
基于密度和记忆的动态多目标优化算法
2022-10-25 12:13王晓冬栗三一
计算机仿真 2022年9期
王晓冬,栗三一
(1. 郑州科技学院,河南郑州450064; 2. 郑州轻工业大学,河南郑州450002)
1 引言
很多实际的多目标优化问题(MOPs)会随着时间发生变化,称之为动态多目标优化问题(DMOPs)。对于随环境变化较慢的MOPs,人们往往在环境变化时随机重新初始化种群,并用静态多目标优化算法求解。然而,对于无人驾驶的路径规划过程中,由于环境因素变化迅速,静态多目标优化算法无法快速追踪帕累托前沿,很难求得高质量的解,从而制约了该技术的应用。
为了解决这个问题,研究人员提出了两类种群初始化方法:基于预测的方法和基于记忆的方法。基于预测的动态多目标优化算法(DMOAs)在环境发生变化时,根据之前获得的帕累托解(POS)预测环境变化后的POS。基于预测的DMOAs可以有效地解决环境变化平缓或有规律的DMOPs。然而,当环境变化剧烈且不稳定时,预测精度难以保证。无人驾驶过程中需要根据路况实时优化行车路线,当遇到复杂的路况时基于预测的方法无法有效及时的确定最优路线。
与基于预测的DMOAs相比,基于记忆的DMOAs不受环境变化剧烈程度的影响。基于记忆的种群初始化方法建立一个记忆池存储之前获得的解,利用记忆池中的解指导新环境下的种群初始化。在算法运行一段时间,记忆库丰富之后,基于记忆的DMOAs有令人满意的效果,在无人驾驶过程中,当遇到相似的路况时可以根据历史经验提供较合理的备选路线,从而快速确定最优路线。但该方法容易导致解丧失多样性。
当环境变化间隔很长时,可以采用局部搜索策略来解决DMOAs中解的多样性丢失问题。局部搜索机制可以有效地增加种群多样性,避免陷入局部最优,但在局部搜索过程中需要大量的计算。因此,当DMOPs的环境变化较快时,现有局部搜索策略效果并不理想。
为了减少局部搜索过程的计算量,本文提出了一种基于密度的局部搜索策略,并将其应用于基于记忆的DMOA中,称为基于密度和记忆的NSGA2算法(NSGA2-DM)。NSGA2-DM建立了一个记忆池来存储代表性的解和相应的环境信息。当遇到相似或相同的环境时,将根据记忆池生成初始种群。在遗传过程中,NSGA2-DM用目标空间中每个解的密度来评价每个非支配解的稀疏度,并将稀疏度最小的非支配解定义为稀疏解。在每个遗传过程中,NSGA2-DM只在稀疏解的周围进行局部搜索。NSGA2-DM同时采用极限优化局部搜索策略和随机局部搜索策略,提高了解的质量和收敛速度。算法的最终目标是在快速变化的环境中获得多样性良好和质量高的非支配解。本文的主要技术贡献可归纳如下:
1)基于记忆的种群初始化方法的一个难点是如何判断环境与记忆的匹配关系。本文提出环境变量的定义并对如何设定环境变量进行了描述,根据环境变量可以准确判断环境与记忆池中记忆的匹配关系。
2)现有的基于记忆的DMOA只记录一个解或将所有非支配解作为记忆。NSGA2-DM将中心解和交界解记录为记忆,其包含了解集的分布信息并且不占用很大的存储空间。例如,双目标优化问题一条记忆记录三个解,三目标优化问题记录四个解。
3) NSGA2-DM每代都在稀疏解周围进行局部搜索。当非支配解不均匀分布时,该策略使解均匀分布。当解分布均匀时,交界解的稀疏度最小,这意味着NSGA2-DM将围绕交界解进行搜索,以扩大解的范围。因此,NSGA2-DM可以保证解的多样性。
4)现有的局部搜索策略都是围绕所有解进行搜索,并且每一代都会产生大量的局部解,导致计算量大。NSGA2-DM只围绕稀疏解进行搜索,因此计算量小于其它局部搜索策略。
通过基准测试函数验证MSGA2-DM算法的有效性,并将MSGA2-DM的结果与两种基于记忆的DMOA、两种基于预测的DMOA和两种局部搜索NSGA2算法进行比较,实验结果表明NSGA2-DM算法可以根据环境变化快速跟踪变化的帕累托前沿,当种群初始化方法相同时,基于密度的局部搜索搜索策略结果优于所对比局部搜索方法。
2 动态多目标优化问题
一个DMOP可表述如下:
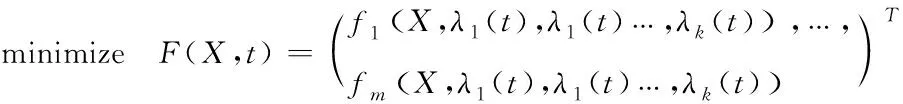
=(,,…,),≤≤,=1,2,…,
(1)
其中=0,1,2,…∈表示瞬时时间;(,)∈为维目标向量,由个时变目标函数组成;∈为维决策向量;和分别是第个决策变量的下限和上限;()为目标函数中的时变参数,为目标函数中时变参数的个数,一旦时间变量固定,则()为常数。DMOP基本上可以分为四类:
第一类:帕累托最优解集(POS)和帕累托最优前沿(POF)都保持不变。
第二类:POS和POF均随时间变化。
第三类:POS改变,POF不变。
第四类:POS保持不变,但POF发生变化。
第一类可以作为静态MOPs求解,后三种类型由于目标的变化增大了优化难度,因此主要研究后三种类型的DMOPs。DMOAs的目标是跟踪动态的POS(POF)。
3 NSGA2-DM的设计与分析
3.1 基于记忆的种群初始化(MPI)
为了复用过去的信息来初始化种群,需要构建一个记忆池来存储具有代表性的解和相应的环境变量值。环境变量的设置原则是:对于一个DMOP,具有相同环境变量值的系统可视为相同的静态系统。换句话说,具有相同环境变量值的DMOP具有相同的POS和POF。
对于式(1)表示的动态多目标优化问题可以将环境向量设置为
=((),()…,())
(2)
根据环境向量可以判断环境是否发生变化,并且可以判断新的环境是否在记忆池中有对应的记忆。设上一时刻的环境向量值为,当前环境向量值为,则当不等式(3)成立时环境发生改变。
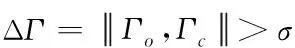
(3)
假设环境已经发生改变且当前环境向量值为,记忆库中共有条记忆,其对应的环境向量值为(,,…,),为与记忆库中环境向量值的欧氏距离,若

(4)
则新环境与记忆库中第条记忆对应的环境相近,否则记忆池中没有对应新环境的记忆。
若环境发生了改变,变化前环境变量若在记忆池中有对应的记忆则更新该记忆,否则生成新的记忆。每条记忆中包含中心解、交界解和对应的环境变量值。中心解是所有非支配解的平均值,交界解至少在一个目标变量上具有最大值。
记录记忆后,如果新的环境变量值与记忆池中的记忆不一致,则随机初始化种群。否则,将对应记忆中的解加入初始种群,初始种群中其余解随机初始化,初始化方法为:
=(,1,,2,…,,) (=1,…,+1)
(5)
=(,1…,,,…,,)=1,2,…,(--1)
(6)
,=(-)+=1,2,…,
(7)
其中,是记忆中的解;是第个初始解;是目标向量的维数;是决策向量的维数;是初始种群规模;是0到1之间的随机值。基于记忆的种群初始化过程如下所示(过程1)。
0) If 环境变量值发生变化.
1) If 前一时刻的环境变量值与记忆池中的一条记忆相匹配.
2)更新现有记忆。
3) else
4)形成新的记忆。
5) end if
6) If 新环境变量值与记忆池中的一条记忆相匹配.
7)将记忆中的解加入初始种群,根据等式(2)得到其它解.
8) else
9)随机生成所有初始解。
10) end if
11) end if
3.2 稀疏度计算
假设初始种群规模为。首先,对目标函数值进行归一化处理。假设第个解的目标向量值为()=((),…,()),归一化公式为
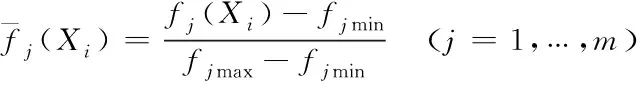
(8)
其中min和max分别是第个目标变量的最小值和最大值。则的稀疏度计算公式为
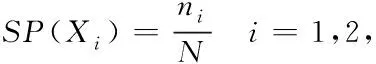
(9)
其中是目标空间中与欧氏距离小于的解的个数。本文将设为01。
备注1:不需要计算()与所有其它目标向量之间的欧几里德距离。只有当所有个目标方向上的距离都小于01,才需要计算其与()的欧氏距离。
备注2:值可以介于0和1之间。但是当值太大或太小时都不能准确反映解的稀疏度。可以做更多的实验来确定最合适的值。由于文章篇幅有限,本文实验根据经验将值设置为01。
3.3 局部搜索NSGA2算法
NSGA2-DM将稀疏度最小的解设置为稀疏解。然后围绕稀疏解进行局部搜索。当非支配解分布不均匀时,该策略提高解的均匀性。当解分布均匀时,它会围绕交界解进行搜索,以扩大解的范围(因为当解分布均匀时,交界点上的解密度更稀疏)。因此,这一策略可以保证种群的多样性。
NSGA2-DM同时采用极限优化局部搜索策略和随机搜索策略生成局部解。在极限优化阶段,每一个生成的局部解只有一个决策变量值与稀疏解不同,在靠近帕累托前沿时可以有效提高解的精度。
极限优化策略具有强大的微调能力。但是极限搜索的搜索范围较小,当非支配解远离POS时收敛速度较慢。为了提高收敛速度,NSGA2-DM同时采用随机局部搜索策略。随机局部搜索策略产生的局部解的个数为0.2N(向下舍入)。局部搜索解产生公式为:
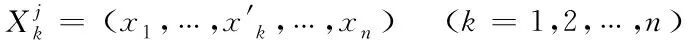
(=1,2,…,「02⎤)
(10)
′=+(-)
(=1,2,…,)(-02<<02)
(11)
其中是介于-02和02之间的随机值。为了保持种群的多样性,随机生成01个解。本部分生成解的总数为+「03⎤。
3.4 NSGA2-DM的主要过程
根据实际问题设置参数:种群规模;环境变化后最大迭代次数;决策变量个数;决策变量下界与上界=(,,…,),=(,,…,);目标函数个数;形状参数;交叉率;变异率;交叉参数;变异参数;环境变量;环境变化阈值;环境检测周期。2-的主要过程如下所示(过程2)。
步骤1:如果到环境检测周期则计算环境变量值。如果满足式(3),则环境发生改变,转至步骤2,否则环境未发生改变,转至步骤3。
步骤2:根据过程1更新记忆并初始化种群。假设初始种群为={,,…,},其中=(1,2,…,),=1,2,…,。
步骤3:计算中各解的适应度值和拥挤距离(与原2相同,本文不介绍具体过程)。所有非支配解记为种群。
步骤4:根据原2中的交叉和突变策略生成子代。
步骤5:根据式(9)计算种群中所有解的稀疏度。将稀疏度最小的解设置为稀疏解。
步骤6:局部搜索生成+「03⎤个解,形成种群。
步骤7:将,和合并形成种群。基于非支配排序和拥挤距离排序从中选择个个体。该个个体形成种群并设置=。
步骤8:如果达到环境检测周期则转到步骤1。否则,如果达到最大迭代次数,转到步骤9。否则,重复步骤7。
步骤9:中的非支配解是目前为止找到的最佳解,等待达到环境检测周期再次进行计算。
4 测试问题和性能指标
4.1 测试问题
本文所用的测试问题为标准测试问题dMOP1、dMOP2、FDA1、FDA4和FDA5。dMOP1和dMOP2是双目标动态优化问题。dMOP1的POS固定不变而POF随时间变化;dMOP2的POS和POF均随时间变化。FDA1是POS随时间变化而POF固定的双目标动态优化问题;FDA4是POS变化而POF固定的三目标优化问题;FDA5是POS和POF都随时间变化的三目标优化问题。所有问题的决策变量个数为20,决策变量的取值范围为0到1,变化幅度参数=10。
4.2 性能指标
Helbig等总结了一些动态多目标优化算法的评价指标。首先介绍静态多目标优化的反向世代距离(IGD)指标,然后将其扩展到动态问题上形成平均IGD指标(MIGD)。
假设*是一组在POF中均匀分布的Pareto最优解。是POF附近的一组解。IGD定义为
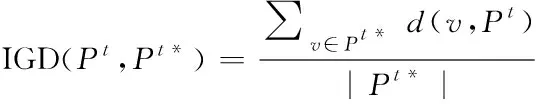
(12)
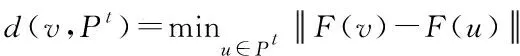
MIGD被定义为DMOP在一段时间中的IGD平均值,计算公式如下
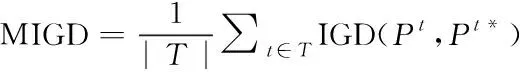
(13)
其中是一组连续的时间点,||是中时间点的个数。
在本文实验中,从双目标问题和三目标问题的POF上分别选取1000点和2500点作为P。
5 实验结果及分析
5.1 参数设置
问题和算法参数设置如下:
1)双目标问题系统每10秒更改一次,三目标问题系统每30秒更改一次,即双目标问题的t值每10秒增加1,三目标问题的t值每30秒增加1。所有实验的环境检测周期t设定为10秒。
2)所有问题的初始种群规模设定为100。
3)环境变化后最大迭代次数Imax设为双目标问题30次,三目标问题50次。
4)所有实验中交叉率设置为90%,突变率设置为1/n;交叉参数和变异参数均设置为20。
5)所有实验的环境变量设置为环境变量设置为=sin(05π+π2)。所有实验的环境变化阈值设定为001。
6)当≥100时,算法停止。
5.2 不同动态优化算法的结果对比
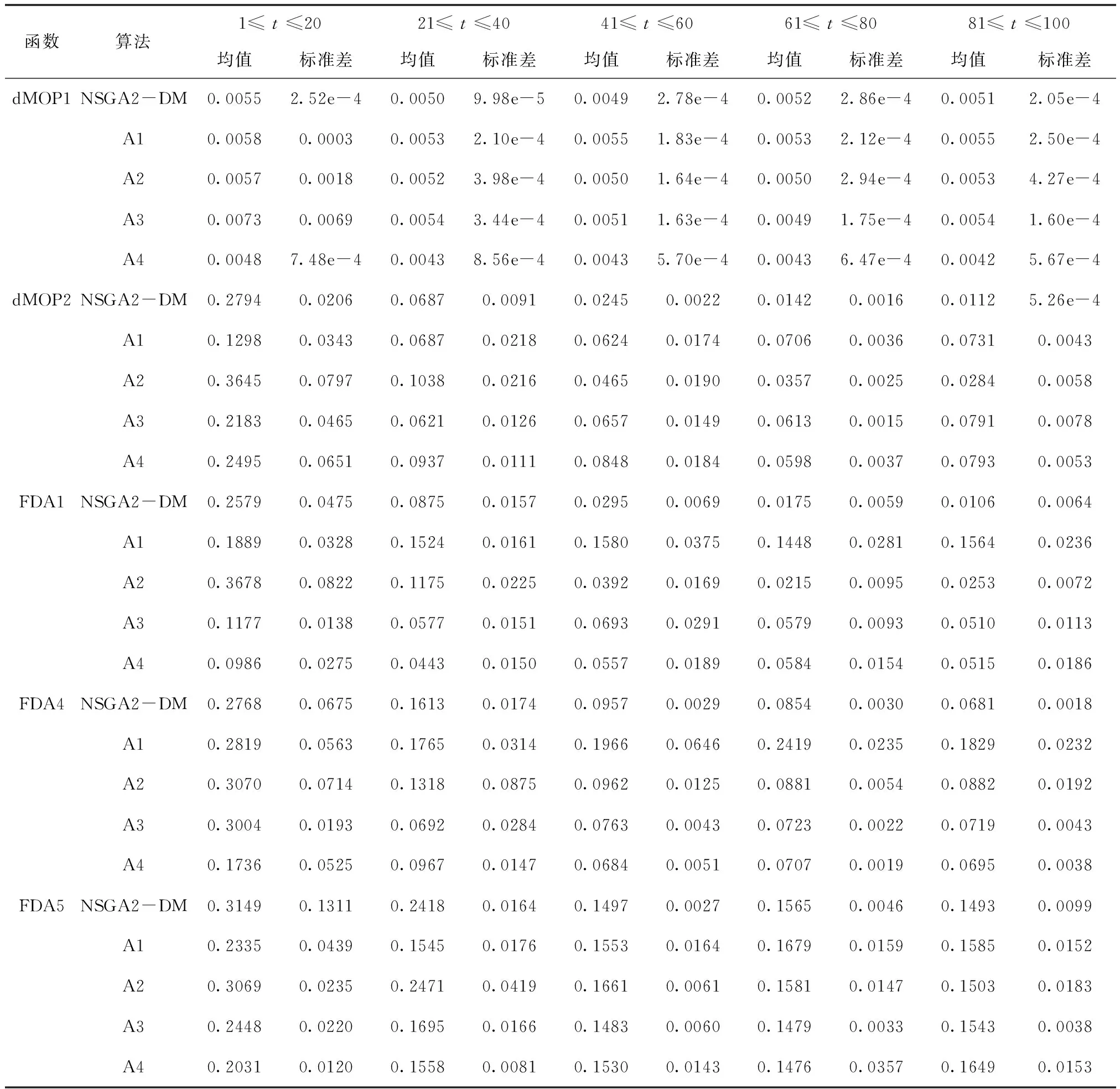
本实验将所提出的基于密度的局部搜索算法与不同的种群初始化方法相结合来解决基准问题。比较的算法包括:①文献[5]中提出的MPI方法(表示为A1);②文献[6]中提出的MPI方法(表示为A2);③文献[7]中提出的基于预测的种群初始化方法(PPI)(表示为A3);④文献[8]中提出的PPI方法(表示为A4)。当环境变化时,A1方法记录上一时刻的一部分特征解,其余解随机生成。A2方法只是在记忆中记录一个中心解。A3和A4建立了两种预测模型来预测环境变化时的解。
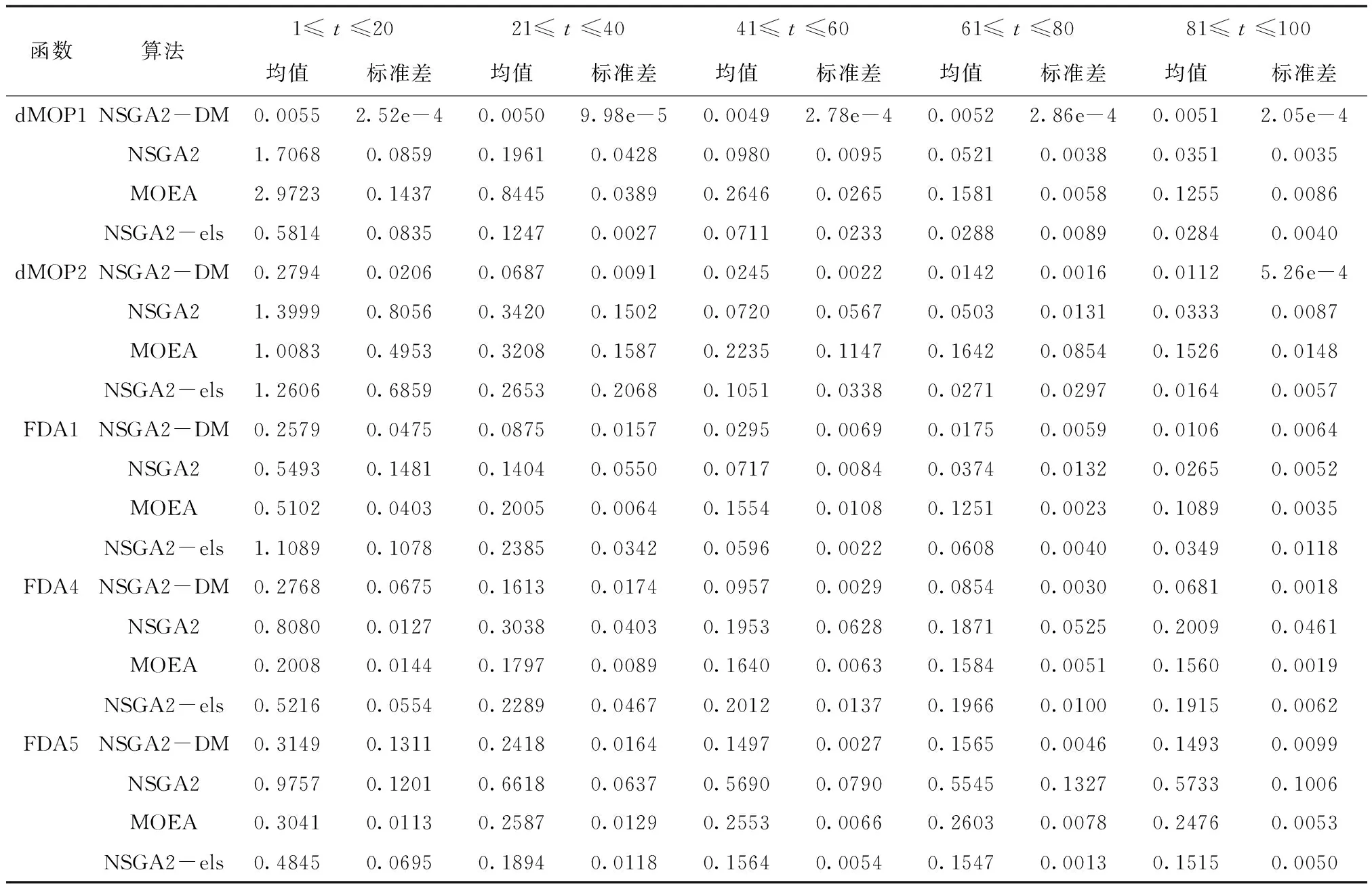
连续20次实验的MIGD统计结果见表1。结果显示,NSGA2-DM的性能优于A1,这意味着所提出的MPI方法比只在一个记忆中记录一个解的MPI方法包含更多有用的信息。对于dMOP1问题,A4达到最低的MIGD值,而在40 实验结果表明,与PPI算法相比,本文提出的种群初始化方法在记忆池完备的情况下可以达到更好的结果。但在算法运行初期,记忆池中的记忆很少,无法有效指导种群初始化,这是基于记忆的初始化方法的一个不足,可以将PPI与MPI进行优势互补解决这个问题。 为了验证所提出的基于密度的局部搜索算法的有效性,将本文提出的MPI方法与不同的局部搜索策略相结合来解决一些基准问题。比较的进化算法包括NSGA2、NSGA2-MOEA和NSGA2-els。 连续20次实验的MIGD统计结果见表2。由表2可知,当0 实验结果表明,当环境变化比较快时,本文提出的基于密度的局部搜索策略的性能优于所对比的局部搜索策略。这些所对比的局部搜索策略性能较差的主要原因是它们的计算量太大,没有足够的时间来获得较好的解。所以本文提出的NSGA2-DM算法适用于环境变化较快的动态多目标优化问题,而当环境变化缓慢时则适合采用计算量大但精度高的算法。 表1 基准测试问题中各算法MIGD指标的统计结果 表2 准测试问题中不同局部搜索策略的MIGD统计结果5.3 不同局部搜索策略之间的对比
 猜你喜欢
今日农业(2022年15期)2022-09-20中华书画家(2021年12期)2022-01-06学生天地(2020年14期)2020-08-25散文诗(2020年1期)2020-07-20特别文摘(2018年3期)2018-08-08生物学教学(2018年3期)2018-08-08中学生物学(2018年8期)2018-03-01东方艺术·国画(2016年3期)2017-02-08棋艺(2016年4期)2016-09-20诗选刊(2015年6期)2015-10-26
猜你喜欢
今日农业(2022年15期)2022-09-20中华书画家(2021年12期)2022-01-06学生天地(2020年14期)2020-08-25散文诗(2020年1期)2020-07-20特别文摘(2018年3期)2018-08-08生物学教学(2018年3期)2018-08-08中学生物学(2018年8期)2018-03-01东方艺术·国画(2016年3期)2017-02-08棋艺(2016年4期)2016-09-20诗选刊(2015年6期)2015-10-26
