
基于BERT-CRF的领域词向量生成研究
2022-11-16 02:25郭振东李成城赵佳鹏
计算机工程与应用 2022年21期
郭振东,林 民,李成城,赵佳鹏
1.内蒙古师范大学 计算机科学技术学院,呼和浩特 010022
2.中国科学院大学 网络空间安全学院,北京 100089
3.中国科学院 信息工程研究所,北京 100089
随着深度学习等人工智能技术的发展,词向量(word embedding)模型[1]由于其出色的语义表示能力在自然语言处理(natural language processing,NLP)领域越来越被重视,并被广泛地应用在机器翻译、信息抽取、自动问答等任务上,词向量结合神经网络模型成为深度学习在解决各类NLP任务的主流方法[2]。
BERT(bidirectional encoder representations from transformers,BERT)[3]是一种基于Transformer[4]双向编码器表示的词向量预训练模型,其旨在通过联合调节所有层中词汇的上下文来预训练深度双向表示,并刷新了11个NLP任务的当前最优效果[3]。然而,现有中文BERT预训练模型大都以字或句子为向量表示单位,对于一些以粗粒度的领域专有词汇(如领域术语、短语、实体词)为处理单位的文本分析任务(如特定领域文本的主题分析任务等)并不适用,而原始BERT 模型无法直接获取符合领域需求的高质量词级向量;如何在BERT预训练字向量基础上,进一步进行fine-tuning获得包含特定领域文本上下文语义信息的高质量领域词向量表示,是目前研究的难点和热点问题。
针对上述问题,本文提出了一种领域动态词向量的生成方法。核心思想是利用少量领域专有词汇,有监督的fine-tuning BERT 的网络参数,使得BERT 在学习领域字的表示时,能够感知到粗粒度的领域词汇为一个语义整体,进而优化领域字的表示,从而缓解原始BERT无法有效表示粗粒度的领域专有词汇的问题。
该方法首先利用少量的领域分词标注数据,再以分词为优化目标,采用BERT-CRF 的网络结构fine-tuning BERT的网络参数。再把经过fine-tuning的字向量采用不同的策略进行融合,生成粗粒度的领域专有词汇的向量表示。实验结果表明本文所提方法不仅有助于提高领域分词准确率,而且达到了仅需少量领域标注数据,就能生成领域高质量词向量表示的目的。
1 相关工作
在词向量表示模型的发展中,传统的Word2Vec[1]和GloVe[5]等模型的文本表征能力都受限于模型本身的结构[3],词与向量是一对一的关系,无法有效解决一词多义问题,静态的词向量表示无法针对特定任务做动态优化。后续提出的ELMo[6]和OpenAI GPT[7]等为单向的语言模型,每次仅能关注某个单向标记,因此特征表示能力有很大的局限性;Google研究员Jacob Devlin等受完形填空的启发,提出了基于Transformer 的双向编码器表示[3]模型,其通过“遮罩语言模型”(masked language model,MLM)和“下个句子预测”任务解决单向约束和一词多义等问题,是一种深层双向Transformer 预训练模型。为进一步促进中文信息处理的研究发展,哈工大讯飞联合实验室崔一鸣等人于2019年发布了基于全词遮罩(whole word masking)技术的中文预训练模型BERT-wwm,在多个中文数据集上取得了当前中文预训练模型的最佳水平[8]。2020年,苏剑林等提出了基于词颗粒度的中文预训练模型WoBERT[9],目前开源WoBERT是Base 版本,在哈工大开源的RoBERTa-wwm-ext 基础上继续进行预训练,预训练任务为MLM。初始化阶段,将每个词用BERT的Tokenizer切分为字,然后用字向量的平均作为词向量的初始化。
近年来,随着深度学习等技术发展,基于长短期记忆网络(long short-term memory,LSTM)、双向LSTM、CRF[10]以及注意力机制的中文分词研究成为主流[11],但这些分词算法对领域未登录词等识别效果差强人意,Jieba 等通用的中文分词器应用到特定领域时,不能准确识别出领域专有名词,并且难以构建覆盖全面的领域词典。因此,如何将文本特征表示能力更强的中文BERT-wwm 预训练模型结合领域分词任务来提升领域分词准确率,并利用BERT 的fine-tuning 模型对特定领域任务动态优化BERT 字向量,以及怎样融合BERT 字向量能得到高质量领域词向量成为本文研究的重点。
针对以上问题,本文提出一种基于BERT-CRF的领域词向量生成方法。在利用大规模自然语言文本数据进行预训练的BERT模型基础上,并结合能充分考虑标签依存关系的CRF 模型[12],构建BERT-CRF 领域分词器,使用少量的《软件工程》样本数据集对BERT网络参数进行fine-tuning,可获取符合领域文本上下文特征的中文字向量。对fine-tuning 后BERT 的12 层隐层字向量采用不同的融合策略进行实验,获取符合本领域更高质量的词向量。
2 基于BERT-CRF的领域词向量学习
基于BERT-CRF 的领域词向量学习模型如图1 所示。fine-tuning是指将预训练模型迁移到新的模型上来进行二次训练,本文方法可分为二次fine-tuning和字向量融合两阶段。在二次fine-tuning阶段,将领域文本传入BERT-CRF 分词器,以领域分词作为BERT 的下游任务,在训练BERT-CRF领域分词器的同时,对BERT字向量进行二次fine-tuning 训练,使得BERT 字向量能够感知到粗粒度的领域词汇整体语义,返回包含领域词整体语义的字向量和分词标签;字向量融合阶段将包含领域词整体语义的相关字向量按“全字求和平均”和“首尾字求和平均”两种策略进行融合实验。两种融合策略说明如表1所示。
2.1 BERT模型
BERT 模型是一种深层双向Transformer 编码器的预训练模型[3],其中,Transformer 是仅基于Attention机制的结构,用来处理序列模型相关问题。它沿用了Encoder-Decoder结构,但摒弃了传统的循环神经网络和卷积神经网络,利用多头注意力机制结合线性变换来提取特征信息,提升并行训练速度的同时,也提升了模型准确性,而BERT 是利用了Transformer 的Encoder 部分进行预训练,Transformer的Encoder结构如图2所示。
在图2 中,输入为字向量与位置向量之和;位置向量首先由公式(1)[13]、(2)[13]获取词在句子中的绝对位置信息表示,再由三角函数公式(3)[13]、(4)[13]得到词之间的相对位置信息表示,并通过注意力机制进行处理,注意力机制原理如公式(5)[14]所示。
其中,Q、K、V分别为查询矩阵、关键词矩阵,值矩阵、Q矩阵与K矩阵的维度为dk。而多头注意力机制是通过多个不同的线性变换对Q、K、V进行投影,最后将不同的Attention结果拼接起来,如公式(6)和式(7)[14]。
使用多头注意力处理求和后得到嵌入向量,并进行残差求和及归一化解决深度神经网络中梯度消失问题,将结果通过一层前馈神经网络并进行残差求和及归一化,得到生成的隐层向量。
而BERT是基于fine-tuning的方法,它沿用了Transformer的多头注意力机制,能够捕获更为宽泛的文本语义特征,并结合遮罩语言模型任务和下一句预测任务进行预训练,BERT的输入形式如图3所示。
其中,中文BERT 的输入表示为词向量、句向量和位置向量三部分之和,每个输入序列的第一个标记[CLS]是一个特殊分类嵌入,用于分类任务中该句子序列的表示;句向量是用来区分句子序列的标记;位置向量包含模型学习到的位置信息。
2.2 CRF模型
在标签分类任务中,条件随机场模型相较于Softmax,能够充分考虑标签之间的依存关系,更适用于分词任务,因此现有的分词模型大都结合了CRF模型,它的模型结构如图4所示[15]。
假定组成句子的字序列长度为n,且字序列为X=(x1,x2,…,xn-1,xn) ,其对应的预测标签序列为Y=(y1,y2,…,yn-1,yn),预测序列标签总得分如公式(8)[14]所示:
其中,A表示标签之间的转移分数,Pi,yi表示每个字对应的预测标签yi的分数。
然后对所有的可能序列进行归一化,得到最大概率正确的序列,如公式(9)[14]所示:
2.3 基于BERT-CRF的领域词向量生成方法
基于BERT-CRF 的领域词向量生成方法是以领域分词为基础,将fine-tuning的领域字向量融合得到领域词向量,模型结构如图5所示。
由图5 可以看出,基于BERT-CRF 的领域词向量生成方法就是将训练数据转换成BERT 的输入表示并传入到BERT-CRF 模型中,用分词作为有监督信号,finetuning 得到基于BERT 的特征字向量表示,融合富含信息量的首尾字向量得到领域词向量。
3 实验与分析
3.1 实验数据集介绍
本文所使用的语料为《软件工程》(后称SED)领域文本,版本为《软件工程——理论与实践》(第2 版),通过人工方式将全书录为电子版文档,并手工标注领域词典,词典共计2 405 个领域词汇。首先将领域文本按句切分,确保切分后的句子长度不超过BERT的最大输入长度512;然后使用Jieba分词工具结合领域词典处理数据集,并对分词结果加上标签,标签采用B、M、E、S格式标注,其中B 表示非单字词的词头标签,M 表示三字词及以上的词中标签,E表示非单字词的词尾标签,S为单字词标签,例如:“软件”的标签为BE,“软件工程”的标签为BMME,“类”的标签为S。语料以“字 标签”格式存储,句子之间由空行切分,语料规模共5 303 句,并将语料文本按7∶2∶1的比例划分为训练集、测试集和验证集,语料统计如表2所示。
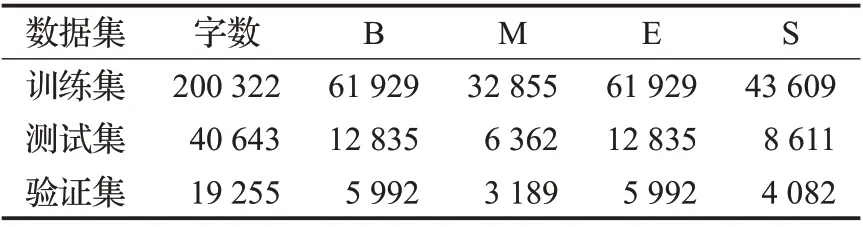
表2 SED领域语料数据统计Table 2 Corpus data statistics in SED field
3.2 实验设置
(1)实验模型的参数设置:训练输入序列最大长度为256,模型训练的batch_size为24,模型的学习率为3×10-5,CRF的学习率1×10-3,为防止过拟合,添加了Dropout层,Dropout 率为0.1,在BERT 模型配置文件config.json中添加参数output_hidden_states 和output_attentions 并设置值为True,即获取BERT的12个隐层向量以及注意力权重。
(2)环境设置:本文所提出的模型使用PyTorch 搭建,所使用的中文BERT是哈工大讯飞联合实验室发布中文BERT-wwm版本,该模型采用12层的Transformer,隐层维度大小为768,multi-head为12,模型的所有参数为110×106。本文将fine-tuning模型的12层隐层字向量和分词器预测标签同时作为领域分词器模型的返回参数,并根据模型分词标签,对字向量采用多种融合策略得到领域词汇的向量表示。
(3)评价指标:在对BERT-CRF 领域分词器实验效果进行评估时,对四种标签都采用了精确率(Precision,P)、召回率(Recall,R)、F1值(F1-score)作为评价指标。
3.3 实验结果分析
为了验证本文所提软件工程领域词向量生成方法的有效性,本文做了详细的对比实验分别对生成的领域词向量以及软件工程领域分词器的性能进行评估。
3.3.1 领域词向量的性能分析
为了更好地评估本文生成领域词向量的性能,本文分别采用聚类方法和词语相似度计算方法做了详细的对比分析。此外,本文也采用了具体的样例对比分析本文所提方法的有效性。
(1)融合策略分析
本文将SED 领域句子“软件开发模型有很多种,主要有瀑布模型、快速原型模型、增量模型、螺旋模型、喷泉模型、基于组件的开发模型、统一软件开发过程模型以及敏捷模型与极限编程等。”传入到原始BERT 模型和fine-tuning 模型,获取BERT 的12 层隐层字向量,将字向量采用不同策略进行融合得到领域词向量,对其中的“软件开发模型”和“增量模型”两个领域词向量进行相似度分析,如图6所示。
在图6中,“全字求和平均”表示采用词中所有字向量求和平均得到领域词向量表示,即“软件开发模型”的词向量表示是组成这个词的所有字向量求和平均的结果。“首尾字求和平均”表示采用首尾字向量求和平均得到领域词向量表示,即“软件开发模型”的词向量表示是首字“软”与尾字“型”的字向量求和平均的结果,“增量模型”同理,再将两个词向量表示计算余弦相似度,即为图中结果;实验表明,采用最后一层Transformer的隐层结果作为字向量表示所得到的结果均不理想;采用倒数第二层Transformer的隐层向量融合得到领域词向量表示最优,fine-tuning模型获得的词向量相对于原始BERT直接获得词向量的质量更高,并且基于“首尾字求和平均”获得的词向量避免了词中非关键字向量的影响,更具泛化性,获得的词向量质量高于“全字求和平均”的方式获得的词向量。本文后续实验均将倒数第二层字向量通过“首尾字求和平均”融合得到词向量进行研究。
(2)聚类分析
本文将学习到的领域词向量采用k-means聚类,聚类中心数为6,对领域词向量聚类结果进行分析,分析结果如表3所示。
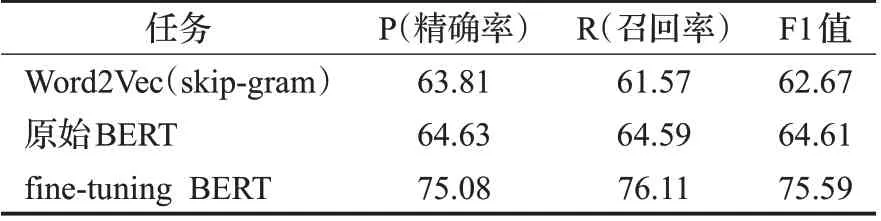
表3 词向量k-means聚类性能对比Table 3 Comparison of performance of word vector k-means clustering单位:%
由表3可以得知,fine-tuning模型的词向量k-means聚类在精确率、召回率、F1值三方面均比Word2Vec以及原始BERT融合的词向量有一定的提升,词向量质量更高。
为了进一步验证在SED领域内,基于BERT-CRF领域分词器作为下游任务获得的词向量表示质量高于原始BERT获得的词向量表示,采用“首尾字求和平均”策略融合倒数第二层Transformer的隐层向量获得领域词向量,使用主成分分析算法(PCA)对领域词向量进行降维,并进行词向量可视化展示对比,如图7所示。
从图7分析知,fine-tuning后的BERT模型获取的词向量的分布更合理,包含相近语义的词簇分布紧凑,聚类相对明显,在向量空间中,具有相同语义的词之间的距离也是相近的,例如,“字段”“索引”“触发器”等词都属于数据库中的领域专有词,所以它们聚为一类的概率更大。
(3)词语相似度计算的对比分析
由于基于“上下句”输入的BERT-CRF 领域分词器模型能够捕获更广泛的文本信息,其获得的词向量表示包含的语义信息理应更为广泛,其词向量质量也应该高于单句的词向量,本文对其进行了实验验证,选取了150个SED领域知识点,并分别计算它们与“增量模型”的相似度,按相似度远近,前12个领域词在向量空间中的分布如图8所示。按相似度排序结果如表4所示。
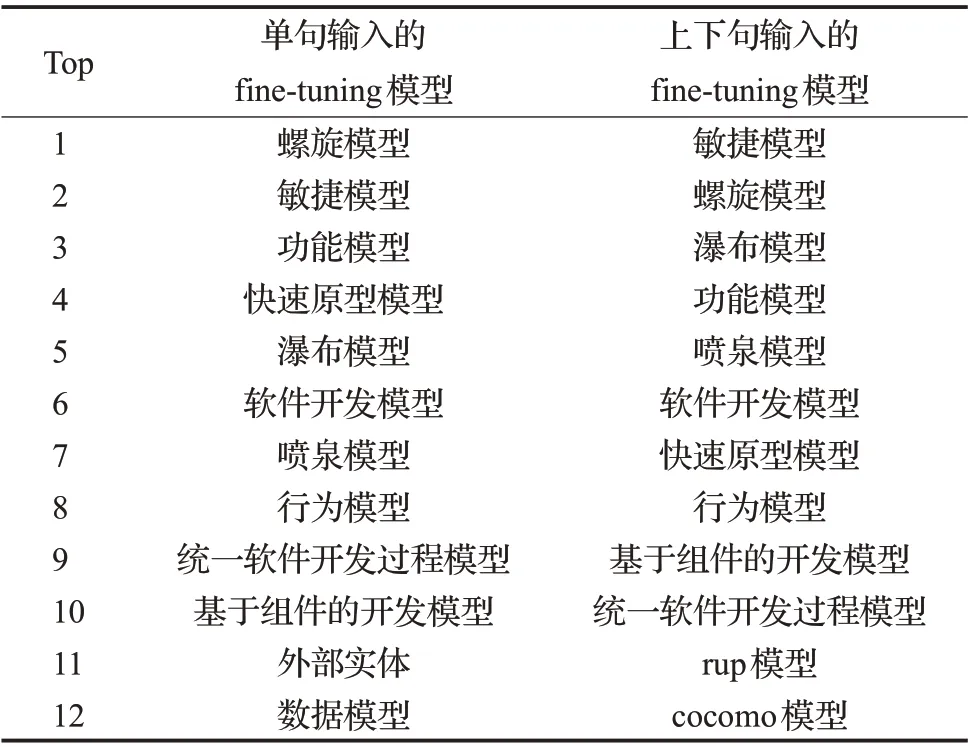
表4 与“增量模型”语义相似度排序对比Table 4 Comparison with ranking of semantic similarity of“incremental model”
在上下句输入的fine-tuning模型中,与“增量模型”相似度较高的词包含了“rup模型”,即“统一软件开发过程模型”,在一定程度上解决了“同义词”的问题,并且包含的相关词更多,证明上下句输入的fine-tuning模型能够捕获更多的语义信息,获得的词向量质量更高,并将fine-tuning模型的注意力机制可视化验证了本文结论如图9所示。
图9中例句在领域分词器的分词结果为“软件特点包括:软件是种逻辑实体,具有抽象性。”相对于原始BERT,fine-tuning模型的“抽”字注意力权重在“抽”“象”“性”三字上更大。原始BERT 在大规模语料下进行预训练具有一定的先验知识[16],但大规模的语料致使“抽”字的注意力权重分布宽泛;fine-tuning 模型在原始BERT基础上,结合CRF模型捕捉领域分词标签之间的依存关系,因而能感知到粗粒度的“抽象性”为一个语义整体,其领域词的平均多头注意力权重提升了4.96%。
(4)“一词多义”现象的样例分析
对于BERT模型词向量如何解决一词多义的研究,本文用“苹果”一词进行实验测试,实验样例如表5所示。

表5 一词多义实验样例Table 5 Example of polysemy experiment
获取fine-tuning 模型“苹果”的词向量,并用样例1与其余各样例中的“苹果”进行词向量的语义相似度计算,结果表6所示。
由表6分析可知,“苹果”的词嵌入对于每个句子都是不同的,这也是BERT 同Word2Vec 最重要的区别之一;一词多义问题在一定程度上得到了解决,对于主题分析等任务的研究,也具有重要的意义。

表6 “苹果”一词多义结果对比Table 6 Result comparison of polysemy of word“apple”
3.3.2 领域分词器的性能分析
(1)分词性能分析
在SED 领域数据集上,对BERT-CRF 领域分词器模型进行训练。BERT 的一种输入形式是“[CLS]Sentence[SEP]”,另一种输入形式是“[CLS]Sentence1[SEP]Sentence2[SEP]”,将单句数据集进行“两两合并”,即每两句采用第二种输入格式进行处理,这样做的目的是为了涵盖SED领域文本的所有上下句关系,对两种输入方式进行实验测试,并对训练后的领域分词器模型进行评估。实验结果如表7所示。
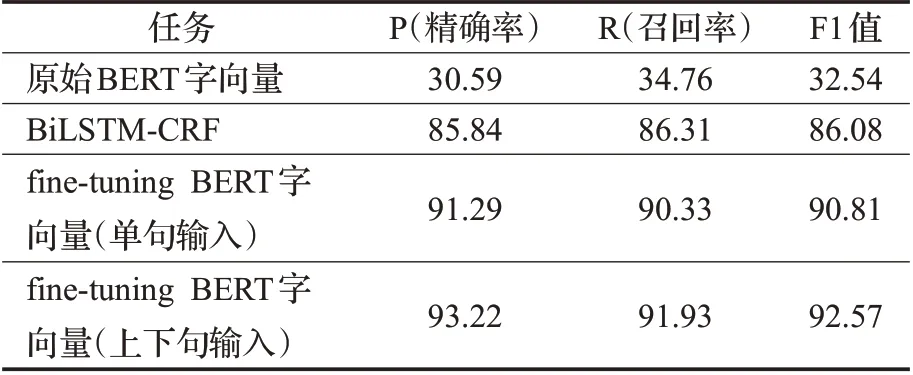
表7 BERT-CRF领域分词性能对比Table 7 Performance comparison of word segmentation in field of BERT-CRF单位:%
通过对表7 的分析,原始BERT 具有一定的先验知识[16],但将其直接应用在领域任务效果不佳;fine-tuning的BERT 模型能明显提升模型效果,其中,基于“上下句”输入训练得到的领域分词器模型的精确率、召回率,F1值都有所提升,相对于“单句输入”,其包含了语料中的上下文关系,训练得到的分词器模型质量更高。
(2)分词样例分析
然而对于领域分词和通用分词的标准不同,需要进一步对本文所涉及的领域分词器分词结果与数据集不一致的词进行对比分析,如表8所示。
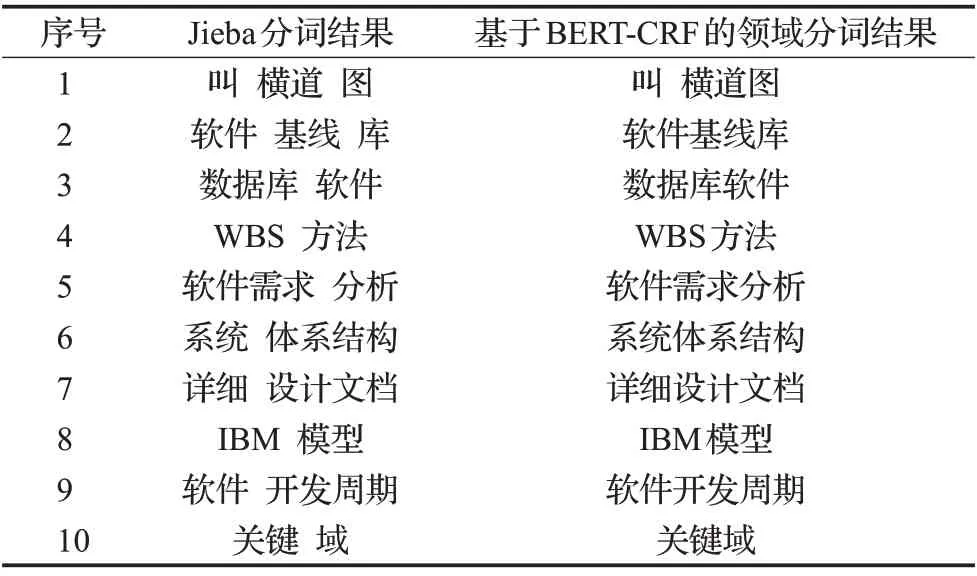
表8 Jieba分词器与BERT-CRF领域分词器分词结果对比Table 8 Comparison of word segmentation results between Jieba tokenizer and BERT-CRF domain-specific tokenizer
通过对表8 的分析,基于BERT-CRF 的领域分词器的分词粒度更大,更符合SED领域分词标准。对于一些未登录词,如横道图、关键域、软件开发周期等,相较于Jieba分词器,本文所提出的方法更有效地识别这些领域未登录词,对一些数据集标记不合理的词也能在BERT预训练模型的基础上减少这些噪声词对分词器模型的干扰。
4 总结与展望
本文采用BERT-CRF领域分词器模型,基于该模型提出了一种领域词向量的生成方法。该模型使用少量领域样本二次训练能获得包含领域词整体语义BERT字向量,根据字向量的分词标签采用“首尾字求和平均”策略对BERT 领域字向量进行融合获得高质量领域词向量表示。实验表明,这种基于BERT-CRF的领域词向量生成方法能获得比原始BERT 字向量更高质量的领域词向量,下一步将考虑将获得的BERT领域词向量应用在主题分析等任务上进一步提升主题表示性能。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
厦门大学学报(自然科学版)(2021年4期)2021-06-22
校园英语·月末(2021年13期)2021-03-15
电脑知识与技术(2019年23期)2019-11-03
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
长江学术(2016年4期)2016-03-11
人间(2015年21期)2015-03-11
长江学术(2015年1期)2015-02-27
外语教学理论与实践(2014年2期)2014-06-21
