
基于骨架的自适应尺度图卷积动作识别
2022-12-01 02:37王小娟肖亚博
天津大学学报(自然科学与工程技术版) 2022年3期
王小娟,钟 云,金 磊,肖亚博
基于骨架的自适应尺度图卷积动作识别
王小娟,钟 云,金 磊,肖亚博
(北京邮电大学电子工程学院,北京 100876)
基于骨架的动作识别任务中,一般将骨骼序列表示为预定义的时空拓扑图.然而,由于样本的多样性,固定尺度的拓扑图往往不是最优结构,针对样本特性构建自适应尺度的骨骼拓扑图能够更好地捕捉时空特征;另外,不同尺度的骨骼图能够表达不同粒度的人体结构特征,因此对多个不同尺度的拓扑图进行特征提取与融合是有必要的.针对这些问题,提出了一种自适应尺度的图卷积动作识别模型.该模型包含自适应尺度图卷积模块和多尺度融合模块两部分.自适应尺度图卷积模块基于先验与空间注意力机制,构建关键点的活跃度判决器,将活跃点细化为小尺度结构、非活跃点聚合为大尺度结构,在加速节点间特征传递的同时最小化特征损耗;多尺度融合模块基于通道注意力机制,动态融合不同尺度的特征,进一步提升网络的灵活性;最后,综合关键点、骨骼、运动信息实现多路特征聚合的动作判别,丰富模型的特征表达.结果表明:该算法在NTU-RGBD数据集的CS和CV子集上分别取得了89.7%和96.1%的分类准确率,显著提高了动作识别的准确性.
人体骨架;动作识别;自适应尺度;图卷积
动作识别是计算机视觉中的基础任务,在安防、医疗、运动等领域有着广泛的应用[1].传统动作识别任务多以RGB-D视频为输入,但是视频数据蕴含着丰富信息的同时也存在着光照、角度、距离等因素的干扰,使模型无法专注于人体动作的表达[2].因此,人体骨架以其对环境的强鲁棒性获得了广泛关注.
传统的骨架动作识别多采用基于手工特征提取的方法,例如,Hussein等[3]提取了骨骼序列上的协方差矩阵,Wang等[4]设计了骨骼相对位置的特征表达,Vemulapalli等[5]利用李群流形对骨骼序列建模.这些方法往往需要耗费大量计算资源,且精度较低.随着深度学习的发展,数据驱动的方式受到了越来越多的关注,主要包括两类:第1类是基于RNN的方法,将不同关键点编码成向量,再用RNN提取时域信息[6],这种方式难以捕捉骨骼间的连接关系.第2类是基于CNN的方法,直接对骨骼数据进行二维或三维卷积[7],但关键点之间的邻接关系是不规则的,因此传统卷积并不适用.
图卷积在多个领域的良好表现[8],为骨架动作识别提供了新思路.Yan等[9]首次将人体关键点作为节点,骨骼作为边,构建了时空图,显著提升了识别精度.Liu等[10]提出了3D图卷积,统一了时空维度的特征提取方式.Shi等[11]设计了全局卷积核,使每个节点都能获取图的整体信息.Obinata等[12]提出了时域拓展模块,将邻居关系拓展到了相邻帧.上述方法虽然取得了一定的效果,但是仍存在一些缺陷:①用预定义尺度的拓扑图表示骨骼序列,缺乏灵活性;人体不同动作往往需要不同身体部位的协同配合,如“喝水”、“拿杯子”等小动作需要对手指、嘴巴等细粒度结构进行分析,而“跑步”、“举重”等大动作需要对胳膊、腿等粗粒度结构进行分析.因此如果网络能对不同样本,自适应地学得图的最佳尺度,就能够更精准地对骨骼序列建模;②缺乏对特征的多尺度提取与融合.对骨骼序列构建多个不同尺度的拓扑图能够提取不同粒度的结构特征,对于动作识别任务而言是至关重要的.
基于上述分析,提出了自适应图卷积模块和多尺度融合模块,基于先验与空间注意力机制构建活跃度判别器,对数据进行多粒度卷积,利于特征提取;基于通道注意力机制,动态融合不同尺度的特征,提高网络灵活性;综合关键点、骨骼、运动信息(运动信息包括两路:关键点运动信息和骨骼运动信息)4路输出,丰富特征的表达,大幅提高了预测精度.
1 基于图卷积的骨架动作识别
图表示是骨架动作识别的首要问题,在保留骨骼原始连接关系的基础上增加网络的灵活性,提高节点间信息的传递效率是至关重要的.
1.1 图表示
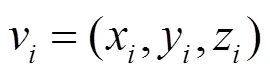
1.2 应 用
空域上,用GCN提取特征,基于第1.1节的骨骼图表示方法,聚合邻居节点的信息,具体公式为
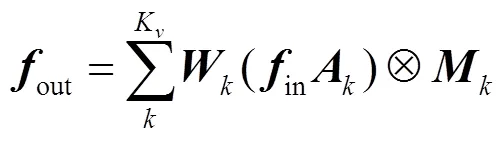
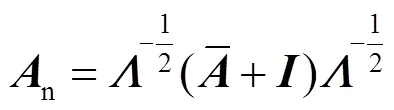
时域上,现有方法[9-12]多采用一维卷积的方式,对同一关键点在不同帧的特征进行融合.
2 自适应尺度图卷积的动作识别
2.1 网络结构
本模型构建过程主要分为3部分:特征获取、模型训练和模型融合,如图1所示.
(1)特征获取:对原始骨架中具有邻接关系的关键点对取向量差,作为骨骼数据,其计算式为
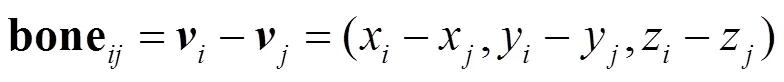
式中表示节点和节点间的骨骼,由人体关节间的真实连接情况得到.
分别对原始数据和骨骼数据取运动信息,其计算式为
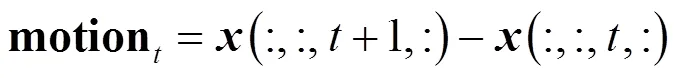
(2) 模型训练:模型由10个基础网络层堆叠而成,每层网络结构相似,包括时、空特征提取单元.其中,空间特征提取单元如图2所示.

图2 空间特征提取单元(实心点代表活跃结构)
首先,对数据进行批归一化处理,综合先验判别机制,共同构建活跃度判决器,生成自适应尺度的图结构.而后,多个尺度的骨骼图卷积后动态融合,完成空域特征的提取.时域上,采用与ST-GCN[9]相同的策略,进行一维卷积.每层网络的输出通道数依次是64、64、64、64、128、128、128、128、256、256.
(3)模型融合:由(1)得到了模型的4路输入,单路模型按照(2)进行训练,得到概率分布向量,对4路输出加权融合,概率值最大的类别即为预测值.
2.2 自适应尺度图卷积模块
自适应尺度图卷积模块基于活跃度判决得到最佳的图结构,使得骨骼图的数值和尺度都能够与网络的其他参数共同训练,极大提高了网络的灵活性.
2.2.1 活跃度判决器
人体不同动作都有主要活动的关节,也称这些关节在当前动作中较为活跃.在构建动作分类模型时,如果网络能够有区别地对活跃度不同的点给予不同的关注,就能更好地区分动作.因此,笔者将活跃度作为自适应尺度图的构建依据,并就关键点的活跃度度量设计了一种联合先验判别与空间注意力机制的策略,具体如下.

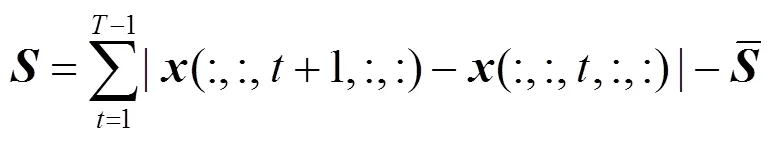
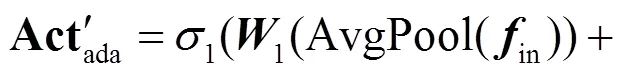
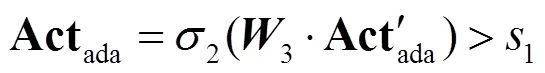
通过步骤1和步骤2得到先验与空间注意力机制各自的活跃度判别矩阵,在两个活跃度矩阵中活跃度均大于阈值的点作为活跃点,反之则为非活跃点.
2.2.2 自适应尺度图卷积模块
自适应尺度图卷积模块包括自适应尺度图的构建和图卷积操作两部分.
不同尺度的图能够丰富语义信息的表达.大尺度下,特征进行粗粒度的融合,加速信息传递,例如,图3(a)中,头(点)与腰(点)是三阶邻居,在小尺度下,需要3次卷积才能融合.但是在大尺度下,如图3(b)中,仅需要1次聚合就能实现特征交互.
因此,大尺度图能够更快地发现自然结构中距离较远的节点间关系.但由于大尺度图一般是通过对关键点取平均得到的,因此存在一定的特征损耗.
笔者提出的自适应尺度图结构能够在最大化保留关键信息的前提下加速特征传递,具体如下:首先,基于先验划分得到大尺度图,如图3(b)所示;接着,将图结构输入活跃度判别器,由第2.2.1节中的步骤1和步骤2综合得到活跃度判别结果,图3(c)中的红色点代表活跃点、灰色点代表非活跃点;最后,将包含活跃点的大尺度结构还原为小尺度关键点,得到图3(d),从而实现了数据驱动的自适应尺度图的构建.自适应尺度图中包含了人体不同尺度的结构,活跃部位往往是小尺度结构,非活跃部位往往是大尺度结构.特别地,每层网络结构均包含活跃度判别器及自适应尺度图的构建模块,因此样本在不同网络层中会自适应得到不同的图结构,从而进行自适应尺度的图卷积,以充分提取不同节点之间的关系.
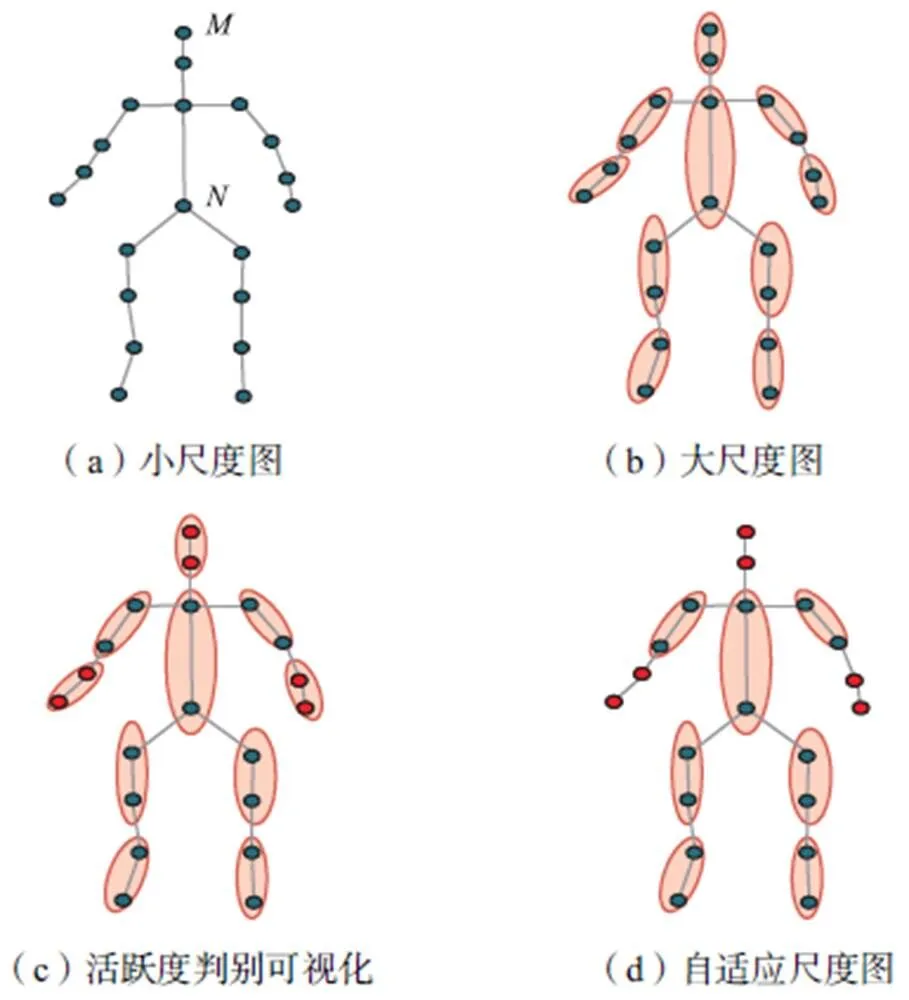
图3 自适应尺度图的构建(红色实心点代表活跃点)
在获取自适应尺度图后,采用2s-AGCN[11]的结构进行图卷积操作,其表达式为
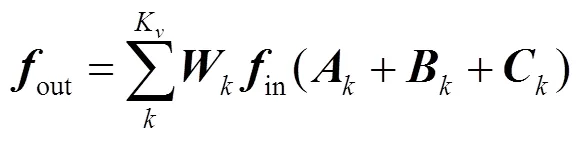
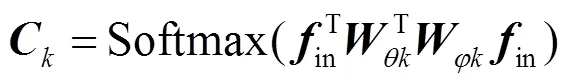
2.3 多尺度融合模块
自适应尺度图卷积模块能够根据样本的局部特性,在单个骨架上生成尺度自适应的图,如第2.2.2节所述,加速了活跃点与其余点的信息交互,更利于发现局部活跃点特征的区分性,因此,笔者将自适应尺度图卷积模块输出作为局部特征,同时将原小尺度图(图3(a))的卷积输出作为全局特征,进行加权融合,如图4所示.
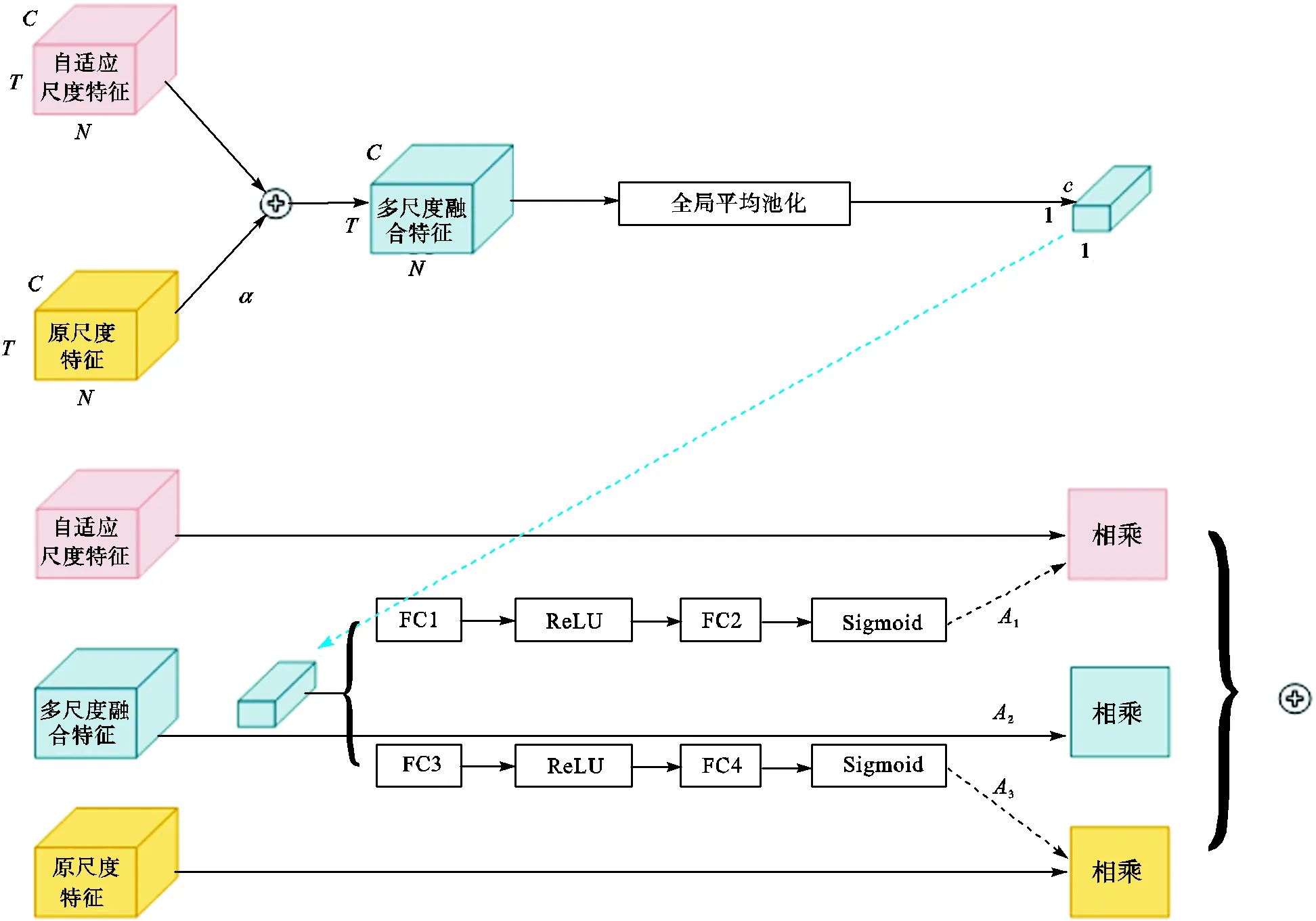
图4 多尺度融合模块
多尺度融合模块基于通道注意力机制,首先,对原尺度特征和自适应尺度特征进行元素和操作,得到
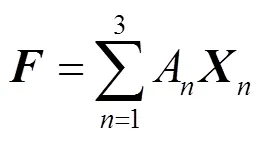
3 实验结果与分析
3.1 数据集与评价指标
(1) NTU-RGBD[15]:该数据集是目前动作识别领域最大的室内数据集,包含了60个类别的56880个数据样本,每个类别都包含了3个Kinect v2摄像机捕获的40名志愿者的数据.按不同的划分标准可得到以下两个子集:①Cross-Subject(CS):根据志愿者的编号划分数据集.训练集有40320个样本,测试集有16560个样本;②Cross-View(CV):根据摄像机的编号划分数据集.训练集有37920个样本,测试集有18960个样本.
(2)评价指标:使用top-1准确率作为评价指标.
(3)数据预处理:为了减少输入数据分布的影响,本文使用时间维度中第1帧的中心节点坐标作为坐标原点来标准化数据.然后,为了减小不同视角的影响,笔者旋转了坐标轴,使得骨骼的左右肩线与水平轴平行、脊柱与纵轴平行.
3.2 活跃度判别的可视化
如图5所示,随机选取了3个不同类别的样本的初始活跃度判别情况进行可视化,可见不同类别样本的活跃度判别情况差异较大,进一步生成的图尺度结构也不相同,因此本模型能够进行灵活的图构建.
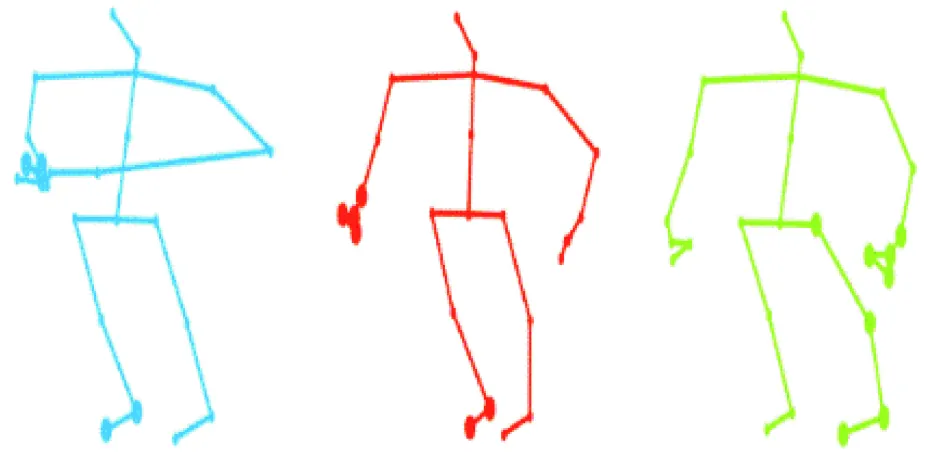
图5 不同样本的活跃度判别(实心点代表活跃点)
3.3 训练参数设置与实验结果
本研究使用pytorch搭建网络,使用了带有动量的随机梯度下降算法和交叉熵损失函数来进行优化,权重削减系数设为0.0002,批大小为32.由于数据集中单个样本最多包含两个人体数据,因此,将仅包含一个人体样本的数据用0进行填充,保证样本维度的统一.另外,样本的最大帧数为300帧,笔者也对不满300帧的样本用0进行了填充.初始学习率设为0.05,在第30轮、40轮和60轮后减小为1/10.
为了分别验证本研究提出的自适应尺度图卷积模块和多尺度融合模块,在NTU-RGBD的跨视角子集(CV)上进行了消融实验.表1是在基线算法的基础上仅加了自适应尺度图卷积模块的效果.
表1 自适应尺度图卷积模块在NTU-RGBD数据集上的消融实验
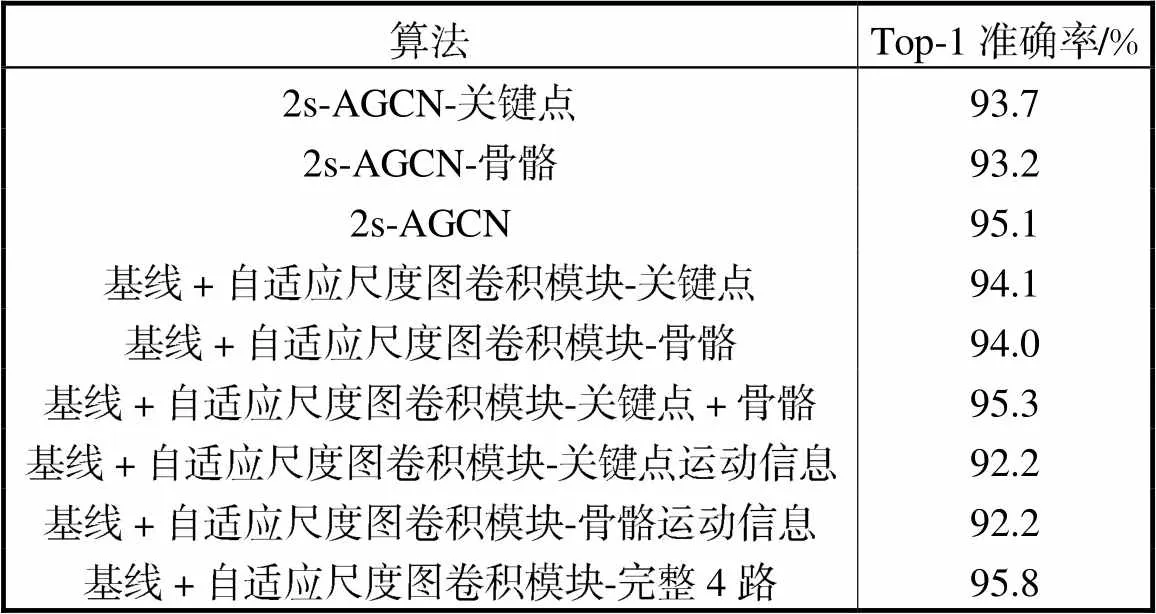
Tab.1 Ablation experiments on the scale adaptive graph convolution module using the NTU-RGBD dataset
(1) 单路输入:使用关键点作为输入时,Top-1准确率由93.7%提升到了94.1%;使用骨骼作为输入时,Top-1准确率由93.2%提升到了94.0%.
(2) 多路输入:使用关键点和骨骼同时作为输入时,Top-1准确率提升了0.2%,使用完整4路输入时,准确率提升了0.7%.综上,自适应尺度图卷积模块对于提升动作识别的准确性是较有效的.
表2描述了在基线算法上同时使用自适应尺度模块和多尺度融合模块的效果,与表1中仅适用自适应尺度模块的效果进行比较.
(1) 单路输入:使用关键点作为输入时,Top-1准确率由94.1%提升到了94.4%;使用骨骼作为输入时,Top-1准确率由94.0%提升到了94.2%.
(2) 多路输入:同时使用关键点和骨骼2路输入时,Top-1准确率提升了0.5%;完整4路输入时,Top-1准确率提升了0.3%.
表2 多尺度融合模块在NTU-RGBD数据集上的消融实验

Tab.2 Ablation experiments on the multiscale fusion module using the NTU-RGBD dataset
另外,将完整模型与基线模型相比,Top-1准确率由95.1%提升到了96.1%,说明笔者所提出的两个模块在本数据集上有较好表现.
为了进一步与现有方法比较,将模型与多个目前识别效果较好的算法在NTU-RGBD数据集上进行了对比,表3结果表明,本文所提出的自适应动态尺度图卷积算法在NTU-RGBD数据集上较有竞争力.
表3 本文算法与其他算法在NTU-RGBD数据集上的对比
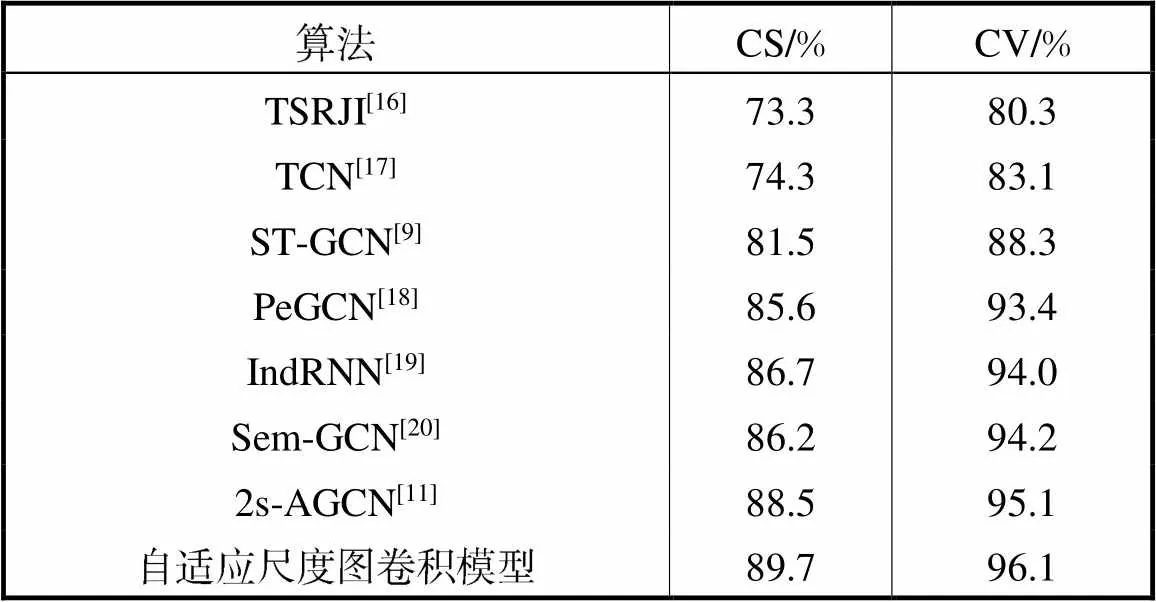
Tab.3 Comparing the validation accuracy of the proposed method with those of previous methods using the NTU-RGBD dataset
4 结 语
针对基于图卷积的动作识任务中缺乏图尺度自适应机制、未考虑多尺度图的特征提取与融合等问题,提出了自适应尺度图卷积的动作识别算法,首先基于先验与空间注意力机制构建关键点活跃度判别器,既保留了动作核心特征,又加快了特征传递效率.此外,基于通道注意力机制构建了多尺度融合模块,将局部特征与全局特征进行动态融合,提高了网络的灵活性.最终,将关键点、骨骼与对应运动信息独立训得的概率向量加权元融合,得到最终的预测结果.实验结果表明:本文方法能够自适应调节图尺度,灵活处理不同动作间的细微差异,较好地实现动作分类,最优Top-1准确率相比于基线方法提高了1.0%.
[1] Herath S,Harandi M,Porikli F.Going deeper into action recognition:A survey[J].Image and Vision Computing, 2017,60:4-21.
[2] Simonyan K,Zisserman A. Two-stream convolutional networks for action recognition in videos[C]// Neural Information Processing Systems. Montreal,Canada,2014:568-576.
[3] Hussein M E,Torki M,Gowayyed M A,et al. Human action recognition using a temporal hierarchy of covariance descriptors on 3D joint locations[C]// International Joint Conference on Artificial Intelligence. Beijing,China,2013:2466-2479.
[4] Wang J,Liu Z C,Wu Y. Mining actionlet ensemble for action recognition with depth cameras[C]// IEEE Computer Vision and Pattern Recognition. Providence,USA,2012:1290-1297.
[5] Vemulapalli R,Arrate F,Chellappa R. Human action recognition by representing 3D skeletons as points in a lie group[C]// IEEE Conference on Computer Vision and Pattern Recognition. Columbus,USA,2014:588-595.
[6] Qi M S,Wang Y H,Qin J,et al.StagNet:An attentive semantic RNN for group activity and individual action recognition[J].IEEE Transactions on Circuits and Systems for Video Technology,2020,30(2):549-565.
[7] Lin J,Gan C,Han S.TSM:Temporal shift module for efficient video understanding[C]// IEEE International Conference on Computer Vision. Seoul,Korea,2019:7082-7092.
[8] Zhao M C,Xiu S W,Peng W,et al. Multi-label image recognition with graph convolutional networks [C]// IEEE Conference on Computer Vision and Pattern Recognition.Long Beach,USA,2019:5172-5181.
[9] Yan S J,Xiong Y J,Lin D H.Spatial temporal graph convolutional networks for skeleton-based action recognition[C]// AAAI Conference on Artificial Intelligence. New Orleans,USA,2018:7444-7452.
[10] Liu Z Y,Zhang H W,Chen Z H,et al. Disentangling and unifying graph convolutions for skeleton-based action recognition[C]// IEEE Conference on Computer Vision and Pattern Recognition. Seattle,USA,2020:140-149.
[11] Shi L,Zhang Y F,Cheng J,et al.Two-stream adaptive graph convolutional networks for skeleton-based action recognition[C]// IEEE Conference on Computer Vision and Pattern Recognition. Long Beach,USA,2019:12018-12027.
[12] Obinata Y,Yamamoto T. Temporal extension module for skeleton-based action recognition[C]// International Conference on Pattern Recognition. Milan,Italy,2020:112-118.
[13] Fang H S,Xie S Q,Tai Y W,et al. RMPE:Regional multi-person pose estimation[C]// IEEE International Conference on Computer Vision. Venice,Italy,2017:2353-2362.
[14] Gang L. Learning skeleton information for human action analysis using kinect[J]. Signal Processing Image Communication,2020,84:115814.
[15] Shahroudy A,Liu J,Ng T T,et al. NTU RGB+D:A large scale dataset for 3D human activity analysis[C]// IEEE Computer Vision and Pattern Recognition. Las Vegas,USA,2016:1010-1019.
[16] Carlos C,François B,William R S, et al. Skeleton image representation for 3D action recognition based on tree structure and reference joints[C]// IEEE Brazilian Symposium on Computer Graphics and Image Processing. Rio de Janeiro,Brazil,2019:16-23.
[17] Tae S K,Austin R. Interpretable 3D human action analysis with temporal convolutional networks[C]// IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops. Honolulu,USA,2017:1623-1631.
[18] Jongmin Y,Yongsang Y,Moongu J. Predictively encoded graph convolutional network for noise-robust skeleton-based action recognition[EB/OL]. https:// arxiv.org/abs/2003.07514,2020-03-17.
[19] Li S,Li W Q,Chris C,et al. Deep independently recurrent neural network[EB/OL]. https://arxiv.org/ abs/1910.06251v1,2019-10-11.
[20] Ding X L,Yang K,Chen W. A semantics-guided graph convolutional network for skeleton-based action recognition[C]// International Conference on Innovation in Artificial Intelligence. Xiamen,China,2020:130-136.
Scale Adaptive Graph Convolutional Network for Skeleton-Based Action Recognition
Wang Xiaojuan,Zhong Yun,Jin Lei,Xiao Yabo
(School of Electronic Engineering,Beijing University of Posts and Telecommunications,Beijing 100876,China)
In skeleton-based action recognition,graph convolutional network(GCN),which models the human skeleton sequences as spatiotemporal graphs,have achieved excellent performance. However,in existing GCN-based methods,the topology of the graph is set manually,and it is fixed over all layers and input samples. This approach may not be optimal for diverse samples. Constructing an scale adaptive graph based on sample characteristics can better capture spatiotemporal features. Moreover,most methods do not explicitly exploit the multiple scales of body components,which carry crucial information for action recognition. In this paper,we proposed a scale adaptive graph convolutional network comprising a dynamic scale graph convolution module and a multiscale fusion module. Specifically,we first used an a priori and attention mechanism to construct an activity judger,which can divide each keypoint into two parts based on whether it is active;thereafter,a scale adaptive graph was automatically learned. This module accelerated the feature transfer between nodes while minimizing the feature loss. Furthermore,we proposed a multiscale fusion module based on the channel attention mechanism to extract features at different scales and fuse features across scales. Moreover,we used a four-stream framework to model the first-order,second-order,and motion information of a skeleton,which shows notable improvement in terms of recognition accuracy. Extensive experiments on the NTU-RGBD dataset demonstrate the effectiveness of our method. Results show that the algorithm achieves 89.7% and 96.1% classification accuracy on the cross-subject(CS) and cross-view(CV) subsets of the NTU-RGBD dataset,respectively,thus significantly improving the accuracy of action recognition.
human skeleton;action recognition;scale adaptive;graph convolutional network(GCN)
TP391.41
A
0493-2137(2022)03-0306-07
10.11784/tdxbz202012073
2020-12-31;
2021-04-06.
王小娟(1985— ),女,博士,副教授,wj2718@bupt.edu.cn.
金 磊,jinlei@bupt.edu.cn.
国家自然科学基金资助项目(62071056).
Supported by the National Natural Science Foundation of China (No. 62071056).
(责任编辑:孙立华)
猜你喜欢
社会科学战线(2022年7期)2022-08-26
建材发展导向(2022年3期)2022-04-19
今日农业(2021年8期)2021-11-28
广东教育·高中(2017年10期)2017-11-07
当代工人·精品C(2016年6期)2017-01-12
太空探索(2016年5期)2016-07-12
新高考·高一物理(2015年5期)2015-08-18
时代英语·高三(2014年5期)2014-08-26
少年科学(2009年12期)2009-07-07
小哥白尼·趣味科学画报(2009年5期)2009-06-19
