
基于改进Mosaic数据增强和特征融合的Logo检测
2022-10-27 02:44陈翠琴范亚臣
计算机测量与控制 2022年10期
陈翠琴,范亚臣,王 林
(西安理工大学 自动化与信息工程学院,西安 710048)
0 引言
标志(Logo)是将企业、公共机构、事业单位或个人的产品和服务标识出来的独特的图形文字或图形符号的组合。Logo检测是目标检测的一个具体应用。它在知识产权保护、产品品牌识别、电商平台保护、智能交通车辆标识检测、社交媒体产品品牌管理等多个领域有着广泛的应用。自然图像中的Logo检测方法大致分为基于手工设计特征的方法和基于深度特征的方法。Sanyal等人[1]提出了一种基于harris仿射检测器获得的尺度不变特征变换(SIFT, scale-invariant feature transform)关键点的方法。Gao等人[2]提出了一种通过空间光谱显著性来发现Logo的检测方法,然后对查询图像中使用的这些区域提取加速鲁棒特征(SURF)。然后根据提取的SURF特征发现数据集图像与查询图像之间的相似度。为了减少误报,使用了局部空间上下文。Chinmoy等人[3]提出了一种基于SIFT、SURF和HOG描述符的Logo融合识别方法。自2012年以深度学习为主的图像分类以来,深度卷积神经网络(CNNs)的使用在计算机视觉领域变得普遍。CNNs在目标特征提取和表达方面比人工选择更合理、更强。S.C.H.Hoi等人[4]创建了大规模Logo图像数据集LOGO-Net以促进标志检测和产品品牌识别的研究,通过探索RCNN[5],Fast RCNN[6]和SPPnet[7]等几种最先进的基于区域的深度卷积网络技术来解决深度Logo检测和品牌识别任务。Oliveira等人[8]使用迁移学习来利用强大的卷积神经网络模型Fast RCNN来训练大规模的数据集,并将它们重新用于图形Logo的检测。C.Eggert等人[9]将Faster R-CNN[10]应用到公司Logo检测任务中,引入了一种改进的生成锚点建议的方案,并提出了一种对Faster R-CNN的修改,它利用了小物体的高分辨率特征地图,而提高小目标检测的性能。Yang等人[11]针对机动车Logo检测任务的YOLOv3模型[12]进行修改,通过难样本训练解决小目标检测问题。
Logo经常出现在较复杂的背景中,同时Logo对象具有多尺度特性,因此本文提出了MP-YOLOv4(improved mosaic and PANet YOLOv4)算法。相比于原始的YOLOv4算法[13],本文主要做了以下的改进。为了进一步丰富Logo对象的尺度和背景,提出了一种改进的Mosaic数据增强方法,将6张原始图片进行随机缩放、裁剪并拼接构成新的训练数据,与单张图片和4张原始图片拼接一起作为模型的训练输入,并确定3种输入形式的相对最优比例,同时采用在训练结束的前30个世代关闭Mosaic数据增强的训练策略。为了进一步加强多尺度特征融合,本文在路径整合网络(PANet, path aggregation network)[14]的基础上,结合跨层连接、重复堆叠、直接连接和加权特征融合等操作,设计了一种新的特征金字塔网络,增强了网络的特征融合和特征表达能力。
1 相关工作
1.1 YOLOv4网络
YOLOv4是YOLO系列中的一种新的目标检测方法,它的网络结构如图1所示。

图1 YOLOv4的整体网络结构
YOLOv4目标检测网络主要由输入(input)、骨干特征提取网络(backbone)、特征融合部分(neck)和预测头(head)四部分组成。模型对于输入采用了Mosaic数据增强方法,丰富了对象的上下文,提高了训练效率。在骨干特征提取网络中,在YOLOv3中Darknet的基础上,融入了CSPnet,从而整合成新的骨干网络CSPDarknet,并在其中用Mish激活函数代替了LeakyReLU激活函数。在Neck部分,使用空间金字塔(SPP,spatial pyramid pooling)和PANet对从骨干网络中获取的3个有效特征层来进行多尺度特征融合。在预测部分仍然使用YOLOv3中的Head对来自不同尺度的融合特征进行预测。本文主要Logo检测任务中的复杂背景和多尺度问题,对YOLOv4算法中的Input部分和PANet部分进行改进。
1.2 Mosaic数据增强方法
Mosaic数据增强算法参考了CutMix[15]数据增强算法,是对CutMix数据增强算法的进一步扩展。一般的数据增强方法是对一幅图像进行翻转、色域变换、缩放等操作,而CutMix的数据增强方法是将两幅图像进行拼接,并将拼接后的图像直接传输到神经网络中进行训练。Mosaic数据增强算法利用4幅图像进行拼接,形成包含4幅原始图像的合成图像,它可以在一幅合成图像中训练出多个不同的目标;这使得对象出现在它们正常出现的背景之外,为模型提供更加复杂和有效的训练背景;同时,在批处理归一化[16]操作中,可以同时计算6张图像的数据,这意味着不需要将超参数批大小(batch_size)设置得太大,就可以有效地训练模型,这样可以在单个GPU下训练目标检测算法,提高了模型训练的效率,节省计算开销。此外,在原始的YOLOv4模型训练过程中,模型有0.5的概率输入单张原始图像进行训练,同时有0.5的概率输入由四张图像拼接而成的合成图像来进行训练。
1.3 多尺度特征融合
不同图像之间以及同一张图像内部多个Logo对象的相对尺度差别较大,Logo检测任务中的多尺度检测问题面临着很大的挑战。为了在网络内部融合多尺度特征,获得多尺度特征表达,Lin等人[17]提出了著名的特征金字塔网络(FPN, feature pyramid networks)。文献[18]使用FPN来融合高低层级的语义信息,提升滤袋开口检测问题中对小目标的检测效果。Liu 等人提出了PANet。PANet在FPN的原自顶向下金字塔方法的基础上增加了一个自底向上的信息流,重新构建了一个强化了空间定位信息的特征金字塔。在YOLOv4目标检测模型中就是使用PANet来进行特征融合。Pang 等人[19]认为无论是FPN还是PANet在构建特征金字塔时都是使用自上而下或者自底而上的路径来传递特征,这个过程会导致信息的丢失,因此他们提出了平衡特征金字塔(BFP, balanced feature pyramid),以同等重视多尺度特征图。它通过缩放、整合、精炼和增强4个步骤来获得相对平衡地兼顾所有特征层的特征图。
2 面向Logo检测的YOLOv4算法的改进
2.1 改进的Mosaic数据增强方法
原始的Mosaic数据增强方法对四张原始图像进行翻转、缩放、色域变换和拼接,从而形成包含4幅原始图像的合成图像。为了进一步丰富Logo对象的背景,提高模型在复杂背景下检测Logo的鲁棒性,同时提高训练效率,本文提出改进的Mosaic数据增强方法,如图2所示。为了便于阐述,将单张原始图像记为mos1,由4张、6张图像混合而成的合成图像分别记为mos4和mos6。上面和中间的实线箭头表示的通道是原始的Mosaic方法,然而改进的Mosaic数据增强方法增加了下面虚线箭头表示的通道,即使用6张图像拼接成的合成图像(mos6)作为模型的训练数据,与mos1和mos4一起作为模型的训练输入。
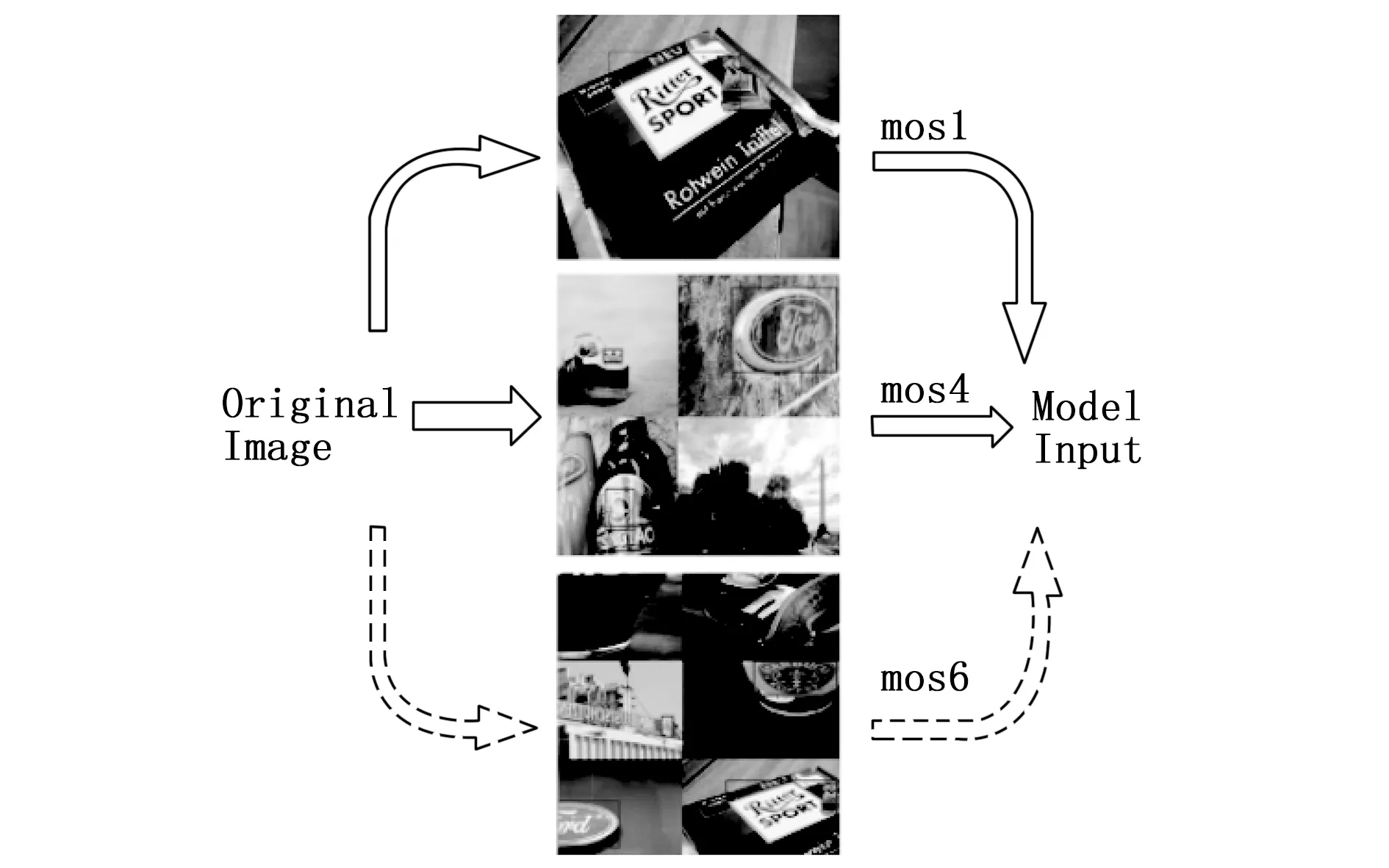
图2 改进的Mosaic数据增强方法
2.1.1 由6张原始图像合成训练数据
1)生成图像随机缩放的大小、随机粘贴的位置和裁剪的范围。
首先按公式(1)生成6张图像分别缩放的随机值:
nws=[int(w*rand(0.4,1)),int(w*rand(0.4,1)),
int(w*rand(0.4,1)),int(w*rand(0.4,1)),
int(w*rand(0.4,1)),int(w*rand(0.4,1))]
nhs=[int(h*rand(0.4,0.8)),int(h*rand(0.4,0.8)),
int(h*rand(0.4,0.8)),int(h*rand(0.4,0.8)),
int(h*rand(0.4,0.8)),int(h*rand(0.4,0.8))]
(1)
式中,rand()函数以均匀分布从一定范围内取出随机值,int()函数是对小数进行四舍五入的操作,(w,h)表示网络要求输入的高和宽。nws和nhs中都包含了6个元素,依次对应6张图像随机缩放之后的宽和高。
其次要生成分别沿x方向的一个偏移比例和y方向的两个偏移比例,计算方法如公式(2)所示:
offset_x=rand(1/4,3/4)
offset_y1=rand(2/9,4/9)
offset_y2=rand(5/9,7/9)
(2)
接着按照公式(3)生成6张图片的粘贴位置:
place_x=[int(w*offset_x)-nws[0],
int(w*offset_x)-nws[1],
int(w*offset_x)-nws[2],int(w*offset_x),
int(w*offset_x),int(w*offset_x)]
place_y=[int(h*offset_y1)-nhs[0],
int(h*offset_y2)-nhs[1],
int(h*offset_y2),int(h*offset_y2),
int(h*offset_y2)-nhs[4],
int(h*offset_y1)-nhs[5]]
(3)
式中,place_x和place_y分别都包含了6个元素,分别对应6张图片随机粘贴的横坐标和纵坐标。
最后,利用偏移比例按照公式(4)计算出图像裁剪的界限:
cutx=int(w*offset_x)
cuty1=int(h*offset_y1)
cuty2=int(h*offset_y2)
(4)
式中,cutx是x方向的裁剪界限,cuty1和cuty2是y方向的两条裁剪界限。利用3条界限分别裁剪出6张图像的相应部分并拼接在一起,从而构成一张新的图像。
2)按照索引从训练集中选取一条训练数据,然后随机选取5条训练数据,共获得6条数据。
3)分别对每一张训练图像进行一系列基本的数据增强。以0.5的概率对图像进行左右翻转,按照公式(1)对图像进行高和宽的随机缩放。
4)6张图像按照公式(3)各自粘贴到一张像素值为(128,128,128),大小为[416,416]的图像上的指定位置。得到的6张图像如图3所示。

图3 6张图像的随机粘贴位置
5)按照公式依次裁取6张图像中的指定区域拼接成一张新的图像。再对合成图像色度(hue)、饱和度(sat)和明度(val)进行扭曲, 扭曲系数分别是hue=0.1,sat=1.5,val=1.5。生成的训练数据及标注情况如图4所示。

图4 合成图像及标注信息
2.1.2 确定相对更优的输入比例
在网络训练过程中mos1、mos4和mos6这3种形式的输入所占的比例记为,这种组合在一定程度上使训练数据集的尺度变化特征更加多样化,从而进一步衰减背景对目标特征的干扰。在本文中通过枚举的方法来获得三者相对更优的输入比例。
2.1.3 改进的Mosaic训练策略
使用Mosaic合成的训练图片,远远脱离了自然图片的真实分布,即Mosaic合成的图片与自然图片存在较大的语义鸿沟。同时,Mosaic数据增强过程中存在大量的裁剪操作会带来很多不准确的标注框。因此,本文对YOLOv4中Mosaic训练策略进行了改进。在训练结束前的30个世代关闭Mosaic数据增强,即只使用数据集中单张原始图像来训练模型。这样训练策略下数据集更专注于原始图片,使得模型能很好地学习到目标的总体特征,在此基础上,用Mosaic数据增强合成的图像拥有更加复杂的背景,用来增强模型对局部特征的学习能力,从而提高整个模型的泛化能力。
2.2 改进的多尺度特征融合
在YOLOv4中,当输入图像大小为416*416时,骨干网络从输入图像中提取出3个层次的有效特征层C1,C2和C3。为了让整个模型学习到更加多样化的特征,提高模型的检测性能,目标检测网络的特征融合部分对不同层级的特征做进一步的增强和融合。本文对YOLOv4中的PANet部分进行改进。改进主要包括了跨层连接、重复堆叠、直接连接和加权特征融合4个方面。在本文所有的实验中,当两个或多个特征进行融合的时候,采用的是元素对位相加(element-wise add)的方式,而不是特征图堆叠(concat)的方式。
2.2.1 跨层连接
在图5(a)PANet的基础上,首先去除了未经过特征融合的即只有一个输入的节点,即P3和P1,因为未经过特征融合的特征图对多尺度预测的贡献较小。其次在同一尺度的输入特征图和输出特征图之间增加一条新的连接,以融合更丰富的特征,称为跨层连接,最终的网络结构如图5(b)所示,图中的短划线表示引入的跨层连接。
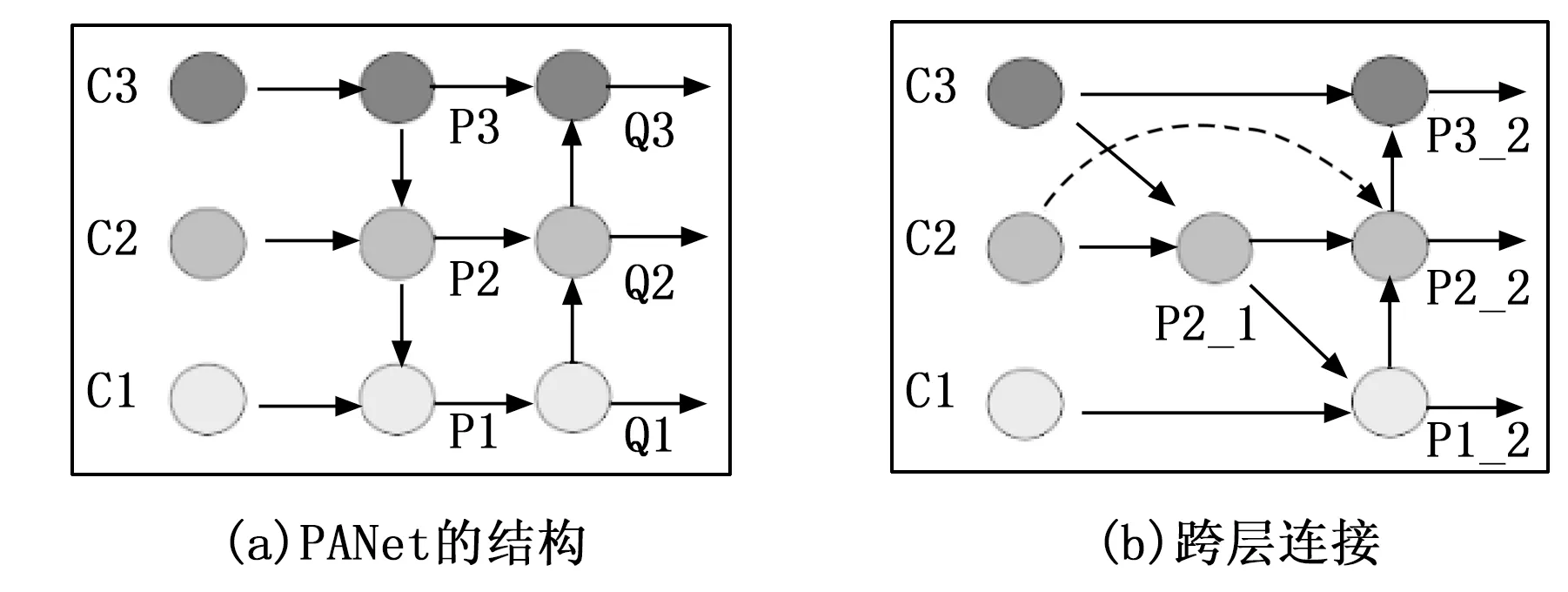
图5 PANet和跨层连接的结构
以特征图P2_1为例,使用跨层连接之后,特征图P2_1的计算方法如公式(5)所示:
P2_1=C2+upSample(C3)
(5)
式中,upSample()是上采样函数,实验中使用缩放因子为2的最近邻上采样。
特征图P2_2的计算方法如公式(6)所示:
P2_2=C2+P2_1+downSample(P1_2)
(6)
式中,downSample()是下采样函数,在实验中使用步长为2的卷积进行下采样。
2.2.2 重复堆叠
为了进行充分的加强特征提取,在Neck部分将设计的特征金字塔结构多次堆叠。如图6所示,将设计的跨层连接结构重复堆叠了3次,以获得更有效的特征融合和特征表达。
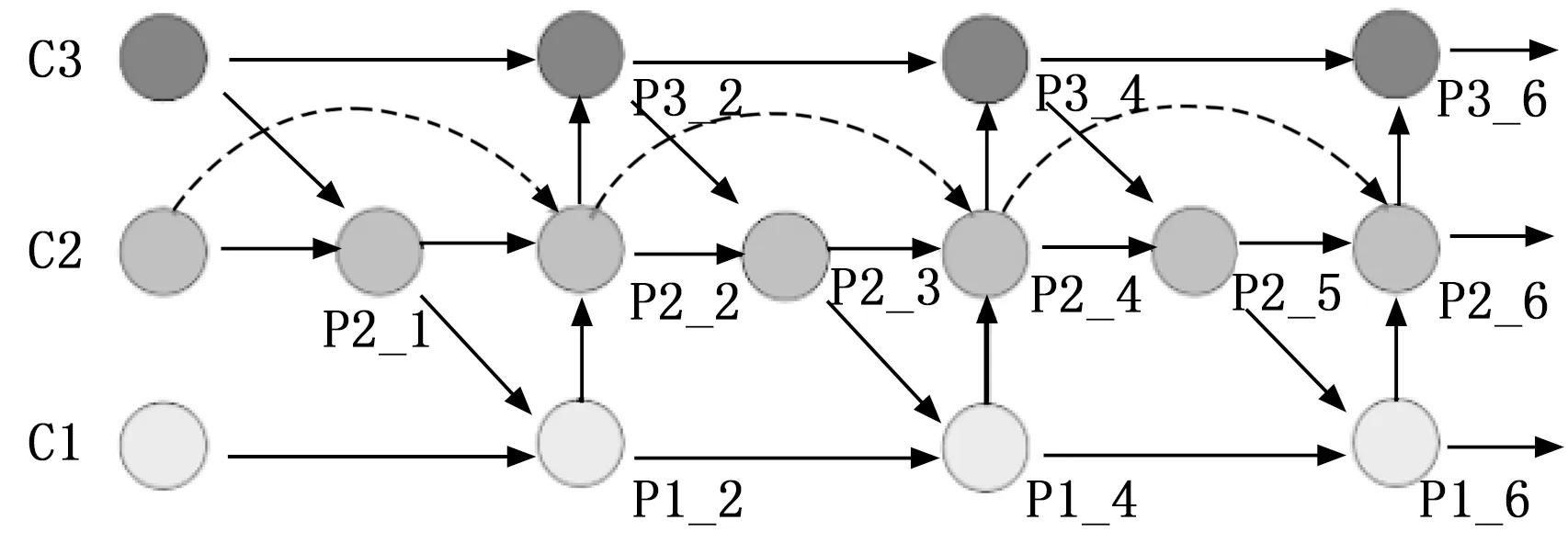
图6 重复堆叠后的网络
2.2.3 直接连接
针对卷积过程中小对象容易丢失的问题,在特征融合网络中设计了信息直接连接层。在跨尺度连接特征融合金字塔的每个迭代输出节点中,我们使用信息直接连接层与初始输入特征图进行特征融合,使小目标特征信息在特征提取过程中保持完整,如图7所示。图中的6条点划线表示6处直接连接。

图7 使用直接连接之后的网络结构
以特征图P2_4为例,使用信息直接连接之后,特征图P2_4的输出为:
P2_4=C2+P2_2+P2_3+downSample(P1_4)
(7)
2.2.4 加权特征融合
当融合具有不同分辨率的特征时,常见的方法是先将它们的大小调整为相同的分辨率,然后直接再对其求和。在PANet中,网络均等地对待所有输入特征,而不同的输入特征具有不同的分辨率,它们对输出特征的贡献通常是不相等的。为了解决这个问题,为每个输入添加额外的权重,并让网络学习每个输入特征的重要性。采用快速归一化融合[20]的方法来进行加权特征融合,它的计算方法如公式(8)所示:
(8)
式中,O是输出特征,Ii是要第i个要融合的特征,wi是第i个要融合特征的权重,在每个wi后应用ReLU激活函数来确保wi大于0。以及ε设置为0.000 1是为了避免数值不稳定。网络在训练的过程中能够学习到对于各个输入特征的权重,从而实现有侧重地进行特征融合。
以特征图P2_4为例,使用加权特征融合之后,特征图P2_4的输出为:
(9)
2.3 改进的YOLOv4算法整体框架
最终,本文将提出的算法称为MP-YOLOv4,MP-YOLOv4算法的整体框架如图8所示。首先,使用改进的Mosaic数据增强算法为模型提供单张原始图像、4张图片拼接成的合成图像和6张图片拼接成的合成图像共3种形式的训练输入数据;其次由Backbone从输入图像中提取特征并获得3个初步的有效特征层用于构建特征金字塔;然后使用改进的路径整合网络PANet来进行多尺度特征增强和融合;最后使用YoloHead得出预测结果。

图8 MP-YOLOv4的整体框架
3 实验验证和分析
3.1 实验设置
本文实验的硬件环境为:处理器为Inter(R)Xeon(R)CPU E5-2640 v4 @2.4 GHz,显卡为NVIDIA 1080Ti(11G)。网络训练阶段的软件开发环境为:操作系统是64位CentOS Linux 7;驱动版本是460.80;CUDA版本是11.2;深度学习框架是Pytorch1.4.0;编程语言是Python3.7。关于目标检测模型训练过程中,网络参数的设置为:使用在COCO数据集上训练获得的YOLOv4整体网络的预训练权重;网络输入图像的高和宽是416和416;总共训练100个世代(epoch);YOLOv4网络训练分为两个阶段,冻结训练阶段网络的主干部分被冻结,特征提取网络的参数不发生改变,解冻训练阶段整个网络的参数都会发生改变;冻结训练阶段的batch_size设置为8,解冻训练阶段的batch_size设置为4;冻结训练阶段初始学习率为10-3,解冻训练阶段的初始学习率设置为10-4,学习率策略使用余弦退火学习率;使用多线程读取数据,num_workers设置为4;使用Adam优化算法。
3.2 实验数据集
FlickrLogos-32数据集[21]由从Flickr官网上收集的真实世界的图像组成,共包含了32种Logo。整个数据集被分割为3个不相交的子集P1、P2和P3。第P1是训练集,由每个类10张人工精心挑选的图像组成,这些图像中仅包含单个Logo,且背景干扰较少。另外P2(验证集)和P3(测试集)每个类包含30张图像。与P1不同的是,这些图像包含了一个或多个Logo实例,且实例的背景更复杂。
3.3 评价指标
在本文中使用COCO评价指标,包括AP、AP50、AP75、APS、APM和APL。其中AP为0.50到0.95之间10个不同IOU设置下平均准确率的平均值;AP50为IOU等于0.5时所有类别上的平均准确度;AP75指标更加严格,表示IOU等于0.75时所有类别上的平均准确度;APS、APM和APL分别描述模型在小目标、中目标和大目标上的准确度。使用模型大小(model size)来评估模型所占的内存空间。
3.4 实验过程
3.4.1 验证改进的Mosaic数据增强方法
本节将首先确定相对较好的比例设置,其次验证提前30个epoch终止训练的有效性。
在不同比例设置下的YOLOv4模型上的实验结果如表1所示。

表1 不同比例设置下的模型性能
实验M1(1∶0∶0)中仅使用mos1图像训练,实验M2(1∶1∶0)中均等地使用mos1和mos4图像训练,这是原始YOLOv4算法中的设置,实验M3(1∶0∶1)中均等地使用mos1和mos6图像训练,对比这3个实验可以发现,M2和M3都可以提升模型的性能,且M2的提升要相对更明显;值得注意的是,M3虽在其他指标上不如M2,但是M3(使用了mos6数据)提高了模型在小目标(APS)检测方面的性能。实验M4(1∶1∶1)中均等地使用mos1、mos4和mos6数据进行训练,比M2和M3的效果都要好。这证明了在原始Mosaic基础上,添加mos6数据进行训练能够改善模型性能。
为了验证数据集应该更侧重于mos1、mos4和mos6中的哪一种,开展了实验M5(2∶1∶1),M6(1∶2∶1),M7(1∶1∶2),与实验M4(1∶1∶1)分别进行对比,可以得出结论,当使用比例1∶1∶2,即当数据集更侧重本文提出的mos6数据时,模型在牺牲很少APM的情况下,在其他指标上的性能都获得了大幅度提升。因此,选择1∶1∶2这个相对来说最优的比例作为模型训练过程中的输入设置,即有0.25的概率输入mos1数据,同样有0.25的概率输入mos4数据,有0.5的概率输入本文提出的mos6数据。
为了验证提出的Mosaic训练策略的有效性,即在训练结束的前30个epoch关闭Mosaic数据增强技术是否能够提升模型的性能,在两种情况下分别进行了实验,实验结果如表2所示。2∶2∶1(w)表示使用提出的训练策略,2∶2∶1(wo)表示不使用。通过实验结果可以得出结论,在损失很小AP50和APM的条件下,其他指标获得了较大幅度的提升。因此,本文提出的提前终止Mosaic数据增强的训练策略是有效的。

表2 是否使用训练策略的对比实验结果
3.4.2 验证改进的PANet
为了验证改进的Neck中跨层连接(①)、反复堆叠(②)、直接连接(③)和加权特征融合(④)4个方面分别对于网络的有效性,下面对改进了Neck进行了消融实验分析。实验结果如表所示。实验BL是基线实验,未使用任何一个改进,实验N1使用了跨层连接(①),实验N2在N1基础上多次堆叠了特征金字塔模块(②),实验N3进一步引入了跨层连接(③),实验N4在N3的基础上引入了加权特征融合(④)。通过分析表3发现,依次引入每一个改进都在一定程度上改善了模型性能。同时引入以上4个方面的改进,在减少21.7%模型大小的同时,在所有指标上的精度都获得了提升,平均精度(AP)提高了0.8%,IOU等于0.5时的平均精度(AP50)提高了1.2%。

表3 特征融合实验
3.4.3 总体实验
为了验证文中提出MP-YOLOv4目标检测算法的有效性,在FlickrLogos-32数据集上对YOLOv4算法和MP-YOLOv4算法进行了训练和测试,并与YOLOv3、SSD[22]和Faster R-CNN等经典的目标检测算法进行对比实验。实验结果如表4所示。与YOLOv4相比,本文提出的MP-YOLOv4方法在IOU等于0.5时的平均精度值(AP50)达到了67.4,AP50提高了2.4%,模型大小减小了21.7%。
与YOLOv3、以VGG为骨干的Faster R-CNN和以Resnet50为骨干的Faster R-CNN以及SSD相比,本文提出的MP-YOLOv4算法在精度方面达到了最高,同时在模型大小方面也达到了可观的水平,因此在模型大小和模型精度之间获得了一个较好的平衡。
3.4.4 消融实验
为了分别验证文中提出的改进的Mosaic数据增强方法和改进的PANet的有效性,开展了以下的消融实验。在基线实验T1中未采用本文提出的任何一个改进,在实验T2中仅采用了改进的Mosaic(IM,improved mosaic),设置3种输入的比例为1∶1∶2,在实验T3中仅采用了改进的特征融合部分(IP,improved PANet),在实验T4中同时采用了本文提出的两个改进。实验结果如表5所示。通过分析表5可以得出结论,引入两个改进中的任意一个都在一定程度上提高模型在所有指标上的性能,同时引入这两个改进,能在最大程度上提升模型性能。
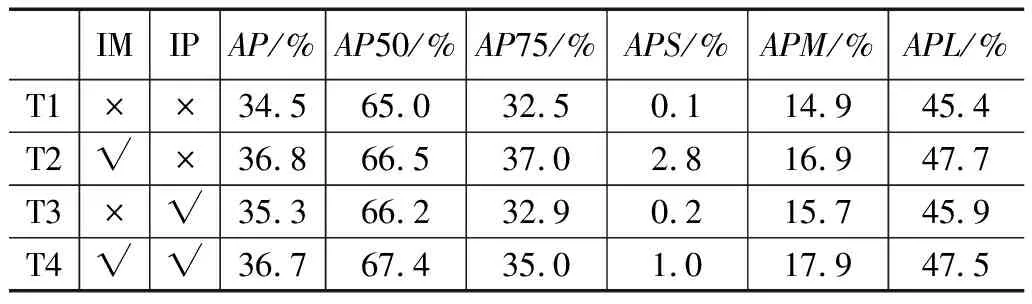
表5 消融实验研究
通过表4可以得出结论,本文提出的MP-YOLOv4算法在平均精度(AP)上达到了36.7%,较YOLOv4提高了2.2个百分点,IOU等于0.5时的平均精度(AP50)达到了67.4%,较YOLOv4提高了2.4个百分点。同时在APS、APM和APL等指标上均有提高,说明MP-YOLOv4算法相比于YOLOv4在多尺度检测问题方面的性能得到了改善。
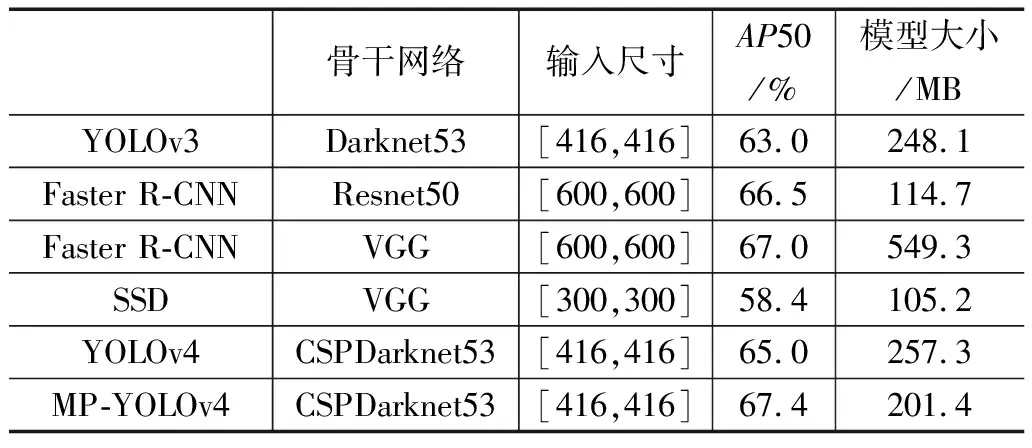
表4 YOLOv4和MP-YOLOv4的对比实验结果
3.4.5 可视化研究
除了定量的实验结果之外,图9展示了YOLOv4算法和MP-YOLOv4算法对于FlickrLogo-32数据集中一些有挑战性样本的检测结果。其中图(a)、(b)、(c)为YOLOv4 网络的检测结果,图(d)、(e)、(f)为MP-YOLOv4算法的检测结果。从图中可以得出结论,本文提出的MP-YOLOv4算法对于小尺寸目标、密集目标和光照条件差等条件下有着更好的检测性能,存在更少漏检和误检等情况。

图9 YOLOv4和MP-YOLOv4的检测效果对比
4 结束语
针对Logo检测任务中出现的复杂背景干扰和多尺度目标等问题,本文提出了一种改进目标检测算法MP-YOLOv4。改进了YOLOv4中的Mosaic数据增强算法,提出使用6张图片混合、四张图片混合和单张图片3种形式来共同作为模型的训练输入,并确定了3种输入的相对最优比例,同时采用了在训练结束前30个epoch关闭Mosaic数据增强方法训练策略,改进的Mosaic方法丰富了Logo对象出现的背景,使得模型更好地学习到Logo对象的全局特征和局部特征,并优化了模型训练。结合跨层连接、重复堆叠、直接相连和加权特征融合等操作重新设计了网络的加强特征融合部分,增强了网络的多尺度特征表达能力。实验结果表明,相较于YOLOv4算法,本文提出的方法压缩了21.7%的模型大小,在平均精度上提高了2.2个百分点,在IOU等于0.5时的平均精度提高了2.4个百分点。同时,在小、中和大目标检测方面的性能都有提升。这说明,本文提出的MP-YOLOv4算法能更好地解决Logo检测任务中的复杂背景和多尺度问题。
猜你喜欢
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
小学生学习指导(低年级)(2021年12期)2021-12-31
成都信息工程大学学报(2021年3期)2021-11-22
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
阅读与作文(英语初中版)(2019年8期)2019-08-27
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
小学生学习指导(低年级)(2018年11期)2018-12-03
小学生学习指导(低年级)(2018年11期)2018-12-03
