
一种改进的随机森林Boost多标签文本分类算法
2022-12-03 01:56邵孟良齐德昱
计算机应用与软件 2022年11期
邵孟良 齐德昱
1(广州软件学院计算机系 广东 广州 510990)2(华南理工大学计算机科学与工程学院 广东 广州 510006)
0 引 言
互联网上海量的数据通常以非结构化的形式表示和存储,需要通过高效的自动文本分类[1]系统来管理和组织这些数据。因此,文本分类是非常重要的研究领域。
文本分类指从一组预定义类别中自动指定文本的合适分类。研究人员提出了很多用于文本分类的分类算法,如支持向量机[2]、决策树[3]等。但这些算法仅限于单标签分类问题。然而,文本可能属于多种分类。为此,研究人员提出了一些多标签分类算法,例如二进制相关算法和分类器链算法等。AdaBoost.MH[4]是Adaboost的多标签形式,其准确性较高,是当前性能领先的多标签分类算法之一。与Boosting算法类似,AdaBoost.MH迭代构建弱假设集合,然后将其合并为一个能够估计给定实例的多个标签的分类器。当数据集较大时,AdaBoost.MH在弱监督学习过程中迭代地检验所有训练特征,其耗时较长[5]。文献[6]使用了一种长短期记忆模型,即一种机器学习的方法进行文本分类学习,并使用注意力机制对词汇文本的贡献程度进行度量。文献[7]提出了AdaBoost.MH的改进算法随机森林提升(RF-Boost),其首先对训练特征进行排序,然后在每个Boosting轮过滤并使用排序靠前特征的较小子集,生成新的弱假设。实验结果表明,RF-Boost是一种快速准确的多标签文本分类算法。但作为一个话题模型,要求对话题估计进行重采样,当数据量较大时,两种用于RF-Boost的特征排序方法可能会增加计算时间。文献[8]提出一种非独立同分布的多实例多标签分类算法,在图像和文本数据集上的实验结果表明,该算法大大提高了多标签分类的准确性。
本文分析了现有的特征加权方法,即信息增益、卡方、GSS系数、互信息、优势比、F1得分和准确度[9],并提出改进的RF-Boost(IRF-Boost)。本文方法基于权重选择单个排序特征,传递到基础学习器生成一个新假设,因此不需要检查所有的训练特征,甚至不需要检查排序特征子集。通过实证分析表明,本文方法能够快速准确地进行多标签文本分类。
1 Boosting算法
1.1 AdaBoost.MH

AdaBoost.MH算法中,通过将指数误差最小化来实现最大限度降低汉明损失:
式中:α(r)为基础系数,取正实值。
在选择Z的最小弱假设h(r)后,对下一个Boosting轮(r+1)的分布W(r+1)进行更新和归一化:
在后续迭代中重复相同过程,直至所有Boosting轮执行完毕。完成所有Boosting轮之后,AdaBoost.MH将选定的弱假设组成最终分类器:
因此,正值表示要分配给给定文本x的正确标签,负值则表示错误标签:
lH(x)=sign(H(x,l))l=1,2,…,m
(5)
为使用AdaBoost.MH进行文本分类,利用代表训练文档的单个词(词项)构建弱假设。设T={t1,t2,…,tv}为所有训练词项的集合。每个文档xj表示为包含v个二进制权值的向量x=(x1,x2,…,xv),其中若ti出现在x中,则xi值为1;否则,xi值为0。
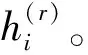
式中:c01和c1l为第r次迭代过程中,根据基础目标Z(r)的最小化策略选出的常数。为得到词项ti的c01和c1l值,先将训练文档集合分割为两个子集(X0,X1):
Xu={x:xi=u}u=0,1
(7)
式中:ti出现在X1中的每个文档中,且未出现在X0中的任何文档。
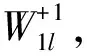
式中:u=0,1;φ(xi,l)为目标函数;p=1或-1。
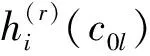
式(9)和式(10)均加入了较小的值ε,以避免除零。根据文献[10],取ε=1/mn。通过选择α(r)=1,利用式(11)得出Z(r):
1.2 RF-Boost
在RF-Boost中,首先对训练特征进行排序,接着在每个Boosting轮中仅利用排序特征的较小子集得到与枢纽词项相对应的弱假设。在当前Boosting轮选定后,在其后的Boosting轮移除枢纽词项,并替换为排序特征索引中下一个排序特征。

算法1RF-Boost弱监督学习算入:训练集S,均匀分布W,Boosting轮数R,训练特征索引T,特征排序法F,排序特征数k。
输出:最终分类器H(x,l)。
begin
2.H*←();
3.W(1)←W;

5.forr←1至Rdo
//对于每次迭代r
6.H(r)←();
//生成一组弱假设Η(r),每个弱假设对应一个特征
7.fori←1至kdo
//对于RF中的每个排序特征
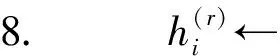
//将训练样本,当前排
//序特征和权重分布传入基础学习器,并得到一个新的弱假设

10.endfor
//选择最优弱假设
12.forj←1至kdo

16.endif
17.endfor
19.更新W(r +1);
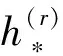
21.endfor

end
1.3 本文方法
RF-Boost和本文方法之间的差异在于,RF-Boost在每个Boosting轮中,将排序特征的较小子集传入基础学习器,用以选择弱假设;而本文方法则仅选择一个排序特征。因此,弱假设搜索空间的大小从k(RF-Boost中排序特征数量)降低至1(本文方法)。
算法2本文IRF-Boost的弱监督学习算入:训练集S,均匀分布W,Boosting轮数R,训练特征索引T,特征排序法F。
输出:最终分类器H(x,l)。
begin
2.Η*←();
3.W(1)←W;
4.forr←1至Rdo
//对于每次迭代r
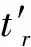
7.fori←1至|×|do
//对于S中的每个样本
8.forl←1至|×|do
//对于S中的每个标签
10.endfor
11.endfor
12.endfor

end
本文方法IRF-Boost可视为RF-Boost的特殊形式,其选定特征数量为1。虽然本文仅将一个特征选择为枢纽词项并传入基础学习器,但通过本文的实证验证,确定本文方法能够如AdaBoost.MH一样,将弱假设的汉明损失最小化。AdaBoost.MH的最终分类器的汉明损失最大为:
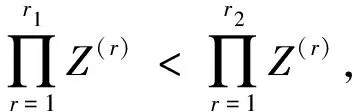
假定训练特征的数量为2 000个。AdaBoost.MH构建2 000个弱假设,每个假设对应一个特征。对于2 000个弱假设h1,h2,…,h2 000,仅返回特定特征t*上的一个弱假设,该弱假设能够最小化基础目标函数Z*的值。假定选定要进入RF-Boost中弱监督学习程序的排序特征的数量为100(k=100,作为用户的输入),则RF-Boost将弱假设的搜索空间从2 000(AdaBoost.MH)降至100。由此,生成的弱假设数量也降至100。在这100个弱假设中,仅选择一个能够最小化Z*的弱假设h*用于最终分类器。与之相比,本文方法则将生成的弱假设数量降至1个,对应于传入基础学习器的特征(t1)。因此,本文方法中无须执行弱假设选择,因此加速了弱监督学习过程。
2 特征排序法和BoWT文本表征模型
2.1 特征排序法
用于特征排序的特征加权方法有很多,RF-Boost和本文方法基于通过不同的指标进行特征加权排序,这些指标分别为信息增益、卡方、互信息、优势比、GSS系数、F1得分和准确度。
对于T中的每个标签l和特征词项t,假定tp为l中且包含t的文档数量,fp为不在l中且包含t的文档数量,fn为l中且不包含t的文档数量,tn为不在l中且不包含t的文档数量。设gPos=tp+fn,gNeg=fp+tn,fPos=tp+fp,fNeg=tn+fn,并设n为训练集中文档总数量。将以下每个特征加权(选择)度量的得分,作为词项t被分入标签l的权重。
信息增益(IG)是广泛使用的词项重要性度量,以信息理论为基础[11]。将词项t分入标签l的近似信息增益为:
卡方(CHI)测量两个变量之间的相关性,并评估其独立性。利用卡方定义词项t和分类l的独立性:
互信息(MI)是广泛使用的特征加权方法,测量两个变量X和Y所共享的信息程度:
优势比(OR)测量词项t出现在类别l中的概率比词项t不出现在类别l中的概率大多少:
GSS系数(GSS)是一种简化卡方法,是一种特征选择法。将词项t分入标签l的GSS系数定义为:
F1得分(F1)和准确度(ACC)用于评价分类算法的性能。对于词项t和分类l,F1得分和准确度的定义分别为:
特征排序法的函数表示为Sort-F[Sc,M]。其中,第1个参数Sc表示所有分类之间的动态调度策略。如轮询策略,即选取每个分类轮流提出的最优特征;或者均匀随机策略,以随机化观察为基础,根据分布概率,随机选择下一个分类。若已知分类的重要性不平等(例如分类成本等),则使用该信息对选择概率分布进行偏移。第2个参数M是分类任务的特征排序指标,可包括特征评分度量,例如信息增益或卡方检验等。本文特征排序法的伪代码如下:
对于数据集的每个分类c:
对于在分类c和所有其他分类之间进行二元子任务区分,根据参数M对所有特征进行排序;
保存分类c的特征排序;
当输出未完成时:
利用动态调度策略Sc,选择下一个分类cn;
从排序表中,选出cn的下一个特征fn。
若该fn不在输出中,则将其添加到输出中。
2.2 BoWT文本表征模型
BoW(词袋)是典型的文本表征模型,其使用单个词在向量空间中表征文本[13]。但BoW会忽略词的顺序及其在文本中的关系,而且BoW会生成高维空间,增加分类算法的训练时长。文献[14]的实验结果表明,基于话题的表征法不适用于不平衡数据。这是因为与样本较少的分类相关联的话题数量很少,因此无法完全表现这些类别的特征。文献[7]提出了BoWT混合式表征法,通过将排序靠前的词和话题合并到一个表征模型中,解决了较少样本话题的表征问题。
BoWT如图1所示,首先使用LDA估计训练文档间的话题,然后基于其概率选择话题,并将话题与排序靠前的词相结合,生成新的合并表征模型。在评价阶段,基于话题估计阶段中的LDA输出,推导出测试文本的话题,并与选定的训练特征结合,以表征用于评价分类性能的测试文档。
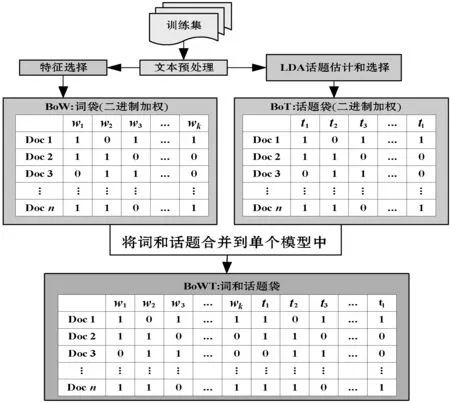
图1 BoWT文本表征模型
3 实 验
3.1 数据集
本文使用文本分类系统评价中常用的四个多标签数据集:
(1) Reuters-21578,包含135个类别的新闻集合,共包含12 902个文档,其中9 603个文档用于训练,3 299个文档用于测试。本文在135个类别中,仅使用了包含文本数量较大的10个类别。
(2) 20-Newsgroups(20NG),一个多标签文本数据集,包含分布在20个不同新闻组(类别)上的20 000个文档。本文使用的20NG版本中包含18 846个文档,分为11 314个训练文档和7 532个测试文档。
(3) OHSUMED,1991年医学主题(MeSH)摘要集合,目标是将摘要分为23种心血管疾病类别。该数据包含13 929个摘要,分为6 286个训练摘要和7 643个测试摘要。
(4) TMC2007,为2007年SIAM文本挖掘竞赛而开发的多标签文本数据集,包含22个类别上的28 596个测试样本,分为21 519篇训练文本和7 077篇测试文本。
3.2 实验设置
对每个数据集进行预处理,即词语切分、标准化、词干提取、停用词移除。使用BoWT表征模型表示特征,将每个数据集的估计话题数量设为200个[15]。对于所有的特征排序法,选择每个数据集的前3 500个权重最高的特征(词和话题)。利用不同Boosting轮数(从200至2000轮递增,增量为200轮)对Boosting算法进行评价。使用宏观平均F1(MacroF1)和微观平均F1(MicroF1)评价分类性能。
实验分为两个步骤:(1) 评价用于RF-Boost的特征排序法;(2) 使用在RF-Boost中性能最优的排序法,对AdaBoost.MH、RF-Boost和本文方法进行比较分析。
本文使用秩和检验[16]验证Boosting算法的统计显著性。秩和检验定义为:
式中:Nd为数据集数量;k为评价的方法的数量;Rj为每个方法的平均秩次。
通过对Boosting算法在不同数据集上的性能秩次进行秩和检验,利用式(20)与k-1自由度得到分布,并计算在5%显著水平下的p值。本文在秩和检验后还进行了双尾Bonferroni-Dunn检验,对各方法进行逐对比较。
3.3 结果分析
本文将评价分为两部分:① 特征排序法在RF-Boost中的性能;② 各Boosting算法的实证比较和统计分析。
3.3.1特征排序法的评价
图2给出了对于不同的特征排序法,在所有数据集上RF-Boost在MacroF1方面的性能。可以看出,MI特征在除OHSUMED数据集之外的所有数据集上得到了最优性能。这是因为MI计算每个训练词项与类别之间的相依性,衡量出现的词项的信息量,准确地分配标签。但MI在OHSUMED数据集上体现的性能较差,这是因为该数据集的性质和结构。

(a) 20NG (b) OHSUMED

(c) Reuster (d) TMC2007图2 RF-Boost的MacroF1在使用不同的特征选择法的得分
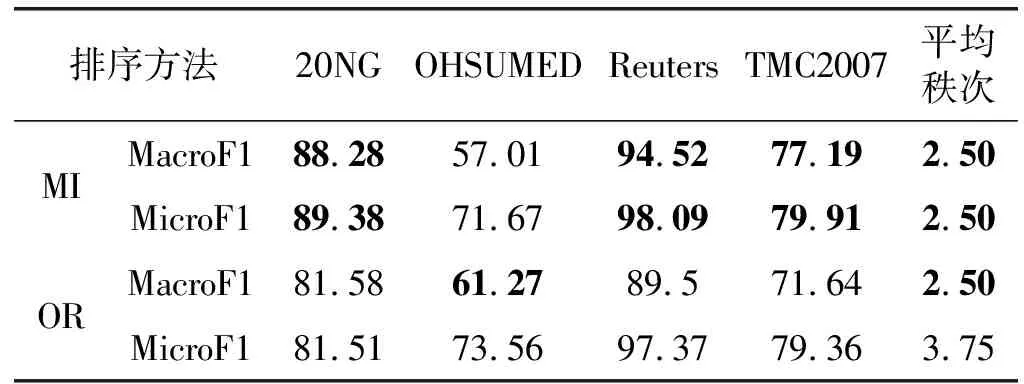
表1给出了对于所有排序方法和所有数据集,在MacroF1和MicroF1上的RF-Boost的最优结果。从表1可知,MI在除OHSUMED数据集之外的所有数据集上均取得了最优MacroF1和MicroF1值;OR特征排序法的平均秩次仅次于MI;OR在OHSUMED数据集上取得了最优MacroF1值;GSS排序法在整体上性能最差。

表1 RF-Boost的最优MacroF1和MicroF1数值(%)
续表1
3.3.2Boosting算法的比较评价
本文通过实验证明MI的性能最佳,所以将其作为特征排序和选择方法,对所有Boosting算法进行评价。图3给出了在使用不同Boosting轮数时,所有Boosting算法在4个数据集上的MacroF1结果。当Boosting轮数超过400时,AdaBoost.MH的性能稍优于RF-Boost。但在Boosting轮数为200至400之间时,本文方法取得了最优性能。本文方法在除TMC2007之外的所有数据集上的性能均优于AdaBoost.MH。图4给出了MicroF1结果。可见本文方法在20NG和OHSUMED数据集上性能优于AdaBoost.MH,后者在Reuters和RMC2007数据集上性能更好。此外,RF-Boost在除OHSUMED之外的所有数据集上均优于AdaBoost.MH和本文方法。

(a) 20NG (b) OHSUMED
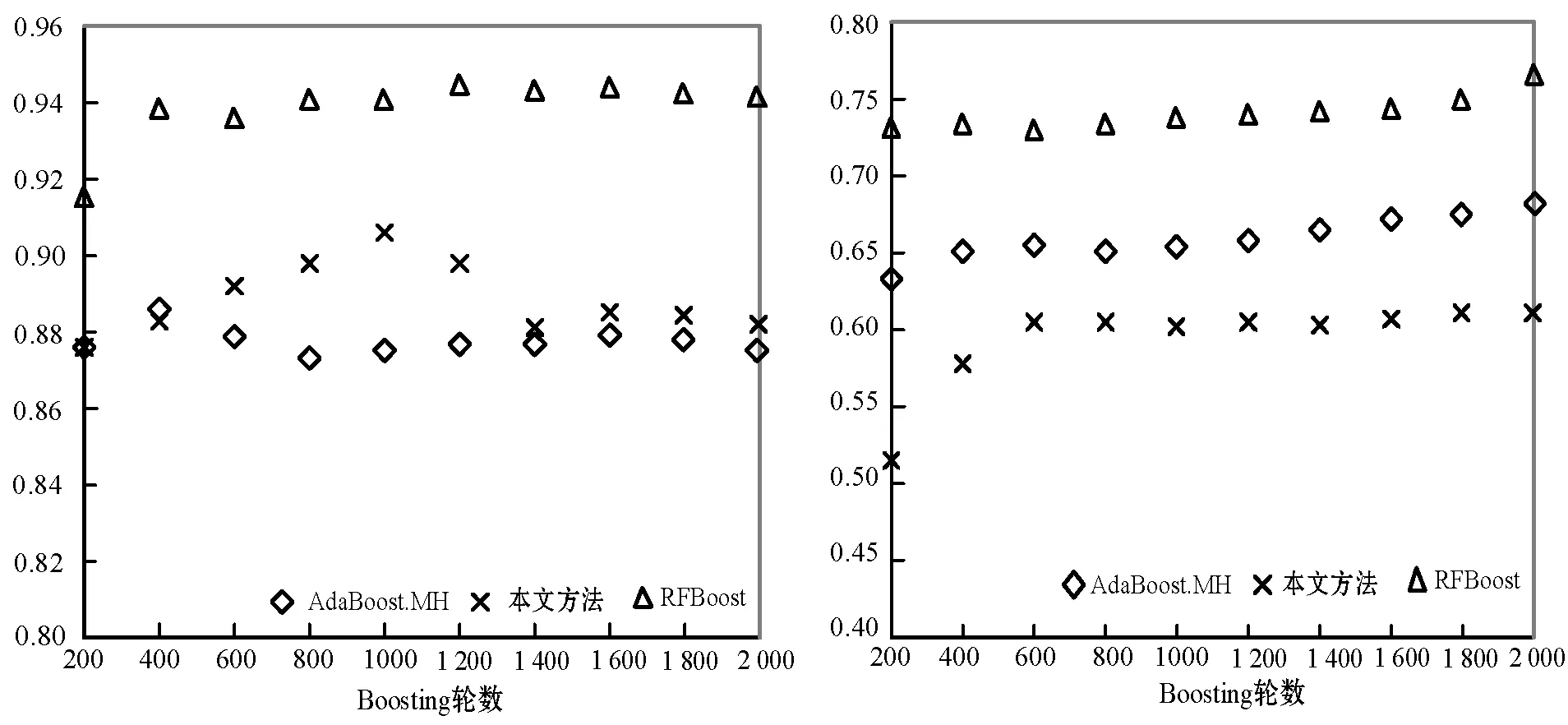
(c) Reuters (d) TMC2007图3 不同轮数时Boosting算法的MacroF1数值
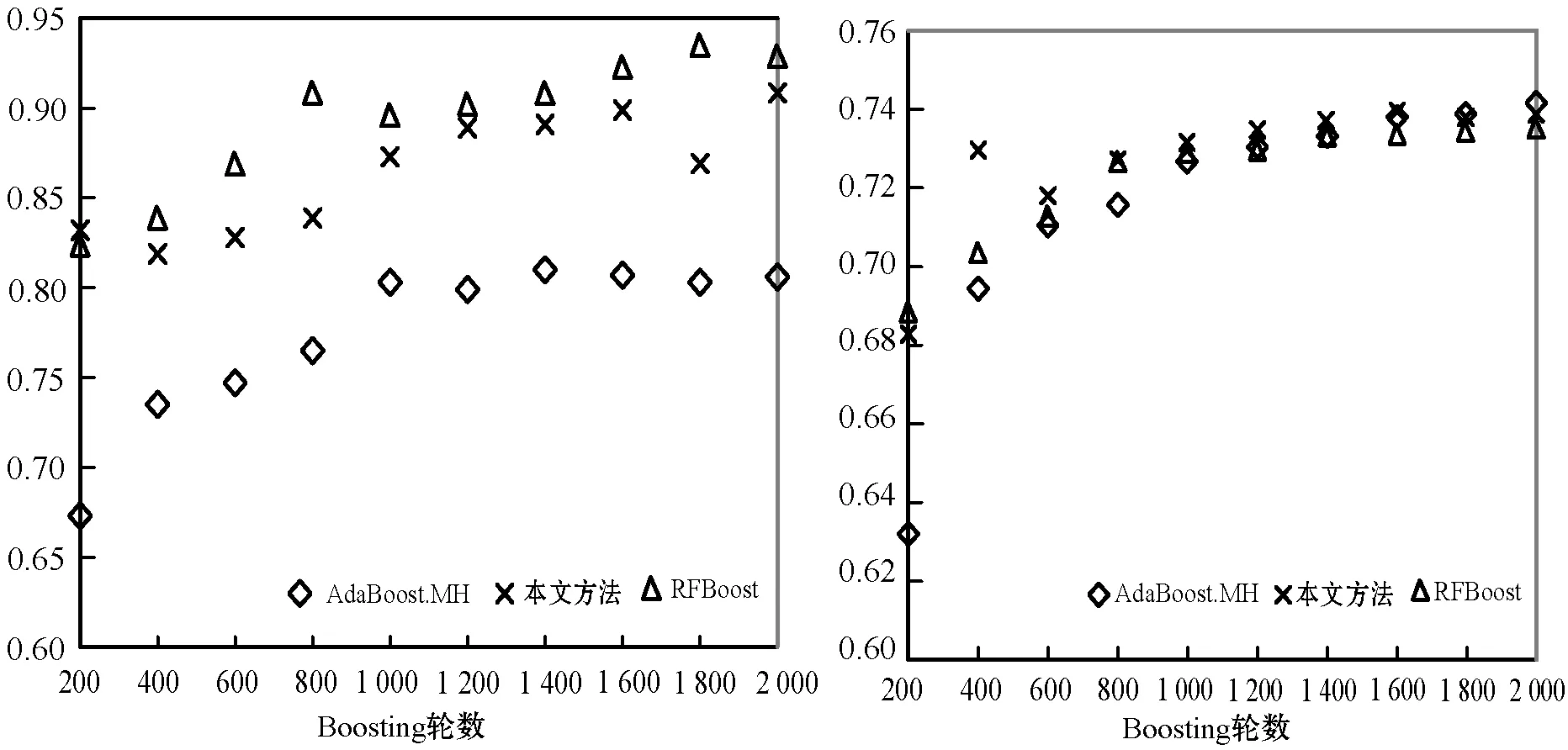
(a) 20NG (b) OHSUMED
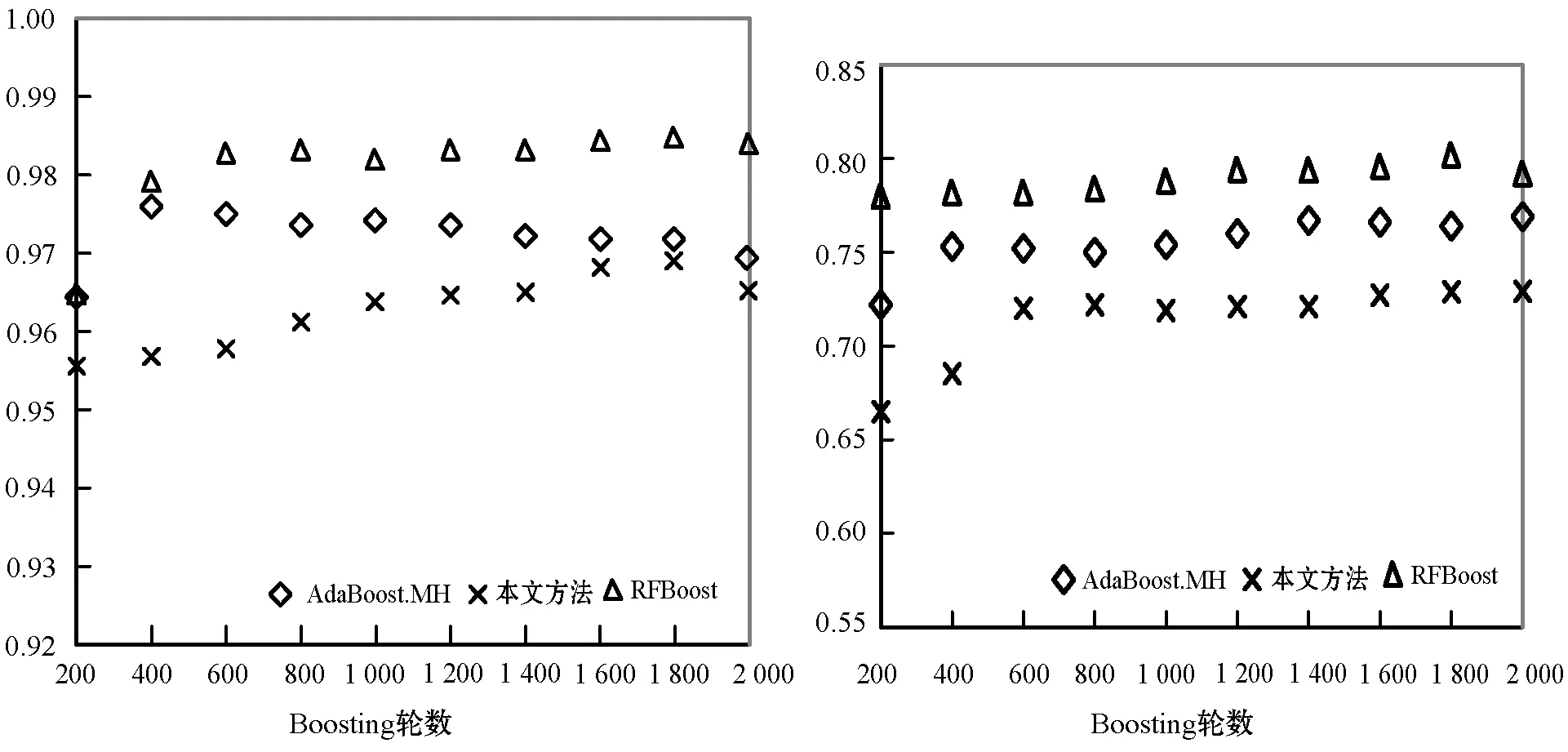
(c) Reuters (d) TMC2007图4 不同轮数时Boosting算法的MicroF1数值
表2给出了所有数据集上,所有Boosting算法的最优MacroF1和MicroF1数值。为了验证Boosting算法之间差异的统计显著性,本文使用5%显著水平下的秩和检验,并进行双尾Bonferroni-Dunn检验,以逐对的方法进行比较。但Boosting算法的最优实验结果不能用于分析该算法在所有Boosting轮的整体性能,将使用特定Boosting轮数取得的每个分类结果作为验证统计显著性的独立观察。

表2 所有Boosting算法的最优MacroF1和MicroF1结果(%)
为了验证Boosting算法之间的差异显著性,首先基于MacroF1度量,对每个Boosting轮数和所有数据集上的分类性能进行排序。然后,进行秩和检验,并根据式(20)得到分布。得出的p值为0.000 1,低于显著水平(0.05)。这表明方法性能之间存在显著差异,且剔除具有相同性能的弱假设。在剔除了弱假设后,本文进行双尾Bonferroni-Dunn检验。表3给出了Boosting算法之间的逐对比较,其中秩和检验之后进行的双尾Bonferroni-Dunn检验,α=0.5,临界值为5.991,p值(双尾)为0.000 1,Bonferroni纠正显著水平为0.016 7。由表可知,RF-Boost显著优于本文方法和AdaBoost.MH。此外,本文方法和AdaBoost.MH的性能之间无显著差异,但本文方法的训练比AdaBoost.MH要快得多,是比AdaBoost.MH更优秀的分类器。

表3 不同算法之间的逐对比较
3.4 计算成本
假定训练样本数为n,分类数为m,训练特征数(特征选择之后)为v。AdaBoost.MH中执行一次Boosting迭代的时长与n、m和v为线性关系,即时间复杂度为O(mnv)。RF-Boost将v减少至较少数量k。因此,RF-Boost中一轮Boosting的时间复杂度为O(mnk)。本文方法仅将一个特征传入基础学习器,即k=1。因此,本文方法的时间复杂度为O(mn),即本文方法计算时间与分类数量和训练集大小是线性相关的。
图5给出了在Reuters数据集上,不同轮数的Boosting算法的学习成本。测试系统使用Java开发,PC配置了3.00 GHz Inter CORE-i5处理器,8.00 GB RAM,使用Windows 10 64位操作系统。从图5可知,本文方法在所有案例中速度均最快,其次为RF-Boost,AdaBoost.MH速度最慢。本文方法比AdaBoost.MH快约4倍,因此适用于学习时间要求较高的文本分类任务。

图5 不同Boosting算法的学习时间
4 结 语
特征排序对RF-Boost的准确度和速度至关重要,本文通过实验证明,在众多特征排序法中,MI能够改进RF-Boost的性能。但由于特征排序法的性能基本上取决于数据集的性质,所以不存在整体上的最优特征选排序法。
本文提出了改进的RF-Boost方法,即IRF-Boost,从排序靠前的特征中选择一个特征进入基础学习器,用以生成新的弱假设。实验结果证明,本文方法能够加速了学习的过程,且不会降低分类性能。本文方法的性能与AdaBoost.MH无显著差异,但本文方法的主要特点是快速性,其速度比AdaBoost.MH约快4倍。
猜你喜欢
客联(2022年3期)2022-05-31
中学生数理化·七年级数学人教版(2022年11期)2022-02-14
中国新闻周刊(2021年26期)2021-07-27
数学年刊A辑(中文版)(2020年2期)2020-07-25
科普童话·学霸日记(2020年1期)2020-05-08
数学物理学报(2019年6期)2020-01-13
井冈山大学学报(自然科学版)(2019年4期)2019-09-09
小天使·一年级语数英综合(2019年2期)2019-01-10
信息安全研究(2016年4期)2016-12-01
