
新闻知识图谱中知识融合量化评估研究
2022-11-16 02:25解天扬席晓桃
计算机工程与应用 2022年21期
解天扬,陈 明,席晓桃
1.上海海洋大学 信息学院,上海 201306
2.农业部渔业信息重点实验室,上海 201306
谷歌公司2012 年推出知识图谱(knowledge graph)[1-3],用可视化技术描述知识以及知识之间的关系,以(实体,关系,实体)或(实体,属性,属性值)的三元组形式保存在图数据库中。按照知识库数据来源可将知识图谱划分为通用知识图谱和领域知识图谱。通用知识图谱的数据来源于各大百科类网站,主要的应用场景为搜索引擎、个性化推荐以及知识问答。领域知识图谱的数据多为多源异构数据,数据模式无法预测,规模化扩展要求更迅速,知识结构更复杂,知识质量要求更高。Wfabc等[4]将计算机视觉算法与本体模型相结合,构建了工地危险检测知识图谱,对施工场所的高处坠落、沟渠和脚手架倒塌等危险进行防范,Zhao等[5]利用知识图谱对气候的时间分布、空间分布和研究热点进行可视化,探究了气候变化对人类健康的影响,Xiu等[6]利用中文电子病历构建了消化系统肿瘤知识图谱,确定了诊断与治疗的潜在的有效关系,Chun 等[7]构建了能源知识图谱作为能源系统知识资源整合的上层模式,解决了相关知识不能有效利用的问题,Tao等[8]从国家健康与营养调查(NHANES)的海量数据中抽取出医学领域知识,构建了医学知识图谱,通过发现人们潜在的疾病,对患者的健康风险进行分类,Li 等[9]利用膝骨关节炎患者电子病历文本构建了医学知识图谱,用于知识检索、决策支持等智能医疗应用,促进医疗资源共享。
新闻作为记录社会、传播信息、反应时代的一种文本,描述了新闻事件、热点话题、人物动态、产品资讯的最新进展。通过网页获取的新闻主要属性包括新闻标题、新闻摘要、URL地址、发布地区、媒体类型、媒体名称等。本文基于新闻的主要属性,将2019—2020 年长江大保护相关新闻作为数据源抽取实体对象,将新闻的URL地址作为实体,新闻属性作为边,新闻对应属性值作为实体属性的属性值,在此基础上构建了长江大保护新闻知识图谱。
在知识图谱构建的知识获取环节,由于知识源的数据误差或规范化表示时的疏忽,会对知识库的一致性和完备性产生影响,所以需要对当前的知识图谱进行知识融合及检验。在新闻知识图谱的构建中,由于新闻数据来源广泛,不同媒体发布的新闻存在标题不同内容相似的问题,导致知识库中的知识和规则存在冗余。因此在新闻知识图谱的构建过程中,需要对多源异构的新闻实体进行上下文关系识别以及实体对齐。
由于新闻数据噪声较大,现存的实体融合检验度方法大多是人工或半人工检验,通过句法检查和实例检验判断知识或规则之间否有冲突。对于数据量庞大的新闻知识图谱,现存融合度检验方法不具说服力,为此,本文提出了一种基于知识融合幂律分布的检验方法,对于同主题新闻的融合度检验具有较好的参考性。
1 知识融合验证研究
知识图谱中实体包含了大量的事实和数据,但是由于知识获取环节可能存在数据支撑不足或表达不全面的问题,导致知识图谱中实体存在异常或冗余现象,这些实体在描述内容上往往有重叠或关联,同名实例可能指代相同的实体,不同名实例也可能指向同一实体,因此在知识图谱的应用中,需要利用知识融合解决数据层的异构问题。
由于知识表示方法的多样性,无法对所有异常或冗余的实体给出知识异常表现形式,所以需要对融合后的知识图谱进行融合度检验,确认当前图谱的一致性和准确性,知识验证方法主要分为静态验证方法和动态验证方法。静态验证方法主要依据领域专家制定的知识图谱本体框架,人工从知识库中抽取知识进行验证,但是由于领域专家的很多知识都是经验性的,且不同的专家对于同一问题的见解可能存在差异,所以基于人工验证的静态方法对融合度的验证存在很大困难。动态验证方法包括基于决策表的方法、基于Petri 网的方法[10]、基于贝叶斯的方法[11]、基于马尔可夫逻辑网络的方法[12]、基于概率软逻辑法的方法等[13],这些动态验证方法大多基于逻辑构建相应规则,对知识库中的矛盾和冗余进行检测,主要检测内容包括多余规则、冲突、循环、多余条件、不可达目标以及死终结。
现阶段对于知识图谱融合度的检验对象一般为通用知识图谱,其知识数据源结构规整、覆盖面广且具有权威性,可以根据数据来源对知识和规则赋予权重。然而对于新闻而言,由于没有统一格式,定义规则的难度较大,尤其是时政新闻中存在大量时政相关谓词,如贯彻落实、战略、建设等,制定规则并赋予权重时没有明显差距,导致运用逻辑和权重进行融合度检验不具有说服力。
2 新闻知识图谱融合量化评估研究
将图论的基本概念映射到新闻知识图谱中,知识图谱中的实体对应图中的节点,关系对应图中的边,节点相关联边的条数对应节点度,其中边的两倍等于节点度的和,例如对于(长江禁捕湖北在行动,媒体名称,荆楚网)三元组,“长江禁捕湖北在行动”和“荆楚网”为节点,“媒体名称”为边,节点度为2。对此本文提出以下定理:
定理1 新闻领域知识图谱经过知识融合后,节点的分布符合幂律分布定律。
证明 当两条新闻内容相关时,存在以下两种情况:(1)标题和摘要均相似或相同;(2)标题不同,摘要相似或相同。因此,当新闻摘要的内容相似或相同时,两条新闻可以进行节点的融合。
上述两种情况可以被具体抽象成以下规则:根据语义相似度对知识图谱进行知识融合时,节点之间的语义相似度越高,节点的融合度越高,融合后相似的节点数越少,融合后的节点数符合幂律分布定律。如图1所示为知识融合前的新闻图谱,其中新闻A 为《泰州召开长江重点水域禁捕工作推进》,新闻B为《泰州长江重点水域禁捕工作推进会召开》,新闻A、B的摘要节点内容相似,语义相似度高。图2所示为新闻A和新闻B融合后的知识图谱。
知识图谱对两个相似节点进行知识融合后,相比融合前的图谱,在新生成的知识图谱中节点数目减少1,度增加1,边增加1。故设图谱的节点为i,边为e,节点度为ki,由于节点度之和等于边数和的两倍,对节点i进行归一化处理,将数据映射到(0,1)之间进行处理,使当前图中所有节点度概率之和为1,得出以下关系:
当新闻知识图谱B融合到新闻知识图谱A时,根据语义相似度对节点进行知识融合,融合后的节点度k增加1,节点i减少1,导致p( )i发生变化,新闻A、B 的节点和边的分布情况如图2所示。因此,融合后的节点度概率满足以下关系:
对公式(2)进行递推,等式两边同时进行求和运算,得到公式(3),简化后得到公式(4):
根据辛钦大数定律,在n→∞时,每次添加相关新闻后,该节点度的概率随之发生变化,取其算数平均值后得到:
此时节点i的节点度概率趋近于算数平均值,即节点i的节点度真实概率趋近于kˉ,即公式(6):
上文得到公式(8)与幂律定律公式f(x)=αx-3相似,即在知识图谱进行知识融合后,图谱中的节点分布满足幂律分布定律,融合后的节点概率与度的数量成反比,其物理意义是,在新闻领域知识图谱中,摘要之间的语义相似度越高,则两个图谱对应节点的融合度越高,融合后的节点数越少。在新闻领域知识图谱融合度检验中,通过观察模型的拟合度是否符合幂律分布定律,可以确定当前图谱是否需要进一步进行节点融合。
3 实验验证与结果分析
3.1 新闻数据融合
新闻作为记录社会、传播信息、反应时代的一种文本,描述了新闻事件、热点话题、人物动态的最新进展。通过网页获取的新闻主要属性包括新闻标题、新闻摘要、URL地址、发布时间、发布地区、媒体类型、媒体名称等。由于新闻存在被广泛转发的可能性,新闻标题不能明确具体到某条新闻,但是URL 地址作为确定互联网上信息位置的标准资源地址的唯一标识,可以为每篇新闻提供不同的URL 地址,因此本文基于新闻的主要属性,使用URL 地址作为本体的父节点,确定了如图3 所示本体结构,将2019—2020 年长江大保护相关新闻作为数据源抽取实体对象,将新闻URL地址作为实体,新闻属性作为边,新闻对应属性值作为实体属性的属性值,在此基础上构建了长江大保护新闻知识图谱。
网络新闻的属性中,URL 地址、发布地区、媒体类型、媒体名称作为属性不能体现新闻本身的内容,且相关性较低,例如对于发布地区这一属性,位于北京的媒体可以发布关于上海的新闻,若在图谱融合时针对地域和媒体进行知识融合,得到的图谱不能体现长江大保护的关注热点和具体政策,所以本文对新闻摘要进行关键词提取,通过计算摘要关键词之间的语义关系,对知识图谱进行融合,为后续知识图谱融合量化评估提供便利。
无监督学习方法中主要包括基于统计特征的关键词提取,如TF 和TF-IDF[14-15],基于词图模型的关键词提取,如PageRank[16]和TextRank[17],基于主题模型的关键词提取,如隐含狄利克雷分布(latent Dirichlet allocation,LDA)[18],其中TF-IDF对于短文本的提取效果不理想且没有考虑语义信息,对于关键词的提取仅停留在表面信息;LDA的随机向量各分量之间的弱相关性,导致潜在主题之间几乎是不相关的,与本文主题均为长江大保护并不相符,且LDA不考虑词与词之间的顺序,更偏向于提取一般关键词,不能很好地代表文本主体;TextRank的关键词提取方法可以考虑语料中的语义信息,对于主体类文本的提取能力较强,因此本文选用TextRank进行长江大保护新闻摘要关键词提取。
TextRank 的思想来源于谷歌的PageRank 算法,用句子的相似度代替网页的转移概率,其主要任务是将新闻摘要T分割成若干个词汇,即T=[S1,S2,…,Sm],过滤掉停用词后,对于句子中的成分进行词性标注,保留特定词性的词汇,例如在本文的关键词提取中,保留的名词包括江豚、自然等,动词包括禁捕、退捕等。一般模型可以表示为一个有向有权图G(V,E),其中V为节点集,表示分词后的关键词候选词T=[S1,S2,…,Sm],对于图G中的任意一个节点Vi存在分值WS的值如公式(9)所示:
其中,In(Vi)表示指向Vi的节点,Out(Vi)表示Vi指向的节点,wji表示Vi→Vj的边的权重,根据公式对各节点的权重进行计算,迭代至算法收敛后利用投票机制对摘要成分的权重进行排序,从而得到新闻中最具有概括性的关键词,将关键词权重降序排列,取前30个词作为本文的长江大保护新闻关键词。
由于新闻关键词可以体现新闻的内容及特征,某些主题词出现次数较多的新闻内容相似,可以在新闻知识图谱中对节点进行知识融合。若两篇新闻摘要相似度较高,则其特征向量在某几个维度的值较大,而在其他维度的值较小;反之,如果两篇新闻不属于同一类,由于关键词不同,则特征向量中值较大的维度交集较少,因此通过比较特征向量的相似性可以得出文本内容是否接近。目前计算文本相似度的主要方法包括Simhash算法和计算余弦距离,由于Simhash 算法[19]的主要思想是通过降维,将高维的特征向量映射成一个f-bit的指纹(Fingerprint),通过比较特征之间f-bit 指纹的Hamming Distance 来确定文本内容是否重复或者高度近似,通常适用于计算长文本相似度以及网页去重,对短文本的误判率较高。本文的新闻摘要文本长度适中,进行分词后的语序不基本影响新闻内容,因此对于此类新闻摘要选择计算余弦距离,余弦距离计算公式如公式(10)所示,相似度结果如表1所示。
3.2 新闻融合度验证
对2019年至2020年的新闻摘要进行摘要关键词提取和关键词语义分析,以长江大保护中的代表政策“十年禁渔”为衡量标准,对抽取出的关键词相似度进行标准化处理,若一篇摘要中同时包含两个以上关键词时,则将与“十年禁渔”相似度更高的候选词作为新闻的关键词,表1 所示为长江大保护新闻关键词相关数据,其中x(%)表示包含关键词的新闻与“十年禁渔”新闻之间的语义相似度;w表示图谱进行知识融合后,包含关键词的新闻个数;y(%)表示包含关键词的新闻数量在新闻总数中的占比。
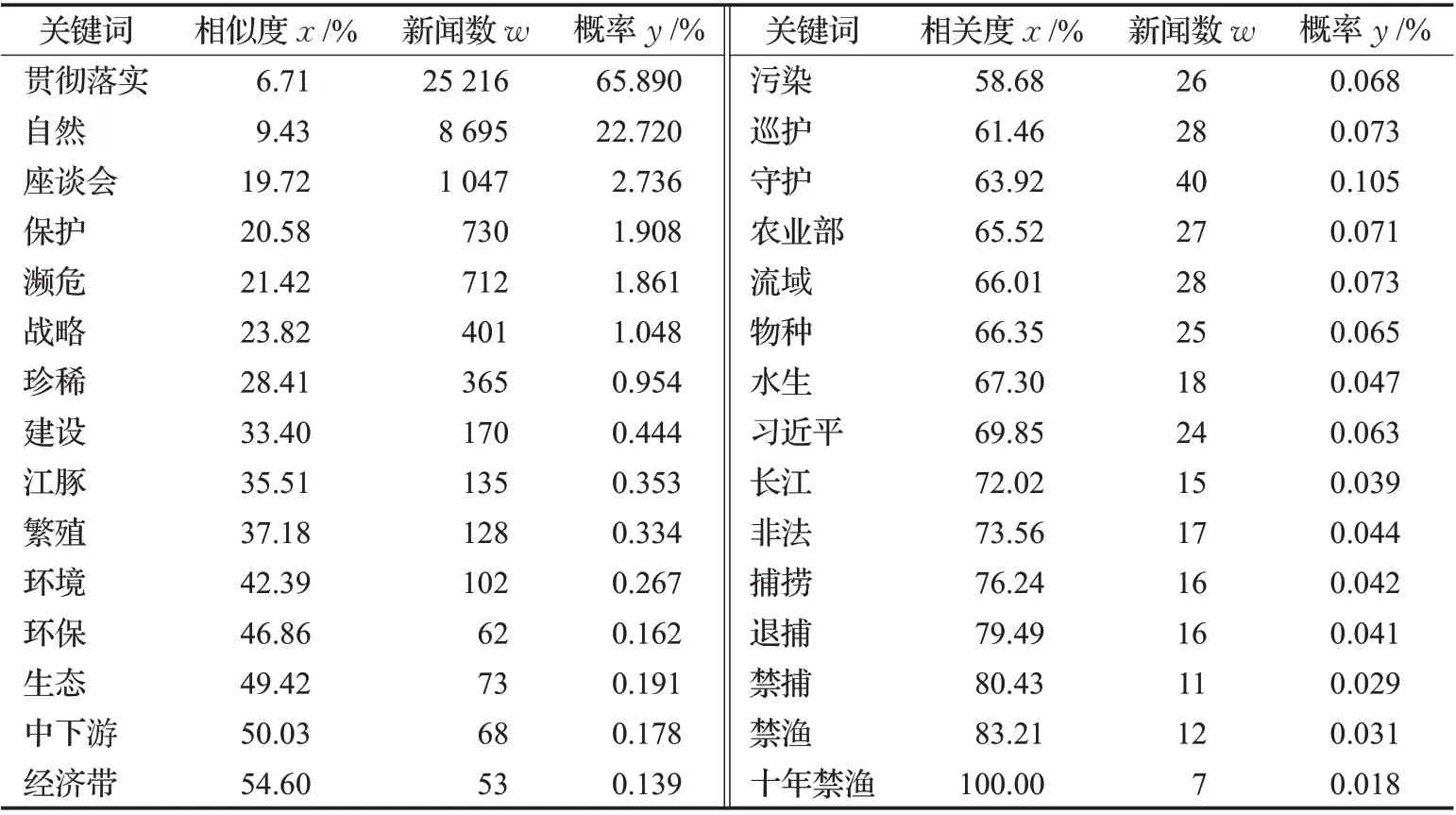
表1 长江大保护新闻关键词相关数据Table 1 Related data of keywords in news of great conservation of Yangtze River
3.2.1 实验过程
假设概率y和关键词相似度x的常数幂存在简单的比例关系:
由于模型II为非线性回归模型,故对于随机误差不做如同如上所述的假设。
3.2.2 分析方法
本文运用线性最小二乘法和非线性迭代计算方法[20],利用R 软件工具,选用调整决定系数R2来表示模型与样本数据的拟合程度,实验结果如表2所示。

表2 两种模型分析结果及其检验Table 2 Two models analysis results and test
模型I:对概率值y和语义相似度x取对数变换,然后对线性方程lny=lnk+qlnx做回归拟合,线性回归采用最小二乘法。由结果可知,模型I拟合优度良好,调整决定系数R2a=0.992 7;经t检验,模型参数q和k显著模型拟合可行,如表3所示。

表3 模型参数检验Table 3 Test of model parameters
模型II:利用概率值y,采取迭代计算的方法,对方程y=f(x)=kxq进行非线性回归,经过13次迭代,模型收敛,故模型稳定。
如图4所示为模型I的残差图,其中x轴为lnx,y轴为残差值,由于lnx的分布不均匀,故lnx较小时图中可见的数据点较少。除此之外,残差分布较随机,没有明显的图案或趋势。已知x的分布较为均匀,且x=elnx。
为了确保上述分析的可靠性,重新绘制残差图如图5所示,其中x轴为语义相似度x,y轴为残差值,由此可得,样本数据正常,没有明显异常值,模型拟合良好。
3.3 结果分析
Zipf 定律和Pareto 定律统称为幂律分布规律,幂律定律广泛存在于计算机科学、经济与金融学、地球与行星科学、人口统计学等众多领域中,其分布共性是绝大多事件的规模都很小,只有少数事件的规模相当大[21]。幂律分布的累计函数在尾部其概率密度值衰减缓慢,呈现“长尾分布”的特征,如图6所示为长江大保护新闻知识图谱原始数据,其中横坐标x为新闻相似度,纵坐标y为概率。为使数据分布更加清晰,删除概率y为65.89%和22.72%的极值点,得到结果如图7所示。对通式公式两边取对数,易得lny与lnx满足线性关系,表现为图像为一条斜率为幂指数的负数的直线,如图8所示为融合后的新闻数据在双对数坐标下与模型I和模型II的数据对比。
由此可以得出,长江大保护新闻知识图谱融合度高,在知识融合时符合幂律分布规律,其物理意义是,知识融合后,相关度低的新闻的节点数多、规模大,随着新闻相关度的升高,知识融合度增加,节点数快速减小,由f(λx)=k(λx)q=kλqxq=λq f(x) 得,当x增加λ倍时,f(x)下降λq倍。
4 结论
本文提出了一种基于语义相似度的新闻知识图谱中知识融合量化评估标准,新闻新闻知识图谱中节点根据语义关系进行融合后,节点的分布符合幂律分布定律。本文用2019—2020年长江大保护相关新闻构建了知识图谱,对提出的定理进行了验证,在对知识融合时发现,随着图谱中节点相似度的提高,节点之间的融合度也随之提高,节点数快速减少,此定理经验证正确。
本文的研究中还存在一些不足:一是在新闻提取中,仅选用了2019—2020 年的长江大保护相关时政新闻,且由于时政新闻的特殊性,大多是由官方新闻网站进行发布,其他平台进行转发,存在大量新闻相似度高的情况,更换新闻数据源后的情况有待进一步深入分析;二是本文提取的关键词数量不多,对于简单的幂律现象可能存在普适性,对关键词进行进一步提取和细分可能符合更复杂、更合适的幂律分布模型。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
北京航空航天大学学报(2022年8期)2022-08-31
乡村科技(2021年22期)2022-01-06
智富时代(2019年7期)2019-08-16
智富时代(2019年7期)2019-08-16
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
新城乡(2018年6期)2018-07-09
财讯(2018年28期)2018-05-14
领导科学论坛(2016年9期)2016-06-05
