
基于多体系信息融合的配电网设备数据分析与优化管控技术
2022-10-11 07:37胡亚山仓敏诸德律王静怡
电子设计工程 2022年19期
胡亚山,仓敏,诸德律,王静怡
(国网江苏省电力有限公司经济技术研究院,江苏南京 210008)
配电网是电力系统发、输、变、配的关键环节之一。随着智能电网的发展建设,电网公司对配电网领域的投资也越来越多。配电网具有众多的电力设备,电网公司对配电设备进行运行维护、资产管理过程中产生了海量的数据,如何管理并利用好这些数据是值得研究的重要问题[1-3]。
近年来,大数据技术结合深度学习等人工智能算法深入挖掘海量数据的潜在价值,其在电力系统的负荷预测、故障诊断、状态评价、用电行为分析等领域应用广泛[4-6]。该文结合深度学习算法开展多体系信息融合数据在配电网设备剩余寿命预测的应用研究,为配电网设备的退役更换提供信息支撑及辅助决策。
1 配电网设备多体系信息融合架构
在配电网设备资产的全寿命周期管理中,涉及海量配电网设备的相关数据信息,这些数据与配电网设备的健康状态存在密切关联。
基于多体系信息融合的配电网设备数据,分析配电网设备全寿命周期质量与关键要素的关联性,可以为配电网设备全寿命周期的管控优化提供指导。
以配电网中常见的电力变压器为例,构建多体系信息融合数据架构如图1 所示。该数据架构主要包括油色谱指标、油化指标和电气指标共3个方面。
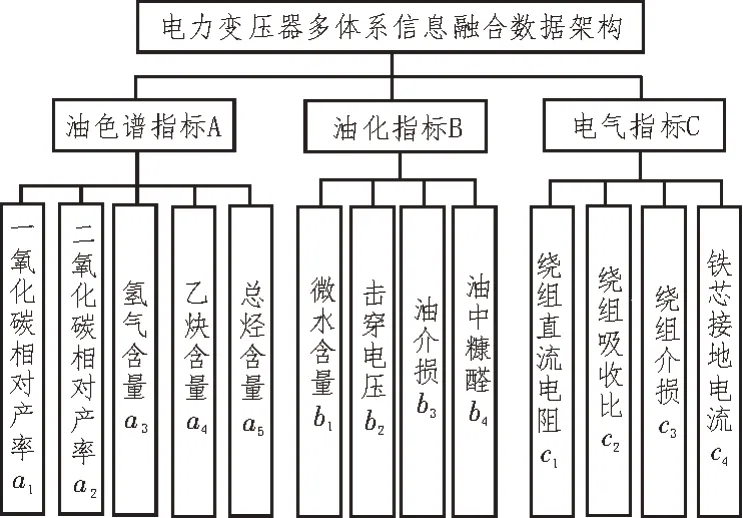
图1 电力变压器多体系信息融合数据架构
油色谱指标是指通过分析变压器绝缘油中特定气体成分的存在情况,以判断电力变压器的使用时间或是否存在局部放电和过热等故障;油化指标是指通过分析变压器绝缘油的绝缘性能,实现电力变压器质量情况的评估;电气指标包括变压器绕组的主要电气特征,其能够直接反映变压器的健康情况。
2 配电设备数据分析与优化管控方法
2.1 PCA原理
主成分分析(Principal Component Analysis,PCA)是一种重要的多维空间数据统计分析技术。其核心思想是将存在相关性的高维数据映射到线性不相关的低维空间,实现数据压缩和特征提取,从而简化数据复杂度,消除数据之间的相关性[7-8]。
假设Rn为特征空间,对于包含j维特征变量的k个数据样本,PCA 的主要计算步骤如下[9-10]:
1)数据标准化
为了消除不同维度特征变量量纲对主特征提取结果的影响,有必要对原始数据进行标准化,计算方法如式(1)-(2)所示:

2)计算协方差矩阵
为消除不同特征变量之间的相关性,达到线性化与降维度的目的,首先计算表征特征变量之间相关性的协方差矩阵R:

式中,rij为第i维特征变量与第j维特征变量之间的相关系数,计算方法如下:

3)计算特征值与特征向量
通过求解特征方程|λI-R|=0 得到协方差矩阵R的特征值,将这些特征值从大到小依次进行排序:
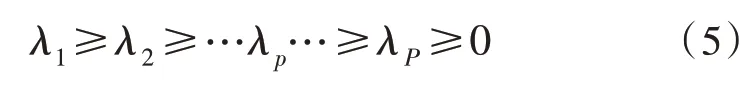
式中,λp为协方差矩阵R的第p个特征值,共有P个特征值。
进一步计算P个特征值对应的单位特征向量:
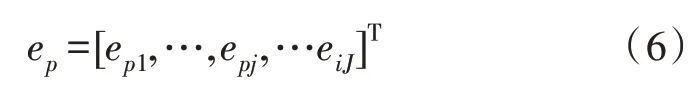
式中,ep为特征值λp对应的单位特征向量,epj为ep第j维取值。
4)计算主成分贡献率
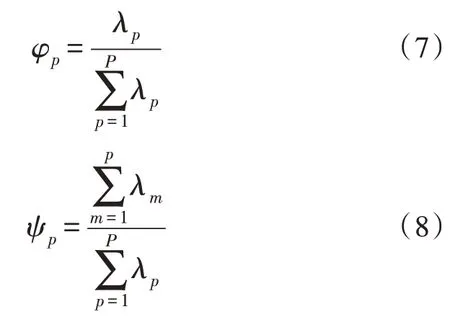
按照如式(7)和式(8)所示的定义,计算各个主成分的贡献率φp,按从大到小进行排序并计算累计贡献率ψp,然后筛选出累计贡献率大于阈值pmin的前h个主成分:
5)数据样本映射
将主成分对应的h个特征向量作为列向量组成特征向量矩阵:

通过以下矩阵运算将原数据样本映射到主成分构成的特征空间中,实现数据的降维和线性化:

式中,X′为映射后的数据样本。
2.2 LSTM网络
长短期记忆(Long Short-Term Memory,LSTM)网络是一种具有时间记忆功能的深度学习神经网络,其核心思想是模拟人类记忆和处理信息的机制[11-12]。LSTM 的结构与神经网络相似,只是每层的输入层和输出层之间由循环的记忆单元连接门[13-15]、输出门及忘记门构成,其结构如图2 所示[16]。

图2 LSTM记忆单元结构
1)忘记门

式中,Wxf为输入层与忘记门之间的权重;Whf为隐藏层与忘记门之间的权重,αf为忘记门的偏置值;σ(·)为激活函数。
2)输入门
输入门负责控制更新的神经元信息,其输出信息如下:
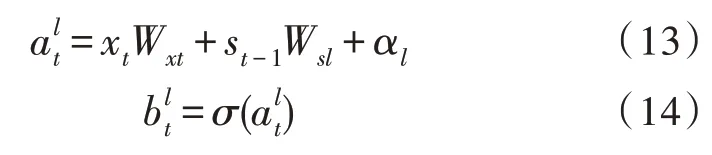
式中,Wxt为输入层与输入门之间的权重;Wsl为记忆单元和输入门之间的权重;αl为输入门的偏执值。
3)输出门
输出门负责控制记忆单元最终的输出信息,公式如下:
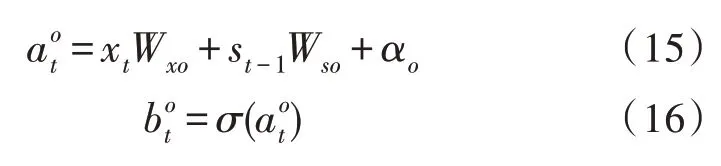
式中,Wxo为输入层与输出门之间的权重;Wso为记忆单元与输出门的权重;αo为输出门的偏置值。
2.3 数据分析与优化
该文提出基于PCA-LSTM 的配电网设备数据分析与优化管控方法,实现配电网设备剩余寿命的预测,从而辅助配电网设备资产的管理运维,管控流程如图3 所示。首先将多体系信息融合数据作为输入,通过PCA 算法对数据进行降维简化处理;然后将提取的主成分数据作为LSTM 模型的输入,从而自动学习数据特征,获得配电网设备剩余寿命预测结果。
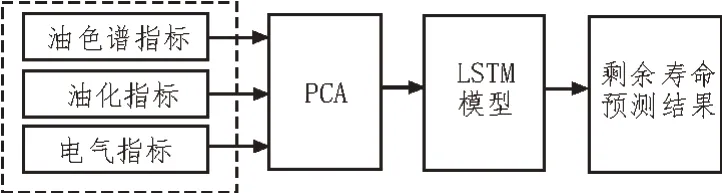
图3 配电网设备数据分析与优化管控流程
3 算例分析
为验证该文提出的基于PCA-LSTM 的配电设备数据分析与优化管控方法的正确性和有效性,选取1 000 组配电设备多体系数据作为样本,并按4∶1 的比例划分为训练样本和测试样本。
3.1 主要特征筛选结果分析
1 000组数据样本中,每个数据样本都包含如图1所示的13 个指标值,数据样本取值如表1 所示。
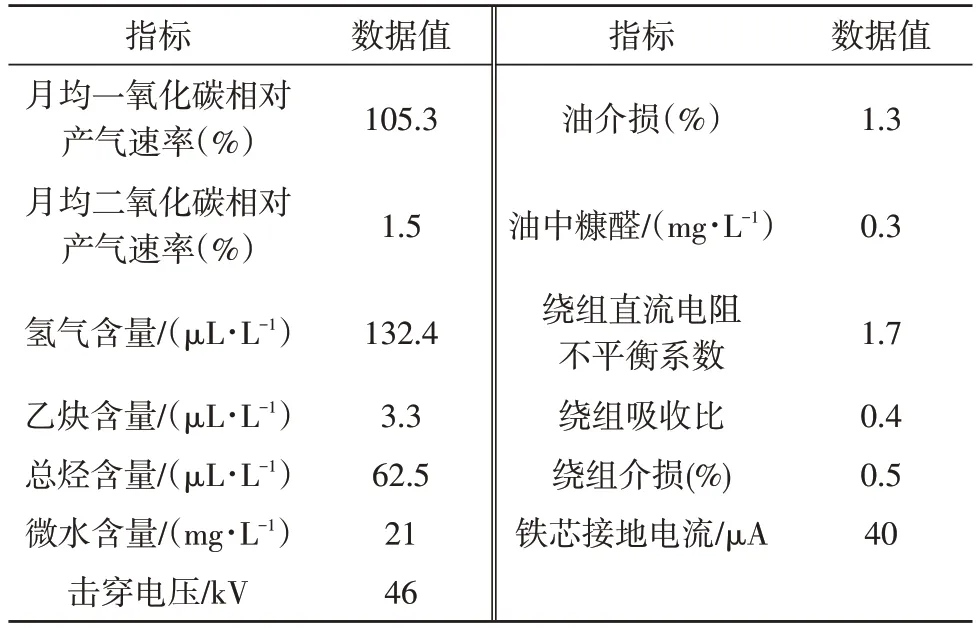
表1 数据样本的取值
通过PCA 算法,前7 个主特征的贡献率及累计贡献率如表2 所示。由表2 可知,主成分1-4 的贡献率分别为40.15%、25.67%、17.91%和13.11%,而主成分5 的贡献率仅为2.25%。前4 项主成分累计的贡献率已达96.84%,大于阈值95%,故选取主成分1-4构建特征向量矩阵,并对原始数据样本进行映射。
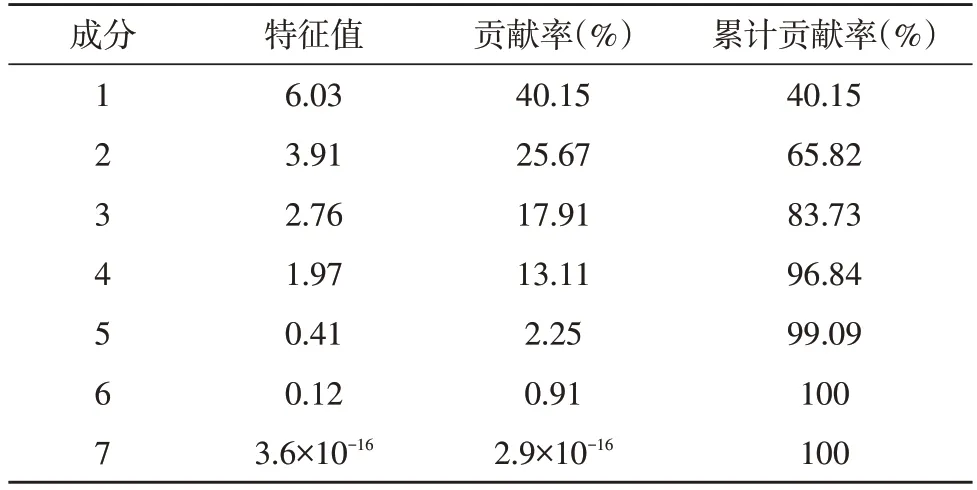
表2 前7个主特征的贡献率
3.2 数据分析与优化管控结果分析
1)算法性能对结果的影响分析
以所有数据样本作为输入,分别采用PCA-LSTM算法、LSTM 算法和PCA-BP 算法,得到配电网设备剩余寿命的预测模型。然后以5 组数据测试模型的准确性,结果如表3 所示。
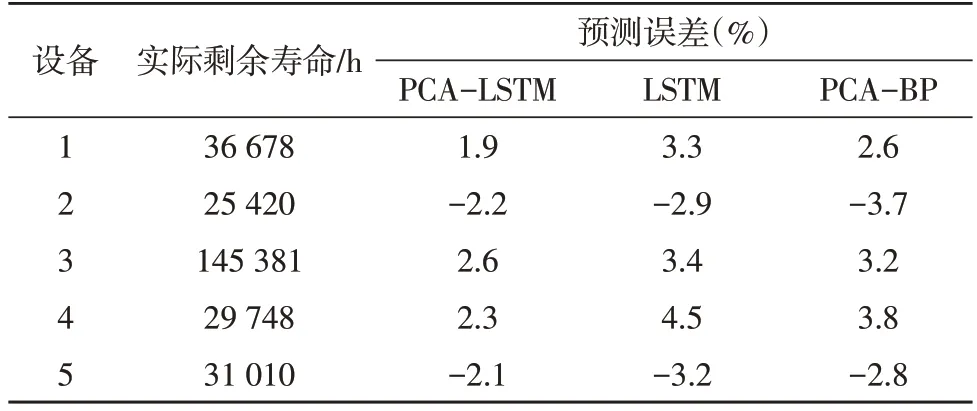
表3 不同算法的剩余寿命预测结果分析
由表3 可知,PCA-LSTM 算法配电网设备剩余寿命预测误差均小于3%,LSTM 算法最大误差达4.5%,PCA-BP 算法最大误差达3.8%。对于同一数据样本,PCA-LSTM 算法的预测误差是3 种算法中最小的一种,而LSTM 算法与PCA-BP 算法则各有优劣。相比于LSTM 算法,PCA-LSTM 算法通过PCA 将配电网设备的特征数据进行降维简化,消除不相关特征对剩余寿命预测结果的干扰;相比于PCA-BP 算法,经过主成分特征数据的学习,LSTM 算法比BP 算法具有更优的自动学习性能,剩余寿命预测结果也更加准确。
2)多体系信息融合对结果的影响分析
选取不同的信息方案作为PCA-LSTM 模型的输入,得到的配电网设备剩余寿命预测结果如表4 所示。由表4 可知,选取单种体系信息作为输入时,剩余寿命预测误差大于12%;选取两种信息作为输入时,剩余寿命预测误差大于5%;而该文所提方法将多种体系信息作为输入,剩余寿命预测误差小于3%。

表4 不同体系信息的剩余寿命预测结果分析
4 结束语
该文开展了基于PCA-LSTM 算法的配电网设备剩余寿命预测研究,通过算例分析结果表明,PCA 算法能够实现配电网多体系信息的主要成分提取,从而达到降低数据复杂度的目的;PCA-LSTM 算法相比于LSTM 算法与PCA-BP 算法,剩余寿命预测结果更加准确;而相比于采用单种体系或两种体系信息,文中所提算法能够全面利用反映配电网设备剩余价值的关键数据,提高预测结果的准确性。但该文所提算法仅实现了配电网设备剩余寿命的预测,如何同步实现配电网设备的故障研判将在后续研究中开展。
猜你喜欢
智慧电力(2022年3期)2022-04-12
作文评点报·低幼版(2020年3期)2020-02-12
华人时刊(2018年17期)2018-12-07
科学与财富(2017年22期)2017-09-10
领导文萃(2017年11期)2017-06-12
科技知识动漫(2016年9期)2016-09-22
高教探索(2015年10期)2015-10-29
湖南大学学报·自然科学版(2014年3期)2014-12-30
中国信息化·学术版(2013年5期)2013-10-09
祝您健康(1994年8期)1994-12-30
