
基于GRA-GA-BP神经网络的港口集装箱吞吐量预测模型
2022-10-28 07:47于少强周钰博肖长凯林宇玲
物流技术 2022年9期
于少强,周钰博,陈 康,肖长凯,林宇玲
(大连海事大学 航运经济与管理学院,辽宁 大连 116026)
0 引言
集装箱运输相较于传统的杂货运输方式有着能保障货物运输安全、提高装卸作业效率、便于自动化管理等优势,可大幅提高港口作业的工作效率及经济效益,已成为国际贸易运输的主要形式。而集装箱吞吐量作为衡量各港口发展状况的关键指标,是港口发展状态分析与相关政策制定的重要参考依据。鉴于“十四五规划”中我国集装箱港口群已经被赋予了推动“一带一路”高质量发展的艰巨使命,精确预测港口吞吐量,进而分析和把握我国港口群的发展态势,挖掘存在的问题和机遇便显得尤为重要。
然而,集装箱港口的吞吐量预测并不容易,其受国家政策、自然天气、科技水平等多种因素的影响,具有显著的随机性和不确定性。因而港口吞吐量预测也是港航领域学术界讨论的热点之一。目前学术界基于港口集装箱吞吐量预测提出的方法较为丰富,主要有时间序列法、灰色预测法、神经网络法等。孔琳琳,等基于时间序列分析建立模型,借助R软件预测了某港口十个月的集装箱吞吐量数据。Javed考虑到季节变化对吞吐量的影响,建立SARIMA模型为港口吞吐量的短期预测提供了一种思路。刘宇璐,等运用ARIMA模型,对武汉港货物吞吐量做出预测及规律分析。而在运用灰色预测模型方面,严雪晴基于灰色理论,利用GM(1,1)模型对广东省货运总量发展趋势提供了参考;刘连花,等利用港口三个货运指标,反映了新冠疫情对广州港货运增长的影响程度;杜泊松,等引入无偏灰色预测理论对传统GM(1,1)模型进行优化,并用马尔可夫理论对模型预测残差值进行修正,为预测货物吞吐量提供了新方法。杨金花运用灰色预测法预测上海港未来3年的集装箱吞吐量。近年来很多学者利用神经网络具有高度自组织、自学习、泛化能力强等优点,结合历史数据对港口吞吐量进行预测:刘长俭,等采用逐步递归的方法,运用神经网络对集装箱吞吐量的预测提供了一种方法。李广儒,等引入宁波舟山港的数据,结合Elman网络证实了模型的有效性。程文忠,等运用支持向量机(SVM)理论,对九江港货物吞吐量进行预测,验证了模型的可行性。Huang,等提出了基于人工蜂群(ABC)优化BP神经网络的港口吞吐量预测模型。除此之外,组合模型、指数平滑法等方法在港口吞吐量预测方面也发挥了重要作用。这些方法从各种角度为港口的吞吐量预测提供了思路,但各自也有一定的局限性。
具体而言,灰色分析预测法使用的是生成的数据序列,适合近似指数增长的预测,不适用于长期预测。而时间序列法强调历史数据,当外界环境发生变化时对预测结果影响较大。组合模型法中各方法被主观赋予的不同权重数值会使预测结果产生较大偏差。针对以上不足,神经网络预测法是一种具有显著潜在优势的选择。但是在传统的神经网络中,用于网络训练的输入变量的选取往往是基于个人经验,各输入变量之间可能存在较大的耦合性,影响模型训练效果;单纯应用神经网络会导致其收敛陷入局部最优,降低训练速率,影响预测精度。
针对上述不足,本文将基于既有的研究成果,提出一种基于GRA-GA-BP神经网络的港口集装箱吞吐量预测模型。对于复杂多样的集装箱吞吐量的影响因素群,首先利用灰色关联度分析法进行筛选及排序,选取关键影响因素作为输入变量赋给GA-BP神经网络模型进行训练和测试。遗传算法是一种具有全局搜索能力、搜索效率高的搜索算法,独特的编码方式使其可以进行多种数据处理,在交通运输领域应用普遍且广泛。利用遗传算法改进BP神经网络建立预测模型,能够优化网络的初始权值与阈值,使模型预测准确度得到有效提高,避免陷入局部极值,提升运算效率。最终利用环渤海港口群中核心港口2001-2019年的集装箱吞吐量数据作为训练样本横向对比传统BP神经网络模型、GA-BP神经网络模型和优化后的GRA-GA-BP神经网络模型,预测结果表明,与前两种模型相比,GRA-GA-BP神经网络模型预测准确度更高。
1 GRA-GA优化的BP神经网络
针对集装箱吞吐量易受多种因素影响的特点,运用灰色关联分析法处理数据灵活、能显示对象间动态关联程度的优势,对港口集装箱吞吐量及其影响因素进行分析,筛选出影响吞吐量变化的主要关联因素。然后将这些因素作为遗传算法优化BP神经网络的输入神经元,从而建立集装箱吞吐量的预测模型。
1.1 灰色关联分析
灰色关联分析(GRA,Grey Relational Analysis)是一种能显示事物动态联系程度的分析方法,其步骤如下:
步骤1确定y(t)(t=1,2,...,l)为反映系统特征的母序列,x(t),x(t),…,x(t)为影响系统特征的子序列。
步骤2对子、母序列进行标准化处理,消除量纲对各数列的影响。得到̂()、̂()、̂()、…、̂()。
步骤3计算子数列与母序列的关联系数:
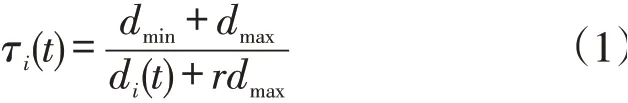

步骤4计算关联度并排序:

其中0≤R≤1,R越接近1,y(t)与x(t)的关联性越强,计算出结果后按n个数列排序,x(t)排名越高,与y(t)关联越强。
1 .2 GRA-GA-BP神经网络模型概述
BP神经 网 络(BPNN,Back Propagation Neural Network)是模仿人类神经元激活、传递过程的神经网络,具有自学习和自适应能力、能进行分布存储、可以并行处理信息等特点,具有很强的非线性映射能力,因此可作为多因素影响前提下的理想预测工具。其工作流程如图1所示。遗传算法的基本思想来源于达尔文的生物进化论,通过自然选择、交叉、变异以及迭代等步骤,最终选出最优表征个体及其体内的基因编码。相比于传统的优化方法,遗传算法在多参数探优过程中有着出色的启发式搜索能力。遗传算法对BP神经网络输出层间的连接权值和隐含层的阈值进行优化,最后进行网络输出,具体流程如图2所示。

图1 BP神经网络流程图
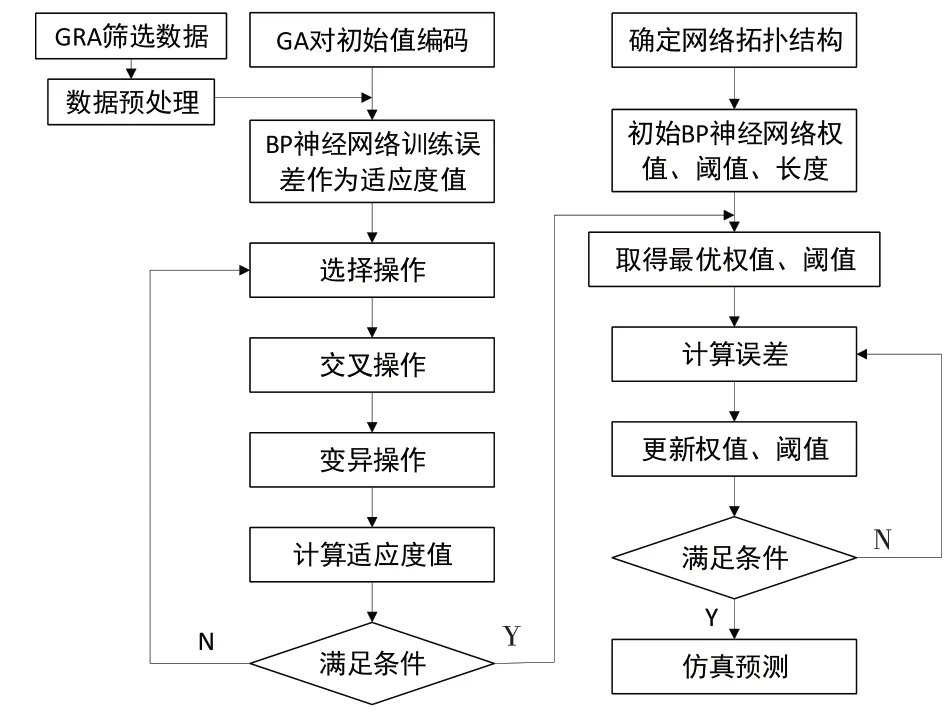
图2 GRA-GA-BP模型流程图
步骤1种群初始化。确定初始种群数量、最大迭代次数、期望输出最大误差、染色体的范围等参数。每个个体包含输入层和隐含层的连接权值、隐含层的阈值、隐含层和输出层的连接权值及输出层的阈值。
步骤2确定适应度函数。用训练样本数据训练BP神经网络后,计算个体适应度值。计算公式为:
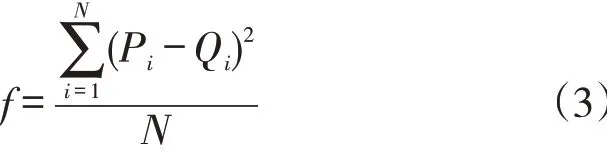
式(3)中,N为训练数据个数;P、Q分别为集装箱吞吐量的实测输出值和预测输出值。
步骤3选择操作。采用轮盘赌法进行选择,复制当前种群适应度高的染色体,以此生长出新的种群,每个个体i被选择的概率为:

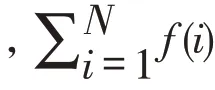
步骤4交叉操作。用实数编码法对选中的成对个体,交换它们之中的部分染色体以产生新的个体。其中第x个染色体a与第y个染色体a在第j点的概率公式为:
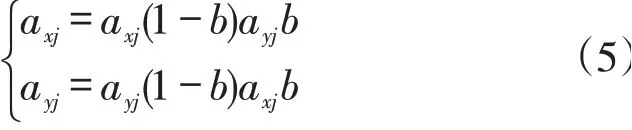
式(5)中,b是[0,1]之间的随机数。
步骤5变异操作。对被选中的个体,以自适应遗传算法得出的概率将某些基因染色体值进行重新编译,得到全新个体。
步骤6赋值并训练神经网络。更换为新染色体后重新计算个体适应度,若迭代次数在规定范围内,将最优个体中的权值和阈值赋予BP神经网络进行自我训练直至误差达到预期设定值,否则回到步骤2继续训练,得到新的适应度。
2 集装箱吞吐量预测实例分析
2.1 输入、输出变量的确定
随着海上贸易量不断走高,我国逐渐形成了五大港口群,其中环渤海港口群作为北部沿海地区贸易运输的支点,也是我国沿海规模最大的港口群,对北方经济发展有着举足轻重的作用。近年来随着中国开放型经济的发展,环渤海港口群技术迭代不断加强,集装箱吞吐量不断走高,已经成为我国北部经济发展的先锋。环渤海港口群中,沿线亿吨级大港包括青岛港、大连港、天津港等,这些大港的经营状况很大程度上能体现环渤海港口群的运行状态。对环渤海港口群的三大代表港口及直接腹地城市产生影响的各项因素进行分析,结合已有文献研究,从综合政策环境、经济发展、社会民生、港口集疏运能力等角度考虑,选取以下因素作为预测模型的输入变量:全市生产总值(X)、全市社会商品零售额(X)、全市规模以上固定资产投资总额(X)、外贸进出口额(X)、第一产业产值(X)、第二产业产值(X)、第三产业产值(X)、全市居民人均可支配收入(X)、全市城乡居民年末储蓄余额(X)、全市水路货物运输量(X)、全市总人口数(X)、全市本专科生人数(X),选取集装箱吞吐量(Y)作为输出变量,数据来源于国家统计网站、各港口城市统计年鉴、《中国港口年鉴》,少量缺失数据由插值法结合相关新闻报道加以填补。部分年份具体数据见表1。

表1 部分年份输入变量基础数据
利用灰色关联分析法对选取的12个输入变量按照灰色关联度的大小进行筛选和排序,得到影响Y程度较大的因素,将其作为GA-BP模型的输入变量,具体步骤为:
步骤1为消除量纲对分析的影响,归一化输入变量。设分辨系数r为0.5,利用matlab软件编写灰色关联度计算程序,计算X与Y的关联度值,见表2。

表2 Xi与Y1的关联度
步骤2根据表2,按照关联度的大小对X至X进行排序。
步骤3由灰色关联度计算结果可知,X,X,X,X,X,X,X,X对Y影响较大,将它们作为输入变量赋予GA-BP神经网络模型进行训练和测试。
2.2 GA-BP神经网络参数设置
将X,X,X,X,X,X,X,X作为输入变量,将Y作为输出变量,建立GA-BP模型,设置网络输入层单元数为8,输出层单元数为1,隐含层的神经单元数L一般由经验公式获得:

式(6)中,m为输入层中的神经单元数,n为输出层中的神经单元数,a为1至10之间的任意常数。由多次实验比较结果可知,当L取8时预测精度和网络收敛效率较高。网络拓扑结构为8-6-1,权值个数设置为6×8+6×1=54个,阈值个数为6+1=7个。在遗传算法中基因编码长度设置为54+7=61个,迭代次数设置为50,种群规模为20,交叉概率为0.2,变异概率为0.1。神经网络设置最大训练次数为1 000,模型训练误差为1×10,学习率为0.01。完成网络结构设置后,利用matlab R2021a实现网络的自我训练与预测,选用2001-2015年三大港口及其腹地城市数据作为训练样本数据,2016-2019年作为测试样本数据。
2.3 预测结果及分析
利用2001-2015年的数据,为证明GRA-GA-BP模型预测结果的准确性,分别对传统BP网 络、GA-BP网 络、GRA-GA-BP网络三种模型进行训练,再利用训练后的模型对2016-2019年的集装箱吞吐量进行预测。设置三种模型的隐含层神经元数和主要参数均相同,利用matlab软件对数据进行分析和计算,分别得到预测结果和预测相对误差,见表3。
由表3可知,GRA-GA-BP神经网络模型相比于未改进的传统BP神经网络模型与GA-BP神经网络模型,在预测港口集装箱吞吐量的效果上表现更好,预测的相对误差区间范围明显小于另外两种模型。再利用机器学习中评价预测精度常用的均方根误差(RMSE)、平均绝对误差(MAE)、平均相对误差(MAPE)测试三种模型,各项误差数据越小,代表预测精度高(见表4)。
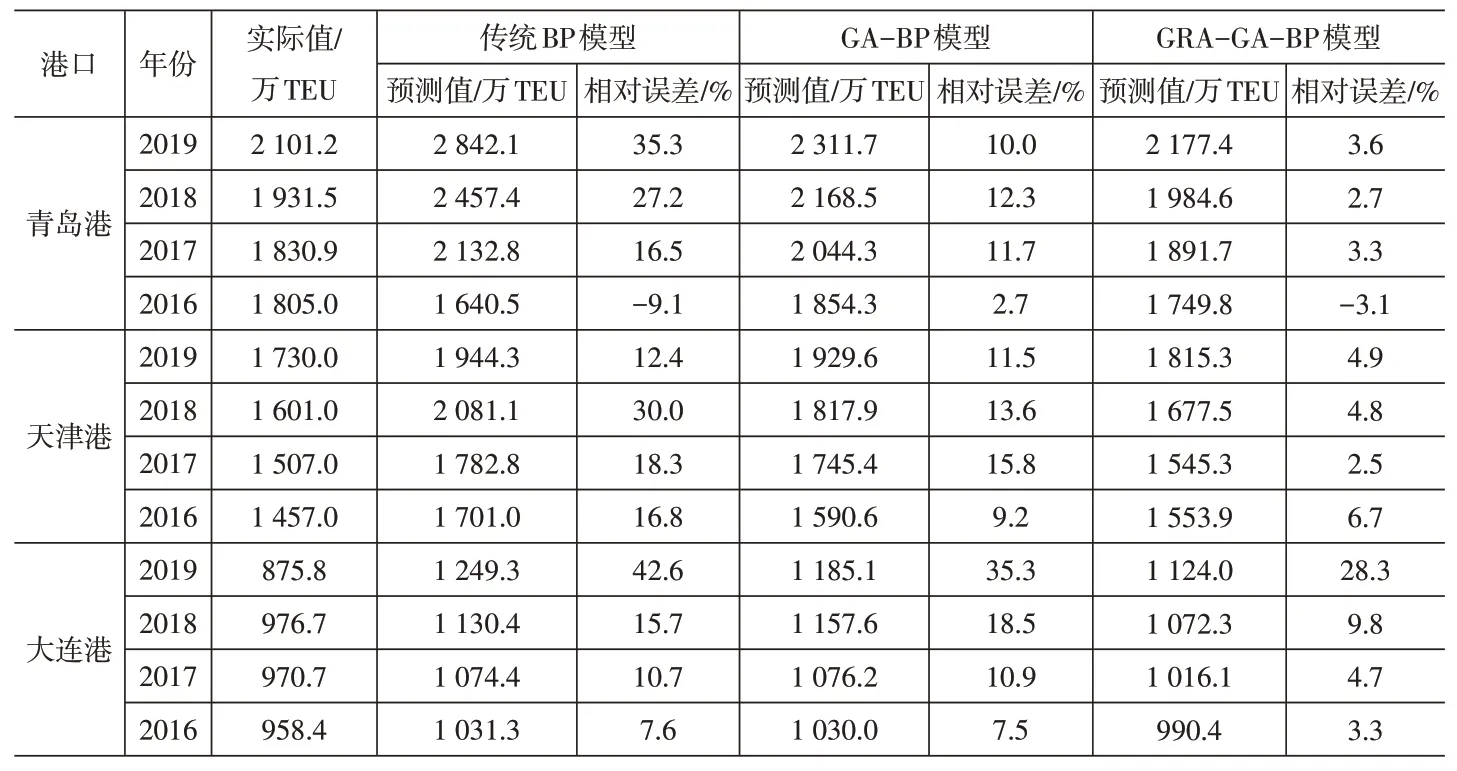
表3 三种模型的预测值及与实际值的相对误差
由表4可知,在其他参数设置相同的前提下,GRA-GA-BP模型的预测输出表现优于其他两种模型,说明在集装箱吞吐量预测方面,GRA-GA-BP模型相比传统BP模型及GA-BP模型具有更高的准确性。由此得出结论,采用以BP神经网络为中心,利用灰色关联分析筛选得出精简后的输入变量,利用遗传算法优化BP神经网络的初始权值及阈值参数的综合模型,是一种有效的港口集装箱吞吐量预测方法,不仅能提高模型预测精度,也能更好地筛选出影响集装箱吞吐量预测的因素,提高模型运算效率,节省模型运行时间。
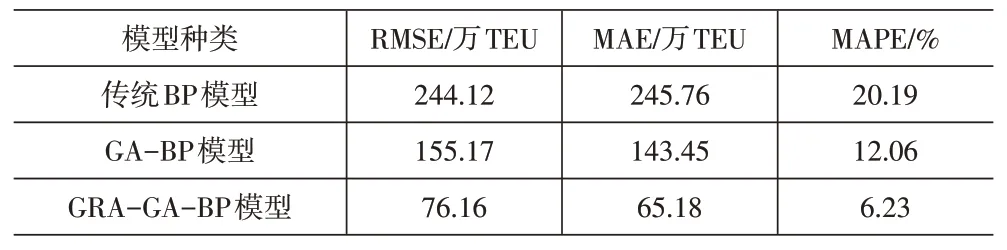
表4 三种模型的预测误差比较
3 结语
针对航运业集装箱吞吐量多影响因素为输入变量的非线性系统特点,将灰色关联度分析法、遗传算法和BP神经网络模型相结合,提出一种应用于预测港口集装箱吞吐量的GRA-GA-BP神经网络预测模型。为了确定对集装箱吞吐量有关键影响的因素,使模型输入变量的选取更准确有效,采用灰色关联度分析确定集装箱吞吐量的关键影响因素作为神经网络的输入变量;引入遗传算法作为优化BP神经网络初始权值和阈值的工具。从环渤海港口群中核心港口的预测实例可以得到以下结论:本文中提出的GRAGA-BP神经网络模型的预测值均高于传统BP模型与GA-BP模型,预测误差也均小于后两种模型,提高了预测精度,可以作为集装箱吞吐量关键指标预测的一种有效工具。
猜你喜欢
智富时代(2018年7期)2018-09-03
智富时代(2018年7期)2018-09-03
智富时代(2018年4期)2018-07-10
智富时代(2018年4期)2018-07-10
大陆桥视野·下(2017年12期)2017-11-29
科学家(2016年13期)2017-09-29
集装箱化(2017年4期)2017-05-17
Coco薇(2017年2期)2017-04-25
Coco薇(2017年2期)2017-04-25
集装箱化(2016年11期)2017-03-29
