
浅层卷积神经网络融合Transformer的金属缺陷图像识别方法
2022-10-18 05:01唐东林刘铭璇
中国机械工程 2022年19期
唐东林 杨 洲 程 衡 刘铭璇 周 立 丁 超
西南石油大学机电工程学院,成都,610500
0 引言
在石油、化工、机械等工业领域,设备表面的金属缺陷会对工业产品的质量造成极大影响,因此工业上对金属缺陷检测的关注度逐年增加。由于检测速度慢、人工成本高、视力限制等,人工检测已不能满足当今行业的需求[1]。模式识别技术的发展极大地提高了缺陷检测技术能力[2]。模式识别技术能够自动学习已知样本特征并对未知样本进行自动识别,已广泛应用于缺陷检测识别领域[3-6]。
目前模式识别的缺陷检测方法中基于深度学习的卷积神经网络(convolutional neural network,CNN)应用最为广泛[7],它具有高度自动化的特点,能自动提取缺陷图像特征,实现端到端学习。文献[8]提出了级联自编码器结合CNN的金属表面缺陷识别模型,优化了池化造成的信息丢失问题,但存在结构复杂、参数优化困难的问题;文献[9]通过改进传统CNN加强了背景和缺陷之间的对比度,并利用决策树评估模型进行调参优化,但其参数量巨大,容易陷入过拟合状态;文献[10]改进了ResNet50,添加了可变形卷积,优化了分类结构,提高了钢材表面缺陷识别准确率,但网络结构复杂且计算量大;文献[11]设计了轻量级CNN用于缺陷识别,并结合随机森林增强了模型特征选择能力,但网络太浅图像感受野太小,无法充分学习图像语义信息;文献[12]构建了多尺度特征重构网络以获取不同尺度的钢板缺陷信息,但网络分支较多,增加了网络训练时间;文献[13-14]基于卷积神经网络对钢管焊缝缺陷进行自动识别,但其网络结构过于单一,不具备识别不同尺度缺陷的能力;文献[15]使用数据生成技术解决了缺陷数据不平衡的问题,并设计了轻量级CNN金属缺陷分类器,但网络中频繁使用池化操作,造成了图像信息丢失问题。总体上,深层CNN参数量多,计算量大,训练成本高,而浅层CNN无法充分学习到图像信息。此外,CNN通过卷积核往往只能考虑到图像局部信息而忽略全局信息。
最近,自然语言领域擅长学习序列全局信息的Transformer模型[16]受到广泛关注。文献[17]将Transformer用于图像分类任务,成功学习到图像全局信息,在超大数据集上性能超越了CNN模型;文献[18]引入蒸馏损失,进一步提高了Transformer图像分类性能;文献[19-20]将Transformer继续加深,并探究了加深Transformer时保持精度提升的方法。目前Transformer在大型数据集上的表现已超越CNN,但其训练成本非常高;在中小规模数据集上,由于Transformer直接学习全局信息且模型参数量大,学习难度高,通常处于欠拟合状态,性能较差。
在此基础上,本文提出了一种适用于中小规模数据集的,利用浅层CNN捕捉图像局部信息,利用Transformer捕捉图像全局信息,并引入通道注意力模块SE(squeeze and excitation)[21]捕捉重要特征通道的金属缺陷识别方法。实验表明,在中小规模数据集上,相比传统CNN和Transformer模型,该方法能更快速准确地实现金属缺陷识别。
1 本文方法
CNN-Transformer模型结构如图1所示。由模型整体框架(图1a)可知:通过4层CNN学习图像局部信息及其位置信息;利用Transformer捕获全局像素点之间的相关性以学习图像全局信息,同时引入SE模块对重要通道进行重点关注;最终利用一层CNN融合所有图像语义信息,通过全局平局池化进行降维,由全连接层(fully connected layer)实现金属缺陷的自动识别。

(a)模型整体框架
1.1 CNN特征提取层
为解决深层CNN模型复杂度高、在中小规模数据集上容易过拟合的问题,本文采用4层浅层CNN进行特征提取,结构简单且特征提取效率高,具体参数如表1所示。其中,输入图像尺寸为C×H×W,C、H、W分别表示图像的通道数、高、宽,本文数据集均为单通道灰度图,输入C=1。本文采用补零操作的主要目的是使越靠近图像边缘的区域卷积后的像素值越小,实现图像位置信息的学习。

表1 卷积层具体参数
由于特征提取中池化下采样会造成图像信息丢失,本文对此进行改进,通过设置卷积核步距为2的方式进行下采样以保留图像信息。为防止过拟合、梯度爆炸和梯度消失现象,卷积后利用BN(batch normalization)层进行批标准化处理,并通过ReLU激活函数进行非线性增强。
1.2 SE通道注意力模块
不同特征通道包含不同图像语义信息,为重点关注重要特征通道并抑制不重要的特征通道,本文引入通道注意力模块SE,如图1b所示。首先进行全局平均池化(global average pooling)以获取通道级全局信息:
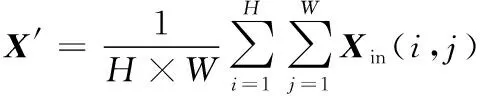
(1)
其中,Xin∈RC×H×W,表示输入特征图;X′∈RC×1×1,表示池化后的特征图。
池化后进行通道权重计算,并将权重乘以原特征通道输出最终特征:
Xout=Xin⊙σ(FC2(ReLU(FC1(X′))))
(2)
其中,FC1(C,C/4)、FC2(C/4,C)为两层全连接层;σ为Sigmoid函数;⊙表示elementwiseproduct乘法;Xout∈RC×H×W,为最终输出特征。
为优化梯度传递,本文在输出特征与原特征之间设置了残差模块。
1.3 Transformer层
由于CNN模型通过卷积核仅能捕捉到图像局部相邻信息,因此本文融合Transformer以学习图像全局信息,使模型在关注局部信息的同时考虑图像全局信息,降低了训练成本并提高了缺陷识别准确率。
Transformer来源于自然语言处理领域,能够捕捉任意长度语言序列之间的相关性。本文融合Transformer用于缺陷图像识别领域,其实现过程如图1c所示:将三维图像C×H×W分块并展平为与自然语言同维度的二维序列,以训练自然语言序列的方式训练二维图像序列,实现图像全局信息的学习。展平后序列维度为N×(P2C),P为图像块大小,N=HW/P2为图像块个数。
传统Transformer需要嵌入位置编码以学习序列之间的位置关系,本文在CNN层已通过补零操作实现自动学习图像位置信息,因此无需嵌入位置编码,简化了Transformer模型结构。为使数据分布更加稳定,对二维序列利用LayerNorm层进行层标准化处理,再将其输入多头自注意力层。
多头注意力机制(multi-head attention)是学习图像全局信息的核心,为便于理解,先引入自注意力机制(self-attention),计算过程如下:
Q=XPWqK=XPWkV=XPWv
(3)
(4)
其中,矩阵Wq、Wk、Wv∈RP2C×P2C;二维图像序列XP∈RN×P2C;Q、K、V分别为查询矩阵、匹配矩阵、值矩阵;Softmax为归一化指数函数;d值取图像序列维度P2C。
为扩展模型专注图像不同位置的能力,引出多头注意力机制,如图2所示。多头注意力机制具有多个自注意力头,将Q、K、V按注意力头数进行划分,分别完成自注意力计算,并融合所有注意力头的信息,更全面地考虑不同序列之间的相关性。
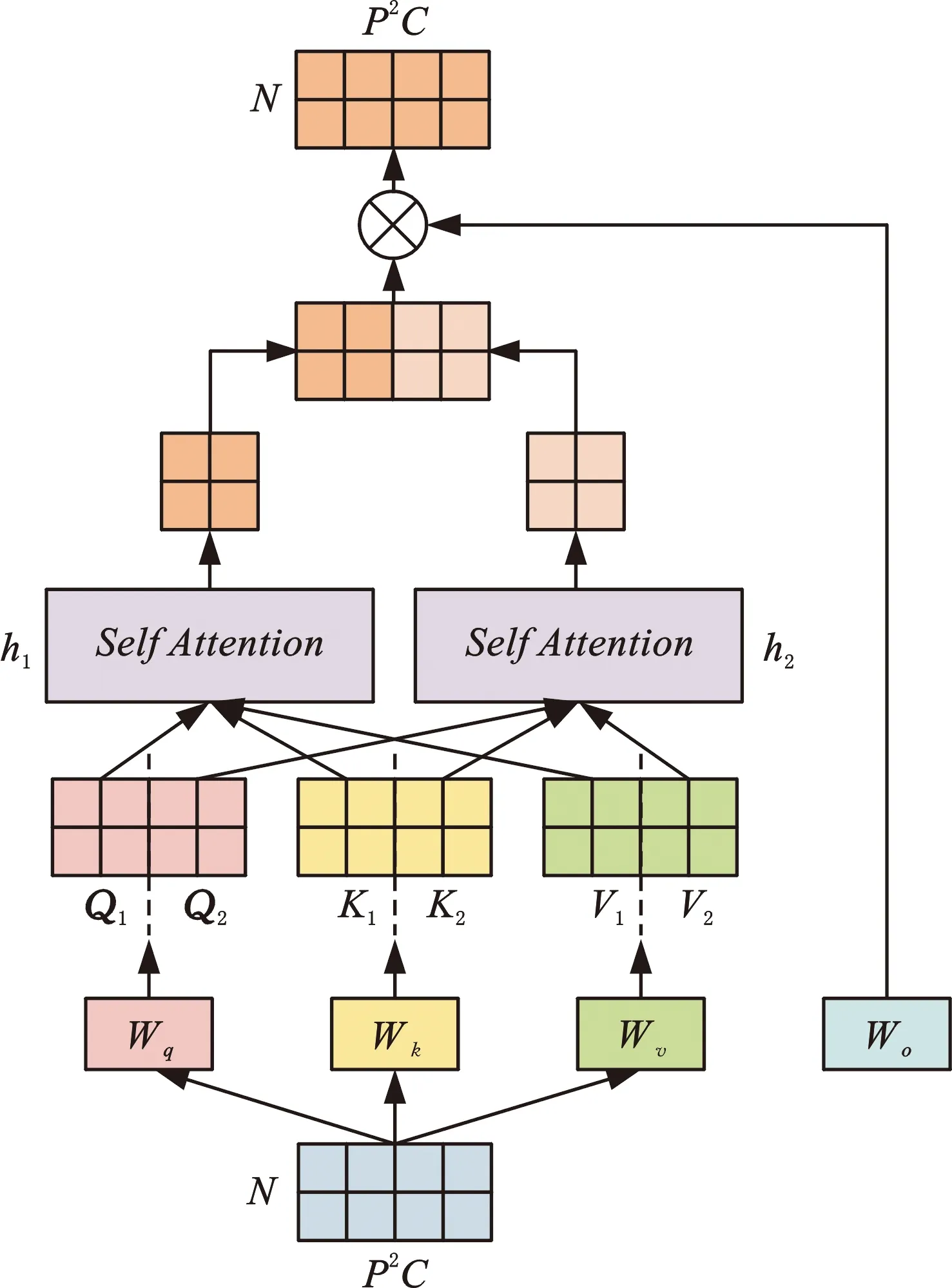
图2 多头自注意力机制Fig.2 Multi-head attention
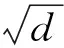
为减小模型参数量与复杂度,本文去除了多头自注意力层之后的前馈全连接结构,并设置了残差模块优化梯度传递。
传统Transformer主要通过在二维图像序列中额外插入一个class token向量进行训练并用以分类。本文对其进行改进,去除class token,将二维图像序列转换为三维图像,直接输入分类层进行分类,简化了模型结构。
1.4 缺陷分类层
分类层用于实现金属缺陷的自动识别。如图1a所示,本文利用一层卷积核大小为1×1的卷积层融合此前所有信息,不改变特征图大小,输出通道为1024;利用全局平均池化将特征图降维至1024×1×1后将其展平;最后全连接层FC(1024,classes)将维度映射到类别数classes实现缺陷分类。
2 实验数据设置
2.1 数据集介绍
为验证本文方法有效性,引入了公开数据集NEU-DET[22],同时通过实验自建钢板缺陷超声数据集来验证模型通用性。
(1)钢材缺陷数据集NEU-DET。该数据集是东北大学发布的表面缺陷数据库,如图3所示,包含热轧钢带的6种表面缺陷:轧制氧化皮(Rs)、斑块(Pa)、开裂(Cr)、点蚀表面(Ps)、内含物(In)和划痕(Sc)。该数据库由1800张灰度图像组成,每一类缺陷包含300张分辨率为200 pixel×200 pixel的灰度图像。
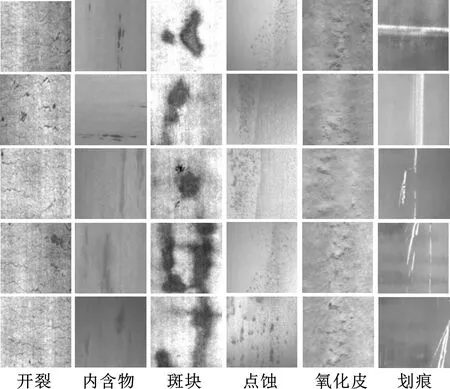
图3 NEU-DET数据集部分缺陷样本Fig.3 Partial defect samples of NEU-DET dataset
(2)钢板缺陷超声数据集。为模拟工业中不同的金属表面缺陷,在厚度11 mm的Q235钢板上加工了2 mm、5 mm、8 mm三种深度的缺陷,每种深度具有不同缺陷形状,如图4所示。实验采用频率2.5 MHz、底部直径20 mm的超声探头,探头通过无缺陷的钢板背面发射超声信号并接收反射信号,利用数字式超声探伤仪、示波器来读取并记录超声缺陷信号。

图4 缺陷钢板和信号检测设备Fig.4 Steel plate with defects and signal detection equipment
实验采集了每种深度200个共600个缺陷信号,每个缺陷信号为1×16 384的一维波形信号。为满足图像处理实验要求,将1×16 384波形信号转化为128 pixel×128 pixel二维灰度图像,如图5所示。
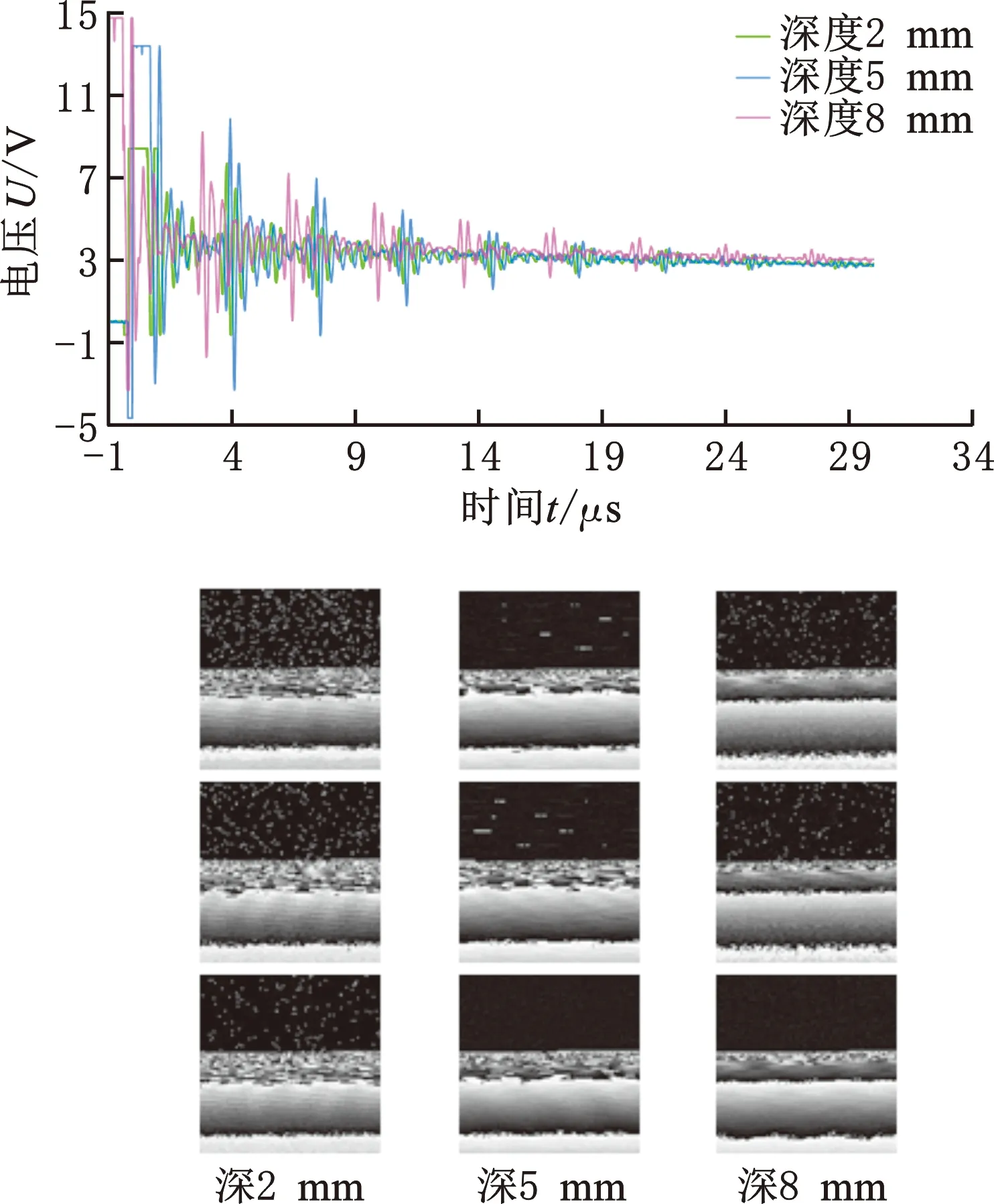
图5 超声部分波形信号和数据转化图Fig.5 Waveform signal and data conversion diagram of ultrasonic
为充分利用所有数据样本以减小实验误差,本文进行10次独立实验,每次均从原数据集中重新随机抽取70%样本作为训练集,其余30%样本作为测试集,取10次实验平均结果作为最终实验结果。其中,NEU-DET数据集以缺陷类别为分类标准,超声数据集以缺陷深度为分类标准。具体数据集划分结果如表2和表3所示。
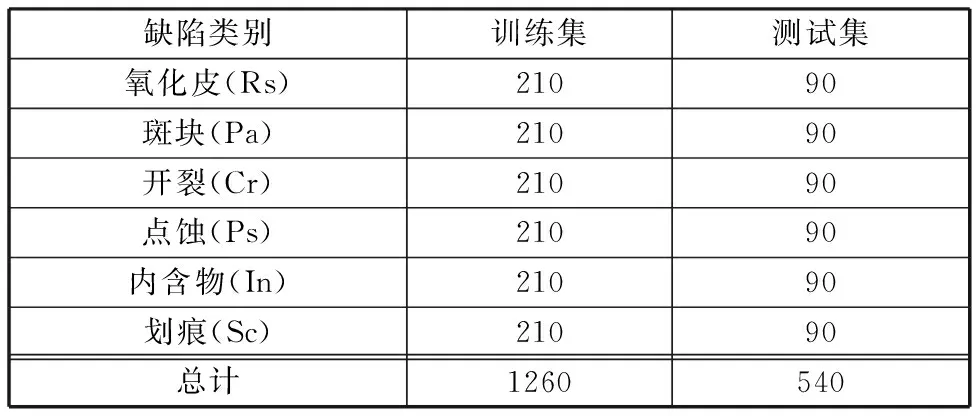
表2 NEU-DET数据集划分

表3 超声数据集划分
为提高模型的鲁棒性,针对本文采用的所有数据集,在每一轮训练中,对训练集进行标准化处理,并以0.5的概率分别进行旋转、平移、水平翻转、垂直翻转或同时进行水平垂直翻转,实现每一轮参与训练的图像均不完全相同,以提高模型泛化能力;在测试集中则只进行标准化处理。
2.2 实验参数设置
本文实验平台为Pycharm,深度学习框架为Pytorch,CPU为Intel(R)Core(TM)i5-10400F CPU @ 2.90 GHz,GPU为NVIDIA GeForce RTX 2060(6 GB)。根据不同数据集的规模对训练参数进行微调,具体如表4所示。

表4 模型参数设置
3 实验结果与分析
实验中训练集负责进行参数学习以拟合模型,测试集用以对模型性能进行评估,不参与训练与参数学习,因此以下实验均采用测试集的实验结果作为模型评价指标。
3.1 缺陷分类实验
为验证本文模型对缺陷的识别性能,引入中小规模数据集NEU-DET进行实验,模型准确率δ和损失Δ变化如图6所示。因为迭代初期学习率相对较大,模型参数更新幅度大,导致准确率和损失有一定波动,但总体准确率呈现上升趋势,迭代40次后模型便接近收敛状态。同时模型结构简单、参数量少,模型性能稳定,未出现过拟合现象。通过10次独立实验取平均值最终准确率为97.8%。
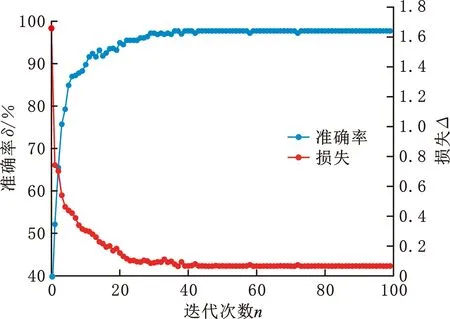
图6 NEU-DET数据集性能曲线Fig.6 NEU-DET dataset performance curve
通过混淆矩阵展示模型的具体识别情况,如图7所示。横坐标为真实类别,纵坐标为预测类别,真实类别与预测类别相同则识别正确,即对角线值。模型整体识别准确率较高,但由于内含物(In)、点蚀(Ps)、划痕(Sc)三类缺陷部分样本存在相似特征,导致模型出现了识别混淆。
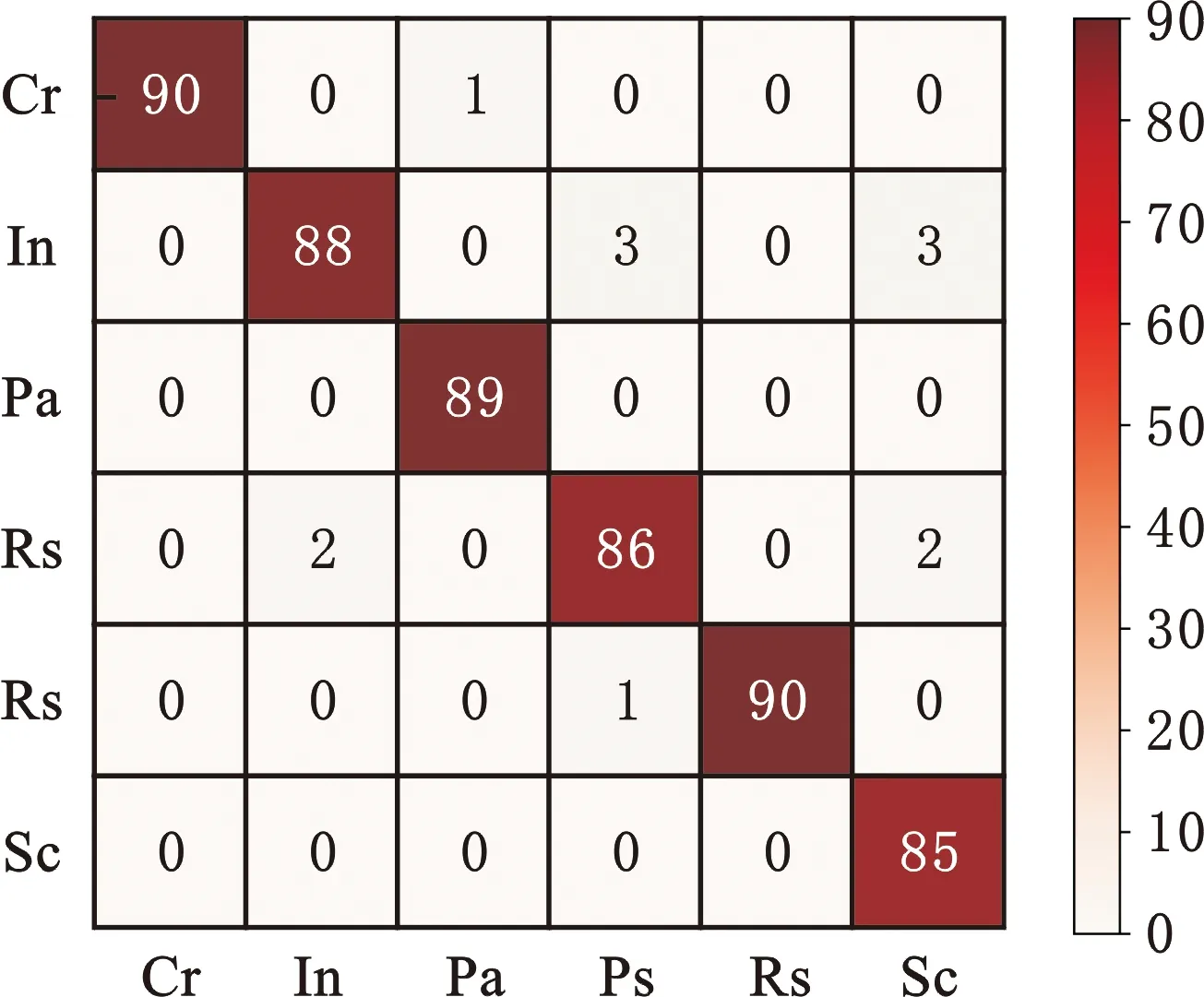
图7 NEU-DET数据集混淆矩阵Fig.7 Confusion matrix of NEU-DET dataset
为验证模型通用性,本文引入实验采集的超声数据集进行实验,其准确率和损失曲线如图8所示,在更小规模的超声数据集上本文模型更快更稳定地达到了收敛状态,这是因为超声数据集类别更少,缺陷特征更为简单,进行10次独立实验后平均准确率达到了更高的98.8%。

图8 超声数据集性能曲线Fig.8 Ultrasonic dataset performance curve
具体分类结果如图9所示,模型对三种深度缺陷识别准确率均较高,证明了本文模型在中小规模数据集上具有较好的通用性。

图9 超声数据集混淆矩阵Fig.9 Confusion matrix of ultrasonic dataset
3.2 类激活热力图可视化实验
为了验证本文模型捕捉缺陷特征的能力,在公开数据集NEU-DET上可视化图像类激活热力图[23],即输入图片的不同区域对模型进行缺陷识别的影响程度,颜色越红的区域越能主导识别结果,如图10、图11所示。

图10 部分简单缺陷类激活热力图Fig.10 Grad-CAM of some simple defects
由图10可以看出,对于特征明显的简单缺陷,主导本文模型进行识别决策的核心区域明显位于缺陷区域。
如图11所示,对于尺寸小、数量多,以及一些特征不明显的缺陷,热力图仍在缺陷区域颜色最深,证明了本文方法能有效捕捉缺陷信息。但也存在个别微小缺陷被遗漏的情况,这可能是影响识别精度进一步提高的原因,值得后续深入研究进行改进。

图11 部分复杂缺陷类激活热力图Fig.11 Grad-CAM of some complex defects
得益于Transformer捕获图像全局信息的能力,使热力图整体上分布广泛,并不仅集中于局部缺陷区域,而是从整个图像收集了更多信息,更符合人类感知结果。
3.3 消融实验
为验证Transformer和SE模块对模型性能的影响,将浅层CNN模型、引入SE模块的CNN模型、CNN-Transformer模型和本文提出的引入SE模块的CNN-Transformer模型进行对比实验,评价指标包括准确率、损失、浮点计算量以及参数量,具体如表5所示。可以看出,Transformer、SE模块都能有效改进CNN模型,在利用CNN捕捉图像局部信息的基础上,通过Transformer捕获图像全局信息,能够以较少的参数量、较低的训练成本提取完整的图像特征,最大程度提高模型性能。引入SE模块能在图像通道层面做进一步特征过滤,加强重要通道的特征表达而抑制不重要的通道特征,进一步提高模型性能,且几乎不增加额外的参数量与计算量。

表5 消融实验
本文方法相对于浅层CNN模型仅有少量参数量和计算量的增加,但却带来了巨大的性能提升,实现了最高的缺陷识别准确率,证明了本文方法在中小规模数据集中能充分发挥性能。
3.4 网络模型综合对比实验
为验证本文模型的综合性能,与CNN模型VGG16[24]、GoogleNet[25]、ResNet34[26]、MobileNetv2[27]、ShuffleNetv2[28]以及Transformer模型ViT[13]进行对比实验。
实验曲线如图12和图13所示,在本文的两个中小规模数据集上,由于Transformer模型ViT直接学习全局图像信息,学习难度大导致收敛速度慢。同时因其对数据量的要求非常高,本文数据集无法有效拟合模型参数,导致其性能较差且迭代曲线波动较大。
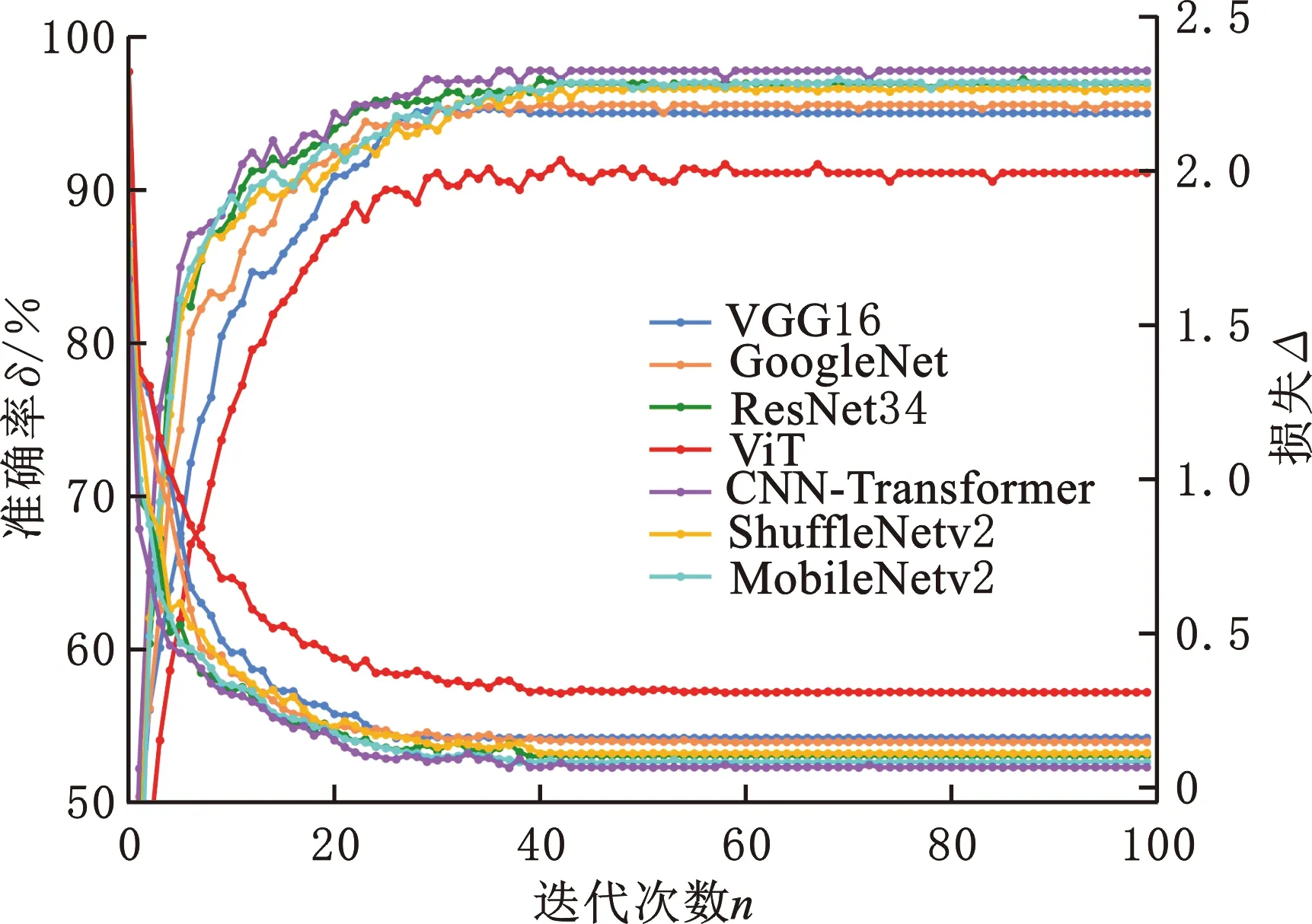
图12 NEU-DET数据集性能对比曲线Fig.12 Performance comparison curve of NEU-DET dataset

图13 超声数据集性能对比曲线Fig.13 Performance comparison curve of Ultrasonic dataset
各模型具体性能指标如表6所示,训练时间为数据集训练耗时,推理时间为单张图片推理耗时,对最优结果进行加粗。可以看出,主流CNN模型的参数量和计算量都比较大,在中小规模数据集中,其性能受限容易过拟合,参数最多的VGG16性能表现较差,表明CNN模型并不会因为可学习参数量多而取得更好性能。
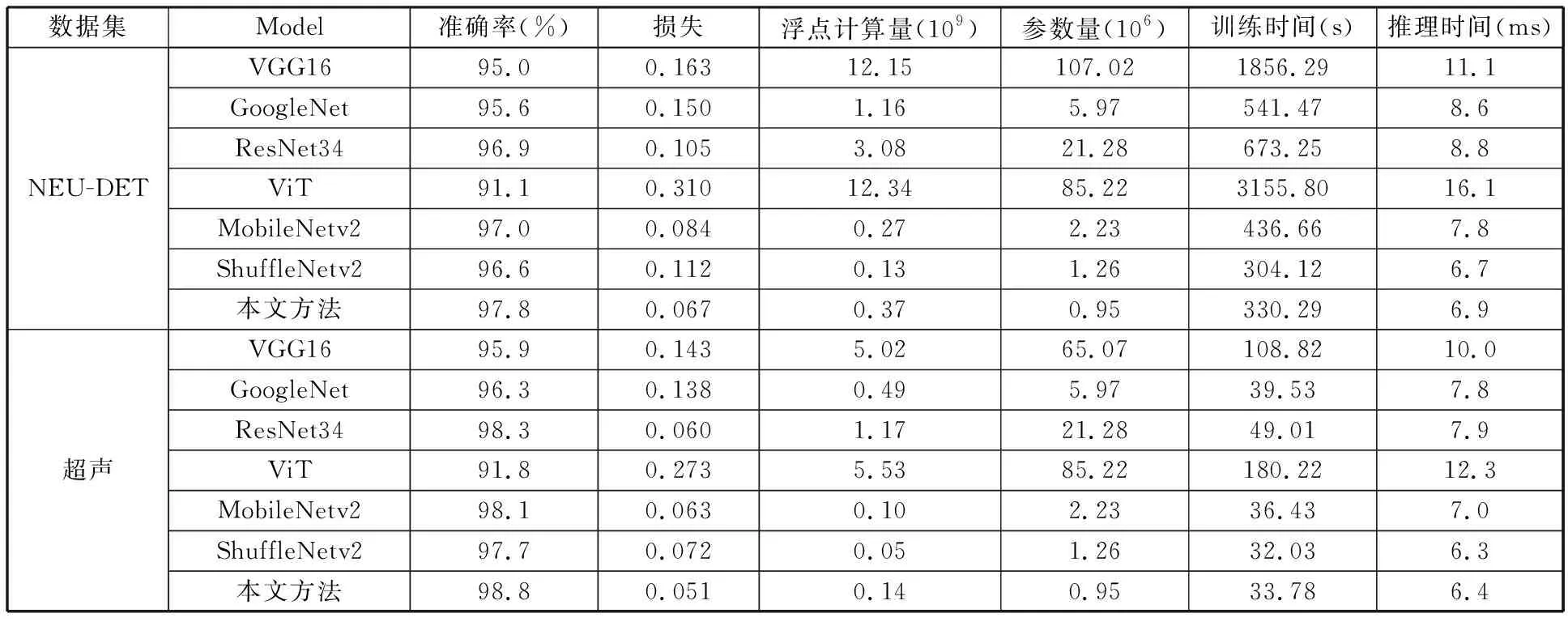
表6 模型综合指标对比
本文方法在中小规模数据集上取得了更好的综合性能,MobileNetv2和ResNet34的准确率虽然和本文方法相近,但是本文模型网络更浅、结构更简单,推理时间更短;ShuffleNetv2参数量、推理时间与本文方法相差不大,但本文方法在保持高效率的同时能够学习图像全局与局部信息的优势是其所不具有的,因而在准确率上表现更优。
4 结论
金属缺陷识别技术在工业领域具有重要研究意义。本文针对中小规模金属缺陷数据集提出了一种浅层CNN融合Transformer并引入SE模块的缺陷识别模型,模型利用浅层CNN捕捉图像局部信息,与主流深层CNN模型相比具有参数量少和计算量小的优点,可有效地避免过拟合现象发生;利用Transformer多头注意力机制捕获图像全局信息,解决了CNN模型无法学习图像全局信息的问题,同时引入通道注意力SE模块实现重点关注重要通道。本文引入了NEU-DET数据集和超声数据集来验证模型性能,试验结果表明,本文方法在准确率、参数量、计算量、推理时间等重要评价指标上都表现出良好的性能,对未来实现工业上金属缺陷的在线高效率、高精度识别具有现实意义。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2022年8期)2022-08-31
中国医院院长(2022年13期)2022-08-15
计算技术与自动化(2022年1期)2022-04-15
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
