
多通道PNCC与残差网络命令词识别系统
2022-11-03 03:30曾庆宁郑展恒卜玉婷
现代电子技术 2022年21期
张 硕,曾庆宁,郑展恒,卜玉婷
(桂林电子科技大学 信息与通信学院,广西 桂林 541004)
0 引 言
命令词识别的目标是在语音中检测出预先定义的命令词。近年来,由于硬件算力和互联网大数据的发展,掀起了一股深度学习的浪潮,受此影响,语音领域也引发了一场科技革命,越来越多的专家学者提出与神经网络相关的命令词识别系统。例如,文献[3]提出训练深度神经网络对目标关键词进行预测,文献[4]使用卷积神经网络(Convolutional Neural Network,CNN),获得了参数更少、更加紧凑的模型,文献[5]将卷积层和递归层的优点相结合,用于小型关键词识别系统的网络模型。最近成果中,文献[6]成功地把图像识别领域的残差网络(Residual Network,ResNet)第一次应用在语音命令词识别领域。
以上所有成果都是基于非特定人的语音识别系统,这意味着非用户的语音可能会错误触发关键词识别系统,或者影响噪声干扰系统对命令词识别的准确率。在部分应用中,例如助听器、人工耳蜗等,为了防止外部人干扰,要求命令词识别系统在准确识别语音命令的情况下,可以判断命令是否由用户发出。同时,生活中处处存在着噪声,如何提高语音识别系统在噪声环境下的鲁棒性也是一个非常重要的问题。
针对以上问题,本文提出一种多通道麦克风阵列与残差网络的命令词识别系统。首先,应用残差网络构建用户/非用户语音检测和命令词识别多任务模型。其次,应用多通道麦克风阵列采集语音数据集。最后,提取功率归一化倒谱系数(Power Normalized Cepstrum Coefficient,PNCC)作为模型输入特征。实验结论表明,本文提出的标准ResNet-CW-15和低功耗ResNet-CW-6模型,匹配PNCC特征的多通道麦克风阵列数据集进行联合优化训练,在命令词识别和用户判断双系统中均取得了良好表现。
1 网络模型
考虑到复杂环境下命令词识别的稳健性,本文应用了具有一定降噪功能的共享阈值收缩残差网络(Residual Shrinkage Network with Channel-wise Threshold,RSN-CW)构建多任务命令词识别模型。
通常来说,数值接近0的信号一般为噪声或者无用的特征信息,在变换域中并不重要,因此可以通过设置一个软阈值把接近0的特征信息直接置0。本文的数据集是基于多通道麦克风阵列,通道数为4,需要对每个通道的特征信息分别求出软阈值。图1是收缩残差单元结构图。
图1中是输入,经过CNN后通过线性整流(Rectified Linear Unit,ReLU)函数,得到作为第二层CNN的输入。在第二层CNN输出后构建软阈值模块,此模块根据特征信息自动学习取值在0~1的阈值'。经软阈值化的特征和恒等映射()作为最终输出,公式如下:
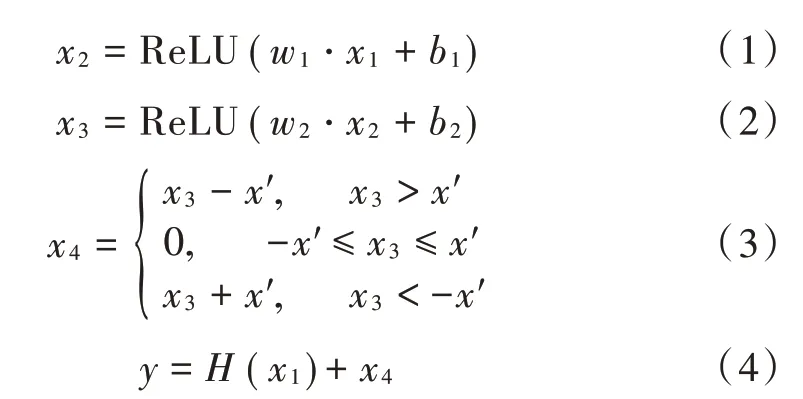
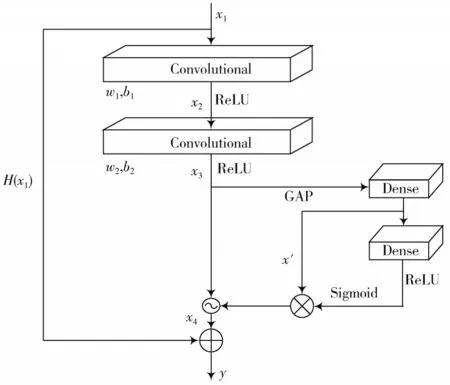
图1 收缩残差单元结构
构建标准多任务模型ResNet-CW-15。首先,第一层为标准卷积层,其次,连接6个收缩残差网络单元;本文多次实验得出,使用6个收缩残差单元可以达到命令词识别和用户判断系统最优效果。最后,加上标准卷积层,结果依次通过(Batch Normalization,BN)和平均池化层(Ave-pooling),应用激活函数Softmax和Sigmoid分别作为命令词识别输出和用户判别输出。模型结构如图2所示。
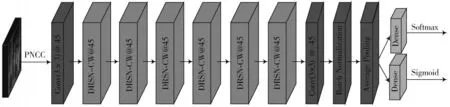
图2 ResNet-CW-15网络结构
为了防止系统被非用户错误触发影响用户体验,同时也为了让系统在部署时尽可能的降低功耗,本文增加了用户判断机制,形成多任务模型。当系统判断命令由用户发出时,会进一步启动命令词识别任务,否则不执行命令词识别功能。
判断原理为:

式中:为输入语音特征,主要包含语音的空间信息特征,对于不同位置的说话者,麦克风所包含的空间特征信息是不同的;为用户,为非用户;只有当(|)>0.5时才会对命令词进行预测,这里0.5是判断阈值,判断与系统交互的是否为用户。
为了增加网络感受野,本文在收缩残差单元的卷积层引入了空洞卷积技术。在语音识别领域内,网络模型使用常规的滤波器会导致处理特征图时感受野不足,因此选择使用空洞卷积可以提升感受野亦减免特征信息的丢失。
在相同实验条件下,本文扩展了实验,提出低功耗模型ResNet-CW-6。将网络中收缩残差单元模块直接减少至2个,同时在第一个卷积层后增加4×3的平均池化层,减小了时频维度,因此没有应用空洞卷积技术,网络中特征输出由45设置为30。值得注意的是,为了使网络更快收敛,本文把收缩残差单元的ReLU层均调整于BN层之前。
2 麦克风阵列
为了提高命令词识别系统对用户/非用户判断的准确度,同时也为了使系统可以广泛地部署在多麦克风智能设备上,本文提出的两个多任务模型皆基于多通道麦克风阵列展开命令词识别研究。
2.1 麦克风阵列介绍
麦克风阵列主要是由多个麦克风按一定规则排列组成,对声场特性进行采样并处理的系统,通过使用多个麦克风可以在时域和频域的基础上再增加一个空间域,从而得到空间信息特征。实验采用双侧麦克风阵列,两侧各放置两个前后麦克风构成多通道麦克风阵列,如图3圆心处所示,黑色圆在前,灰色圆在后,每侧麦克风之间距离1 cm。这种阵列结构的优点:其一,同时有微型与多通道的结构特点,达到仿生人耳结构的目的;其二,不同位置的阵元采集相同位置的声源会包含不同的空间特征信息;其三,更适合广泛部署于当前的多阵列人工智能设备。
麦克风阵列中不同位置麦克风采集的语音信号含有不同空间信息,有利于系统更好地辨别用户与非用户间的不同特征,提高用户/非用户判断的准确率。这一结论在后续的实验与分析中也得到了证明。
2.2 麦克风阵列数据集
本文使用文献[12]的GSCD(Google Speech Commands Dataset)的公开数据集进行实验。声学录音场景如图3所示。12个扬声器组成圆形阵列,阵列位于圆心。随机选择扬声器播放,圆心处麦克风阵列获取用户声音,1.5 m外扬声器处为非用户语音。
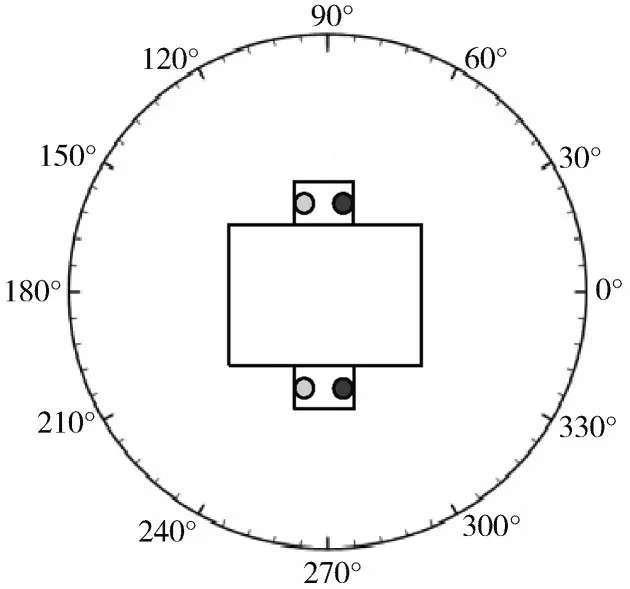
图3 阵列语音采集示意图
数据集总共有50 626组命令词语音,训练数据集、验证数据集、测试数据集的占比分别为67.5%,10.8%和21.7%。选用的命令词语音为:“left”“yes”“on”“up”“go”“right”“no”“down”“stop”“off”,其余未选用关键字单独划为未知类,共11类。
3 特征工程
语音识别领域经典的特征是梅尔频率倒谱系数(Mel Frequency Cepstrum Coefficient,MFCC),但MFCC容易受到噪声干扰,在低信噪比条件下会导致系统的语音识别准确率严重下降。为了提高语音识别系统在噪声环境下的稳健性,本文选择了对噪声具有一定鲁棒性的PNCC。
3.1 功率归一化倒谱系数
2016年,由Kim等提出的功率归一化倒谱系数与MFCC相比,在保证语音识别性能的前提下,增加了语音识别的鲁棒性。PNCC的改进之处在:
1)将梅尔倒谱系数的滤波器改为Gammatone;
2)平滑每帧语音数据时,采用更长的时间窗口;
3)采用类似谱减法消除低频噪声;
4)PNCC使用幂函数,更符合人耳听觉神经特性。
PNCC特征提取流程图如图4所示。
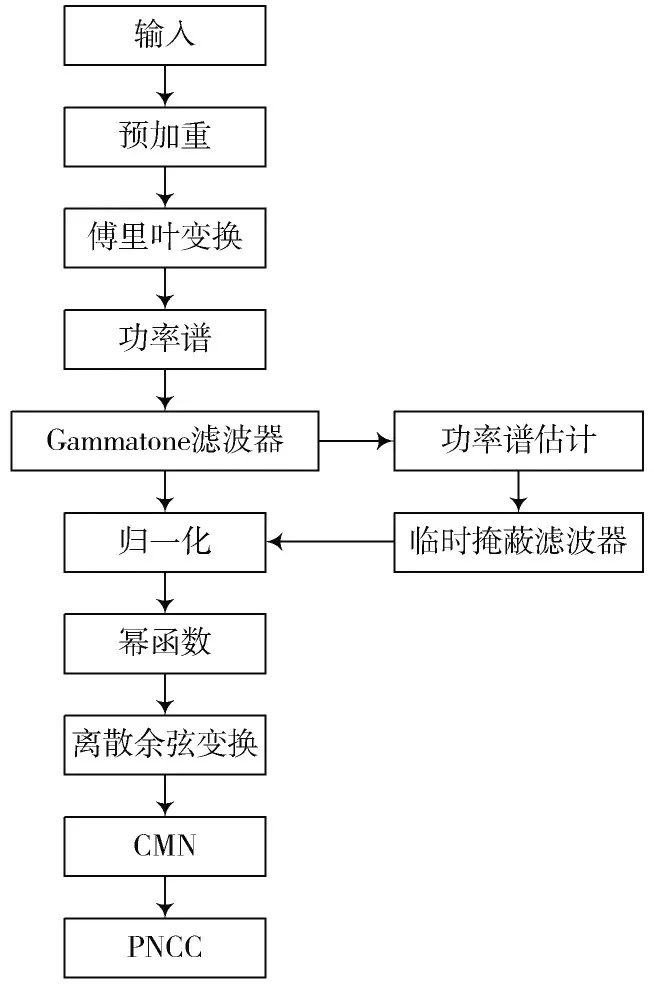
图4 PNCC特征提取流程图
3.2 动态特征
语音信号是非平稳信号,一般提取MFCC与PNCC等特征系数的步骤仅仅反映了语音信号的静态特性,但是神经网络可以更好地学习语音的动态特征参数。为了提高语音识别的准确度,本文对特征系数进行差分运算,语音的动态特征可以用静态特征的差分运算来描述,原理如下:
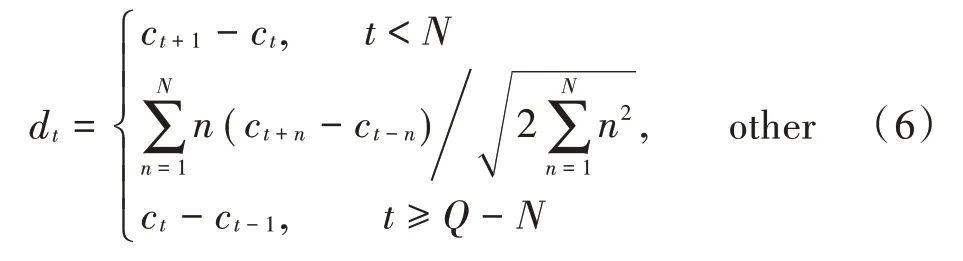
式中:d表示第次一阶差分;表示倒谱系数;表示倒谱系数的阶数;表示导数时间差,取1或2。将式中结果再次代入公式运算就可得到下一阶差分结果。
3.3 特征处理
首先让语音通过截止频率为20 Hz和4 kHz的带通滤波器。使用30 ms的汉明窗,10 ms帧移对语音数据分帧。同时,为了达到数据集扩充的目的,对每组语音随机移动ms,∈(-100,100),并且随机截取GSCD中的噪声片段,加入80%的训练数据集语音中。最后提取PNCC特征得到40维的特征参数,由1帧语音对数能量、13维特征、13维一阶差分特征、13维二阶差分组成。在多通道麦克风阵列信号的情况下,本文将上述特征提取独立应用于每个通道。
4 实验与结果分析
4.1 网络参数设置
ResNet-CW-15和ResNet-CW-6网络采用的优化器是随机梯度下降,其中下降参数设置为0.9,学习率=0.1,衰减系数=10,minibatch=32,训练次数epoch=40。
4.2 实验及结果分析
本文基于多通道麦克风阵列采集GSCD数据集,测试ResNet-CW-15和ResNet-CW-6网络。本文使用单侧麦克风阵列MFCC信号作为输入来测试标准ResNet15模型。该模型没有用户/非用户语音判断机制,只含有命令词检测功能作为对比基线。模型Multi-ResNet15和本文算法均采用命令词识别、用户/非用户判断多任务系统。为了体现PNCC和本文麦克风阵列的效果,分别使用单麦克风MFCC、单侧双麦克风MFCC和PNCC、本文麦克风阵列PNCC对Multi-ResNet15进行测试。其中用户数据集仅包含用户的语音数据,整体数据集包含非用户语音干扰,目的是测试模型在干扰环境下的稳健性。由于ResNet15模型和Multi-ResNet15模型参数一样,所以下面选择后者进行参数数量对比。
命令词识别系统本质是完成分类任务,而评估系统分类性能一般使用ROC曲线,如图5所示。
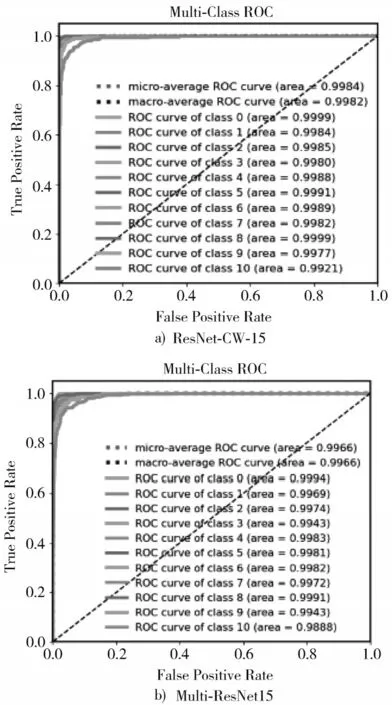
图5 ROC曲线对比
ROC曲线下的面积是衡量系统优劣的一种性能指标,面积范围一般为(0.5,1),分数越接近1真实性越高,当分数等于0.5时,真实性最低,无实用价值。其中“micro”和“macro”是求ROC值的不同方法。
表1、表2分别对比模型在不同麦克风阵列、特征以及单任务和多任务系统中的命令词识别结果、参数数量。图表分析如下:
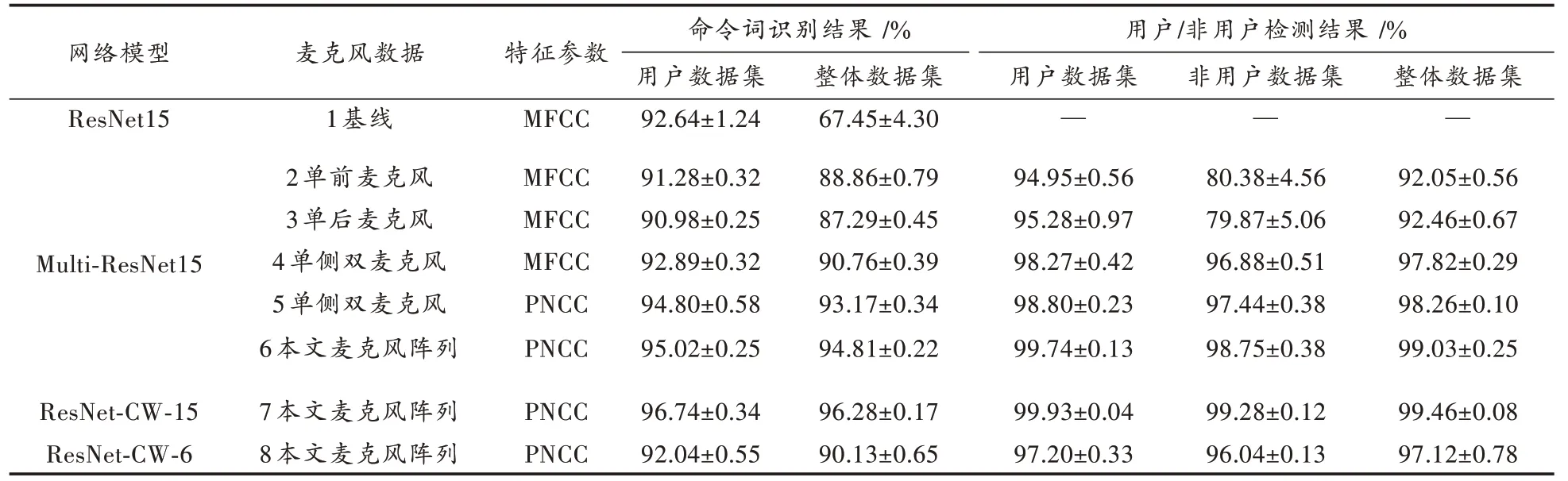
表1 语音命令词识别准确率
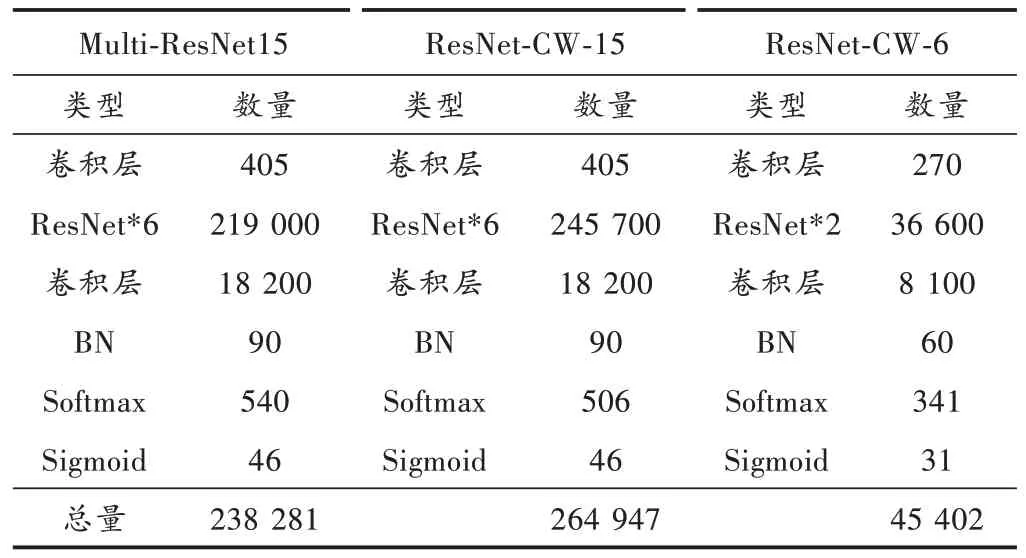
表2 网络参数数量表
1)图5在PNCC和本文阵列数据集的条件下,对比本文构建的ResNet-CW-15与Multi-ResNet15的分类效果。从ROC曲线来看,ResNet-CW-15模型在命令词识别分类效果中平均准确率最高为0.998 4,达到了优秀的分类精准度,并且优于Multi-ResNet15的0.996 6。
2)表1中对比实验1与实验4均采用单侧双麦克风MFCC做特征参数,模型皆为标准残差网络构建,不同之处在于实验4加入了用户/非用户语音检测模块,为多任务模型。
其中实验1整体数据集表现较差,准确率为67.45%。反观实验4,加入多任务机制后识别准确率达到90.76%。因为在单任务机制下,用户语音数据集加入距离较远且音质较差的非用户语音数据集时,严重影响了系统识别用户命令词的特征信息,导致整体数据集识别率急剧下降。实验证明,使用多任务机制有利于提高系统在非用户语音干扰时命令词识别的稳健性。
3)对比实验4与实验5可知,在相同麦克风阵列结构和模型条件下,采用PNCC特征的命令词识别准确率在用户数据集和整体数据集皆优于MFCC,并且用户/非用户判断的准确率也有稍许提升。这是因为提取PNCC过程有降噪步骤,因此特征含有更少的干扰信息,有助于模型识别语音的有用信息。因此,使用PNCC可以提高系统对非用户语音干扰时的鲁棒性。
4)对比实验5和实验6,实验6采用本文提出的麦克风阵列数据,其命令词识别准确率在整体数据集的表现非常接近用户数据集。这是不容易的,因为用户数据集一般语音质量较好,提取的特征比较明显,容易正确完成用户/非用户的判断任务,得益于此,后续识别命令词的任务相较于非用户数据也容易一些;但是,整体数据集包含音质较差的非用户数据,容易误判为用户,更容易在命令词识别任务中产生错误判断。
对比实验5和实验6的用户检测部分,在相同模型和PNCC条件下,实验6对于用户的判断比实验5准确率更高,这意味着实验6的配置可以更好地防止非用户错误触发系统,从而避免了系统对非用户的低质量语音识别,提高了系统整体的识别率,同时也降低了系统功耗。综上所述,本文提出的麦克风阵列结构优于单侧麦克风,因为本文麦克风阵列采集的数据含有更丰富的说话者方位角特征信息,有利于系统对用户做出更精确的判断,进一步提高了系统整体效果。
5)在表1命令词识别部分,实验7在用户和整体数据集的准确率都超过了实验6。在用户判断检测部分,也得到相同的结论。结合图6用户判别率对比可更直观看出,实验7的ResNet-CW-15模型在360°方位角的判断都比较准确,而实验6的Multi-ResNet15模型把部分0°,45°附近和180°~270°之间的语音误判为用户。这是因为,得益于收缩残差网络把干扰和无用特征信息置零的功能,使得ResNet-CW-15模型对噪声具有更好的鲁棒性。因此,可以得出结论,本文构建的ResNet-CW-15模型在复杂环境下的鲁棒性优于Multi-ResNet15模型,更适用于情况复杂的现实生活场景。
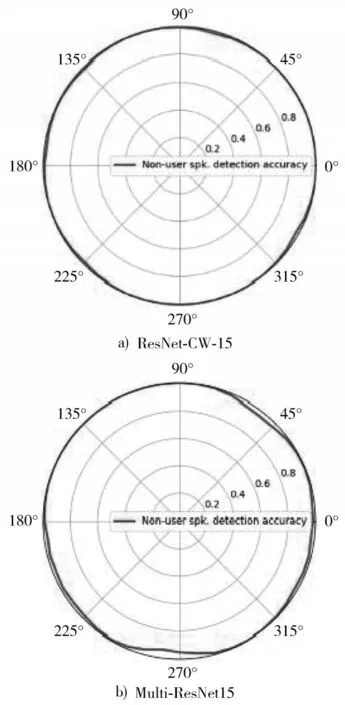
图6 用户判别率对比
6)实验8的结果在用户数据集和整体数据集效果对比实验6、7有所降低,但是参考表2的参数数量对比可知,ResNet-CW-6的参数数量比Multi-ResNet15降低了80.9%,较ResNet-CW-15降低了82.8%,极大地减少了系统的资源占用率。该模型虽然在识别精度上有所降低,但也足够满足应用要求,是部署在小型低功耗设备的极佳网络。
5 结 语
本文针对稳健的命令词识别系统,提出了双侧多通道麦克风阵列结构,并将PNCC特征应用到多通道阵列数据集之中,最后配合本文构建的标准多任务ResNet-CW-15模型联合优化训练的方法。
首先采用双侧多通道麦克风阵列结构采集语音数据,这一步骤可以采集到丰富的声源位置信息。其次对数据集提取PNCC特征,达到对语音初步降噪的目的。最后把特征导入多任务ResNet-CW-15模型进行训练。在相同实验条件下,本文还构建了一种紧凑的ResNet-CW-6模型,该模型适合广泛部署于低功耗智能设备中。通过实验对比,验证了本文提出的命令词识别系统在噪声和非用户干扰下的鲁棒性。后续研究将着重于对模型进一步改进,例如调整网络宽度,在不增加网络功耗的条件下提高识别精准度,或者测试更深层次的模型。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
娃娃乐园·综合智能(2022年3期)2022-04-19
北京航空航天大学学报(2020年10期)2020-11-14
自动化学报(2019年6期)2019-07-23
复旦学报(自然科学版)(2019年3期)2019-07-19
电子测试(2018年23期)2018-12-29
军营文化天地(2018年2期)2018-04-20
小学科学(2016年12期)2017-01-06
中国老区建设(2016年9期)2016-02-28
做人与处世(2015年19期)2015-09-10
