
面向不平衡数据的云模型旋转机械故障识别方法
2022-12-01 10:25赵荣珍
振动与冲击 2022年22期
赵 楠,赵荣珍
(兰州理工大学 机电工程学院,兰州 730050)
旋转机械故障诊断技术对于流程工业的安全可靠运行发挥着重要作用[1]。随着该类装置必须向优质高效运行目标迈进,其监测信息的规模也在扩大,这使得旋转机械故障监测系统获取海量数据,从而推动旋转机械故障诊断领域进入“大数据”时代[2]。面对积累的工业大数据资源,必须使用合理、高效的智能决策技术将其开发利用,这对于快速发展旋转机械智能制造至关重要[3-4]。
故障模式识别是旋转机械故障诊断的本质问题,其目的在于获得高识别精度[5]。为此,多种分类器应运而生,典型的分类算法包括神经网络(neural network)、支持向量机(support vector machine,SVM)、K最近邻分类算法(K-nearest neighbor,KNN)等。这些分类算法对于平衡数据能够取得较好的识别效果,然而对于不平衡数据中少数类样本的识别精度不高[6]。其原因在于这些算法受到数据不平衡的影响,在特征学习过程中偏向于多数类样本学习,而对少数类样本普遍存在着学习不足的情况,导致分类器存在对于少数类样本识别精度较低的缺陷[7]。在实际情况下的机械设备监测中,设备故障的发生属于少数类,检测的数据大多数为正常工作数据,这种情况容易使得分类器将故障状态数据误判为正常状态数据,进而错过机械设备的最佳维护时间,造成难以估计的后果和损失[8]。
就不平衡数据的分类算法而言,目前较为典型的方法包括集成学习法、代价敏感法、单类学习法等。其中,集成学习法根据不平衡数据构建多个具有差异性的分类器,并按照一定方式将分类器识别结果整合以提高整体分类器对于不平衡数据的识别精度。但它存在着多个分类器训练时间长、基分类器类型和数量选择较为困难的缺陷。代价敏感法则以错分代价这一概念为基础,着重关注错误代价较高类别所对应的样本,并使得分类错误的总代价最低,从而优化分类算法。其缺陷在于难以真实准确地估计错分代价,并且不适用于少数类样本数量过少的情况。而单类学习法仅利用单一类别的训练数据进行训练,能够减少训练时间,对于处理少数类样本数量极少的情况具有一定优势。然而该方法在训练少数类样本时容易发生过拟合现象,导致分类方法泛化能力偏低。为寻找一种泛化能力强、识别精度高的不平衡数据模式识别方法,本文拟将云理论中的云模型引入对于旋转机械不平衡故障数据的处理过程中。
云模型具有优良的数学性质,能够实现数据的可视化效果,因此被广泛应用于各个领域,模式识别是云模型应用的重要方面之一[9-13]。云模型能够实现定性概念与定量值间的相互转换,在以不平衡数据训练分类器的过程中,通过逆向云发生器(backward cloud generator,BCG)将多数类样本与少数类样本转换为期望、熵、超熵3个数字特征,再通过正向云发生器(forward cloud generator,FCG)将数字特征绘制成相同云滴点数的云图,有效地减少了不平衡数据对于分类过程的影响,解决对不平衡数据分类时少数类样本识别精度较低的问题。
基于上述缘由,故本文拟对利用云模型改善旋转机械故障数据集质量问题进行研究,将借助于云图概念改进云分类器以解决不平衡故障数据集的分类与识别问题。欲为工业大数据的智能决策技术实现,提供数据运算的基础理论依据。
1 云模型理论介绍
云模型理论是李德毅院士以概率论与模糊数学理论两者为基础所提出的研究定性概念与其定量表示的认知计算模型,其赋予样本点随机确定度以统一刻画概念中的模糊性、随机性以及关联性[14]。生成云模型最为关键的两个步骤是构建正向、逆向云发生器。其中:逆向云发生器计算样本数据的3个数字特征,既期望(Ex)、熵(En)、超熵(He);正向云发生器依据逆向云发生器输出的3个数字特征绘制云图。两者相辅相成。
云模型按照云滴概率分布的不同,可分为正态云、高斯云、幂律云等。正态分布是概率分布中最基本、最重要、最为广泛应用的模型。因此,正态隶属函数也成为模糊理论中最常使用的隶属函数,本文所使用的正态云模型正是以正态分布和正态隶属函数为基础构建的。
1.1 云模型的数字特征
云模型通过逆向云发生器与正向云发生器实现定量数据与定性概念之间的相互转换,以期望、熵、超熵这3个数字特征描述一个不确定性概念,这3个数字特征在云图中的表示如图1所示,所代表的含义如下:
期望Ex——期望是云滴在论域空间的中心值,也是最能代表定性概念的点。
熵En——熵值既论域空间中云滴可被定性概念接受的取值范围,是定性概念不确定性的度量,能够反应云滴的离散程度。
超熵He——超熵是熵值的熵,既熵值的不确定性度量,代表云滴的凝聚程度,超熵值越小则云滴的离散程度也越小。

图1 云图中的数字特征Fig.1 Digital features in cloud chart
1.2 正向云发生器
正向云发生器能够完成定性概念到定量值的转换,它能够通过3个数字特征生成云图中的云滴。构建正态云模型时所使用的二阶正向正态云发生器算法FCG(Ex,En,He,n)如图2所示,具体步骤如下:
输入(Ex,En,He,n)3个数字特征及生成的云滴个数n
输出n个云滴xi及其所对应的隶属度μ(xi)
算法步骤:
步骤1生成一个正态随机数yi=RN(En,He),yi以En为期望、以He2为方差;


步骤4根据隶属度μ(xi)以及正态随机数xi在数域中生成一个云滴;
步骤5循环步骤1~步骤4,直至生成n个云滴(i=1∶n)。

图2 正向云发生器Fig.2 Forward cloud generator
1.3 逆向云发生器
与图2所示的正向云发生器相反,逆向云发生器能够完成定量值到定性概念的转换,它将精确数值转换为3个数字特征所表示的定性概念。本文选择较为常用的无需确定隶属的逆向云分类器算法BCG(xi),如图3所示,具体步骤如下:
输入样本点xi(i=1,2,…,n)
输出反映定性概念的3个数字特征Ex,En,He
算法步骤:

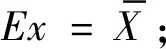



图3 逆向云发生器Fig.3 Backward cloud generator
对于云模型在模式识别中的应用,多数方法是将由正向云发生器改进出的隶属度公式与逆向云发生器相结合,由此构造云分类器对数据进行处理分析[16-18]。这种分类方法没有很好的利用所绘制的云图,得到的识别结果与云图并无直接关系。为此,本文提出一种改进的云分类器,依据云图间的位置关系判断出测试数据所属类别。将这种改进的云分类器应用于旋转机械故障诊断的数据不平衡情况,提高模式识别精度的同时,实现识别结果的可视化。
2 设计的不平衡故障诊断方法与流程
融合了云模型的数据挖掘方法考虑到模糊性与随机性,其结果相较于多种数据挖掘方法更加合理,有利于数据挖掘的智能化[19]。正态云模型通过逆向云发生器与正向云发生器二者结合的方式,将不平衡数据中的多数类样本与少数类样本绘制成云滴点数相同的云图,能够有效的降低不平衡数据对于模式识别结果的影响。本文借助云模型对不平衡数据分类的优势,以绘制云图为基础提出一种改进的云分类器。
2.1 改进的云分类器
构建云分类器是云模型理论应用于模式识别领域的关键环节。本节依据各类云图间的位置关系提出改进云分类器。首先,通过逆向与正向云发生器绘制各类数据云图;然后,比较测试数据云图与各类训练数据云图之间中心线的距离,以对测试数据进行分类;最后,选择距离最小的训练数据云图对应类别作为测试数据的判别结果,完成模式识别的同时实现特征数据的可视化表达。以3个类别的训练数据为例,测试数据通过改进云分类器进行分类的可视化识别结果表达,如图4所示。其中:Ex1,Ex2,Ex3对应3种训练数据云图的中心线;Ex对应测试数据云图的中心线。由图4可知,测试数据云图与第二类训练数据云图的中心线距离最短,因此将测试数据归为第二类别。

图4 改进云分类器的可视化结果表达Fig.4 Improve the visualization result expression of cloud classifier
由逆向云发生器及正向云发生器的过程推导可知,对于某一特征下的单个待测样本,其期望值为特征值本身,熵值与超熵值为零,使得该样本能够计算得出云图中心线对应于x轴的坐标值(即期望Ex),而无法求解出云滴在云图中对应于y轴的坐标值(即隶属度μ(xi)),不能绘制出单个待测样本的云图,进而模式识别也难以进行。为解决该问题,依据云图中位置关系提出类别判别公式D=|Ex-Ext|,将待测样本的期望值减去各个训练样本的期望值,绝对值最小的差值所对应训练样本状态即为待测样本状态。通过上述判别准则,以测试数据绘制云图、以判别公式对待测样本进行分类,完成的改进云分类器构建流程如图5所示,具体应用步骤如下:
输入单一特征下的t组训练数据与测试数据、云滴个数n,其中t为数据的类别个数
输出识别结果d
算法步骤:
步骤1生成数字特征,将某一特征下各个类别的训练数据与该特征下的测试数据作为逆向云发生器的输入,得到t+1组数字特征(Ex,En,He);
步骤2绘制云图,将生成的t+1组数字特征作为正向云发生器的输入,分别得到由各组数字特征衍生出的n个云滴(xi,μi)(i=1∶n),将各组云滴绘制成所对应的训练数据及测试数据云图;
步骤3计算距离,通过公式D=|Exj-Ext|(j=1∶j),其中j为测试数据所包含的待测样本数量。计算出待测样本所对应的期望值Exj与各个状态下训练数据云图所对应的期望值Ext之间差值的绝对值,即待测样本期望值与各个训练数据云图中心线之间的距离;
步骤4模式识别,取t个距离中最小值Dmin所对应的期望值Exj=d(t∈1∶t),则判定第d个训练数据云图所对应的类别即为待测样本的识别结果。即将待测样本归类于云图中心线间距离最近的训练数据所属类别。
2.2 建立的模式识别方法流程
改进的云分类器能够使识别结果与所绘制的云图对应,实现识别结果的可视化。但该分类器在分类的过程中只利用数据集中的单一特征,不利于获得较高识别精度,同时造成了数据资源浪费。为解决这一问题,将本文所提方法与集成学习方法相结合,以n个特征训练对应个数的云分类器,形成n组识别标签,再将这些标签通过相对多数投票法进行整合,选取标签数量最多的类别作为识别结果。

图5 改进云分类器流程图Fig.5 Improved cloud classifier flow chart
通过集成学习的方式将多个云分类器进行组合,使得分类方法能够处理多个特征,但在分类过程中,并不是特征数量越多越好。过多的特征数量将会导致分类器训练时间过长、分类模型复杂,甚至会降低模式识别精度[20]。因此,本研究采用ReliefF算法对初始特征集中的特征进行选择,以选取出特征数量适当并有利于实施分类的低维特征集进行模式识别。构建低维特征集的过程中,通过ReliefF算法计算出初始特征集中各个特征的权重,并依据权重的降序排序对特征进行重新排序,以选取出权重较大的前m个优质特征构成低维特征集。ReliefF算法计算特征权重的过程中,首先从初始特征集中随机选取一个样本Ri(i=1,2,…,m),从Ri的同类样本子集中寻找Ri的k个近邻样本,记为Hj(j=1,2,…,k),从Ri的不同类样本子集中寻找Ri的k个近邻样本,记为Mj(j=1,2,…,k);其次将选好的各样本代入特征A的权重w(A)迭代公式(式(1));最后对上述步骤进行m次重复,以完成权重公式的m次迭代,得到初始特征集中各个特征的权重。

(1)
式中:抽样次数m为公式的迭代次数;diff(A,Ri,Hj)为样本Ri与样本Hj在特征A上的距离;class(Ri)为样本Ri所属类别;C≠class(Ri)为类别C与样本Ri不为同类别;P(C)为C类别样本占总样本数量的比例。
为能够达到较高的识别精度,同时减少分类算法运行时间、降低分类模型复杂度,通过网格搜索法选取最优特征数量m以及ReliefF算法中近邻样本数k。
将改进云分类器与上述集成学习算法、ReliefF算法相结合,所构建的不平衡数据模式识别方法流程图如图6所示,具体步骤如下:
步骤1采集旋转机械的原始振动信号并进行预处理,构造初始特征集;
步骤2通过ReliefF算法对初始特征集进行特征选取,构建低维特征集;
步骤3依据低维特征集划分出不平衡训练集和测试集;
步骤4将单一特征下的各状态训练数据及待测样本代入改进的云分类器,构建出低维特征集特征个数的云分类器,并绘制各状态云图;
步骤5将各个云分类器的识别结果通过相对多数投票法进行结合,输出故障识别结果。

图6 建立方法的流程图Fig.6 Flow chart of the establishment method
3 试验结果与分析
3.1 试验数据及相关参数的选择情况
为验证本文所提不平衡数据模式识别方法的有效性,使用无锡厚德自动化仪表有限公司所提供的综合故障模拟试验台,模拟滚动轴承运行状态并对不同状态下的振动信号进行采集,通过本方法对所采集的数据进行模式识别,使用的试验台如图7所示。
试验采用NSK6308型号轴承,通过加速度传感器采集轴承在正常、内圈故障、外圈故障、滚动体故障、保持架故障共5种状态下的振动信号。试验设置采样频率为8 000 Hz,采样转速分别为2 600 r/min,2 800 r/min,3 000 r/min的运行状态。对所采集的振动信号进行小波消噪,截取同一转速下的各个状态振动信号80组,共计400组样本,样本长度为1 024点。提取该样本的时域特征6个、频域特征10个、时频域特征4个,共计20个特征,具体特征组成情况如表1所示。试验台设置有5个信号采集通道,故所构成的初始特征集特征维数为100。为便于后续计算、利于云图可视化表达,将初始特征集进行归一化,归一化区间为[-1,1]。

图7 综合故障模拟试验台Fig.7 Comprehensive failure simulation test bench

表1 故障特征组成情况Tab.1 Fault feature composition
通过RelifF算法计算初始特征集中各个特征的权重,以3 000 r/min运行状态下的初始特征集为例得到的权重状态,如图8所示。图8中,特征序号1~20代表通道1振动信号的表1中所述20个特征,依此类推。将此权重降序排序,取权重较大的前m个权重所对应的特征构成低维特征集。采用网格搜索法,选取ReliefF算法中的k近邻样本数为7、低维特征集的特征数为29。3 000 r/min运行状态下低维特征集的特征组成情况,如表2所示,特征排序按照其权重由大到小进行排列。以表2中序号5特征为例,其表示低维特征集中的第5个特征为通道1下的频谱一阶重心(表1中的序号10特征)。将此低维特征集按照5∶5划分为平衡训练集与测试集,两者样本数均为200。取训练集中的正常样本40个、内圈故障样本20个、外圈故障样本20个、滚动体故障样本10个、保持架故障样本10个,完成不平衡训练集的构建。为便于后续试验的表达,将本文提出的依据云图间距离的不平衡数据模式识别方法命名为以云图间距离为基础的云模型模式识别方法(distance cloud model,DCT)。

图8 特征权重图Fig.8 Feature weight histogram

表2 低维特征集的特征组成情况Tab.2 Feature composition of low-dimensional feature set
3.2 本方法的识别性能验证
获得高的识别精度是模式识别研究的目的所在,为验证本文所提方法对于不平衡数据的故障识别能力,选用3.1节所述的3 000 r/min运行状态下的数据进行验证,按照该节所述方法构造维数为29的低维特征集、划分不平衡训练集以及测试集。对于不平衡数据的各类训练数据、各类测试数据的云图绘制,如图9所示。图9中的测试数据云图均能得到正确分类;DCT方法对于测试集的识别结果如表3所示。该结果证明了DCT方法对于不平衡数据的多数类样本、少数类样本均能实施正确分类,验证了本文方法的可行性。为证明DCT方法与其他分类方法对于不平衡数据的分类具有一定优势,将本方法与BP(back propagation)神经网络、SVM、以及云模型和集成极限学习机相结合的滚动轴承故障诊断方法(ensemble-extreme learning machine,E-ELM),这3种故障识别算法进行识别精度对比。BP、SVM分类方法均选用之前所述的3 000 r/min运行状态下的低维特征集所划分的不平衡训练集以及测试集,将不平衡训练集代入各个分类方法进行训练、测试集进行测试,其中SVM的核函数使用高斯径向基函数(radial basis function,RBF),BP神经网络的结构为29-100-5。E-ELM方法按照文献[21]所述步骤,提取3 000 r/min 运行状态振动信号的云特征构建初始特征集,特征集划分训练、测试集的比例和不平衡训练集的构建方法均与本文方法相一致,将ELM分类器的隐层神经元个数设置为25,其余参数按照赵荣珍等研究中的参数选择部分进行设置。本文所提方法以及各分类算法对于平衡数据、不平衡数据的识别结果见表3。
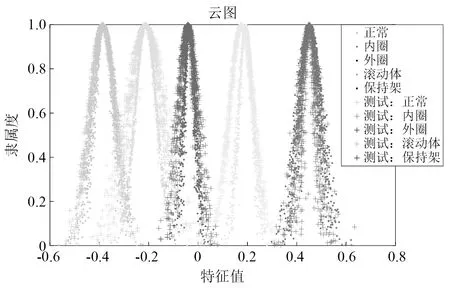
图9 3 000 r/min下的各类数据云图Fig.9 Various data cloud images under 3 000 r/min
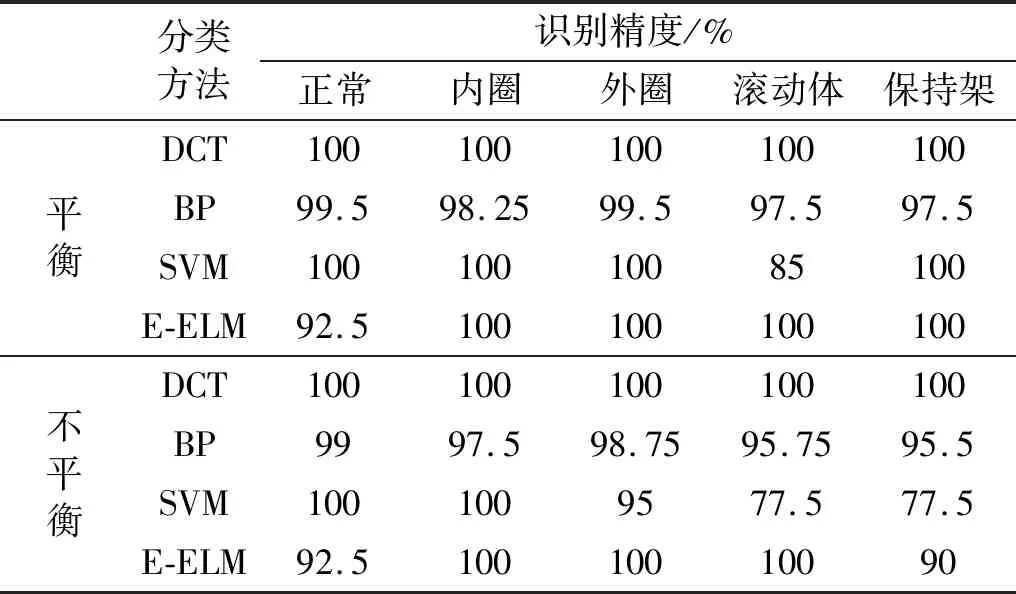
表3 各分类方法识别精度Tab.3 Identification accuracy of classification methods
由表3分析可知,各算法对于平衡数据识别精度较高,BP神经网络、SVM、E-ELM的各状态平均识别精度分别为98.45%,97%,98.5%,而本文所提DCT方法的平均识别精度为100%,具有一定的优势。对于不平衡数据,BP神经网络、SVM、E-ELM的识别精度明显下降,对于训练样本数量较少的保持架状态识别精度下降至95.5%,77.5%,90%,平均识别精度也下降至97.3%,90%,96.5%,而本文所提DCT方法的平均识别精度保持不变。其原因在于,BP神经网络对样本的依赖性强,少数类样本的识别精度会明显低于多数类样本识别精度;SVM在对不平衡数据实施分类时,分类面会向少数类样本方向偏移,导致部分少数类样本被误判为多数类样本,降低了少数类样本的识别精度;E-ELM中所使用的ELM分类器与BP神经网络都基于前馈神经网络的架构之下,故ELM同样对样本有着较强的依赖性,少数类样本识别精度相对较低。而DCT方法通过逆向、正向云发生器将多数类、少数类训练样本绘制成云滴点数相同的云图,并依据云图间距离对测试样本进行分类,一定程度减少了不平衡数据对于分类的影响。因此,相较于其他分类算法,本文方法在不平衡数据故障识别中具有一定优势。
3.3 不同工况下DCT方法的识别效果
对于某一转速的轴承不平衡故障数据,所提方法有着较高的识别精度,然而旋转机械的轴承在实际运转情况下转速不唯一,甚至会出现速度波动的干扰。因此,需要对本文方法对于不同工况的适用性以及抗速度波动干扰能力进行验证。为验证本文所提的DCT方法在不同转速下的识别能力,分别采用3.1节介绍的2 600 r/min,2 800 r/min,3 000 r/min这3种工况下的轴承故障数据进行识别。为验证本文方法的抗速度波动干扰能力,将两种转速下的轴承故障初始特征集按照5∶5进行混合,2 600 r/min,2 800 r/min初始特征集合并成维数相等的2 600~2 800 r/min初始特征集,2 800 r/min,3 000 r/min初始特征集合并成维数相等的2 800~3 000 r/min初始特征集,并通过DCT方法对两个混合转速的初始特征集进行识别。将2 600 r/min,2 800 r/min,3 000 r/min,2 600~2 800 r/min,2 800~3 000 r/min 故障初始特征集的转速命名为转速A、B、C、D、E,不平衡数据构建以及试验参数选择按照3.1节所述方法进行。DCT方法对于不同工况的不平衡数据识别结果,如表4所示。
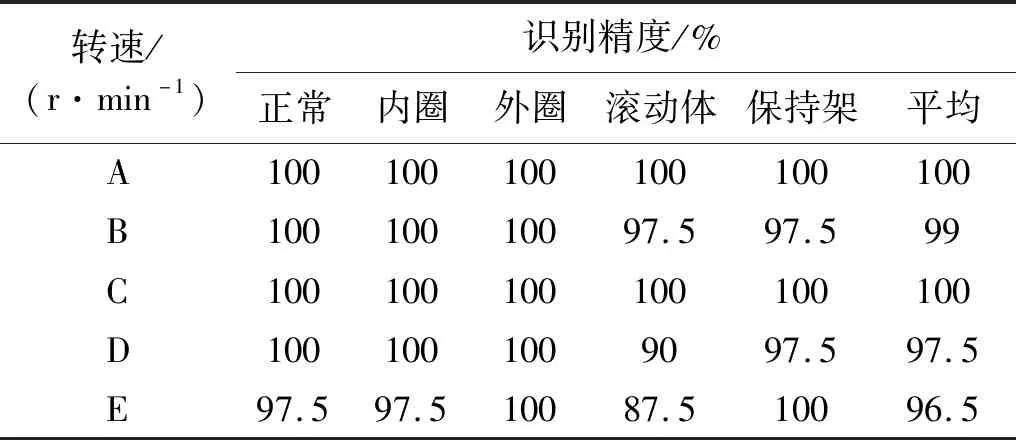
表4 DCT方法对于不同工况下的不平衡数据识别结果Tab.4 DCT method for the identification results of unbalanced data under different working conditions
由表4可以看出,DCT方法对于不同工况下的不平衡数据仍有较高模式识别精度并有良好的抗速度波动干扰能力,故本文所提方法在轴承故障不平衡数据的模式识别领域具有较好的适用性。
3.4 DCT方法的泛化性能验证
DCT方法在本实验室所测的轴承数据集上对样本分布不平衡的少数类样本能够取得较高的识别精度,而该方法是否适用于其他数据集需要进一步验证。为验证本文所提方法的泛化性能,采用美国凯斯西储大学电气工程实验室的滚动轴承数据进行试验验证。所使用数据采集于机械系统驱动端的加速度传感器,负载为1 hp、采样频率为12 kHz,故障损伤直径为0.533 4 mm。数据集中包含了轴承运转的正常状态以及3种故障状态:内圈故障、外圈故障、滚动体故障。对各个状态振动信号进行小波消噪,并截取各类振动信号80组,共计320组样本,样本长度为2 048点。按照3.1节所述方法构建特征集,选取权重较大的前10个特征构成低维特征集,不平衡训练集组成情况为:正常状态样本40个、内圈故障样本20个、外圈故障样本20个、滚动体故障样本20个。由DCT方法得到的识别结果如图10所示。

图10 不平衡数据集识别结果图Fig.10 Unbalanced data set identification result graph
由图10分析得出,对于此不平衡数据集,内圈状态的识别精度为97.5%,其中一个样本被误分为正常状态,其余状态的识别精度均能达到100%。由此可见,本文所提的DCT不平衡数据模式识别方法具有较好的泛化性。
4 结 论
针对不平衡数据分类时少样本数据识别精度较低的问题,提出了一种基于云模型的不平衡数据模式识别方法。该方法以RelifF算法对特征集进行二次选择,精简分类器结构、减少计算量;通过云模型中的逆向、正向云发生器将多数类样本以及少数类样本绘制成云滴点数相同的各类数据云图,依据测试数据云图与训练数据云图间的距离判别测试数据类型,有效避免了不平衡数据对于识别过程的影响;结合集成学习方法,将各个特征的云分类器进行整合,解决了云分类器仅处理单一特征的问题,提高了识别精度。
研究结果表明,本文所建立的方法相较于其他模式识别方法对旋转机械轴承的不平衡数据有着较高识别精度,同时本方法适用于不同工况数据以及公开数据集,具有一定的泛化性,为旋转机械的智能故障识别方法提供了一种新的参考方案。
猜你喜欢
舰船科学技术(2022年20期)2022-11-28
导航定位学报(2022年4期)2022-08-15
中国药房(2022年10期)2022-05-30
导弹与航天运载技术(2022年2期)2022-05-09
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
计算机测量与控制(2019年4期)2019-05-08
名家名作(2017年3期)2017-09-15
燕山大学学报(2015年4期)2015-12-25
科技视界(2015年24期)2015-08-22
