
基于深度学习的语义级中文文本自动校对研究
2022-10-14 05:55张芙蓉罗志娟
长沙航空职业技术学院学报 2022年3期
张芙蓉,罗志娟
(长沙航空职业技术学院,湖南 长沙 410124)
现有的文本校对研究大多数是针对字词错误和语法错误,对于语义错误的校对研究较少。传统的文本校对方法一般基于统计和规则:基于规则的方法由于规则的制定过于依赖专家,因此不宜迁移;基于统计的方法需要大量的数据,当数据量不是很大时效果并不好;规则和统计相结合的方法能实现二者的优势互补,但不能从根本上解决语义错误的校对问题。语义错误是指中文文本中字词表示正确、句法结构完整,而不符合上下文语义逻辑的错误。语义级的中文文本校对方法指在中文文本校对中能够从语义角度进行查错纠错的方法。到目前为止,还没有比较成熟的解决方案。能实现语义级自动校对的方法,须以对文本的语义分析为基础,语义问题的研究一直是计算语言学和自然语言处理研究中的薄弱环节,也是中文文本校对的难点。
1 语义级中文文本校对研究现状
1.1 语义分析研究现状
语义分析是自然语言处理的核心任务,其目的是实现对语言输入的语义理解,进而支撑后续的操作和处理。根据语言输入的粒度不同,语义分析可分为词汇级语义分析、句子级语义分析和篇章级语义分析。词汇级语义分析主要关注如何区分和获取单个词语的语义,经典任务是词义消歧,即在特定的语境中,识别出某个歧义词的正确词义。句子级语义分析主要关注如何解析由词语所组成的句子的语义,根据分析的深浅程度又分为浅层语义分析和深层语义分析。浅层语义分析的经典任务是语义角色标注,即识别出给定句子的谓词及谓词的相应语义角色成分。深层语义分析,又称为语义解析,即将输入的句子转换为计算机可识别、可计算的语义表示,语义解析根据应用情境的不同,可分为自然语言到结构化查询、语言到代码和语言到机器操作指令。篇章级语义分析主要关注由句子组成的篇章的内在结构并理解各个句子的语义以及句子与句子之间的语义关系,进而理解整个篇章的语义。
紧跟自然语言处理领域的发展大潮,语义分析技术发展迅速,一方面部分方法受其他任务的先进技术的启发,如基于序列到序列的语义分析方法;另一方面部分方法也启发了其他领域,如基于受限解码的事件抽取方法。由于词汇级语义分析发展多年,技术已趋成熟,因此研究的重心由词汇级转向句子级的语义分析;而篇章级语义分析由于完全的篇章理解过于困难,因此衍生了多个与之相关的任务,如篇章的结构分析、话语分割、指代消解、共指消解等,任务分散且偏边缘,导致得到的研究和关注很少,进展也缓慢。整体来说,语义分析虽然已取得了一定的进展,但技术还远未成熟完美。
1.2 语义级文本校对已取得的成果
目前,已有的语义级校对方法有三种: 基于规则或语言学知识的方法、基于统计的方法、基于机器学习的方法。早在2003年,骆卫华等[1]提出统计和规则相结合的校对策略,可视为中文语义校对的最早研究。郭充等在语义知识库的基础上设计相应的自动查错算法,实现了语义级的中文文本查错[2]。张仰森等[3]提出了一种基于语义搭配知识库和证据理论的语义错误侦测模型。姜赢等[4]提出利用本体技术将中文文本中的语义内容提取出来转换为结构化本体。奚雪峰等[5]、江洋洋等[6]、王乃钰等[7]对深度学习在自然语言处理领域的研究进展进行了总结,深度学习技术为中文文本语义校对提供了新的方法,使有较高准确率的中文语义校对有望实现,因此基于深度学习的方法是当前最有前途的一种方法。已有研究者对深度学习应用于中文文本校对做出了有益的探索:任柏青[8]借助句法分析、语言模型等技术对文本进行深度分析和挖掘,并引入语义分析技术,通过计算句子中各词语的语义相关程度来提高错误识别率。郝亚男等基于神经网络与注意力机制,通过增强词间语义逻辑关系的捕获能力,能够对含语义错误的文本进行校对[9]。龚永罡等先提出了将Transformer模型应用于中文文本自动校对领域[10],后又提出了一种新的基于Seq2Seq和双向长短期记忆(Bi-LSTM)结合的深度学习模型,该模型能处理语义错误[11]。
1.3 语义级文本校对技术瓶颈
语义级文本校对在字词级已取得了成熟的成果,包括字词级语义校对中的词义消歧问题和未登录词识别问题。句子级语义校对仅能解决简单句型,对于复杂句型中的差错还考虑不够。存在的瓶颈有:(1)目前的语义校对方法没有对语言学知识进行充分运用,仅仅是考虑了词语之间的搭配,没有考虑词语之间的限制。(2)有对语义搭配知识库的研究,但语义搭配知识库的正确性和语义错误侦测的准确性还有待提高。目前的方法仅对正式文本(书面语文本)有效,还不能实现社交网络文本的语义校对。(3)在语义自动校对中,语义搭配是校对的基础,目前对语义搭配的证据理论还缺乏深入挖掘。(4)用于判断语义搭配的大规模知识库还不够成熟,亟须开放性的大规模的语义知识库共建共享技术。
2 深度学习相关理论
2.1 深度学习常用模型
卷积神经网络(Convolutional Neural Networks, CNN),作为首批表现良好的深度模型之一,是用于专门处理具有类似网格结构的数据的神经网络,比如时间序列数据和图像数据。CNN可以用于输出高维的结构化对象,而不仅仅是预测分类任务的类标签或回归任务的实数值卷。CNN提供了一种方法来特化神经网络,使其能够处理具有清楚的网络结构拓扑的数据,这种方法在二维图像拓扑上最成功。CNN在自然语言处理(Natural Language Processing, NLP)领域的应用如:文本语义相似度计算。CNN应用于文本时,由于文本不是二维卷积层而是一维的,其输入序列可以是字符序列也可以是单词序列。CNN在字符级别的文字应用上,可以被可视化。当应用于大噪声数据时,字符级CNN表现良好。CNN非常适合具有空间结构的数据,包括声音、图像、视频和文本。由于文本不是二维卷积层,而是一维的,CNN用于文本时需要引入预处理。
循环神经网络(Recurrent Neural Network, RNN),是一类用于处理序列数据的神经网络,循环网络可以扩展到更长的序列。人类的大脑能够存储记忆,因此可以分析过去的数据,检索有用的信息以理解当前的场景。多层感知层和CNN在结构中缺少内存,因此不能存储来自过去输入的任何信息以分析当前输入。RNN由于具有内存功能,被广泛应用于语音识别、时间序列预测、自然语言处理。RNN是通过输入序列而不是单个输入来训练的,可以处理不同的序列长度,可以以不同的形式使用,且可以互相堆叠。RNN的优势是加入了上一时刻隐藏层的输出,处理了时序问题,缺点是存在无法解决长时依赖的问题,即只能保存上一次比较短暂的内容,序列较长时,序列在前的信息对后面序列的作用越来越弱。
对简单循环神经网络的优化模型,包括门控循环单元(Gated Recurrent Unit, GRU)和长短期记忆网络(Long Short-Term Memory, LSTM)。由于最简单的RNN不能在序列中保持长期的关系,为纠正该缺点,需要在其中添加一个特殊的层,即门控循环单元(GRU)。为摆脱梯度消失的问题,GRU帮助网络以明确的方式记住长期依赖关系,通过在简单RNN中引入更多变量来实现。梯度消失问题使得梯度难以从网络中的较后层传播到较前层,导致网络的初始权重与初始值相差不大,因此模型学习效果不佳。LSTM通过在网络中引入“记忆”来解决这个问题,允许网络从先前时间步长的激活中转移大部分知识。遗忘门负责确定应在前一个时间步长中遗忘的单元状态的内容,在每一个时间步长可使用表达式计算新的候选单元状态,输入门确定候选单元状态的哪些值被传递到下一个单元状态,输出门负责调节当前单元状态允许影响时间步长的激活值的数量。
2.2 深度学习在NLP中的应用
NLP是计算机科学领域与人工智能领域中的一个重要方向,它研究实现人与计算机之间用自然语言进行有效通信的各种理论与方法,涉及所有用计算机对自然语言进行的操作,包括获得文本语料和词汇资源、处理原始文本、文本分类、从文本提取信息、分析句子结构、建立文法、分析语句的含义、语言数据管理等。NLP由于其面临的众多问题,已成为目前制约人工智能取得更大突破和更广泛应用的瓶颈之一。使用深度学习技术推动NLP的发展是当前的研究热点和难点。基于深度学习的自然语言处理存在的主要问题包含方法与应用两个层面:在方法层面主要存在缺乏理论基础、 模型缺乏可解释性、对大量数据的需求和对强大计算资源的依赖,以及难以处理的长尾问题;在应用层面通常只报告最佳性能,很少提及平均水平、变化情况及最差性能。
3 基于深度学习的语义级中文文本校对
3.1 深度模型
端到端的深度模型可以避免人工提取特征,减少人工工作量。常用基于深度学习的纠错方法分三种:分别是基于LSTM的纠错方法、基于Transformer 的纠错方法以及基于预训练模型的纠错方法。最经典的NLP模型是序列到序列模型,按时间分为两种,一种是简单的RNN模型,在处理长文本序列的时候,会构成连乘结构导致梯度消失和梯度爆炸等情况的出现;第二种是包含时间信息的,如LSTM采用了三个门结构:输入门控制当前结点的输入信息、输出门控制当前节点的输出信息、遗忘门控制上一个节点的遗忘信息。Transformer依旧是序列到序列模型,在结构上进行了创新,抛弃了传统的RNN,完全采用注意力机制进行计算,既解决了序列模型长距离依赖的问题,也解决了序列模型并行程度差的问题。Transformer 用于文本纠错,与 LSTM 相差不大,都是以错误文本为源文本,正确文本为目标文本,用于训练深度学习模型。
由于预训练模型在特定场景使用时不需要用大量的语料来进行训练,节约时间效率高效,因此,基于预训练模型的纠错方法是目前最好的选择。选用基于预训练模型的方法,预训练模型通过自监督的训练方式学习文本的表征方式、语义关系、语法结构等,再将学习到的知识迁移到下游任务中,加快模型收敛速度,提升模型效果。BERT模型是一种预训练模型,模型使用了全注意力机制,能够在预测时,利用全局的文本信息,是真正的双向语言模型。BERT在多方面的NLP任务变现来看效果都较好,具备较强的泛化能力,对于特定的任务只需要添加一个输出层来进行精调即可。因此,选用BERT模型作为预训练模型。
3.2 数据集
实验数据包括训练数据集和测试数据集。采用深度学习的模型,实现中文语义校对,需要有足量的语义错误数据集。现有的专门用于语义错误测试的数据较少,为实现语义级中文文本校对,即要求方法从功能上能实现语义错误的校对,而不仅仅限于语义校对,可以使用原有的中文校对数据集,向其中加入语义错误的数据,为保证方法的效能,应使语义错误占比为50%以上。
由于文本数据在可用的数据中是无结构的,文本内部会包含很多不同类型的噪点,所以要对文本进行预处理。文本预处理过程主要是对文本数据进行清洗与标准化。文本标准化是NLP任务里的一个数据预处理过程。它的主要目标与常规数据预处理的目标一致:提升文本质量,使得文本数据更便于模型训练。
为扩大语义错误样本规模,扩充训练数据集,可使用数据增强技术:一是增加噪音,即在原始差错数据集中通过增加字词、删除字词、替换字词等构造新的差错文本数据;二是采用回译的方法,如先将中文翻译成英文,再将英文翻译成中文,得到的目标文本即为构造的数据。为得到更多的差错文本数据,可以采用多语种回译,翻译及回译都可借助翻译软件获得。
3.3 语义校对知识集
基于深度学习的文本自动校对,其实施依赖于模型的预训练及微调。对于用户来说,语义知识库是不可见的,但对于系统本身,须考虑模型的可靠性以及模型训练的硬件开销及时间开销,合理的利用已有的语义知识库可以大大降低算法的时间复杂度,同时也可节省硬件消耗。语义知识库即针对某类语义差错问题相应的语义匹配知识集。
出现频次较高的语义错误有成语使用错误、文本褒贬色彩使用错误、敬语与谦词的误用、历史事实的错误、地理知识错误、人名-职务-时间错误等。为验证校对系统的语义校对功能,模型训练及测试环节都要用到相应的知识集。根据常见语义错误,可以逐项构建如表1所示的知识集。
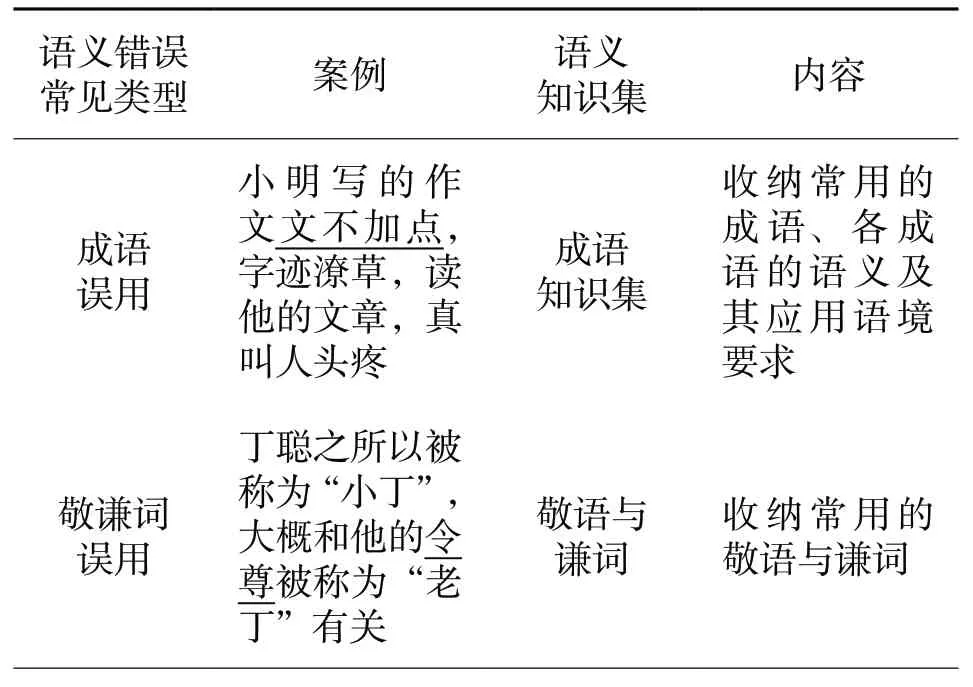
表1 语义匹配知识集系列

(续表)
3.4 实验与测评
根据NLPCC 2018竞赛发布数据将三个主要的代表团队在比赛中取得的成绩列为表2,由三个中文校对系统取得的F0.5分数可知,网易有道团队的Youdao系统为NLPCC 2018 GEC共享任务冠军解决方案。表2中获得的精确率、准确率及F值为语义校对系统评价提出了参照指标。

表2 系统模型在数据集上的F0.5值结果对比
待模型训练成熟,参数设置稳定后,基于深度学习的语义校对实验环节,主要通过测试数据验证系统的纠错功能。目前公开的中文校对测试数据有NLPCC2018比赛数据集、SIGHAN2015的纠错数据集以及今日头条在新闻标题中自动构建的500万条纠错数据集。但上述数据集均为未特定包含语义错误的数据集,不便与其他测试系统进行横向比较。因此,实验测试仅关注在逐步增加迭代次数和数据集规模中,系统获得的校对准确率及召回率变化情况。
4 结论
针对出版界对于中文文本校对现有产品的语义校对能力薄弱的问题,本文基于深度学习的方法,从查错纠错模型上对语义级中文文本校对进行探索,基于BERT模型,利用现有的开放的数据集进行模型训练,该方式可以有效提升校对效果。由于硬件实验平台条件有限,可用于深度学习训练的真实语义错误数据集规模有限,目前仅能实现若干词语级别、句子级别语义错误的校对,但准确率还有待提高,且实验测试数据规模还需扩大,这是后续研究中需要进一步努力的方向。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
快乐学习报·教育周刊(2022年16期)2022-05-01
小天使·一年级语数英综合(2022年2期)2022-03-30
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
福建基础教育研究(2019年6期)2019-05-28
长江学术(2016年4期)2016-03-11
人间(2015年21期)2015-03-11
人生十六七(2015年29期)2015-02-28
长江学术(2015年1期)2015-02-27
短篇小说(2014年11期)2014-02-27
