息数据,并经过系统的自动提取、过滤、整合后形成系统的基础数据和文本的价值,使系统获取的数据信息直观有效,便于用户的查询和获取,为信息化和智能化提供有效支撑和保障。该研究说明,重新设计的信息检索系统具有较强的实用价值,其是可行的。
猜你喜欢
健康体检与管理(2022年4期)2022-05-13
健康体检与管理(2021年10期)2021-01-03
技术与创新管理(2020年5期)2020-10-09
商情(2020年24期)2020-06-30
科学与财富(2019年27期)2019-10-25
现代信息科技(2018年3期)2018-09-10
新农业(2018年3期)2018-07-08
科学与财富(2017年28期)2017-10-14
科技视界(2016年17期)2016-07-15
科技视界(2016年12期)2016-05-25
