
基于GPU的相位干涉仪FX鉴相算法
2022-10-29 08:25焦义文高泽夫杨文革毛飞龙
系统工程与电子技术 2022年11期
李 冬, 焦义文, 高泽夫, 杨文革, 毛飞龙, 滕 飞
(航天工程大学电子与光学工程系, 北京 101400)
0 引 言
相位干涉仪是无源定位方法中发展较为成熟的一种比相法测向体制,相位干涉仪的关键技术之一是鉴相算法。而在鉴相算法中, 频域互相关(简称为FX)鉴相法具有能够最大限度的抑制噪声能量、减小噪声相位对信号的干扰、鉴相精度高等显著优点。但在FX鉴相法中,涉及大量并行数据的处理与计算,尤其是算法中的快速傅里叶变换(fast Fourier transform, FFT)部分,其运算量尤为巨大,对如何实现大量高速并行数据的快速处理提出了较高要求。为满足测向系统高速实时性的要求,需要考虑采用协加速器对鉴相过程进行加速处理。
常见的相位干涉仪鉴相器使用现场可编程门阵列(field programmable gate array,FPGA)和数字信号处理器(digital signal processing, DSP),虽然其计算速度能够满足实时性要求,但存在以下局限性:一是FPGA和DSP开发周期长、升级难度大、程序调试困难;二是仅使用中央处理器(central processing unit, CPU)作为计算核心的信号处理机,受限于CPU时钟频率和内核数目,在处理实时数据时面临着系统资源消耗过多、性能下降等突出问题。
图形处理单元(graphic processing uint, GPU)由于具有众多的运算核心,特别适合进行大量数据的并行处理,特别是NVIDIA公司提出的计算统一设备架构(compute unified device architecture, CUDA)大大简化了基于GPU的系统架构设计与软件开发流程,使得GPU在通用计算领域得到了更为广泛的应用。针对前文分析的相位干涉仪在鉴相过程中并行运算多、实时性要求高等特点,采用 GPU 来进行核心鉴相算法的运行和处理是非常适合的。下文将对基于GPU 的相关技术进行具体研究。
前人基于GPU和CUDA架构,在信号处理领域取得了一定的研究成果。文献[22]中,王可东等针对FFT捕获算法的并行运算、处理数据量较大等特点和GPU平台特别适合于进行并行处理的优势,设计了FFT捕获算法的GPU实现方案,试验结果表明捕获结果完全正确,且捕获时间得到了大幅度缩短。文献[23]中,刘燕都等基于CUDA平台设计了混频器、鉴相器、滤波器等模块的并行程序,实现了二进制相移键控(binary phase shift keying, BPSK)的信号解调,测试结果表明,基于GPU的通用计算平台与专有硬件解调信号的指标相当,但通用计算机平台的实现方法更为灵活、易于功能扩展。文献[24]中,杨千禾为解决传统信号处理机在研发阶段调试困难、计算能力受硬件限制及程序复用性差等问题,提出使用GPU作为计算核心方案,将程序编写为并行代码,调用合适的GPU快速计算库,并通过相应的优化方法使优化后的GPU计算性能相比CPU提升了20~1 000倍。文献[25]中,谢维华等采用高性能并行CUDA编程方法,设计并实现了一种新的相关器算法,该算法处理1 ms多通道数据的相关运算平均时间小于0.5 ms,实现了多通道并行实时相关运算。文献[26]中,陈大强等提出了基于GPU的软件化警戒雷达,完成对警戒雷达信号处理算法从CPU平台到GPU平台的CUDA软件并行移植,很好解决了信号处理实时性、雷达软硬性解耦等问题。
基于上述研究成果和本文的实际需求,本文设计了一种基于GPU的相位干涉仪FX鉴相算法,完成了相应的并行程序设计,利用CPU进行数据调度、分发和逻辑控制,利用GPU进行大量信号数据的并行计算,并进行了实测验证。实验结果表明,在较好地保证鉴相精度的条件下,本文设计的基于GPU的鉴相系统数据处理速度可达CPU平台的140倍左右,鉴相速度得到了明显提升。
1 相位干涉仪测向原理研究
传统一维单基线相位干涉仪通过测量目标信号到达基线两端接收天线的几何时延差,计算来波方向角。图1中所示为传统的一维单基线相位干涉仪测向原理模型,阵元间的连线称为基线。

图1 传统单基线相位干涉仪测向模型Fig.1 Direction finding model of traditional single baseline phase interferometer
假设信号到达接收天线前的阵前波为平行波,则天线1和天线2接收到的信号分别为

(1)
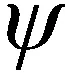
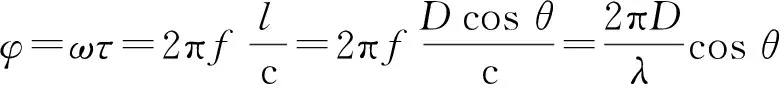
(2)
式中:为信号波长;为入射信号与视轴之间的夹角,即入射信号的俯仰角;c为光速,即信号传播的速度;为两个接收天线的间距,即基线长度。则对应的来波方向角为

(3)
实际工程应用中,由于物理因素限制,相位干涉仪鉴相器输出的测量相位差的范围是[-π,π],所以测量相位差是一个以2π为模糊的观测值,因此无模糊理论相位差和鉴相器测量相位差的关系满足:

(4)
式中:为相位模糊数。由式(2)和式(4)可得

(5)
对于多基线相位干涉仪接收同一入射信号时,假设有条基线,基线长度分别为,,…,,基线长度满足:
::…:=::…:
(6)
式中:(=1,2,…,)分别为互质正整数,在不存在相位差噪声干扰的情况下,任意两个基线的相位差满足:

(7)
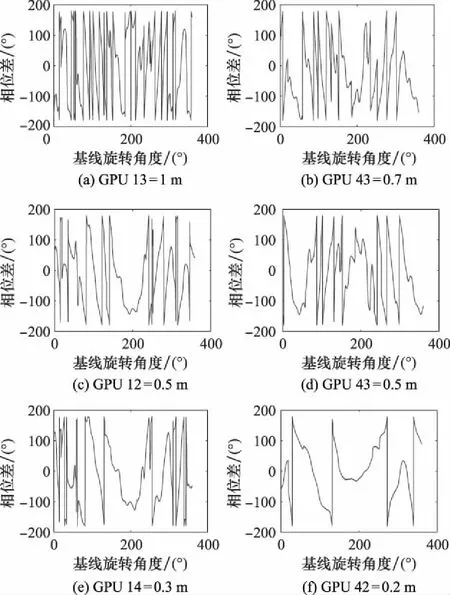
其中,,=1,2,…,。由式(7)可得,相位干涉仪不同长度基线的相位差不同,且基线越长相位模糊数越大,即鉴相器测量相位差在[-π,π]范围内翻折次数越多。
2 FX鉴相算法基本原理
以只有两个阵元的单基线干涉仪为例,传统的FX鉴相算法先将干涉仪接收到的两路信号(),()做FFT得到()和(),再求得其相关谱为

(8)
相关谱谱峰位置处的相位值即为两路信号的相位差:
=angle[()|=2π]
(9)
本系统是四阵元测向系统,算法的流程示意图如图2所示。由4个天线接收四路模拟信号,经过射频前端下变频处理后,再对信号分别进行离散化处理,得到四路数字信号,接下来数字信号进入鉴相系统中开始进行提相处理。
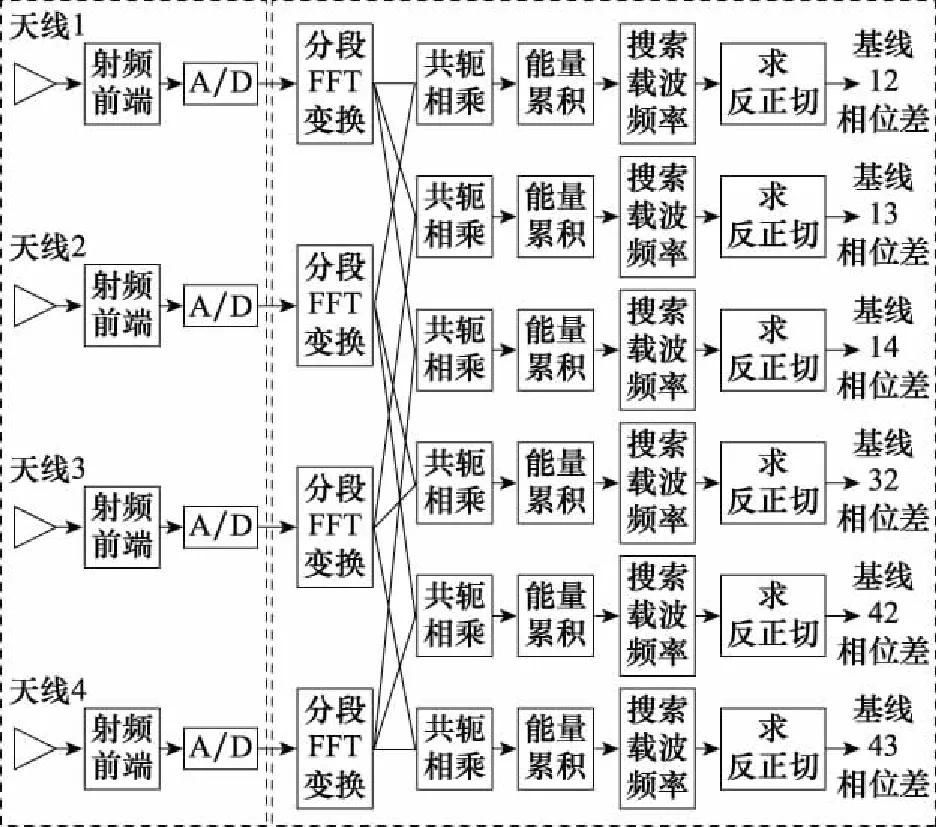
图2 四阵元相位干涉仪FX鉴相算法流程Fig.2 Flow of FX phase identification for four-array phase interferometer
首先对四路数字信号分别进行FFT,得到每路信号的频谱,再由每两路信号进行共轭相乘得到相关谱。受躁声的影响,由少数几个数据得到的结果可能不准确,因此需要多个样本平均以提高测向准确度,即能量累积。然后,在搜索到载波频率后利用反正切求出频谱最大值对应位置处的相位差信息,由此实现了四阵元相位干涉仪FX鉴相算法。
3 基于GPU的FX鉴相算法
本文设计的FX鉴相算法基于GPU+CPU异构处理平台开发,以CPU为控制器,GPU为协处理器,由于GPU采用并行处理的架构设计,使得其在进行大量并行数据处理时计算性能明显优于CPU。
3.1 本文算法相比于传统算法的主要改进
本文设计的基于GPU的FX鉴相算法,相比于传统基于CPU的算法,主要改进如下:
如图3所示, 利用GPU具有的众核优势,将本文面对的FX鉴相这一核心算法加载到基于CUDA架构的GPU中实现,运用CUDA流结构设计了高速并行的实时鉴相算法处理流程,通过调用GPU中足够多的线程和线程块,对于鉴相算法的各分模块(特别是FFT模块)进行了加速并行化处理,基于CUDA C语言编写了基于GPU的FX鉴相算法代码,在实测过程中通过调整GPU中的线程和线程块数目,实现最优的加速并行效果,最终完成了整个鉴相算法。

图3 基于GPU的FX鉴相算法在GPU中的线程调用情况Fig.3 GPU thread invocation of GPU-based FX phase identification algorithm
本算法通过将原本需要在CPU中实现的众多运算单元加载到GPU中,充分发挥了GPU的多线程并发处理的优势;通过设计GPU中的鉴相算法流程,有效调用了GPU中的运算资源,利用众多线程和线程块实现了各运算单元的高速处理,基本满足了实时化处理需求。
以本算法的核心且运算量最大的FFT模块为例,在进行FFT计算时可以将任意维数的矩阵数据分成若干层,其中层与层是串行的计算,每层计算的次数和点数都一样,所以具有良好的并行特性,因此使用具有高度并行性的GPU进行鉴相处理可以极大地提高数据处理速度。本文调用了GPU中的512个线程块,充分满足了FFT模块的运算量和实时性要求。并且不同于传统算法在CPU下先将实数转成复数再进行计算,GPU下的FFT计算通过cufftExecR2C(实数到复数)直接输出复数结果,因此极大地提高了算法运行效率。
3.2 基于GPU的FX鉴相算法的主要流程
基于GPU的FX鉴相算法实现流程如图4所示。

图4 基于GPU的FX鉴相算法实现流程Fig.4 Implementation process of FX phase identification based on GPU
GPU中的算法流程主要分为以下几步:原始数据转换、FFT、共轭相乘、能量累积和求频谱最大值处的相位值。其中,FFT调用CUDA已有的函数库CUFFT中的cufftPlanD函数,其他各步的处理则分别调用在GPU内编写的CUDA架构的核函数(kernel)。当调用的一个函数或者加载的核函数接收到数据后,将启用一定数量的线程(thread)(线程数量在前期已经过分析和计算),工作完成后关闭已启用的线程,处理完毕的数据经过特定的分发机制依照流程传递至下一个函数或者核函数,不同核函数之间的线程完全独立。
3.3 原始数据类型转换
相位干涉仪测向时需要两个或多个天线接收信号,每次采样时在同一时刻的各个天线的信号按照通道号排列在一起,即多路信号AD采集后转换为1路数据流发送至GPU显存。本文的测向系统共设有4个天线,CPU将4个天线接收的信号数据分割成每段16 000个采样点拷贝给GPU,因此GPU第一个核函数(kernel 1)每次读取16 000个点数据,kernel 1的功能是将1路数据流的每段数据分成4路、每路4 000个点存放。
本文设计的GPU每个线程块(block)中分配线程数为512,共启用(≥1)个线程块。kernel 1工作时所有线程块内的线程同时启动,保证每个线程对每个采样点数据同时进行转换,启用的所有线程完成一次点数据转换后,循环加载进行下一段点数据类型转换。设本次处理的数据在第iW个线程块,每个线程块大小为uL,数据点在线程块内索引为iL,其在整个数据序列的索引值为=iW·uL+iL。由此实现了GPU中的原始数据类型的转换。
本文设计的原始数据类型转换核函数的CUDA代码如下所示。

/*转置函数的定义*/__global__ void transpose(float *odata, char *idata, int width, int height){int tid=threadIdx.x+blockIdx.x*blockDim.x;if(tid>=width)return;int lid=tid+blockIdx.y*width;int did=tid*height+blockIdx.y;odata[did]=idata[lid];}/*转置函数的调用*/transpose<<
3.4 FFT
在已有的FFT研究成果中,已知在 CPU 平台下,点FFT的运算量为2·log次的复数乘法和·log次的复数加法,表示做傅里叶变换的点数。本系统每次读取16 000个点数据,在CPU平台下每次的计算量大小为16 000/2·log16 000次的复数乘法以及16 000·log16 000次的复数加法。对于如此大量的高速并行数据,在CPU平台中无法做到实时处理。针对FFT变化中大量高速数据的并行性这一显著特点,本文考虑将FFT部分放在GPU中进行加速并行处理,利用CUDA中自带的CUFFT库,可实现大量高速数据的FFT实时同步处理。
在上一步kernel 1完成原始数据类型转换后关闭所有线程,将数据发送给下一个函数,调用CUFFT函数库内的cufftPlanD函数对数据进行FFT。在GPU上进行FFT需要完成以下工作。
(1) 用malloc(·)函数为输入信号分配主机内存,并存储输入信号;
(2) 用cudaMalloc(·)为输入信号分配GPU端显存;
(3) 用cudaMemcpy(·)将主机内存数据传输到GPU端显存;
(4) 创建一个plan,调用cufftPlan创建FFT;
(5) 执行plan,使用cufftExecR2C(·)函数完成 plan 的计算任务;
(6) 用cudaMemcpy(·)将GPU端显存数据传输到主机内存;
(7) 执行完成以后不再需要该plan,则调用cufftDestroy(·)函数销毁该plan及为其分配的计算资源。
以上各步的具体流程和所用的CUDA函数如图5所示。

图5 GPU上进行FFT的具体流程图Fig.5 Specific flow chart of FFT on GPU
在CUFFT库中,有3种不同的库函数:cufftExecC2C(复数到复数,简称为C2C)、cufftExecC2R(复数到实数,简称为C2R)、cufftExecR2C(实数到复数,简称为R2C),3种库函数的计算耗时由于本身运算量的差异而有所不同。因此,为最大限度地缩短运算时间,必须针对本提相过程的实际情况,选择最合适的库函数类型。在本系统输入信号的FFT计算中,由于输入是实信号,而输出是复数信号,因此最宜采用R2C类型的FFT。
实验表明,相比于使用C2C或R2C,本库函数可以减少数据虚部初始化操作,有效减少数据传输量和计算量,节省运算时间,便于更好地实现数据的实时同步处理。
本系统中天线数为4,cufftPlanD函数每次处理点数为,即对每个天线接收的数据每次处理4个采样点,为了减小噪音对信号的干扰,做FFT前将4个点等分成段,分段进行FFT变换,每段4个点,因此每个天线每段FFT后会得到2·4+1点数据,段数据FFT后得到2·4+点复数数据,即每个天线每次接收的个实数得到2·4+个复数,因此4个天线FFT时每输入个实数输出2+4个复数。由此我们实现了基于GPU的FFT。
本文调用的CUFFT库代码如下所示。

/*直接调用CUDA自带的cufft库,选择cufftExecR2C 函数*/cufftExecR2C(m_fftHandle_batch,(cufftReal*)m_float2,(cufftComplex*)m_float2FFT);
3.5 共轭相乘

本文设计的共轭相乘的核函数部分的CUDA代码如下。

/*共轭相乘函数的定义/__global__ void Conj(float2*src,float2*send,float2*dst,int length){ int tid=threadIdx.x+blockIdx.x*blockDim.x; if(tid>=length) return; int lid=tid+blockIdx.y*length; float signalx=src[lid].x; float signaly=src[lid].y; dst[lid].x=signalx*send[lid].x+signaly*send[lid].y; dst[lid].y=signaly*send[lid].x-signalx*send[lid].y;}/*共轭相乘函数的调用(以21该路信号的处理为例)*/Conj<<
3.6 能量累积并求相位
共轭相乘后的数据传输至kernel 3进行能量累积及提相等处理,能量累积即将每条基线的2·4+个数据等分成段进行相加平均,累加平均后使用atan2函数求出每条基线的(2·4+)个复数的相角,所得相角即为每个采样点处两路信号相位差。接着,在所有相角中,找到最大值处的相位信息,由此完成了GPU中的整个提相算法过程。
本文设计的能量累积的核函数部分的CUDA代码如下所示。

/*能量累积函数定义*/___global__ void FAdd(float2* src,float* dst,float* dst2,int jft,int length){ int tid=threadIdx.x+blockIdx.x*blockDim.x; if(tid>=length) return; int curpos; float2 sum={0}; for(int i=0;i /*能量累积函数调用,并求相位*/FAdd<< 图6 本文设计的相位干涉仪布阵示意图Fig.6 Element arrangement of phase interferometer 每条基线的长度如表1所示。 表1 相位干涉仪各条基线长度Table 1 Length of each of phase interferometer baseline 系统硬件平台选用NVIDIA Tesla V100显卡,接收信号频段采用测控常用S频段,系统采样率为50 MHz。本系统的核心设计指标如表2所示。 表2 系统总体设计指标Table 2 Overall system design index MHz AD采集后的数据进入鉴相器进行FFT时,每个通道信号在每个积分时间(0.4 ms)内处理2×10个采样点的数据,积分后只取相关谱最大值处对应的相位值,因此每个通道每2×10个采样点求得一个相位结果,由此每个通道的信号每秒将得到2 500个相位结果。 为充分验证本文提出的基于GPU的鉴相算法的优越性,本文将该鉴相系统在CPU和GPU平台下分别进行了鉴相精度和鉴相速度的测试,并根据测试结果分析了鉴相标准差和鉴相加速比。 本文分别基于CPU和GPU平台,对鉴相算法进行了多次长时间的实测数据验证,得到了如下所示的鉴相结果。图7所示为6条基线的1 s数据在GPU平台下的鉴相结果。图8所示为6条基线的1 s数据在CPU平台下鉴相结果。 图7 GPU鉴相算法的鉴相结果Fig.7 Phase identification result based on GPU phase identification algorithm 图8 传统鉴相算法的鉴相结果Fig.8 Phase identification result of traditional phase identification algorithms 由图7和图8可知,两个平台下6条基线提取的相位差的翻折次数与基线长度的关系均满足式(6),即基线越长,相位翻折次数越多。 为验证基于GPU的鉴相算法的准确性,本文在相同的测试条件下,针对同样的实测数据,对比了两种算法的鉴相结果,得到了如图9所示的同一次测试中两平台下6条基线鉴相结果的误差图。由图9可知,各条基线的鉴相误差基本均维持在[(-2×10)°,(2×10)°]内。 图9 两种鉴相算法在各基线的鉴相结果标准差Fig.9 Standard deviations of phase dientification results of two phase identification algorithms shown at each baseline 图10所示为两个平台下分别进行10次系统测试之后鉴相误差的标准差,6条基线的鉴相标准差始终小于2×10°,可知两种平台下的鉴相效果相当,从而充分验证了本文设计的GPU平台下的FX鉴相算法的准确性。 图10 两个平台连续10次测试的鉴相结果标准差Fig.10 Standard deviation of phase results of ten consecutive tests on two platforms 为了进一步研究两种算法提取相位差时各个关键运算单元及整个系统的耗时情况,本文利用NVIDIA提供的分析工具NVVP软件,针对1 s数据对GPU鉴相算法中关键运算单元的执行性能和整个鉴相算法的时间分配进行了分析和测试。全过程的数据传输和核函数运算时间的NVVP分析结果如图11所示。 图11 基于NVVP的GPU鉴相算法全流程模块调用情况分析Fig.11 Analysis of the whole process module call of GPU phase identification algorithm based on NVVP 从图11可以看出,cudaMalloc(申请设备内存)、cudaMemcpy(数据传输)、Compute(执行关键运算单元)、cudaFree(释放设备内存)、cudaDeviceReset(释放和清空GPU中的资源)等模块依次执行,计算1 s数据的相位差总用时895 ms,满足系统实时性的要求。其中,并行化程度最高,运算量最大的Compute部分,仅耗时285 ms,占总鉴相过程的31.84%。Compute中原始数据转换(transpose)、FFT、共轭相乘(Conj)、能量累积并求相位(FAdd)这4个模块并行执行,充分利用了GPU各线程块之间的并行化特性,极大地减少了时间消耗。 接着选取并行化程度最高的Compute部分作重点分析,将图11中4个关键运算单元在处理数据时的总时长和各个单元的用时占比,以及CPU平台下鉴相系统的用时情况如表3、图12和图13所示。在CPU、GPU执行同一任务的条件下,定义在CPU平台下的运行时间为,在GPU平台下的运行时间为,那么加速比=/。 表3 两种算法关键运算单元的性能比较Table 3 Performance comparison of the key operation units of two algorithms 图12 GPU鉴相算法中关键运算单元在GPU上的耗时情况Fig.12 Time-consuming proportion of the key computing units in the GPU phase identification algorithm 图13 两种鉴相算法关键运算单元的耗时情况对比Fig.13 Comparison of time-consuming conditions of the key computing units two phase identification algorithms 通过对比各个单元的加速比可知,GPU平台下对于FFT处理加速较快。从图12中可见,运算量最大的FFT在Compute的总耗时中仅占到了9%。图13则充分说明了调用CUFFT函数库以及采用GPU进行并行算法加速的巨大优势。这充分证明了GPU的加速效果及其对于并行化大规模数据量计算的优越性。 表4及图14所示为两个平台分别进行10次系统测试的鉴相时长以及两个平台的加速比,由此可知,相比于传统算法,本文涉及的基于GPU的鉴相算法可以加速140倍左右,充分证明了GPU平台下的鉴相算法具有较为强大的实时化、高速处理数据能力。 表4 两种算法连续10次的总运行时间测试结果Table 4 Total running time test results of two algorithms for ten consecutive times 图14 两种算法在10次测试下的总运行时间对比Fig.14 Comparison of total running time of two algorithms for ten tests 为了实现鉴相过程的高速、实时、可靠,本文研究了提相算法原理,分析了算法并行性并设计了基于GPU的实时信号鉴相算法。针对GPU的加速效果进行分析,研究了GPU的鉴相性能并对结果进行分析,本文主要所做工作如下。 (1) 设计了基于CUDA架构的鉴相器提相算法。通过对鉴相算法的分析,将模块运算流程分为原始数据转换、FFT、共轭相乘、能量累积并求相位等环节,分析了各环节算法的并行性并基于CUDA架构设计了并行实现的具体算法及流程;最后用实验对算法进行了验证,证明了算法的正确性。 (2) 研究了GPU平台的加速效果。通过对并行运算单元中关键运算单元以及整个鉴相过程的研究,分析了GPU平台下鉴相算法的显著优势与较为强大的实时化、高速处理能力,基于NVVP分析了GPU鉴相算法流程内部的具体线程分配与模块调用情况,证明了算法的优越性。
4 实验验证与分析
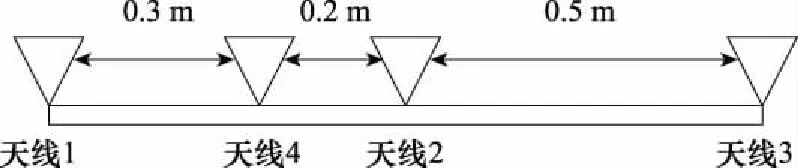
4.1 系统及核心参数设计



4.2 鉴相精度验证与分析




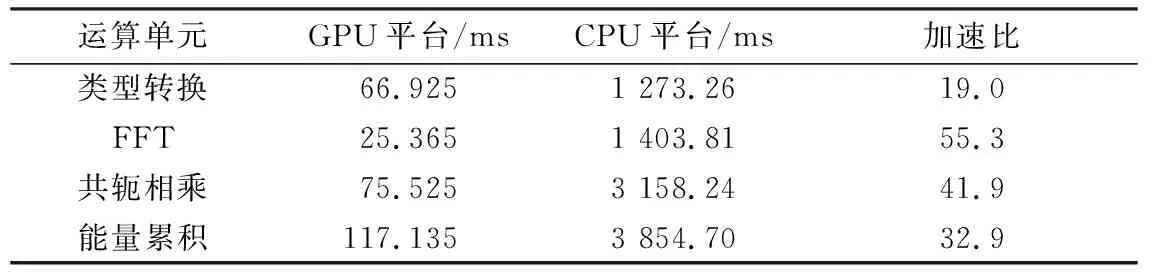
4.3 加速效果验证与分析





5 结 论
猜你喜欢
导航定位学报(2022年5期)2022-10-13
计算机应用与软件(2022年9期)2022-10-10
导航定位学报(2022年4期)2022-08-16
测绘地理信息(2022年3期)2022-06-05
中学生数理化(高中版.高考数学)(2022年1期)2022-04-26
现代电子技术(2022年8期)2022-04-13
体育科技文献通报(2022年1期)2022-01-15
理论与创新(2020年14期)2020-09-22
学苑创造·B版(2019年4期)2019-05-09
中学生数理化·八年级数学人教版(2017年2期)2017-03-25
