
一种求解多目标FJSP的自学习遗传算法
2022-12-06 11:05常镜洳
小型微型计算机系统 2022年12期
常镜洳,于 东
1(中国科学院大学,北京 100049)
2(中国科学院 沈阳计算技术研究所,沈阳 110168)
3(大连东软信息学院,辽宁 大连 116023)
1 引 言
FJSP(flexible job-shop scheduling problem)已被证明为一种强NP难问题[1],作为智能化生产制造[2,3]中经典决策活动,在生产管理系统中占据核心和关键位置,其生产决策方案的精准度、可靠性、时效性很大程度上体现企业的智能化水平.由于全局搜索和并行搜索的优越性,遗传算法(GA)是解决多目标FJSP问题的最广泛群智能优化算法之一[4].
Gu等针对复杂柔性生产调度问题,提出了一种改进的自适应变邻域搜索遗传算法[5].Zeng等针对混合工作日历下的多目标FJSP问题,设计了一种基于精英策略的非支配排序遗传算法[6].Rooyani D等对大规模工件生产问题,提出了一种高效的两阶段遗传算法[7].Shi等利用模糊学和IGA算法求解能源消耗最小、最大完工时间和消费者满意度最大等不确定多重目标的FJSP问题[8].朱等基于直觉模糊集相似度改进遗传算法,求解空闲时间、机器能耗为目标的多目标FJSP问题[9].Wang等设计并行双链式编码,结合变邻域搜索强化遗传算法的局部搜索能力,解决多目标的柔性生产调度问题[10].
GA的性能与交叉概率(Pc)和变异概率(Pm)紧密相关.如果Pc和Pm太大,较优解易丢失;如果Pc和Pm太小,则很难生成新染色体[11,12].因此,采用遗传算法作为多目标FJSP基本优化方法,并基于增强学习(RL)对Pc和Pm进行种群迭代间智能调整.本文结构如下:第2章节FJSP问题描述及数学建模;第3章节介绍基于非支配排序的GA算法和增强学习算法;第4章节介绍融合算法模型及增强学习设计要素;实验验证在第5章节展示;最后结论部分进行总结及下一步研究工作介绍.
2 问题定义
n×m的FJSP问题描述如下:车间n种独立工件J={J1,J2,J3,…,Jn}在m台独立机器M={M1,M2,M3,…,Mm}上加工;每个工件Ji有多道加工工序Oij(第i个工件Ji的第j个工序,j=1,2,3,…,hi),并按照一定先后工艺次序进行加工,且每道工序Oij可被多台机器进行加工,Oij在机器Mk(k=1,2,3,…,m)上的加工时间tijk固定且已知.
3个调度目标:最大完工时间最小Cmax、最大负荷机器最小Wm、总机器负荷最小Wt,其目标函数如式(1)~式(3)所示:
(1)
(2)
(3)
问题约束函数如下:
tij≥0,sij≥0i=1,2,3,…,n;j=1,2,3,…,hi;
(a)
sij+tij≤si(j+1)i=1,2,3,…,n;j=1,2,3,…,hi;
(b)
sij+tijk≤srt+Z×(1-yijrtk)i=1,2,3,…,n;r=1,2,3,…,n;j=1,2,3,…,hi;t=1,2,3,…,hr;k=1,2,3,…,m;
(c)
(d)
(e)
(f)
其中sij表示工序Oij在加工开始时间,hi表示工件Ji的工序总数,Z表示一个足够大的正数,mij表示工序Oij的可选加工机器数.约束式(a)表示工序的加工时间必须大于0;约束式(b)表示每一个工件的工序间先后顺序;约束式(c)表示同一台机器在同一时刻只能加工一个工件;约束式(d)表示同一工件在同一时刻只能被一台机器加工.
表1为一个2×4的FJSP实例,表中数字表示加工时间tijk,‘-’表示工序在对应机器上不能被加工.
3 基础算法
3.1 遗传算法
3.1.1 编码
染色体采用A/B分段编码,将FJSP的工序排序(OS)和机器选择(MS)两个子问题分开表示,OS部分基因位长度和MS部分基因位长度都等于所有工件工序数总和T0,以表1的P-FJSP为例,一个染色体编码如图1所示.
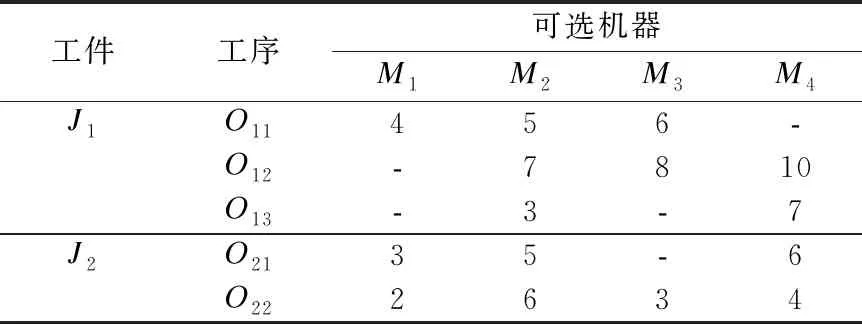
表1 P-FJSP实例
图1从左至右,OS部分从左至右的先后顺序表示工序Oij间的先后加工顺序,第1个2′代表工件J2,J2第1次出现表示工序O21.MS部分整数基因位依次对应OS部分工序Oij选择的机器,左边第1个1′代表工序O21在可加工机器集{M1,M2,M4}中选择M1.

图1 一条染色体表示
3.1.2 种群初始化
为提高初始种群解的质量,本算法的工序排序OS部分采用随机方法生成,而机器选择MS部分采用全局选择GS、局部选择LS和随机选择RS相结合的方式生成.
全局选择机器是以所有机器负荷均衡化的角度,使用贪心算法设计策略为每个工序选择当前可加工机器中负荷最小的机器;局部选择机器在每个工件内部使用贪心设计策略,在每个工件Ji内,其每个工序Oij选择机器时,考虑所有机器负荷均衡化的角度;下一个工件Ji+1的第一个工序选择机器时,每台机器负荷重新设置为0.
3.1.3 快速非支配排序和适应度值分配
依据NSGA-II[13]中快速非支配排序,将种群P划分成互不相交的且具有支配关系的子群体P1P2…Pn,对染色体支配关系进行分类划定对应帕累托阶层prank=1,2,3,…,n.
为保证种群分布多样性,采用小生境技术中的拥挤距离.Dij表示同一帕累托阶层Pi中染色体i、j之间的距离如见式(4),则染色体i到同层染色体距离的最小值为i的拥挤距离Cd(i)如式(5)所示:
Dij=|Cmax(i)-Cmax(j)|+|Wm(i)-Wm(j)|+|Wt(i)-Wt(j)|(i≠j)
(4)
Cd(i)=min{Di1,Di2,…,Dik,…,Din}(i≠k)
(5)
根据染色体i所在的帕累托阶层prank和其拥挤距离Cd(i),计算适应度值分配;计算公式如式(6)所示:
(6)
3.1.4 遗传算子
1)选 择
本文采用轮盘赌和精英保留策略相结合的选择方法,两者相辅相成加快算法收敛速度.假设种群规模为popSize,前popSize-1个染色体通过轮盘赌方法选择,第popSize个染色体设置为当前种群中适应度值最高的染色体.
2)交 叉
Price及Stephens等在1975年的Holland的模式理论基础上做了相关研究表明[14]:进化算法的多点交叉上,适应度高的模式在子代中成指数阶增长.因此本算法在MS部分采用均匀交叉方式,OS部分采用POX(基于工件优先顺序交叉)方式.
3)变 异
机器选择部分采用多轮单点交换变异;为了提高GA的局部搜索能力且保证种群多样性,OS部分采用邻域搜索变异.
3.2 增强学习
增强学习[15,16]基础模型包括环境、智能体、行动策略、奖励、值函数,通常用马尔科夫决策过程(Markov Decision Process)[17]描述学习过程.环境的状态空间S,智能体采取的行动空间A,智能体感知到环境当前状态st(st∈S)并对其实施行动at(at∈A),行动at作用在状态st上,环境状态发生变化,转移至状态st+1,同时给予智能体奖励rt+1,智能体根据rt+1更新行动选择,并对环境实施下一个行动at+1.
SARSA和Q-learning[18]是两种典型的基于值的增强学习算法.Q值用于表征动作选择,SARSA和Q-learning的一步更新函数如式(7)和式(8)[19]所示:
Q(st,at)=(1-α)Q(st,at)+α(rt+1+γQ(st+1,at+1))
(7)
Q(st,at)=(1-α)Q(st,at)+α(rt+1+γmaxQ(st+1,at+1))
(8)
其中Q(st,at)为状态st与动作at的Q值函数,rt+1为动作at执行后奖励值,α为学习率,γ为学习折扣率.
本文将SARSA和Q-learning算法结合动态调整Pc和Pm;种群迭代初期,GA与SARSA结合,通过公式(7)更新Q值;种群迭代次数满足公式(9)转换条件,GA与Q-learning结合,Q值通过公式(8)更新.
(9)
其中t表示当前迭代次数,|S|表示环境状态总数,|A|表示行动总数.
4 融合算法
4.1 融合算法模型
GA与RL融合算法模型如图2所示,包括GA环境、增强学习模型和学习过程.学习过程如下:

图2 融合算法模型
1)RL获取GA的状态st;
2)RL根据行动选择策略确定行动at:确定种群当前迭代Pc、Pm值;
3)GA执行at,即根据Pc、Pm值执行遗传算子,GA环境状态转移至st+1;
4)RL从GA获取奖励值rt,更新行动选择以确定下一步行动at+1,并计算Q值以更新Q值表.
4.2 学习模型设计要素
1)GA状态集
多目标FJSP的目标包括最大完工时间最小Cmax、最大负荷机器最小Wm、总机器负荷最小Wt,因此非支配排序分配的适应度作为GA环境状态依据,GA算法状态st计算公式如式(10)所示:
(10)

GA环境状态集S={s1,s2,…,s19,s20}[20],S取值范围[0,1),s的取值跨度为0.05.若st∈[0,0.05),则s=s1;若st∈[0.05,0.1),则s=s2;依此类推,若st∈[0.95,1),则s=s20.
2)行动集
学习模型中行动确定GA的交叉概率Pc和变异概率Pm,因此行动集A={a1,a2,…,a9,a10}.Pc取值范围[0.4,0.9],因此每个交叉概率取值跨度为0.05;例如学习模型根据策略选择行动a1,那么Pc∈[0.4,0.45],从[0.4,0.45]中选取一随机数赋值给Pc.Pm取值范围[0.01,0.21],每个变异概率取值跨度为0.02,例如选择行动a2,那么Pm∈[0.04,0.06],从[0.04,0.06]中选取一随机数赋值给Pm.
3)奖励函数
交叉和变异算子分别体现GA的全局搜索和局部搜索能力,因此最优染色体适应度和平均染色体适应度分别体现Pc和Pm的奖励.如果第t代中最优染色体适应度值优于第t-1代中最优染色体适应度值,说明当前Pc的有效性,因此GA给与智能体有效的奖励rc;如果第t代平均染色体适应度值优于第t-1代平均染色体适应度值,说明当前Pm的有效性,因此GA给与智能体有效的奖励rm;rc和rm的计算公式如式(11)、式(12)所示:
(11)
(12)
其中Bestf(xit)表示第t代种群Population中最优适应度.
4)行动策略
exploitation和exploration是矛盾体,若使得累计奖励最大,必须在两者间达成折中.ε-greedy策略基于概率进行折中,以ε概率进行exploration,以1-ε概率进行exploitation,其表达式如式(13)所示:
(13)
4.3 融合算法流程
融合算法流程图如图3所示,其具体实现步骤如下:

图3 融合算法流程
Step1.初始化基本参数
1)GA基本参数:全局选择比例Pgs、局部选择比例Pls和随机选择比例Prs、种群规模Popsize和迭代上限Iteration等.
2)初始化RL基本参数:状态集S、行为集A、学习率α、学习折扣率γ、奖励值r、Q值表等.
Step2.根GA中种群初始化策略和染色体编码规则生成初始种群Population;并设置当前迭代次数t←0.
Step3.为初始种群中每个染色体划定帕累托阶层、计算拥挤距离、基于阶层和距离分配适应度.
Step4.从行动集中随机选择一个行动at,令a←at;根据公式(10)计算GA算法的状态st,令当前状态s←st.
Step5.判断迭代次数t是否达到上限,如果达到,输出最优解集;否则转入步骤6.
Step6.根据公式(11)和(12)计算奖励函数rc和rm.
Step7.判断转换条件式(9)是否达到,若未达到,转至Step8;否则转至Step 9.
Step8.根据ε-greedy策略选择行动at+1,并根据公式(7)更新Q值表.
Step9.根据贪心策略选择行动at+1,并根据公式(8)更新Q值表,根据ε-greedy策略更新行动at+1.
Step10.根据公式(10)计算GA算法的状态st+1,更新当前状态s←st+1;更新当前行动a←at+1;
Step11.根据a中Pc和Pm执行遗传算子,生成新的种群Population,迭代次数t←t+1.
Step12.解码活动调度:种群Population中每个染色体划定帕累托阶层、计算拥挤距离、基于阶层和距离分配适应度.
Step13.转至步骤5.
5 实验测试
上述融合算法在Matlab 2018a上采用matlab语言实现,程序在处理器Intel CoreIi5-5200U,主频2.2GHz,内存8G的PC机上运行.为证明该融合算法求多目标FJSP最优解集的准确性和高效性,实验测试包含:
实验1.选用Kacem et al.设计的8×8、10×10、15×10实例[21]测试Pareto最优解集准确性;
实验2.选取Brandimarte的标准实例mk01-mk10[22]进行算法时间效率测试.
算法其他参数设置:种群规模Popsize为100,最大迭代次数Iteration为100,全局机器选择概率Pgs=0.6,局部机器选择概率Pls=0.3,随机选择机器概率Prs=0.1;初始Q值表:一个20行10列的0值矩阵,初始化随机选取行动a,奖励函数r=1,策略贪心率ε=0.85,学习率α=0.75,学习折扣率γ=0.2.
5.1 实验1
以Kacem设计8×8、10×10、15×10问题数据进行测试,每个问题仿真实验运行30次.为验证算法有效性,将测试结果和EDA[23]、DCRO[24]、GSA-M[25]算法进行比较,测试结果如表2所示.
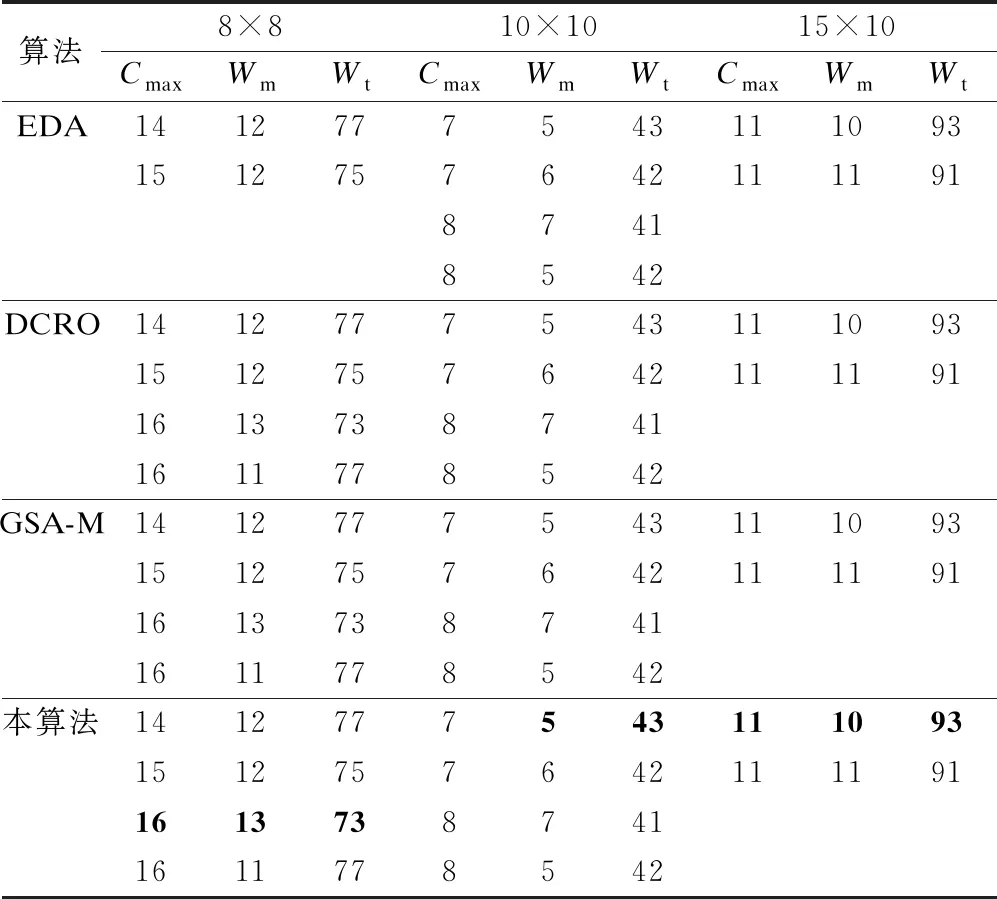
表2 Kacem的3个算例数据对比
8×8问题本算法和其他算法相比,最优解都找到了,且最优解(16,13,73)找到的频率最高,其调度方案如图4所示.10×10的问题本算法和其他算法相比,最优解都找到了,且最优解(7,5,43)找到的频率最高,其调度方案如图5所示.15×10的问题本算法和其他算法相比,两个最优解都找到了,且最优解(11,10,93)找到的频率最高,其调度方案如图6所示.

图4 8×8问题实例解(Cmax=16,Wm=13,Wt=73)

图5 10×10问题实例解(Cmax=7,Wm=5,Wt=43)

图6 15×10问题实例解(Cmax=11,Wm=10,Wt=93)
5.2 实验2
为证明该多目标融合算法的时间有效性,测试算例选取Brandimarte设计的mk01-mk10数据;在改进的快速非支配排序GA算法基础上,对GA、GA+SARSA、GA+Q-Learning和本文中融合算法进行执行时间对比,以及mk06算例交叉和变异数量对比.
每组算例均仿真实验运行30次,执行时间取平均值,测试结果如表3所示,在每组算例上提出的融合算法的执行平均时间都最小.mk06算例仿真实验运行30次,交叉数量和变异数量取平均值,测试结果如表4所示;第2行和第3行中所提融合算法的交叉数和变异数均最少;第4行和第5行表示所提算法相对于其他3种算法的缩减百分比.
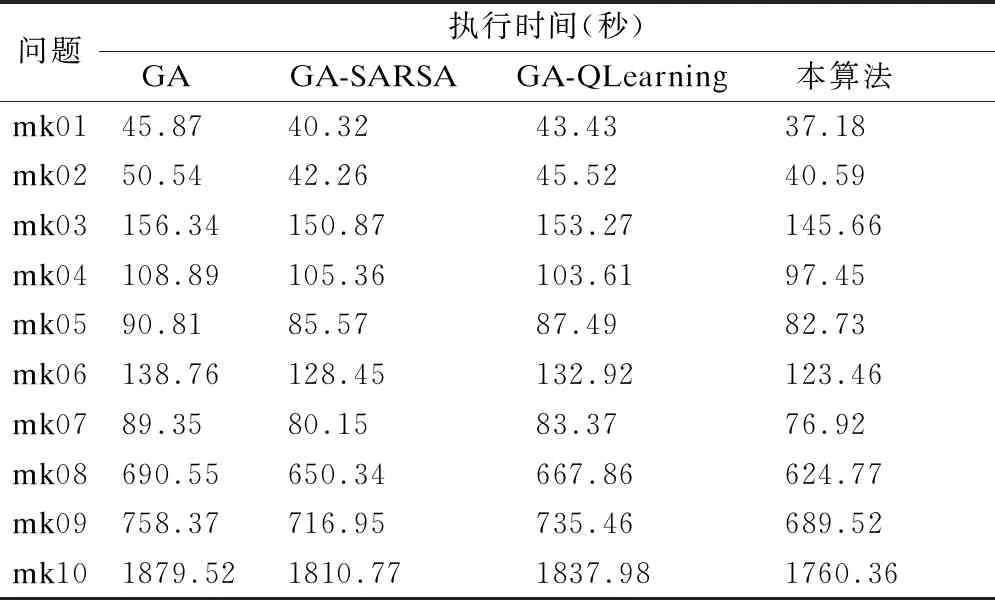
表3 Brandimarte的10个算例执行时间对比

表4 交叉和变异平均数量对比
所提融合算法保证解的质量的同时,通过增强学习,GA减少了冗余的交叉和变异操作;通过统计分析验证了该融合算法的时间有效性.
6 结 论
实验1证明融合算法寻找多目标最优解的准确性,实验2证明融合算法求解多目标FJSP问题的时间高效性,为求解多目标柔性车间调度问题提供一条有效途径.
在实际车间生产复杂场景下解决FJSP问题,GA算法的Pc和Pm直接影响算法效率,如果值太大,较优解容易丢失,如果它们值太小,影响种群多样性.本文提出的融合调度算法,提升智能生产中决策活动的自适应性、动态调度的可操作性.
针对碳中和节能为目标的柔性作业车间调度实际生产环境中,单纯依靠智能算法并不能有效、快速解决所有机器故障柔性作业车间动态调度问题[26].下一步研究重点:在本融合算法基础上研究基于人机协同的多目标柔性作业车间动态调度问题.
猜你喜欢
计算机仿真(2022年8期)2022-09-28
山东冶金(2022年3期)2022-07-19
昆钢科技(2022年2期)2022-07-08
石材(2020年4期)2020-05-25
建材发展导向(2019年10期)2019-08-24
科学之谜(2019年3期)2019-03-28
科学之谜(2018年8期)2018-09-29
郑州大学学报(工学版)(2018年2期)2018-04-13
恋爱婚姻家庭·养生版(2016年9期)2016-09-07
中国塑料(2016年11期)2016-04-16
