
基于最大熵原理和融合机器学习的手写体汉字识别算法
2022-11-16 02:16张湛梅张晓川
电子技术与软件工程 2022年16期
张湛梅 张晓川
(中国移动通信集团 广东省广州市 510000)
脱机手写体汉字识别技术作为字符识别技术(OCR)的一个分支,已成为模式识别领域新的研究热点。由于不同汉字字体结构繁多,存在大量相似汉字,书写习惯不同导致手写汉字结构形体更是因人而异,千差万别,体现在汉字手写体识别更加困难。脱机手写汉字识别是针对静止的二维图像中的汉字进行识别,通过票据合同图片特征提取文字,故而识别更为复杂困难,准确度难以提高,脱机识别的手写汉字识别一直是当前业界研究的难点热点。
目前脱机识别手写汉字的方案主要有两类:第一类是基于传统机器学习方法,主要有支持向量机(SVM)、线性判别模型(LDA)与修正二次判别函数(MQDF)等。这类方法在建模前需要对建模数据进行数据预处理和复杂的特征工程建设,由于提取特征复杂,包括汉字质心、笔画特征处理,难以全面的提取出准确的特征。另一类是基于深度学习进行手写体汉字的识别,目前主流模型有VGGNet、ResNet 等,这类做法存在调优参数多、网络收敛缓慢、存储模型空间较大等问题。
为了解决现有技术中存在的上述问题,本文提出了一种基于改进的YOLO‐9000 与DBN 模型的融合模型,主要是根据应用最大熵原理来正则化训练过程,在交叉熵损失中添加一个负熵项,使用最大熵正则化与平均方差相似度函数联合作为损失函数,增加类间变异,减少类内变异,融合机器学习的融合模型方案进一步解决了识别效率低的问题与重量级网络泛化难的问题。
1 算法原理与数据
1.1 算法原理
本文通过融合传统机器学习算法,解决传统机器学习识别效果差与深度网络泛化能力、速度慢的问题。主要算法步骤如下:
(1)数据的采集与输入。针对票据合同中的手写体汉字样本进行采集,并将采集的图片汇集成数据集。
(2)数据加工与图像增强过程。针对每个汉字进行单独标注,并将采集的图片进行图像增强处理,由于票据合同中某些常用汉字出现频率多,用词要对数据集进行数据扩增,防止拟合模型时发生过拟合。
(3)改进YOLO‐9000 模型。YOLO‐9000 是指可以对9000 类物体进行识别。在常见的票据合同中,每一个汉字均可以认为是一个物体,而票据合同中的常用的汉字约为500‐1000 个,因此改进YOLO‐9000 模型可以将分类减少到1000 类。
(4)DBN 模型训练。DBN 模型是由一系列叠加的玻尔兹曼机(RBM)和顶层的反向传播网络(BP)组成,在有标签样本的训练模型阶段,细分类会调整BP 网络的权值,将实际输出与预期数据的误差逐层反向传播。通过RBM 层进行无监督的机器学习训练,将下层RBM 作为上一层的输出。再对输出结果使用BP 神经网络进行训练,将实际输出与预期输出的误差逐层反向传播,调增网络的权重,最终得到DBN 模型。
(5)模型融合,步骤4 与步骤5 的两个模型都可以手写体汉字识别,并应用各自的网络进行特征提取。由于YOLO 和DBN 模型建模本质有区别,其提取特征的手段各有优势,融合的YOLO 和DBN 的融合模型,在效果上会超过单一模型的识别能力。
(6)结果输出。通过步骤五模型融合的结构,对于一个新输入的样本x,将x 所属分类的最大概率值进行输出,并进行结果的可视化展示。
1.2 算法各步骤原理
1.2.1 汉字识别流程图
票据合同中手写体汉字的识别系统主要由数据采集、数据清洗、模型融合、输出结果四部分组成。其中数据采集与数据清洗分别负责原始手写体汉字的样本采集与标注。最终通过结果输出部分,针对一个新输入的样本,输出它预测最大概率所属的分类。如图1 所示。
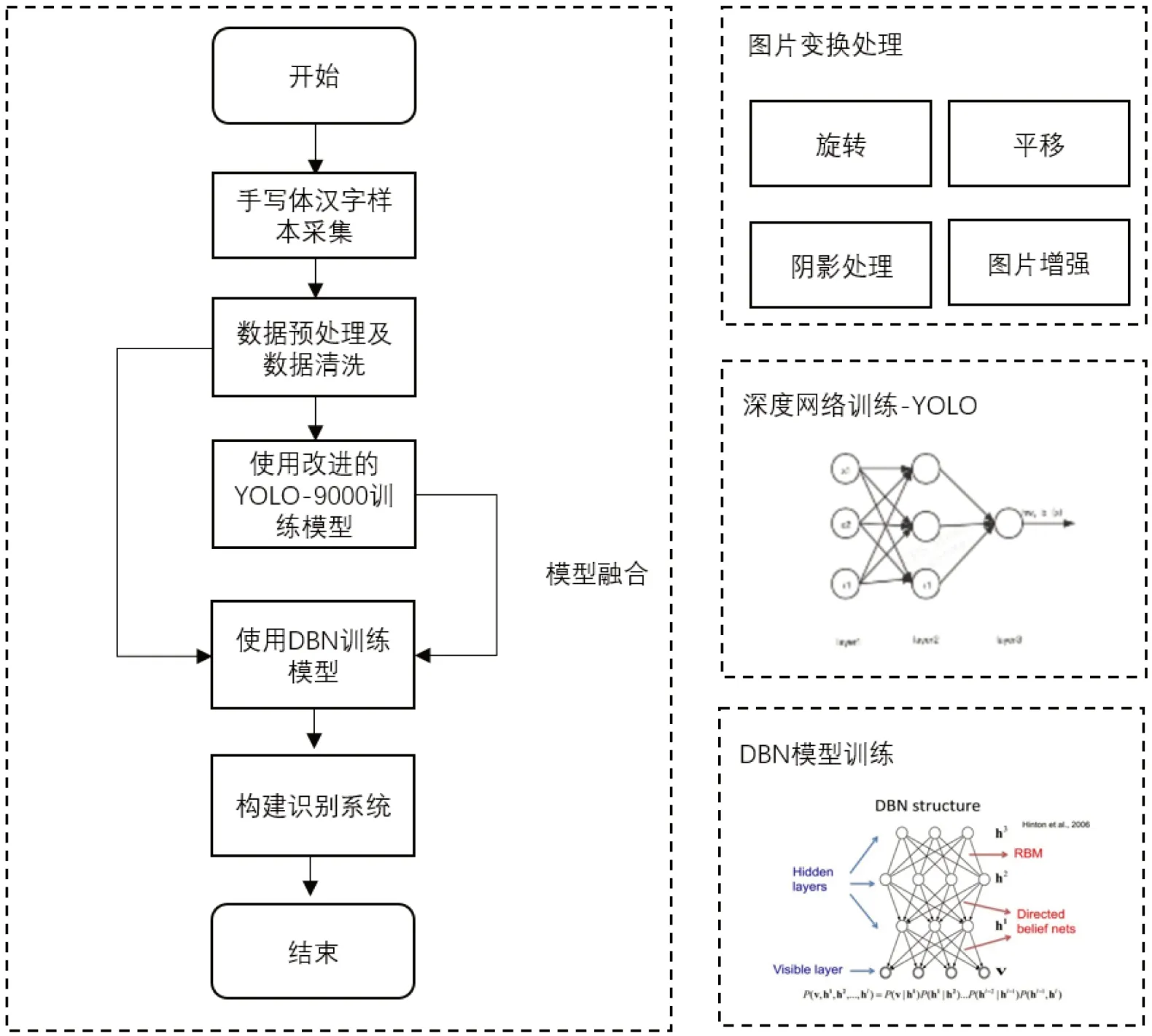
图1:票据合同的手写体汉字识别系统流程图
1.2.2 改进YOLO‐9000 结构
YOLO‐9000 使用最大熵正则化项加平均方差相似度函数作为损失函数,增加类间变异,减少类内变异,如图2 所示。一般来说,手写汉字识别中预测的类内方差同样很大,即熵很大,我们将输出的熵进行正则化,使模型更加一般化,减轻过拟合,表达式如下,
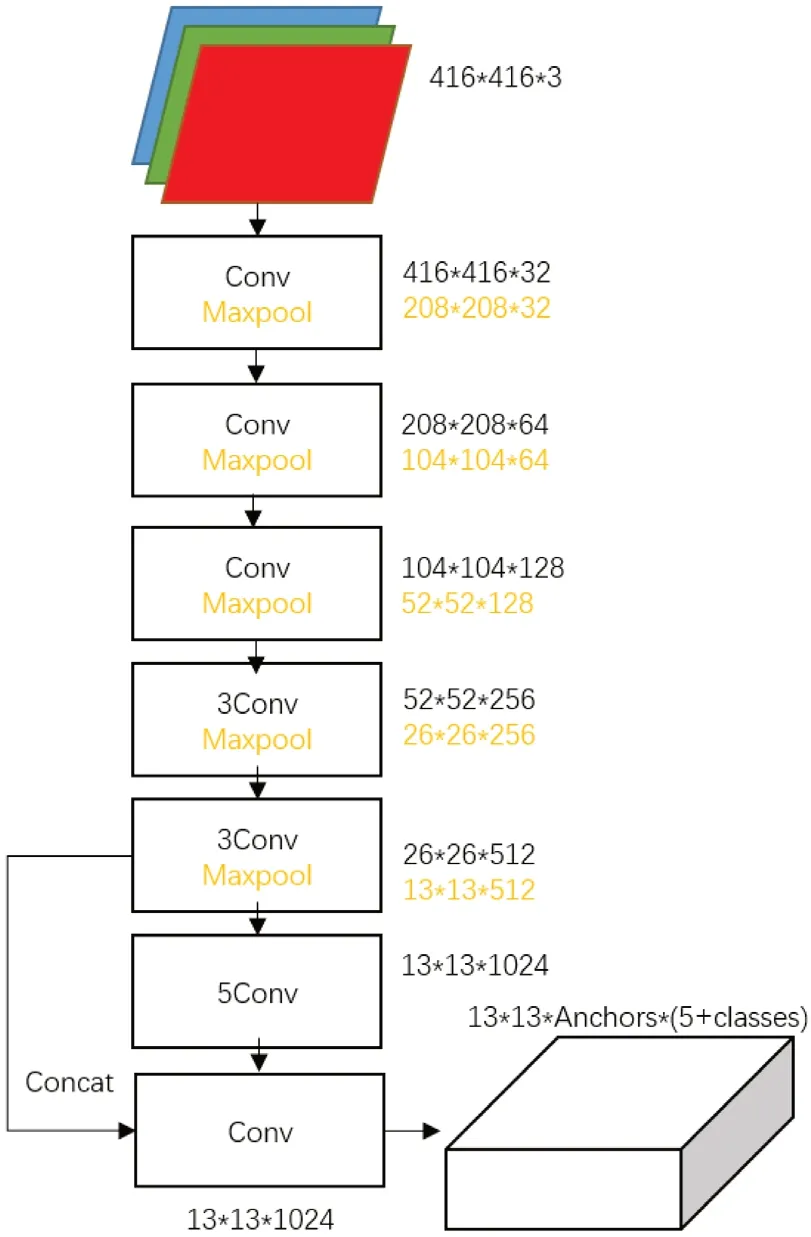
图2:改进的YOLO-9000 结构
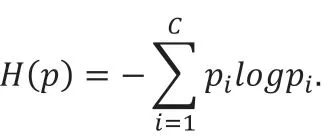
熵是一个热向量时达到最小值,在p 是均匀分布时达到最大值。前者是通过普通的交叉熵损失自动实现的,而后者则有望促进正则化。因此,我们将负熵作为最大熵正则化项,它直接作用于一般的交叉熵损失函数上,
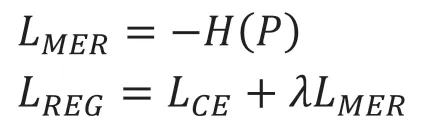
其中λ 是决定MER 影响的超参数。从直观上看,MER降低了交叉熵损失造成的极端置信值。考虑正则化损失对输出分数的导数,它与模型直接相关,对概率分布的导数为:
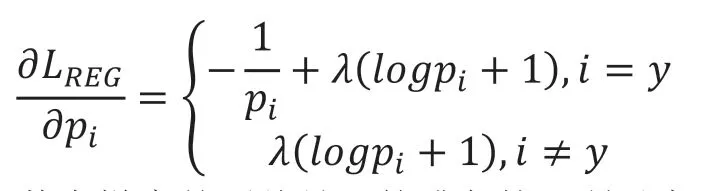
其中梯度并不总是正的或负的,所以在更多分布的分数下,概率不会下降到0 或增加到1。至此就完成了损失函数的构建。
改进模型共又15 层卷积层,通过减少瓶颈结构的卷积的构造,删除了两层1×1 卷积及瓶颈卷积,原本的检测头从9 个卷积层减少到6 个,同时在每个最大池化层后接入dropout 层,以防止过拟合,使得体量更加轻便适合票据合同中手写体汉字识别的需求。在损失函数的选择上,本文对以往的YOLO 模型改造,使用交叉熵损失函数加平均差相似度函数作为损失函数,这种做法可以增加类间变异,减少类内变异,从而获得更好的分类性能。
1.2.3 改进的YOLO9000 与DBN 模型构成的融合模型
(1)改进的YOLO9000 模型。如图3 所示,本文给出了DBN 模型的构成。DBN 是一个具有层次特征的概率生成模型,通过训练神经元之间的权重。本文中的DBN 模型是由一系列的受限玻尔兹曼机(RBM)和顶层的反向传播网络(BP)组成。RBM 层共有三层,由可视层输入数据,隐藏层做特征检测,两层之间全连接。通过RBM 层进行无监督的机器学习训练,将下层RBM 作为上一层的输出。再对输出结果使用BP 神经网络进行训练,将实际输出与预期输出的误差逐层反向传播,调增网络的权重,最终得到适用手写体识别的三层DBN 模型。
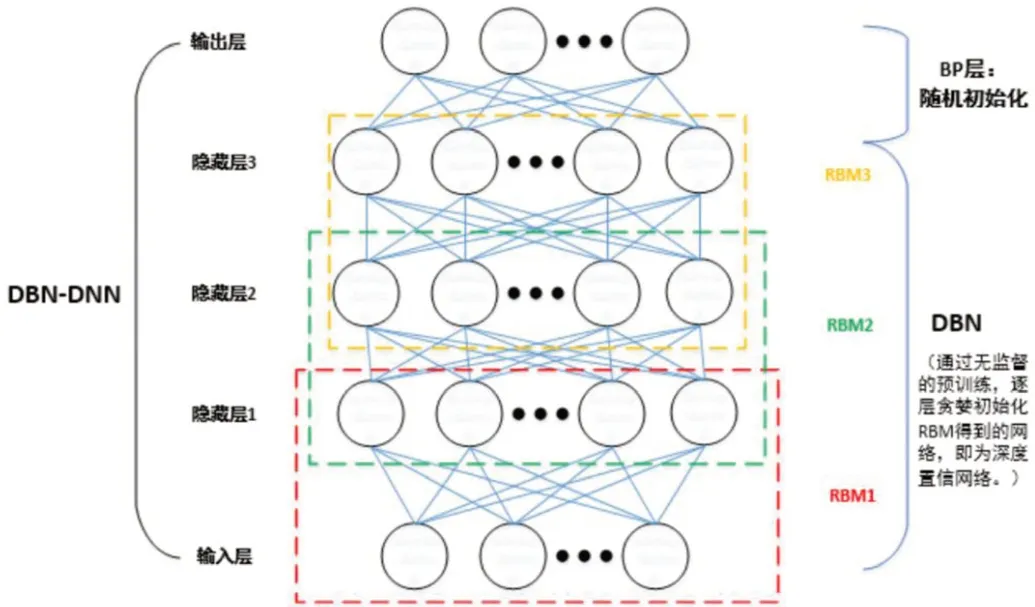
图3:DBN 模型结构
(2)融合模型。如图4 所示,将改进的YOLO9000 与DBN 模型构成的融合模型,首先单独训练YOLO 模型和DBN 模型,并得到训练好的识别模型;然后在样本集上统计两个模型对不同字符的识别能力,通过下式定义pi为模型对第i 个字的识别能力;ci表示第i 种汉字被识别正确的此申诉,ni代表第i 种汉字在样本集中出现的总次数。N 为汉字种类总数。
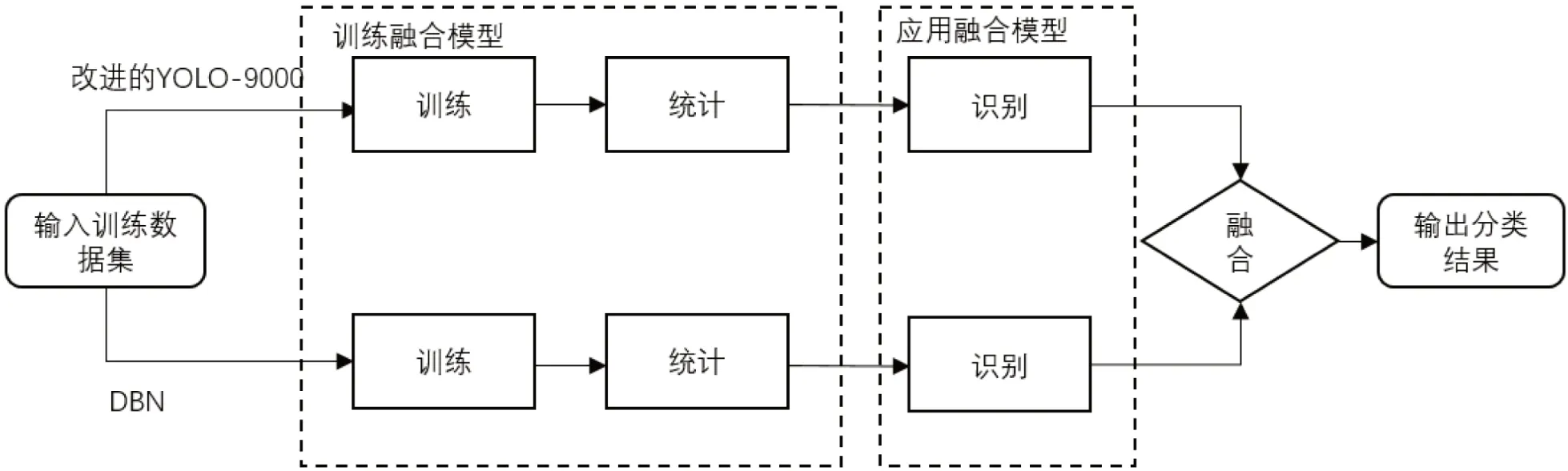
图4:改进的YOLO-9000 和DBN 的融合模型
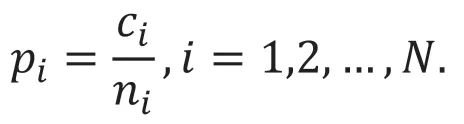
YOLO 对N 种字符的识别能力向量表示如下:
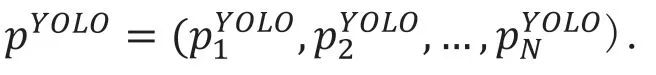
同样的DBN 模型对N 种字符的识别能力向量表示如下:
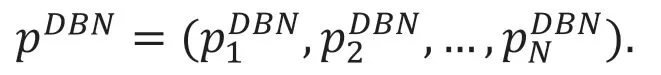
其中涉及的融合模型算法的主要步骤如下:
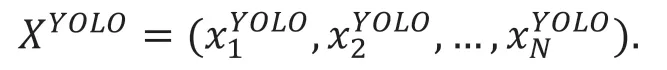
将YOLO 模型的识别分数与模型的能力向量进行点乘的结果作为模型最后的识别得分:
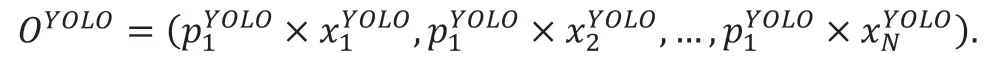
首先来说说我自己,我是一个生来性格内向的人,我认为这和从小的家庭教育、家庭环境以及接触的人、事物都有着很大的关系,所以我很害怕与人沟通,不愿意多说话,宁愿自己多干点就是不愿张嘴去与人沟通。其次我还是一个害怕产生人际冲突的人,就是俗话中的老好人,当别人的意见与我相悖时,我总是因为害怕发生人际冲突造成同事间的关系紧张,所以总是无条件的按照其他人的意见进行事情的处理。
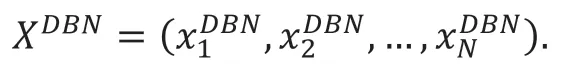
将DBN 模型的识别分数与模型的能力向量进行点乘的结果作为模型最后的识别得分:
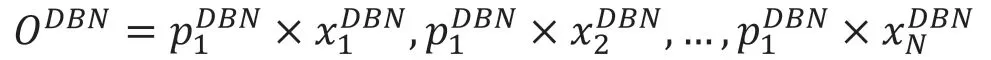
(3)将YOLO 模型得分的分量从大到小排序,选取最的大两个分量并记录,
(4)将DBN 模型得分的分量从大到小排序,选取最的大两个分量并记录,
(5)融合YOLO 和DBN 两模型的结果,输出最后分类识别结果class,采用线性可信度累积(LCA),引入α,β作为加权因子,融合两模型的识别得分,其中α,β 的相加和等于1,通过调节α,β 的值权衡两个模型之间的比重,识别得分的计算公式如下,
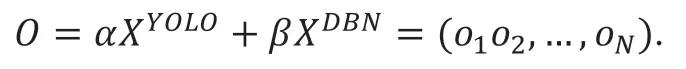
最后得到O 中概率最大的分量,记为class 并输出:
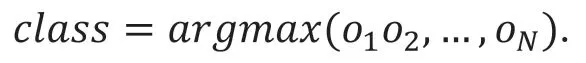
2 算法实现及结果分析
2.1 数据集及其预处理
为了让网络模型快速、简单、易懂地进行分类判别,对选择的手写汉字库批量构造了对应标签;为了让待识别图片与数据集图片具有一致性,再对选择的手写汉字库实行批量预处理。采用中科院自动化模式识别国家实验室2010 年05月发布的 HCL200 脱机手写汉字数据集,此数据集是现今最大的手写汉字图片库,它包含国家规定的GB2312‐80 里日常生活中使用的3755 个汉字。
文中的卷积神经网络具有15 层卷积层,通过改进卷积层,减少瓶颈结构的卷积的构造减轻了网络的量级,删除了两层1×1 卷积,原本的检测头从9 个卷积层减少到6 个,每个最大池层之后都应用dropout 层以防止过拟合。
2.2 数据分析与结果分析
对比现有识别手写体汉字使用传统的机器学习模型的做法,改进的YOLO‐9000 通过改进损失函数,重构主干网络的做法融合DBN 模型,使得模型在保证识别时长的情况下,提升了识别率。对比深度学习模型,融合模型通过调节加权因子,使得识别率强于单一模型,模型泛化性能比单一的深度学习模型好防止过拟合。由于对YOLO‐9000 主干网络的卷积层修改,使得运算识别速度强于一般深度学习模型识别手写体汉字。
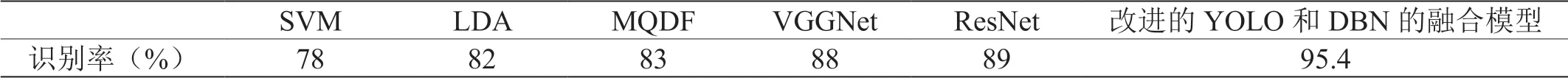
表1:本文改进的YOLO 和DBN 的融合模型与传统的识别算法对比分析结果
3 结论
本文主要针对票据合同中的手写体汉字识别问题。
(1)本文定义了基于机器学习算法的手写体文字识别的系统,其特征在于识别系统包括数据采集、数据加工、融合模型建模及结果输出部分。
(2)与传统机器学习算法相比,本文提出的融合模型在程序上识别效果更好,泛化能力更强,其特征在于使用了融合模型,结合两种不同的神经网络通过引入加权因子融合两模型分类能力,得到最终分类结果。
(3)与复杂深度学习网络相比,本文具有识别速度更快、对算力要求低,减少识别时长的优势,其特征在于通过改进的YOLO‐9000 来完成网络的构建,在保证准确率高的情况下相比VGGNet、AlexNet 等模型识别速度更快,且适合手写体汉字的识别。
(4)本文的改进的YOLO‐9000 算法,通过改进损失函数和调整卷积层,使得CNN 模型更加适应手写体汉字识别分类。
猜你喜欢
星星·诗歌原创(2023年1期)2023-05-30
星星·散文诗(2023年1期)2023-04-15
北京航空航天大学学报(2021年9期)2021-11-02
作文成功之路·小学版(2020年7期)2020-08-24
科技风(2020年3期)2020-02-24
中国篆刻(2019年6期)2019-12-08
电子制作(2019年11期)2019-07-04
电子制作(2018年18期)2018-11-14
北京航空航天大学学报(2018年1期)2018-04-20
自动化学报(2016年8期)2016-04-16
