
基于数据挖掘的学习效果评估算法设计
2022-10-11 07:36程红阳
电子设计工程 2022年19期
程红阳,叶 青
(空军军医大学,陕西西安 710032)
新型冠状病毒疫情的蔓延,给人民群众的生命安全及社会生产均造成了极大的破坏。而线下教育则会使人群聚集,进而带来病毒传播的风险。基于此,大规模的线上教学及在线学习课程在疫情严重时期扮演了极为重要的角色。
在线上教学中,在线课程学习是基于网络视频流传输技术的线上开放课程。该学习过程包括课程视频的观看、问题回答、考试与讨论等行为[1]。但线上教学存在的主要问题是无法精准地控制教学质量,而通过采集学习者的学习行为数据并加以分析处理,即可实现对教学质量和学习效果的评估。
目前,对学习者进行学习效果评估主要是通过对学习特征加以分类,进而实现对其学习行为的分析[2-3],同时也可对学习者后续的学习进行预测性及推荐性的部署。该文对传统的评估方法加以改进,从数据源的挖掘及评价算法入手,设计出可用于线上教学的学习效果评估算法。
1 基于数据挖掘的学习效果评估模型
1.1 在线学习行为特征选取
目前,海量的网络教学平台丰富了人们的学习方式。用户基于该平台进行学习提升时,会产生诸多学习行为。通过对线上多种学习行为进行梳理,可将学习者的在线学习行为变量大致分为四类,具体可概括为视频学习行为、协作互动学习行为、作业学习行为及页面访问学习行为[4-6]。在线学习行为变量分类及其子分类如图1 所示。

图1 在线学习行为变量分类及其子分类
如图1 所示,在线学习行为的大分类下包含了具体的学习行为组成。由此可看出该文进行学习效果评估时,选用的数据量丰富且全面。相较于传统的学习效果评估模型仅选取学习者作业完成度与平时测试成绩作为评估标准的方式,该文学习效果评估模型更具有全面性和准确性。
1.2 基于FP-Growth算法的频繁数据项挖掘
FP-Growth(Frequent Pattern-Growth)是一种可以挖掘频繁项集的算法。在用户观看网课时,会出现大量的学习动作行为,如评论、提问、评价与考试等。该算法可对网课学习中多种复杂行为之间的关联规则进行挖掘[7-10],并将行为数据集以树结构的形式进行存储,再从结构树中挖掘关联规则。
FP-Free 的结构如图2 所示,其通过链表连接相似的元素,而FP 算法将数据集分配到FP-Free 结构中,该结构的数据库形式会大幅提升数据搜索效率。
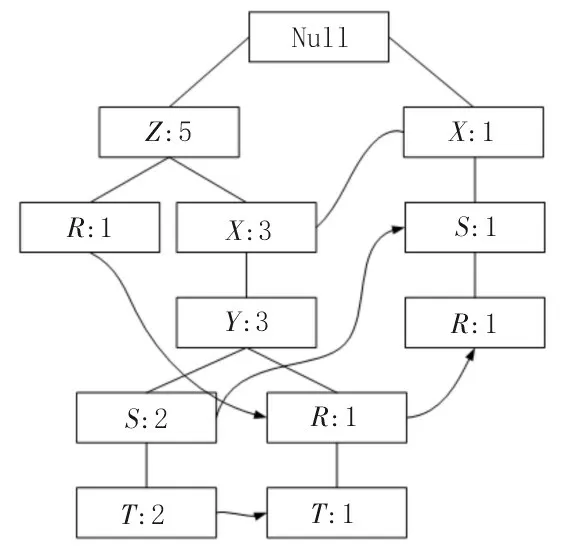
图2 FP-Tree示例
构建FP-Free 需遵循一定的规则:首先构建频繁项数据列表,并对数据库进行扫描,这样能够取得数据列表中数据的频率,进而筛选出合适的数据项,以便得到FP-List;然后创建根节点,再根据FP-List 中的排序方式进行节点插入;最终构成完整的FP-Tree。
FP-Free 创建完成后,通过FP-Growth 函数完成对数据的挖掘。该算法的函数实现过程如下所示:
1.if树包含有单独的路径path then;
2.for 每个路径path 中节点组合m;
3.do
4.取节点组合m与条件模式基n的共集,也称为支持度计数过程,若支持度大于筛选阈值,则输出;
5.end
6.else
7.for 树中的头部链表的每个条件模式基n1;
8.do
9.将n1和n的并集结果赋给m;
10.创造m的条件模式基,写入树;
11.end
12.end
经过上述步骤,即可完成树的构建及扫描两个过程。
1.3 PFP并行计算系统
FP-Growth 可对频繁项进行关联规则挖掘,但该算法的特点是当学习者的行为较为频繁时,需对FP-Tree 不断地进行递归与遍历,大多时候将会生成近万个FP-Tree,这将严重影响算法的性能。因此,该文使用并行算法对其性能进行提升。
Hadoop 并行系统[11-12]是一种分布式存储计算系统。该系统由分布式存储HDFS(Hadoop Distributed File System)与并行计算MapReduce 框架两个子系统构成。
HDFS 是Hadoop 系统文件存储管理的客观体现[13],该存储管理能够同本地服务器系统或云端服务器系统集成。整个HDFS 集群由名称节点Namenode和数据节点Datanode 组成,其组成形式为主从模式。名称节点负责文件命名空间的构建及元数据的管理等,数据节点则负责数据的存储与读写等工作。HDFS 的系统组成如图3 所示。
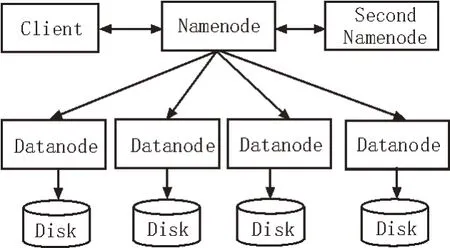
图3 HDFS系统组成
而Map Reduce 为并行运算函数,分为Map 函数与Reduce 函数[14]。其中,Map 函数可将小数据集合进行分片并行计算,而Reduce 函数能够将输入的中间结果进行简化运算。MapReduce 共有四个部分,具体结构如图4 所示。

图4 MapReduce组成
在图4 所示的结构中,Client 为客户端,其通过接口将数据传输至UI,用户则可利用Client 观看系统的运行状态;JobTracker 为资源监控及调度资源模块,其用来监控任务的运行状态,并对计算任务进行综合分配;TaskTracker 为任务显示模块,该模块会将节点的使用资源传输至JobTracker 模块中;而TaskScheduler 则为具体的计算任务。
HDFS 系统与MapReduce 系统协同工作的流程如图5 所 示[15]。

图5 协同工作流程
而该文基于Hadoop 系统构建PFP 算法[16],该算法主要利用了三个MapReduce 块来实现,其主要步骤如下:
1)数据输入
将原始的数据集合存入至Hadoop 系统的分布式存储系统,HDFS 分布式存储系统会将这些数据集合进行分片处理。
2)计算支持度
如1.2 节所示内容,FP-Growth 算法的核心点在于取得FP-Tree 的支持度。因此,第一个Map Reduce模块便是对其支持度加以计算。计算完毕后,即可结合筛选器对数据进行过滤及分组。
3)分组
分组是并行化计算的基础,PFP 算法根据Hadoop 计算集群节点的数量,并对原始数据集进行分组。然后根据分组结果对组内的相关元素项进行统计和计算。
4)并行计算与数据挖掘
第二个MapReduce 模块用于数据的挖掘。每个存储节点会根据上一步骤中的分组结果建立FPTree,同时计算条件模式基,然后再进行递归挖掘。
5)数据聚合
最后一个MapReduce 模块用于节点结果的聚合,最终对整体数据进行输出。
PFP 算法的具体流程如图6 所示。

图6 PFP算法流程
1.4 评估模型构建
为了对线上教学的学习效果进行评估,该文将FP-Growth 算法同Hadoop 系统相结合,最终能够实现对学习效果的实时评估。所构建的在线学习效果评估系统如图7 所示。

图7 系统设计
由图7 可知,该文总体算法模型由数据采集模块、模型训练模块及效果评估模块三部分组成。其中,数据采集模块用来收集用户在学习过程中产生的实时行为数据并存入数据库中。而模型训练模块主要通过Hadoop 集群算法对数据进行并行训练,最终完成数据挖掘。而效果评估模块,则为结果输出。
2 仿真测试
2.1 实验环境仿真
该算法在Hadoop 集群系统中完成,共使用四个分布式节点,实验环境配置如表1 所示。实验所使用的数据集为MOOC 平台的学生行为特征数据,共有95 万条,而训练时最小支持度的值设置为0.3。

表1 环境配置
2.2 性能测试
实验使用单次MapReduce 与PFP 算法进行对比,测试内容为算法在不同数据集工作的运行时间,单位为s。在四个计算节点集群环境下进行运算处理的结果如表2 所示。
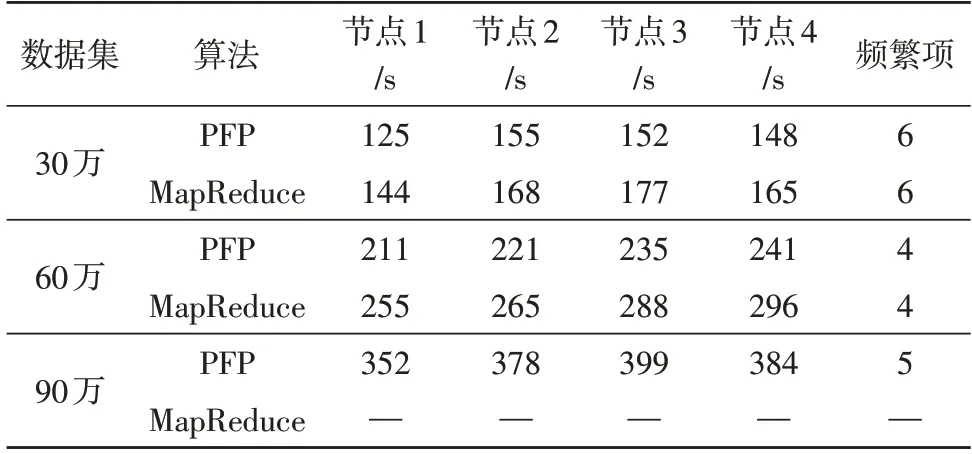
表2 多机运算结果
从表中可以看出,PFP 算法和单次MapReduce算法形成的频繁项数目是相同的。但在运行时间方面,PFP 算法的平均运行时间更短,说明PFP 能够增强算法性能,缩短运行时间。同时也可看出,PFP 算法可提升数据的存储容量,因为当数据量达到90 万条时,单次MapReduce 算法已无法处理数据。
下文将测试算法的单机性能,分别在10 万、20万、40 万、60 万及80 万数据集样本的情况下进行实验。默认最小的支持度为0.3,测试数据指标为算法完成时间。这些样本在单机测试环境下,能够被算法处理。最终的实验结果如表3 所示。

表3 单机运算运行时间
由单机运算结果可以看出,该文设计算法在单机执行效率方面要优于对比的单次MapReduce 算法,说明该算法系统性能较优,计算优势较为显著。
3 结束语
该文研究了一种基于数据挖掘的学习效果评估算法。该算法以数据挖掘作为算法的基础思想,并使用FP-Growth 算法来挖掘频繁项集,进而发现用户复杂行为后的关联规则。同时,在算法部署与运算方面使用了PFP 算法。该算法基于Hadoop 并行计算系统改进而来,进一步克服了FP-Growth 算法运算较慢的缺点。实验结果表明,所提方法在算法效率及性能方面均优于对比算法。
猜你喜欢
中国现代医生(2022年21期)2022-08-22
消费电子(2022年5期)2022-08-15
中国教育信息化·高教职教(2022年4期)2022-05-13
民族文汇(2022年14期)2022-05-10
课程教育研究(2021年10期)2021-04-13
作文大王·笑话大王(2019年8期)2019-09-09
学苑创造·B版(2019年4期)2019-05-09
小天使·三年级语数英综合(2017年10期)2017-11-20
中学生数理化·八年级数学人教版(2017年2期)2017-03-25
电子技术与软件工程(2016年24期)2017-02-23
