
基于负边距损失的小样本目标检测
2022-11-30 08:39杜芸彦李鸿杨锦辉江彧毛耀
计算机应用 2022年11期
杜芸彦,李鸿,杨锦辉,江彧,毛耀*
基于负边距损失的小样本目标检测
杜芸彦1,2,李鸿1,2,杨锦辉1,2,江彧1,2,毛耀1,2*
(1.中国科学院大学,北京 100049; 2.中国科学院光束控制重点实验室(中国科学院光电技术研究所),成都 610207)(∗通信作者电子邮箱maoyao@ioe.ac.cn)
现有的大部分目标检测算法都依赖于大规模的标注数据集来保证检测的正确率,但某些场景往往很难获得大量标注数据,且耗费大量人力、物力。针对这一问题,提出了基于负边距损失的小样本目标检测方法(NM‑FSTD),将小样本学习(FSL)中属于度量学习的负边距损失方法引入目标检测,负边距损失可以避免将同一新类的样本错误地映射到多个峰值或簇,有助于小样本目标检测中新类的分类。首先采用大量训练样本和基于负边距损失的目标检测框架训练得到具有良好泛化性能的模型,之后通过少量具有标签的目标类别的样本对模型进行微调,并采用微调后的模型对目标类别的新样本进行目标检测。为了验证NM‑FSTD的检测效果,使用MS COCO进行训练和评估。实验结果表明,所提方法AP50达到了22.8%,与Meta R‑CNN和MPSR相比,准确率分别提高了3.7和4.9个百分点。NM‑FSTD能有效提高在小样本情况下对目标类别的检测性能,解决目前目标检测领域中数据不足的问题。
目标检测;小样本学习;负边距损失;度量学习
0 引言
近年来,为了解决目标检测中数据量不足的问题,越来越多的研究人员尝试将FSL与目标检测方法相结合。通过对数据、训练策略、模型结构以及损失函数等部分的巧妙设计,使模型仅采用少量标注样本就可以快速学习到具有一定泛化性能的检测模型。现有的大部分小样本目标检测方法主要可分成三类:基于微调的方法、基于度量学习的方法以及基于模型结构的方法[31]。
基于微调的方法是采用大量标注数据训练得到预训练模型,并用该模型参数初始化目标域模型,最后再根据新类的少量标注样本进行微调。在文献[32]中,小样本迁移检测器(Low‑Shot Transfer Detector, LSTD)模型利用SSD设计边界框回归,利用Faster R‑CNN设计目标分类;同时提出了基于源域和目标域的转移指数(Transfer‑Knowledge, TK)以及背景抑制(Background‑Depression, BD)的正则化方法。TK主要在目标提案中迁移标签知识,BD主要是用边界框来做特征图的额外监督,以此来抑制背景的干扰。在文献[33]中,首先使用目标检测网络对前景区域进行提取,然后借助纹理特征等训练更为准确的分类器,同时采用文献[32]中的正则化方法去提高模型的泛化性能。
一些研究人员将属于度量学习的FSL方法引入目标检测领域也取得了良好的效果。在文献[34]中引入了贝叶斯条件概率理论,提出了单样本条件目标检测(One‑Shot Conditional object Detection, OSCD)框架。首先采用孪生网络进行特征采样,然后将两个特征融合输入条件区域候选网络(Conditional‑Region Proposal Network, C‑RPN)中计算感兴趣区域(Region of Interest, ROI)相似度和边界框,再把相似的区域用在条件分类器(Conditional‑Classifier, C‑Classifier)进行相似度计算和边界框计算。文献[35]中提出了一种新的距离度量学习(Distance Metric Learning, DML)方法,在一个端到端的训练过程中,同时学习主干网络参数、嵌入空间以及该空间中每个训练类别的多模态分布,并将提出的DML架构作为分类头合并到一个标准的目标检测模型中实现对小样本的目标检测。文献[36]中提出了对比提议编码(Contrastive Proposal Encoding)进行小样本目标检测,利用对比提议编码损失使同簇更紧密、不同簇之间距离增大,提高了检测模型在小样本设置中的通用性。
基于模型结构方法是通过重新设计模型结构实现小样本目标检测。文献[37]中提出了元学习小样本检测(Few‑Shot Detection, FSD)框架,该框架包含一个元学习器和一个目标检测器。元学习系统从一系列的FSD任务中学习一个元学习器,可以指导检测器如何在一个新的小样本任务中快速准确地更新网络。文献[38]中提出了一个基于Faster R‑CNN的小样本目标检测(Few‑Shot Object Detection, FSOD)模型,该模型在区域候选网络(Region Proposal Network, RPN)中加入了注意力机制,并使用多关系检测器作为分类器,同时提出了一种对比训练策略,使检测器拥有判断相同类和区分不同类的能力。
1 FSOD模型
FSOD模型的总体框架[38]以Faster R‑CNN为基础。在此基础上,加入了注意力区域候选网络(Attention‑RPN)和多关系检测器(Multi‑Relation Detector),图1为FSOD的总体结构。
多关系检测器通过计算支持图像特征和查询图像特征的相似性,留下相似性高的区域,剔除相似性低的区域,以此得到更准确的候选区域。其中包含三个关系,分别为:全局关系、局部关系和模块关系。全局关系使用全局表示来匹配图像;局部关系获取像素到像素的匹配关系;模块关系模拟一对多像素关系。通过这三种关系并行计算相似度,将得到的结果相加取平均就获得了该候选区域最终的置信度,留下置信度阈值之上的框从而得到最终的预测结果。
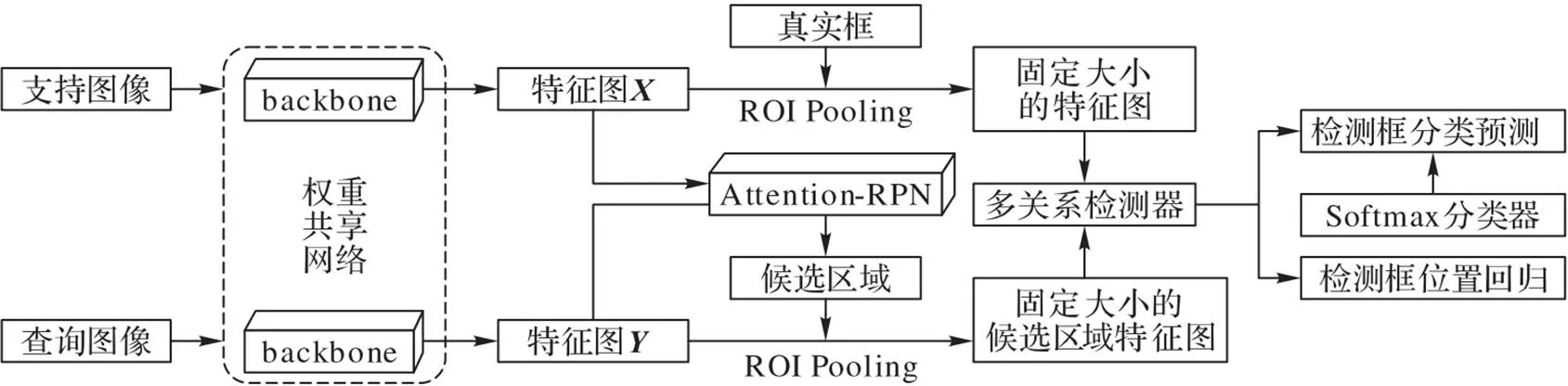
图1 FSOD模型的总体结构
2 负边距损失的小样本目标检测
2.1 负边距损失函数
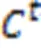
在目标检测分类任务中,通常会采用Softmax分类器直接输出样本属于每个类的概率,以此对目标进行分类。常规Softmax损失函数如式(1)所示:
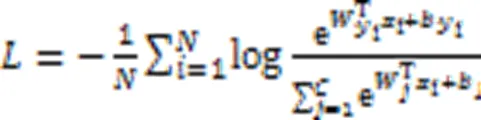
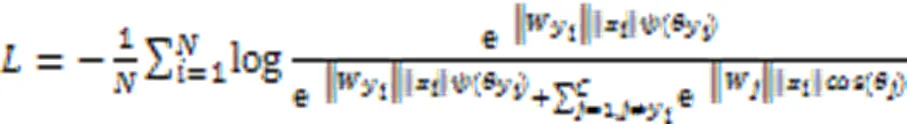
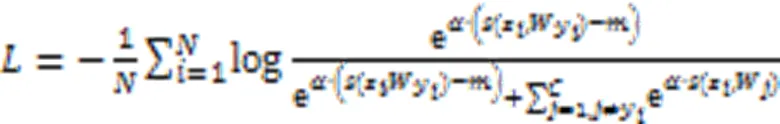

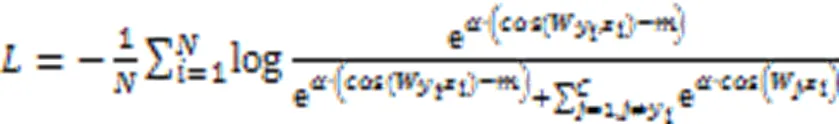
2.2 负边距小样本检测框架
本节将在上述目标检测框架中采用负边距损失,构建一个小样本目标检测框架NM‑FSTD。如图2所示,负边距损失主要作用于NM‑FSTD的目标分类部分,应用于Softmax分类器。

图2 NM‑FSTD总体框架
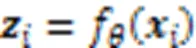
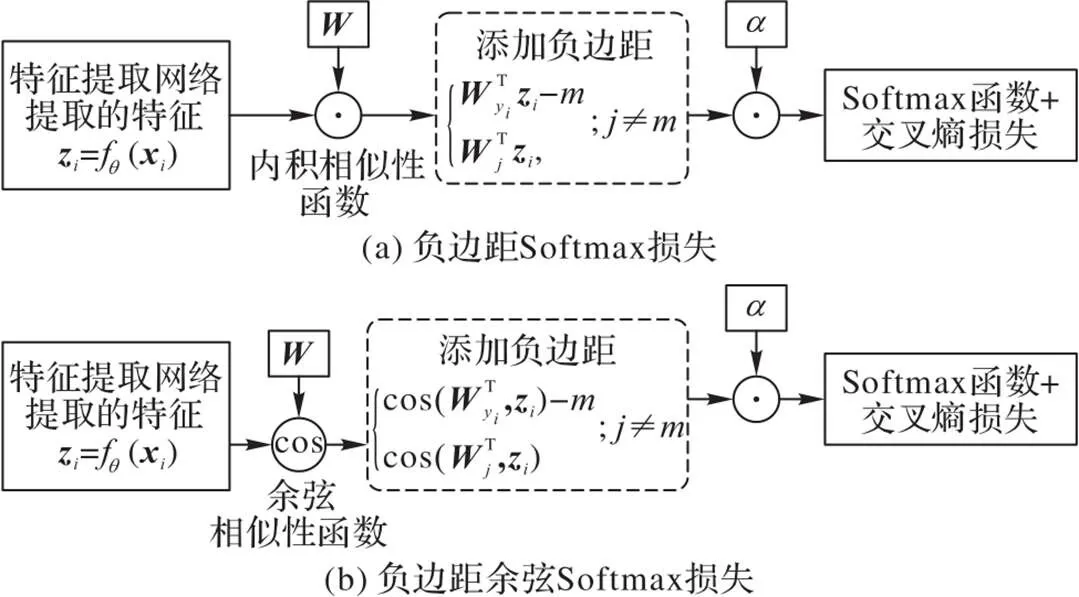
图3 负边距Softmax损失与负边距余弦Softmax损失的计算过程
3 实验与结果分析
3.1 数据集
本文实验使用MS COCO[45]中的60个类别作为训练类,并使用剩下的与PASCAL VOC中包含的20个类别相同的类别作为新的评估类别。MS COCO数据集是一个大型的、丰富的数据集,常用于目标检测与实例分割、人体关键点检测等。该数据集包括81类目标,328 000幅图像和2 500 000个标签。PASCAL VOC数据集是用于图像分类和目标检测两个任务的基准测试集,主要分为VOC 2007和VOC 2012,每部分包含20个常见类别,主要包括猫狗等动物、飞机自行车等交通工具、家具等。其中:VOC 2007包含5 011幅训练和验证图像,4 952幅测试图像;VOC 2012包含11 540幅训练和验证图像,10 991幅测试图像。
3.2 模型训练和评价指标

此外,本文也设计了实验用于验证负边距损失函数有利于在小样本情况下对新类别样本进行目标分类,从而有利于新类别的小样本目标检测。本文选取miniImagenet数据集用于验证,其中的64个类别作为基础类别,16个类别作为验证类别,20个类别作为新类别,分别用于训练、验证和测试,输入图像大小为224×224,图像批量大小为256。
3.3 结果分析
表1 miniImagenet数据集在不同下采用余弦Softmax损失的分类准确率对比 单位: %
表2 miniImagenet数据集在不同下采用 Softmax损失的分类准确率对比 单位: %
利用MS COCO数据集中的60个类别进行训练,剩下的与PASCAL VOC数据集中的20个类别相同的类别进行评估,并且训练集和评估集的类别不重合;对比本文方法(负边距Softmax FSTD和负边距余弦Softmax FSTD)与LSTD、FR(Feature Reweighting)[46]、Meta R‑CNN[47]、MPSR(Multi‑Scale Positive Sample Refinement)[50]、TFA(Two‑stage Fine‑tuning Approach)[49]、SRR‑FSD(Semantic Relation Reasoning Few‑ Shot Object Detection)[48]、FSCE(Few‑Shot object detection via Contrastive proposal Encoding)[36]、FSOD[38]、Cos‑FSOD(指将FSOD的Softmax损失修改为余弦Softmax损失)等,结果如表3。可以看出本文方法的结果优于现有的大部分小样本目标检测方法,提升了小样本目标检测性能。
此外,表3也列出了各个方法的主干网络、参数量及每秒浮点运算次数(FLoating-point OPerations per second, FLOPs),可以看出,在参数量与FLOPs上,本文方法也有一定的优势。
表3各方法的性能对比
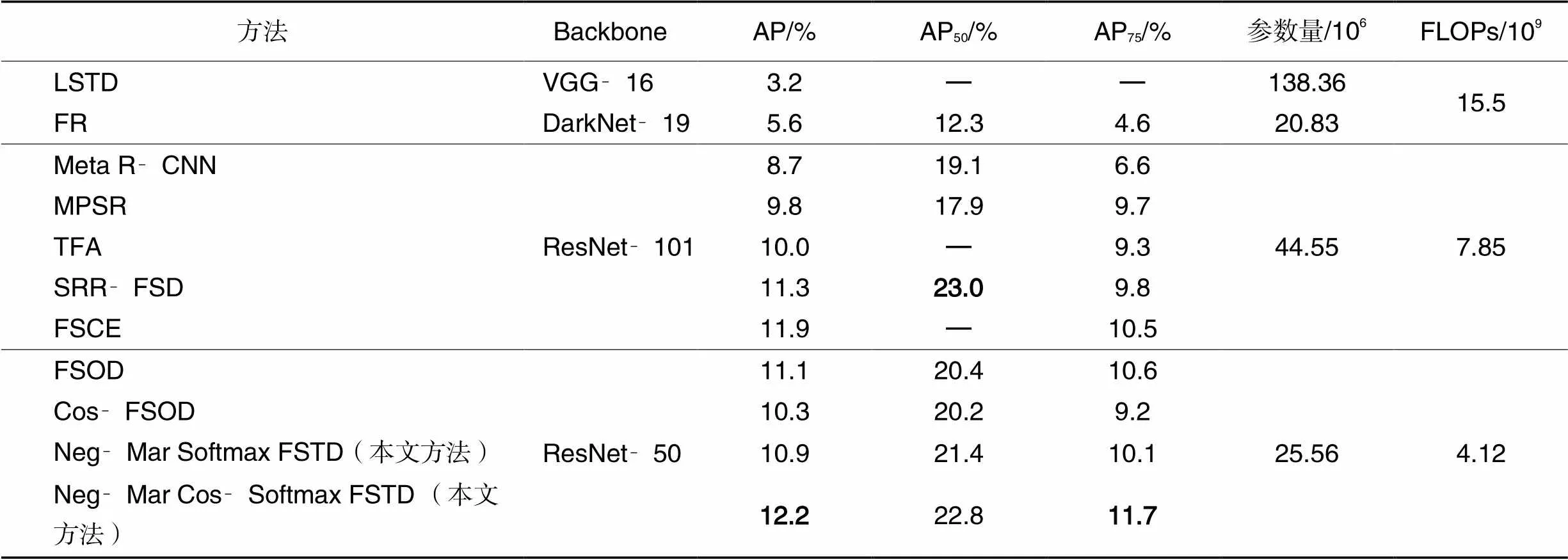
Tab.3 Performance comparison of different methods

表4 负边距损失对小样本目标检测准确率的影响 单位: %
此外,本文对骨干网络也进行了消融实验,结果如表5所示。在表5中,采用负边距余弦Softmax小样本目标检测方法(Negative‑Margin Cosine Softmax FSTD),其余实验设置不变,选取了不同的骨干网络进行实验,得到了相应的检测精度。实验结果表明,选取ResNet‑50作为骨干网络比ResNet-34在AP/AP50/AP75上分别提高了2.8/3.3/3.0个百分点;而ResNet‑101比ResNet‑50在AP/AP50/AP75上分别提高了1.8/1.5/1.7个百分点,比ResNet‑34在AP/AP50/AP75上分别提高了4.6/4.8/4.7个百分点。
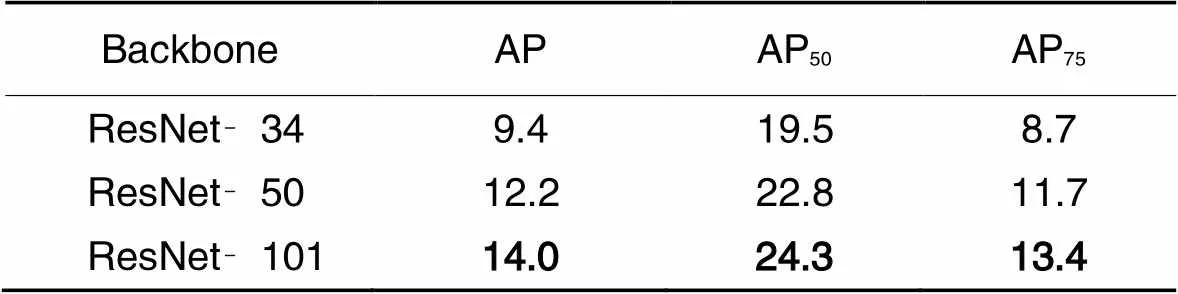
表5 骨干网络的消融实验结果 单位: %
图4显示了对于训练类别,图像中的大部分对象利用NM‑FSTD都能够准确地定位到它们的位置并按概率对其进行分类,判断出样本所属类别。图5展示了在新类别上,即模型没有采用大量数据学习过的类别,NM‑FSTD的检测效果,图像左上角表示该幅图像的支持样本,可以看出对于图像中的目标基本都能够进行准确定位和正确分类。

图4 NM‑FSTD在训练类别上的检测结果

图5 NM‑FSTD在新类别上的检测结果
4 结语
本文对小样本目标检测问题进行了分析和研究。首先,针对现在目标检测中样本数据不足的问题,总结和分析了现有的目标检测、小样本学习以及小样本目标检测方法,提出了将小样本学习中的度量学习方法负边距损失引入目标检测框架FSOD中,并通过实验对其有利于新类的学习和判别进行了验证;然后,基于FSOD提出了引入负边距损失的新的小样本目标检测框架NM‑FSTD,其中负边距损失作用于目标分类部分的Softmax分类器,使模型能进行端到端的训练;最后,使用MS COCO数据集对提出的方法进行了验证和评估,取得了较好的结果,说明了NM‑FSTD的有效性。在未来的工作中,还需要更进一步地研究小样本学习方法与目标检测方法的结合,提出更具有普适性和可迁移性的小样本目标检测方法。
[1] LIU W, ANGUELOY D, ERHAN D, et al. SSD: Single Shot MultiBox Detector[C]// Proceedings of the 2016 European Conference on Computer Vision, LNIP 9905. Cham: Springer, 2016: 21-37.
[2] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real‑time object detection[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 779-788.
[3] REDMON J, FARHADI A. YOLO9000: better, faster, stronger[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 6517-6525.
[4] REDMON J, FARHADI A. YOLOv3: an incremental improvement [EB/OL]. [2021-08-10]. https://doi.org/10.48550/arXiv.1804.02767.
[5] BOCHKOVSKIY A, WANG C Y, LIAO H. YOLOv4: optimal speed and accuracy of object detection [EB/OL]. [2021-07-05]. https://doi.org/10.48550/arXiv.2004.10934.
[6] 刘丹,吴亚娟,罗南超,等. 嵌入注意力和特征交织模块的Gaussian‑YOLO v3目标检测[J]. 计算机应用, 2020, 40(8): 2225-2230.(LIU D, WU Y J, LUO N C, et al. Object detection of Gaussian‑YOLO v3 implanting attention and feature intertwine modules[J]. Journal of Computer Applications, 2020, 40(8): 2225-2230.)
[7] HE K, ZHANG X, REN S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 37(9):1904-1916.
[8] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2014: 580-587.
[9] GIRSHICK R. Fast RCNN[C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2015: 1440-1448.
[10] REN S, HE K, GIRSHICK R, et al. Faster R‑CNN: towards real‑ time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6):1137-1149.
[11] WANG Y,YAO Q, KWOK J T, et al. Generalizing from a few examples: a survey on few‑shot learning[J]. ACM Computing Surveys, 2020, 53(3):1-34.
[12] MILLER E G, MATSAKIS N E, VIOLA P A. Learning from one example through shared densities on transforms[C]// Proceedings of the 2000 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2000: 464-471.
[13] SCHWARTZ E, KARLINSKY L, SHTOK J, et al. Delta‑ encoder: an effective sample synthesis method for few‑shot object recognition[C]// Proceedings of the 32nd International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2018: 2850-2860.
[14] 甘岚,沈鸿飞,王瑶,等. 基于改进DCGAN的数据增强方法[J]. 计算机应用, 2021, 41(5): 1305-1313.(GAN L, SHEN H F, WANG Y, et al. Data augmentation method based on improved deep convolutional generative adversarial networks[J]. Journal of Computer Applications, 2021, 41(5): 1305-1313.)
[15] 陈佛计,朱枫,吴清潇,等. 基于生成对抗网络的红外图像数据增强[J]. 计算机应用, 2020, 40(7): 2084-2088.(CHEN F J, ZHU F, WU Q X, et al. Infrared image data augmentation based on generative adversarial network[J]. Journal of Computer Applications, 2020, 40(7): 2084-2088.)
[16] HARIHARAN B, GIRSHICK R. Low‑shot visual recognition by shrinking and hallucinating features[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 3037-3046.
[17] PFISTER T, CHARLES J, ZISSERMAN A. Domain‑adaptive discriminative one‑shot learning of gestures[C]// Proceedings of the 2014 European Conference on Computer Vision, LNCS 8694. Cham: Springer, 2014: 814-829.
[18] DOUZE M, SZLAM A, HARIHARAN B, et al. Low‑shot learning with large‑scale diffusion[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2018: 3349-3358.
[19] GRANT E, FINN C, LEVINE S, et al. Recasting gradient‑based meta‑learning as hierarchical Bayes [EB/OL]. [2021-08-10]. https://doi.org/10.48550/arXiv.1801.08930.
[20] TSAI Y, SALAKHUTDINOV R. Improving one‑shot learning through fusing side information [EB/OL]. [2021-06-19]. https://doi.org/10.48550/arXiv.1710.08347.
[21] GAO H, SHOU Z, ZAREIAN A, et al. Low‑shot learning via covariance‑preserving adversarial augmentation networks[C]// Proceedings of the 32nd International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2018: 983-993.
[22] VINYALS O, BLUNDELL C, LILLICRAP T, et al. Matching networks for one shot learning[C]// Proceedings of the 30th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2016: 3637-3645.
[23] SNELL J, SWERSKY K, ZEMEL R S. Prototypical networks for few‑shot learning[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 4077-4087.
[24] SUNG F, YANG Y, ZHANG L, et al. Learning to compare: relation network for few‑shot learning[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 1199-1208.
[25] KOCH G R, ZEMEL R, SALAKHUTDINOV R. Siamese neural networks for one‑shot image recognition[C/OL]// Proceedings of the 2015 32nd International Conference on Machine Learning. Brookline, MA: JMLR.org, 2015 [2021-06-05]. http://www.cs.cmu.edu/~rsalakhu/papers/oneshot1.pdf.
[26] MUNKHDALAI T, YU H. Meta networks[C]// Proceedings of the 34th International Conference on Machine Learning. Brookline, MA: JMLR.org, 2017: 2554-2563.
[27] LAKE B M, SALAKHUTDINOV R, TENENBAUM J B. Human‑ level concept learning through probabilistic program induction[J]. Science, 2015, 350(6266): 1332-1338.
[28] KINGMA D P, WELLING M. Auto‑encoding variational Bayes [EB/OL]. [2021-07-10]. https://doi.org/10.48550/arXiv. 1312.6114.
[29] HOFFMAN J, TZENG E, DONAHUE J, et al. One‑shot adaptation of supervised deep convolutional models [EB/OL]. [2021-06-15]. https://doi.org/10.48550/arXiv.1312.6204.
[30] LEE Y, CHOI S. Gradient‑based meta‑learning with learned layerwise metric and subspace [EB/OL]. [2021-05-10]. https://doi.org/10.48550/arXiv.1801.05558.
[31] 潘兴甲,张旭龙,董未名,等.小样本目标检测的研究现状[J].南京信息工程大学学报(自然科学版),2019,11(6):698-705.(PAN X J, ZHANG X L, DONG W M, et al. A survey of few‑shot object detection[J]. Journal of Nanjing University of Information Science and Technology (Natural Science Edition), 2019,11(6):698-705)
[32] CHEN H, WANG Y, WANG G, et al. LSTD: a low‑shot transfer detector for object detection [EB/OL]. [2021-04-25]. https://doi.org/10.48550/arXiv.1803.01529.
[33] SINGH P, VARADARAJAN S, SINGH A N, et al. Multidomain document layout understanding using few shot object detection [EB/OL]. [2021-05-10]. https://doi.org/10.48550/arXiv.1808.07330.
[34] ZHANG T, ZHANG Y, SUN X, et al. Comparison network for one‑shot conditional object detection [EB/OL]. [2021-08-10]. https://doi.org/10.48550/arXiv.1904.02317.
[35] KARLINSKY L, SHTOK J, HARARY S, et al. RepMet: representative‑based metric learning for classification and few‑shot object detection[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Washington, DC: IEEE Computer Society, 2019: 5192-5201.
[36] SUN B, LI B, CAI S, et al. FSCE: Few‑shot object detection via contrastive proposal encoding[C]// Proceedings of the 2021 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2021: 7352-7362.
[37] FU K, ZHANG T, ZHANG Y, et al. Meta‑SSD: towards fast adaptation for few‑shot object detection with meta‑learning[J]. IEEE Access, 2019, 7: 77597-77606.
[38] FAN Q, ZHUO W, TANG C K, et al. Few‑shot object detection with attention‑RPN and multi‑relation detector[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2020:4012-4021.
[39] WEN Y, ZHANG K, LI Z, et al. A discriminative feature learning approach for deep face recognition[C]// Proceedings of the 2016 European Conference on Computer Vision, LNIP 9911. Cham: Springer, 2016: 499-512.
[40] LIU W, WEN Y, YU Z, et al. Large‑margin Softmax loss for convolutional neural networks [EB/OL]. [2021-07-01]. https://doi.org/10.48550/arXiv.1612.02295.
[41] DENG J, GUO J, ZAFEIRIOU S. ArcFace: additive angular margin loss for deep face recognition [EB/OL]. [2021-05-17]. https://doi.org/10.48550/arXiv.1801.07698.
[42] WANG H, WANG Y, ZHOU Z, et al. CosFace: large margin cosine loss for deep face recognition[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2018: 5265-5274.
[43] LIU B, CAO Y, LIN Y, et al. Negative margin matters: understanding margin in few‑shot classification [C]// Proceedings of the 2020 European Conference on Computer Vision, LNIP 12361. Cham: Springer, 2020: 438-455.
[44] LIU W, WEN Y, YU Z, et al. SphereFace: deep hypersphere embedding for face recognition[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2017: 6738-6746.
[45] LIN T Y, MAIRE M, BELONGIE S,et al. Microsoft COCO: common objects in context[C]// Proceedings of the 2014 European Conference on Computer Vision, LNIP 8693. Cham: Springer, 2014: 740-755.
[46] KANG B, ZHUANG L, XIN W, et al. Few‑shot object detection via feature reweighting[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 8420-8429.
[47] YAN X, CHEN Z, XU A, et al. Meta R‑CNN: towards general solver for instance‑level low‑shot learning[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 9576-9585.
[48] ZHU C, CHEN F, AHMED U, et al. Semantic relation reasoning for shot‑stable few‑shot object detection [EB/OL]. [2021-08-05]. https://doi.org/10.48550/arXiv.2103.01903.
[49] WANG X, HUANG T E, DARRELL T, et al. Frustratingly simple few-shot object detection [EB/OL]. [2021-08-10]. https://doi.org/10.48550/arXiv.2003.06957.
[50] WU J, LIU S, HUANG D, et al. Multi‑scale positive sample refinement for few‑shot object detection [C]// Proceedings of the 2020 European Conference on Computer Vision, LNIP 12361. Cham: Springer, 2020: 456-472.
Few‑shot target detection based on negative‑margin loss
DU Yunyan1,2, LI Hong1,2, YANG Jinhui1,2, JIANG Yu1,2, MAO Yao1,2*
(1,100049,;2,(),610207,)
Most of the existing target detection algorithms rely on large‑scale annotation datasets to ensure the accuracy of detection, however, it is difficult for some scenes to obtain a large number of annotation data and it consums a lot of human and material resources. In order to resolve this problem, a Few‑Shot Target Detection method based on Negative Margin loss (NM‑FSTD) was proposed. The negative margin loss method belonging to metric learning in Few‑Shot Learning (FSL) was introduced into target detection, which could avoid mistakenly mapping the samples of the same novel classes to multiple peaks or clusters and helping to the classification of novel classes in few‑shot target detection. Firstly, a large number of training samples and the target detection framework based on negative margin loss were used to train the model with good generalization performance. Then, the model was finetuned through a small number of labeled target category samples. Finally, the finetuned model was used to detect the new sample of target category. To verify the detection effect of NM‑FSTD, MS COCO was used for training and evaluation. Experimental results show that the AP50of NM‑FSTD reaches 22.8%; compared with Meta R‑CNN (Meta Regions with CNN features) and MPSR (Multi‑Scale Positive Sample Refinement), the accuracies are improved by 3.7 and 4.9 percentage points, respectively. NM‑FSTD can effectively improve the detection performance of target categories in the case of few‑shot, and solve the problem of insufficient data in the field of target detection.
target detection; Few‑Shot Learning (FSL); negative‑margin loss; metric learning
This work is partially supported by The National Key Research and Development Program of China (2017YFB1103002).
DU Yunyan, born in 1997, M. S. candidate. Her research interests include target detection, few-shot learning.
LI Hong, born in 1996, M. S. candidate. His research interests include deep learning, lightweight target detection.
YANG Jinhui, born in 1996, M. S. candidate. His research interests include lightweight target detection.
JIANG Yu, born in 1977, M. S., associate researcher. Her research interests include computer application technology, human computer interaction system.
MAO Yao, born in 1978, Ph. D., researcher. His research interests include computer technology, machine vision, reinforcement learning.
TP391.41
A
1001-9081(2022)11-3617-08
10.11772/j.issn.1001-9081.2021091683
2021⁃09⁃27;
2022⁃05⁃25;
2022⁃05⁃26。
国家重点研发计划项目(2017YFB1103002)。
杜芸彦(1997—),女,四川成都人,硕士研究生,主要研究方向:目标检测、小样本学习;李鸿(1996—),男,贵州毕节人,硕士研究生,主要研究方向:深度学习、轻量化目标检测;杨锦辉(1996—),男,甘肃平凉人,硕士研究生,主要研究方向:轻量化目标检测;江彧(1977—),女,安徽黄山人,副研究员,硕士,主要研究方向:人机交互系统;毛耀(1978—),男,四川眉山人,研究员,博士,CCF会员,主要研究方向:机器视觉、强化学习。
猜你喜欢
陶瓷学报(2021年4期)2021-10-14
中学生数理化(高中版.高一使用)(2021年2期)2021-03-19
少儿画王(3-6岁)(2020年4期)2020-09-13
小天使·二年级语数英综合(2019年10期)2019-11-08
领导决策信息(2018年16期)2018-09-27
数学学习与研究(2017年3期)2017-03-09
共产党员(辽宁)(2015年2期)2015-12-06
读者·校园版(2015年19期)2015-05-14
海外英语(2013年8期)2013-11-22
西南学林(2011年0期)2011-11-12
