
基于K-means 聚类的电力大数据脱敏技术研究
2022-10-11 07:37徐敏
电子设计工程 2022年19期
徐敏
(云南电网有限责任公司,云南昆明 650217)
数字南方电网作为一家大型商业公司,拥有大量核心商业机密和国家安全机密的数据,同时也有许多敏感数据,包括用户个人信息、位置以及一些重要设备名称等[1]。如果没有采取有效的保护措施,会导致这些重要的机密数据丢失或被破坏,不仅会给企业造成无法估量的严重后果,而且还会影响企业的良好形象[2]。伴随着智能电网的迅速发展,对敏感数据的保护要求也越来越高,如何在数据交换、共享和使用过程中精确定位、充分脱敏,是当前实现数据安全使用的关键性问题。就当前存在的问题,有文献提出采用传统的“烟囱式”架构搭建数据的中间库,但是该数据中间库在数据使用监管方面存在薄弱点,对数据脱敏存在数据安全隐患;大数据使用面向HBase 的脱敏技术,并结合权限算法完成脱敏任务[3]。然而该方法计算步骤复杂,需要耗费大量时间,大大降低了电力数据的传输速率,大数据脱敏效果较差。综上所述,提出了基于K-means 聚类的电力大数据脱敏技术研究。该技术结合K-means 聚类算法检测异常电力大数据,实现数据高效脱敏。
1 基于K-means聚类异常电力大数据检测
采用目标函数最小化的方法,在初始聚类点处进行迭代选择,对K-means 算法进行优化,达到局部最优聚类效果。在采用K-means 算法聚类时,要根据不同的聚类对象选择组合,需要多次选择不同的聚类对象,并据此进行聚类运算[4]。
在K-means 聚类分析结果的基础上,对异常大数据进行检测与计算,通过对电力系统大数据进行聚类,确定聚类中心的位置,比较各数据点到聚类中心的距离,判断各数据点是否存在异常[5-7]。
假定在初始数据集中有样本数据,执行K-means聚类算法,样本数据的特征数据属性为整数[8]。基于样本数据的特征属性,整个K-means 聚类过程产生聚类中心距离的平方和,公式为:
式(1)中,Aj表示第j个数据的中心点;Bi表示第i个聚类中心;λij表示聚类系数[9]。
基于计算得到的聚类中心距离平方和目标函数极值,将K-means 聚类算法应用于电力大数据异常检测中,应用流程如图1 所示。
在检测过程中,首先要确定原始文本数据,然后随机选取聚类中心,最后用K-means聚类算法进行数值计算[10]。如果这个值是常数,说明聚类算法在迭代过程中并不是最优的,需要通过更新聚类中心来重复迭代过程[11]。K-means 聚类结果如图2 所示。

图2 K-means聚类结果
由图2 可知,依据K-means 聚类分簇结果,对电力大数据进行分类处理,以此进行异常数据检测[12]。
2 基于K-means聚类的脱敏技术研究
根据上述检测结果,构建脱敏系统,通过该系统实现数据高效脱敏。
2.1 脱敏系统构建
电力大数据脱敏系统由四个层次构成。该系统分别通过各个层次的计算与存储,发现敏感数据并对其进行脱敏处理,满足终端用户需求。
1)资源层:为系统提供计算、存储等基本的物理资源,包括网络资源,用于数据脱敏服务[13]。
2)数据层:负责对所有数据进行操作管理和安全管理,其中包括知识库、规则库和权限库,利用机器学习形成模型库对不同数据进行排除、管理的规则化脱敏策略,支持对敏感数据的权限管理[14]。
3)服务层:作为核心服务层,可提供数据脱敏引擎、规则化引擎和服务器引擎的支持,可发现结构复杂、较大的敏感数据,并完成这些数据的脱敏操作。
4)应用层:负责将数据库、文件和多媒体脱敏按数据类型提供给终端用户,可根据业务需要,分为静态脱敏、动态脱敏,以满足不同测试和研发过程的需要。
2.2 数据脱敏流程设计
在脱敏系统上的电力大数据脱敏步骤如下所示:
步骤一:敏感配置信息导入。根据具体的接口信息需求,将元数据管理系统接口在数据脱敏系统中提取预留,方便敏感配置信息的输入[15]。
步骤二:敏感数据识别。识别全部数据,从中选择用户想要访问的信息,并对信息内容进行详细分析。依据识别格式,结合处理技术,识别出敏感数据。
步骤三:敏感数据判断。基于数据脱敏配置方法,在业务应用调用各种数据时,应根据业务用户的数据进行权限和数据敏感性检查,并判断敏感数据的脱敏程度。如果用户权限或数据触发脱敏处理中敏感程度越高,则数据脱敏程度越低;如果用户权限或数据敏感性较低,则触发程度越高;如果未触发数据解密过程,则数据直接呈现给业务用户[16-17]。
步骤四:脱敏服务运行。针对脱敏服务,需从静态和动态两种方式展开,如下所示:
1)静态数据脱敏
根据执行策略,通过脱敏程序对低权限个体访问的敏感数据进行脱敏处理。静态数据脱敏机制如图3 所示。
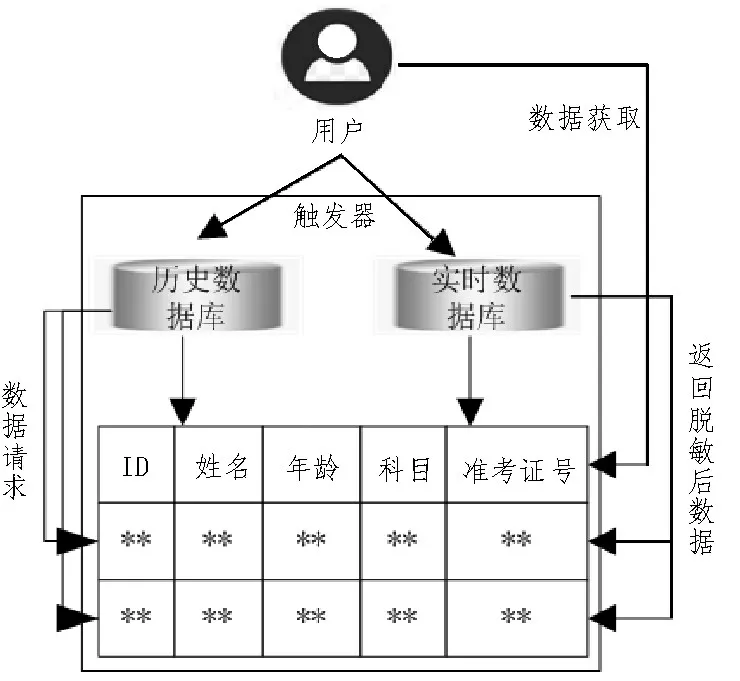
图3 静态数据脱敏机制
从图3 可以看出,储存同一个数据库中全部脱敏静态数据,按不同权限级别对用户访问数据内容进行划分。与分离组件相结合,获得不同用户的访问请求,根据请求对敏感数据进行分类。高权限用户可以获得原始版本数据;低权限用户只能获得敏感版本数据。
2)动态数据脱敏
结合替代查询功能的代理数据库实现动态数据脱敏,对代理数据库查询语句进行自动识别,重新写入这些敏感字段,转换为不包含敏感字段的语句。向代理数据库传递转换结果,对查询结果进行重新计算和修改,最终按所需的统一格式打包发送给用户,完成敏感信息的处理,图4 为动态数据脱敏机制。

图4 动态数据脱敏机制
从图4 可以看出,脱敏系统中的响应改写模块和请求改写模块作为数据容器出口,对用户与服务器之间所有数据的请求和响应进行检测和处理,或者应用程序代码,无需更改数据存储,从而实现代理机制。
3 实验分析
使用Linux 操作系统,研究基于K-means 聚类的电力大数据脱敏技术的合理性,并进行试验验证分析。
3.1 试验项目
数字南方电网以公司发展战略为引领,以稳定、灵活的一体化数字平台为核心,构建以数据驱动的业务运作、管控和决策体系,一体化数字平台如图5所示。

图5 一体化数字平台
该公司为全面开展数据资产运营,推进数据供给,实现数据供给侧和数据需求侧对接。目前该公司xx 部门利用生产库ADG 为原始数据端,通过OGGDSGDBLINK 等不同的方式抽取同步到下游自建“中间库”,为应用开发测试提供数据服务。同一个源头数据库中存在多个中间库,这些中间库分别由所服务的项目组进行维护,在数据集成、应用方面实现统一的管理。然而,由于中间库服务结束后,没有后续管理,如果项目组未能及时申报退运相关中间库,则中间库的软、硬件资源不能回收,其中所承载的业务数据不能及时清除、销毁。
3.2 试验结果分析
分别使用基于“烟囱式”架构脱敏技术、面向HBase 的大数据脱敏技术和基于K-means 聚类脱敏技术,对电力大数据进行脱敏处理,处理结果如图6所示。
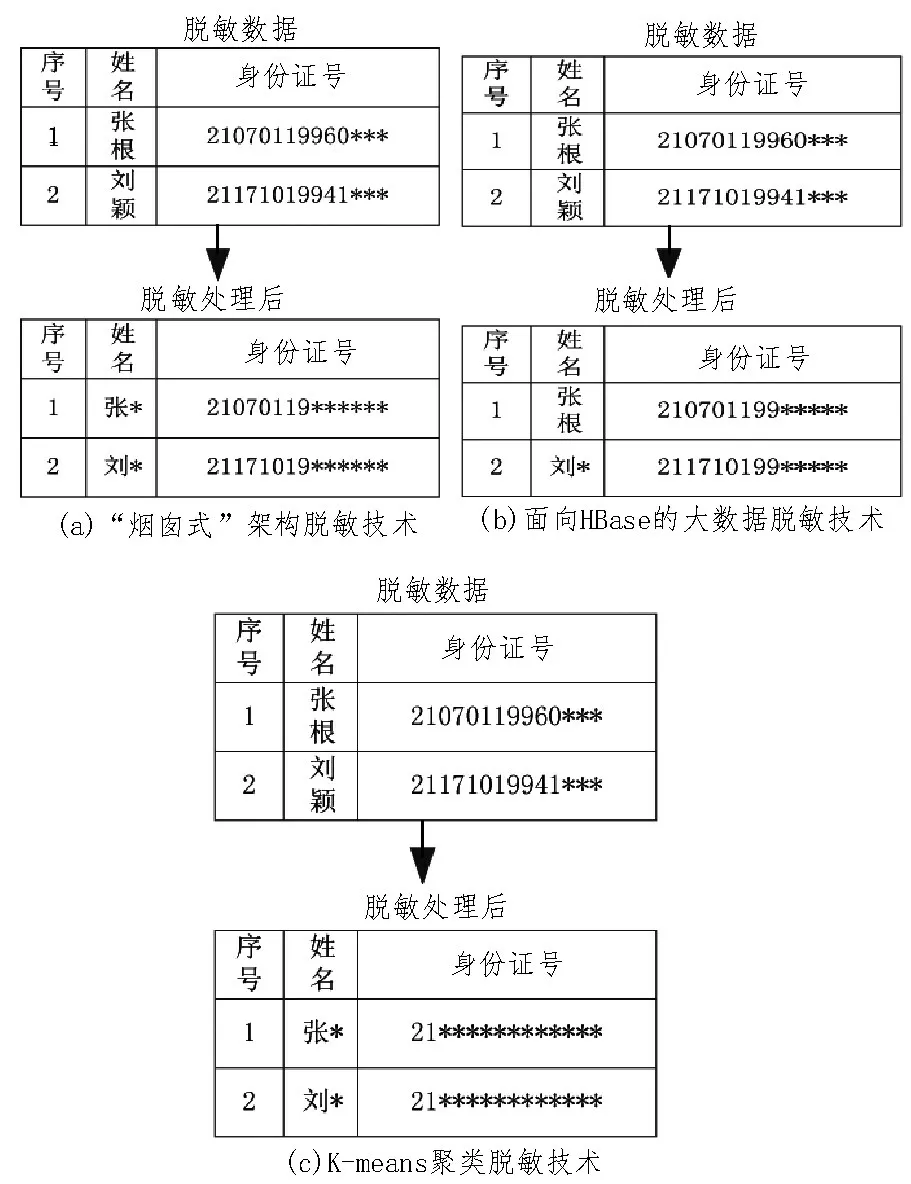
图6 三种技术脱敏处理结果
由图6 可知,使用基于“烟囱式”架构脱敏技术无法有效保护电力用户的身份信息安全,身份证大部分数据已暴露;使用面向HBase 的大数据脱敏技术,用户部分姓名完全暴露,身份数据部分暴露;使用基于K-means 聚类脱敏技术,用户姓名和身份证号均能被脱敏处理,有效保证了用户身份信息安全。
分别使用三种技术分析大数据安全性,对比结果如表1 所示。
由表1 可知,使用基于“烟囱式”架构脱敏技术和面向HBase 的大数据脱敏技术无法保证用户身份信息安全,而使用基于K-means 聚类脱敏技术能够使电力大数据高效脱敏,保证用户身份安全。
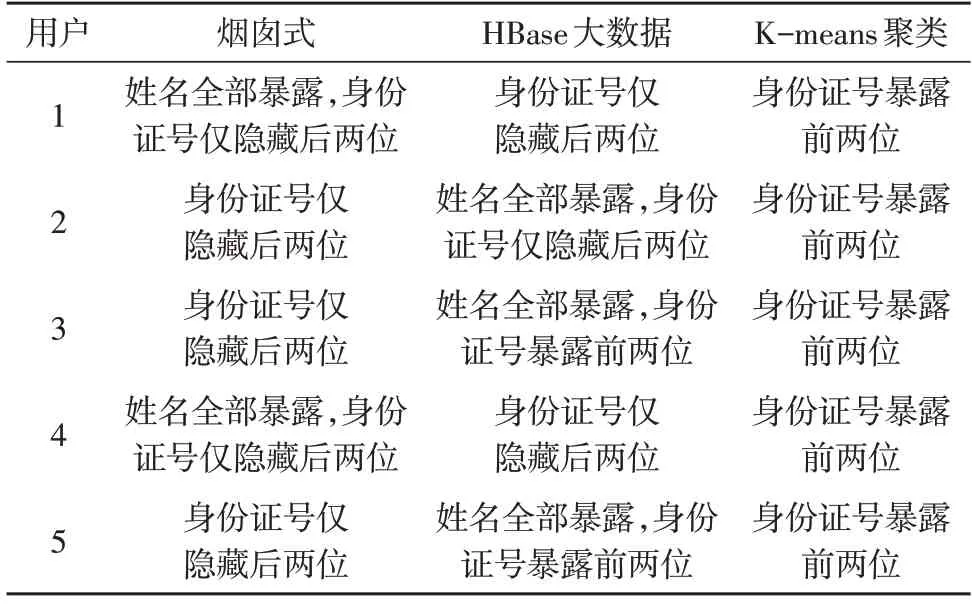
表1 三种技术大数据安全性对比分析
4 结束语
该文将提出的基于K-means 聚类的电力大数据脱敏技术应用于数字南方电网。该技术能够保障用户之间数据透明,确保业务紧密关联,实现一个平台上多数据源脱敏服务。在当今大数据时代,数据脱敏是企业进行数字治理所必需的一种安全机制。随着数据脱敏技术的不断发展,应以更高的精确度、最细的粒度以及更好的可用性来面对用户。同时,大数据脱敏技术还需要具备更高的自动化能力,能够进行良好的呈现,具有较强的扩展性,以适应未来用户对多领域数据交换、共享与整合需求。
猜你喜欢
中国典型病例大全(2022年11期)2022-05-13
汽车实用技术(2022年4期)2022-03-07
中华临床免疫和变态反应杂志(2021年6期)2021-11-19
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
阅读与作文(英语初中版)(2019年8期)2019-08-27
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
电子技术与软件工程(2016年23期)2017-03-06
祝您健康(1996年9期)1996-12-30
