
基于改进YOLOv5 的O 型密封圈缺陷检测方法
2022-11-24 03:31朱文博夏林聪吴晨睿陈红光
上海理工大学学报 2022年5期
朱文博, 夏林聪, 陈 龙, 吴晨睿, 陈红光
(1. 上海理工大学 机械工程学院,上海 200093;2. 上海贝特威自动化科技有限公司,上海 201109)
机器视觉检测技术具有非接触、可在线、客观、自动化等突出优点[3-4],适合现代制造业的产品检测[5]。但应用到O 型圈缺陷检测时,由于其缺陷像素占比不到整张图像像素的0.5%,造成模型可用的分辨率有限和特征不明显,导致小缺陷检测困难[6]。模板匹配法[7]通过计算缺陷的周长或面积来判断缺陷是否在规定范围内,从而确定其有无异常。文献[8]使用面积法检测表面缺陷,计算各个连通区域的面积,通过设定相应阈值来判断缺陷。文献[9]将获得的图像进行奇异值分解,通过奇异区域检测缺陷。以上传统图像处理的方法主要适用于O 型圈的边缘检测或者对特定类型的缺陷进行单独检测,其缺点是难以设计一种或多种算法来全面满足各种缺陷同时检测的要求。
近年来,基于卷积神经网络的深度学习算法在检测领域得到较多应用[10],例如双阶段检测算法中的Faster R-CNN[11]和R-FCN[12],单阶段检测算法中的SSD[13]和YOLO[14]。但是,对于具体实例,尤其是小特征缺陷检测很难取得令人满意的效果[15]。针对较小特征的检测,文献[16-17]围绕图像特定区域进行处理,聚焦于双阶段检测算法,以牺牲推理时间来实现更好的性能,因而难以满足实时检测要求。YOLOv5 是一种单阶段检测算法[18],结构清晰灵活,计算量小,识别速度快,检测性能好,但对于检测较小的物体时精度较低。
本文提出一种基于改进YOLOv5 的O 型圈缺陷检测算法,相比上述传统图像处理算法,该算法可同时全面地检测多种缺陷,通过在网络的预测层嵌入标签平滑模块[19]来解决模型对标签的过度依赖问题。在骨干网络中添加卷积注意力机制[20]和在颈部结构中引入剪枝的双向特征金字塔网络[21],能使该算法对相似缺陷和小特征缺陷进行较高精度的检测,满足工厂对不同类型缺陷进行分拣的要求。并且,该算法可随时添加新的缺陷类型,有助于后续工作的展开,拥有较强的工艺柔性。
1 数据准备和预处理
1.1 数据集准备
通过工业相机采集全部O 型圈图像,数据采集装置如图1 所示,采集图像的原始分辨率为1 256×1 080,将筛选出存在缺陷的5 000 张图像中的2 000 张进行人工标注,其中1 500 张作为初始训练集,剩余500 张作为测试集,测试集中的缺陷类型和数量如表1 所示。测试集虽是人工标出缺陷,但在测试过程中只需将预测结果与人工标注的真实框对比计算即可。

图1 数据采集装置Fig. 1 Data collection

表1 测试集中的缺陷类型及数量Tab.1 Number of defects in the test set
半自动标注示例如图2(a)所示,利用初始权重自动推理出孔洞和刮蹭的标注信息,即自动完成部分缺陷标注。其中,孔洞边界框不够紧致,需要人工微调,红色框内的凸起缺陷为漏检情况,需要人工补充。同理,将待标注的3 000 张图像使用半自动标注方法进行粗标注。首先,通过YOLOv5 将3 000 张图像进行预测,得到预测框和类别,对预测模块的功能进行改进,将预测标签信息导入Labelimg 模块中,即生成粗标注数据。最后,在Labelimg 模块中通过人工微调及补充标签的方法得到标注数据集。数据标注流程如图2(b)所示。
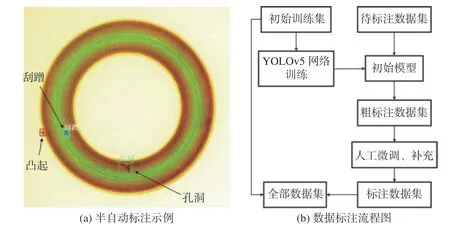
图2 半自动标注示例与数据标注流程Fig.2 Semi-automatic annotation example and data annotation process
1.2 数据增强
在实际情况中,数据标注成本昂贵,创建虚拟数据并添加至训练集是减少标注成本的最佳方法。YOLOv5 使用了Mosaic 数据增强方法,即4 张图像进行随机裁剪、缩放等操作后随机拼接成一张新的图像,增加小目标样本的数量,在进行归一化操作时,会一次性计算4 张图片,提升网络训练速度。
由于采集得到的O 型圈缺陷图像有限,但实际制造中产生的缺陷千变万化,并且其表面存在的缺陷通常不是单一类型的,可能存在多类型多数量的缺陷,因此提供给模型不同形态的缺陷数据越多,检测结果越准确。本文改进Mosaic 方法,称之为Mosaic-9,流程图如图3(a)所示。从数据集中随机抽取9 张图像作为Mosaic 数据增强原图,9 张图像拼接的方法采用随机裁剪5%~25%;由于缺陷在原图像的占比较小,对9 张原图随机缩放的程度不宜过高,避免小型缺陷的特征丢失,采用随机缩放原图像60%~110%。将9 张图像随机裁剪缩放后拼接成一张新的图像,具体实现方法如图3(b)所示。

图3 Mosaic-9 数据增强方法Fig.3 Mosaic-9 data enhancement method
1.3 超参数优化
超参数优化方法可分为两类:一类为可视化优化方法,比如Zeiler 等[22]利用反卷积可视化AlexNet 网络;另一类为自动超参数优化方法[23],其中,网格搜索通过穷举的方式遍历参数的取值范围,具有简单、直观、全局优化的特点,适合低维度参数寻优,且不会陷入局部最优。本文采用网格搜索的方法来寻找最优的超参数数值。合适的超参数可以很快地达到训练效果,并且训练权重更加符合O 型圈表面缺陷的检测。YOLOv5微调了29 个超参数,与默认超参数的模型相比,最终测试集上的检测正确率提高了2.17%。超参数优化结果如表2 所示。

表2 超参数进化结果Tab.2 Results of hyperparametric evolution
2 改进的YOLOv5

2.1 标签平滑
标签平滑最早应用于分类算法中,之后才引入目标检测算法中,它们都在网络预测层中使用交叉熵损失。对于每一个输入样本x,损失函数Li和yj的计算方式如下所示[19]:
193 Application of magnetic resonance imaging in diagnosis of breast cancer: an update
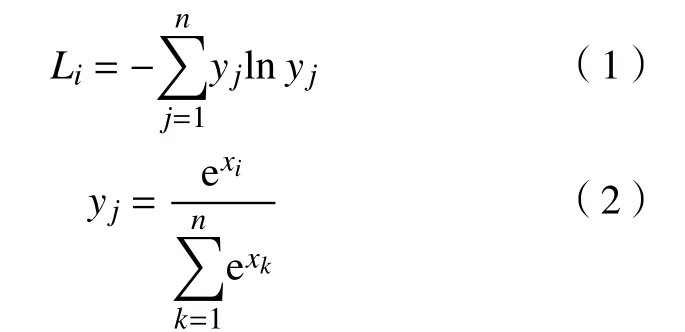
式中:yj表 示模型的输出;n为 样本数量;j和k为初始值为1 的两个变量。
通过式(2) 可知,在交叉熵损失的计算过程中,模型会不断调整权重,使预测结果尽可能地接近0 和1。除此之外,YOLOv5 在生成真实标签的时候,存在偏差,因此通过自动标注获取的标签容易产生错标。针对此问题,在计算交叉熵损失的过程中引入了标签平滑技术。交叉熵损失的计算公式为[19]

基于实验结果,将 ε值设置为0.1。通过引入标签平滑机制,模型在训练过程中不会拟合0 和1 这样的极端值,避免了过拟合的现象,并在一定程度上提升了模型的泛化能力和学习速度,有益于O 型圈数据半自动标注的效果。
2.2 骨干网络改进
在实际O 型圈检测场景中,由于光照环境、缺陷相似及缺陷尺寸范围变化明显的影响,常规的目标检测算法受到置信度的影响,易出现漏检部分缺陷从而造成损失。为了让骨干网络学习到更加细致的局部特征信息,并融合全局信息作出更加准确的判断,避免误检测和漏检测,本文对YOLOv5 的骨干网络进行改进,在每一个跨阶段连接网络(cross stage partial,CSP)结构之后引入一个卷积注意力机制模板(convolution block attention module,CBAM),CBAM-Backbone模块如图4所示。

图4 CBAM-Backbone 模块Fig.4 Convolution block attention module-backbone module
卷积注意力机制模块可以在通道维和空间维分别推断出注意力的权重,使模型在训练过程中会重点关注缺陷区域,提取缺陷区域中更加全面的特征信息,加大特征提取网络的全局感受野,增强特征提取能力,有效地减少环境背景和相似缺陷对O 型圈表面缺陷检测的影响。
通道注意力模块对输入特征图分别进行全局平均池化和全局最大池化来聚合图像的空间信息,经过2 个多层感知机结构构建模型之间的相关性,最后经过Sigmoid 激活函数获得每一个通道的权重。其表示形式为[20]


空间注意力模块将通道注意力模块中的输出作为输入特征图。首先,对输入特征图做一个基于通道的全局平均池化和全局最大池化,将2 个单通道特征图进行拼接;然后,通过一个7×7 的卷积对特征图进行降维,获得一个单通道特征图,便于特征融合;最后,经过Sigmoid 激活函数获得图像空间位置的每一个特征权重。对各个通道的特征进行加权操作,增强各个通道的信息交互,强化有效信息,抑制无效信息。其表示形式为[20]

2.3 颈部结构改进
O 型圈表面不仅存在孔洞、亮斑和褶皱等尺度变化范围大的缺陷,还存在断裂和划痕等特征相似的缺陷。为了更好地进行不同尺寸的特征融合,捕捉小缺陷和相似缺陷的具体特征,提出剪枝的双向特征金字塔网络(bidirectional feature pyramid network,BiFPN)颈部结构,双向特征金字塔网络和剪枝的双向特征金字塔网络结构如图5(a)和(b)所示。

图5 BiFPN 和剪枝的BiFPN 结构对比Fig.5 BiFPN and pruning BiFPN structure comparison




图6 改进的颈部结构Fig.6 Improved neck structure

3 实验分析与结果
3.1 实验分析
改进的YOLOv5 模型搭建完毕,通过计算机完成相应实验,计算机的具体配置如表3 所示。利用训练集对改进的YOLOv5 作训练优化,实验采用随机梯度下降法,具体参数如表4 所示。准备待测试的图像数据,将其全部放入改进的YOLOv5 中,通过向前传播过程获取一个测试结果,将图像标签与测试结果作比对,计算出测试精度指标。

表3 实验平台相关配置表Tab.3 Configuration table of experimental platform

表4 模型训练参数Tab.4 Model training parameters
3.2 实验结果
在完成一轮训练并更新参数后,都要完成相应测试来检验此模型的泛化性和稳定性。如图7所示,box_loss 表示标签中边界框中心点横纵坐标x,y和宽高w,h带来的误差,class_loss 表示类别带来的误差,mAP_50 表示交并比取50%时的平均精度均值。

图7 训练评价指标Fig.7 Training evaluation index
不同算法实验结果对比如表5 所示,针对各个缺陷类型,分别使用SSD,YOLOv5 与改进的YOLOv5 进行对比,改进的YOLOv5 检测效果整体优于SSD 算法和YOLOv5 算法,其平均精度均值比SSD 算法高出5.93%,比YOLOv5 高出4.26%。在实际检测过程中,需要排查少数有缺陷的O 型圈,因此,将候选框阈值适当降低来严格筛查有缺陷的O 型圈,可以接受将少数无缺陷的O 型圈误检测为有缺陷以保证实际应用价值。经测试,本文所述改进的YOLOv5 召回率为94%,而SSD,YOLOv5 检测召回率分别为83%和86%。YOLOv5与改进的YOLOv5 检测结果示例如图8(a)和(b)所示,对于一些较小的缺陷,YOLOv5 出现漏检情况,而改进的YOLOv5 可以检测出较小缺陷的种类且精度符合实际应用要求,其推理时间由15 ms增加至24 ms。但在实际的转盘机分拣系统中,当检测时间不超过30 ms 时满足正常分拣要求。

表5 不同算法实验结果对比Tab.5 Comparison of experimental results of different algorithms

图8 检测结果图Fig. 8 Test result diagram
3.3 消融实验
为了更好地说明改进的YOLOv5 中各个改进模块对检测效果的影响,在自制的O 型圈数据集上进行消融实验,结果如表6 所示。基于标签平滑方法的YOLOv5 网络可以有效避免模型对半自动标注标签的过度依赖,与YOLOv5 相比,其平均精度均值提高了1.62%。通过添加CBAM 注意力机制训练,获取更多重点关注目标的细节信息,抑制其他无用信息,该模块将平均精度均值从94.85% 提高到95.92%。将引入标签平滑方法和CBAM 注意力机制的YOLOv5 网络融入剪枝的双向特征金字塔网络结构,平均精度均值从95.92%提高到97.49%。结果表明,改进后的特征融合网络结构可以有效检测O 型圈表面的各种缺陷,提高网络的检测精度。

表6 自制O 型圈数据集上的消融实验Tab.6 Ablation experiments on a self-made O-ring dataset
4 结束语
针对O 型圈表面缺陷检测,提出一种改进的YOLOv5 卷积神经网络模型,其性能优于原YOLOv5网络模型,有效地提升了检测O 型圈表面缺陷的精度,为O 型圈的智能分拣提供了一种可行的方法。本文通过改进Mosaic 数据增强算法增大了小目标的数据量,减少批标准化计算的次数。在网络预测层使用标签平滑方法进行标签修正,有效提升了模型的泛化能力。针对原算法出现误检测和漏检测的情况,提出骨干网络中添加卷积注意力机制模块的策略,捕捉更多缺陷细节,融合全局信息对缺陷作出更加准确的判断。为了解决图像中小缺陷在特征提取过程中特征丢失的问题,通过剪枝的双向特征金字塔网络结构来加强对小缺陷的特征融合,将小缺陷的检测率由89.46%提升至94.35%。在后续的研究中,将利用各种加速方法,在保证检测精度的前提下,提高算法的运行速度,以适应更为严苛的工业应用环境。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
数学小灵通·3-4年级(2017年9期)2017-10-13
公民与法治(2016年10期)2016-05-17
少儿科学周刊·少年版(2015年2期)2015-07-07
河南科技(2014年23期)2014-02-27
