
基于支持向量机的微博情感分析方法研究
2022-12-08 17:03李首政
现代计算机 2022年19期
李首政,王 琪,王 力
(1.南阳理工学院信息工程学院,南阳 473000;2.南阳理工学院土木工程学院,南阳 473000)
0 引言
微博作为国内最大的社交媒体之一,是一种极其丰富的文本来源,具有内容精炼、时效性强、简短、通俗等特点,研究专门的情感分析技术有利于决策者分配业务及合理的决策[1]。
过去人工监控和分析的方法不仅需要耗费大量的人力成本,而且产生了很大的滞后性。目前对微博数据进行情感分析的方法主要包括两大类,基于情感词典的方法和基于机器学习的方法。基于词典的方法虽然设计思想简单,准确率较高,但需依赖于专业人士的词典构造,人工工作量巨大,且受限于词典先验知识,普遍性不强[2]。基于KNN 的分类方法虽然算法简单,但准确率较低且内存占用量较大[3]。Krishnaveni 等[4]提出面向文本的朴素贝叶斯分类器的基本思想,然而经典的回归思想和贝叶斯方法都是基于一个假设,即概率分布及分布模型是先验的,但实际数据集往往并不同分布,因此准确率较低。基于深度学习的方法采用RNN 的方法虽然准确率较高,但需大量数据进行模型训练,且参数较大,实际应用中小样本数据存在过拟合问题[5]。支持向量机(SVM)方法采用监督方式学习数据的分布模型,从而有效避免了先验模型与实际模型差距较大的问题[6-7]。
本文分析微博文本数据,提出了一种基于支持向量机的微博文本分析方法,首先爬取微博文本数据并进行预处理,然后采用TF-IDF 算法进行文本向量化,通过词袋模型获得文本特征向量,设计高斯核支持向量机分类模型对文本特征向量进行分类器训练,最终,获得微博文本数据的情感分类结果,通过实验分析本文支持向量机方法的准确性,总体流程如图1所示。

图1 总体结构
1 文本预处理及特征获取
通过微博数据爬取工具Weibo Spider 爬取微博平台个人发布数据,获得微博文本原始数据。然而,直接爬取的数据存在大量冗余和无效内容,且计算机并不能直接处理文本信息,因此需要对文本数据进行预处理,使得文本特征向量更准确,从而达到提高训练准确性的目的。文本预处理包含文本清洗、情感标注、文本分词、去除停用词四部分。预处理后的文本计算机并不能直接处理,本文提出基于关键词的词袋模型,获得文本特征矩阵降低文本特征矩阵稀疏性,最终,构建了实验数据为10000条的训练集和500条的测试集数据。
1.1 文本预处理
1.1.1 文本清洗和情感标注
由于爬取程序是直接复制博主发布的内容,导致爬取的数据中包含了“#”开头和“#”结尾的Tag等较多无效内容,因此需要对无效信息进行清洗。同时,由于微博短文本的特点,爬取信息中包含较多表情符号,而这些表情符号可以很好地体现人的情感,因此将表情符号转换为同义文本表示,比如微博常见的允悲表情,用文字“允悲”表示。文本分类是有监督学习,因此清洗后的训练集文本需进行情感标注,根据自然语言知识及人类普遍认知对爬取的文本逐条进行情感标注,本文设计的情感分为积极和消极两种情感,积极情感用标签“1”表示,消极情感用标签“0”表示。
1.1.2 文本分词和去除停用词
文本由词语组成,而与英文句子相比,中文句子中若没有空格则无法简单地识别词语,因此需要分词。本文采用jieba 分词工具进行文本分词。停用词是指一些无意义词的中文词,比如“你,我,他”,“如果,那么”。去除停用词是常见的NLP 预处理的一个步骤,能帮助减少特征矩阵的大小,从而减少特征矩阵的计算消耗,实现减少计算时间和成本的目的。清洗后的文本标注“积极”或“消极”情感标签,用于构建数据集及模型训练。
1.2 基于关键词的词袋模型
本文采用词袋模型将文本进行向量化。但传统词袋模型获得的文本向量稀疏性较强,存在很大冗余且不能体现句子关键词,因此本文提出基于关键词的词袋模型,从而获得文本特征向量,算法通过IF-IDF 方法获得,包括三个步骤。
第一步,通过TF-IDF 算法提取文本特征词,由特征词构建新的文本词袋,从而解决了传统词袋模型高冗余性的问题,同时能够体现词的权重概率。
特征词提取主要是指提取出有利于情感分析分类的情感词,本文采取TF-IDF 算法计算每个词的IF-IDF 值,并采用L2 范数进行标准化,选取文档权值最高前20 个词作为特征词。TF 是词出现的频率,TF-IDF 的基本思想是如果某个单词在一篇文章中出现的频率TF 高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合作为特征词,算法见式(1)—(4)。

第二步,运用新建的词袋表计算句子的词袋向量,并将每个词的TF-IDF值替代传统词袋向量中词出现的次数。
第三步,数据标准化的目的是通过标准化得到均值为0 和标准差为1 的服从标准正态分布的数据,此外,标准化能提升分类器拟合的速度,同时缩小可能的异常值的影响。本文采用数据标准化的方法是减去均值然后除以方差或标准差,经过这种数据标准化方法处理过的数据符合标准正态分布。
2 分类器构建
2.1 线性分类器
支持向量机算法的基本思想是寻找一个分类器,使得超平面和最近的数据点之间的分类边缘(超平面和最近的数据点之间的间隔)最大。对于SVM 算法,通常认为分类边缘越大,平面越优,通常定义具有最大间隔的决策面就是SVM 要寻找的最优解。因为支持向量到决策边界有一定的距离,因此支持向量机容许一定的误差,算法的鲁棒性得到一定的提高。对线性可分样本集T=,其中x(m)∈ℝn,y(m)∈{-1,1};选择惩罚参数C>0,构造并求解凸二次规划。

其中ɑj为拉格郎日乘子,得到最优解a*=(a1
*,a2*,…,aN
*)T。
计算ω*=yixi,b*=yj-yi(xi·xj),得到超平面ω*x + b*= 0,则分类决策函数:

可见,SVM 分类问题需求解样本的内积,然而实际样本往往线性不可分,因而需引入核函数,核函数可将样本向量映射到高维核空间,使得原本线性不可分的样本变为线性可分,核函数一般包括线性核函数、多项式核函数和高斯核函数。
2.2 高斯核函数
高斯核函数可以将输入特征映射到无限多维,不仅可以解决样本线性不可分的问题,而且能够突出样本特征的相似性,同时相比多项式核函数计算量更小,因其仅需一个参数σ,所以调参较易。

引入高斯核函数后分类器优化问题变为

3 实验与分析
采用本文方法爬取数据并进行文本处理后构建了10000 条数据作为训练集,500 条作为测试集。统计出训练集的文本长度分布如图2 所示,文本长度集中在31—151区间,更接近于真实语料环境。训练集经过标注后得到1 标签和0标签的文本数量分布如图3 所示。图3 横坐标的0 代表着文本的情感是消极的;横坐标1 代表着文本的情感是积极的。由图3可见训练样本中积极情感占比54.96%,消极情感占比45.04%,积极情感略高于消极情感,但整体数量相当,合理的数据分布有利于提高分类器训练的准确性。
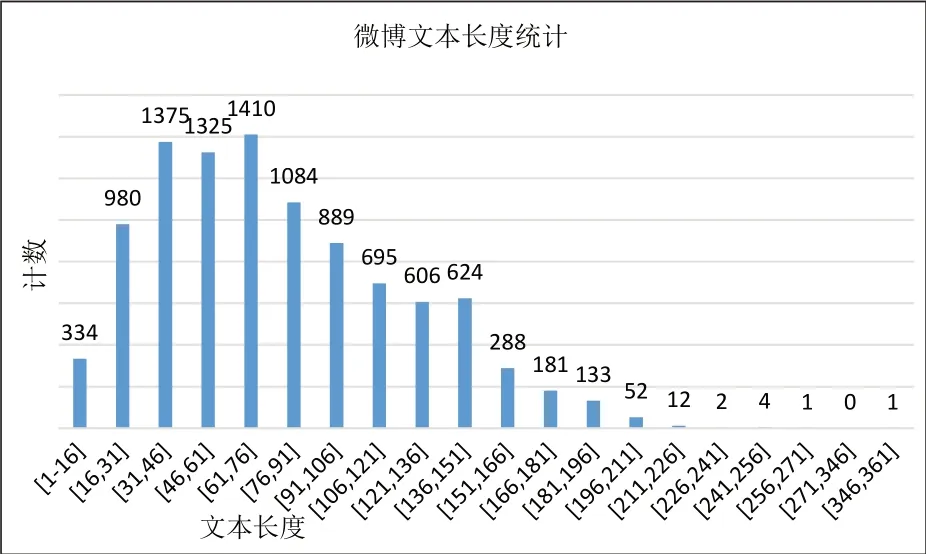
图2 微博训练集文本长度统计
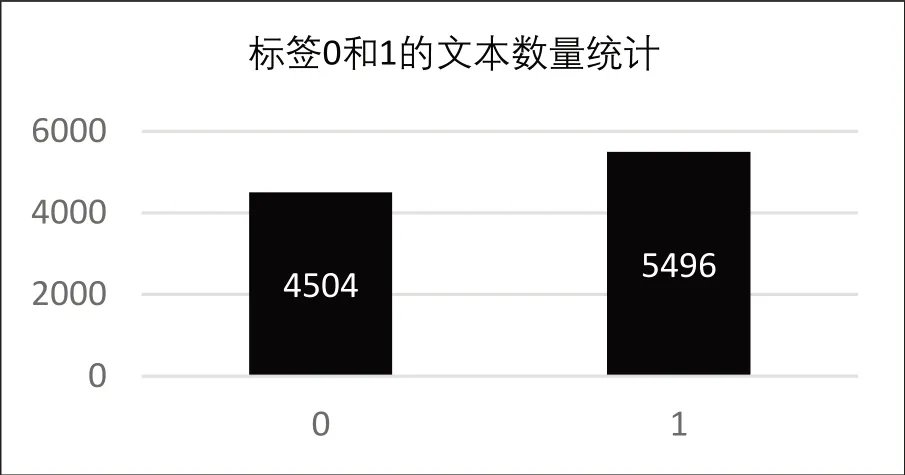
图3 微博训练集情感极性分布
通过基于关键词的词袋模型对10000条训练集文本进行特征词提取,共提取出61949个特征词,并获得(10000,61949)大小的文本特征矩阵,500条测试集特征矩阵大小为(500,1949)。利用本文高斯核SVM 的方法对训练集数据进行训练,学习曲线如图4 所示,由图4 中准确率的变化趋势可见,训练集和验证集的准确率随着样本数的增大能够较好地拟合,最终稳定在较高准确率,说明本文方法获得的训练模型有较好的泛化能力。与通过传统词袋模型采用多项式SVM、线性SVM、朴素贝叶斯、KNN 和决策树五种方法的训练集和测试集得分进行对比,结果如表1 所示,SVM 三种分类器表现出较理想的效果,其中本文高斯核的SVM 方法在训练集和验证集上都取得了较高的准确率,且拟合度较好,KNN 方法和朴素贝叶斯方法的准确率不高,决策树方法出现了较严重的过拟合现象。采用本文高斯核SVM 方法和上述五种方法分别建立分类器对测试集进行验证,其预测的准确率如图5所示。

图4 高斯SVM分类器学习曲线

表1 各种方法的准确率对比结果
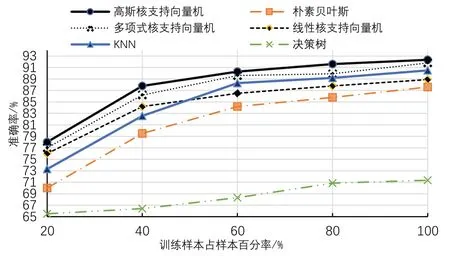
图5 分类器准确率对比图
图5可见,使用小样本训练支持向量机分类器已经取得不错的准确率,与同等样本数训练的其他分类器相比有明显的优势,随着样本数的增加,六种分类器的准确率均有所提高,且KNN 和朴素贝叶斯分类器与SVM 分类器准确率差距有所缩小,其中本文高斯SVM 的方法准确率最高。决策树方法由于存在过拟合现象导致总体效果不佳。由此可见,本文采用的高斯SVM 方法在微博情感分析中能取得较高的准确率,且相比KNN、朴素贝叶斯等方法,本文方法在小样本数据集上有较明显优势。
4 结语
针对当前需要对内容精炼、时效性强、通常包含简短且非正式缩写词的微博短文本情感分析问题,本文提出一种更适合微博文本情感分析的方法,通过weibo Spider 爬取微博数据并进行人工标注,构建数据集,TF-IDF 算法和词袋模型构建基于关键词的词袋模型,获得文本特征矩阵,最后采用了高斯核的支持向量机方法进行分类器训练,通过测试集验证准确率,对比多项式支持向量机、KNN、朴素贝叶斯决策树等方法,实验结果显示本文方法准确率较高,在小样本数据的情况下可获得较高的准确率。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
中国交通信息化(2018年5期)2018-08-21
计算机应用(2017年4期)2017-06-27
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
高中生学习·高三版(2016年9期)2016-05-14
